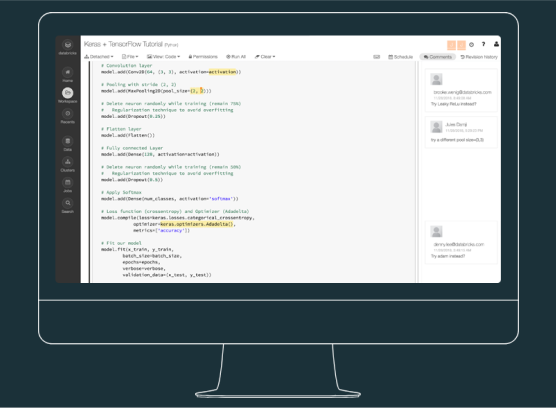
Databricks의 TensorFlow™

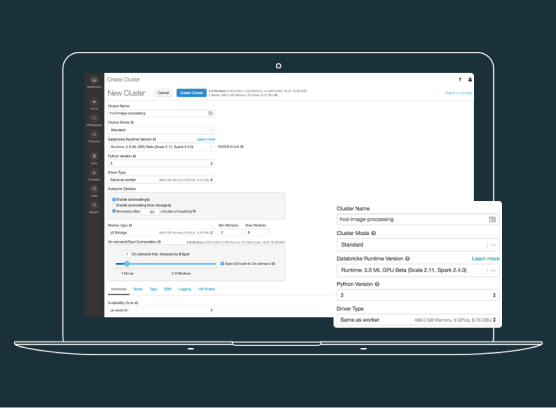
즉시 사용 가능한 TensorFlow
유연성을 극대화하기 위해 AWS와 Azure의 CPU 및 GPU 인스턴스에서 몇 초 만에 클러스터를 시작하고 실행합니다.
TensorFlow, Keras 및 관련 종속 항목을 머신 러닝용 Databricks Runtime과 즉시 통합하여 빠르게 시작합니다.
다양한 하위 수준 API 및 상위 수준 API를 활용하여 TensorFlow, Keras, Apache Spark를 사용한 최첨단 신경망을 트레이닝할 수 있습니다.
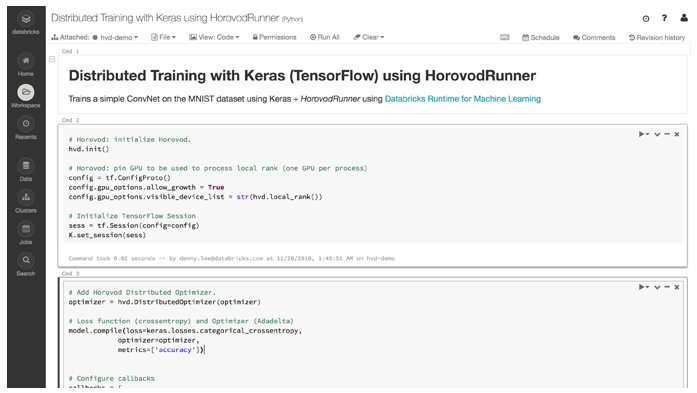
컴퓨팅 확장
새로운 Databricks HorovodRunner를 사용하여 분산 방식으로 컴퓨팅을 쉽게 확장합니다.
가속화된 하드웨어 지원(CUDA 및 cuDNN)의 이점을 활용하여 가장 까다로운 작업에서 더 나은 성능을 발휘할 수 있습니다.
필요에 따라 리소스를 자동으로 확장하고 컴퓨팅 리소스에서 스토리지를 분리하여 비용을 통제합니다.