Einführung in Fensterfunktionen in Spark SQL
von Yin Huai und Michael Armbrust
In diesem Blogbeitrag stellen wir die neue Fensterfunktionsfunktion vor, die in Apache Spark hinzugefügt wurde. Fensterfunktionen ermöglichen es Benutzern von Spark SQL, Ergebnisse wie den Rang einer bestimmten Zeile oder einen gleitenden Durchschnitt über einen Bereich von Eingabezeilen zu berechnen. Sie verbessern die Ausdruckskraft der SQL- und DataFrame-APIs von Spark erheblich. Dieser Blog wird zuerst das Konzept der Fensterfunktionen vorstellen und dann erörtern, wie sie mit Spark SQL und der DataFrame-API von Spark verwendet werden.
Was sind Fensterfunktionen?
Vor Version 1.4 unterstützte Spark SQL zwei Arten von Funktionen, die zur Berechnung eines einzelnen Rückgabewerts verwendet werden konnten. Integrierte Funktionen oder UDFs, wie substr oder round, nehmen Werte aus einer einzelnen Zeile als Eingabe und generieren für jede Eingabezeile einen einzelnen Rückgabewert. Aggregatfunktionen, wie SUM oder MAX, arbeiten auf einer Gruppe von Zeilen und berechnen für jede Gruppe einen einzelnen Rückgabewert.
Obwohl diese in der Praxis beide sehr nützlich sind, gibt es immer noch eine breite Palette von Operationen, die nicht allein mit diesen Arten von Funktionen ausgedrückt werden können. Insbesondere gab es keine Möglichkeit, sowohl auf einer Gruppe von Zeilen zu arbeiten als auch gleichzeitig einen einzelnen Wert für jede Eingabezeile zurückzugeben. Diese Einschränkung erschwert verschiedene Datenverarbeitungsaufgaben wie die Berechnung eines gleitenden Durchschnitts, die Berechnung einer kumulativen Summe oder den Zugriff auf die Werte einer Zeile, die vor der aktuellen Zeile liegt. Glücklicherweise für Benutzer von Spark SQL schließen Fensterfunktionen diese Lücke.
Im Kern berechnet eine Fensterfunktion für jede Eingabezeile einer Tabelle basierend auf einer Gruppe von Zeilen, dem sogenannten Frame, einen Rückgabewert. Jede Eingabezeile kann einen eindeutigen Frame zugeordnet haben. Dieses Merkmal von Fensterfunktionen macht sie leistungsfähiger als andere Funktionen und ermöglicht es Benutzern, verschiedene Datenverarbeitungsaufgaben, die schwer (wenn nicht unmöglich) ohne Fensterfunktionen auszudrücken sind, prägnant zu formulieren. Schauen wir uns nun zwei Beispiele an.
Angenommen, wir haben eine productRevenue-Tabelle wie unten gezeigt.
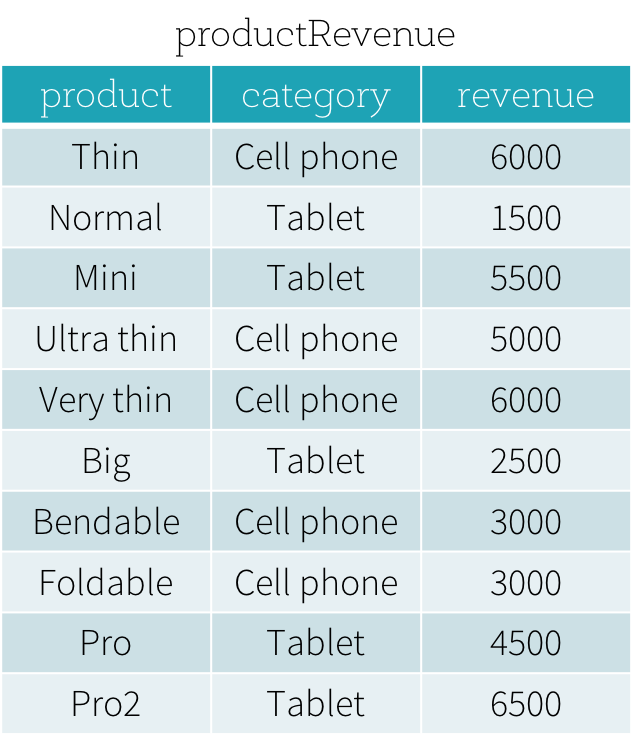
Wir möchten zwei Fragen beantworten:
- Was sind die meistverkauften und die zweitmeistverkauften Produkte in jeder Kategorie?
- Was ist die Differenz zwischen dem Umsatz jedes Produkts und dem Umsatz des meistverkauften Produkts in derselben Kategorie wie dieses Produkt?
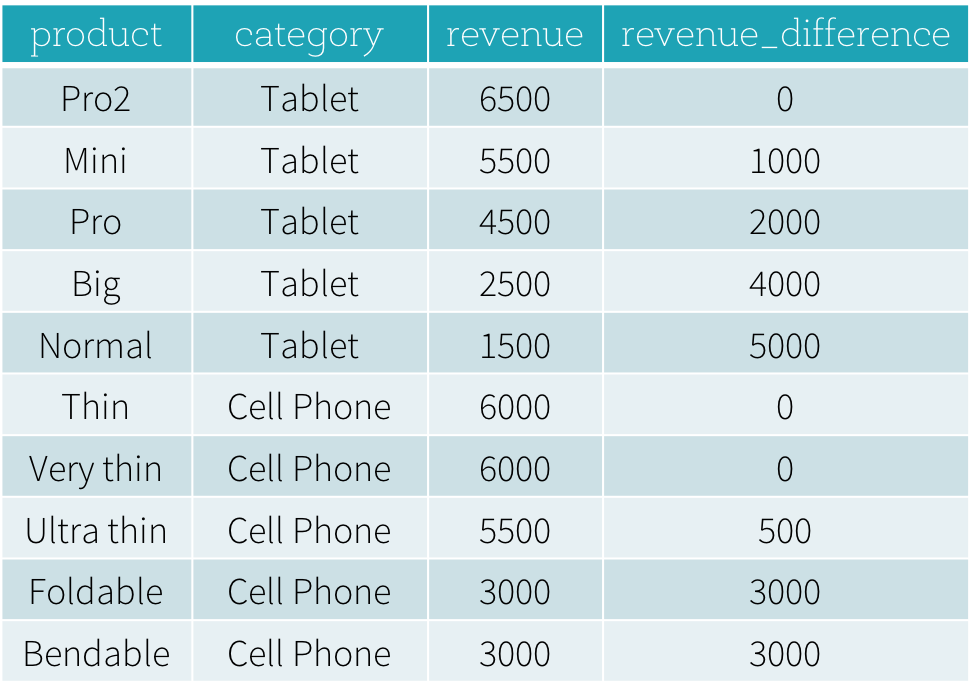
Um die erste Frage „Was sind die meistverkauften und die zweitmeistverkauften Produkte in jeder Kategorie?“ zu beantworten, müssen wir die Produkte einer Kategorie basierend auf ihrem Umsatz einstufen und die meistverkauften und zweitmeistverkauften Produkte basierend auf der Rangfolge auswählen. Unten sehen Sie die SQL-Abfrage, mit der diese Frage mithilfe der Fensterfunktion dense_rank beantwortet wird (wir werden die Syntax der Verwendung von Fensterfunktionen im nächsten Abschnitt erläutern).
Das Ergebnis dieses Programms ist unten zu sehen. Ohne die Verwendung von Fensterfunktionen müssen Benutzer alle höchsten Umsätze aller Kategorien ermitteln und dann diesen abgeleiteten Datensatz mit der ursprünglichen productRevenue-Tabelle verknüpfen, um die Umsatzdifferenzen zu berechnen.
Verwendung von Fensterfunktionen
Spark SQL unterstützt drei Arten von Fensterfunktionen: Ranking-Funktionen, analytische Funktionen und Aggregatfunktionen. Die verfügbaren Ranking- und analytischen Funktionen sind in der folgenden Tabelle zusammengefasst. Für Aggregatfunktionen können Benutzer jede vorhandene Aggregatfunktion als Fensterfunktion verwenden.
| SQL | DataFrame API | |
| Ranking-Funktionen | rank | rank |
| dense_rank | denseRank | |
| percent_rank | percentRank | |
| ntile | ntile | |
| row_number | rowNumber | |
| Analytische Funktionen | cume_dist | cumeDist |
| first_value | firstValue | |
| last_value | lastValue | |
| lag | lag | |
| lead | lead |
Um Fensterfunktionen zu verwenden, müssen Benutzer markieren, dass eine Funktion als Fensterfunktion verwendet wird, indem sie entweder
- Eine OVER-Klausel nach einer unterstützten Funktion in SQL hinzufügen, z. B.
avg(revenue) OVER (...); oder - Die over-Methode für eine unterstützte Funktion in der DataFrame-API aufrufen, z. B.
rank().over(...).
Sobald eine Funktion als Fensterfunktion markiert ist, besteht der nächste wichtige Schritt darin, die Window Specification zu definieren, die dieser Funktion zugeordnet ist. Eine Window Specification definiert, welche Zeilen in dem Frame enthalten sind, der einer bestimmten Eingabezeile zugeordnet ist. Eine Window Specification besteht aus drei Teilen:
- Partitionierungsspezifikation: Steuert, welche Zeilen sich in derselben Partition wie die gegebene Zeile befinden. Der Benutzer möchte möglicherweise auch sicherstellen, dass alle Zeilen mit demselben Wert für die Spalte category vor der Sortierung und Berechnung des Frames auf derselben Maschine gesammelt werden. Wenn keine Partitionierungsspezifikation angegeben ist, müssen alle Daten auf eine einzige Maschine gesammelt werden.
- Sortierungsspezifikation: Steuert die Art und Weise, wie Zeilen in einer Partition sortiert werden, und bestimmt die Position der gegebenen Zeile in ihrer Partition.
- Framespezifikation: Gibt an, welche Zeilen basierend auf ihrer relativen Position zur aktuellen Zeile in den Frame für die aktuelle Eingabezeile aufgenommen werden. Zum Beispiel beschreibt „die drei Zeilen vor der aktuellen Zeile bis zur aktuellen Zeile“ einen Frame, der die aktuelle Eingabezeile und drei davor liegende Zeilen enthält.
In SQL werden die Schlüsselwörter PARTITION BY und ORDER BY verwendet, um Partitionierungsausdrücke für die Partitionierungsspezifikation bzw. Sortierungsausdrücke für die Sortierungsspezifikation anzugeben. Die SQL-Syntax ist unten dargestellt.
OVER (PARTITION BY ... ORDER BY ...)
In der DataFrame-API bieten wir Hilfsfunktionen zur Definition einer Window Specification. Am Beispiel von Python können Benutzer Partitionierungs- und Sortierungsausdrücke wie folgt angeben.
Zusätzlich zur Sortierung und Partitionierung müssen Benutzer die Startgrenze des Frames, die Endgrenze des Frames und die Art des Frames definieren, die drei Komponenten einer Framespezifikation sind.
Es gibt fünf Arten von Grenzen: UNBOUNDED PRECEDING, UNBOUNDED FOLLOWING, CURRENT ROW, UNBOUNDED PRECEDING und UNBOUNDED FOLLOWING repräsentieren die erste bzw. letzte Zeile der Partition. Für die anderen drei Arten von Grenzen geben sie den Offset von der Position der aktuellen Eingabezeile an, und ihre spezifischen Bedeutungen werden basierend auf der Art des Frames definiert. Es gibt zwei Arten von Frames: ROW-Frame und RANGE-Frame.
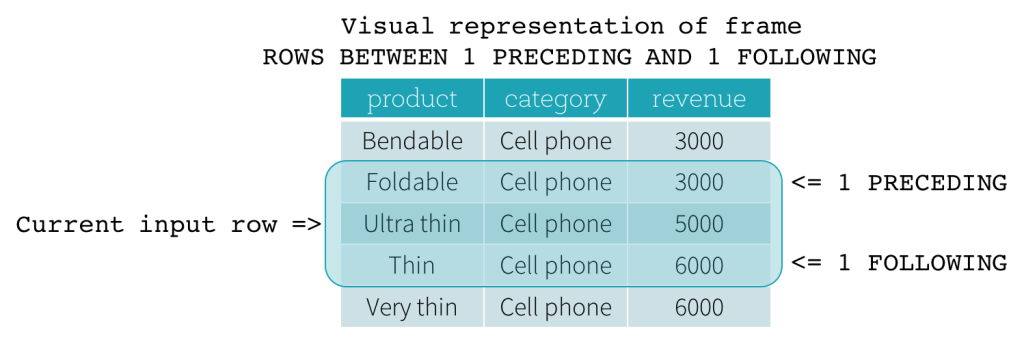
ROW-Frame
ROW-Frames basieren auf physischen Offsets von der Position der aktuellen Eingabezeile, was bedeutet, dass CURRENT ROW, CURRENT ROW als Grenze verwendet wird, repräsentiert es die aktuelle Eingabezeile. 1 PRECEDING als Startgrenze und 1 FOLLOWING als Endgrenze (ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING in der SQL-Syntax).
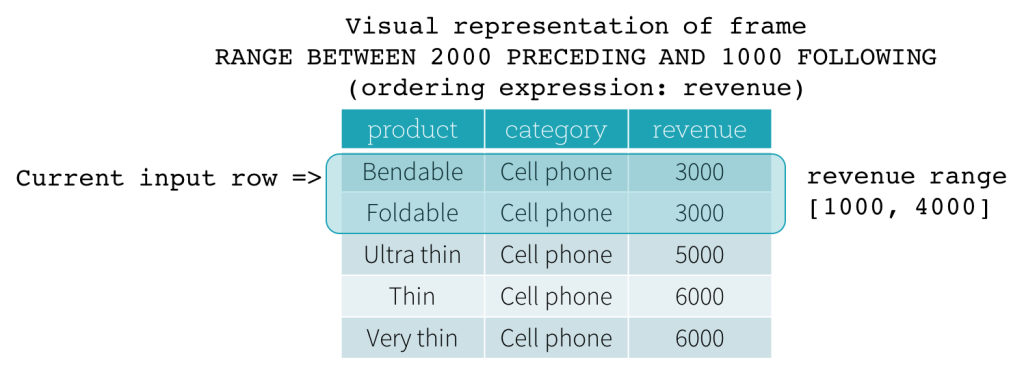
RANGE-Frame
RANGE-Frames basieren auf logischen Offsets von der Position der aktuellen Eingabezeile und haben eine ähnliche Syntax wie der ROW-Frame. Ein logischer Offset ist die Differenz zwischen dem Wert des Ordnungsdrucks der aktuellen Eingabezeile und dem Wert desselben Ausdrucks der Grenzzeile des Frames. Aufgrund dieser Definition ist bei Verwendung eines RANGE-Frames nur ein einziger Ordnungsdruck zulässig. Außerdem werden bei einem RANGE-Frame alle Zeilen mit demselben Wert des Ordnungsdrucks wie die aktuelle Eingabezeile als dieselbe Zeile betrachtet, was die Grenzberechnung betrifft.
Betrachten wir nun ein Beispiel. In diesem Beispiel ist der Ordnungsdruck revenue; die Startgrenze ist 2000 PRECEDING und die Endgrenze ist 1000 FOLLOWING (dieser Frame ist in der SQL-Syntax als RANGE BETWEEN 2000 PRECEDING AND 1000 FOLLOWING definiert). Die folgenden fünf Abbildungen veranschaulichen, wie der Frame mit der Aktualisierung der aktuellen Eingabezeile aktualisiert wird. Grundsätzlich berechnen wir für jede aktuelle Eingabezeile basierend auf dem Umsatzwert den Umsatzbereich [aktueller Umsatzwert - 2000, aktueller Umsatzwert + 1000]. Alle Zeilen, deren Umsatzwerte in diesen Bereich fallen, befinden sich im Frame der aktuellen Eingabezeile.
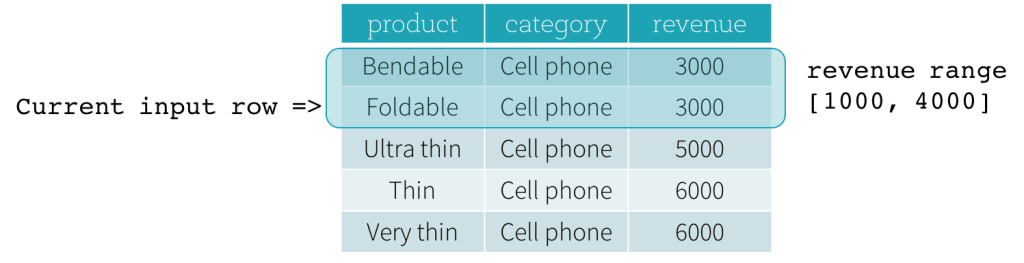
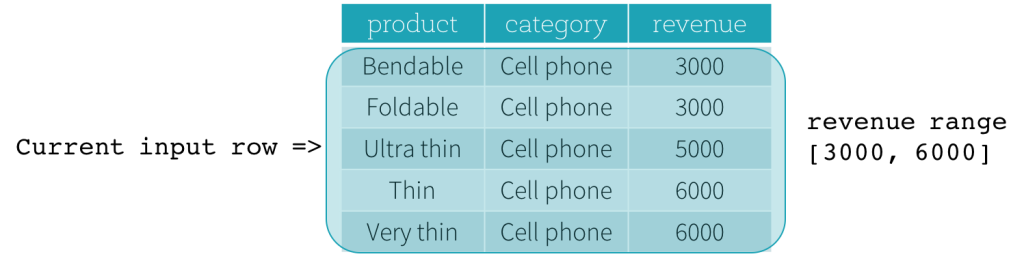
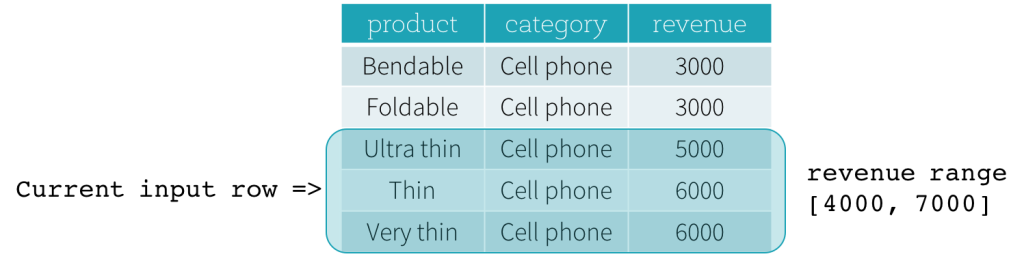
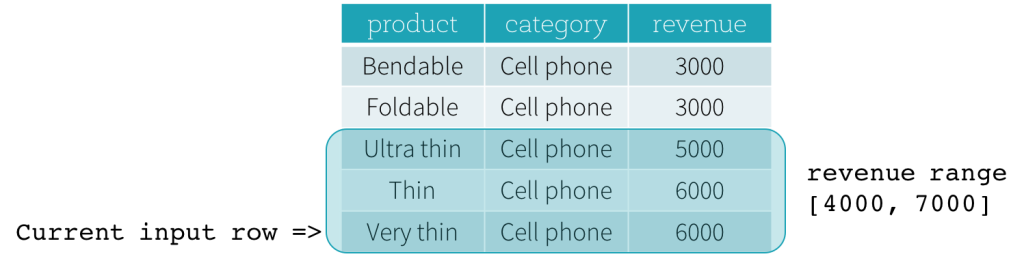
Zusammenfassend lässt sich sagen, dass Benutzer zur Definition einer Fenster-Spezifikation die folgende Syntax in SQL verwenden können.
OVER (PARTITION BY ... ORDER BY ... frame_type BETWEEN start AND end)
Hier kann frame_type entweder ROWS (für ROW-Frame) oder RANGE (für RANGE-Frame) sein; start kann einer von UNBOUNDED PRECEDING, CURRENT ROW, end kann einer von UNBOUNDED FOLLOWING, CURRENT ROW,
In der Python DataFrame API können Benutzer eine Fenster-Spezifikation wie folgt definieren.
Was kommt als Nächstes?
Seit der Veröffentlichung von Spark 1.4 arbeiten wir aktiv mit Community-Mitgliedern an Optimierungen, die die Leistung verbessern und den Speicherverbrauch des Operators zur Auswertung von Fensterfunktionen reduzieren. Einige davon werden in Spark 1.5 hinzugefügt, andere in zukünftigen Versionen. Neben der Leistungsverbesserung werden wir in naher Zukunft zwei Funktionen hinzufügen, um die Unterstützung von Fensterfunktionen in Spark SQL noch leistungsfähiger zu machen. Erstens arbeiten wir an der Unterstützung des Interval-Datentyps für Datums- und Zeitstempel-Datentypen (SPARK-8943). Mit dem Interval-Datentyp können Benutzer Intervalle als Werte für
Um diese Spark-Funktionen auszuprobieren, erhalten Sie eine kostenlose Testversion von Databricks oder nutzen Sie die Community Edition.
Danksagungen
Die Entwicklung der Unterstützung für Fensterfunktionen in Spark 1.4 ist eine Gemeinschaftsarbeit vieler Mitglieder der Spark-Community. Insbesondere möchten wir Wei Guo für die Bereitstellung des ursprünglichen Patches danken.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.