Eine Geschichte von drei Apache Spark APIs: RDDs im Vergleich zu DataFrames und Datasets
Wann man sie einsetzt und warum
von Jules Damji
Von allen Entwickler-Freuden ist keine attraktiver als eine Reihe von APIs, die Entwickler produktiv machen, einfach zu bedienen, intuitiv und ausdrucksstark sind. Einer der Reize von Apache Spark für Entwickler waren seine einfach zu bedienenden APIs für die Arbeit mit großen Datensätzen in verschiedenen Sprachen: Scala, Java, Python und R.
In diesem Blogbeitrag untersuche ich drei API-Sets – RDDs, DataFrames und Datasets –, die in Apache Spark 2.2 und neuer verfügbar sind; warum und wann Sie jedes Set verwenden sollten; skizziere ihre Leistungs- und Optimierungsvorteile; und zähle Szenarien auf, in denen DataFrames und Datasets anstelle von RDDs verwendet werden sollten. Hauptsächlich werde ich mich auf DataFrames und Datasets konzentrieren, da diese beiden APIs in Apache Spark 2.0 vereinheitlicht wurden.
Unsere Hauptmotivation hinter dieser Vereinheitlichung ist unser Bestreben, Spark zu vereinfachen, indem wir die Anzahl der zu lernenden Konzepte begrenzen und Möglichkeiten zur Verarbeitung strukturierter Daten bieten. Und durch Struktur kann Spark höherwertige Abstraktionen und APIs als domänenspezifische Sprachkonstrukte anbieten.
Resilient Distributed Dataset (RDD)
RDD war seit seiner Einführung die primäre benutzerorientierte API in Spark. Im Kern ist ein RDD eine unveränderliche verteilte Sammlung von Elementen Ihrer Daten, die über Knoten in Ihrem Cluster partitioniert sind und parallel mit einer Low-Level-API, die Transformationen und Aktionen bietet, bearbeitet werden können.
Wann sollten RDDs verwendet werden?
Betrachten Sie die folgenden Szenarien oder gängigen Anwendungsfälle für die Verwendung von RDDs:
- Wenn Sie Low-Level-Transformationen und -Aktionen sowie Kontrolle über Ihren Datensatz wünschen;
- Wenn Ihre Daten unstrukturiert sind, wie z. B. Medien-Streams oder Text-Streams;
- Wenn Sie Ihre Daten mit funktionalen Programmierkonstrukten anstelle von domänenspezifischen Ausdrücken manipulieren möchten;
- Wenn Sie sich nicht darum kümmern, ein Schema aufzuerlegen, wie z. B. ein spaltenbasiertes Format, während Sie Datenattribute nach Namen oder Spalten verarbeiten oder darauf zugreifen; und
- Wenn Sie auf einige Optimierungs- und Leistungsvorteile verzichten können, die mit DataFrames und Datasets für strukturierte und semi-strukturierte Daten verfügbar sind.
Was passiert mit RDDs in Apache Spark 2.0?
Sie fragen sich vielleicht: Werden RDDs zu Bürgern zweiter Klasse degradiert? Werden sie veraltet sein?
Die Antwort ist ein klares NEIN!
Darüber hinaus können Sie, wie unten gezeigt, nahtlos zwischen DataFrame oder Dataset und RDDs wechseln – durch einfache API-Methodenaufrufe –, und DataFrames und Datasets basieren auf RDDs.
DataFrames
Wie ein RDD ist ein DataFrame eine unveränderliche verteilte Datensammlung. Im Gegensatz zu einem RDD sind die Daten in benannten Spalten organisiert, ähnlich einer Tabelle in einer relationalen Datenbank. DataFrame wurde entwickelt, um die Verarbeitung großer Datensätze noch einfacher zu machen. Es ermöglicht Entwicklern, eine Struktur auf eine verteilte Datensammlung anzuwenden, was eine höherwertige Abstraktion ermöglicht; es bietet eine domänenspezifische Sprach-API zur Manipulation Ihrer verteilten Daten; und macht Spark einem breiteren Publikum zugänglich, über spezialisierte Dateningenieure hinaus.
In unserer Vorschau auf das Apache Spark 2.0 Webinar und dem nachfolgenden Blogbeitrag erwähnten wir, dass in Spark 2.0 die DataFrame-APIs mit den Dataset-APIs zusammengeführt werden, wodurch die Datenverarbeitungsfähigkeiten über Bibliotheken hinweg vereinheitlicht werden. Aufgrund dieser Vereinheitlichung müssen Entwickler nun weniger Konzepte lernen oder sich daran erinnern und arbeiten mit einer einzigen, hochwertigen und typsicheren API namens Dataset.
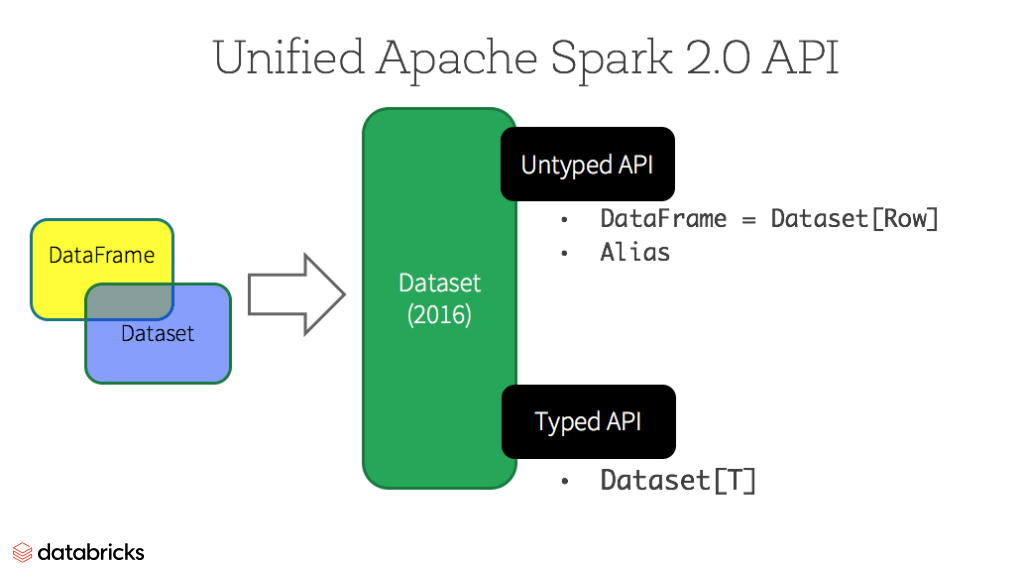
Datasets
Ab Spark 2.0 weist Dataset zwei unterschiedliche API-Charakteristika auf: eine stark typisierte API und eine nicht typisierte API, wie in der folgenden Tabelle gezeigt. Konzeptionell kann DataFrame als Alias für eine Sammlung generischer Objekte Dataset[Row] betrachtet werden, wobei ein Row ein generisches nicht typisiertes JVM-Objekt ist. Dataset hingegen ist eine Sammlung von stark typisierten JVM-Objekten, die durch eine von Ihnen in Scala definierte Klasse oder eine Klasse in Java bestimmt werden.
Typisierte und nicht typisierte APIs
| Sprache | Hauptabstraktion |
|---|---|
| Scala | Dataset[T] & DataFrame (Alias für Dataset[Row]) |
| Java | Dataset[T] |
| Python* | DataFrame |
| R* | DataFrame |
Hinweis: Da Python und R keine Laufzeitsicherheit für Typen haben, verfügen wir nur über nicht typisierte APIs, nämlich DataFrames.
Vorteile von Dataset-APIs
Als Spark-Entwickler profitieren Sie in Spark 2.0 auf verschiedene Weise von den vereinheitlichten DataFrame- und Dataset-APIs.
1. Statische Typisierung und Laufzeit-Typsicherheit
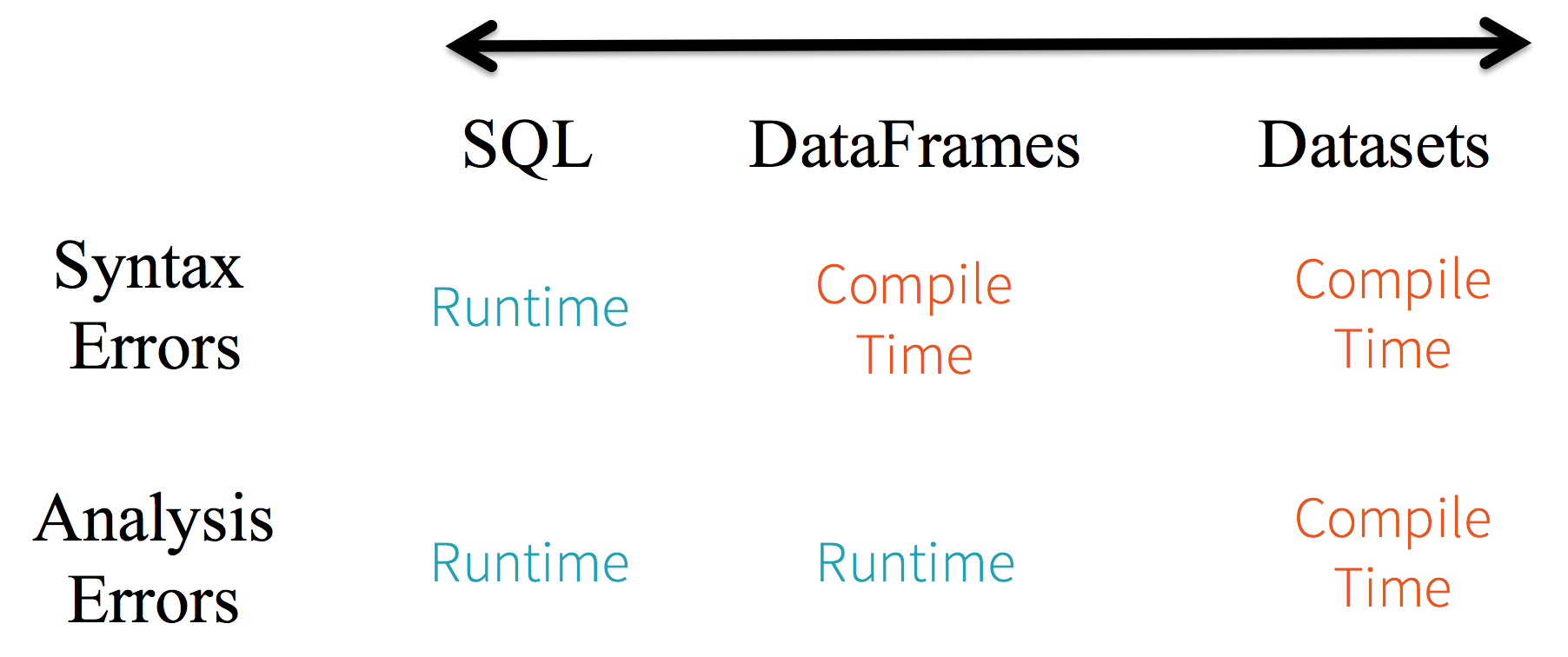
Betrachten Sie statische Typisierung und Laufzeitsicherheit als Spektrum, wobei SQL am wenigsten restriktiv und Dataset am restriktivsten ist. In Ihren Spark SQL-Stringabfragen erfahren Sie beispielsweise erst zur Laufzeit von einem Syntaxfehler (was kostspielig sein kann), während Sie bei DataFrames und Datasets Fehler zur Kompilierzeit erkennen können (was Entwicklerzeit und Kosten spart). Das heißt, wenn Sie eine Funktion in DataFrame aufrufen, die nicht Teil der API ist, wird der Compiler dies erkennen. Ein nicht vorhandener Spaltenname wird jedoch erst zur Laufzeit erkannt.
Am anderen Ende des Spektrums befindet sich Dataset, das am restriktivsten ist. Da Dataset-APIs alle als Lambda-Funktionen und JVM-typisierte Objekte ausgedrückt werden, werden alle Abweichungen bei typisierten Parametern zur Kompilierzeit erkannt. Auch Ihr Analysefehler kann bei Verwendung von Datasets zur Kompilierzeit erkannt werden, was Entwicklerzeit und Kosten spart.
All dies bedeutet ein Spektrum an Typsicherheit für Syntax- und Analysefehler in Ihrem Spark-Code, wobei Datasets am restriktivsten, aber für einen Entwickler am produktivsten sind.
2. Hochwertige Abstraktion und benutzerdefinierte Ansicht für strukturierte und semi-strukturierte Daten
DataFrames als Sammlung von Datasets[Row] bieten eine strukturierte benutzerdefinierte Ansicht Ihrer semi-strukturierten Daten. Wenn Sie beispielsweise einen riesigen Datensatz von IoT-Geräteereignissen haben, der als JSON ausgedrückt wird. Da JSON ein semi-strukturiertes Format ist, eignet es sich gut für die Verwendung von Dataset als Sammlung von stark typisierten, spezifischen Dataset[DeviceIoTData].
Sie könnten jeden JSON-Eintrag als DeviceIoTData, ein benutzerdefiniertes Objekt, mit einer Scala-Case-Klasse ausdrücken.
Als Nächstes können wir die Daten aus einer JSON-Datei lesen.
Drei Dinge passieren hier im Hintergrund des obigen Codes:
- Spark liest das JSON, leitet das Schema ab und erstellt eine Sammlung von DataFrames.
- Zu diesem Zeitpunkt konvertiert Spark Ihre Daten in DataFrame = Dataset[Row], eine Sammlung generischer Row-Objekte, da der genaue Typ nicht bekannt ist.
- Nun konvertiert Spark Dataset[Row] -> Dataset[DeviceIoTData], ein typspezifisches Scala-JVM-Objekt, wie durch die Klasse DeviceIoTData vorgegeben.
Die meisten von uns, die mit strukturierten Daten arbeiten, sind es gewohnt, Daten entweder spaltenweise zu betrachten und zu verarbeiten oder auf bestimmte Attribute innerhalb eines Objekts zuzugreifen. Mit Dataset als Sammlung von Dataset[ElementType] typisierten Objekten erhalten Sie nahtlos sowohl Kompilierzeit-Sicherheit als auch eine benutzerdefinierte Ansicht für stark typisierte JVM-Objekte. Und Ihr resultierendes stark typisiertes Dataset[T] aus dem obigen Code kann einfach mit High-Level-Methoden angezeigt oder verarbeitet werden.
3. Einfache API-Nutzung mit Struktur
Obwohl Struktur die Kontrolle darüber einschränken kann, was Ihr Spark-Programm mit Daten tun kann, führt sie reichhaltige Semantik und eine einfache Menge domänenspezifischer Operationen ein, die als High-Level-Konstrukte ausgedrückt werden können. Die meisten Berechnungen können jedoch mit den High-Level-APIs von Dataset durchgeführt werden. Zum Beispiel ist es viel einfacher, agg, select, sum, avg, map, filter oder groupBy Operationen durchzuführen, indem man auf das DeviceIoTData eines typisierten Dataset-Objekts zugreift, als die Datenfelder von RDD-Zeilen zu verwenden.
Die Berechnung in einer domänenspezifischen API auszudrücken ist weitaus einfacher und unkomplizierter als mit relationale algebra-ähnlichen Ausdrücken (in RDDs). Zum Beispiel wird der folgende Code verwendet, um ein weiteres unveränderliches Dataset zu erstellen, indem filter() und map() verwendet werden.
4. Leistung und Optimierung
Neben all den oben genannten Vorteilen dürfen Sie die Effizienz bei der Speichernutzung und die Leistungssteigerungen bei der Verwendung von DataFrames und Dataset-APIs aus zwei Gründen nicht übersehen.
Erstens, da DataFrame- und Dataset-APIs auf der Spark SQL-Engine aufbauen, verwenden sie Catalyst, um einen optimierten logischen und physischen Abfrageplan zu generieren. Über R-, Java-, Scala- oder Python-DataFrame/Dataset-APIs hinweg durchlaufen alle relationale Abfragen denselben Code-Optimierer, was für Platz- und Geschwindigkeitsersparnis sorgt. Während die typisierte Dataset[T] API für Data-Engineering-Aufgaben optimiert ist, ist die untypisierte Dataset[Row] (ein Alias von DataFrame) noch schneller und für die interaktive Analyse geeignet.

Zweitens, da Spark als Compiler Ihr typisiertes JVM-Objekt von Dataset versteht, ordnet es Ihr typspezifisches JVM-Objekt der internen Speicherrepräsentation von Tungsten mithilfe von Encoders zu. Infolgedessen können Tungsten Encoders JVM-Objekte effizient serialisieren/deserialisieren und kompakten Bytecode generieren, der mit überlegener Geschwindigkeit ausgeführt werden kann.
Wann sollte ich DataFrames oder Datasets verwenden?
- Wenn Sie reichhaltige Semantik, High-Level-Abstraktionen und domänenspezifische APIs wünschen, verwenden Sie DataFrame oder Dataset.
- Wenn Ihre Verarbeitung High-Level-Ausdrücke, Filter, Maps, Aggregationen, Durchschnittswerte, Summen, SQL-Abfragen, spaltenweisen Zugriff und die Verwendung von Lambda-Funktionen auf semistrukturierten Daten erfordert, verwenden Sie DataFrame oder Dataset.
- Wenn Sie zur Kompilierzeit ein höheres Maß an Typsicherheit wünschen, typisierte JVM-Objekte nutzen, von der Catalyst-Optimierung profitieren und von Tungstens effizienter Codegenerierung profitieren möchten, verwenden Sie Dataset.
- Wenn Sie eine Vereinheitlichung und Vereinfachung von APIs über Spark-Bibliotheken hinweg wünschen, verwenden Sie DataFrame oder Dataset.
- Wenn Sie ein R-Benutzer sind, verwenden Sie DataFrames.
- Wenn Sie ein Python-Benutzer sind, verwenden Sie DataFrames und greifen Sie auf RDDs zurück, wenn Sie mehr Kontrolle benötigen.
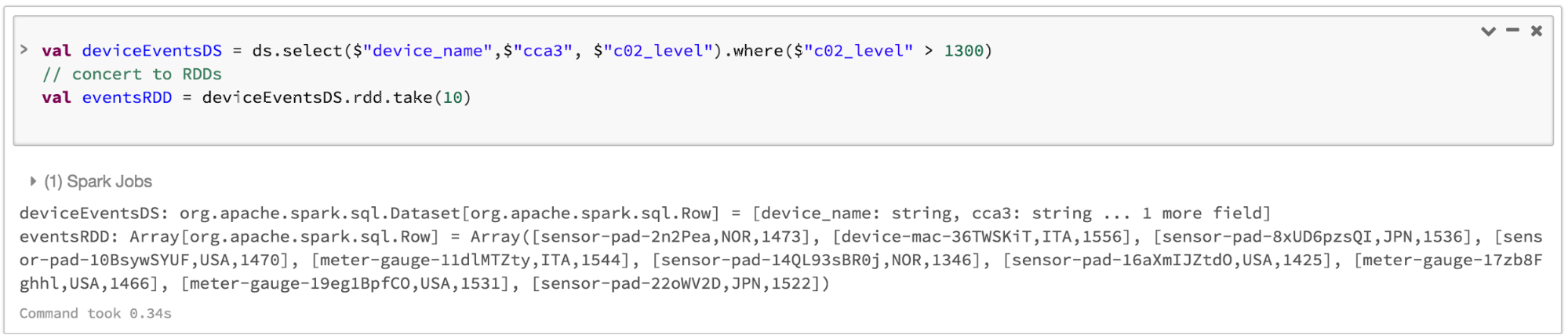
Beachten Sie, dass Sie jederzeit nahtlos mit RDDs interagieren oder von DataFrame und/oder Dataset zu einem RDD konvertieren können, indem Sie einfach die Methode .rdd aufrufen. Zum Beispiel:
Alles zusammenbringen
Zusammenfassend lässt sich sagen, dass die Wahl, wann RDD oder DataFrame und/oder Dataset verwendet werden soll, offensichtlich erscheint. Während ersteres Ihnen Low-Level-Funktionalität und Kontrolle bietet, ermöglicht letzteres eine benutzerdefinierte Ansicht und Struktur, bietet High-Level- und domänenspezifische Operationen, spart Speicherplatz und wird mit überlegener Geschwindigkeit ausgeführt.
Als wir die Lektionen aus frühen Spark-Versionen untersuchten – wie Spark für Entwickler vereinfacht, wie es optimiert und performant gemacht wird –, entschieden wir uns, die Low-Level-RDD-APIs zu einer High-Level-Abstraktion wie DataFrame und Dataset zu erweitern und diese einheitliche Datenabstraktion über Bibliotheken hinweg auf Basis des Catalyst-Optimierers und Tungsten aufzubauen.
Wählen Sie eine – DataFrames und/oder Dataset oder RDD-APIs –, die Ihren Bedürfnissen und Anwendungsfällen entspricht, aber ich wäre nicht überrascht, wenn Sie zu den meisten Entwicklern gehören, die mit strukturierten und semistrukturierten Daten arbeiten.
Was kommt als Nächstes?
Probieren Sie Apache Spark 2.2 auf Databricks aus.
Sie können sich auch die Spark Summit-Präsentation ansehen: A Tale of Three Apache Spark APIs: RDDs vs DataFrames and Datasets
Testen Sie Databricks jetzt, falls Sie sich noch nicht angemeldet haben.
In den kommenden Wochen werden wir eine Reihe von Blogs über Structured Streaming veröffentlichen. Bleiben Sie dran.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.