Verarbeitung von Geodaten im großen Maßstab mit Databricks
von Nima Razavi und Michael Johns
Dieser Blogbeitrag ist veraltet. Bitte beachten Sie diesen Spatial SQL Blogbeitrag für aktuelle Ansätze zur Speicherung und Verarbeitung von Geodaten in Ihrem Databricks Lakehouse.
Die Entwicklung und Konvergenz von Technologie hat einen lebendigen Markt für zeitnahe und genaue Geodaten angeheizt. Jeden Tag generieren Milliarden von Handheld- und IoT-Geräten sowie Tausende von luftgestützten und satellitengestützten Fernerkundungsplattformen Hunderte von Exabytes an standortbezogenen Daten. Dieser Boom von Geodaten-Big-Data, kombiniert mit Fortschritten im maschinellen Lernen, ermöglicht es Organisationen branchenübergreifend, neue Produkte und Fähigkeiten zu entwickeln.
Zum Beispiel bieten zahlreiche Unternehmen lokalisierte Drohnen-basierte Dienste wie Kartierung und Inspektion von Standorten an (siehe Entwicklung für die intelligente Cloud und die intelligente Edge). Eine weitere schnell wachsende Branche für Geodaten sind autonome Fahrzeuge. Start-ups und etablierte Unternehmen sammeln gleichermaßen große Korpora hochgradig kontextualisierter Geodaten von Fahrzeugsensoren, um die nächste Innovation bei selbstfahrenden Autos zu liefern (siehe Databricks treibt Wejos' Ehrgeiz voran, ein Mobilitätsdaten-Ökosystem zu schaffen). Einzelhändler und Regierungsbehörden suchen ebenfalls nach Möglichkeiten, ihre Geodaten zu nutzen. Beispielsweise kann die Analyse von Fußgängerverkehr (siehe Erstellung eines Datensatzes für Fußgängerverkehr-Einblicke) helfen, den besten Standort für die Eröffnung eines neuen Geschäfts zu bestimmen oder im öffentlichen Sektor die Stadtplanung zu verbessern. Trotz all dieser Investitionen in Geodaten gibt es eine Reihe von Herausforderungen.
Herausforderungen bei der Analyse von Geodaten im großen Maßstab
Die erste Herausforderung besteht darin, mit der Skalierung in Streaming- und Batch-Anwendungen umzugehen. Die schiere Verbreitung von Geodaten und die von Anwendungen geforderten SLAs überfordern traditionelle Speicher- und Verarbeitungssysteme. Kundendaten fließen seit vielen Jahren aus bestehenden, vertikal skalierten Geo-Datenbanken in Data Lakes, bedingt durch Faktoren wie Datenvolumen, Geschwindigkeit, Speicherkosten und die strikte Erzwingung von Schema-on-Write. Obwohl Unternehmen in Geodaten investiert haben, verfügen nur wenige über die richtige Technologiearchitektur, um diese großen, komplexen Datensätze für nachgelagerte Analysen vorzubereiten. Darüber hinaus scheitern die meisten KI-gesteuerten Initiativen daran, von der Pilotphase zur Produktion überzugehen, da skalierte Daten oft für fortgeschrittene Anwendungsfälle benötigt werden.
Die Kompatibilität mit verschiedenen räumlichen Formaten stellt die zweite Herausforderung dar. Es gibt viele verschiedene spezialisierte Geodatenformate, die über viele Jahrzehnte entwickelt wurden, sowie zufällige Datenquellen, aus denen Standortinformationen gewonnen werden können:
- Vektorformate wie GeoJSON, KML, Shapefile und WKT
- Rasterformate wie ESRI Grid, GeoTIFF, JPEG 2000 und NITF
- Navigationsstandards, wie sie von AIS- und GPS-Geräten verwendet werden
- Geodatenbanken, zugänglich über JDBC/ODBC-Verbindungen wie PostgreSQL/PostGIS
- Fernerkundungsformate von Hyperspectral-, Multispectral-, Lidar- und Radarplattformen
- OGC-Webstandards wie WCS, WFS, WMS und WMTS
- Geotaggte Protokolle, Bilder, Videos und soziale Medien
- Unstrukturierte Daten mit Ortsangaben
In diesem Blogbeitrag geben wir einen Überblick über allgemeine Ansätze zur Bewältigung der beiden oben genannten Hauptprobleme mithilfe der Databricks Unified Data Analytics Platform. Dies ist der erste Teil einer Reihe von Blogbeiträgen zur Verarbeitung großer Mengen von Geodaten.
Skalierung von Geodaten-Workloads mit Databricks
Databricks bietet eine einheitliche Datenanalyseplattform für Big-Data-Analysen und maschinelles Lernen, die von Tausenden von Kunden weltweit genutzt wird. Sie wird von Apache Spark™, Delta Lake und MLflow mit einem breiten Ökosystem von Drittanbieter- und verfügbaren Bibliotheksintegrationen angetrieben. Databricks UDAP bietet unternehmensweite Sicherheit, Support, Zuverlässigkeit und Leistung im großen Maßstab für Produktions-Workloads. Geodaten-Workloads sind typischerweise komplex, und es gibt keine einzelne Bibliothek, die für alle Anwendungsfälle geeignet ist. Obwohl Apache Spark nativ keine räumlichen Datentypen bietet, haben die Open-Source-Community sowie Unternehmen erhebliche Anstrengungen unternommen, räumliche Bibliotheken zu entwickeln, was zu einer Fülle von Optionen führt, aus denen gewählt werden kann.
Es gibt im Allgemeinen drei Muster für die Skalierung von räumlichen Operationen wie räumliche Joins oder Nachbarschaftssuchen:
- Verwendung von spezialisierten Bibliotheken, die Apache Spark für räumliche Analysen erweitern. GeoSpark, GeoMesa, GeoTrellis und Rasterframes sind einige solcher Bibliotheken, die von unseren Kunden verwendet werden. Diese Frameworks bieten oft mehrere Sprachbindungen, haben eine deutlich bessere Skalierbarkeit und Leistung als nicht formalisierte Ansätze, können aber auch eine Lernkurve mit sich bringen.
- Einbettung von Single-Node-Bibliotheken wie GeoPandas, Geospatial Data Abstraction Library (GDAL) oder Java Topology Service (JTS) in Ad-hoc User Defined Functions (UDFs) zur verteilten Verarbeitung mit Spark DataFrames. Dies ist der einfachste Ansatz zur Skalierung bestehender Workloads ohne große Code-Änderungen; er kann jedoch zu Leistungseinbußen führen, da er eher einem Lift-and-Shift-Ansatz entspricht.
- Die Indizierung der Daten mit Gittersystemen und die Nutzung des generierten Index zur Durchführung räumlicher Operationen ist ein gängiger Ansatz für die Bewältigung sehr großer oder rechenbeschränkter Workloads. S2, GeoHex und Uber's H3 sind Beispiele für solche Gittersysteme. Gitter approximieren Geo-Features wie Polygone oder Punkte mit einer festen Menge identifizierbarer Zellen, wodurch teure räumliche Operationen vermieden werden und somit ein deutlich besseres Skalierungsverhalten erzielt wird. Implementierer können zwischen Gittern wählen, die auf eine einzige Genauigkeit festgelegt sind und etwas verlustbehaftet, aber leistungsfähiger sein können, oder Gittern mit mehreren Genauigkeiten, die weniger leistungsfähig sein können, aber Verluste vermeiden.
Die folgenden Beispiele orientieren sich im Allgemeinen an einem Datensatz von Taxiabholungen/-abgaben in New York City, der hier zu finden ist. NYC Taxi Zone-Daten mit Geometrien werden ebenfalls als Polygonmenge verwendet. Diese Daten enthalten Polygone für die fünf Stadtteile von NYC sowie die Stadtviertel. Dieses Notebook führt Sie durch die Vorbereitungs- und Bereinigungsarbeiten, die erforderlich sind, um die ursprünglichen CSV-Dateien in Delta Lake Tabellen als zuverlässige und performante Datenquelle umzuwandeln.
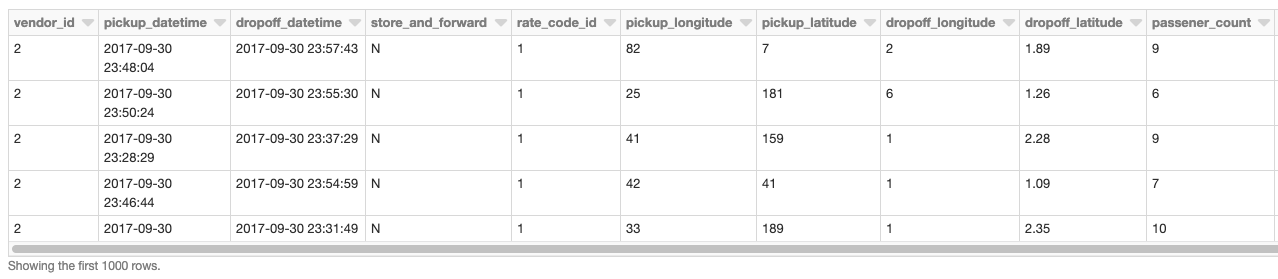
Unser Basis-DataFrame sind die Taxi-Abholungs-/Abgabe-Daten, die aus einer Delta Lake Tabelle mit Databricks gelesen werden.
Geospatiale Operationen mit GeoSpatial Libraries für Apache Spark
In den letzten Jahren wurden mehrere Bibliotheken entwickelt, um die Fähigkeiten von Apache Spark für die georäumliche Analyse zu erweitern. Diese Frameworks übernehmen die Registrierung von häufig verwendeten benutzerdefinierten Typen (UDTs) und Funktionen (UDFs) auf konsistente Weise und nehmen den Benutzern und Teams die Last ab, ad-hoc räumliche Logik zu schreiben. Bitte beachten Sie, dass wir in diesem Blogbeitrag verschiedene räumliche Frameworks verwenden, die ausgewählt wurden, um verschiedene Fähigkeiten hervorzuheben. Wir wissen, dass es neben den hervorgehobenen Frameworks auch andere gibt, die Sie möglicherweise auch mit Databricks verwenden möchten, um Ihre räumlichen Workloads zu verarbeiten.
Zuvor haben wir unsere Basisdaten in einen DataFrame geladen. Jetzt müssen wir die Breiten-/Längenattribute in Punktgeometrien umwandeln. Um dies zu erreichen, werden wir UDFs verwenden, um Operationen auf DataFrames auf verteilte Weise durchzuführen. Bitte beachten Sie die bereitgestellten Notebooks am Ende des Blogs für Details zur Hinzufügung dieser Frameworks zu einem Cluster und die Initialisierungsaufrufe zur Registrierung von UDFs und UDTs. Für den Anfang haben wir GeoMesa zu unserem Cluster hinzugefügt, ein Framework, das sich besonders gut für die Verarbeitung von Vektordaten eignet. Für die Ingestion nutzen wir hauptsächlich die Integration von JTS mit Spark SQL, was es uns ermöglicht, registrierte JTS-Geometrieklassen einfach zu konvertieren und zu verwenden. Wir werden die Funktion st_makePoint verwenden, die aus Breiten- und Längengrad ein Punktgeometrieobjekt erstellt. Da die Funktion eine UDF ist, können wir sie direkt auf Spalten anwenden.
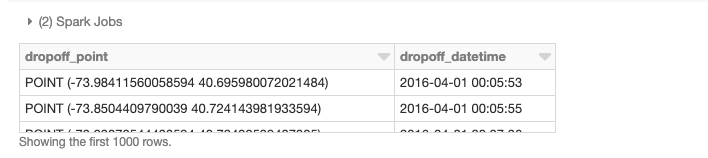
Wir können auch verteilte räumliche Joins durchführen, in diesem Fall unter Verwendung der von GeoMesa bereitgestellten st_contains UDF, um den resultierenden Join aller Polygone gegen Abholpunkte zu erzeugen.
Einbindung von Single-Node-Bibliotheken in UDFs
Zusätzlich zur Verwendung von speziell entwickelten verteilten räumlichen Frameworks können bestehende Single-Node-Bibliotheken auch in ad-hoc UDFs eingepackt werden, um georäumliche Operationen auf DataFrames in verteilter Weise durchzuführen. Dieses Muster ist für alle Spark-Sprachbindungen verfügbar – Scala, Java, Python, R und SQL – und ist ein einfacher Ansatz, um bestehende Workloads mit minimalen Codeänderungen zu nutzen. Um ein Single-Node-Beispiel zu demonstrieren, laden wir NYC-Bezirkdaten und definieren die UDF find_borough(...) für die Point-in-Polygon-Operation, um jeden GPS-Standort einem Bezirk mithilfe von geopandas zuzuweisen. Dies hätte auch mit einer vektorisierten UDF für eine noch bessere Leistung erreicht werden können.
Nun können wir die UDF anwenden, um eine Spalte zu unserem Spark DataFrame hinzuzufügen, die jedem Abholpunkt einen Bezirksnamen zuweist.
Grid-Systeme für räumliche Indizierung
Georäumliche Operationen sind von Natur aus rechenintensiv. Point-in-Polygon, räumliche Joins, Nearest Neighbor oder Snapping zu Routen beinhalten alle komplexe Operationen. Durch die Indizierung mit Grid-Systemen ist das Ziel, georäumliche Operationen ganz zu vermeiden. Dieser Ansatz führt zu den skalierbarsten Implementierungen mit dem Vorbehalt approximativer Operationen. Hier ist ein kurzes Beispiel mit H3.
Die Skalierung räumlicher Operationen mit H3 ist im Wesentlichen ein zweistufiger Prozess. Der erste Schritt ist die Berechnung eines H3-Index für jedes Merkmal (Punkte, Polygone usw.), das als UDF geoToH3(...) definiert ist. Der zweite Schritt ist die Verwendung dieser Indizes für räumliche Operationen wie räumliche Joins (Punkt in Polygon, k-nächste Nachbarn usw.), die in diesem Fall als UDF multiPolygonToH3(...) definiert sind.
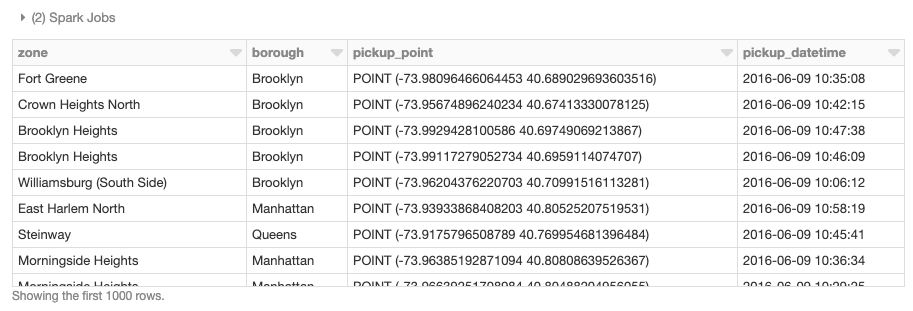
Wir können nun diese beiden UDFs auf die NYC-Taxidaten sowie auf den Satz von Bezirkspolygonen anwenden, um den H3-Index zu generieren.
Gegeben eine Menge von Längen-/Breitengradpunkten und eine Menge von Polygon-Geometrien ist es nun möglich, den räumlichen Join unter Verwendung des h3index-Feldes als Join-Bedingung durchzuführen. Diese Zuordnungen können beispielsweise verwendet werden, um die Anzahl der Punkte zu aggregieren, die in jedes Polygon fallen. Es gibt normalerweise Millionen oder Milliarden von Punkten, die mit Tausenden oder Millionen von Polygonen abgeglichen werden müssen, was einen skalierbaren Ansatz erfordert. Es gibt andere Techniken, die in diesem Blog nicht behandelt werden und die für die Indizierung zur Unterstützung räumlicher Operationen verwendet werden können, wenn eine Annäherung nicht ausreicht.

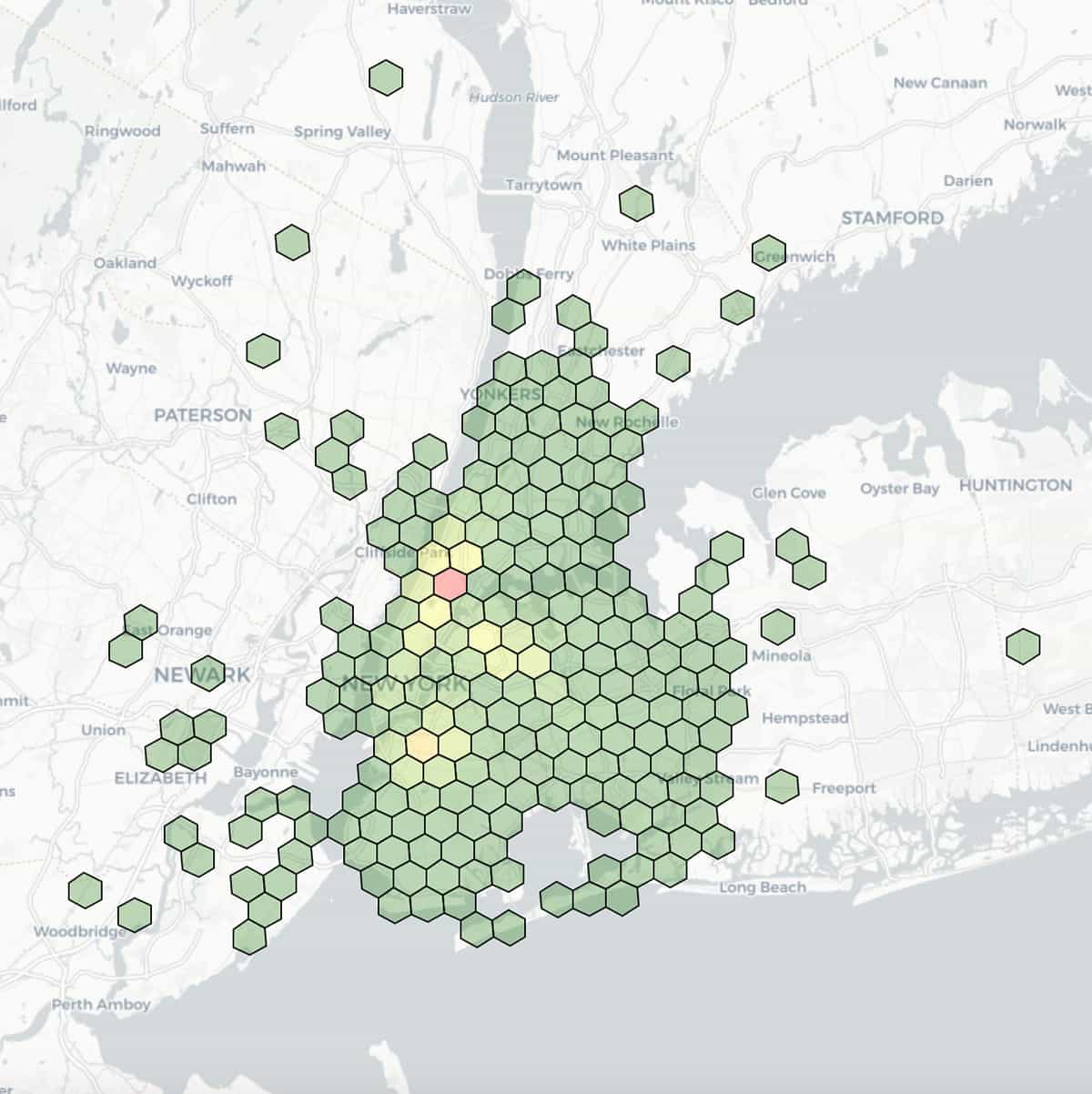
Hier ist eine Visualisierung von Taxi-Abgabestandorten, wobei Längen- und Breitengrade auf eine Auflösung von 7 (1,22 km Kantenlänge) abgerundet und nach aggregierten Zählungen innerhalb jedes Bins eingefärbt sind.
Umgang mit räumlichen Formaten mit Databricks
Georäumliche Daten umfassen Referenzpunkte wie Längen- und Breitengrade zu physischen Orten oder Ausdehnungen auf der Erde zusammen mit Attributen beschriebenen Merkmalen. Obwohl es viele Dateiformate zur Auswahl gibt, haben wir eine Handvoll repräsentativer Vektor- und Rasterformate ausgewählt, um das Lesen mit Databricks zu demonstrieren.
Vektordaten
Vektordaten sind eine Darstellung der Welt, die in x- (Längen-), y- (Breiten-) Koordinaten in Grad gespeichert ist, sowie z (Höhe in Metern), wenn die Höhe berücksichtigt wird. Die drei grundlegenden Symboltypen für Vektordaten sind Punkte, Linien und Polygone. Well-known-text (WKT), GeoJSON und Shapefile sind einige gängige Formate zum Speichern von Vektordaten, die wir unten hervorheben.
Lassen Sie uns NYC Taxi Zone-Daten lesen, wobei Geometrien als WKT gespeichert sind. Die Datenstruktur, die wir zurückerhalten möchten, ist ein DataFrame, der es uns ermöglicht, ihn mit anderen APIs und verfügbaren Datenquellen zu standardisieren, wie sie an anderer Stelle im Blog verwendet werden. Wir können den WKT-Textinhalt im Feld the_geom durch den UDF-Aufruf st_geomFromWKT(...) einfach in seine entsprechende JTS Geometry-Klasse konvertieren.
GeoJSON wird von vielen Open-Source-GIS-Paketen zum Kodieren einer Vielzahl von georäumlichen Datenstrukturen verwendet, einschließlich ihrer Merkmale, Eigenschaften und räumlichen Ausdehnungen. Für dieses Beispiel lesen wir NYC Borough Boundaries mit dem Ansatz, der vom Workflow abhängt. Da die Daten konformes JSON sind, könnten wir den integrierten JSON-Reader von Databricks mit .option("multiline","true") verwenden, um die Daten mit dem verschachtelten Schema zu laden.

Von dort aus könnten wir wählen, eines der Felder mit der integrierten Explode-Funktion von Spark in Spalten auf oberster Ebene zu verschieben. Wir könnten zum Beispiel Geometrie, Eigenschaften und Typ nach oben bringen und dann die Geometrie wie im WKT-Beispiel gezeigt in ihre entsprechende JTS-Klasse konvertieren.

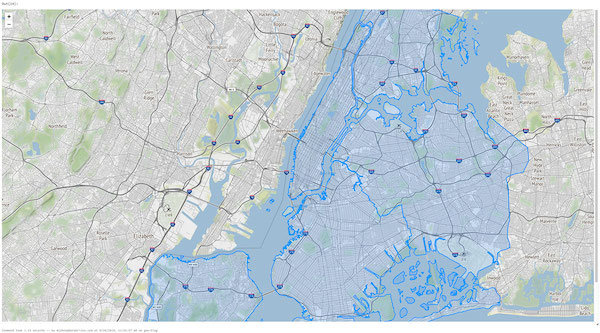
Wir können die NYC Taxi Zone-Daten auch innerhalb eines Notebooks mithilfe eines vorhandenen DataFrames visualisieren oder die Daten direkt mit einer Bibliothek wie Folium rendern, einer Python-Bibliothek zum Rendern von räumlichen Daten. Databricks File System (DBFS) läuft über einer verteilten Speicherschicht, die es dem Code ermöglicht, mit Datenformaten unter Verwendung vertrauter Dateisystemstandards zu arbeiten. DBFS verfügt über einen FUSE Mount, um lokale API-Aufrufe zu ermöglichen, die Datei-Lese- und Schreibvorgänge durchführen, was das Laden von Daten mit nicht verteilten APIs für interaktives Rendering sehr einfach macht. Im unten stehenden Python open(...) Befehl ermöglicht das Präfix "/dbfs/..." die Verwendung von FUSE Mount.
Shapefile ist ein beliebtes Vektorformat, das von ESRI entwickelt wurde und die geometrische Position und Attributinformationen von georäumlichen Merkmalen speichert. Das Format besteht aus einer Sammlung von Dateien mit einem gemeinsamen Präfix (*.shp, *.shx und *.dbf sind obligatorisch), die im selben Verzeichnis gespeichert sind. Eine Alternative zu Shapefile ist KML, das auch von unseren Kunden verwendet wird, aber aus Gründen der Kürze nicht gezeigt wird. Für dieses Beispiel verwenden wir NYC Building Shapefiles. Obwohl es viele Möglichkeiten gibt, das Lesen von Shapefiles zu demonstrieren, geben wir ein Beispiel mit GeoSpark. Der integrierte ShapefileReader wird verwendet, um den rawSpatialDf DataFrame zu generieren.
Durch die Registrierung von rawSpatialDf als temporäre Ansicht können wir einfach zur reinen Spark SQL-Syntax wechseln, um mit dem DataFrame zu arbeiten, einschließlich der Anwendung eines UDF zur Konvertierung des Shapefile WKT in Geometry.
Zusätzlich können wir die integrierte Visualisierung von Databricks für Inline-Analysen verwenden, wie z. B. das Erstellen eines Diagramms der höchsten Gebäude in NYC.

Rasterdaten
Rasterdaten speichern Informationen über Merkmale in einer Matrix von Zellen (oder Pixeln), die in Zeilen und Spalten (diskret oder kontinuierlich) organisiert sind. Satellitenbilder, Photogrammetrie und gescannte Karten sind alles Arten von rasterbasierten Erdbeobachtungsdaten (EO).
Das folgende Python-Beispiel verwendet RasterFrames, ein DataFrame-zentriertes Framework für räumliche Analysen, um zwei Bänder von GeoTIFF Landsat-8-Bildern (rot und nahinfrarot) zu lesen und sie zum Normalized Difference Vegetation Index zu kombinieren. Wir können diese Daten verwenden, um die Pflanzengesundheit rund um NYC zu bewerten. Das Modul rf_ipython wird verwendet, um RasterFrame-Inhalte in eine Vielzahl von visuell nützlichen Formen zu manipulieren, wie unten gezeigt, wo die roten, NIR- und NDVI-Kachelspalten mit Farbabstufungen gerendert werden, wobei der Databricks-integrierte Befehl displayHTML(...) verwendet wird, um die Ergebnisse innerhalb des Notebooks anzuzeigen.
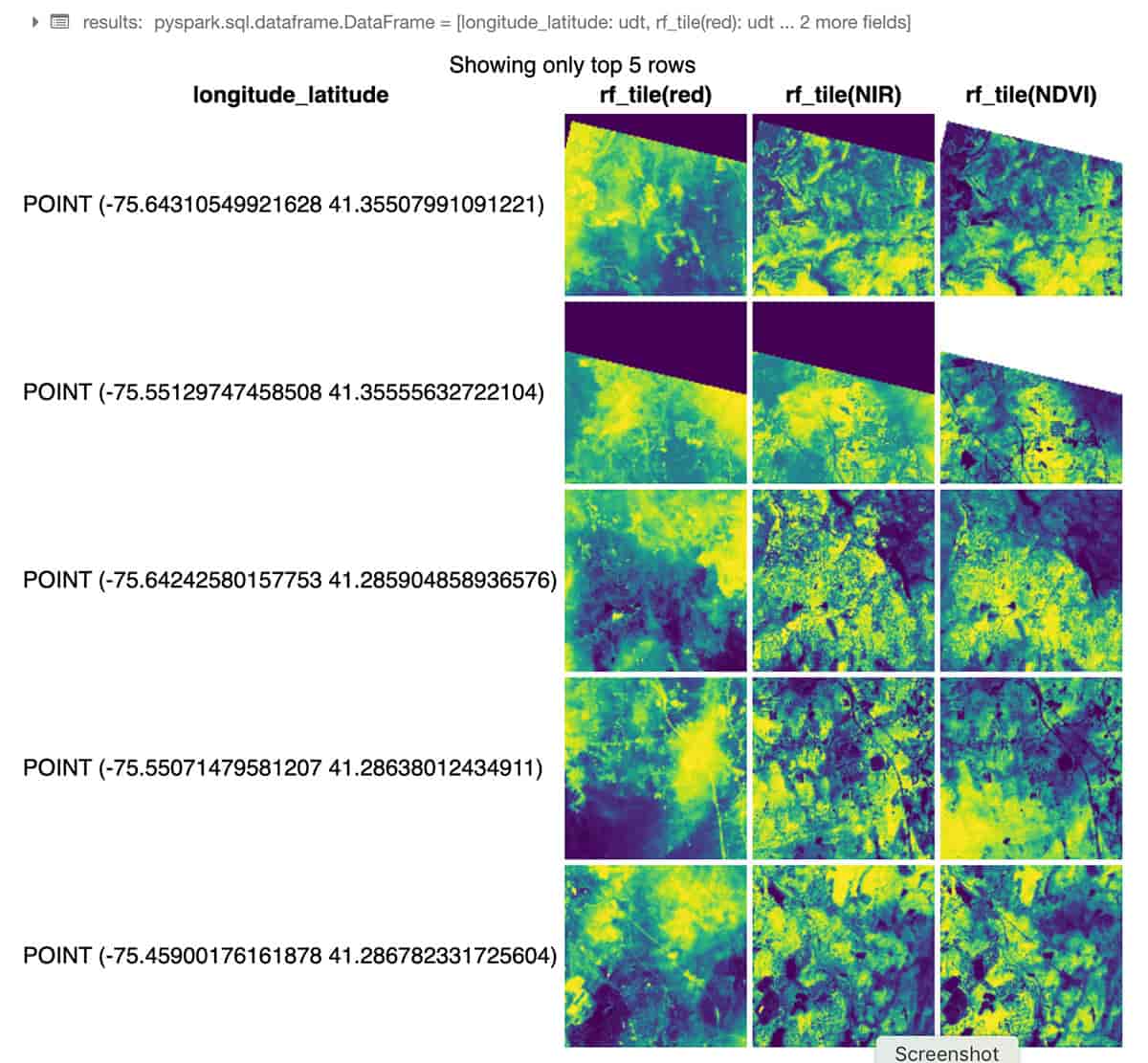
Über seine benutzerdefinierte Spark DataSource kann RasterFrames verschiedene Rasterformate lesen, darunter GeoTIFF, JP2000, MRF und HDF, von einer Reihe von Diensten. Es unterstützt auch das Lesen der Vektorformate GeoJSON und WKT/WKB. RasterFrame-Inhalte können durch über 200 Raster- und Vektorfunktionen gefiltert, transformiert, zusammengefasst, neu abgetastet und rasterisiert werden, wie z. B. st_reproject(...) und st_centroid(...), die im obigen Beispiel verwendet werden. Es bietet APIs für Python, SQL und Scala sowie Interoperabilität mit Spark ML.
Geo-Datenbanken
Geo-Datenbanken können dateibasiert für kleinere Datenmengen sein oder über JDBC / ODBC-Verbindungen für mittlere Datenmengen zugänglich sein. Sie können Databricks verwenden, um viele SQL-Datenbanken mit der integrierten JDBC / ODBC Datenquelle abzufragen. Die Verbindung zu PostgreSQL wird unten gezeigt, das häufig für kleinere Workloads verwendet wird, indem PostGIS-Erweiterungen angewendet werden. Dieses Konnektivitätsmuster ermöglicht es Kunden, den bestehenden Datenbanken weiterhin wie gewohnt Zugriff zu gewähren.
Erste Schritte mit Geodatenanalyse auf Databricks
Unternehmen und Regierungsbehörden möchten räumlich referenzierte Daten in Verbindung mit Unternehmensdatenquellen nutzen, um umsetzbare Erkenntnisse zu gewinnen und eine breite Palette innovativer Anwendungsfälle zu realisieren. In diesem Blog haben wir gezeigt, wie die Databricks Unified Data Analytics Platform Geodaten-Workloads einfach skalieren kann, sodass unsere Kunden die Leistung der Cloud nutzen können, um riesige Datenmengen zu erfassen, zu speichern und zu analysieren.
In einem kommenden Blog werden wir uns eingehend mit fortgeschritteneren Themen für die Geodatenverarbeitung im großen Maßstab mit Databricks befassen. Zusätzliche Details zu den räumlichen Formaten und hervorgehobenen Frameworks finden Sie in den folgenden Notebooks: Data Prep Notebook, GeoMesa + H3 Notebook, GeoSpark Notebook, GeoPandas Notebook und Rasterframes Notebook. Bleiben Sie auch auf dem Laufenden für einen neuen Abschnitt in unserer Dokumentation speziell für Geodaten-Themen von Interesse.
Nächste Schritte
- Nehmen Sie an unserem bevorstehenden Webinar Geospatial Analytics and AI in the Public Sector teil, um eine Live-Demo mit einer Reihe beliebter Anwendungsfälle zu sehen
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.