Einführung in Spatial SQL in Databricks: Über 80 Funktionen für hochperformante Geodatenanalysen
Das beste Daten-"where-house" ist ein Lakehouse
von Kent Marten und Michael Johns
- Beschleunigen Sie Ihre skalierten Geodatenabfragen mit über 80 Spatial SQL-Funktionen, die jetzt für die öffentliche Vorschau verfügbar sind.
- Speichern Sie nahtlos planare und geodätische Daten mit nativen GEOMETRY- und GEOGRAPHY-Datentypen.
- Verbessern Sie Ihre räumliche Analyse mit leistungsstarken räumlichen Joins und vergessen Sie die manuelle Indizierung.
Jeden Tag sind Milliarden von Datenpunkten an Orte auf der Karte gebunden. Lieferrouten, Besuche in Geschäften, Straßennetze, Mobilfunkmasten und Felder tragen alle wichtige Kontexte für Geschäftsentscheidungen. Das Problem ist, dass die Analyse dieser Daten in großem Maßstab schwierig war. Veraltete räumliche Systeme sind langsam, erfordern manuelle Indizierung und sperren Informationen oft in proprietäre Formate.
Heute führen wir Spatial SQL in Databricks ein. Spatial SQL bringt Geodatenanalyse direkt auf die Databricks-Plattform. Sie können jetzt mit nativen GEOMETRY und GEOGRAPHY Datentypen arbeiten, mehr als 80 SQL-Funktionen verwenden und räumliche Joins mit hoher Geschwindigkeit und Leistung ausführen, während Ihre Daten offen und bereit für Skalierung bleiben.
Standortdaten spielen in fast jeder Branche eine Rolle, und Spatial SQL erleichtert die Nutzung dieser Informationen.
Hier sind einige Beispiele:
- Einzelhandelsbetriebe können verstehen, woher ihre Kunden kommen, indem sie Gebiete und Kundenfrequenz analysieren
- Transportanalysten können die Sicherheit und das Kundenerlebnis verbessern, indem sie Fahrzeugvorfälle und die Konnektivität von Mobilfunknetzen analysieren
- Energieunternehmen können den Einsatz von Teams bei Stromausfällen optimieren und ideale Standorte für Wind- und Solarparks finden
- Landwirtschaftliche Betriebe können Präzisionslandwirtschaftstechniken anwenden, um Kosten zu senken und die Ertragseffizienz zu verbessern
- Versicherungsanalysten können Risiken verstehen, indem sie die Adressen von Versicherungsnehmern in Überschwemmungs-, Feuer- und Hurrikanzonen analysieren
- Gesundheitsorganisationen können Gesundheitsergebnisse vergleichen und vorhersagen, indem sie Umweltfaktoren über verschiedene Geographien hinweg analysieren
- Und vieles mehr!
Spatial SQL hilft Kunden bereits, die Leistung zu beschleunigen und die Kosten zu senken:
„Databricks Spatial SQL hat neu definiert, wie wir groß angelegte räumliche Joins durchführen. Durch die Integration von Spatial SQL-Funktionen in unsere Verarbeitungspipelines haben wir eine über 20-mal schnellere Leistung und über 50 % niedrigere Kosten bei denselben Workloads erzielt. Dieser Durchbruch ermöglicht die Integration und Bereitstellung von umfangreichen Straßennetzinformationen in einem Umfang und einer Geschwindigkeit, die zuvor einfach nicht möglich waren.“
– Laxmi Duddu, Sr. Manager, Autonomy Data Platform & Analytics, Rivian Automotive
Kunden hatten zuvor Schwierigkeiten, räumliche Workloads mit veralteten Systemen, Bibliotheken von Drittanbietern oder manuellen Indizierungsstrategien zu verwalten und zu skalieren. Mit Spatial SQL erhalten Kunden Out-of-the-Box-Einfachheit und Skalierbarkeit.
„Spatial SQL ermöglicht es uns, Geodaten-ETL wie nie zuvor zu skalieren. Anstatt PostGIS-Server mit schweren Abfragen zu überlasten, verlagern wir die Last auf Databricks und nutzen verteilte Verarbeitung, schnelle räumliche Joins und effiziente Handhabung von Vektordaten. Es ist ein effizienterer, widerstandsfähigerer und skalierbarerer Ansatz für die Verarbeitung großer und komplexer Geodaten.“
— Pierre Chenaux, Tech Leader of Geospatial department, TotalEnergies
Ein wesentlicher Treiber für die Leistung ist die Unterstützung von erstklassigen Geodaten-Datentypen. Anstatt Geodaten in Zeichen-, Binär- oder Dezimalspalten zu speichern, können Sie jetzt native GEOMETRY und GEOGRAPHY Datentypen verwenden. Diese Typen enthalten Bounding-Box-Statistiken, die Databricks während der Abfrageausführung verwendet, um irrelevante Daten zu überspringen und Joins zu beschleunigen. Spatial SQL bietet auch Importfunktionen für Standardformate wie Well Known Text, Well Known Binary, GeoJSON und einfache Breiten- oder Längenwerte.
Diese Datentypen sind in Parquet, Iceberg und Delta vollständig offen. Das Databricks-Team hat zur Gestaltung der vorgeschlagenen Spezifikationen beigetragen und stellt sicher, dass es keine Abhängigkeit von proprietären Data Warehouses gibt. Mit dem genehmigten Apache Spark™ SPIP werden GEOMETRY und GEOGRAPHY bald auch erstklassige Datentypen in der Open-Source-Engine sein.
Was können Sie mit Spatial SQL tun?
Spatial SQL ist mehr als nur eine Reihe neuer Funktionen. Es bietet Ihnen die Bausteine, um den gesamten Lebenszyklus von Geodaten zu verwalten, von der Speicherung und dem Import bis hin zur Analyse und Transformation. Durch die Arbeit mit nativen Datentypen und effizienten Operationen können Sie Standortinformationen in alltägliche Abfragen integrieren, ohne zusätzliche Komplexität hinzuzufügen.
Hier sind einige der Kernfunktionen, die Sie nutzen können:
- Speichern Sie Geodaten nativ mit GEOMETRY und GEOGRAPHY
- Importieren und exportieren Sie in Formaten wie WKT, WKB, GeoJSON und GeoHash
- Erstellen Sie neue Objekte mit Konstruktoren wie ST_Point oder ST_MakeLine
- Berechnen Sie Messungen mit Funktionen wie ST_Distance und ST_AREA
- Führen Sie räumliche Joins mit Beziehungen wie ST_Contains und ST_Intersects durch
- Transformieren Sie zwischen Koordinatensystemen mit ST_Transform
- Bearbeiten, validieren und kombinieren Sie räumliche Objekte mit ST_ISVALID oder ST_UNION_AGG
- Und vieles mehr!
Diese Funktionen bieten Ihnen ein vollständiges Toolkit für räumliche Analysen direkt in SQL, das auch mit Python- und Scala-APIs verfügbar ist. Wenn Sie sie kombinieren, erschließen Sie reale Workflows, die in der Praxis wichtig sind und die wir im nächsten Abschnitt behandeln werden.
Spatial SQL-Beispiele in der Praxis
Geodaten sind allgegenwärtig und wachsen. GPS-Spuren mit Breiten- und Längengraden werden jede Sekunde von einer wachsenden Anzahl von Geräten, Sensoren und Fahrzeugen gesendet. Die Welt wird ständig katalogisiert und aktualisiert, wobei Orte, Straßen, Netze und Grenzen als Punkte, Linien und Polygone modelliert werden. In jeder Branche – Einzelhandel, Transport und Logistik, Energie, Klima und Naturwissenschaften, Landwirtschaft, öffentlicher Sektor, Finanzdienstleistungen, Immobilien, Versicherungen, Telekommunikation – sind Standortinformationen für jeden Entscheidungsträger wichtig, der das „Wo“ in seinen Daten verstehen muss.
Wir haben vier kurze Beispiele erstellt, um Ihnen den Einstieg in die Arbeit mit den neuen Geodaten-Datentypen und -Ausdrücken zu erleichtern, mit den folgenden Zielen.
- Bereiten Sie Daten für eine effiziente Verarbeitung vor, indem Sie den neuen GEOMETRY-Typ verwenden
- Führen Sie eine Datenanreicherung durch, indem Sie zwei räumliche Datensätze mithilfe eines räumlichen Joins kombinieren
- Transformieren Sie Daten in ein geeignetes räumliches Bezugssystem, um die Genauigkeit von Entfernungsmessungen zu verbessern
- Messen Sie die Entfernung zwischen zwei Städten
In diesen Beispielen verwenden wir Adress-, Gebäude- und Abteilungsdatensätze von OvertureMaps.org. Diese Datensätze werden auf verschiedene Weise zum Download angeboten, z. B. als GeoParquet.
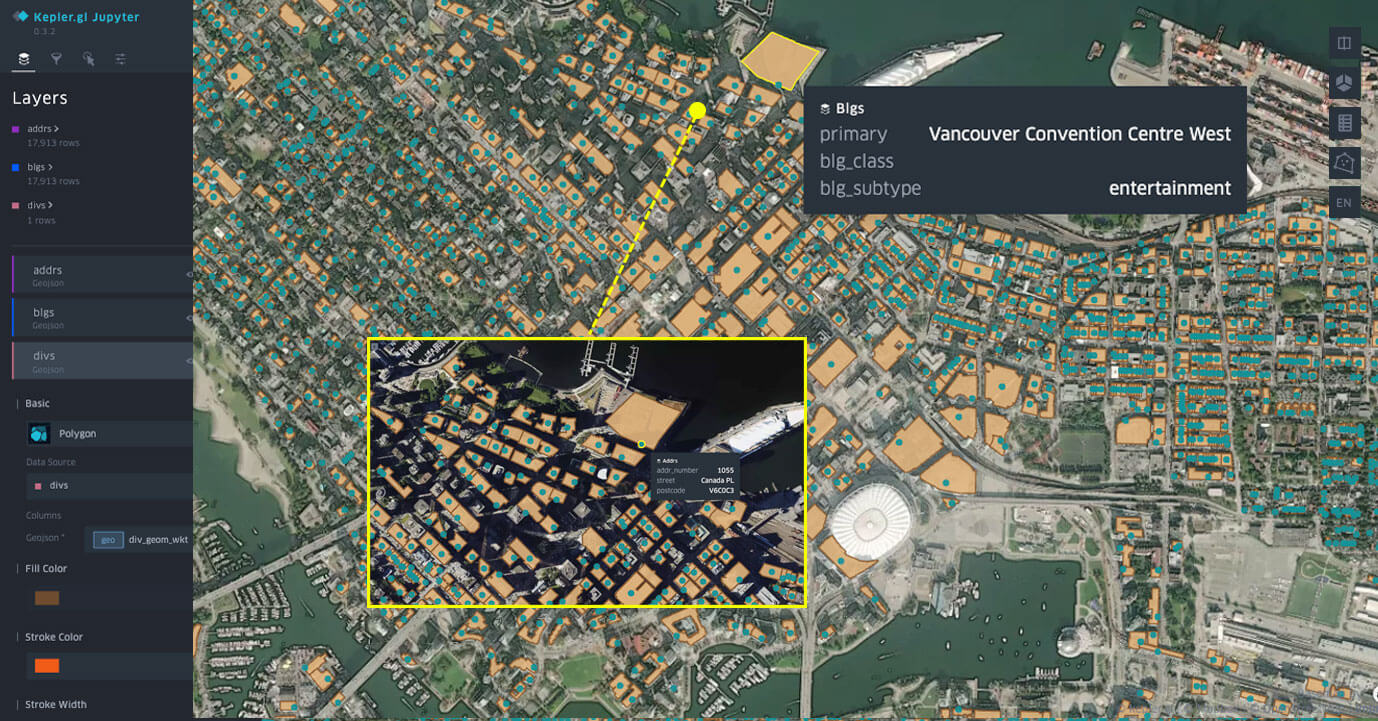
Overture Maps-Datensätze visualisiert in einem Databricks Notebook mit kepler.gl.
1. Erstellen einer GEOMETRY-Spalte
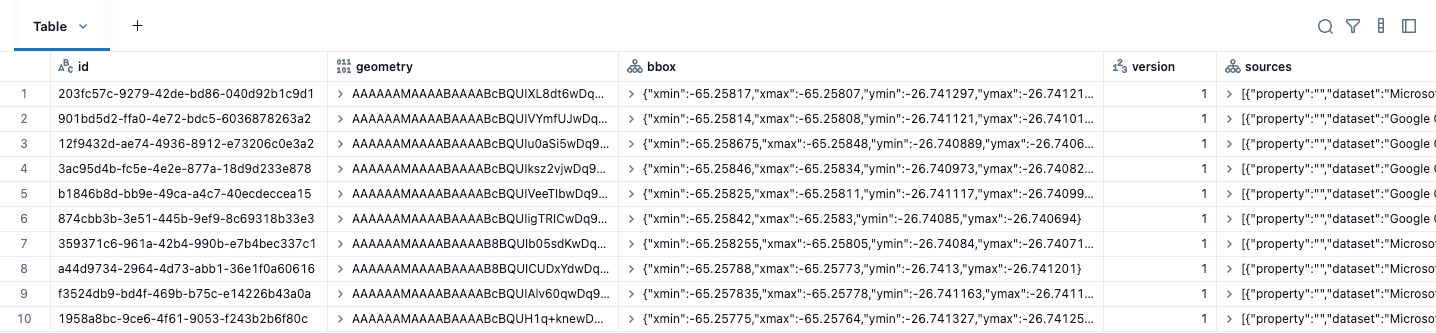
Der erste Schritt vor jeder räumlichen Analyse ist die Konvertierung Ihrer Daten zur Verwendung von GEOMETRY- oder GEOGRAPHY-Datentypen. Nach dem Herunterladen der Overture Maps-Daten müssen wir lediglich eine native GEOMETRY-Spalte aus der bereitgestellten WKB-Geometriespalte erstellen und andere unnötige Spalten wie bbox löschen. Eine Bounding Box ist das kleinste Rechteck, das eine Geometrie enthält. In räumlichen Abfragen beschleunigen Bounding Boxes Abfragen, indem sie schnell Daten verwerfen, die unmöglich überlappen können. Wenn sich zwei Bounding Boxes nicht überschneiden, überschneiden sich die darin enthaltenen Geometrien definitiv nicht, sodass die Datenbank die kostspielige Schnittprüfung überspringen und die Menge der verarbeiteten Daten reduzieren kann. Wir benötigen das bbox-Feld nicht, da diese Informationen jetzt in den Spaltenstatistiken verwaltet werden. Für diese Datensätze sind Adressen POINTS, während Gebäude und Abteilungen POLYGONS / MULTI-POLYGONS sind. Hier sind die ursprünglich heruntergeladenen Gebäudedaten, die die ersten fünf Spalten zeigen.
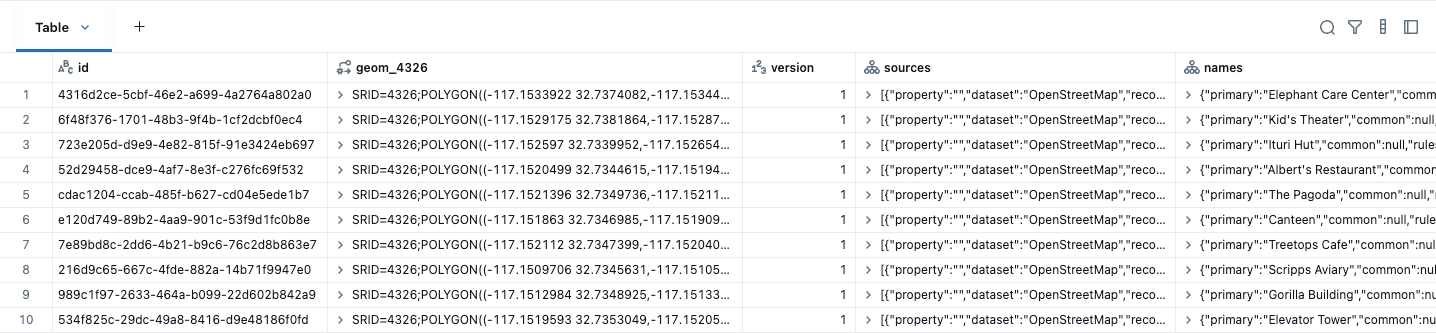
Diese Daten können mit nativem GEOMETRY und ST_GeomFromWKB einfach in eine Lakehouse Table konvertiert werden, wie im folgenden Beispiel für Gebäude gezeigt. Wir wissen, dass unsere Daten in WGS84 (EPSG:4326) vorliegen, daher geben wir dies bei der Erstellung des räumlichen Typs an. Eine SRID identifiziert das Koordinatensystem Ihrer räumlichen Daten, das die Einheiten (wie Grad oder Meter) definiert, die in Berechnungen wie Entfernung und Fläche verwendet werden. Sie müssen eine gültige SRID festlegen, wenn Sie eine Geometriespalte erstellen, andernfalls gibt die Abfrage einen Fehler zurück. Beachten Sie auch, dass unsere nativen Typen in einem menschenfreundlichen Format (EWKT) angezeigt werden.
Neben WKB können räumliche Daten auch direkt aus den gängigsten Austauschformaten in unsere nativen Typen importiert werden:
- Breiten- und Längengradkoordinaten mit ST_POINT
- WKT mit ST_GeomFromWKT oder ST_GeomFromText
- WKB mit ST_GeomFromWKB oder ST_GeomFromBinary
- GeoJSON mit ST_GeomFromGeoJSON
- GeoHash mit ST_PointFromGeoHash
Ebenso können räumliche Daten in eine Reihe von Formaten exportiert werden:
- WKT mit ST_AsWKT oder ST_AsText
- WKB mit ST_AsWKB oder ST_AsBinary
- GeoJSON mit ST_AsGeoJSON
- Erweitertes WKT mit ST_AsEWKT
- Erweitertes WKB mit ST_AsEWKB
- GeoHash mit ST_GeoHash
Hinweis: Wir haben auch Import- und Export-Ausdrücke für GEOGRAPHY-Typen.
2. Räumliches Verknüpfen mehrerer Datensätze
Räumliche Joins sind eine der wichtigsten und am weitesten verbreiteten Operationen in der Verarbeitung von Geodaten. Sie ermöglichen es Ihnen, Attribute aus verschiedenen Datensätzen zu kombinieren und Aggregationen oder Datenanreicherungen basierend auf ihren räumlichen Beziehungen wie Inklusion, Schnittmenge und Nähe durchzuführen. Dies macht räumliche Joins unerlässlich, um reale Fragen zu beantworten, wie z. B. die Identifizierung, welche Gebäude sich in einer Überschwemmungszone befinden, die Zuordnung von Zensusdemografien zu Kundenadressen und die Analyse von vernetzten Fahrzeugen innerhalb von Mobilfunkabdeckungsbereichen. Da ein Großteil der Geodatenanalyse von der Integration mehrerer Datensätze abhängt, sind räumliche Joins oft ein erster Schritt in der explorativen räumlichen Analyse, der räumlichen Modellierung und der standortbasierten Entscheidungsfindung.
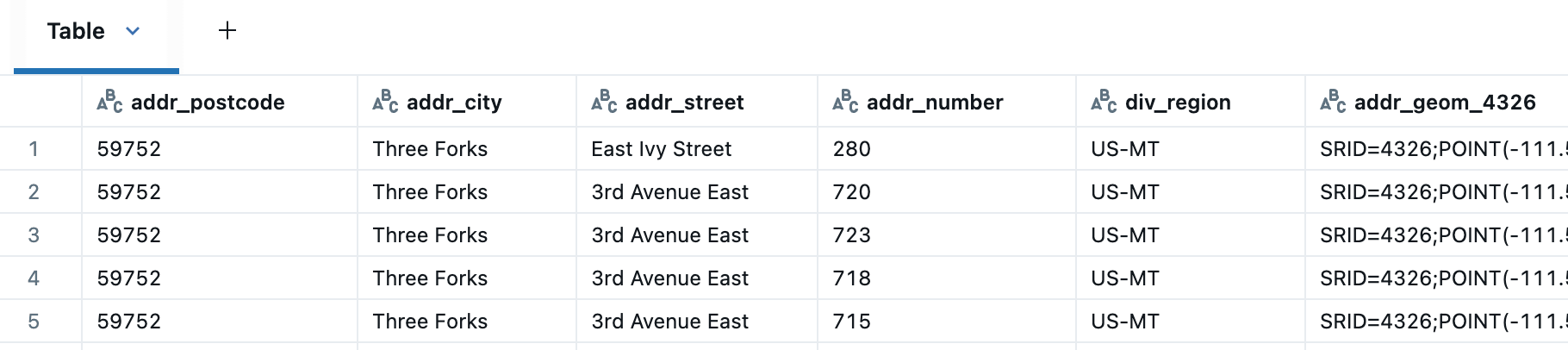
Als Nächstes verknüpfen wir die Adress- und Divisionstabellen mithilfe eines räumlichen Joins. Jeder, der mit Adressdatenquellen gearbeitet hat, weiß, dass Adressen unordentliche Daten sein können (eine häufige Ursache ist, dass verschiedene Länder unterschiedliche Adresssysteme verwenden). Darüber hinaus enthält die Adressentabelle keine vollständige administrative Hierarchie (d. h. keine Kreisinformationen für US-Adressen). Wir werden also die Divisionstabelle verwenden, um die Stadtinformationen zu validieren und sie durch Hinzufügen von Kreis-Äquivalentinformationen anzureichern.
Dieser Prozess der Datenvalidierung und -anreicherung wäre ohne einen räumlichen Join anders zu lösen. Dazu müssen wir die Adresse innerhalb der Division finden. Wir verwenden ST_Contains, um einen Punkt-in-Polygon-Räumlichen Join durchzuführen, und lassen Databricks die Interna der Operation handhaben, ohne dass eine manuelle räumliche Indizierung erforderlich ist.
Jetzt können wir uns leichter auf die richtige Stadt, den richtigen Bundesstaat, den richtigen Kreis und das richtige Land standardisieren, z. B. fehlende Städte in Adressen durch die in der Divisionstabelle angegebenen ersetzen.
Nach der Validierung der Adressen haben wir einen ähnlichen Ansatz verfolgt, um die Adressen mit Gebäuden mithilfe von ST_Intersects zu verknüpfen, um die Gebäudetabelle mit Adressinformationen anzureichern. Für die USA hat dieser räumliche Join 44 Millionen Adressen mit Gebäuden abgeglichen, wobei 55 Millionen Gebäude nicht abgeglichen wurden. Im nächsten Beispiel sehen wir, wie wir die Nähe nutzen können, um Gebäude zu identifizieren, die nicht mit einer Adresse übereinstimmen.
3. Transformation von Daten in spezifische räumliche Bezugssysteme
Geodaten werden oft in unterschiedlichen Koordinatenbezugssystemen (CRS) erstellt, wie z. B. Längen- und Breitengrad (WGS84) oder projizierte Systeme wie UTM, abhängig von ihrer Quelle und ihrem Zweck. Während jedes CRS definiert, wie die gekrümmte Oberfläche der Erde auf einer flachen Karte dargestellt wird, kann die Verwendung von Datensätzen mit nicht übereinstimmenden Projektionen dazu führen, dass Merkmale fehlausgerichtet werden, Entfernungen verzerrt werden oder falsche räumliche Joins und Messungen entstehen. Ein Geschäft in einer Überschwemmungszone wird bei einem räumlichen Join nicht übereinstimmen, wenn unterschiedliche Koordinatensysteme verwendet werden. Für eine genaue Analyse – sei es bei der Berechnung von Flächen, dem Verknüpfen von Ebenen oder der Visualisierung räumlicher Beziehungen – ist es unerlässlich, sicherzustellen, dass alle Datensätze in die gleiche Projektion transformiert werden, damit sie eine konsistente räumliche Referenz teilen.
Um Adressen in der Nähe der verbleibenden 55 Millionen nicht übereinstimmenden Gebäude in den USA zu identifizieren, projizieren wir unsere WGS84 GEOMETRY-Daten nach Conus Albers (EPSG:5070) für Nordamerika, was uns Einheiten in Metern liefert. Dies wird mit der Funktion ST_Transform erreicht.
Wenden wir ST_DWithin zwischen unseren nicht übereinstimmenden US-Gebäuden und Adressen an, wobei ein Abstandswert von nur 2 Metern verwendet wird.
Der Abstandswert kann nach Bedarf erhöht werden, um eine Reihe potenzieller Adressübereinstimmungen zu sammeln. Außerdem kann eine rekursive CTE nützlich sein, um über mehrere Abstände zu iterieren. Für dieses Beispiel ermöglicht ein Filterpolygon die einfache Isolierung unserer Suche auf die Umgebung von Saint Petersburg, Florida. Das Polygon wird zunächst aus WKT mit ST_GeomFromWKT vorbereitet und dann in SRID 5070 transformiert, um mit den Adress- und Gebäudedaten übereinzustimmen.
Um Datensätze für die rekursive CTE einzurichten, wenden wir einen räumlichen Filter auf unsere Daten an, indem wir Gebäude und Adressen mit dem Suchpolygon schneiden. Unten sind die Gebäude dargestellt (Adressen werden ähnlich behandelt).
Die folgende rekursive CTE iteriert über Gebäude, um Adresskandidaten innerhalb von 5, 10 und 15 Metern zu identifizieren. Die Ergebnistabelle entfernt doppelte Adressen über aufeinanderfolgende Abstände hinweg mithilfe des folgenden Fenster-Ausdrucks: QUALIFY RANK() OVER (PARTITION BY blg_id,addr_id ORDER BY dwithin) = 1.
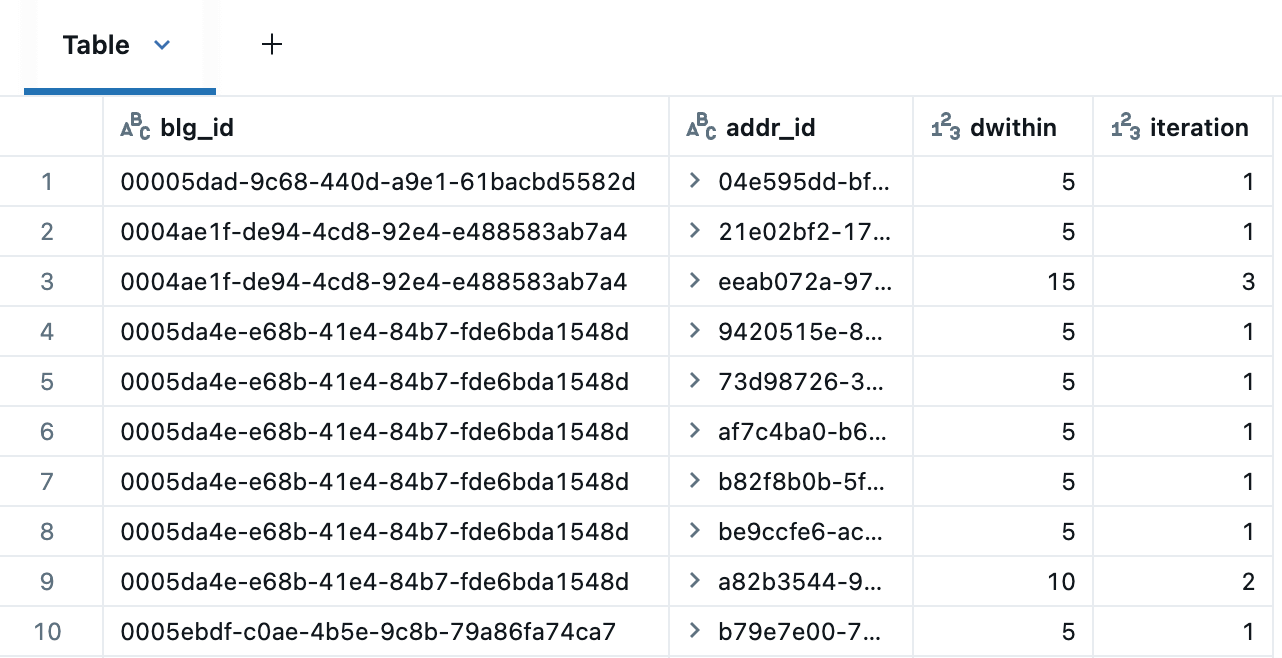
Hier sind die Adresskandidaten rund um eines der Gebäude, die Übereinstimmungen bei 5 m (blau), 10 m (orange) und 15 m (grün) zeigen. Dies wird mit den integrierten Marker Maps von Databricks im Clustering-Modus gerendert, der nahe Punkte zur einfacheren Ansicht auffächert. Bei der Erstellung eines Dashboards hätten wir auch AI/BI Point Maps verwenden können, die Cross-Filtering und Drill-Through unterstützen.
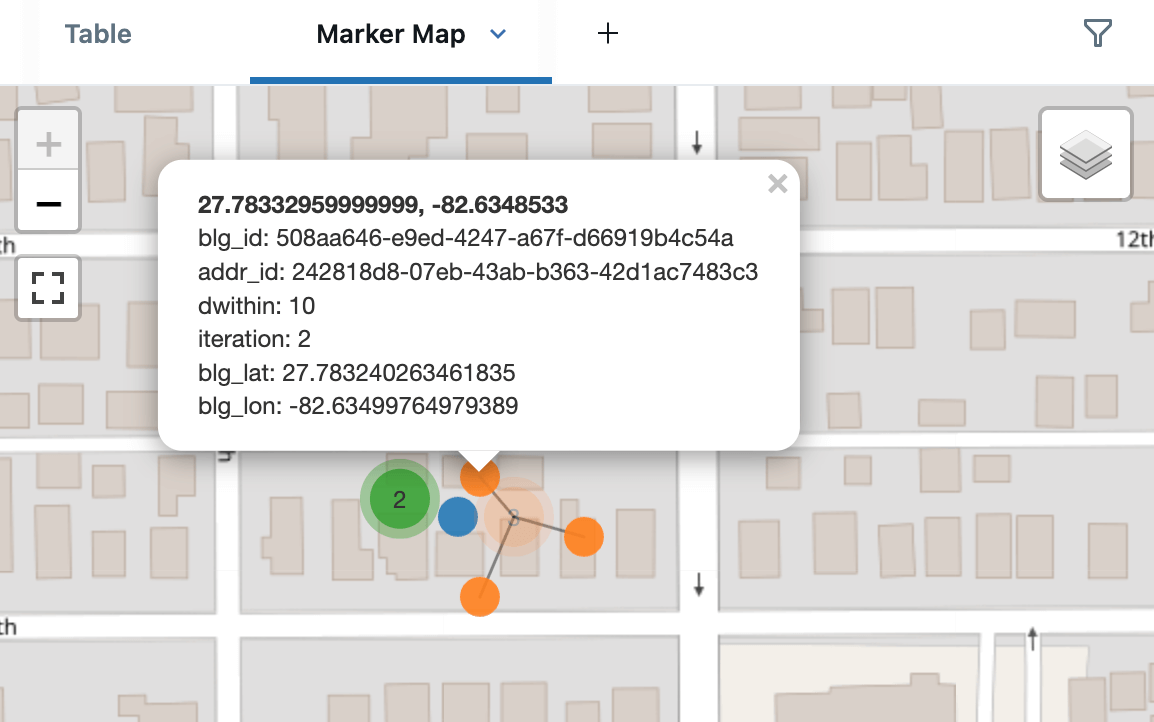
Es gibt zahlreiche alternative Anwendungen von rekursiven CTEs für die räumliche Verarbeitung, z. B. die Implementierung des Algorithmus von Prim zum Aufbau eines minimalen Spannbaums Ihrer Lieferpunkte.
4. Messen von Distanzen zwischen Orten
Nähe ist ein Kernkonzept in der räumlichen Analyse, da die Distanz oft die Stärke oder Relevanz von Beziehungen zwischen Orten bestimmt. Ob es darum geht, das nächste Krankenhaus zu identifizieren, die Konkurrenz zwischen Geschäften zu analysieren oder Pendlerströme abzubilden – das Verständnis, wie nahe sich Objekte zueinander befinden, liefert entscheidenden Kontext.
Fortfahrend mit unserem Beispiel-Datensatz haben wir dieselbe Conus-Albers-Transformationsoperation auf unseren Städten in Florida durchgeführt, um ihre Distanzen zu messen. Wir messen vom geometrischen Zentrum der Städte, das mit der Funktion generiert wird: ST_Centroid.
Bei der Berechnung der Distanz zwischen zwei GEOMETRIES gibt es mehrere verschiedene Funktionen zu beachten:
- ST_Distance - Gibt die kartesische Distanz in den Einheiten der bereitgestellten GEOMETRIES zurück und berechnet den geradlinigen Pfad basierend auf ihren x- und y-Koordinaten, als ob die Erde flach wäre.
- ST_DistanceSphere - Gibt die sphärische Distanz (immer in Metern) zwischen zwei Punkt-GEOMETRIES zurück, gemessen am mittleren Radius des WGS84-Ellipsoids der Erde, wobei angenommen wird, dass Koordinatenpunkte Einheiten von Grad haben, z. B. wäre SRID 4326 gültig, aber nicht SRID 5070.
- ST_DistanceSpheroid - Gibt die geodätische Distanz (immer in Metern) zwischen zwei Punkt-GEOMETRIES auf dem WGS84-Ellipsoid der Erde zurück; auch hier wird angenommen, dass Koordinatenpunkte Einheiten von Grad haben. Wiederum wären SRID 4326 oder jede andere SRID mit Einheiten in Grad gültige Eingaben für dieses Beispiel.
Die verschiedenen Distanzberechnungen werden zwischen city1 und city2 angewendet, wobei ST_Distance für die GEOMETRIES in 5070 und dann ST_DistanceSphere und ST_DistanceSpheroid für die GEOMETRIES in 4326 verwendet wird.
Unter den Distanzfunktionen würden wir erwarten, dass ST_DistanceSpheriod (Messungen basierend auf der ellipsoiden Form der Erde) in diesem Fall am genauesten ist, gefolgt von ST_DistanceSphere (Messungen gehen von einer perfekten Kugel aus). Beachten Sie, dass ST_Distance am nützlichsten ist, wenn Sie mit projizierten Koordinatenreferenzsystemen arbeiten oder wenn die Krümmung der Erde anderweitig ignoriert werden kann. Obwohl SRID 5070 in Metern angegeben ist, können wir die Auswirkungen kartesischer Berechnungen über größere Distanzen sehen. ST_Distance wäre im Allgemeinen keine geeignete Wahl für SRID 4326, da die von einem Längengrad zurückgelegte Distanz drastisch variiert, wenn Sie sich vom Äquator zu den Polen bewegen, z. B. unterscheidet sich 1 Längengrad um bis zu 6 km allein innerhalb des Bundesstaates Florida.
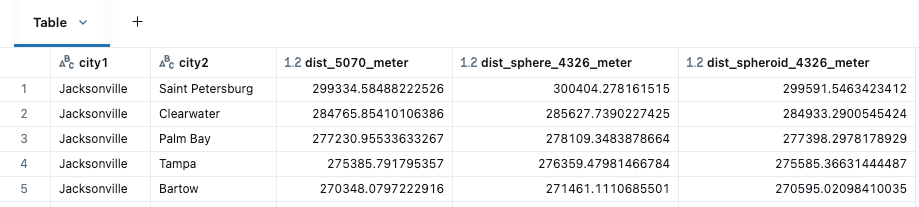
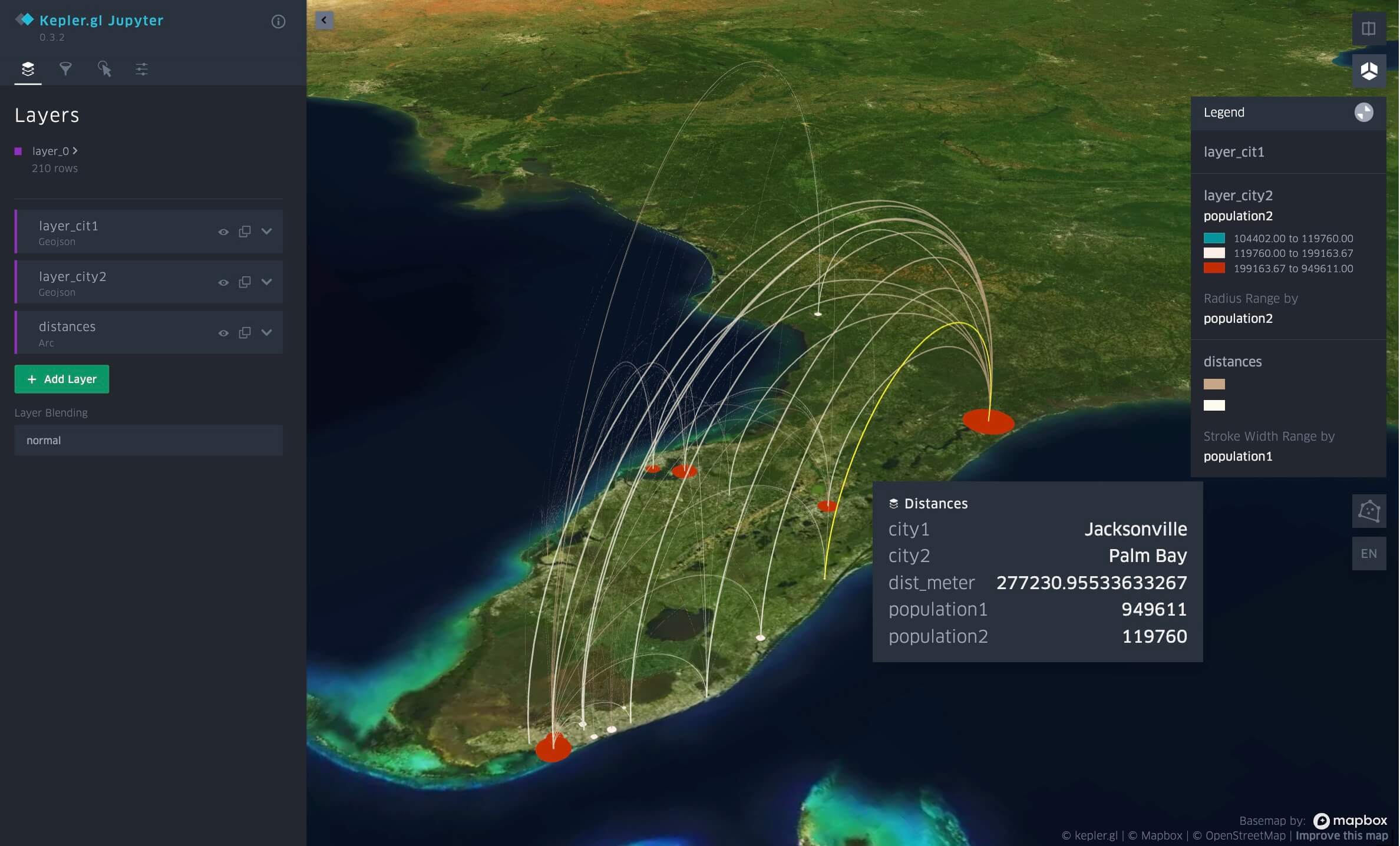
Nähe nach Distanz zwischen Städten in Florida, visualisiert in Databricks Notebook mit kepler.gl.
Spatial SQL umfasst mehr als 80 Funktionen, die es Kunden ermöglichen, gängige räumliche Datenoperationen einfach und skalierbar durchzuführen. Mit Spatial SQL beginnen Kunden nun, ihren Ansatz für die Verwaltung und Integration mit GIS-Systemen zu ändern:
„Räumliche Daten sind der Kern von allem, was wir bei OSPRI tun, sei es bei der Rückverfolgbarkeit von Nutztieren, der Krankheitsbekämpfung oder dem Schädlingsmanagement. Databricks Spatial SQL ermöglicht es uns, Databricks vollständig in all unsere Arbeit zu integrieren. Diese Fortschritte ermöglichen es uns, große desktopbasierte räumliche Modellierungsaufgaben auf eine Plattform zu verlagern, auf der sie näher an den Daten liegen und parallel und schnell ausgeführt werden können. Wochenlange Iterationen über Betriebsgrenzen hinweg können bequem innerhalb von ein oder zwei Tagen durchgeführt werden, was unsere Entscheidungsfindung beschleunigt. Diese neuen Funktionen ermöglichen es uns auch, Databricks zur Integrationsschicht zwischen unseren Transaktionssystemen und unserer GIS-Plattform zu machen, um sicherzustellen, dass sie ohne Kompromisse von Daten aus der gesamten Organisation informiert werden können.“ - Campbell Fleury, Manager, Data and Information Products, OSPRI New Zealand
Was kommt als Nächstes
Es gibt so viel, was Sie mit Spatial SQL in Databricks tun können, und es kommt noch mehr, einschließlich neuer Ausdrücke und schnellerer räumlicher Joins. Wenn Sie mitteilen möchten, welche zusätzlichen ST-Ausdrücke Sie benötigen, füllen Sie bitte diese kurze Umfrage aus.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.