Adaptive Query Execution: Beschleunigung von Spark SQL zur Laufzeit
von Wenchen Fan, Herman van Hövell und MaryAnn Xue
Lesen Sie Rise of the Data Lakehouse, um zu erfahren, warum Lakehouses die Datenarchitektur der Zukunft sind, mit dem Vater des Data Warehouse, Bill Inmon.
Dies ist eine gemeinsame technische Anstrengung des Databricks Apache Spark Engineering Teams – Wenchen Fan, Herman van Hovell und MaryAnn Xue – und des Intel Engineering Teams – Ke Jia, Haifeng Chen und Carson Wang.
Sehen Sie sich das AQE-Notebook an, um die unten beschriebene Lösung zu demonstrieren oder tauchen Sie tiefer in die Funktionsweise der Databricks Lakehouse Platform ein
Im Laufe der Jahre gab es erhebliche und kontinuierliche Bemühungen, den Query Optimizer und Planner von Spark SQL zu verbessern, um qualitativ hochwertige Query-Ausführungspläne zu generieren. Eine der größten Verbesserungen ist das Cost-Based Optimization Framework, das verschiedene Datenstatistiken (z. B. Zeilenanzahl, Anzahl eindeutiger Werte, NULL-Werte, Max/Min-Werte usw.) sammelt und nutzt, um Spark bei der Auswahl besserer Pläne zu helfen. Beispiele für diese Cost-Based Optimization-Techniken sind die Auswahl des richtigen Join-Typs (Broadcast Hash Join vs. Sort Merge Join), die Auswahl der richtigen Build-Seite in einem Hash-Join oder die Anpassung der Join-Reihenfolge in einem Multi-Way-Join. Veraltete Statistiken und unvollständige Kardinalitätsschätzungen können jedoch zu suboptimalen Query-Plänen führen. Adaptive Query Execution, neu in der kommenden Apache SparkTM 3.0-Version und verfügbar in Databricks Runtime 7.0, zielt nun darauf ab, solche Probleme zu lösen, indem Query-Pläne basierend auf Laufzeitstatistiken neu optimiert und angepasst werden, die während der Query-Ausführung gesammelt werden.
Das Adaptive Query Execution (AQE) Framework
Eine der wichtigsten Fragen für Adaptive Query Execution ist, wann neu optimiert werden soll. Spark-Operatoren werden oft in Pipelines verarbeitet und in parallelen Prozessen ausgeführt. Ein Shuffle- oder Broadcast-Exchange unterbricht jedoch diese Pipeline. Wir nennen sie Materialisierungspunkte und verwenden den Begriff „Query Stages“, um durch diese Materialisierungspunkte abgegrenzte Unterabschnitte einer Abfrage zu bezeichnen. Jede Query Stage materialisiert ihr Zwischenergebnis, und die nachfolgende Stage kann erst fortfahren, wenn alle parallelen Prozesse, die die Materialisierung ausführen, abgeschlossen sind. Dies bietet eine natürliche Gelegenheit zur Neuoptimierung, da hier die Datenstatistiken für alle Partitionen verfügbar sind und die nachfolgenden Operationen noch nicht begonnen haben.
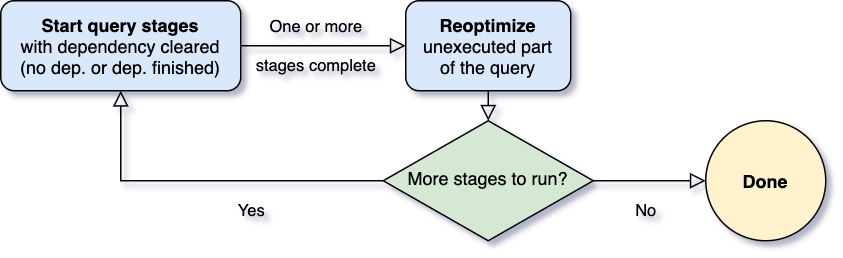
Wenn die Abfrage startet, initiiert das Adaptive Query Execution Framework zunächst alle Leaf Stages – die Stages, die von keiner anderen Stage abhängen. Sobald eine oder mehrere dieser Stages die Materialisierung abgeschlossen haben, markiert das Framework sie im physischen Query-Plan als abgeschlossen und aktualisiert den logischen Query-Plan entsprechend, mit den Laufzeitstatistiken, die aus den abgeschlossenen Stages abgerufen wurden. Basierend auf diesen neuen Statistiken führt das Framework dann den Optimizer (mit einer ausgewählten Liste logischer Optimierungsregeln), den physischen Planner sowie die physischen Optimierungsregeln aus, zu denen die regulären physischen Regeln und die auf Adaptive Execution zugeschnittenen Regeln gehören, wie z. B. das Zusammenfassen von Partitionen, die Behandlung von Skew Joins usw. Nun, da wir einen neu optimierten Query-Plan mit einigen abgeschlossenen Stages haben, sucht das Adaptive Execution Framework nach neuen Query Stages, deren Child Stages alle materialisiert wurden, und wiederholt den obigen Prozess des Ausführens-Neuoptimierens-Ausführens, bis die gesamte Abfrage abgeschlossen ist.
In Spark 3.0 wird das AQE Framework mit drei Funktionen ausgeliefert:
- Dynamisches Zusammenfassen von Shuffle-Partitionen
- Dynamisches Umschalten von Join-Strategien
- Dynamische Optimierung von Skew Joins
Die folgenden Abschnitte werden diese drei Funktionen im Detail behandeln.
Dynamisches Zusammenfassen von Shuffle-Partitionen
Beim Ausführen von Abfragen in Spark zur Verarbeitung sehr großer Daten hat Shuffle neben vielen anderen Dingen normalerweise einen sehr wichtigen Einfluss auf die Abfrageleistung. Shuffle ist ein teurer Operator, da er Daten über das Netzwerk bewegen muss, damit die Daten für nachgelagerte Operatoren entsprechend umverteilt werden.
Eine Schlüsseleigenschaft von Shuffle ist die Anzahl der Partitionen. Die optimale Anzahl von Partitionen hängt von den Daten ab, aber die Datengrößen können von Stage zu Stage und von Abfrage zu Abfrage stark variieren, was diese Zahl schwer zu optimieren macht:
- Wenn es zu wenige Partitionen gibt, kann die Datengröße jeder Partition sehr groß sein, und die Tasks zur Verarbeitung dieser großen Partitionen müssen möglicherweise Daten auf die Festplatte auslagern (z. B. bei Sortier- oder Aggregationsoperationen), was die Abfrage verlangsamt.
- Wenn es zu viele Partitionen gibt, kann die Datengröße jeder Partition sehr klein sein, und es werden viele kleine Netzwerkanfragen zum Lesen der Shuffle-Blöcke erforderlich, was die Abfrage aufgrund des ineffizienten I/O-Musters ebenfalls verlangsamen kann. Eine große Anzahl von Tasks belastet auch den Spark Task Scheduler stärker.
Um dieses Problem zu lösen, können wir zu Beginn eine relativ große Anzahl von Shuffle-Partitionen festlegen und dann zur Laufzeit benachbarte kleine Partitionen zu größeren Partitionen zusammenfassen, indem wir die Shuffle-Dateistatistiken betrachten.
Nehmen wir zum Beispiel an, wir führen die Abfrage SELECT max(i) FROM tbl GROUP BY j aus. Die Eingabedaten tbl sind eher klein, sodass es vor der Gruppierung nur zwei Partitionen gibt. Die anfängliche Anzahl der Shuffle-Partitionen ist auf fünf festgelegt, sodass nach der lokalen Gruppierung die teilweise gruppierten Daten in fünf Partitionen geshuffelt werden. Ohne AQE startet Spark fünf Tasks für die endgültige Aggregation. Es gibt jedoch drei sehr kleine Partitionen, und es wäre eine Verschwendung, für jede davon einen separaten Task zu starten.
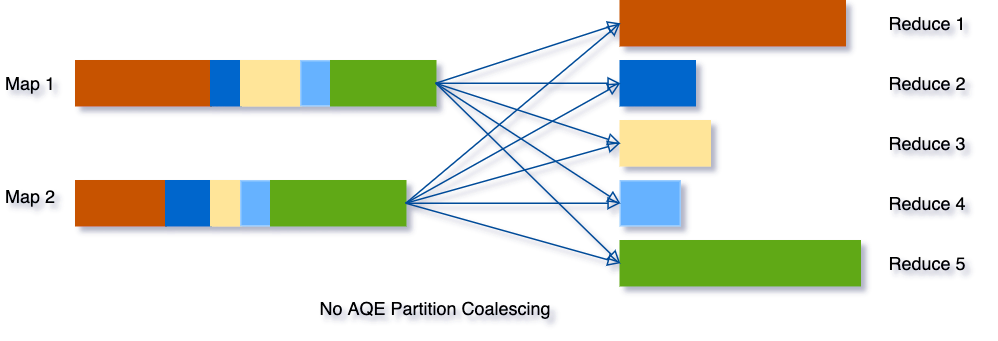
Stattdessen fasst AQE diese drei kleinen Partitionen zu einer zusammen, und infolgedessen muss die endgültige Aggregation nur noch drei Tasks anstelle von fünf durchführen.

Dynamisches Umschalten von Join-Strategien
Spark unterstützt eine Reihe von Join-Strategien, von denen Broadcast Hash Join normalerweise am performantesten ist, wenn eine Seite des Joins gut in den Speicher passt. Aus diesem Grund plant Spark einen Broadcast Hash Join, wenn die geschätzte Größe einer Join-Relation unter dem Broadcast-Größen-Schwellenwert liegt. Eine Reihe von Dingen kann jedoch dazu führen, dass diese Größenschätzung fehlerhaft ist – wie z. B. das Vorhandensein eines sehr selektiven Filters – oder die Join-Relation eine Reihe komplexer Operatoren und nicht nur ein Scan ist.
Um dieses Problem zu lösen, plant AQE die Join-Strategie jetzt zur Laufzeit basierend auf der genauesten Join-Relationsgröße neu. Wie im folgenden Beispiel zu sehen ist, ist die rechte Seite des Joins deutlich kleiner als geschätzt und auch klein genug, um übertragen zu werden. Nach der AQE-Neuoptimierung wird der statisch geplante Sort Merge Join nun in einen Broadcast Hash Join umgewandelt.
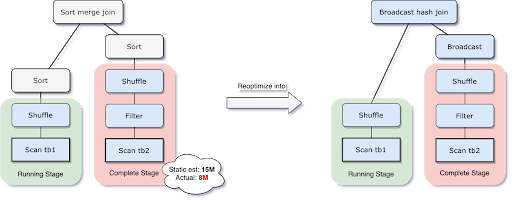
Für den zur Laufzeit konvertierten Broadcast Hash Join können wir den regulären Shuffle weiter zu einem lokalisierten Shuffle (d. h. einem Shuffle, der pro Mapper statt pro Reducer liest) optimieren, um den Netzwerkverkehr zu reduzieren.
Dynamische Optimierung von Skew Joins
Data Skew tritt auf, wenn Daten ungleichmäßig auf die Partitionen im Cluster verteilt sind. Starker Skew kann die Abfrageleistung erheblich beeinträchtigen, insbesondere bei Joins. Die AQE Skew Join-Optimierung erkennt solchen Skew automatisch anhand von Shuffle-Dateistatistiken. Sie teilt dann die verzerrten Partitionen in kleinere Unterpartitionen auf, die jeweils mit der entsprechenden Partition von der anderen Seite verbunden werden.
Nehmen wir dieses Beispiel einer Tabelle A, die Tabelle B joinen, bei der Tabelle A eine Partition A0 hat, die deutlich größer ist als ihre anderen Partitionen.
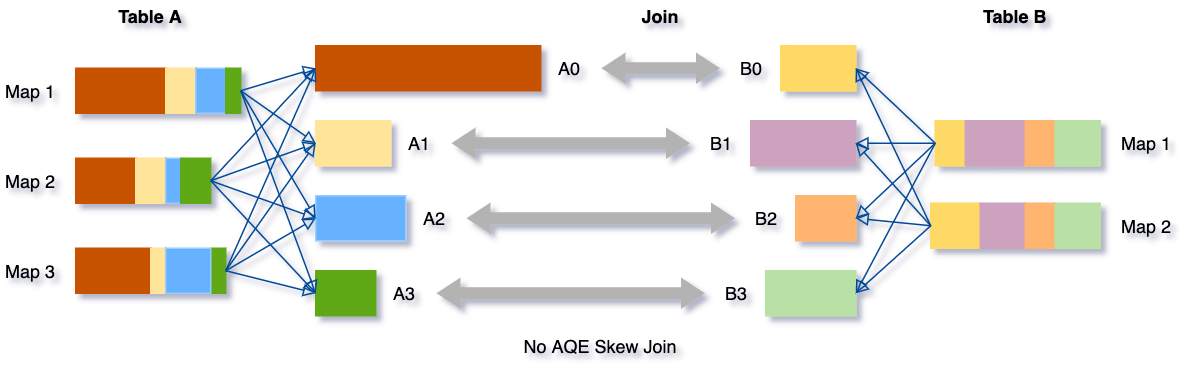
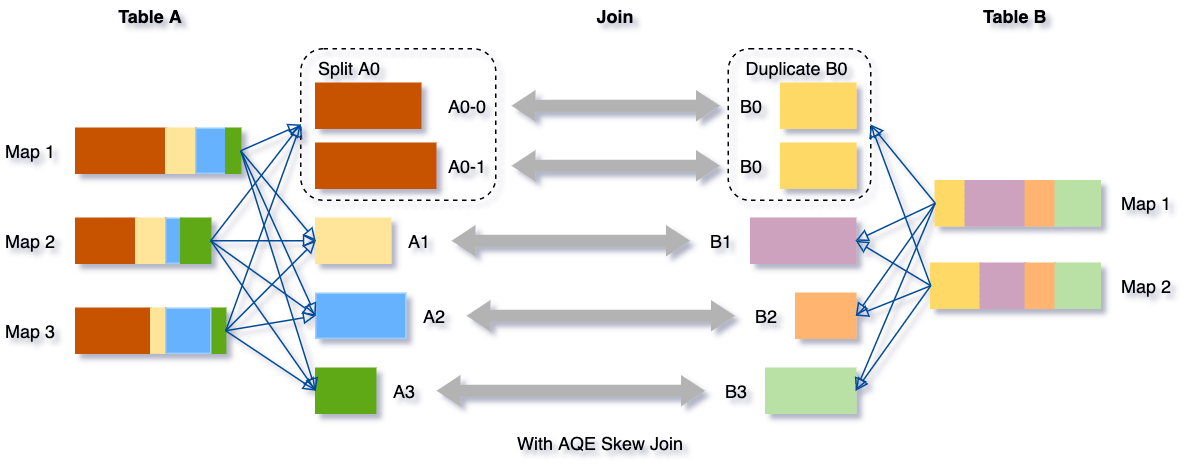
Ohne diese Optimierung würden vier Tasks den Sort Merge Join ausführen, wobei eine Aufgabe deutlich länger dauern würde. Nach dieser Optimierung werden fünf Tasks den Join ausführen, aber jede Aufgabe wird ungefähr gleich viel Zeit in Anspruch nehmen, was zu einer insgesamt besseren Leistung führt.
TPC-DS-Leistungssteigerungen durch AQE
In unseren Experimenten mit TPC-DS-Daten und -Abfragen erzielte Adaptive Query Execution eine Beschleunigung der Abfrageleistung um das bis zu 8-fache, und 32 Abfragen zeigten eine Beschleunigung von mehr als 1,1x. Unten sehen Sie eine Grafik der 10 TPC-DS-Abfragen mit der größten Leistungsverbesserung durch AQE.
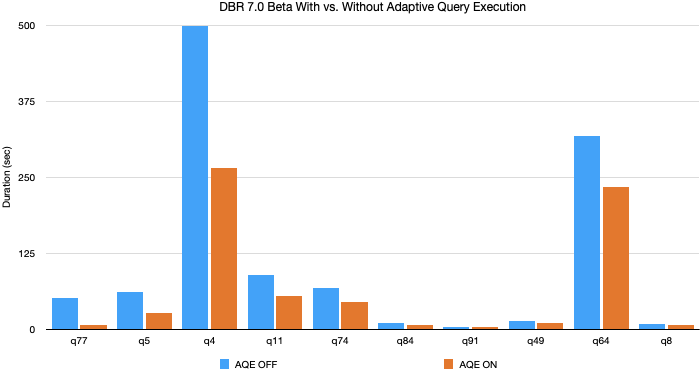
Die meisten dieser Verbesserungen stammen aus der dynamischen Partitionszusammenfassung und dem dynamischen Wechsel der Join-Strategie, da zufällig generierte TPC-DS-Daten keine Verzerrungen aufweisen. Dennoch haben wir in Produktions-Workloads, bei denen alle drei Funktionen von AQE genutzt werden, noch größere Verbesserungen gesehen.
AQE aktivieren
AQE kann durch Setzen der SQL-Konfiguration spark.sql.adaptive.enabled auf true (Standard false in Spark 3.0) aktiviert werden und gilt, wenn die Abfrage die folgenden Kriterien erfüllt:
- Es handelt sich nicht um eine Streaming-Abfrage
- Sie enthält mindestens einen Austausch (normalerweise bei Join-, Aggregat- oder Fensteroperatoren) oder eine Unterabfrage
Indem die Abfrageoptimierung weniger von statischen Statistiken abhängig gemacht wird, hat AQE einen der größten Schwierigkeiten der kostenbasierten Optimierung von Spark gelöst – das Gleichgewicht zwischen dem Aufwand für die Statistiksammlung und der Genauigkeit der Schätzung. Um die beste Schätzgenauigkeit und das beste Planungsergebnis zu erzielen, ist es in der Regel erforderlich, detaillierte, aktuelle Statistiken zu pflegen, und einige davon sind teuer zu sammeln, wie z. B. Spaltenhistogramme, die zur Verbesserung der Selektivitäts- und Kardinalitätsschätzung oder zur Erkennung von Datenverzerrungen verwendet werden können. AQE hat die Notwendigkeit solcher Statistiken sowie den manuellen Abstimmungsaufwand weitgehend eliminiert. Darüber hinaus hat AQE die SQL-Abfrageoptimierung widerstandsfähiger gegen das Vorhandensein beliebiger UDFs und unvorhersehbarer Datenänderungen gemacht, z. B. plötzliche Zunahme oder Abnahme der Datengröße, häufige und zufällige Datenverzerrungen usw. Es ist nicht mehr notwendig, Ihre Daten im Voraus zu „kennen“. AQE ermittelt die Daten und verbessert den Abfrageplan während der Ausführung der Abfrage, was die Abfrageleistung für schnellere Analysen und die Systemleistung erhöht.
Erfahren Sie mehr über Spark 3.0 in unserem Vorschau-Webinar. Probieren Sie AQE in Spark 3.0 noch heute kostenlos auf Databricks als Teil unserer Databricks Runtime 7.0 aus.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.