Durchsetzung von spaltenbasierter Verschlüsselung und Vermeidung von Datenredundanz mit PII
Verwendung von Fernet-Verschlüsselungsbibliotheken, UDFs und Databricks-Geheimnissen zur unaufdringlichen Sicherung von PII-Daten
von Keyuri Shah und Fred Kimball
Dies ist ein Gastbeitrag von Keyuri Shah, Lead Software Engineer, und Fred Kimball, Software Engineer, Northwestern Mutual.
Der Schutz von PII (personenbezogenen Daten) ist sehr wichtig, da die Anzahl der Datenpannen und Datensätze mit exponierten sensiblen Informationen täglich zunimmt. Um nicht das nächste Opfer zu werden und Benutzer vor Identitätsdiebstahl und Betrug zu schützen, müssen wir mehrere Ebenen der Daten- und Informationssicherheit integrieren.
Da wir die Databricks-Plattform nutzen, müssen wir sicherstellen, dass nur die richtigen Personen Zugriff auf sensible Informationen haben. Durch die Kombination von Fernet-Verschlüsselungsbibliotheken, benutzerdefinierten Funktionen (UDFs) und Databricks-Geheimnissen hat Northwestern Mutual einen Prozess entwickelt, um PII-Informationen zu verschlüsseln und nur denen die Entschlüsselung zu ermöglichen, die sie aus geschäftlichen Gründen benötigen, ohne dass zusätzliche Schritte für den Datenleser erforderlich sind.
Die Notwendigkeit des Schutzes von PII
Die Verwaltung einer beliebigen Menge von Kundendaten erfordert heutzutage fast immer den Schutz von PII. Dies stellt ein großes Risiko für Organisationen jeder Größe dar, da Fälle wie die Capital One-Datenpanne dazu führten, dass Millionen sensibler Kundendatensätze aufgrund eines einfachen Konfigurationsfehlers gestohlen wurden. Obwohl die Verschlüsselung des Speichergeräts und die Spaltenmaskierung auf Tabellenebene wirksame Sicherheitsmaßnahmen sind, stellt unbefugter interner Zugriff auf diese sensiblen Daten immer noch eine große Bedrohung dar. Daher benötigen wir eine Lösung, die normale Benutzer mit Datei- oder Tabellenzugriff daran hindert, sensible Informationen innerhalb von Databricks abzurufen.
Wir möchten jedoch auch, dass diejenigen, die sensible Informationen aus geschäftlichen Gründen lesen müssen, dies auch können. Wir möchten keinen Unterschied darin machen, wie jeder Benutzertyp die Tabelle liest. Sowohl normale als auch entschlüsselte Lesevorgänge sollten auf demselben Delta Lake-Objekt erfolgen, um die Abfragekonstruktion für die Datenanalyse und die Berichterstellung zu vereinfachen.
Erstellung des Prozesses zur Durchsetzung der spaltenbasierten Verschlüsselung
Angesichts dieser Sicherheitsanforderungen haben wir versucht, einen Prozess zu entwickeln, der sicher, unaufdringlich und einfach zu verwalten ist. Das folgende Diagramm bietet einen allgemeinen Überblick über die für diesen Prozess erforderlichen Komponenten
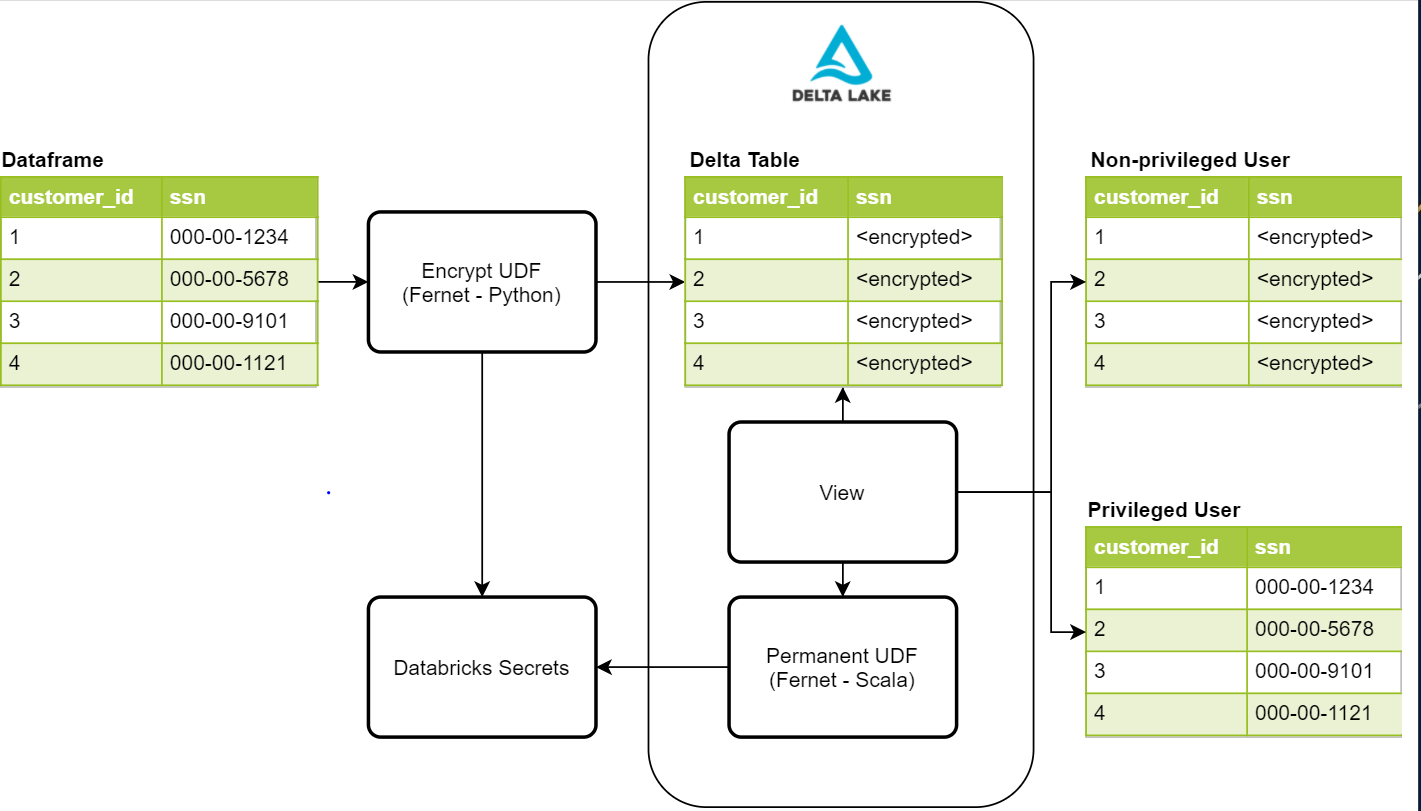
Schreiben von geschützten PII mit Fernet
Der erste Schritt in diesem Prozess ist der Schutz der Daten durch Verschlüsselung. Eine mögliche Lösung ist die Fernet Python-Bibliothek. Fernet verwendet symmetrische Verschlüsselung, die auf mehreren Standard-Kryptoprimitiven basiert. Diese Bibliothek wird innerhalb einer Verschlüsselungs-UDF verwendet, die es uns ermöglicht, jede gegebene Spalte in einem Dataframe zu verschlüsseln. Zum Speichern des Verschlüsselungsschlüssels verwenden wir Databricks Secrets mit Zugriffskontrollen, die nur unserem Datenaufnahmeverfahren den Zugriff darauf gestatten. Sobald die Daten in unsere Delta Lake-Tabellen geschrieben sind, sind PII-Spalten mit Werten wie Sozialversicherungsnummer, Telefonnummer, Kreditkartennummer und anderen Identifikatoren für einen unbefugten Benutzer unlesbar.
Lesen der geschützten Daten aus einer Ansicht mit benutzerdefinierter UDF
Sobald wir die sensiblen Daten geschrieben und geschützt haben, benötigen wir eine Möglichkeit für privilegierte Benutzer, die sensiblen Daten zu lesen. Als Erstes muss eine permanente UDF erstellt werden, die zur laufenden Hive-Instanz auf Databricks hinzugefügt wird. Damit eine UDF permanent ist, muss sie in Scala geschrieben sein. Glücklicherweise gibt es auch eine Scala-Implementierung von Fernet, die wir für unsere entschlüsselten Lesevorgänge nutzen können. Diese UDF greift auch auf dasselbe Geheimnis zu, das wir beim verschlüsselten Schreiben verwendet haben, um die Entschlüsselung durchzuführen, und wird in diesem Fall zur Spark-Konfiguration des Clusters hinzugefügt. Dies erfordert, dass wir Cluster-Zugriffskontrollen für privilegierte und nicht privilegierte Benutzer hinzufügen, um deren Zugriff auf den Schlüssel zu steuern. Sobald die UDF erstellt ist, können wir sie in unseren Ansichtsdefinitionen verwenden, damit privilegierte Benutzer die entschlüsselten Daten sehen können.
Derzeit haben wir zwei Ansichtsobjekte für einen einzelnen Datensatz, eines für privilegierte und eines für nicht privilegierte Benutzer. Die Ansicht für nicht privilegierte Benutzer hat die UDF nicht, sodass sie PII-Werte als verschlüsselte Werte sehen. Die andere Ansicht für privilegierte Benutzer hat die UDF, sodass sie die entschlüsselten Werte im Klartext für ihre geschäftlichen Anforderungen sehen können. Der Zugriff auf diese Ansichten wird ebenfalls durch die von Databricks bereitgestellten Tabellenzugriffskontrollen gesteuert.
In naher Zukunft möchten wir eine neue Databricks-Funktion namens dynamische Ansichtsfunktionen nutzen. Diese dynamischen Ansichtsfunktionen ermöglichen es uns, nur eine Ansicht zu verwenden und entweder die verschlüsselten oder entschlüsselten Werte einfach zurückzugeben, basierend auf der Databricks-Gruppe, der sie angehören. Dies reduziert die Anzahl der Objekte, die wir in unserem Delta Lake erstellen, und vereinfacht unsere Tabellenzugriffskontrollregeln.
Jede Implementierung ermöglicht es den Benutzern, ihre Entwicklung oder Analyse durchzuführen, ohne sich Gedanken darüber machen zu müssen, ob sie Werte aus der Ansicht entschlüsseln müssen oder nicht, und erlaubt nur den Zugriff auf diejenigen, die ihn aus geschäftlichen Gründen benötigen.
Vorteile dieser Methode der spaltenbasierten Verschlüsselung
Zusammenfassend lässt sich sagen, dass die Vorteile der Verwendung dieses Prozesses sind:
- Die Verschlüsselung kann mit vorhandenen Python- oder Scala-Bibliotheken durchgeführt werden
- Sensible PII-Daten haben eine zusätzliche Sicherheitsebene, wenn sie in Delta Lake gespeichert werden
- Dasselbe Delta Lake-Objekt wird von Benutzern mit allen Zugriffsebenen auf dieses Objekt verwendet
- Analysten werden nicht behindert, unabhängig davon, ob sie berechtigt sind, PII zu lesen
Ein Beispiel dafür, wie dies aussehen könnte, finden Sie im folgenden Notebook, das einige Anleitungen geben kann:
Zusätzliche Ressourcen:
Fernet-Bibliotheken
Permanente UDF erstellen
Dynamische Ansichtsfunktionen
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.