Wie Sie CDC mit dem Change Data Feed von Delta Lake vereinfachen können
von Surya Sai Turaga und John O'Dwyer
Probieren Sie dieses Notebook in Databricks aus
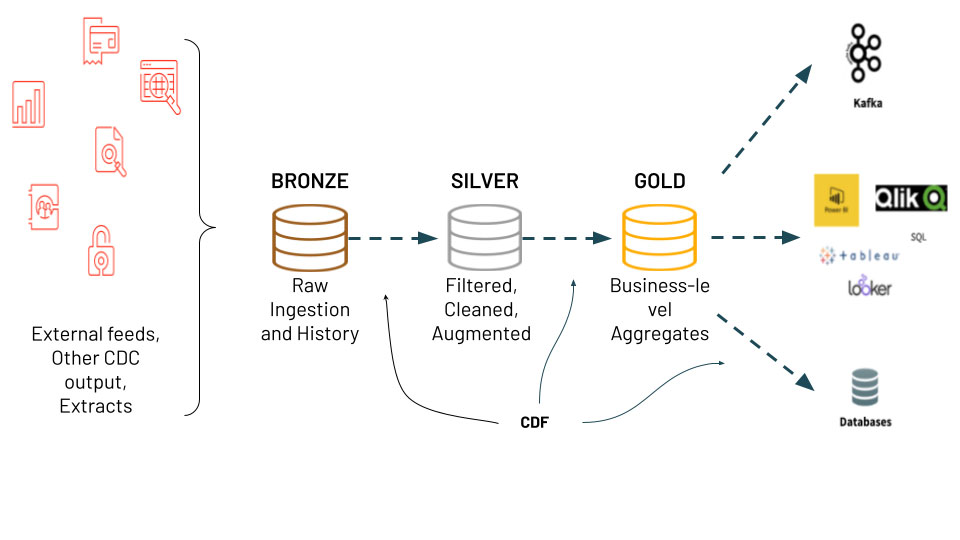
Change data capture (CDC) ist ein Anwendungsfall, den viele Kunden in Databricks implementieren – Sie können sich hier unseren vorherigen Deep Dive zu diesem Thema ansehen: hier. Typischerweise sehen wir CDC in einer Ingestion-to-Analytics-Architektur, die als Medallion-Architektur bezeichnet wird. Die Medallion-Architektur nimmt Rohdaten, die aus Quellsystemen stammen, und verfeinert die Daten durch Bronze-, Silber- und Goldtabellen. CDC und die Medallion-Architektur bieten den Benutzern mehrere Vorteile, da nur geänderte oder hinzugefügte Daten verarbeitet werden müssen. Darüber hinaus ermöglichen die verschiedenen Tabellen in der Architektur unterschiedlichen Personas, wie Data Scientists und BI-Analysten, die richtigen, aktuellen Daten für ihre Bedürfnisse zu verwenden. Wir freuen uns, die spannende neue Change Data Feed (CDF)-Funktion in Delta Lake ankündigen zu können, die diese Architektur einfacher zu implementieren macht und die MERGE-Operation sowie die Protokollversionierung von Delta Lake ermöglicht!
Erhalten Sie eine frühe Vorschau von O'Reillys neuem E-Book mit der Schritt-für-Schritt-Anleitung, die Sie benötigen, um mit Delta Lake zu beginnen.
Warum wird die CDF-Funktion benötigt?
Viele Kunden nutzen Databricks für CDC, da die Implementierung mit Delta Lake im Vergleich zu anderen Big-Data-Technologien einfacher ist. Selbst mit den richtigen Werkzeugen kann CDC jedoch immer noch eine Herausforderung darstellen. Wir haben CDF entwickelt, um die Codierung noch einfacher zu gestalten und die größten Schmerzpunkte rund um CDC zu adressieren, darunter:
- Qualitätskontrolle – Zeilenänderungen sind zwischen Versionen schwer zu ermitteln.
- Ineffizienz – Es kann ineffizient sein, nicht geänderte Zeilen zu berücksichtigen, da die Änderungen der aktuellen Version auf Dateiebene und nicht auf Zeilenebene erfolgen.
Hier erfahren Sie, wie die Implementierung von Change Data Feed (CDF) zur Lösung der oben genannten Probleme beiträgt:
- Einfachheit und Komfort – Verwendet ein gängiges, einfach zu bedienendes Muster zur Identifizierung von Änderungen, wodurch Ihr Code einfach, bequem und leicht verständlich wird.
- Effizienz – Die Möglichkeit, nur die Zeilen zu erhalten, die sich zwischen den Versionen geändert haben, macht den nachgelagerten Verbrauch von Merge-, Update- und Delete-Operationen äußerst effizient.
CDF erfasst Änderungen nur aus einer Delta-Tabelle und ist nach der Aktivierung nur zukunftsorientiert.
Change Data Feed in Aktion!
Tauchen wir ein in ein Beispiel für CDF für einen gängigen Anwendungsfall: Finanzprognosen. Das am Anfang dieses Blogs erwähnte Notebook erfasst Finanzdaten. Estimated Earnings Per Share (EPS) sind Finanzdaten von Analysten, die die vierteljährlichen Gewinne pro Aktie eines Unternehmens prognostizieren. Die Rohdaten können aus vielen verschiedenen Quellen und von mehreren Analysten für mehrere Aktien stammen.
Mit der CDF-Funktion werden die Daten einfach in die Bronze-Tabelle (Rohdatenerfassung) eingefügt, dann gefiltert, bereinigt und in der Silber-Tabelle angereichert und schließlich werden aggregierte Werte in der Gold-Tabelle basierend auf den geänderten Daten in der Silber-Tabelle berechnet.
Während diese Transformationen komplex werden können, ist die zeilenbasierte CDF-Funktion dankbarerweise einfach und effizient. Aber wie verwendet man sie? Lassen Sie uns eintauchen!
HINWEIS: Das Beispiel hier konzentriert sich auf die SQL-Version von CDF und auch auf eine bestimmte Art, die Operationen zu verwenden. Um Variationen zu bewerten, siehe die Dokumentation hier
Aktivieren von CDF für eine Delta Lake-Tabelle
Damit die CDF-Funktion für eine Tabelle verfügbar ist, müssen Sie die Funktion zuerst für diese Tabelle aktivieren. Unten sehen Sie ein Beispiel für die Aktivierung von CDF für die Bronze-Tabelle bei der Tabellenerstellung. Sie können CDF auch als Update für eine Tabelle aktivieren. Darüber hinaus können Sie CDF für einen Cluster für alle von diesem Cluster erstellten Tabellen aktivieren. Für diese Variationen siehe die Dokumentation hier.

Change Data Feed ist eine zukunftsorientierte Funktion. Sie erfasst Änderungen, sobald die Tabelleneigenschaft eingerichtet ist, und nicht früher.
Abfragen der Änderungsdaten
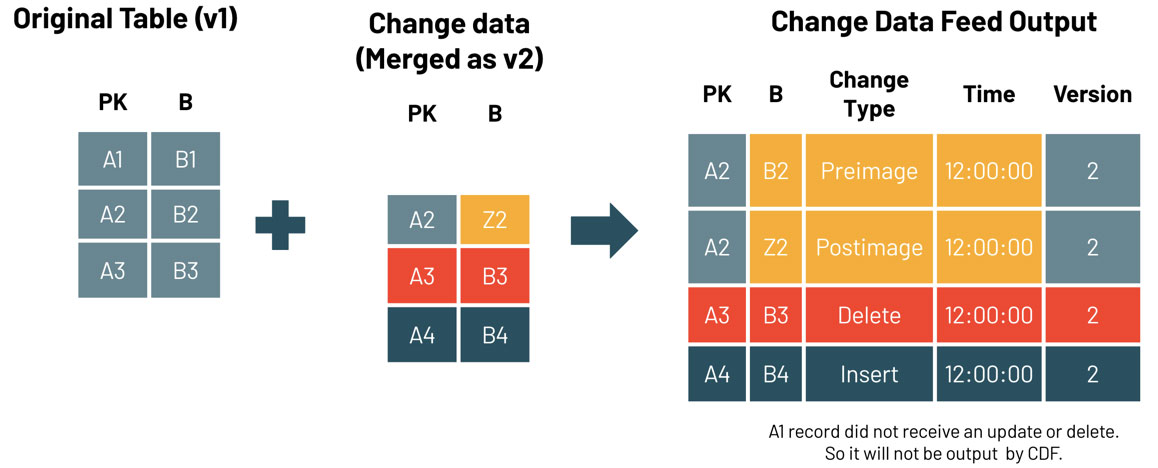
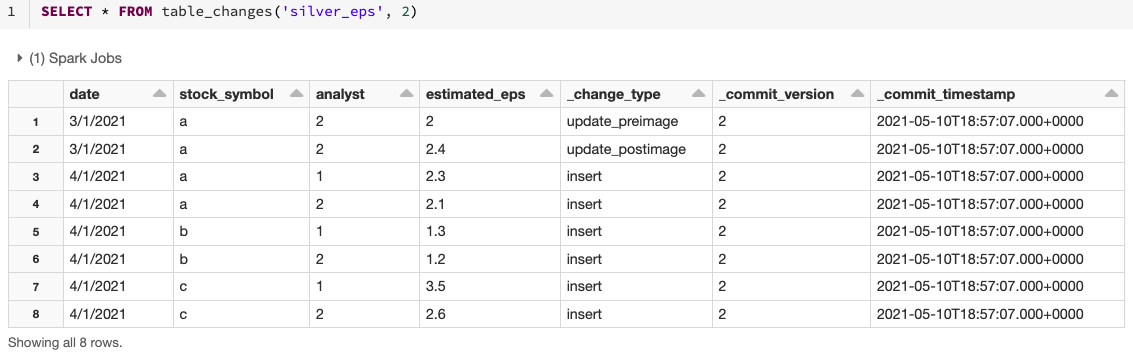
Verwenden Sie den Vorgang table_changes, um die Änderungsdaten abzufragen. Das folgende Beispiel enthält eingefügte Zeilen und zwei Zeilen, die das Vorher- und Nachher-Bild einer aktualisierten Zeile darstellen, damit wir die Unterschiede in den Änderungen bei Bedarf bewerten können. Es gibt auch einen delete-Änderungstyp, der für gelöschte Zeilen zurückgegeben wird.
Dieses Beispiel greift auf die geänderten Datensätze basierend auf der Startversion zu, aber Sie können die Versionen auch basierend auf der Endversion sowie auf Start- und Endzeitstempeln begrenzen, falls erforderlich. Dieses Beispiel konzentriert sich auf SQL, aber es gibt auch Möglichkeiten, auf diese Daten in Python, Scala, Java und R zuzugreifen. Für diese Variationen siehe die Dokumentation hier.
Verwenden von CDF-Zeilendaten in einer MERGE-Anweisung
Aggregierte MERGE-Anweisungen, wie das Mergen in die Gold-Tabelle, können von Natur aus komplex sein, aber die CDF-Funktion macht die Codierung dieser Anweisungen einfacher und effizienter.
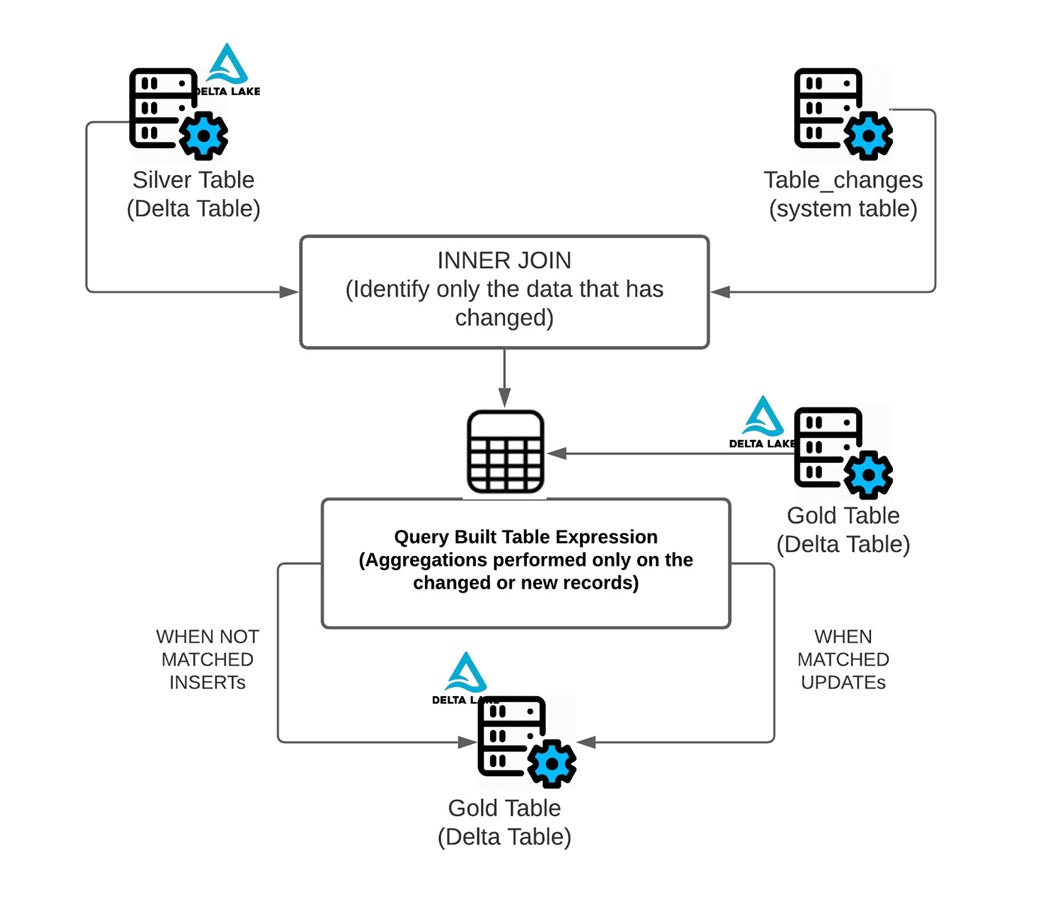
Wie im obigen Diagramm zu sehen ist, macht CDF es einfach, abzuleiten, welche Zeilen sich geändert haben, da es die erforderliche Aggregation nur auf den Daten durchführt, die sich geändert haben oder neu sind, unter Verwendung des table_changes-Vorgangs. Unten sehen Sie, wie Sie die geänderten Daten verwenden können, um zu bestimmen, welche Daten und Aktiensymbole sich geändert haben.
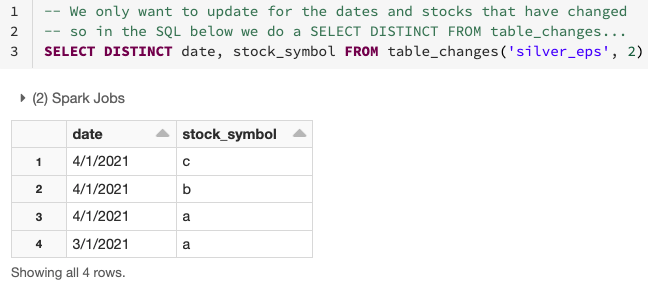
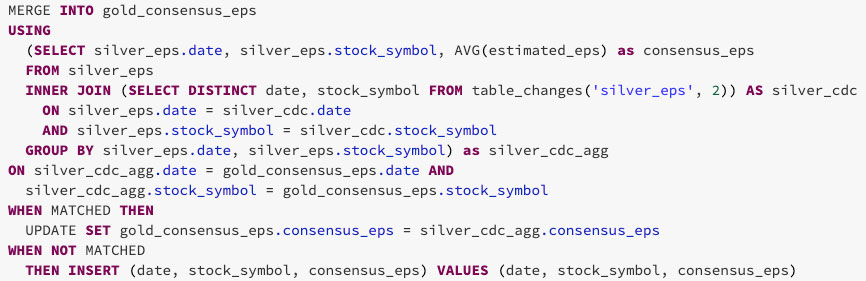
Wie unten gezeigt, können Sie die geänderten Daten aus der Silber-Tabelle verwenden, um nur die Daten in den Zeilen zu aggregieren, die in die Gold-Tabelle aktualisiert oder eingefügt werden müssen. Verwenden Sie dazu INNER JOIN mit table_changes('table_name','version')
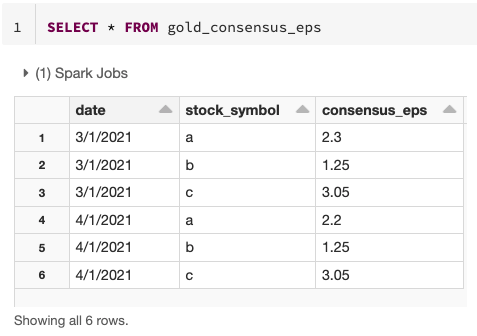
Das Endergebnis ist eine klare und prägnante Version einer Gold-Tabelle, die sich im Laufe der Zeit inkrementell ändern kann!
Typische Anwendungsfälle
Hier sind einige gängige Anwendungsfälle und Vorteile der neuen CDF-Funktion:
Silver & Gold-Tabellen
Verbessern Sie die Delta-Leistung, indem Sie nur Änderungen nach dem anfänglichen MERGE-Vergleich verarbeiten, um ETL/ELT-Vorgänge zu beschleunigen und zu vereinfachen.
Materialisierte Sichten
Erstellen Sie aktuelle, aggregierte Datenansichten für BI und Analysen, ohne die gesamten zugrunde liegenden Tabellen neu verarbeiten zu müssen. Aktualisieren Sie stattdessen nur die Stellen, an denen Änderungen vorgenommen wurden.
Änderungen übertragen
Senden Sie den Change Data Feed an nachgelagerte Systeme wie Kafka oder RDBMS, die ihn verwenden können, um inkrementell in späteren Phasen von Datenpipelines zu verarbeiten.
Audit-Trail-Tabelle
Die Erfassung von Change Data Feed-Ausgaben als Delta-Tabelle bietet eine dauerhafte Speicherung und effiziente Abfragefunktionen, um alle Änderungen im Laufe der Zeit anzuzeigen, einschließlich Löschungen und vorgenommener Aktualisierungen.
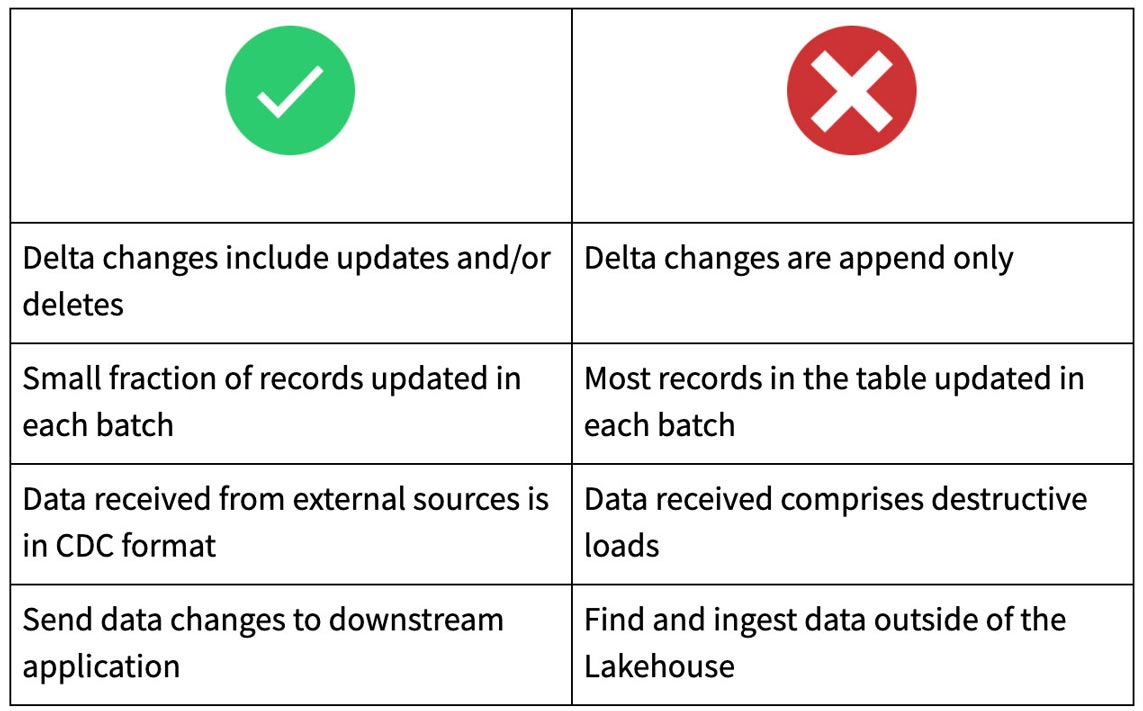
Wann Change Data Feed verwendet werden sollte
Fazit
Bei Databricks streben wir danach, das Unmögliche möglich und das Schwierige einfach zu machen. CDC, Log-Versioning und MERGE-Implementierung waren bis zur Erstellung von Delta Lake in großem Maßstab praktisch unmöglich. Jetzt machen wir es mit der spannenden Change Data Feed (CDF)-Funktion einfacher und effizienter!
Probieren Sie dieses Notebook in Databricks aus
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.