Einführung von Datenprofilen im Databricks Notebook
Vereinfachung der explorativen Datenanalyse
von Edward Gan, Moonsoo Lee und Austin Ford
Bevor ein Data Scientist einen Bericht über Analysen schreiben oder ein Machine-Learning-Modell (ML) trainieren kann, muss er die Struktur und den Inhalt seiner Daten verstehen. Diese explorative Datenanalyse ist iterativ, wobei jede Phase des Zyklus oft die gleichen grundlegenden Techniken beinhaltet: Visualisierung von Datenverteilungen und Berechnung von zusammenfassenden Statistiken wie Zeilenanzahl, Null-Anzahl, Mittelwert, Elementhäufigkeiten usw. Leider ist die manuelle Erstellung dieser Visualisierungen und Statistiken umständlich und fehleranfällig, insbesondere bei großen Datensätzen. Um diese Herausforderung zu bewältigen und die explorative Datenanalyse zu vereinfachen, führen wir Datenprofilierungsfunktionen im Databricks Notebook ein.
Daten im Notebook profilieren
Datenteams, die auf einem Cluster mit DBR 9.1 oder neuer arbeiten, haben zwei Möglichkeiten, Datenprofile im Notebook zu generieren: über die Benutzeroberfläche der Zellenausgabe und über die dbutils-Bibliothek. Beim Anzeigen des Inhalts eines DataFrames mit der Databricks display-Funktion (AWS|Azure|Google) oder der Ausgabe einer SQL-Abfrage sehen Benutzer einen „Datenprofil“-Tab rechts neben dem „Tabelle“-Tab in der Zellenausgabe. Ein Klick auf diesen Tab führt automatisch einen neuen Befehl aus, der ein Profil der Daten im DataFrame generiert. Das Profil enthält zusammenfassende Statistiken für numerische Spalten, Zeichenketten und Datumsangaben sowie Histogramme der Wertverteilungen für jede Spalte. Beachten Sie, dass dieser Befehl den gesamten Datensatz im DataFrame oder in den SQL-Abfrageergebnissen profiliert, nicht nur den im Tabellenausschnitt angezeigten Teil (der abgeschnitten sein kann).
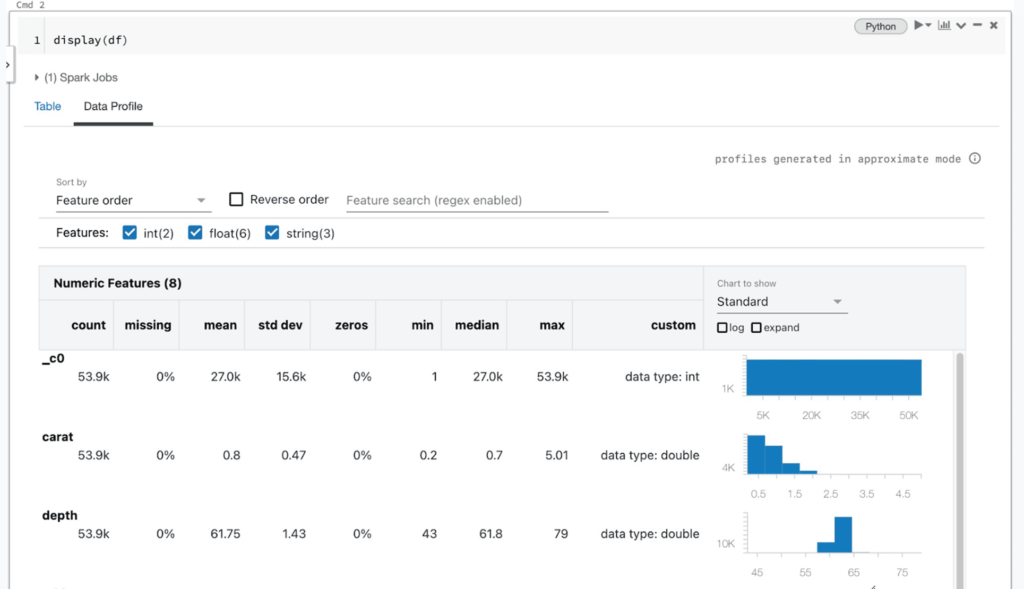
Unter der Haube gibt die Notebook-Benutzeroberfläche einen neuen Befehl zur Berechnung eines Datenprofils aus, der über eine automatisch generierte Apache Spark™-Abfrage für jeden Datensatz implementiert wird. Diese Funktionalität ist auch über die dbutils API in Python, Scala und R mit dem Befehl dbutils.data.summarize(df) verfügbar. Weitere Informationen finden Sie in der Dokumentation (AWS|Azure|Google).
Probieren Sie Datenprofile noch heute aus, wenn Sie DataFrames in Databricks Notebooks in der Vorschau anzeigen!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.