Vereinfachung von Change Data Capture mit Databricks Delta Live Tables
von Mojgan Mazouchi
Dieser Leitfaden zeigt Ihnen, wie Sie Change Data Capture (CDC) in Delta Live Tables Pipelines nutzen können, um neue Datensätze zu identifizieren und Änderungen am Datensatz in Ihrem Data Lake zu erfassen. Delta Live Tables Pipelines ermöglichen die Entwicklung skalierbarer, zuverlässiger und latenzarmer Datenpipelines, während Change Data Capture in Ihrem Data Lake mit minimalen Rechenressourcen und nahtloser Behandlung von out-of-order Daten durchgeführt wird.
Hintergrund zu Change Data Capture
Change Data Capture (CDC) ist ein Prozess, der inkrementelle Änderungen (Datenlöschungen, -einfügungen und -aktualisierungen) in Datenbanken identifiziert und erfasst, wie z. B. die Verfolgung von Kunden-, Bestell- oder Produktstatus für nahezu Echtzeit-Datenanwendungen. CDC liefert Echtzeit-Datenentwicklung, indem Daten kontinuierlich und inkrementell verarbeitet werden, sobald neue Ereignisse auftreten.
Da über 80 % der Organisationen bis 2025 Multi-Cloud-Strategien implementieren wollen, ist die Wahl des richtigen Ansatzes für Ihr Unternehmen, der eine nahtlose Echtzeit-Zentralisierung aller Datenänderungen in Ihrer ETL-Pipeline über mehrere Umgebungen hinweg ermöglicht, entscheidend.
Durch die Erfassung von CDC-Ereignissen können Databricks-Benutzer die Quelltabelle als Delta Table im Lakehouse neu materialisieren und darauf ihre Analysen ausführen, während sie gleichzeitig Daten mit externen Systemen kombinieren können. Der MERGE INTO-Befehl in Delta Lake auf Databricks ermöglicht es Kunden, Datensätze in ihren Data Lakes effizient einzufügen und zu löschen – Sie können sich hier eine frühere detaillierte Betrachtung des Themas ansehen: hier. Dies ist ein häufiger Anwendungsfall, bei dem viele Databricks-Kunden Delta Lakes nutzen, um ihre Data Lakes mit aktuellen Geschäftsdaten auf dem neuesten Stand zu halten.
Während Delta Lake eine vollständige Lösung für die Echtzeit-CDC-Synchronisation in einem Data Lake bietet, freuen wir uns, nun die Change Data Capture-Funktion in Delta Live Tables anzukündigen, die Ihre Architektur noch einfacher, effizienter und skalierbarer macht. DLT ermöglicht es Benutzern, CDC-Daten nahtlos über SQL und Python zu erfassen.
Frühere CDC-Lösungen mit Delta-Tabellen verwendeten die MERGE INTO-Operation, die eine manuelle Sortierung der Daten erforderte, um Fehler zu vermeiden, wenn mehrere Zeilen des Quelldatensatzes übereinstimmten, während versucht wurde, dieselben Zeilen der Ziel-Delta-Tabelle zu aktualisieren. Um out-of-order Daten zu verarbeiten, war ein zusätzlicher Schritt erforderlich, um die Quelltabelle mithilfe einer foreachBatch-Implementierung vorzuverarbeiten, um die Möglichkeit mehrerer Übereinstimmungen zu eliminieren und nur die letzte Änderung für jeden Schlüssel beizubehalten (siehe das Beispiel für Change Data Capture). Die neue APPLY CHANGES INTO-Operation in DLT-Pipelines verarbeitet out-of-order Daten automatisch und nahtlos, ohne dass eine manuelle Intervention durch Data Engineering erforderlich ist.
CDC mit Databricks Delta Live Tables
In diesem Blogbeitrag zeigen wir, wie der APPLY CHANGES INTO-Befehl in Delta Live Tables Pipelines für einen gängigen CDC-Anwendungsfall verwendet wird, bei dem die CDC-Daten aus einem externen System stammen. Es gibt eine Vielzahl von CDC-Tools wie Debezium, Fivetran, Qlik Replicate, Talend und StreamSets. Obwohl die spezifischen Implementierungen variieren, erfassen und protokollieren diese Tools im Allgemeinen die Historie von Datenänderungen in Protokollen; nachgelagerte Anwendungen verbrauchen diese CDC-Protokolle. In unserem Beispiel werden die Daten aus einem CDC-Tool wie Debezium, Fivetran usw. in Cloud-Objektspeicher geladen.
Wir haben Daten von verschiedenen CDC-Tools, die in einem Cloud-Objektspeicher oder einer Nachrichtenwarteschlange wie Apache Kafka landen. Typischerweise sehen wir CDC im Rahmen einer Ingestion in das, was wir als Medallion-Architektur bezeichnen. Eine Medallion-Architektur ist ein Datenentwurfsmuster, das zur logischen Organisation von Daten in einem Lakehouse verwendet wird, mit dem Ziel, die Struktur und Qualität von Daten inkrementell und fortschreitend zu verbessern, während sie durch jede Schicht der Architektur fließen. Delta Live Tables ermöglicht die nahtlose Anwendung von Änderungen aus CDC-Feeds auf Tabellen in Ihrem Lakehouse; die Kombination dieser Funktionalität mit der Medallion-Architektur ermöglicht es, inkrementelle Änderungen problemlos und in großem Umfang durch analytische Workloads fließen zu lassen. Die Verwendung von CDC zusammen mit der Medallion-Architektur bietet den Benutzern mehrere Vorteile, da nur geänderte oder hinzugefügte Daten verarbeitet werden müssen. Somit können Benutzer kostengünstig Gold-Tabellen mit den neuesten Geschäftsdaten auf dem neuesten Stand halten.
HINWEIS: Das Beispiel hier gilt sowohl für die SQL- als auch für die Python-Versionen von CDC und auch für eine spezifische Art der Verwendung der Operationen. Um Variationen zu bewerten, siehe die offizielle Dokumentation hier.
Voraussetzungen
Um das Beste aus diesem Leitfaden herauszuholen, sollten Sie mit Folgendem vertraut sein:
- SQL oder Python
- Delta Live Tables
- Entwicklung von ETL-Pipelines und/oder Arbeit mit Big-Data-Systemen
- Databricks interaktive Notebooks und Cluster
- Sie müssen Zugriff auf einen Databricks Workspace mit Berechtigungen zum Erstellen neuer Cluster, Ausführen von Jobs und Speichern von Daten an einem Speicherort im externen Cloud-Objektspeicher oder DBFS haben.
- Für die in diesem Blog erstellte Pipeline muss die Produktedition "Advanced" ausgewählt werden, die die Erzwingung von Datenqualitätsbeschränkungen unterstützt.
Der Datensatz
Hier verbrauchen wir realistisch aussehende CDC-Daten aus einer externen Datenbank. In dieser Pipeline verwenden wir die Faker-Bibliothek, um den Datensatz zu generieren, den ein CDC-Tool wie Debezium produzieren und für die anfängliche Ingestion in Databricks in den Cloud-Speicher bringen kann. Mit Auto Loader laden wir inkrementell Nachrichten aus dem Cloud-Objektspeicher und speichern sie in der Bronze-Tabelle, da sie die Rohnachrichten speichert. Die Bronze-Tabellen sind für die Datenaufnahme bestimmt und ermöglichen einen schnellen Zugriff auf eine einzige Quelle der Wahrheit. Als Nächstes führen wir APPLY CHANGES INTO von der bereinigten Bronze-Layer-Tabelle aus, um die Aktualisierungen an die Silver-Tabelle weiterzuleiten. Wenn Daten zu Silver-Tabellen fließen, werden sie im Allgemeinen verfeinert und optimiert ("just-enough"), um einem Unternehmen eine Sicht auf alle seine wichtigsten Geschäftseinheiten zu bieten. Siehe das Diagramm unten.
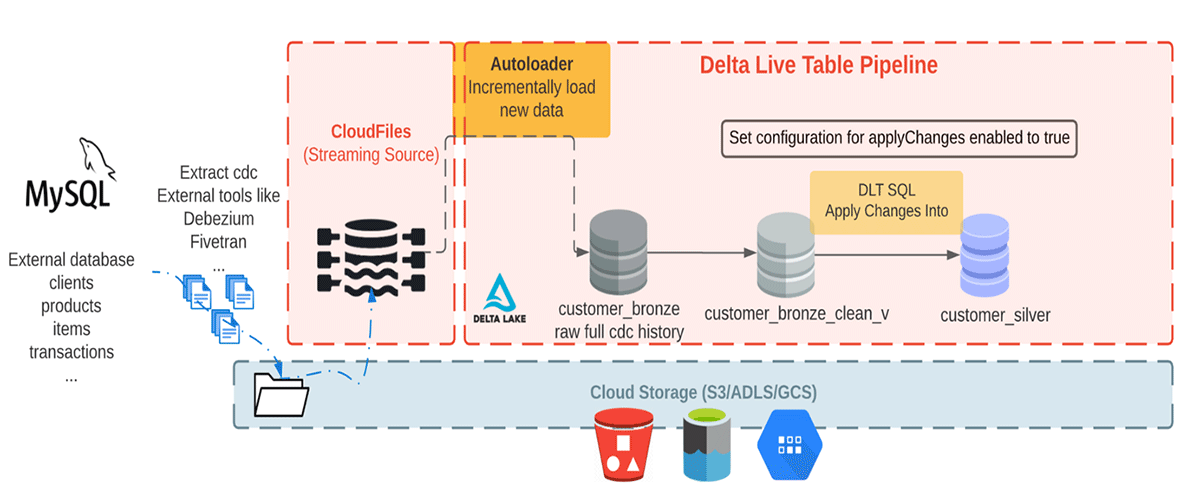
Dieser Blog konzentriert sich auf ein einfaches Beispiel, das eine JSON-Nachricht mit vier Feldern für Kundenname, E-Mail, Adresse und ID sowie die beiden Felder operation (die den Operationscode (DELETE, APPEND, UPDATE, CREATE) speichert und operation_date (die das Datum und die Uhrzeit für jede Operation speichert) zur Beschreibung der geänderten Daten benötigt.
Um einen Beispieldatensatz mit den oben genannten Feldern zu generieren, verwenden wir ein Python-Paket, das gefälschte Daten generiert: Faker. Das Notebook, das sich auf diesen Abschnitt der Datengenerierung bezieht, finden Sie hier. In diesem Notebook geben wir den Namen und den Speicherort an, an dem die generierten Daten gespeichert werden sollen. Wir verwenden die DBFS-Funktionalität von Databricks, siehe die DBFS-Dokumentation, um mehr darüber zu erfahren, wie es funktioniert. Dann verwenden wir eine PySpark User-Defined-Function, um den synthetischen Datensatz für jedes Feld zu generieren und die Daten zurück an den definierten Speicherort zu schreiben, auf den wir in anderen Notebooks zum Zugriff auf den synthetischen Datensatz verweisen werden.
Ingestion des Rohdatensatzes mit Auto Loader
Gemäß dem Medallion-Architekturparadigma enthält die Bronze-Schicht die Rohdatenqualität. In diesem Stadium können wir neue Daten inkrementell mit Autoloader von einem Speicherort im Cloud-Speicher lesen. Hier fügen wir den Pfad zu unserem generierten Datensatz zum Konfigurationsabschnitt unter den Pipeline-Einstellungen hinzu, was uns erlaubt, den Quellpfad als Variable zu laden. Unsere Konfiguration unter den Pipeline-Einstellungen sieht also wie folgt aus:
Dann laden wir diese Konfigurationseigenschaft in unsere Notebooks.
Werfen wir einen Blick auf die Bronze-Tabelle, die wir ingestieren werden: a. In SQL und b. Mit Python
a. SQL
b. Python
Die obigen Anweisungen verwenden den Auto Loader, um eine Streaming Live Table namens customer_bronze aus JSON-Dateien zu erstellen. Wenn Sie Autoloader in Delta Live Tables verwenden, müssen Sie keinen Speicherort für das Schema oder den Checkpoint angeben, da diese Speicherorte automatisch von Ihrer DLT-Pipeline verwaltet werden.
Auto Loader bietet eine Structured Streaming-Quelle namens cloud_files in SQL und cloudFiles in Python, die einen Cloud-Speicherpfad und ein Format als Parameter entgegennimmt.
Um Rechenkosten zu senken, empfehlen wir, die DLT-Pipeline im Triggered-Modus als Micro-Batch auszuführen, vorausgesetzt, Sie haben keine sehr niedrigen Latenzanforderungen.
Erwartungen und hochwertige Daten
Im nächsten Schritt zur Erstellung eines hochwertigen, vielfältigen und zugänglichen Datensatzes legen wir Qualitätsprüfungs-Erwartungskriterien mithilfe von Constraints fest. Derzeit kann eine Einschränkung entweder beibehalten, gelöscht oder fehlschlagen. Weitere Details finden Sie hier. Alle Einschränkungen werden protokolliert, um eine optimierte Qualitätsüberwachung zu ermöglichen.
a. SQL
b. Python
Verwenden der APPLY CHANGES INTO-Anweisung, um Änderungen an der nachgelagerten Zieltabelle weiterzugeben
Bevor die Apply Changes Into-Abfrage ausgeführt wird, müssen wir sicherstellen, dass eine Ziel-Streaming-Tabelle vorhanden ist, die die aktuellsten Daten enthalten soll. Wenn sie nicht vorhanden ist, müssen wir eine erstellen. Die folgenden Zellen sind Beispiele für die Erstellung einer Ziel-Streaming-Tabelle. Beachten Sie, dass zum Zeitpunkt der Veröffentlichung dieses Blogs die Anweisung zur Erstellung der Ziel-Streaming-Tabelle zusammen mit der Apply Changes Into-Abfrage erforderlich ist und beide in der Pipeline vorhanden sein müssen, andernfalls schlägt Ihre Tabellenerstellungsabfrage fehl.
a. SQL
b. Python
Nachdem wir nun eine Ziel-Streaming-Tabelle haben, können wir Änderungen mithilfe der Apply Changes Into-Abfrage an die nachgelagerte Zieltabelle weitergeben. Während CDC-Feeds INSERT-, UPDATE- und DELETE-Ereignisse enthalten, besteht das Standardverhalten von DLT darin, INSERT- und UPDATE-Ereignisse aus jedem Datensatz in der Quelldatentabelle anzuwenden, der mit den Primärschlüsseln übereinstimmt und nach einem Feld sortiert ist, das die Reihenfolge der Ereignisse identifiziert. Genauer gesagt wird jede Zeile in der vorhandenen Zieltabelle aktualisiert, die mit dem/den Primärschlüssel(n) übereinstimmt, oder eine neue Zeile eingefügt, wenn kein übereinstimmender Datensatz in der Ziel-Streaming-Tabelle vorhanden ist. Wir können APPLY AS DELETE WHEN in SQL oder das entsprechende Argument apply_as_deletes in Python verwenden, um DELETE-Ereignisse zu verarbeiten.
In diesem Beispiel haben wir „id“ als Primärschlüssel verwendet, der die Kunden eindeutig identifiziert und es CDC-Ereignissen ermöglicht, auf die identifizierten Kundendatensätze in der Ziel-Streaming-Tabelle angewendet zu werden. Da „operation_date“ die logische Reihenfolge der CDC-Ereignisse im Quelldatensatz beibehält, verwenden wir „SEQUENCE BY operation_date“ in SQL oder das entsprechende „sequence_by = col("operation_date")" in Python, um Änderungen zu verarbeiten, die außer der Reihe eintreffen. Beachten Sie, dass der Feldwert, den wir mit SEQUENCE BY (oder sequence_by) verwenden, bei allen Aktualisierungen desselben Schlüssels eindeutig sein sollte. In den meisten Fällen ist die Spalte „sequence by“ eine Spalte mit Zeitstempelinformationen.
Schließlich haben wir „COLUMNS * EXCEPT (operation, operation_date, _rescued_data)" in SQL oder das entsprechende „except_column_list"= ["operation", "operation_date", "_rescued_data"] in Python verwendet, um drei Spalten von „operation“, „operation_date“, „_rescued_data" aus der Ziel-Streaming-Tabelle auszuschließen. Standardmäßig sind alle Spalten in der Ziel-Streaming-Tabelle enthalten, wenn wir die Klausel „COLUMNS" nicht angeben.
a. SQL
b. Python
Eine vollständige Liste der verfügbaren Klauseln finden Sie hier.
Bitte beachten Sie, dass zum Zeitpunkt der Veröffentlichung dieses Blogs eine Tabelle, die aus dem Ziel einer APPLY CHANGES INTO-Abfrage oder apply_changes-Funktion liest, eine Live-Tabelle sein muss und keine Streaming-Live-Tabelle sein kann.
Ein SQL- und Python-Notebook stehen als Referenz für diesen Abschnitt zur Verfügung. Jetzt, da wir alle Zellen vorbereitet haben, erstellen wir eine Pipeline, um Daten aus dem Cloud-Objektspeicher zu erfassen. Öffnen Sie Jobs in einem neuen Tab oder Fenster in Ihrem Arbeitsbereich und wählen Sie „Delta Live Tables“.
Die Pipeline, die mit diesem Blog verknüpft ist, hat die folgenden DLT-Pipeline-Einstellungen:
- Wählen Sie „Pipeline erstellen“, um eine neue Pipeline zu erstellen
- Geben Sie einen Namen wie „Retail CDC Pipeline“ an
- Geben Sie die Notebook-Pfade an, die Sie zuvor erstellt haben, einen für den generierten Datensatz mit dem Faker-Paket und einen weiteren Pfad für die Erfassung der generierten Daten in DLT. Der zweite Notebook-Pfad kann je nach Ihrer Sprachwahl auf das in SQL oder Python geschriebene Notebook verweisen.
- Um auf die im ersten Notebook generierten Daten zuzugreifen, fügen Sie den Datensatzpfad in die Konfiguration ein. Hier haben wir die Daten unter "/tmp/demo/cdc_raw/customers" gespeichert, daher setzen wir "source" auf "/tmp/demo/cdc_raw/", um in unserem zweiten Notebook auf "source/customers" zu verweisen.
- Geben Sie das Ziel an (optional, bezieht sich auf die Zieldatenbank), wo Sie die resultierenden Tabellen aus Ihrer Pipeline abfragen können.
- Geben Sie den Speicherort in Ihrem Objektspeicher an (optional), um auf Ihre von DLT erstellten Datensätze und Metadatenprotokolle für Ihre Pipeline zuzugreifen.
- Setzen Sie den Pipeline-Modus auf Triggered. Im Triggered-Modus verarbeitet die DLT-Pipeline neue Daten in der Quelle auf einmal und beendet die Rechenressource automatisch, sobald die Verarbeitung abgeschlossen ist. Sie können zwischen Triggered- und Continuous-Modi wechseln, indem Sie die Pipeline-Einstellungen bearbeiten. Das Setzen von "continuous": false in der JSON-Datei entspricht dem Setzen der Pipeline auf den Triggered-Modus.
- Für diese Workload können Sie die automatische Skalierung unter Autopilot-Optionen deaktivieren und nur einen Worker-Cluster verwenden. Für Produktions-Workloads empfehlen wir, die automatische Skalierung zu aktivieren und die maximale Anzahl von Workern für die Clustergröße festzulegen.
- Wählen Sie "Start"
- Ihre Pipeline ist erstellt und läuft jetzt!
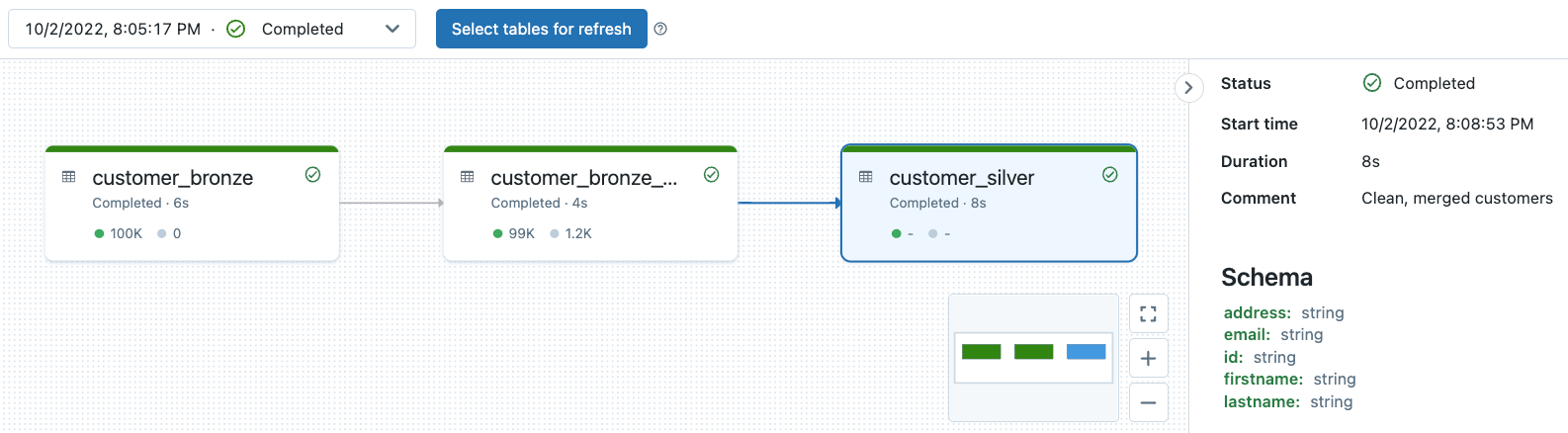
DLT Pipeline Lineage Observability und Data Quality Monitoring
Alle DLT-Pipeline-Protokolle werden im Speicherort der Pipeline gespeichert. Sie können Ihren Speicherort nur angeben, wenn Sie Ihre Pipeline erstellen. Beachten Sie, dass Sie den Speicherort nach der Erstellung der Pipeline nicht mehr ändern können.
Sie können sich unser vorheriges Deep Dive zu diesem Thema hier ansehen. Probieren Sie dieses Notebook aus, um Pipeline-Observability und Data Quality Monitoring am Beispiel der zu diesem Blog gehörenden DLT-Pipeline zu sehen.
Fazit
In diesem Blog haben wir gezeigt, wie wir es Benutzern ermöglicht haben, Change Data Capture (CDC) nahtlos und effizient in ihre Lakehouse-Plattform mit Delta Live Tables (DLT) zu implementieren. DLT bietet integrierte Qualitätskontrollen mit tiefer Einsicht in den Pipeline-Betrieb, Überwachung der Pipeline-Lineage, des Schemas und der Qualitätsprüfungen in jedem Schritt der Pipeline. DLT unterstützt automatische Fehlerbehandlung und erstklassige automatische Skalierungsfähigkeiten für Streaming-Workloads, was es Benutzern ermöglicht, qualitativ hochwertige Daten mit optimalen Ressourcen für ihre Workloads zu erhalten.
Data Engineers können jetzt CDC mit einer neuen deklarativen APPLY CHANGES INTO API mit DLT in SQL oder Python einfach implementieren. Diese neue Funktion ermöglicht es Ihren ETL-Pipelines, Änderungen einfach zu identifizieren und diese Änderungen über Zehntausende von Tabellen mit Low-Latency-Unterstützung anzuwenden.
Bitte sehen Sie sich dieses Webinar an, um zu erfahren, wie Delta Live Tables die Komplexität der Datentransformation und ETL vereinfacht, und sehen Sie sich unser Dokument Change data capture with Delta Live Tables, das offizielle GitHub an und folgen Sie den Schritten in diesem Video, um Ihre Pipeline zu erstellen!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.