Verwendung eines Wissensgraphen zur Bereitstellung einer semantischen Datenebene für Databricks
von Prasad Kona und Aaron Wallace
Dies ist ein gemeinsamer Beitrag von Databricks und Stardog. Wir danken Aaron Wallace, Sr. Product Manager bei Stardog, für seinen Beitrag.
Wissensgraphen sind allgegenwärtig geworden, auch wenn wir es nicht wissen. Wir erleben es jeden Tag, wenn wir bei Google suchen oder die Feeds unserer Social-Media-Konten verfolgen, die die Leute zeigen, die wir kennen, die Unternehmen, denen wir folgen, oder die Inhalte, die uns gefallen. Ebenso bieten Enterprise Knowledge Graphs eine Grundlage für die Strukturierung der Inhalte, Daten und Informationsbestände Ihres Unternehmens, indem sie Wissen extrahieren, Beziehungen herstellen und Wissen als Antworten, Empfehlungen und Erkenntnisse für jede datengesteuerte Anwendung bereitstellen – von Chatbots über Empfehlungs-Engines bis hin zur Verbesserung Ihres BI und Analytics.
In diesem Blog erfahren Sie, wie Databricks und Stardog die letzte Meile bei der Demokratisierung von Daten und Erkenntnissen überwinden. Databricks bietet eine Lakehouse-Plattform für Daten-, Analyse- und künstliche Intelligenz (KI)-Workloads auf einer Multi-Cloud-Plattform. Stardog bietet eine Wissensgraphen-Plattform, die komplexe Beziehungen zu breiten, nicht nur großen Daten modellieren kann, um Personen, Orte, Dinge und deren Beziehungen zu beschreiben. Die Databricks Lakehouse Platform bietet zusammen mit der Wissensgraphen-gestützten semantischen Schicht von Stardog Unternehmen eine Grundlage für eine Enterprise Data Fabric-Architektur, die es funktionsübergreifenden, unternehmensweiten oder organisationsübergreifenden Teams ermöglicht, komplexe Abfragen über Domänensilos hinweg zu stellen und zu beantworten.
Der wachsende Bedarf an einer Data Fabric Architektur
Schnelle Innovationen und Umwälzungen im Datenmanagement helfen Unternehmen, Werte aus Daten zu schöpfen, die sowohl innerhalb als auch außerhalb des Unternehmens verfügbar sind. Unternehmen, die über physische und digitale Grenzen hinweg agieren, finden neue Möglichkeiten, Kunden so zu bedienen, wie sie bedient werden möchten.
Diese Unternehmen haben alle relevanten Daten über die Datenlieferkette hinweg verbunden, um ein vollständiges und genaues Bild im Kontext ihrer Anwendungsfälle zu erstellen. Die meisten Branchen, die Daten organisationsübergreifend betreiben und teilen möchten, um Daten zu harmonisieren und den Datenaustausch zu ermöglichen, übernehmen offene Standards in Form von vorgeschriebenen Ontologien, von FIBO im Finanzdienstleistungsbereich bis hin zu D3FEND im Bereich Cybersicherheit. Diese Business-Ontologien (oder semantischen Modelle) spiegeln wider, wie wir über Daten mit Bedeutung denken, d. h. über „Dinge“ und nicht darüber, wie Daten strukturiert und gespeichert werden, d. h. über „Strings“, und ermöglichen den Austausch und die Wiederverwendung von Daten.
Die Idee einer semantischen Schicht ist nicht neu. Sie existiert seit über 30 Jahren und wurde oft von BI-Anbietern gefördert, die Unternehmen beim Aufbau von zweckspezifischen Dashboards unterstützen. Eine breite Akzeptanz wurde jedoch durch die eingebettete Natur dieser Schicht als Teil eines proprietären BI-Systems behindert. Diese Schicht ist oft zu starr und komplex und leidet unter den gleichen Einschränkungen wie ein physisches relationales Datenbanksystem, das Daten zur Optimierung seiner strukturierten Abfragesprache modelliert und nicht, wie Daten in der realen Welt zusammenhängen – viele zu viele. Eine Wissensgraphen-gestützte semantische Datenschicht, die zwischen Ihren Speicher- und Konsumschichten liegt, bietet den Klebstoff und Multiplikator, der alle Daten verbindet, um im Kontext des Business-Anwendungsfalls Mehrwert für Citizen Data Scientists und Analysten zu liefern, die andernfalls außerhalb einer Handvoll Spezialisten nicht an datenzentrierten Architekturen teilnehmen und zusammenarbeiten können.
Ermöglichen eines Anwendungsfalls rund um Versicherungen
Betrachten wir ein reales Beispiel eines Multi-Carrier-Versicherungsunternehmens, um zu veranschaulichen, wie Stardog und Databricks zusammenarbeiten. Wie die meisten großen Unternehmen haben viele Versicherungsunternehmen ähnliche Herausforderungen im Umgang mit Daten, wie z. B. die mangelnde breite Verfügbarkeit von Daten aus internen und externen Quellen für die Entscheidungsfindung durch kritische Stakeholder. Jeder, von der Risikobewertung im Underwriting über die Policenverwaltung bis hin zur Schadensregulierung und den Agenturen, kämpft damit, die richtigen Daten und Erkenntnisse für kritische Entscheidungen zu nutzen. Sie alle benötigen eine unternehmensweite Daten-Fabric, die die Elemente einer modernen Daten- und Analysearchitektur zusammenbringt, um Daten FAIR zu machen – Findable, Accessible, Interoperable und Reusable. Die meisten Unternehmen beginnen ihre Reise, indem sie alle Datenquellen in einen Data Lake bringen. Der Lakehouse-Ansatz von Databricks bietet Unternehmen eine hervorragende Grundlage für die Speicherung all ihrer Analyse-Daten und macht alle Daten für jeden im Unternehmen zugänglich. In dieser Datenschicht finden die gesamte Bereinigung, Transformation und Disambiguierung statt. Der nächste Schritt auf dieser Reise ist die Datenharmonisierung, die Verbindung von Daten basierend auf ihrer Bedeutung, um reichhaltigeren Kontext zu liefern. Eine semantische Schicht, die von einem Wissensgraphen bereitgestellt wird, verlagert den Fokus auf Datenanalyse und -verarbeitung und bietet ein vernetztes Geflecht von domänenübergreifenden Erkenntnissen für Underwriter, Risikoanalysten, Agenten und Kundendienstteams, um Risiken zu managen und ein außergewöhnliches Kundenerlebnis zu bieten.
Wir werden untersuchen, wie dies mit einem vereinfachten semantischen Modell als Ausgangspunkt funktionieren würde.
Einfaches Modellieren domänenspezifischer Entitäten und domänenübergreifender Beziehungen
Die visuelle Erstellung eines semantischen Datenmodells durch eine Whiteboard-ähnliche Erfahrung ist der erste Schritt zur Erstellung einer semantischen Datenschicht. Klicken Sie im Stardog Designer-Projekt einfach, um spezifische Klassen (oder Entitäten) zu erstellen, die für die Beantwortung Ihrer Geschäftsfragen entscheidend sind. Sobald eine Klasse erstellt ist, können Sie alle notwendigen Attribute und Datentypen hinzufügen, um diese neue Entität zu beschreiben. Das Verknüpfen von Klassen (oder Entitäten) ist einfach. Wenn eine Entität ausgewählt ist, klicken Sie einfach, um einen Link hinzuzufügen, und ziehen Sie den Punkt der neuen Beziehung, bis er an der anderen Entität einrastet. Geben Sie dieser neuen Beziehung einen Namen, der die Geschäftsbedeutung beschreibt (z. B. ein „Kunde“ „besitzt“ ein „Fahrzeug“).
Fügen Sie eine neue Klasse hinzu und verknüpfen Sie sie mit einer vorhandenen Klasse, um eine Beziehung zu erstellen
Metadaten aus der Databricks Lakehouse Platform zuordnen
Was ist ein Modell ohne Daten? Stardog-Benutzer können sich mit einer Vielzahl von strukturierten, semistrukturierten und unstrukturierten Datenquellen verbinden, indem sie Daten nach Bedarf persistieren oder virtualisieren oder eine Kombination davon. Im Designer ist es einfach, Daten aus vorhandenen Quellen wie Delta Lake zu verbinden, um Metadaten aus vom Benutzer angegebenen Tabellen zu verbinden. Dies ermöglicht den ersten Zugriff auf diese Daten �über die Virtualisierungsschicht, ohne sie in den Wissensgraphen zu verschieben oder zu kopieren. Die Virtualisierungsschicht übersetzt automatisch eingehende Abfragen von Stardog von seinem auf offenen Standards basierenden SPARQL in optimierte Push-Down-SQL-Abfragen in Databricks SQL.
Fügen Sie eine neue Datenquelle als Projektressource hinzu
Klicken Sie, um eine neue Projektressource hinzuzufügen, und wählen Sie aus einer der verfügbaren Verbindungen, z. B. Databricks. Diese Verbindung nutzt den neuen SQL-Endpunkt, der kürzlich von Databricks veröffentlicht wurde. Definieren Sie einen Geltungsbereich für die Daten und geben Sie zusätzliche Eigenschaften an. Verwenden Sie die Vorschau, um die Daten schnell zu überprüfen, bevor Sie sie Ihrem Projekt hinzufügen.
Zusätzliche Daten aus verschiedenen Quellen einbeziehen
Der Designer vereinfacht die Einbeziehung von Daten aus anderen Datenquellen und Dateien wie CSVs für Teams, die Ad-hoc-Datenanalysen durchführen möchten, indem Daten aus Delta mit diesen neuen Informationen kombiniert werden. Sobald sie als Ressource hinzugefügt wurden, fügen Sie einfach einen Link hinzu und ziehen Sie ihn per Drag & Drop auf eine Klasse, um die Daten zuzuordnen. Geben Sie der Zuordnung einen aussagekräftigen Namen, geben Sie eine Datenspalte für den Primärschlüssel, die Bezeichnung und alle anderen Datenspalten an, die den Attributen der Entität entsprechen.
Daten aus einer Projektressource einer Klasse zuordnen
Veröffentlichen Sie Ihre Arbeit
Innerhalb des Designers können Sie das Modell und die Daten dieses Projekts direkt auf Ihrem Stardog-Server veröffentlichen, um sie im Stardog Explorer zu verwenden. Der Designer ermöglicht es Ihnen auch, die Ausgabe des Wissensgraphen auf verschiedene Weise zu veröffentlichen und zu konsumieren. Sie können direkt in einen gezippten Ordner mit Dateien, einschließlich Ihres Modells und Ihrer Zuordnungen, in Ihr Versionskontrollsystem veröffentlichen.
Direkt auf eine Stardog-Datenbank veröffentlichen
Nachdem die Daten in Stardog veröffentlicht wurden, können Datenanalysten auch gängige BI-Tools wie Tableau verwenden, um über den BI/SQL-Endpunkt von Stardog eine Verbindung herzustellen und Daten über die semantische Schicht in einen Bericht oder ein Dashboard zu ziehen. Ein automatisch generiertes Schema in jedem SQL-kompatiblen Tool ermöglicht es Benutzern, SQL-Abfragen gegen den Knowledge Graph zu schreiben. Abfragen, die über die SQL-Schicht kommen, werden automatisch in SPARQL, die Abfragesprache des Knowledge Graphs, übersetzt und über die virtuelle Schicht mittels automatisch generierter, quelloptimierter Abfragen für die Berechnung an der Quelle, in diesem Fall Databricks über den Databricks SQL-Endpunkt, weitergeleitet. Dieselben Informationen können auch Databricks-Benutzern in einem Notebook über die Python-API von Stardog, pystardog, zur Verfügung gestellt werden. Sie können auch den virtuellen Graphen einbetten, um ihn direkt in Ihren Anwendungen über die GraphQL-API von Stardog zu verwenden. Die semantische Schicht über dem Lakehouse bietet eine einzige Umgebung für alle Arten von Benutzern und ihre bevorzugten Tools, wobei die Operationen durch einen konsistenten Datensatz unterstützt werden.
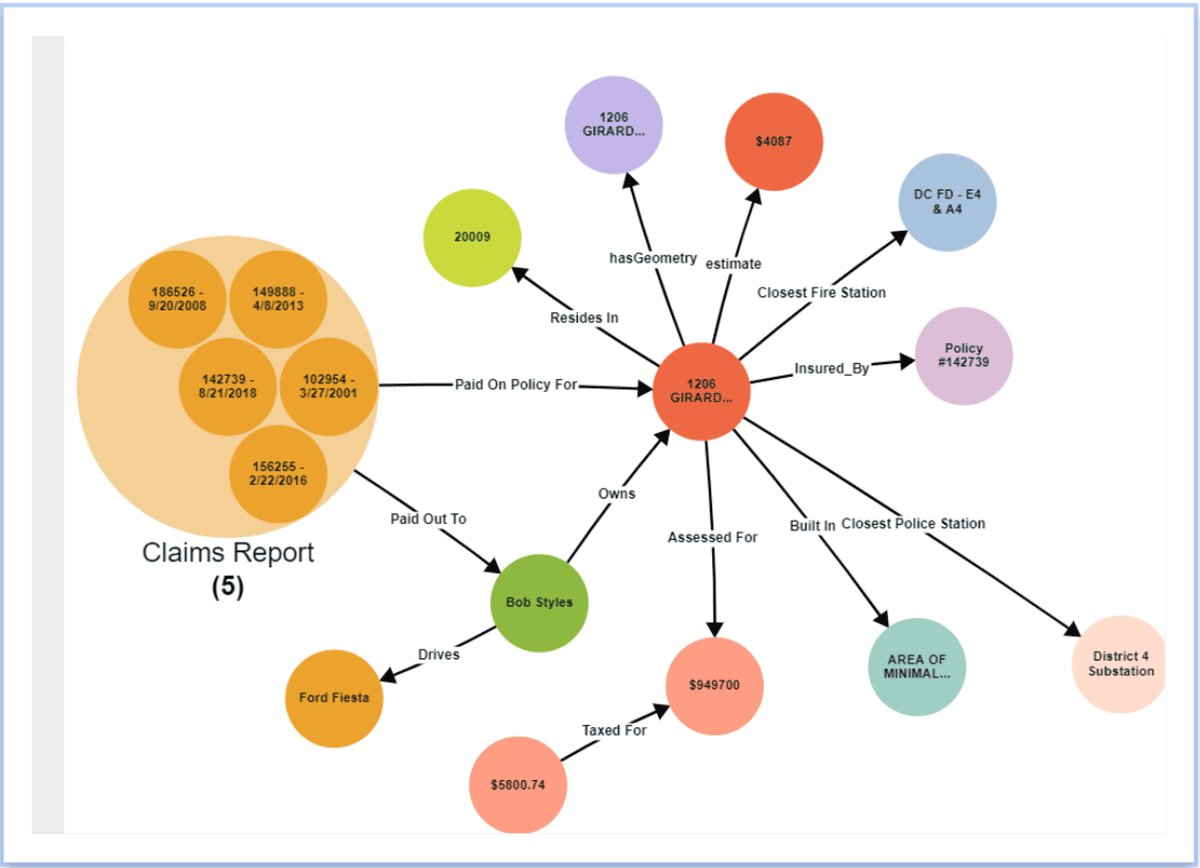
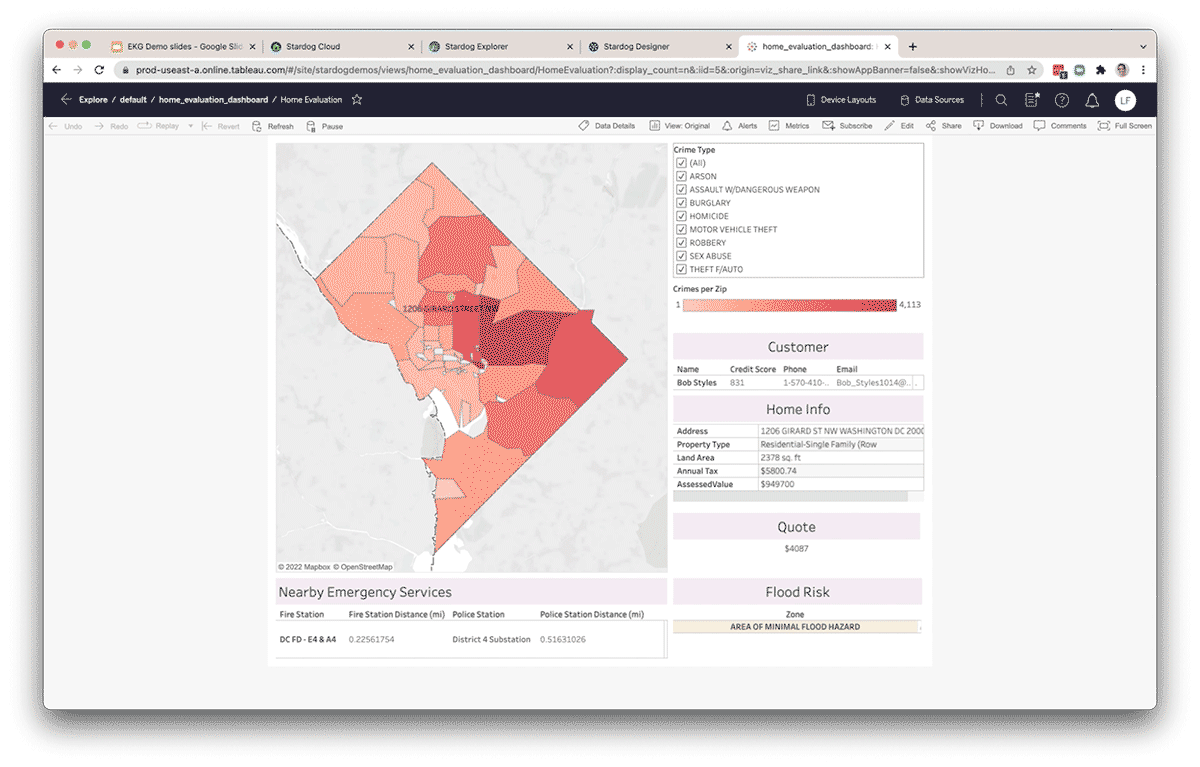
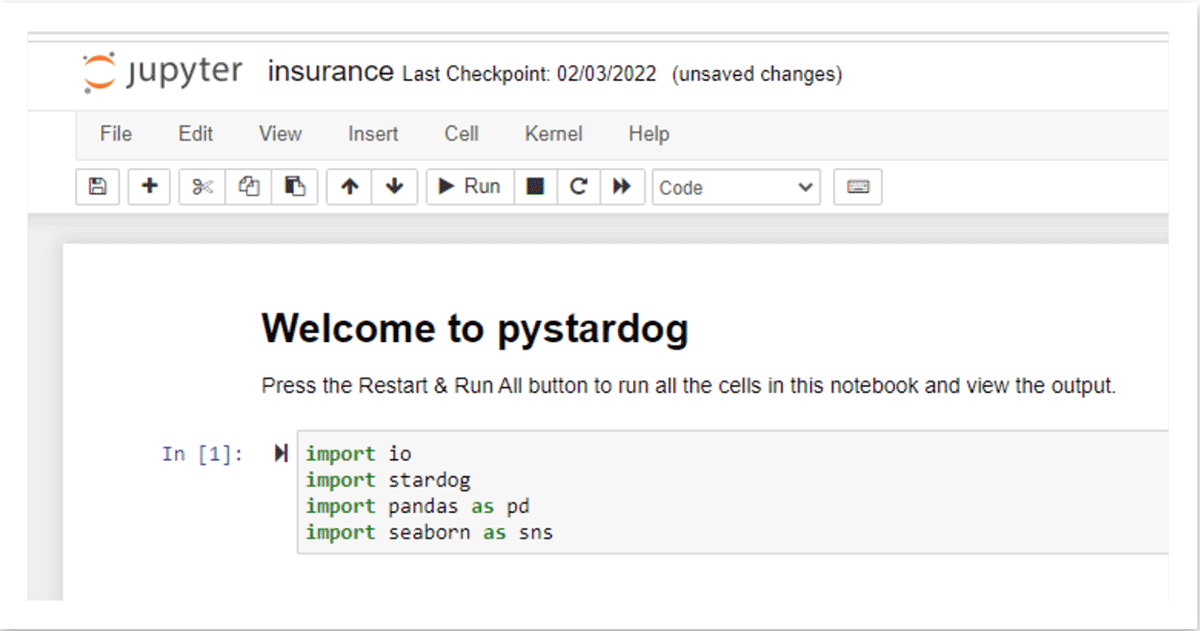
Produktivität steigern & neue Erkenntnisse gewinnen
Durch die Organisation von Daten in einem Knowledge Graph steigern Datenteams ihre Produktivität, indem sie die Zeit reduzieren, die sie mit dem Aufbereiten von Daten aus externen Quellen für die Ad-hoc-Datenanalyse verbringen. Daten außerhalb von Databricks können über die Virtualisierungsschicht von Stardog föderiert und mit Daten innerhalb von Databricks verbunden werden. Darüber hinaus können neue Beziehungen zwischen Entitäten abgeleitet werden, ohne sie explizit in den Knowledge Graph zu modellieren, indem Techniken wie statistische und/oder logische Inferenz verwendet werden. Da Databricks und Stardog nahtlos zusammenarbeiten, bietet die Kombination eine echte End-to-End-Erfahrung, die komplexe domänenübergreifende Abfragen und Analysen vereinfacht. Darüber hinaus wird die semantische Schicht zu einer lebendigen, teilbaren und einfach zu bedienenden Schicht als Teil einer unternehmensweiten Daten-Fabric-Grundlage, die unternehmensweites Wissen zur Unterstützung neuer datengesteuerter Initiativen bereitstellt.
Erste Schritte mit Databricks und Stardog
In diesem Blog haben wir einen Überblick darüber gegeben, wie Stardog eine Knowledge Graph-gestützte semantische Datenschicht auf der Databricks Lakehouse Platform ermöglicht. Für einen detaillierten Überblick sehen Sie sich unsere Deep-Dive-Demo an. Stardog liefert Wissensarbeitern kritische Einblicke „just-in-time“ über ein vernetztes Universum von Daten-Assets, um ihre Analysen zu beschleunigen und den Wert ihrer Data Lake-Investitionen zu steigern. Durch die gemeinsame Nutzung von Databricks und Stardog können Daten- und Analyseteams schnell eine Daten-Fabric aufbauen, die mit den wachsenden Anforderungen Ihrer Organisation Schritt hält.
Fordern Sie unten eine kostenlose Testversion an, um mit Databricks und Stardog zu beginnen:
https://www.databricks.com/try-databricks
https://cloud.stardog.com/get-started
https://www.stardog.com/learn-stardog/
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.