Implementierung der Notfallwiederherstellung für einen Databricks-Arbeitsbereich
von Ankit Shah und Lorin Dawson
Dieser Beitrag ist eine Fortsetzung von Disaster Recovery Overview, Strategies, and Assessment und Disaster Recovery Automation and Tooling for a Databricks Workspace.
Disaster Recovery (DR) bezeichnet eine Reihe von Richtlinien, Tools und Verfahren, die die Wiederherstellung oder Fortführung kritischer technologischer Infrastrukturen und Systeme nach einer natürlichen oder menschengemachten Katastrophe ermöglichen. Auch wenn Cloud-Anbieter wie AWS, Azure, Google Cloud und SaaS-Unternehmen Schutzmaßnahmen gegen Single Points of Failure (SPOF) implementieren, treten dennoch Ausfälle auf. Das Ausmaß der Störung und ihre Auswirkungen auf ein Unternehmen können variieren. Für Cloud-native Workloads ist ein klares DR-Muster entscheidend.
Databricks Disaster Recovery Setup
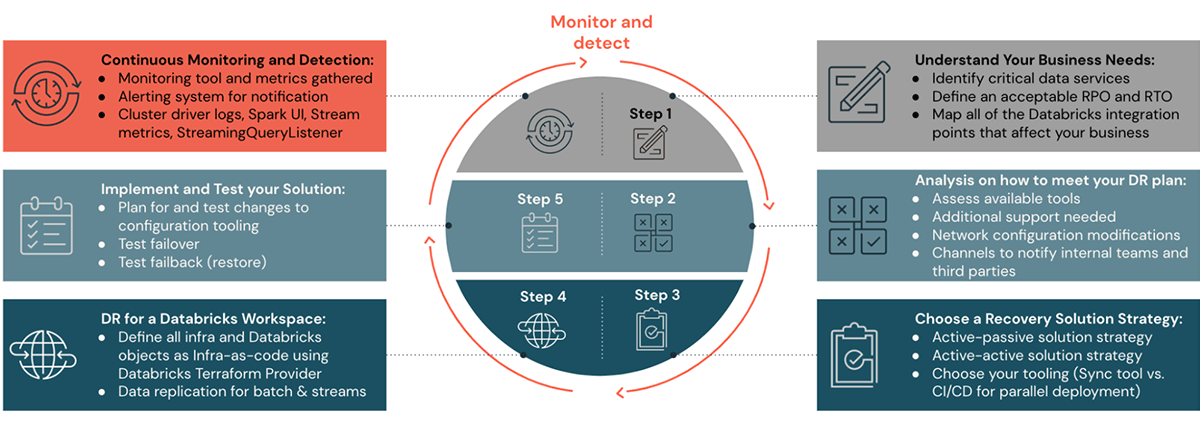
Bitte beachten Sie die vorherigen Blogbeiträge dieser DR-Blogserie, um die Schritte eins bis vier zu verstehen, wie man eine DR-Lösungsstrategie plant, einrichtet und automatisiert. In den Schritten fünf und sechs dieses Blogbeitrags werden wir uns ansehen, wie man ein DR-Setup überwacht, ausführt und validiert.
Disaster Recovery Lösung
Eine typische Databricks-Implementierung umfasst eine Reihe kritischer Assets wie Notebook-Quellcode, Abfragen, Job-Konfigurationen und Cluster, die reibungslos wiederhergestellt werden müssen, um minimale Unterbrechungen und fortlaufenden Service für die Endbenutzer zu gewährleisten.
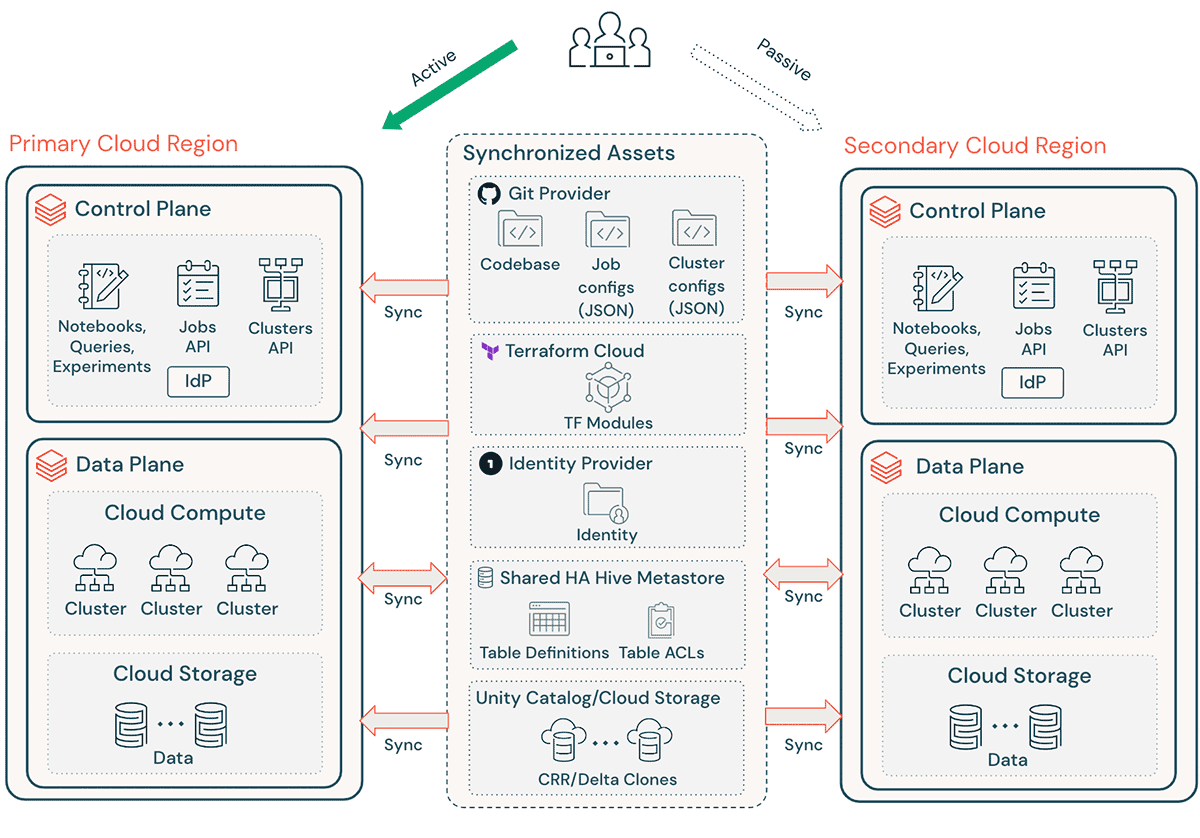
Wichtige DR-Überlegungen:
- Stellen Sie sicher, dass Ihre Architektur über Terraform (TF) replizierbar ist, sodass diese Umgebung woanders erstellt und neu erstellt werden kann.
- Verwenden Sie Databricks Repos (AWS | Azure | GCP), um Notebooks und Anwendungscode in unterstützten beliebigen Dateien zu synchronisieren (AWS | Azure | GCP).
- Verwenden Sie Terraform Cloud, um TF-Läufe (Plan und Apply) für Infrastruktur- und Anwendungspipelines auszulösen und dabei den Status zu verwalten.
- Replikieren Sie Daten aus Cloud-Speicherkonten wie Amazon S3, Azure ADLS und GCS in die DR-Region. Wenn Sie AWS verwenden, können Sie Daten auch mit S3 Multi-Region Access Points speichern, sodass die Daten mehrere S3-Buckets in verschiedenen AWS-Regionen umfassen.
- Databricks-Clusterdefinitionen können Informationen zu Verfügbarkeitszonen enthalten. Verwenden Sie das Cluster-Attribut "auto-az", wenn Sie Databricks auf AWS ausführen, um Probleme während eines regionalen Failovers zu vermeiden.
- Verwalten Sie Configuration Drift in der DR-Region. Stellen Sie sicher, dass Ihre Infrastruktur, Daten und Konfigurationen in der DR-Region wie benötigt vorhanden sind.
- Für Produktionscode und -assets verwenden Sie CI/CD-Tools, die Änderungen gleichzeitig in die Produktionssysteme beider Regionen pushen. Wenn Sie beispielsweise Code und Assets von Staging/Entwicklung nach Produktion pushen, macht ein CI/CD-System diese gleichzeitig in beiden Regionen verfügbar.
- Verwenden Sie Git, um TF-Dateien und die Infrastruktur-Codebasis, Job-Konfigurationen und Cluster-Konfigurationen zu synchronisieren.
- Regionsspezifische Konfigurationen müssen aktualisiert werden, bevor TF `apply` in einer sekundären Region ausgeführt wird.
Hinweis: Bestimmte Dienste wie Feature Store, MLflow-Pipelines, ML-Experiment-Tracking, Modellverwaltung und Modellbereitstellung können derzeit nicht als für Disaster Recovery geeignet betrachtet werden. Für Structured Streaming und Delta Live Tables ist eine Active-Active-Bereitstellung erforderlich, um Exactly-Once-Garantien aufrechtzuerhalten, aber die Pipeline wird eine eventual consistency zwischen den beiden Regionen aufweisen.
Weitere wichtige Überlegungen finden Sie in den vorherigen Beiträgen dieser Serie.
Überwachung und Erkennung
Es ist entscheidend, so früh wie möglich zu wissen, ob Ihre Workloads nicht in einem gesunden Zustand sind, damit Sie schnell eine Katastrophe erklären und einen Vorfall beheben können. Diese Reaktionszeit, gepaart mit angemessenen Informationen, ist entscheidend für die Erreichung aggressiver Wiederherstellungsziele. Es ist wichtig, Vorfallerkennung, Benachrichtigung, Eskalation, Entdeckung und Erklärung in Ihre Planung und Ziele einzubeziehen, um realistische und erreichbare Ziele zu formulieren.
Service-Status-Benachrichtigungen
Die Databricks Statusseite bietet einen Überblick über alle Kern-Databricks-Dienste für die Control Plane. Sie können den Status eines bestimmten Dienstes einfach auf der Statusseite einsehen. Optional können Sie sich auch für Statusaktualisierungen einzelner Dienstkomponenten anmelden, die eine Benachrichtigung senden, sobald sich der von Ihnen abonnierte Status ändert.
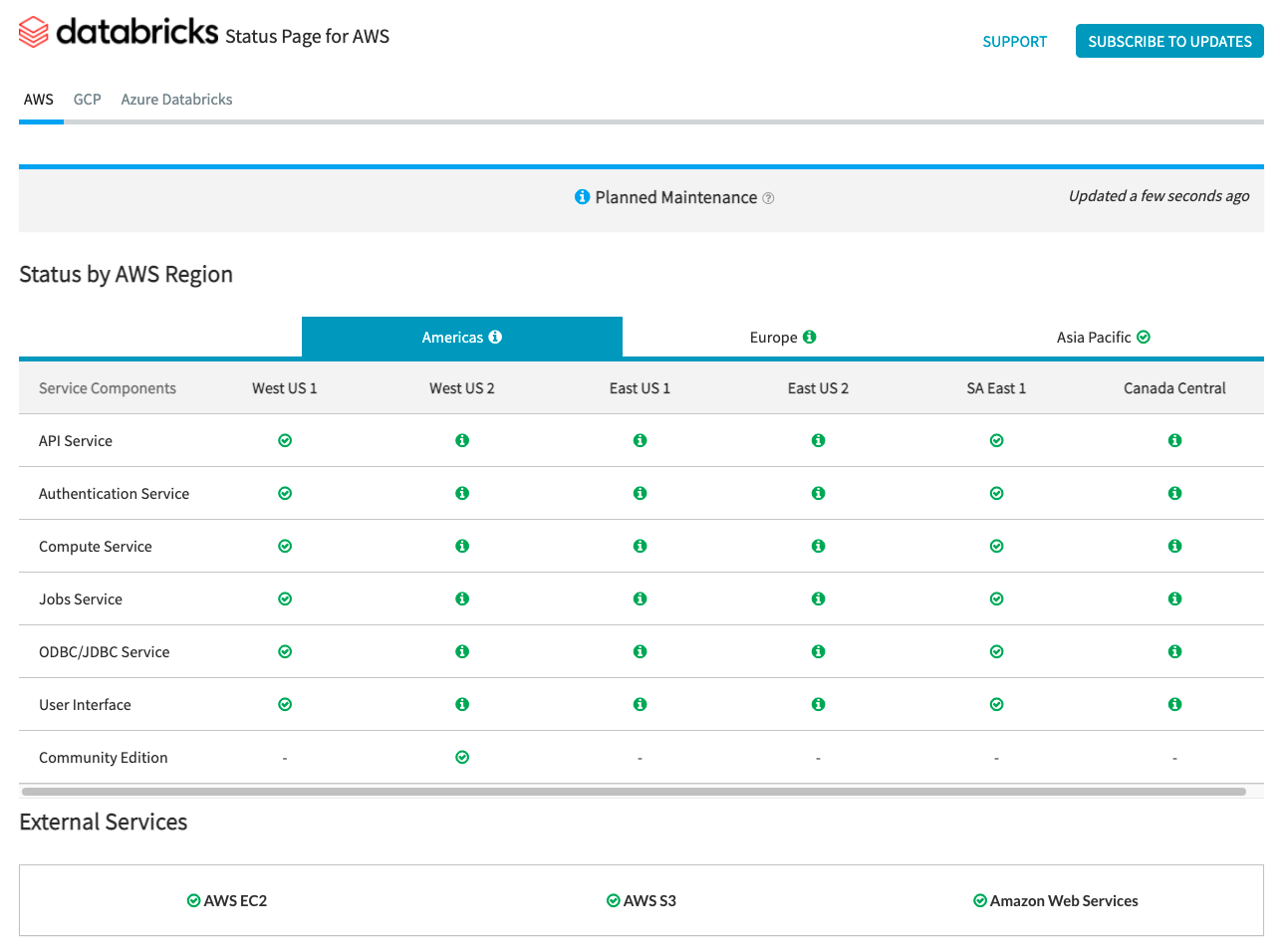
Für Statusprüfungen bezüglich der Data Plane sollten das AWS Health Dashboard, die Azure Statusseite und die GCP Service Health Page zur Überwachung verwendet werden.
AWS und Azure bieten API-Endpunkte, die Tools zur Aufnahme und Benachrichtigung über Statusprüfungen verwenden können.
Infrastruktur-Überwachung und Alarmierung
Die Verwendung eines Tools zum Sammeln und Analysieren von Infrastrukturdaten ermöglicht es Teams, die Leistung im Laufe der Zeit zu verfolgen. Dies befähigt Teams proaktiv, Ausfallzeiten und Serviceverschlechterungen insgesamt zu minimieren. Darüber hinaus etabliert die Überwachung über die Zeit eine Basislinie für Spitzenleistungen, die als Referenz für Optimierungen und Alarmierungen benötigt wird.
Im Kontext von DR kann ein Unternehmen möglicherweise nicht auf Benachrichtigungen von seinen Dienstanbietern warten. Selbst wenn die RTO/RPO-Anforderungen es zulassen, auf eine Benachrichtigung des Dienstanbieters zu warten, wird die Benachrichtigung des Support-Teams des Anbieters über eine Leistungsminderung im Voraus eine frühere Kommunikationslinie eröffnen.
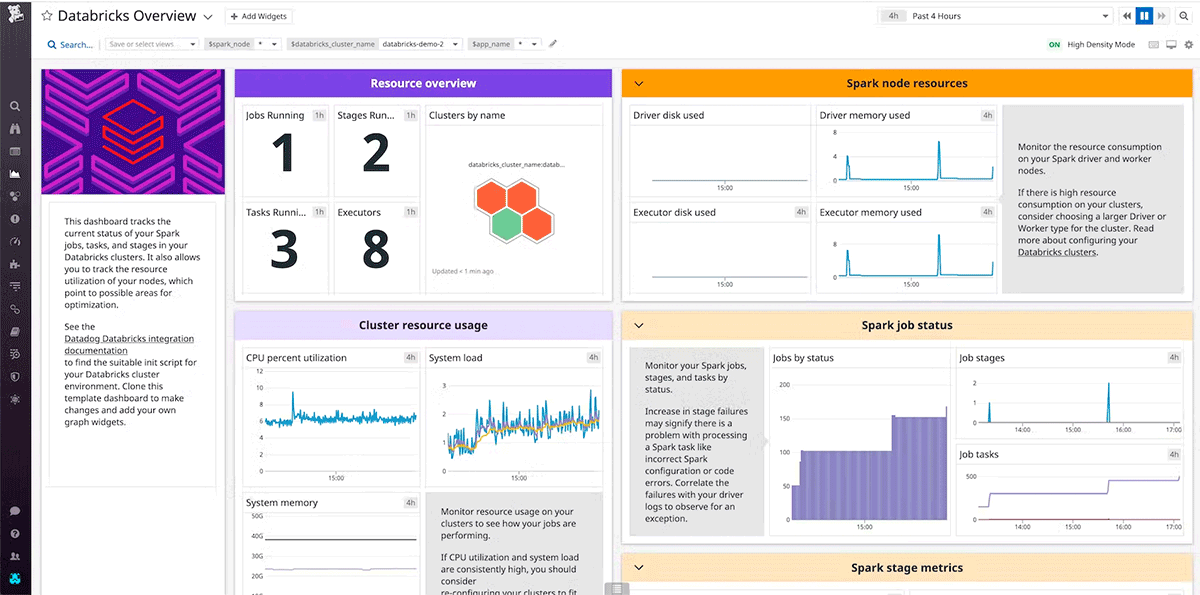
Sowohl DataDog als auch Dynatrace sind beliebte Überwachungstools, die Integrationen und Agenten für AWS, Azure, GCP und Databricks-Cluster bieten.
Health Checks
Für die strengsten RTO-Anforderungen können Sie ein automatisiertes Failover basierend auf Health Checks von Databricks-Diensten und anderen Diensten implementieren, mit denen die Workload direkt in der Data Plane interagiert, z. B. Objektspeicher und VM-Dienste von Cloud-Anbietern.
Entwerfen Sie Health Checks, die die Benutzererfahrung widerspiegeln und auf Key Performance Indicators (KPIs) basieren. Oberflächliche Heartbeat-Checks können bewerten, ob das System betriebsbereit ist, d. h. ob der Cluster läuft. Tiefgreifende Health Checks, wie Systemmetriken von CPU, Festplattenauslastung einzelner Knoten und Spark-Metriken über jede aktive Phase oder jeden zwischengespeicherten Partition, gehen über oberflächliche Heartbeat-Checks hinaus, um eine signifikante Leistungsverschlechterung festzustellen. Verwenden Sie tiefgreifende Health Checks, die auf mehreren Signalen basieren, entsprechend der Funktionalität und der Basisleistung der Workload.
Seien Sie vorsichtig, wenn Sie die Entscheidung zum Failover mithilfe von Health Checks vollständig automatisieren. Wenn False Positives auftreten oder ein Alarm ausgelöst wird, das Unternehmen jedoch die Auswirkungen abfedern kann, ist kein Failover erforderlich. Ein falsches Failover birgt Risiken für die Verfügbarkeit und Datenkorruption und ist zeitaufwändig. Es wird empfohlen, einen Menschen einzubeziehen, z. B. einen Bereitschafts-Incident-Manager, der die Entscheidung trifft, wenn ein Alarm ausgelöst wird. Ein unnötiges Failover kann katastrophal sein, und die zusätzliche Überprüfung hilft festzustellen, ob das Failover erforderlich ist.
Ausführung einer DR-Lösung
Auf hoher Ebene gibt es zwei Ausführungsszenarien für eine Disaster-Recovery-Lösung. Im ersten Szenario ist der DR-Standort temporär. Sobald der Dienst am primären Standort wiederhergestellt ist, muss die Lösung ein Failover vom DR-Standort zum permanenten primären Standort orchestrieren. Die Erstellung neuer Artefakte sollte eingeschränkt werden, während der DR-Standort aktiv ist, da er temporär ist und das Failback in diesem Szenario erschwert. Umgekehrt wird im zweiten Szenario der DR-Standort zum neuen primären Standort befördert, sodass Benutzer schneller wieder arbeiten können, da sie nicht auf die Wiederherstellung der Dienste warten müssen. Darüber hinaus erfordert dieses Szenario kein Failback, aber der ehemalige primäre Standort muss als neuer DR-Standort vorbereitet werden.
In beiden Szenarien sollte jede Region im Geltungsbereich der DR-Lösung alle erforderlichen Dienste unterstützen, und es muss ein Prozess vorhanden sein, der den Ziel-Workspace auf gute Betriebsbereitschaft überprüft, als Sicherheitsmaßnahme. Die Validierung kann simulierte Authentifizierung, automatisierte Abfragen, API-Aufrufe und ACL-Prüfungen umfassen.
Failover
Beim Auslösen eines Failovers zum DR-Standort kann die Lösung nicht davon ausgehen, dass das System ordnungsgemäß heruntergefahren werden kann. Die Lösung sollte versuchen, laufende Dienste am primären Standort herunterzufahren, den Shutdown-Status für jeden Dienst aufzuzeichnen und dann zu versuchen, Dienste ohne den entsprechenden Status in einem definierten Zeitintervall herunterzufahren. Dies reduziert das Risiko, dass Daten gleichzeitig im primären und im DR-Standort verarbeitet werden, minimiert Datenkorruption und erleichtert den Failback-Prozess, sobald die Dienste wiederhergestellt sind.
Die wichtigsten Schritte zur Aktivierung des DR-Standorts sind:
- Führen Sie einen Shutdown-Prozess am primären Standort aus, um Pools, Cluster und geplante Aufträge in der primären Region zu deaktivieren, damit die primäre Region keine neuen Daten verarbeitet, falls der ausgefallene Dienst wieder online geht.
- Stellen Sie sicher, dass die Infrastruktur und die Konfigurationen des DR-Standorts auf dem neuesten Stand sind.
- Überprüfen Sie das Datum der zuletzt synchronisierten Daten. Siehe Branchenterminologie für Disaster Recovery. Die Details dieses Schritts variieren je nachdem, wie Sie Daten synchronisieren und welche individuellen Geschäftsanforderungen Sie haben.
- Stabilisieren Sie Ihre Datenquellen und stellen Sie sicher, dass alle verfügbar sind. Beziehen Sie alle kritischen externen Datenquellen ein, wie z. B. Objektspeicher, Datenbanken, Pub/Sub-Systeme usw.
- Informieren Sie die Plattformbenutzer.
- Starten Sie relevante Pools (oder erhöhen Sie die min_idle_instances auf relevante Zahlen).
- Starten Sie relevante Cluster, Aufträge und SQL Warehouses (falls nicht beendet).
- Ändern Sie die gleichzeitige Ausführung für Aufträge und führen Sie relevante Aufträge aus. Dies können einmalige oder periodische Ausführungen sein.
- Aktivieren Sie Auftragspläne.
- Aktualisieren Sie für jedes externe Tool, das eine URL oder einen Domainnamen für Ihren Databricks-Workspace verwendet, die Konfigurationen, um die neue Steuerungsebene zu berücksichtigen. Aktualisieren Sie beispielsweise URLs für REST-APIs und JDBC/ODBC-Verbindungen. Die kundenorientierte URL der Databricks-Webanwendung ändert sich, wenn sich die Steuerungsebene ändert. Informieren Sie daher Ihre Organisationsbenutzer über die neue URL.
Failback
Die Rückkehr zum primären Standort während des Failbacks ist einfacher zu steuern und kann in einem Wartungsfenster erfolgen. Das Failback folgt einem sehr ähnlichen Plan wie das Failover, mit vier wesentlichen Ausnahmen:
- Die Zielregion ist die primäre Region.
- Da das Failback ein kontrollierter Prozess ist, ist das Herunterfahren eine einmalige Aktivität, die keine Statusprüfungen erfordert, um Dienste herunterzufahren, sobald sie wieder online gehen.
- Der DR-Standort muss bei Bedarf für zukünftige Failover zurückgesetzt werden.
- Alle gewonnenen Erkenntnisse sollten in die DR-Lösung integriert und für zukünftige Katastrophenereignisse getestet werden.
Fazit
Testen Sie Ihre Disaster-Recovery-Einrichtung regelmäßig unter realen Bedingungen, um sicherzustellen, dass sie ordnungsgemäß funktioniert. Es hat wenig Sinn, eine Disaster-Recovery-Lösung zu unterhalten, die nicht verwendet werden kann, wenn sie benötigt wird. Einige Organisationen testen ihre DR-Infrastruktur, indem sie alle paar Monate ein Failover und Failback zwischen Regionen durchführen. Regelmäßige Failover zum DR-Standort testen Ihre Annahmen und Prozesse, um sicherzustellen, dass sie die Wiederherstellungsanforderungen in Bezug auf RPO und RTO erfüllen. Dies stellt auch sicher, dass die Notfallrichtlinien und -verfahren Ihrer Organisation auf dem neuesten Stand sind. Testen Sie alle organisatorischen Änderungen, die für Ihre Prozesse und Konfigurationen im Allgemeinen erforderlich sind. Ihr Disaster-Recovery-Plan hat Auswirkungen auf Ihre Deployment-Pipeline. Stellen Sie daher sicher, dass Ihr Team weiß, was synchron gehalten werden muss.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.