Visuelle Datenmodellierung mit erwin Data Modeler von Quest auf der Databricks Lakehouse Platform
Datenmodellierungs- mit erwin auf Databricks
von Vani Mishra, Abhishek Dey, Leo Mao, Soham Bhatt und Pradeep Anandapu
Dies ist ein gemeinsamer Beitrag von Databricks und Quest Software. Wir danken Vani Mishra, Director of Product Management bei Quest Software, für ihre Beiträge.
Datenmodellierung mit erwin Data Modeler
Wenn Kunden ihre Datenlandschaft auf Databricks modernisieren, konsolidieren sie verschiedene Data Marts und EDWs in einer einzigen skalierbaren Lakehouse-Architektur, die ETL, BI und KI unterstützt. Normalerweise beginnt einer der ersten Schritte dieser Reise damit, die vorhandenen Datenmodelle der Altsysteme zu erfassen, zu rationalisieren und in die Bronze-, Silber- und Gold-Zonen der Databricks Lakehouse-Architektur zu überführen. Ein robustes Datenmodellierungstool, das die Lakehouse-Datenassets visualisieren, entwerfen, bereitstellen und standardisieren kann, vereinfacht die Gestaltung und Migration des Lakehouse erheblich und beschleunigt die Aspekte der Datenverwaltung.
Wir freuen uns, unsere Partnerschaft und Integration von erwin Data Modeler von Quest mit der Databricks Lakehouse Platform bekannt zu geben, um diese Anforderungen zu erfüllen. Datenmodellierer können jetzt mit erwin Data Modeler Lakehouse-Datenstrukturen modellieren und visualisieren, um logische und physische Datenmodelle zu erstellen und die Migration zu Databricks zu beschleunigen. Datenmodellierer und Architekten können Datenbanken und ihre zugrunde liegenden Tabellen und Ansichten auf Databricks schnell neu entwickeln oder rekonstruieren. Sie können jetzt einfach auf erwin Data Modeler über Databricks Partner Connect zugreifen!
Hier sind einige der Hauptgründe, warum Datenmodellierungstools wie erwin Data Modeler wichtig sind:
- Verbessertes Datenverständnis: Datenmodellierungstools bieten eine visuelle Darstellung komplexer Datenstrukturen, wodurch es für Stakeholder einfacher wird, die Beziehungen zwischen verschiedenen Datenelementen zu verstehen.
- Erhöhte Genauigkeit und Konsistenz: Datenmodellierungstools können dazu beitragen, dass Datenbanken mit Genauigkeit und Konsistenz entworfen werden, wodurch das Risiko von Fehlern und Inkonsistenzen in den Daten reduziert wird.
- Erleichterte Zusammenarbeit: Mit Datenmodellierungstools können mehrere Stakeholder an der Gestaltung einer Datenbank zusammenarbeiten, um sicherzustellen, dass alle auf dem gleichen Stand sind und das resultierende Schema den Bedürfnissen aller Stakeholder entspricht.
- Bessere Datenbankleistung: Richtig gestaltete Datenbanken können die Leistung von Anwendungen, die von ihnen abhängen, verbessern, was zu einer schnelleren und effizienteren Datenverarbeitung führt.
- Einfachere Wartung: Mit einer gut gestalteten Datenbank werden Wartungsaufgaben wie das Hinzufügen neuer Datenelemente oder die Änderung bestehender einfacher und fehlerfreier.
- Verbesserte Datenverwaltung, Datenintelligenz und Metadatenmanagement.
In diesem Blog demonstrieren wir drei Szenarien, wie erwin Data Modeler mit Databricks verwendet werden kann:
- Das erste Szenario ist, in dem ein Team ein neues Entity Relationship Diagram (ERD) basierend auf der Dokumentation des Business-Teams erstellen möchte. Ziel ist es, ein ER-Diagramm für das logische Modell zu erstellen, damit eine Geschäftseinheit Beziehungen, Definitionen und Geschäftsregeln, wie sie im System angewendet werden, verstehen und anwenden kann. Basierend auf diesem logischen Modell werden wir auch ein physisches Modell für Databricks erstellen.
- Im zweiten Szenario erstellt die Geschäftseinheit ein visuelles Datenmodell durch Reverse Engineering aus ihrer aktuellen Databricks-Umgebung, um Geschäftsdefinitionen, Beziehungen und Governance-Perspektiven zu verstehen und mit dem Reporting- und Governance-Team zusammenzuarbeiten.
- Im dritten Szenario konsolidiert das Plattformarchitektenteam seine verschiedenen Enterprise Data Warehouse (EDW) und Data Marts wie Oracle, SQL Server, Teradata, MongoDB usw. in die Databricks Lakehouse-Plattform und erstellt ein konsolidiertes Master-Modell.
Nach Abschluss der ERD-Erstellung zeigen wir Ihnen, wie Sie eine DDL/SQL-Datei für das physische Designteam von Databricks generieren.
Szenario #1: Erstellen eines neuen logischen und physischen Datenmodells zur Implementierung in Databricks
Der erste Schritt ist die Auswahl eines logischen/physischen Modells, wie hier gezeigt:
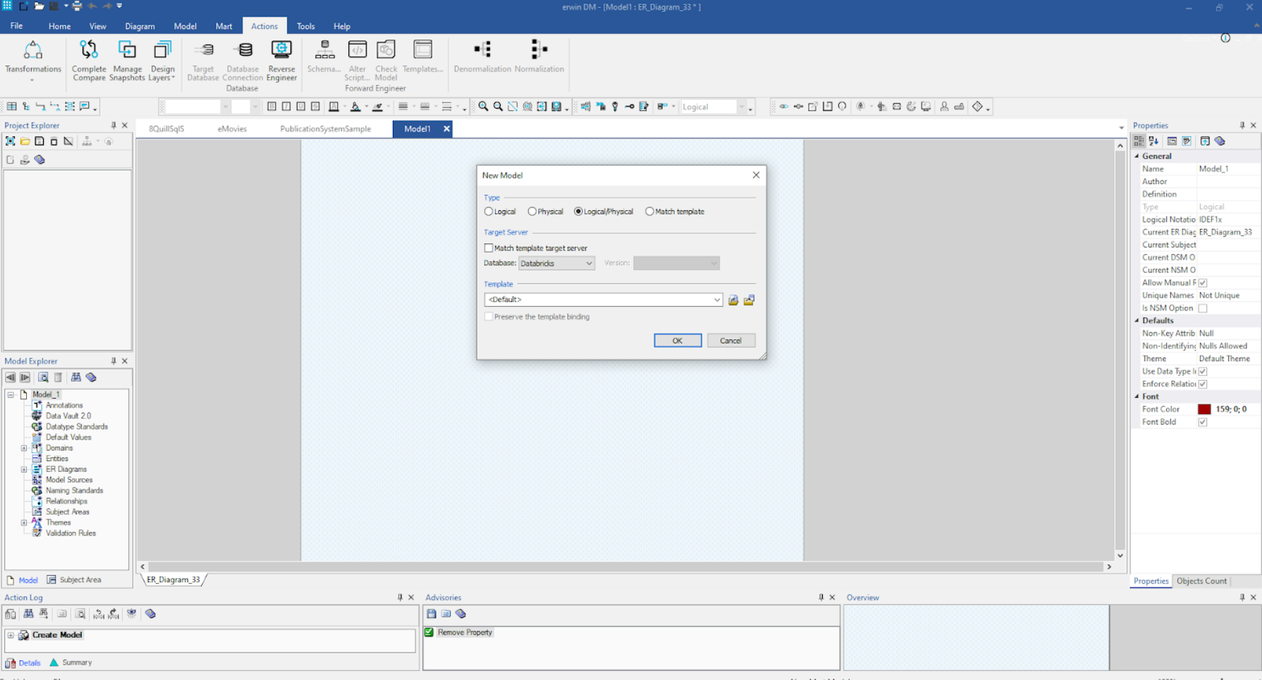
Nach der Auswahl können Sie mit dem Erstellen Ihrer Entitäten, Attribute, Beziehungen, Definitionen und anderer Details in diesem Modell beginnen.
Der folgende Screenshot zeigt ein Beispiel für ein erweitertes Modell:
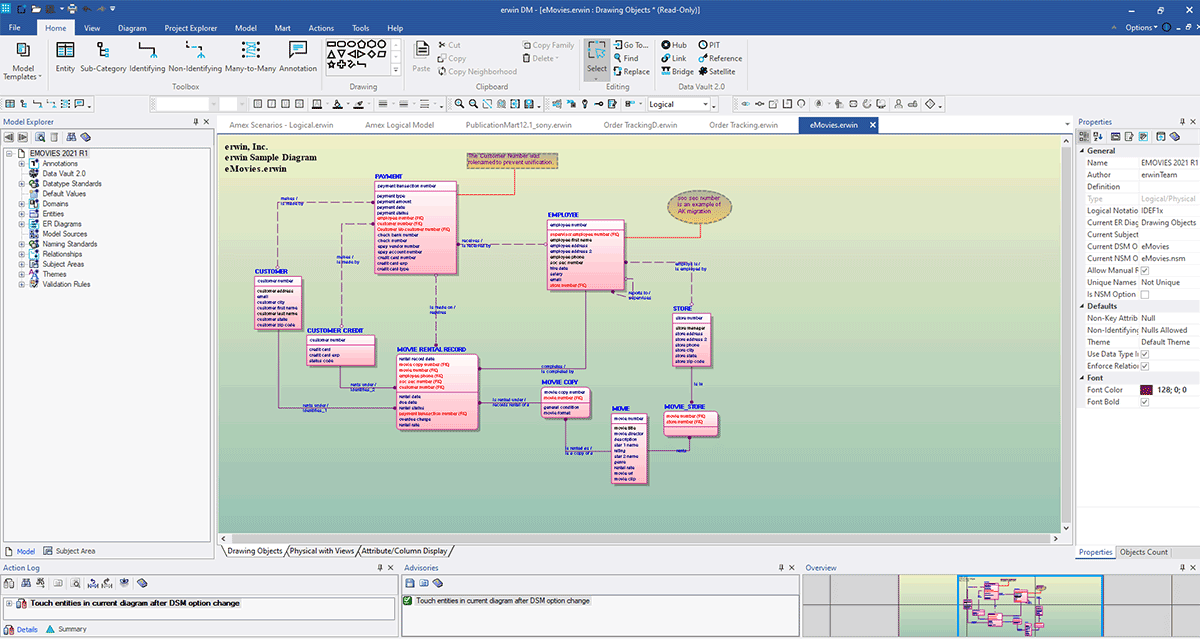
Hier können Sie Ihr Modell erstellen und die Details nach Bedarf dokumentieren. Um mehr darüber zu erfahren, wie Sie erwin Data Modeler verwenden, lesen Sie die Online-Hilfe-Dokumentation.
Szenario #2: Reverse Engineering eines Datenmodells von der Databricks Lakehouse Platform
Reverse Engineering eines Datenmodells bedeutet, ein Datenmodell aus einer vorhandenen Datenbank oder einem Skript zu erstellen. Das Modellierungstool erstellt eine grafische Darstellung der ausgewählten Datenbankobjekte und der Beziehungen zwischen den Objekten. Diese grafische Darstellung kann ein logisches oder ein physisches Modell sein.
Wir werden uns über Partner Connect von erwin Data Modeler mit Databricks verbinden:
Verbindungsoptionen:
| Parameter | Beschreibung | Zusätzliche Informationen |
|---|---|---|
| Verbindungstyp | Gibt den Verbindungstyp an, den Sie verwenden möchten. Wählen Sie Use ODBC Data Source, um eine Verbindung über die definierte ODBC-Datenquelle herzustellen. Wählen Sie Use JDBC Connection, um eine Verbindung über JDBC herzustellen. | |
| ODBC-Datenquelle | Gibt die Datenquelle an, mit der Sie eine Verbindung herstellen möchten. Die Dropdown-Liste zeigt die auf Ihrem Computer definierten Datenquellen an. | Diese Option ist nur verfügbar, wenn der Verbindungstyp auf Use ODBC Data Source gesetzt ist. |
| ODBC-Administrator aufrufen. | Gibt an, ob Sie die ODBC-Administratorsoftware starten und das Dialogfeld Datenquelle auswählen anzeigen möchten. Sie können dann eine zuvor definierte Datenquelle auswählen oder eine Datenquelle erstellen. | Diese Option ist nur verfügbar, wenn der Verbindungstyp auf Use ODBC Data Source gesetzt ist. |
| Verbindungszeichenfolge | Gibt die Verbindungszeichenfolge basierend auf Ihrer JDBC-Instanz im folgenden Format an: jdbc:spark://<server-hostname>:443/default;transportMode=http;ssl=1;httpPath=<http-path> | Diese Option ist nur verfügbar, wenn der Verbindungstyp auf Use JDBC Connection gesetzt ist. Beispiel: jdbc:spark://<url>.cloud.databricks.com:443/default;transportMode=http;ssl=1;httpPath=sql/protocolv1/o/<workspaceid>/xxxx |
Der folgende Screenshot zeigt die JDBC-Konnektivität über erwin DataModeler zum Databricks SQL Warehouse.
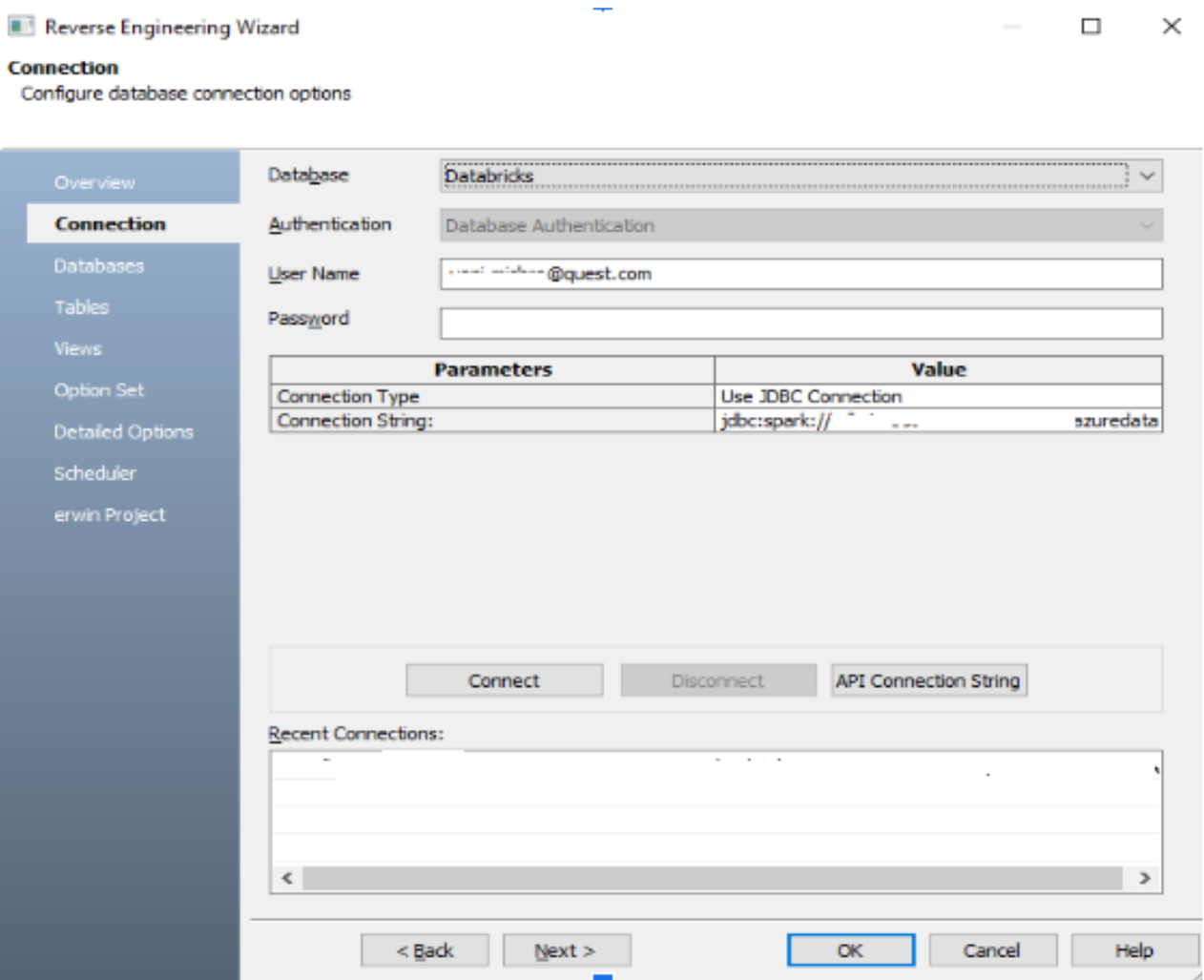
Es ermöglicht uns, alle verfügbaren Datenbanken anzuzeigen und auszuwählen, in welcher Datenbank wir unser ERD-Modell erstellen möchten, wie unten gezeigt.
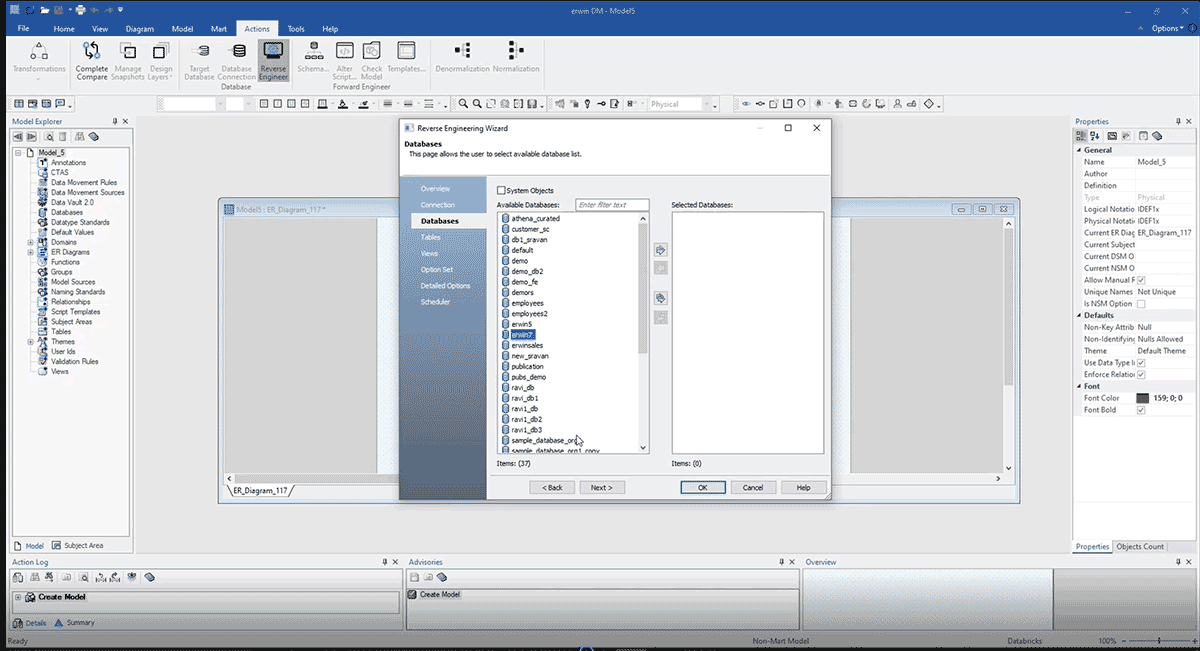
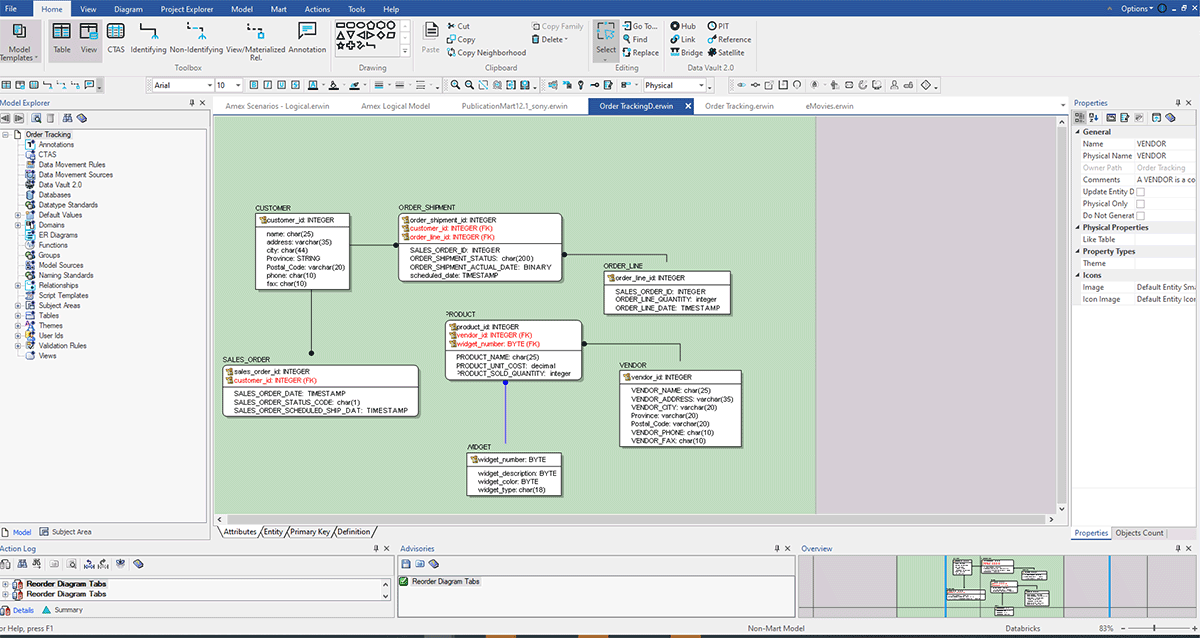
Der obige Screenshot zeigt ein ERD, das nach Reverse Engineering von Databricks mit der obigen Methode erstellt wurde. Hier sind einige Vorteile des Reverse Engineering eines Datenmodells:
- Verbessertes Verständnis bestehender Systeme: Durch Reverse Engineering eines bestehenden Systems können Sie besser verstehen, wie es funktioniert und wie seine verschiedenen Komponenten interagieren. Es hilft Ihnen, potenzielle Probleme oder Verbesserungsmöglichkeiten zu identifizieren.
- Kosteneinsparungen: Reverse Engineering kann Ihnen helfen, Ineffizienzen in einem bestehenden System zu identifizieren, was zu Kosteneinsparungen führt, indem Prozesse optimiert oder Bereiche mit verschwendeten Ressourcen identifiziert werden.
- Zeitersparnis: Reverse Engineering kann Zeit sparen, indem es Ihnen ermöglicht, vorhandenen Code oder Datenstrukturen wiederzuverwenden, anstatt bei Null anzufangen.
- Bessere Dokumentation: Reverse Engineering kann Ihnen helfen, genaue und aktuelle Dokumentationen für ein bestehendes System zu erstellen, was für die Wartung und zukünftige Entwicklung nützlich sein kann.
- Einfachere Migration: Reverse Engineering kann Ihnen helfen, die Datenstrukturen und Beziehungen in einem bestehenden System zu verstehen, was die Migration von Daten zu einem neuen System oder einer neuen Datenbank erleichtert.
Insgesamt ist Reverse Engineering wertvoll und ein grundlegender Schritt für das Datenmodellierungs. Reverse Engineering ermöglicht ein tieferes Verständnis eines bestehenden Systems und seiner Komponenten, kontrollierten Zugriff auf den Enterprise-Designprozess, volle Transparenz über den Modellierungslebenszyklus, Effizienzsteigerungen, Zeit- und Kostenersparnis sowie eine bessere Dokumentation, die zu besseren Governance-Zielen führt.
Szenario Nr. 3: Bestehende Datenmodelle zu Databricks migrieren.
Die obigen Szenarien gehen davon aus, dass Sie mit einer einzelnen Datenquelle arbeiten, aber die meisten Unternehmen verfügen über verschiedene Data Marts und EDWs zur Unterstützung ihrer Reporting-Anforderungen. Stellen Sie sich vor, Ihr Unternehmen passt zu dieser Beschreibung und beginnt nun mit der Erstellung eines Databricks Lakehouse, um seine Datenplattformen in der Cloud auf einer einzigen, einheitlichen Plattform für BI und KI zu konsolidieren. In dieser Situation ist es einfach, erwin Data Modeler zu verwenden, um Ihre bestehenden Datenmodelle von einem Legacy-EDW in ein Databricks-Datenmodell zu konvertieren. Im folgenden Beispiel kann ein für ein EDW wie SQL Server, Oracle oder Teradata erstelltes Datenmodell nun in Databricks implementiert werden, indem die Zieldatenbank zu Databricks geändert wird.
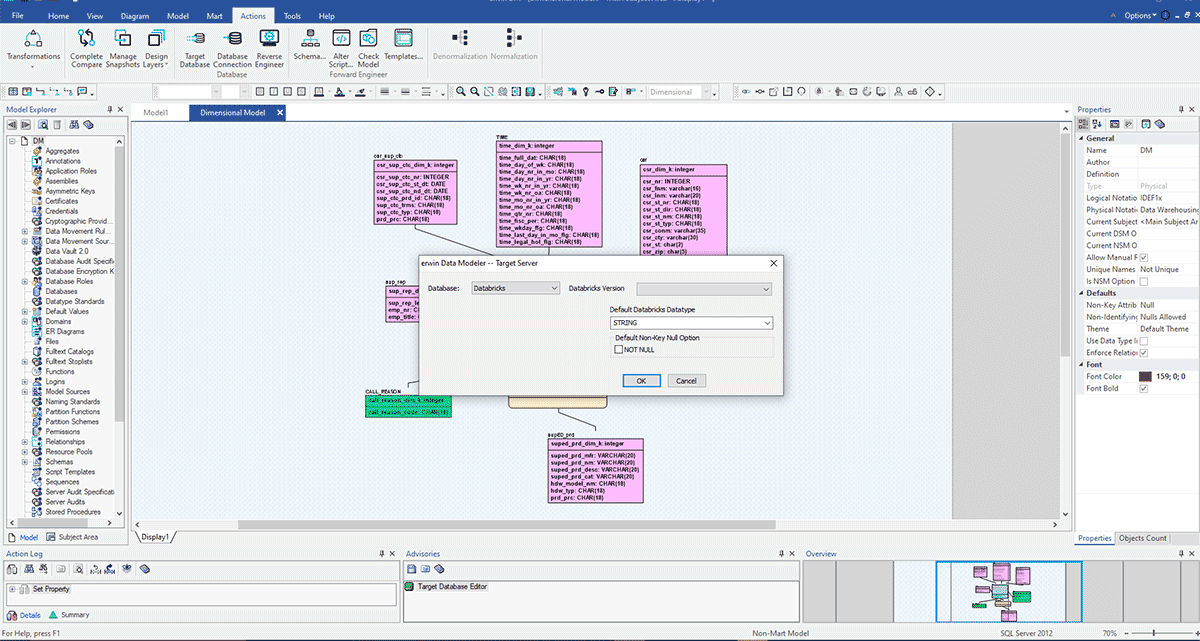
Wie Sie im markierten Kreisbereich sehen können, wurde dieses Modell für SQL Server erstellt. Nun werden wir dieses Modell konvertieren und seine Bereitstellung nach Databricks migrieren, indem wir den Zielserver ändern. Diese Art der einfachen Konvertierung Ihrer Datenmodelle hilft Unternehmen, Datenmodelle schnell und sicher von Legacy- oder On-Premise-Datenbanken in die Cloud zu migrieren und diese Datensätze während ihres gesamten Lebenszyklus zu verwalten.
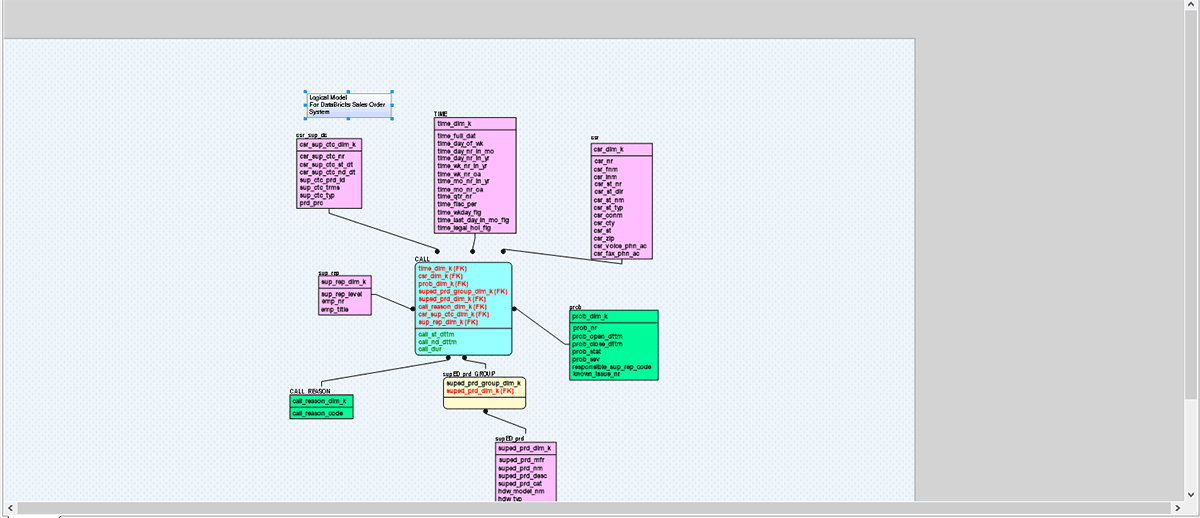
Im obigen Bild haben wir versucht, ein Legacy-SQL-Server-basiertes Datenmodell mit wenigen einfachen Schritten nach Databricks zu konvertieren. Dieser einfache Migrationspfad ermöglicht und hilft Unternehmen, ihre Daten und Assets schnell und sicher nach Databricks zu migrieren, fördert die Remote-Zusammenarbeit und verbessert die Sicherheit.
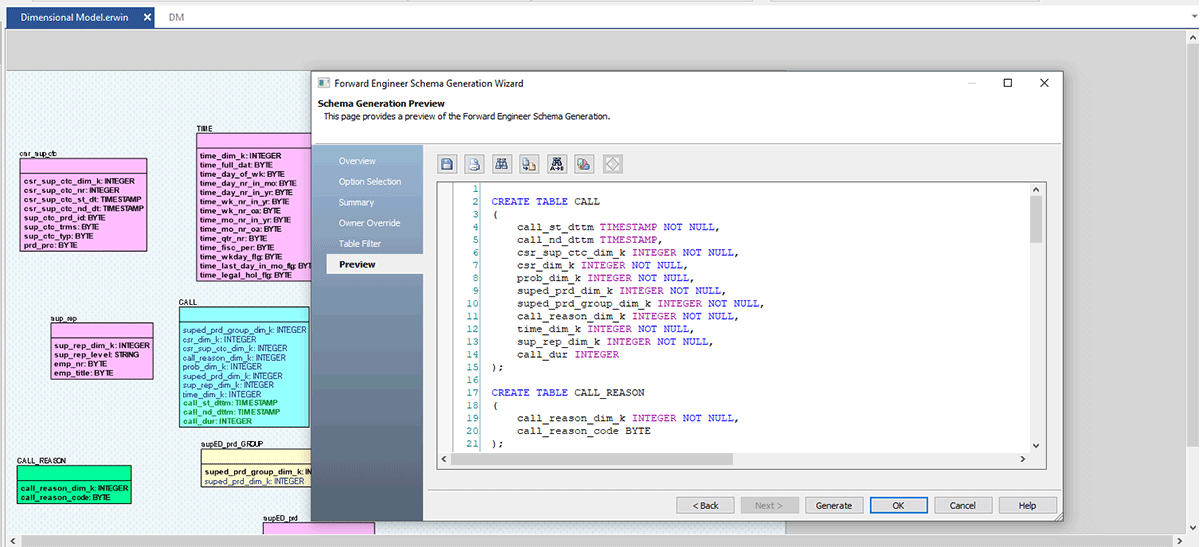
Kommen wir nun zu unserem letzten Teil; sobald das ER-Modell fertig und vom Datenarchitekturteam genehmigt ist, können Sie schnell eine .sql-Datei aus erwin DM generieren oder sich mit Databricks verbinden und dieses Modell direkt nach Databricks forward-engineeren.
Befolgen Sie die nachstehenden Screenshots, die den Schritt-für-Schritt-Prozess zur Erstellung einer DDL-Datei oder eines Datenbankmodells für Databricks erklären.
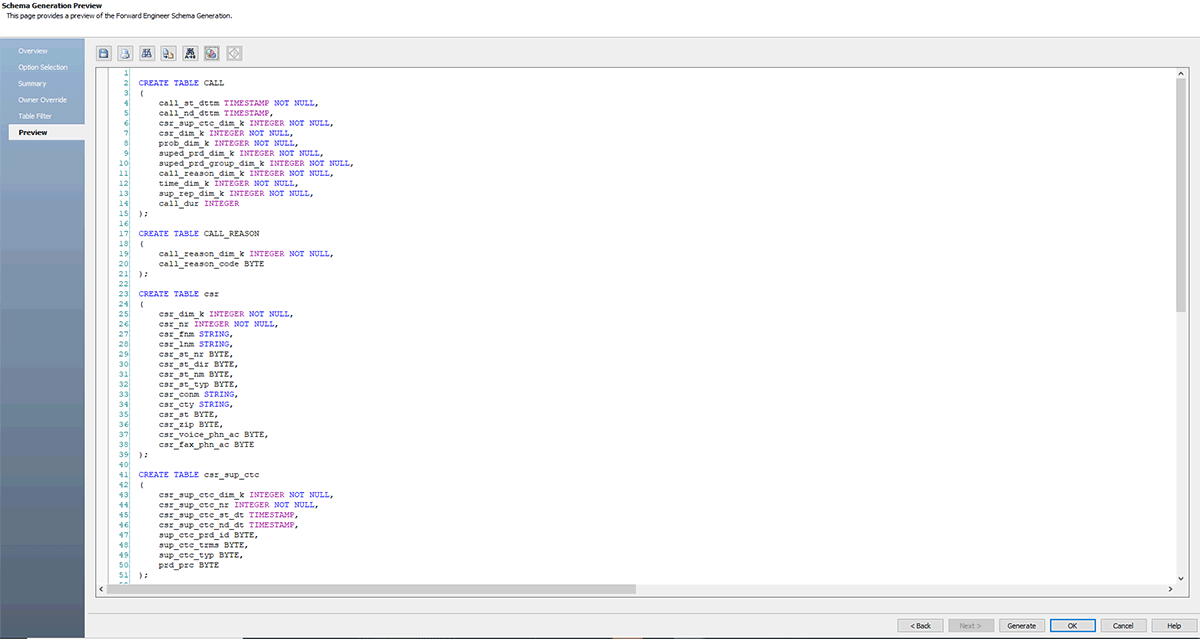
erwin Data Modeler Mart unterstützt auch GitHub. Diese Unterstützung ermöglicht es Ihrem DevOps-Team, Ihre Skripte in den von Ihnen gewählten Enterprise-Quellcode-Repositorys zu verwalten. Mit der Git-Unterstützung können Sie jetzt einfach mit Entwicklern zusammenarbeiten und Versionierungs-Workflows befolgen.
Fazit
In diesem Blog haben wir gezeigt, wie einfach es ist, Datenmodelle mit erwin Data Modeler zu erstellen, zu reverse-engineeren oder forward-engineeren und visuelle Datenmodelle für die Migration Ihrer Tabellendefinitionen zu Databricks zu erstellen und Datenmodelle für Data Governance und die Erstellung von semantischen Ebenen zu reverse-engineeren.
Diese Art von Datenmodellierungspraxis ist das Schlüsselelement, um Mehrwert für Ihre zu schaffen:
- Data Governance Praxis
- Kosten senken und schnellere Wertschöpfung für Ihre Daten und Metadaten erzielen
- Geschäftsergebnisse und die zugehörigen Metadaten verstehen und verbessern
- Komplexität und Risiko reduzieren
- Zusammenarbeit zwischen dem IT-Team und den Business-Stakeholdern verbessern
- Bessere Dokumentation
- Schließlich ein einfacher Weg zur Migration von Legacy-Datenbanken zur Databricks-Plattform
Beginnen Sie mit der Verwendung von erwin über Databricks Partner Connect.
Testen Sie Databricks 14 Tage kostenlos.
Testen Sie erwin Data Modeler
** erwin DM 12.5 wird mit Databricks Unity Catalog-Unterstützung geliefert, mit der Sie Ihre Primär- und Fremdschlüssel visualisieren können.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.