Beschleunigung der LLM-Inferenz mit Prompt Caching für Open-Source-Modelle auf Databricks
Schnellere, sichere OSS LLM-Inferenz mit Prompt Caching.
von Pei-Lun Liao, Asfandyar Qureshi, Roshan Regula, Bruce Fontaine, James Thomas und Chenyang Yu
- Prompt Caching wiederverwendet wiederholte Prompt-Präfixe, damit LLMs schneller laufen. Es reduziert automatisch die Latenz und erhöht den Durchsatz.
- Databricks unterstützt jetzt Prompt Caching für Open-Source-Modelle über Batch-, Pay-per-Token- und Provisioned Workloads. Keine Einrichtung erforderlich.
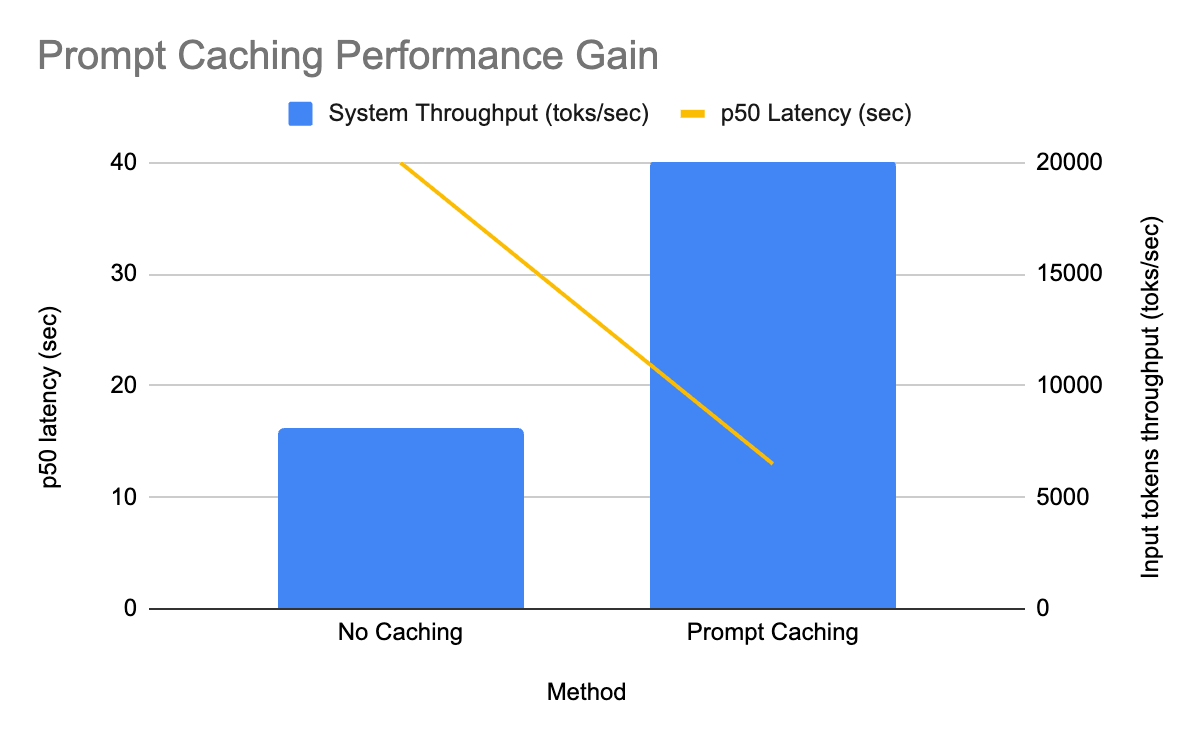
- In der Produktion auf GPT-OSS erhöhte Prompt Caching den Durchsatz um das 2,5-fache und reduzierte die P50-Latenz um das 3-fache.
Warum Prompt Caching wichtig ist
Die Inferenz von Large Language Models (LLMs) beinhaltet oft wiederholte Prompts – denken Sie an denselben System- oder Anweisungsprompt, der in Tausenden von Anfragen vorkommt. Die erneute Verarbeitung dieses identischen Präfixes für jeden Aufruf verschwendet Rechenzyklen, erhöht die Latenz und steigert die Kosten.
Prompt Caching eliminiert diese Redundanz und bietet:
- Geringere Latenz – die Vorfüllphase kann bei einem Cache-Treffer übersprungen werden.
- Höherer Durchsatz – mehr Tokens werden pro Modelleinheit verarbeitet.
Prompt Caching kann eine leistungsstarke Technik sein, um die Qualität eines Modells in bestimmten Domänen zu verbessern, ohne den Token-Durchsatz des Modells zu beeinträchtigen. Abfragen können einen großen domänenspezifischen System-Prompt teilen, wobei die Rechenkosten dieses gemeinsamen Prompts auf alle diese Abfragen verteilt werden. Frontier-Modelle wie Claude verwenden System-Prompts, die intern viele Tausend Tokens lang sind. Darüber hinaus haben wir in unserer kürzlich veröffentlichten Forschung gezeigt, dass die automatisierte Prompt-Optimierung es Open-Source-Modellen ermöglicht, die Qualität von Frontier-Modellen für Unternehmensaufgaben zu übertreffen.
Verfügbarkeit von Features
Databricks bietet bereits integriertes Prompt Caching für proprietäre Modelle (GPT, Gemini, Claude). Wir haben diese Funktion nun auf die Open-Weights-Modelle erweitert, die unsere Foundation Model APIs (FMAPIs) für Batch-Inferenz, Pay-per-Token und Provisioned Throughput Workloads antreiben. Dies gilt auch für alle übergeordneten Dienste, die von einem Foundation Model unterstützt werden, z. B. Agent Bricks, Genie, AI Functions.
Prompt Caching wird jetzt für die folgenden OSS-Modelle unterstützt, die auf Databricks gehostet werden:
- GPT‑OSS 20B und 120B
- Gemma 3 12B
- Fine-tuned Llama 3.1 8B (via PEFT Serving)
- Llama 3.1 8B und 3.3 70B
Wir werden dieses Feature weiterhin für unsere anderen Modelle ausrollen. Sicherheit hat bei Databricks oberste Priorität. Prompt-Caches sind isoliert, befinden sich nur im flüchtigen Speicher und werden niemals persistent gespeichert. Wichtig ist, dass das Caching implizit ist: Kunden müssen nichts konfigurieren, unser System ist darauf ausgelegt, das Prompt Caching automatisch auszuführen und zur Verbesserung des Durchsatzes wiederzuverwenden.
Reale Auswirkungen: Batch-Inferenz auf GPT OSS
Wir haben Prompt Caching zuerst für unsere GPT‑OSS-Modelle eingeführt und sofort messbare Verbesserungen in einer der groß angelegten Produktions-Batch-Inferenz-Pipelines festgestellt:
- Der Input-Token-Durchsatz pro Replikat stieg um das 2,5-fache
- Die Latenz für P50 reduzierte sich um das 3-fache
- All dies bei einer relativ niedrigen Cache-Hit-Rate von 30 %
Fazit
Durch die automatische Wiederverwendung von KV-Caches für identische Prompts ermöglicht Databricks Ihnen, Open-Source-LLMs schneller, kostengünstiger und sicherer auszuführen – und das alles ohne zusätzliche Konfiguration. Egal, ob Sie Echtzeit-Chats bedienen, große Dokumentensammlungen im Batch verarbeiten oder KI-Agenten erstellen, Prompt Caching kann eine gute Inferenz-Pipeline zu einer großartigen machen. Probieren Sie es bei Ihrem nächsten OSS-Modell-Deployment aus und beobachten Sie, wie die Leistungskennzahlen steigen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.