State-of-the-Art Enterprise Agents 90x günstiger erstellen mit automatisierter Prompt-Optimierung
Databricks Agent Bricks ist eine Plattform zum Erstellen, Bewerten und Bereitstellen von produktionsreifen KI-Agenten für Unternehmens-Workflows. Unser Ziel ist es, Kunden dabei zu unterstützen, die optimale Qualität-Kosten-Balance auf der Pareto-Grenze für ihre domänenspezifischen Aufgaben zu erreichen und ihre Agenten, die auf ihren eigenen Daten schlussfolgern, kontinuierlich zu verbessern. Um dies zu unterstützen, entwickeln wir unternehmenszentrierte Benchmarks und führen empirische Auswertungen von Agenten durch, die Genauigkeit und Serving-Effizienz messen und reale Kompromisse widerspiegeln, denen sich Unternehmen in der Produktion stellen müssen.
Innerhalb unseres breiteren Toolkits zur Agentenoptimierung konzentriert sich dieser Beitrag auf die automatisierte Prompt-Optimierung, eine Technik, die iterative, strukturierte Suche nutzt, die durch Feedback-Signale aus der Evaluierung geleitet wird, um Prompts automatisch zu verbessern. Wir zeigen, wie wir:
- Open-Source-Modelle befähigen können, die Qualität von Frontier-Modellen für Unternehmensaufgaben zu übertreffen: Unter Nutzung von GEPA, einer neu veröffentlichten Technik zur Prompt-Optimierung aus der Forschung von Databricks und UC Berkeley, präsentieren wir, wie gpt-oss-120b die proprietären State-of-the-Art-Modelle Claude Sonnet 4 und Claude Opus 4.1 um ~3 % übertrifft und dabei ungefähr 20x bzw. 90x günstiger im Serving ist (siehe Pareto-Grenzen-Diagramm unten).
- Proprietäre Frontier-Modelle noch weiter verbessern: Wir wenden den gleichen Ansatz auf führende proprietäre Modelle an, steigern die Baseline-Leistung von Claude Opus 4.1 und Claude Sonnet 4 um 6-7 % und erzielen eine neue State-of-the-Art-Leistung.
- Einen überlegenen Qualität-Kosten-Kompromiss im Vergleich zu SFT bieten: Die automatisierte Prompt-Optimierung liefert eine Leistung, die mit Supervised Fine-Tuning (SFT) vergleichbar oder besser ist, und reduziert gleichzeitig die Serving-Kosten um 20 %. Wir zeigen auch, dass Prompt-Optimierung und SFT zusammenarbeiten können, um die Leistung weiter zu steigern.
In den folgenden Abschnitten behandeln wir
- wie wir die Leistung von KI-Agenten bei der Informationsextraktion als Kernanwendungsfall bewerten und warum dies für Unternehmens-Workflows wichtig ist;
- einen Überblick darüber, wie Prompt-Optimierung funktioniert, welche Vorteile sie bringen kann, insbesondere in Szenarien, in denen Fine-Tuning nicht praktikabel ist, und welche Leistungssteigerungen in unserer Evaluierungspipeline erzielt werden;
- um diese Gewinne in den Kontext zu setzen, messen wir die Auswirkungen der Prompt-Optimierung und analysieren die wirtschaftlichen Aspekte dieser Techniken;
- Leistungsvergleich mit Supervised Fine-Tuning (SFT), wobei der überlegene Qualität-Kosten-Kompromiss durch Prompt-Optimierung hervorgehoben wird;
- Schlussfolgerungen und nächste Schritte, insbesondere wie Sie mit Databricks Agent Bricks beginnen können, um erstklassige KI-Agenten zu entwickeln, die für die reale Unternehmensbereitstellung optimiert sind.
Bewertung der neuesten LLMs auf IE Bench
Informationsextraktion (IE) ist eine Kernfunktion von Agent Bricks, die unstrukturierte Quellen wie PDFs oder gescannte Dokumente in strukturierte Datensätze umwandelt. Trotz schneller Fortschritte bei den generativen KI-Fähigkeiten bleibt IE im Unternehmensmaßstab schwierig:
- Dokumente sind lang und enthalten domänenspezifisches Fachjargon
- Schemata sind komplex, hierarchisch und enthalten Mehrdeutigkeiten
- Labels sind oft verrauscht und inkonsistent
- Die operative Fehlertoleranz bei der Extraktion ist gering
- Anforderung hoher Zuverlässigkeit und Kosteneffizienz für große Inferenz-Workloads
Infolgedessen stellen wir fest, dass die Leistung je nach Domäne und Aufgabenkomplexität stark variieren kann. Daher erfordert der Aufbau der richtigen zusammengesetzten KI-Systeme für IE über verschiedene Anwendungsfälle hinweg eine gründliche Bewertung der unterschiedlichen Fähigkeiten von KI-Agenten.
Um dies zu untersuchen, haben wir IE Bench entwickelt, eine umfassende Evaluierungssuite, die mehrere reale Unternehmensdomänen wie Finanzen, Recht, Handel und Gesundheitswesen abdeckt. Der Benchmark spiegelt komplexe reale Herausforderungen wider, darunter Dokumente mit über 100 Seiten, Extraktionsentitäten mit über 70 Feldern und hierarchische Schemata mit mehreren verschachtelten Ebenen. Wir berichten über Auswertungen auf dem zurückgehaltenen Testdatensatz des Benchmarks, um eine zuverlässige Messung der realen Leistung zu liefern.
Wir haben die neueste Generation von Open-Source-Modellen, die über die Databricks Foundation Models API bereitgestellt werden, einschließlich der neu veröffentlichten gpt-oss-Serie, sowie führende proprietäre Modelle von mehreren Anbietern, einschließlich der neuesten GPT-5-Familie, einem Benchmark unterzogen.1
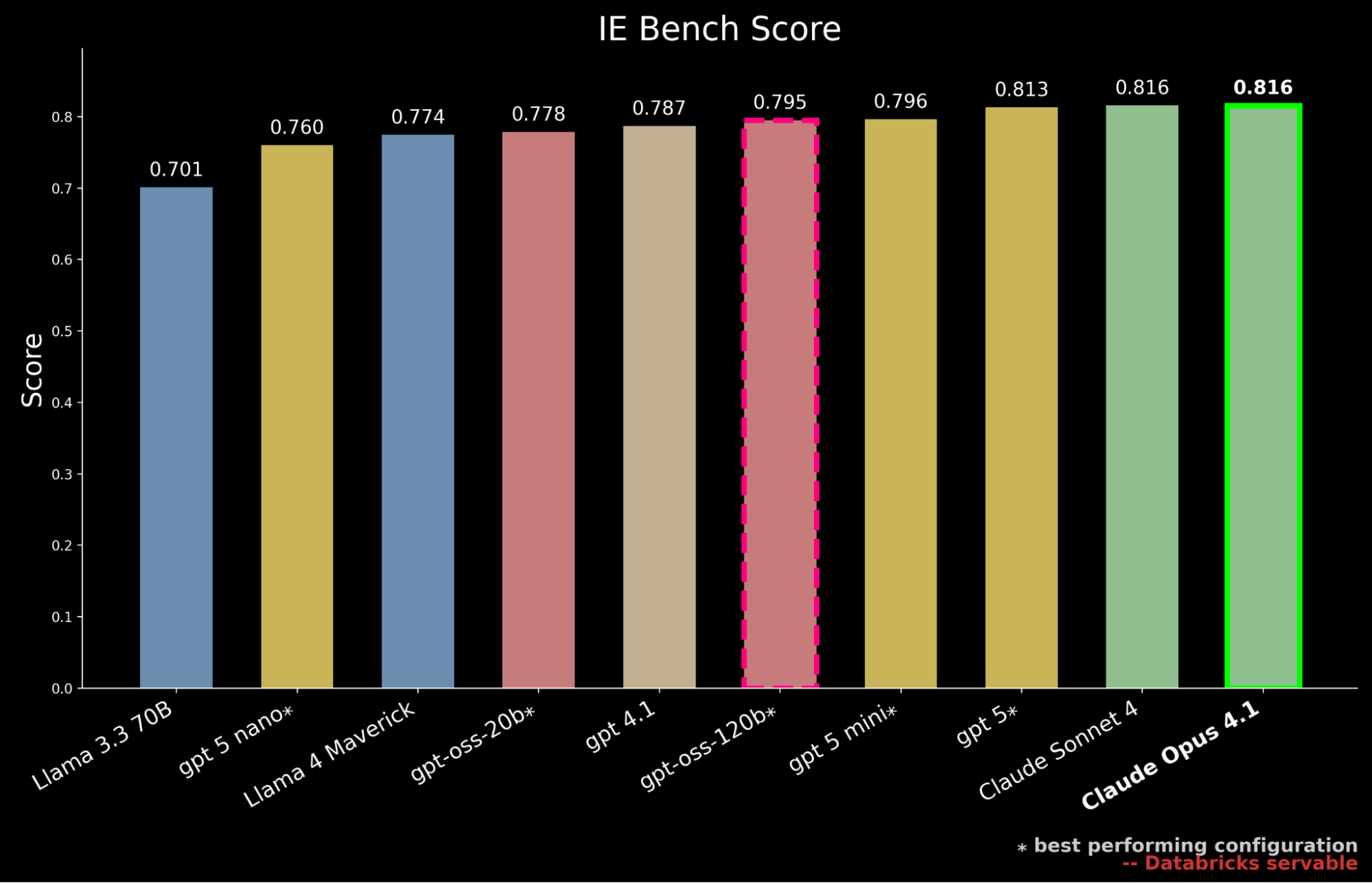
Unsere Ergebnisse zeigen, dass gpt-oss-120b das leistungsstärkste Open-Source-Modell auf IE Bench ist und die bisherige Open-Source-State-of-the-Art-Leistung von Llama 4 Maverick um ~3 % übertrifft und sich der Leistungsebene von gpt-5-mini annähert, was einen bedeutenden Fortschritt für Open-Source-Modelle darstellt. Es bleibt jedoch hinter der Leistung proprietärer Frontier-Modelle zurück und liegt hinter gpt-5, Claude Sonnet 4 und Claude Opus 4.1 zurück – letzteres erzielt die höchste Punktzahl im Benchmark.
Doch in Unternehmensumgebungen muss die Leistung auch gegen die Serving-Kosten abgewogen werden. Wir kontextualisieren unsere bisherigen Ergebnisse weiter, indem wir hervorheben, dass gpt-oss-120b die Leistung von gpt-5-mini erreicht und dabei nur etwa 50 % der Serving-Kosten verursacht. 2 Proprietäre Frontier-Modelle sind größtenteils teurer: gpt-5 kostet etwa das ~10-fache der Serving-Kosten von gpt-oss-120b, Claude Sonnet 4 das ~20-fache und Claude Opus 4.1 das ~90-fache.
Um den Qualität-Kosten-Kompromiss über die Modelle hinweg zu veranschaulichen, stellen wir unten die Pareto-Grenze dar, die die Baseline-Leistung aller Modelle vor jeglichen Verbesserungen zeigt.
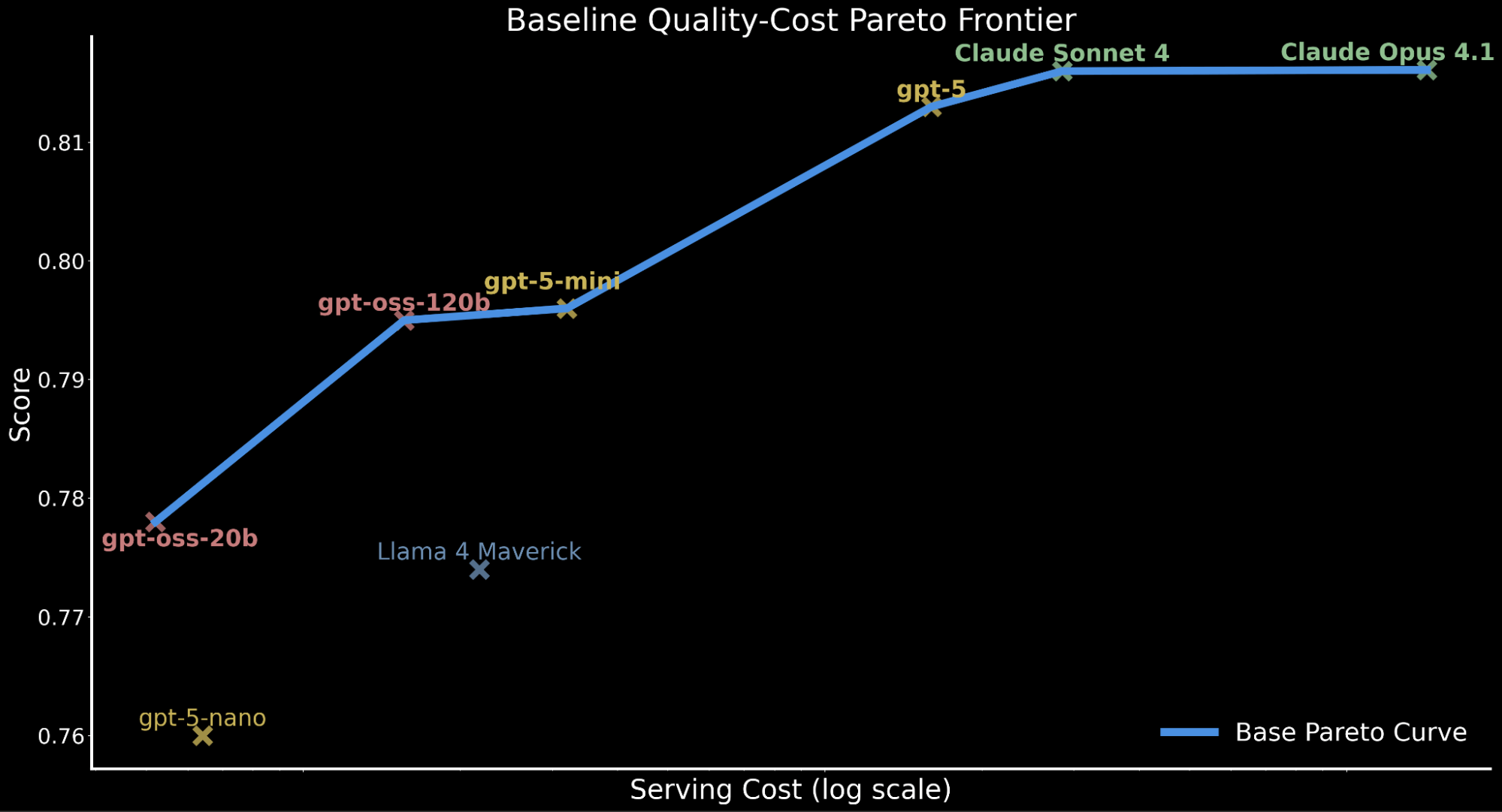
Dieser Qualität-Kosten-Kompromiss hat erhebliche Auswirkungen auf unternehmensweite Workloads, die große Inferenz erfordern und das Rechenbudget und den Serving-Durchsatz berücksichtigen müssen, während gleichzeitig eine performante Genauigkeit beibehalten wird.
Dies motiviert unsere Untersuchung: Können wir gpt-oss-120b auf Frontier-Niveau bringen, während wir seine Kosteneffizienz beibehalten? Wenn ja, würde dies eine führende Leistung auf der Kosten-Qualitäts-Pareto-Grenze liefern und gleichzeitig für die Unternehmensakzeptanz bei Databricks servierbar sein.
Optimierung von Open-Source-Modellen zur Übertreffung der Frontier-Modell-Leistung
Wir untersuchen die automatische Prompt-Optimierung als systematische Methode zur Steigerung der Modellleistung. Manuelles Prompt-Engineering kann zu Verbesserungen führen, ist aber typischerweise von Fachwissen und Versuch-und-Irrtum-Experimenten abhängig. Diese Komplexität wächst weiter in zusammengesetzten KI-Systemen, die mehrere LLM-Aufrufe und externe Tools integrieren, die gemeinsam optimiert werden müssen, was manuelles Prompt-Tuning unpraktisch für Skalierung oder Wartung in Produktionspipelines macht.
Prompt-Optimierung bietet einen anderen Ansatz, der strukturierte Suche nutzt, die durch Feedback-Signale geleitet wird, um Prompts automatisch zu verbessern. Solche Optimierer sind Pipeline-agnostisch und können mehrere voneinander abhängige Prompts in mehrstufigen Pipelines gemeinsam optimieren, was diese Techniken robust und anpassungsfähig für zusammengesetzte KI-Systeme und verschiedene Aufgaben macht.
Um dies zu testen, wenden wir automatisierte Prompt-Optimierungsalgorithmen an, insbesondere MIPROv2, SIMBA und GEPA, einen neuen Prompt-Optimierer aus der Forschung von Databricks und UC Berkeley, der sprachbasierte Reflexion mit evolutionärer Suche kombiniert, um KI-Systeme zu verbessern. Wir wenden diese Algorithmen an, um zu bewerten, wie optimiertes Prompting die Lücke zwischen dem leistungsstärksten Open-Source-Modell, gpt-oss-120b, und State-of-the-Art Closed-Source-Frontier-Modellen schließen kann.
Wir betrachten die folgenden Konfigurationen von automatisierten Prompt-Optimierern in unserer Untersuchung
Jede Prompt-Optimierungstechnik nutzt ein Optimizer-Modell, um verschiedene Aspekte des Prompts für ein Ziel-Studentenmodell zu verfeinern. Abhängig vom Algorithmus kann das Optimizer-Modell Few-Shot-Beispiele aus gebootstrappten Traces generieren, um In-Context-Learning anzuwenden, und/oder die Aufgabeninstruktionen durch Suchalgorithmen vorschlagen und verbessern, die iterative Reflexionen durchführen, um bessere Prompts über Optimierungsversuche hinweg zu mutieren und auszuwählen. Diese Erkenntnisse werden in verbesserte Prompts für das Studentenmodell destilliert, die es während der Inferenzzeit beim Serving verwenden kann. Während dasselbe LLM für beide Rollen verwendet werden kann, experimentieren wir auch mit der Verwendung eines „stärkeren Modells“ als Optimizer-Modell, um zu untersuchen, ob eine qualitativ hochwertigere Anleitung die Leistung des Studentenmodells weiter steigern kann.
Aufbauend auf unseren früheren Erkenntnissen, dass gpt-oss-120b das führende Open-Source-Modell auf IE Bench ist, betrachten wir es als unsere Studentenmodell-Baseline für weitere Verbesserungen.
Bei der Optimierung von gpt-oss-120b betrachten wir zwei Konfigurationen:
- gpt-oss-120b (Optimizer) → gpt-oss-120b (Student)
- Claude Sonnet 4 (Optimizer) → gpt-oss-120b (Student)
Da Claude Sonnet 4 die Spitzenleistung auf IE Bench über gpt-oss-120b erzielt und im Vergleich zu Claude Opus 4.1 mit ähnlicher Leistung relativ günstiger ist, untersuchen wir die Hypothese, ob die Anwendung eines stärkeren Optimizer-Modells zu einer besseren Leistung für gpt-oss-120b führen kann.
Wir evaluieren jede Konfiguration über die Optimierungstechniken hinweg und vergleichen sie mit der jeweiligen gpt-oss-120b-Baseline:
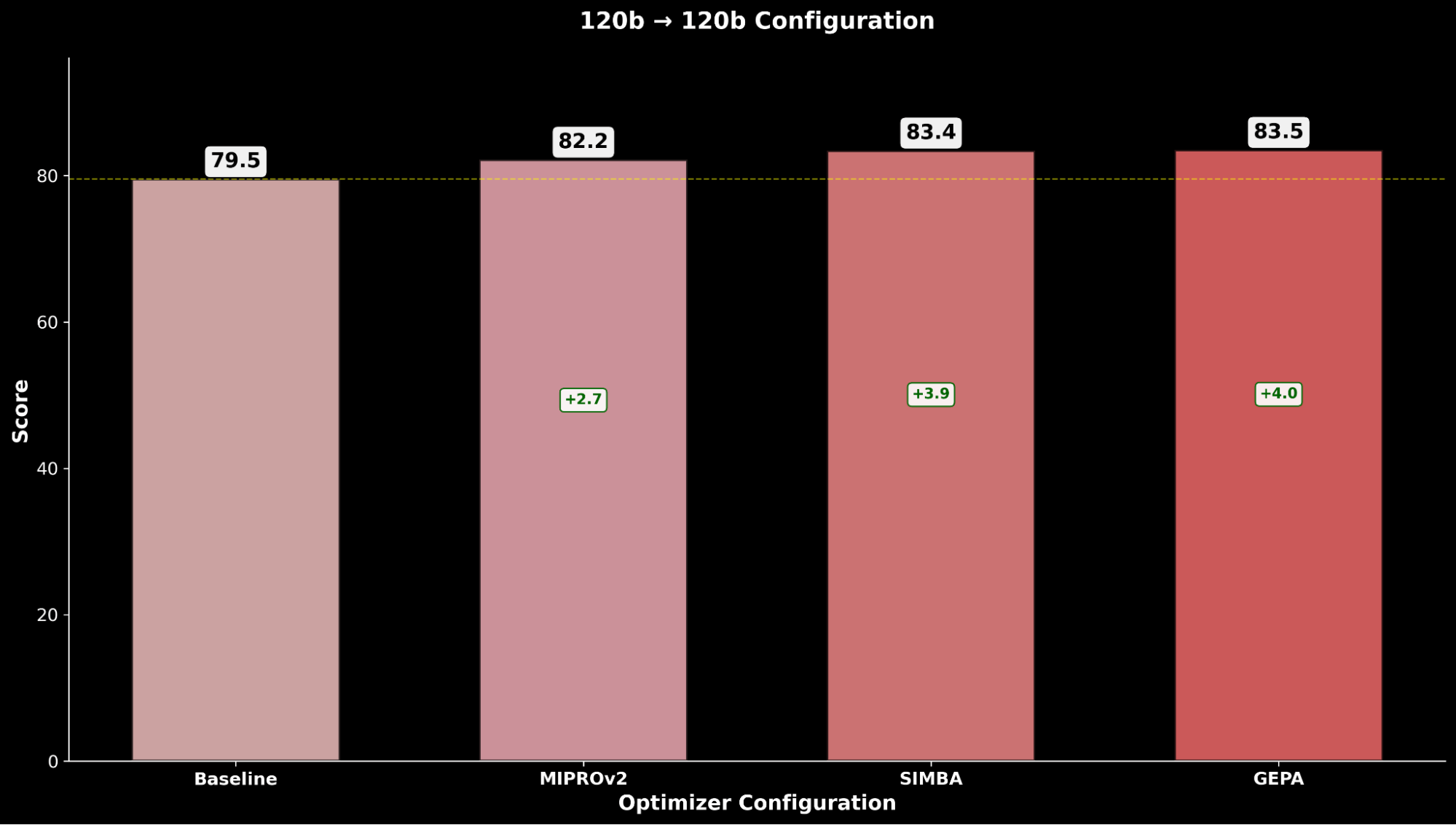
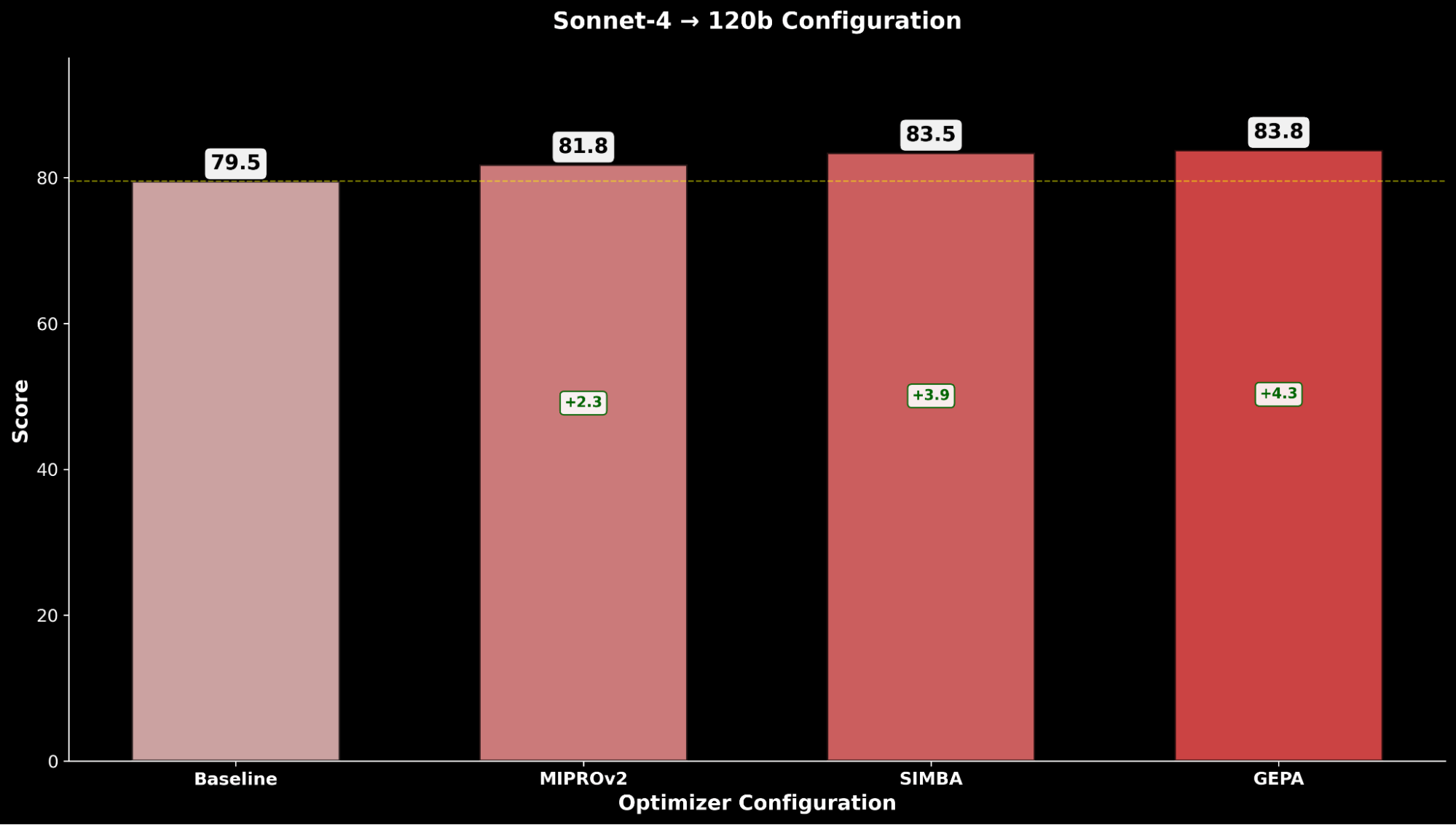
Über IE Bench hinweg stellen wir fest, dass die Optimierung von gpt-oss-120b mit Claude Sonnet 4 als Optimizer-Modell die meisten Verbesserungen gegenüber der Baseline-Leistung von gpt-oss-120b erzielt, mit einer signifikanten Verbesserung von +4,3 Punkten gegenüber der Baseline und einer Verbesserung von +0,3 Punkten gegenüber der Optimierung von gpt-oss-120b mit sich selbst als Optimizer-Modell, was den Nutzen durch die Verwendung eines stärkeren Optimizer-Modells hervorhebt.
Wir vergleichen die am besten abschneidende GEPA-optimierte gpt-oss-120b-Konfiguration mit den Frontier-Claude-Modellen:
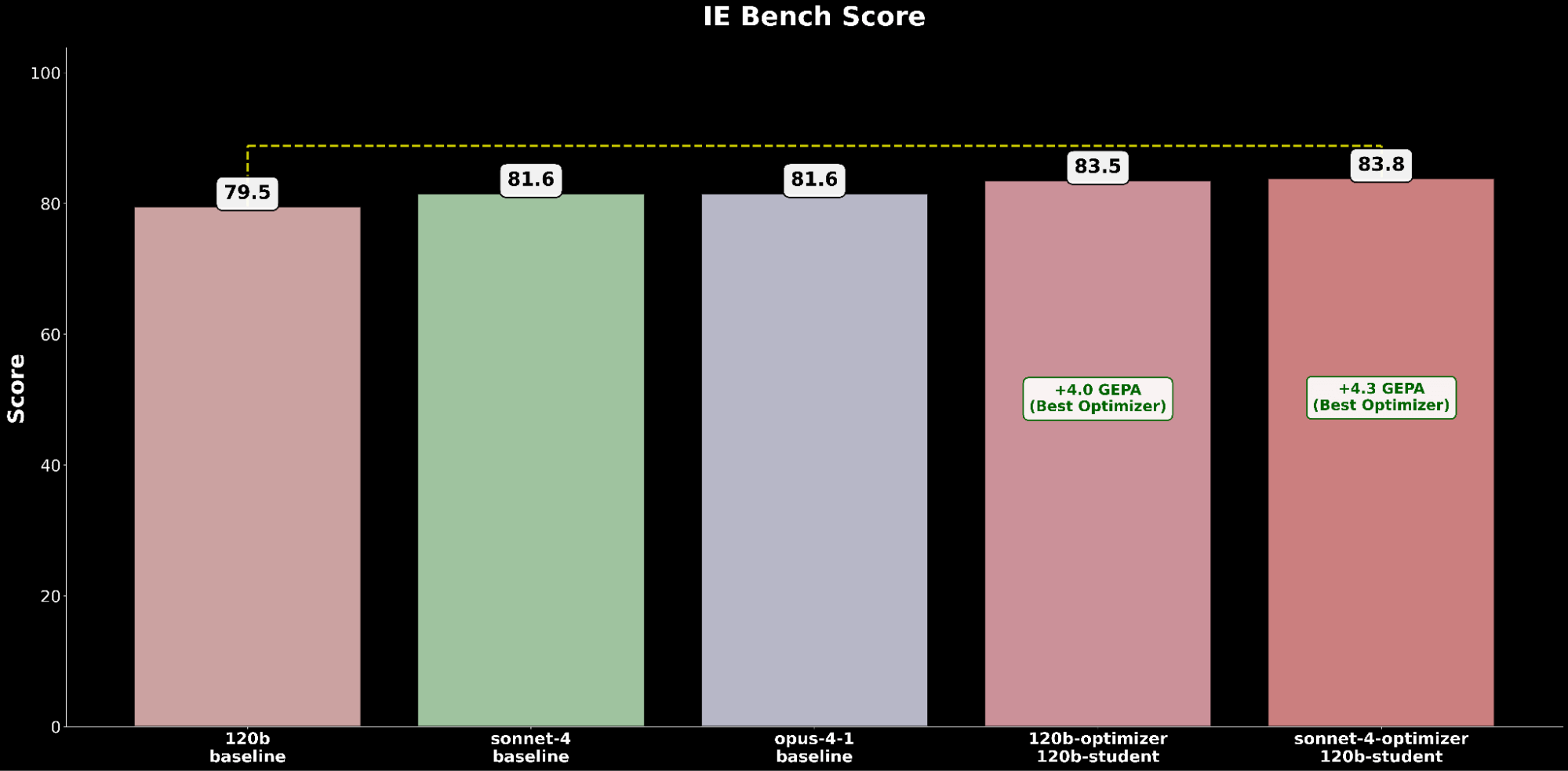
Die optimierte gpt-oss-120b-Konfiguration übertrifft die State-of-the-Art-Baseline-Leistung von Claude Opus 4.1 um einen absoluten Gewinn von +2,2 Punkten und unterstreicht die Vorteile der automatisierten Prompt-Optimierung bei der Verbesserung eines Open-Source-Modells, um führende proprietäre Modelle bei IE-Fähigkeiten zu übertreffen.
Optimieren Sie Frontier-Modelle, um die Leistungsgrenze weiter zu erhöhen
Angesichts der Bedeutung der automatisierten Prompt-Optimierung untersuchen wir, ob die Anwendung desselben Prinzips auf die führenden Frontier-Modelle Claude Sonnet 4 und Claude Opus 4.1 die erreichbare Leistungsgrenze für IE Bench weiter verschieben kann.
Bei der Optimierung jedes proprietären Modells betrachten wir die folgenden Konfigurationen:
- Claude Sonnet 4 (Optimizer) → Claude Sonnet 4 (Student)
- Claude Opus 4.1 (Optimizer) → Claude Opus 4.1 (Student)
Wir betrachten die Standard-Konfigurationen des Optimierermodells, da diese Modelle bereits die Leistungsgrenze definieren.
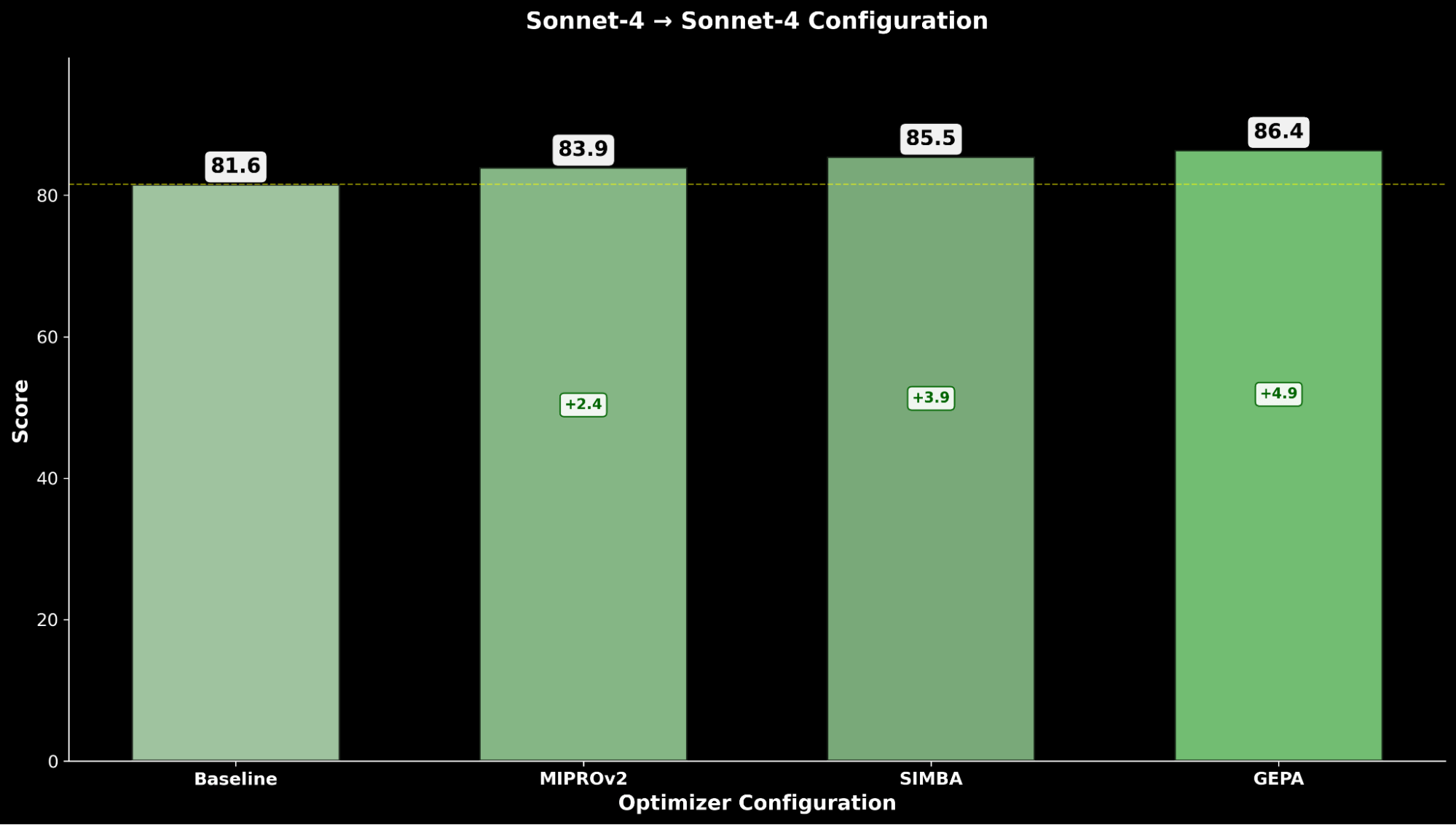
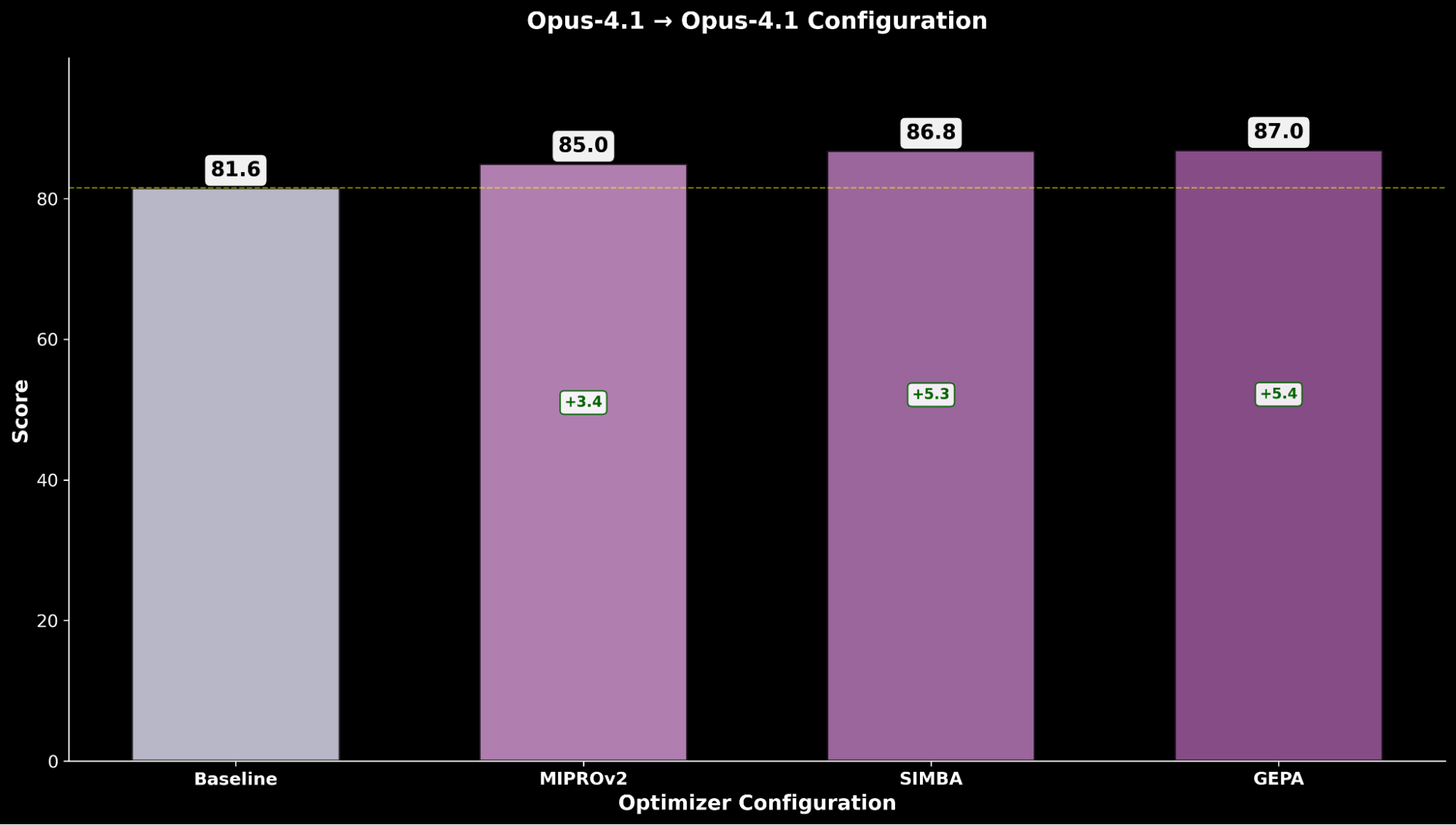
Die Optimierung von Claude Sonnet 4 erzielt eine Verbesserung von +4,8 gegenüber der Basisleistung, während optimiertes Claude Opus 4.1 die insgesamt beste Leistung erzielt, mit einer signifikanten Verbesserung von +6,4 Punkten gegenüber der vorherigen Spitzenleistung.
Wenn wir die Experimentergebnisse zusammenfassen, beobachten wir einen konsistenten Trend, dass die automatisierte Prompt-Optimierung erhebliche Leistungssteigerungen über die Basisleistung aller Modelle hinweg liefert.
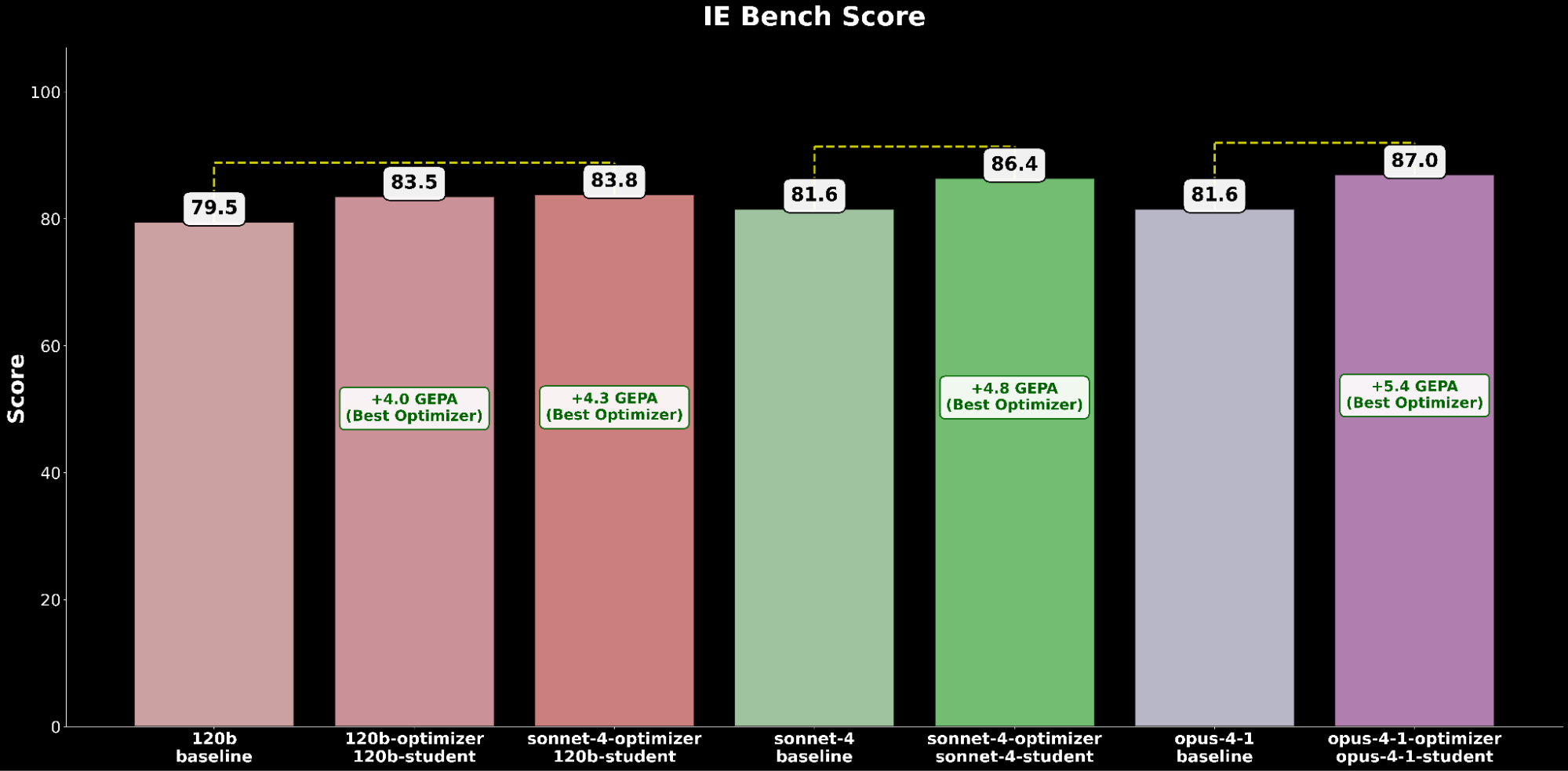
Sowohl bei Open-Source- als auch bei Closed-Source-Modellbewertungen stellen wir durchweg fest, dass GEPA der leistungsstärkste Optimierer ist, gefolgt von SIMBA und dann MIPRO, was erhebliche Qualitätssteigerungen durch automatisierte Prompt-Optimierung ermöglicht.
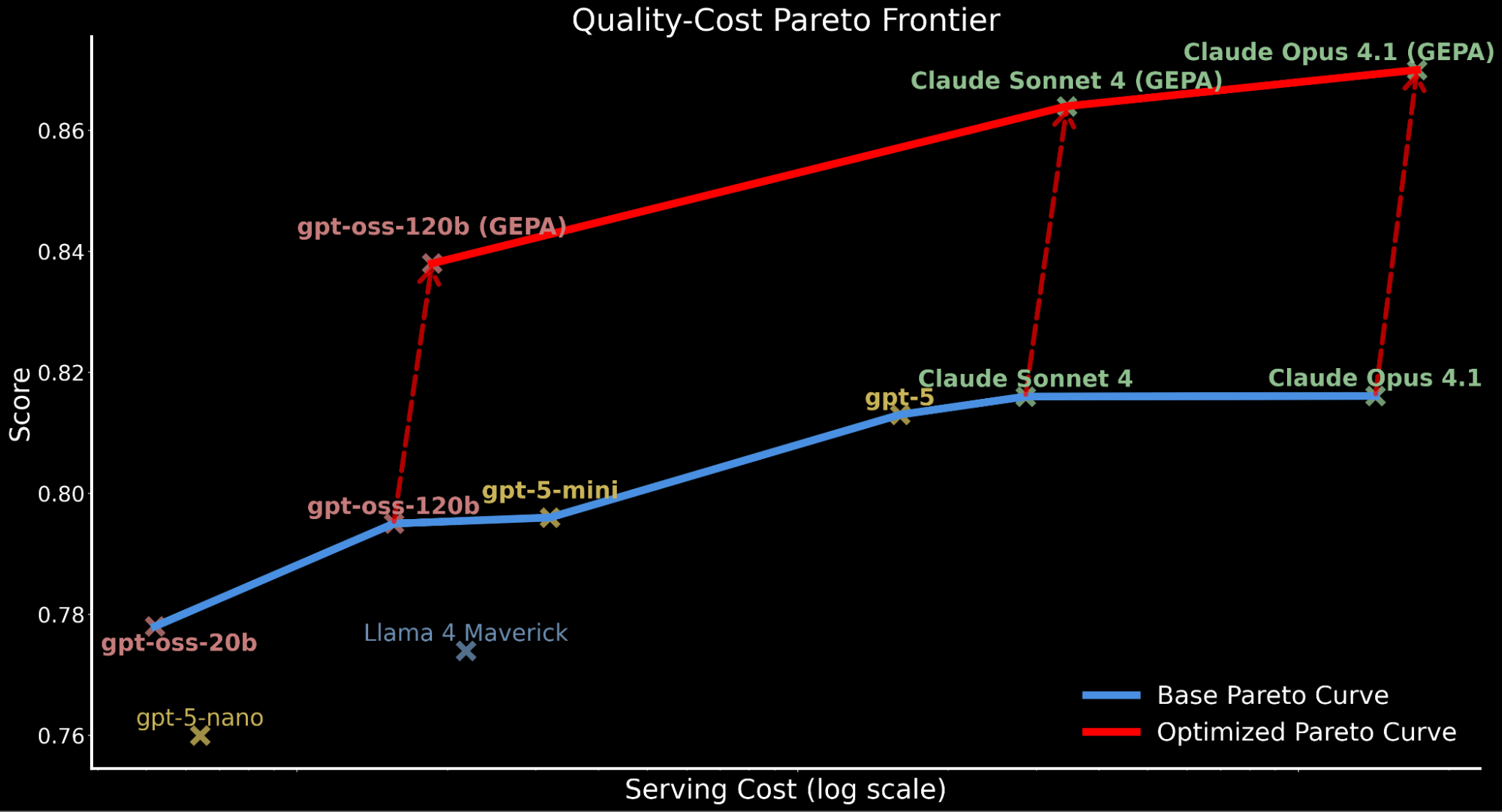
Wenn wir jedoch die Kosten berücksichtigen, stellen wir fest, dass GEPA einen relativ höheren Laufzeit-Overhead hat (da die Optimierungsexploration das 3-fache mehr LLM-Aufrufe (~2-3 Stunden) als MIPRO und SIMBA (~1 Stunde) dauern kann)3 während dieser empirischen Analyse von IE Bench. Wir berücksichtigen daher die Kosteneffizienz und aktualisieren unsere Qualitäts-Kosten-Pareto-Grenze, einschließlich der optimierten Modellleistungen.
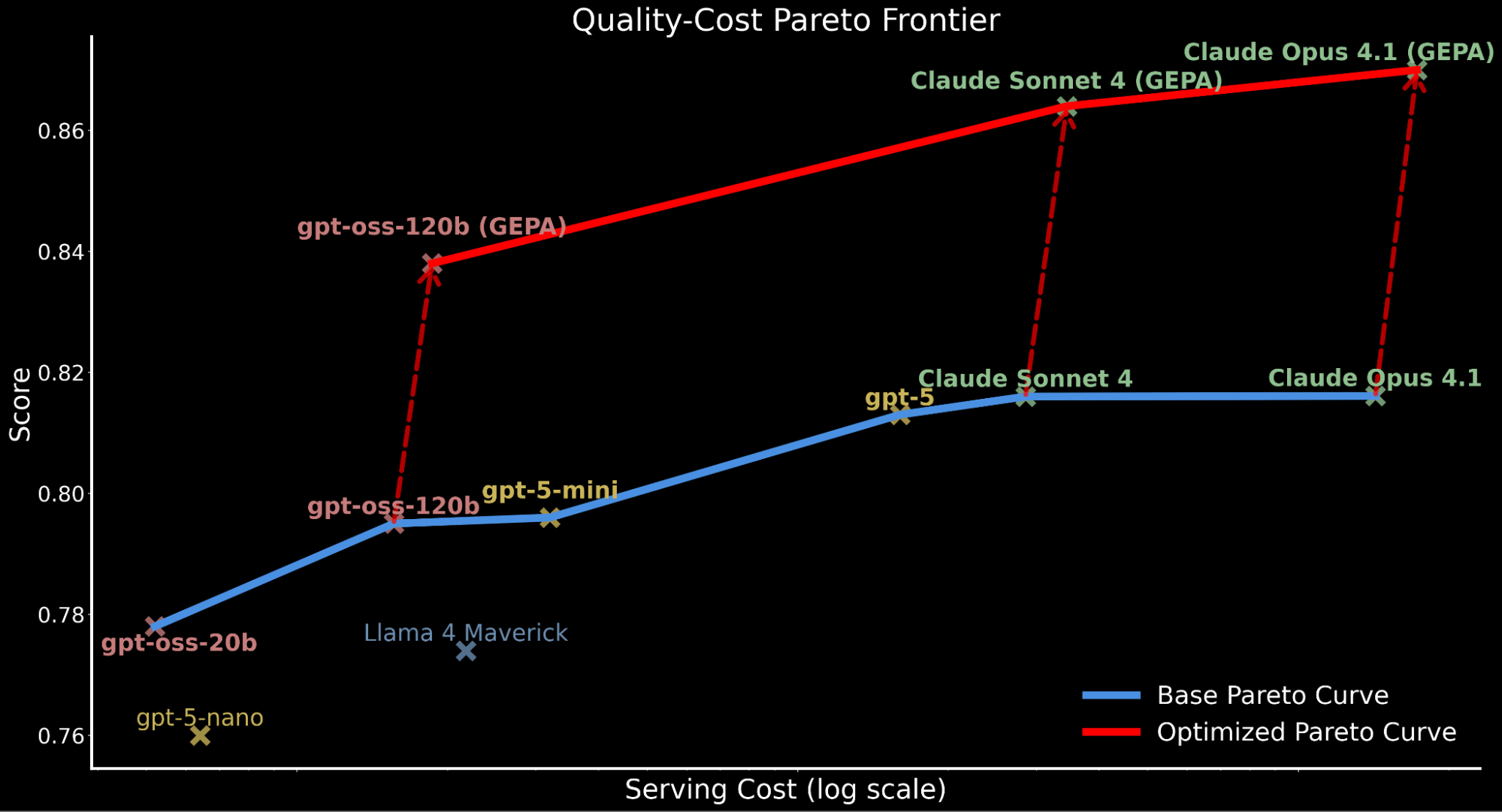
Wir heben hervor, wie die Anwendung der automatisierten Prompt-Optimierung die gesamte Pareto-Kurve nach oben verschiebt und neue Spitzenleistungen erzielt:
- GEPA-optimiertes gpt-oss-120b übertrifft die Basisleistung von Claude Sonnet 4 und Claude Opus 4.1 und ist dabei 22x und 90x günstiger.
- Für Kunden, die Qualität über Kosten stellen, erzielt GEPA-optimiertes Claude Opus 4.1 die neue Spitzenleistung und zeigt starke Gewinne für Spitzenmodelle, die nicht feinabgestimmt werden können.
- Wir führen den erfassten Anstieg der gesamten Servierkosten für GEPA-optimierte Modelle auf die längeren, detaillierteren Prompts im Vergleich zum durch Optimierung erzeugten Basis-Prompt zurück.
Durch die Anwendung automatisierter Prompt-Optimierungen auf Agenten präsentieren wir eine Lösung, die die Kernprinzipien von Agent Bricks – hohe Leistung und Kosteneffizienz – erfüllt.
Vergleich mit SFT
Supervised Fine-Tuning (SFT) wird oft als Standardmethode zur Verbesserung der Modellleistung angesehen, aber wie schneidet es im Vergleich zur automatisierten Prompt-Optimierung ab?
Um dies zu beantworten, führten wir ein Experiment auf einem Teilsatz von IE Bench durch und wählten gpt 4.1 aus, um die Leistung von SFT und automatisierter Prompt-Optimierung zu bewerten (wir schließen gpt-oss und gpt-5 von diesen Vergleichen aus, da die Modelle zum Zeitpunkt der Bewertung nicht veröffentlicht wurden).
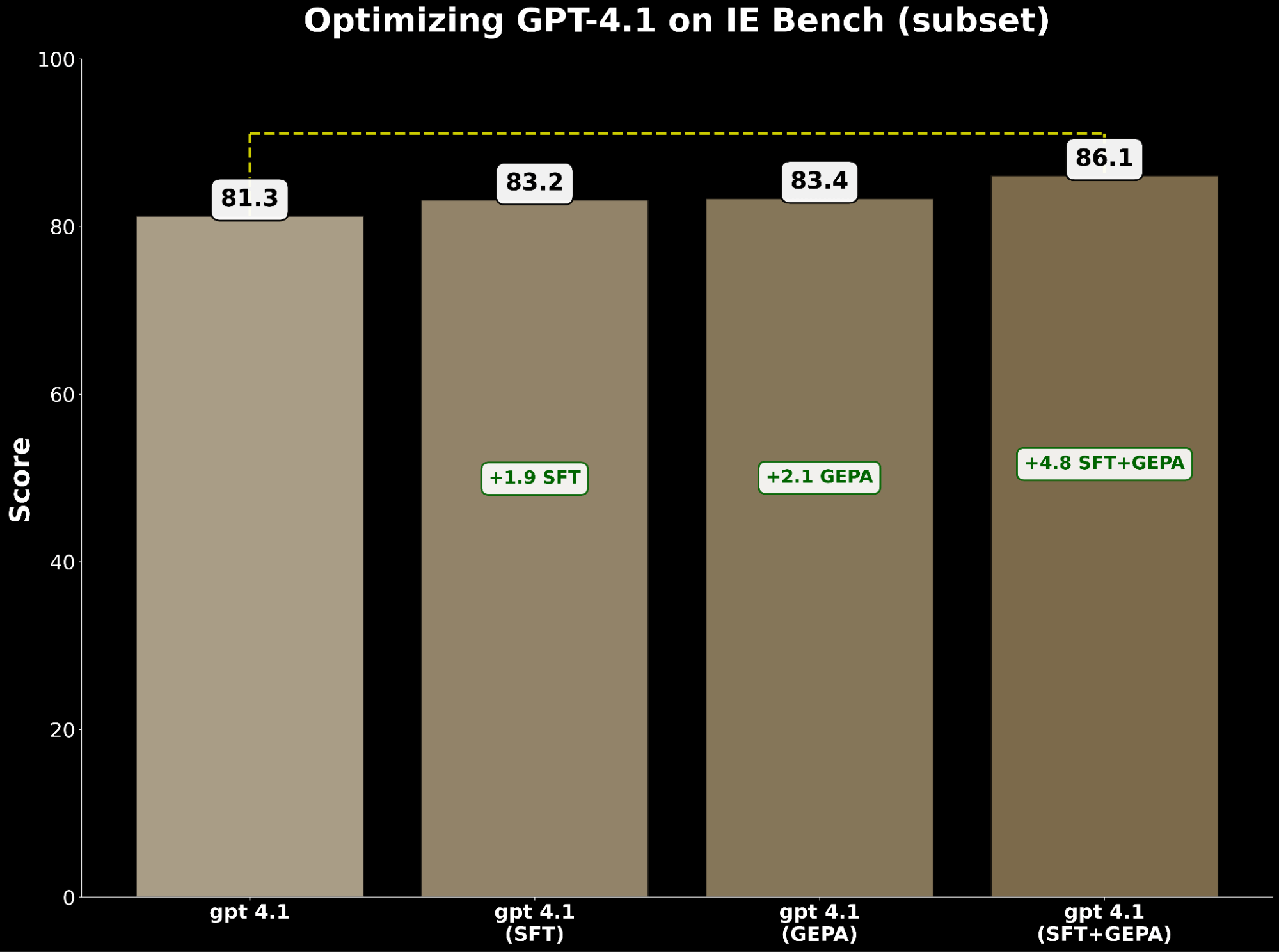
Sowohl SFT als auch Prompt-Optimierung verbessern gpt-4.1 unabhängig voneinander. Insbesondere:
- SFT gpt-4.1 gewann +1,9 Punkte gegenüber der Basislinie.
- GEPA-optimiertes gpt-4.1 gewann +2,1 Punkte und übertraf damit SFT leicht.
Dies zeigt, dass Prompt-Optimierung die Verbesserungen des supervised fine-tuning erreichen – und sogar übertreffen – kann.
Inspiriert von BetterTogether, einer Technik, die abwechselnde Prompt-Optimierung und Modellgewichts-Feinabstimmung zur Verbesserung der LLM-Leistung berücksichtigt, wenden wir GEPA auf SFT an und erzielen einen Gewinn von +4,8 Punkten gegenüber der Basislinie – was das starke Potenzial der Kombination dieser Techniken hervorhebt.
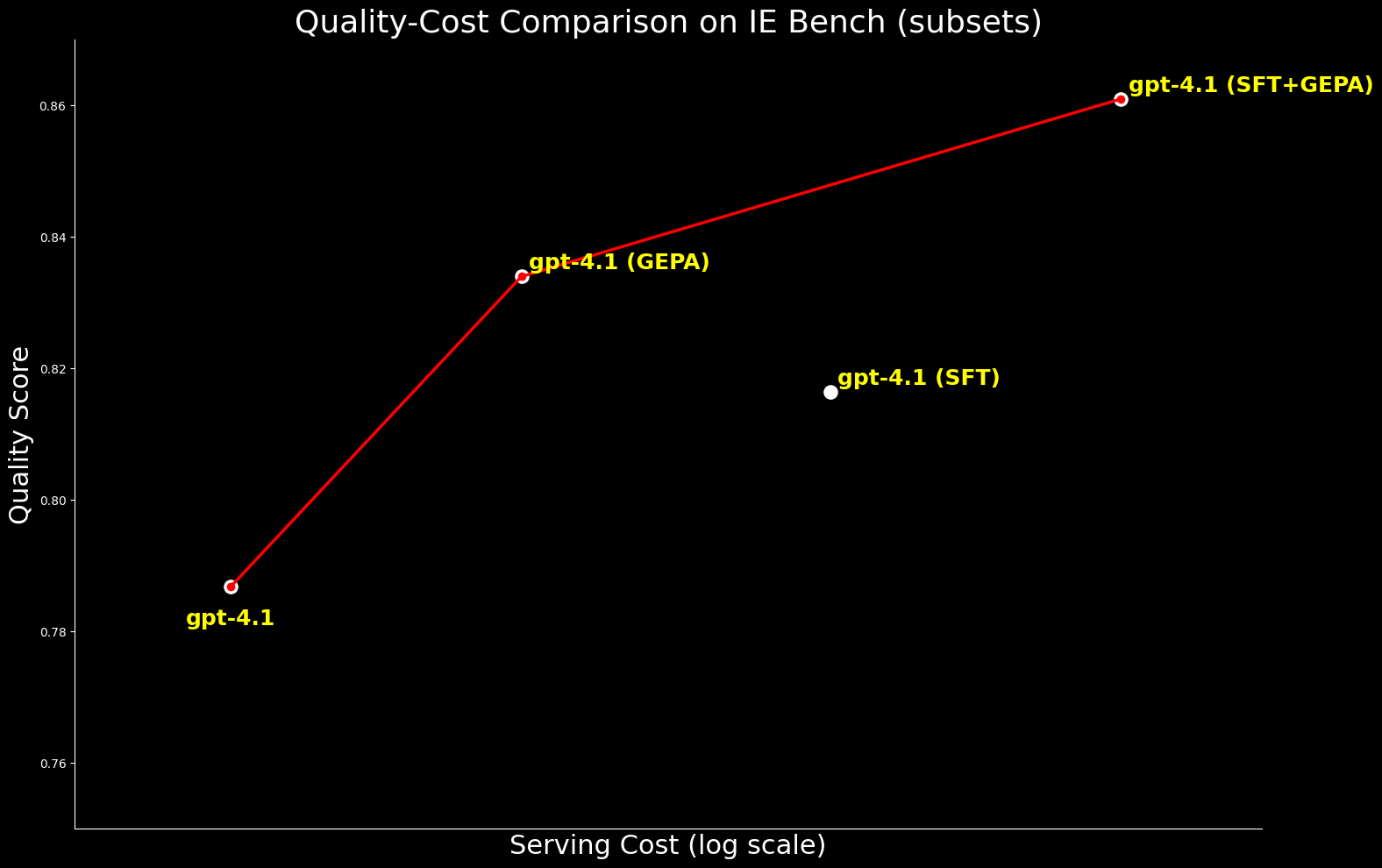
Aus Kostensicht ist GEPA-optimiertes gpt-4.1 etwa 20 % günstiger im Betrieb als SFT-optimiertes gpt-4.1 und liefert dabei eine bessere Qualität. Dies unterstreicht, dass GEPA eine überlegene Qualitäts-Kosten-Balance gegenüber SFT bietet. Darüber hinaus können wir die absolute Qualität maximieren, indem wir GEPA mit SFT kombinieren, was eine 2,7 %ige Verbesserung gegenüber SFT allein erzielt, aber mit etwa 22 % höheren Betriebskosten verbunden ist.4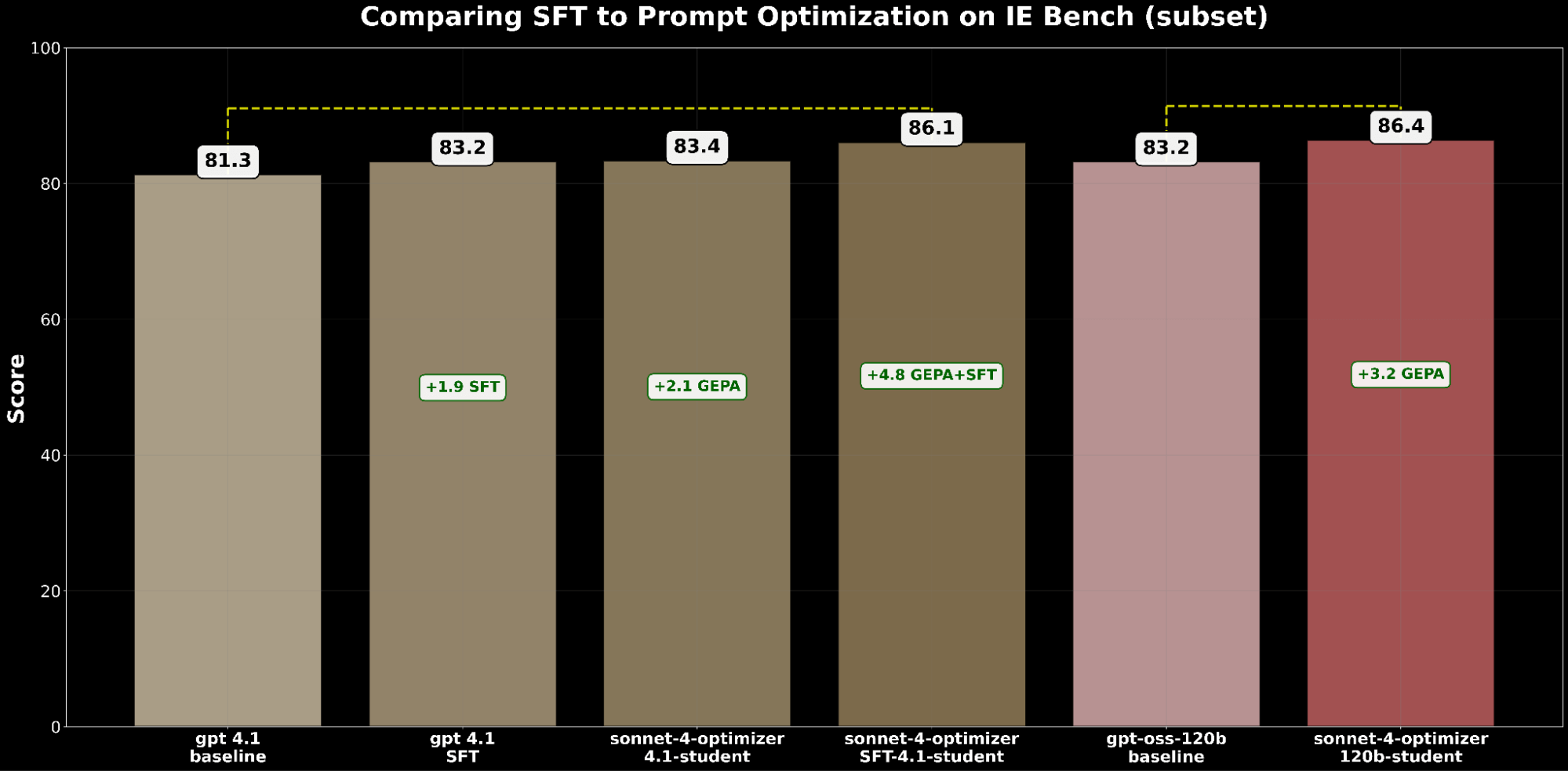
Wir haben den Vergleich auf gpt-oss-120b ausgeweitet, um die Qualitäts-Kosten-Grenze zu untersuchen. Während SFT+GEPA-optimiertes gpt-4.1 nahe herankommt – innerhalb von 0,3 % der Leistung von GEPA-optimiertem gpt-oss-120b – liefert letzteres die gleiche Qualität zu 15-mal geringeren Betriebskosten, was es für die groß angelegte Bereitstellung weitaus praktikabler und attraktiver macht.

Zusammengenommen unterstreichen diese Vergleiche die starken Leistungssteigerungen, die durch GEPA-Optimierung ermöglicht werden – ob allein oder in Kombination mit SFT. Sie heben auch die außergewöhnliche Qualitäts-Kosten-Effizienz von gpt-oss-120b hervor, wenn es mit GEPA optimiert wird.
Lebenszykluskosten
Um die Optimierung in realen Begriffen zu bewerten, betrachten wir die Lebenszykluskosten für Kunden. Das Ziel der Optimierung ist nicht nur die Verbesserung der Genauigkeit, sondern auch die Erstellung eines effizienten Agenten, der Anfragen in der Produktion bedienen kann. Daher ist es unerlässlich, sowohl die Kosten der Optimierung als auch die Kosten für die Bedienung großer Mengen von Anfragen zu betrachten.
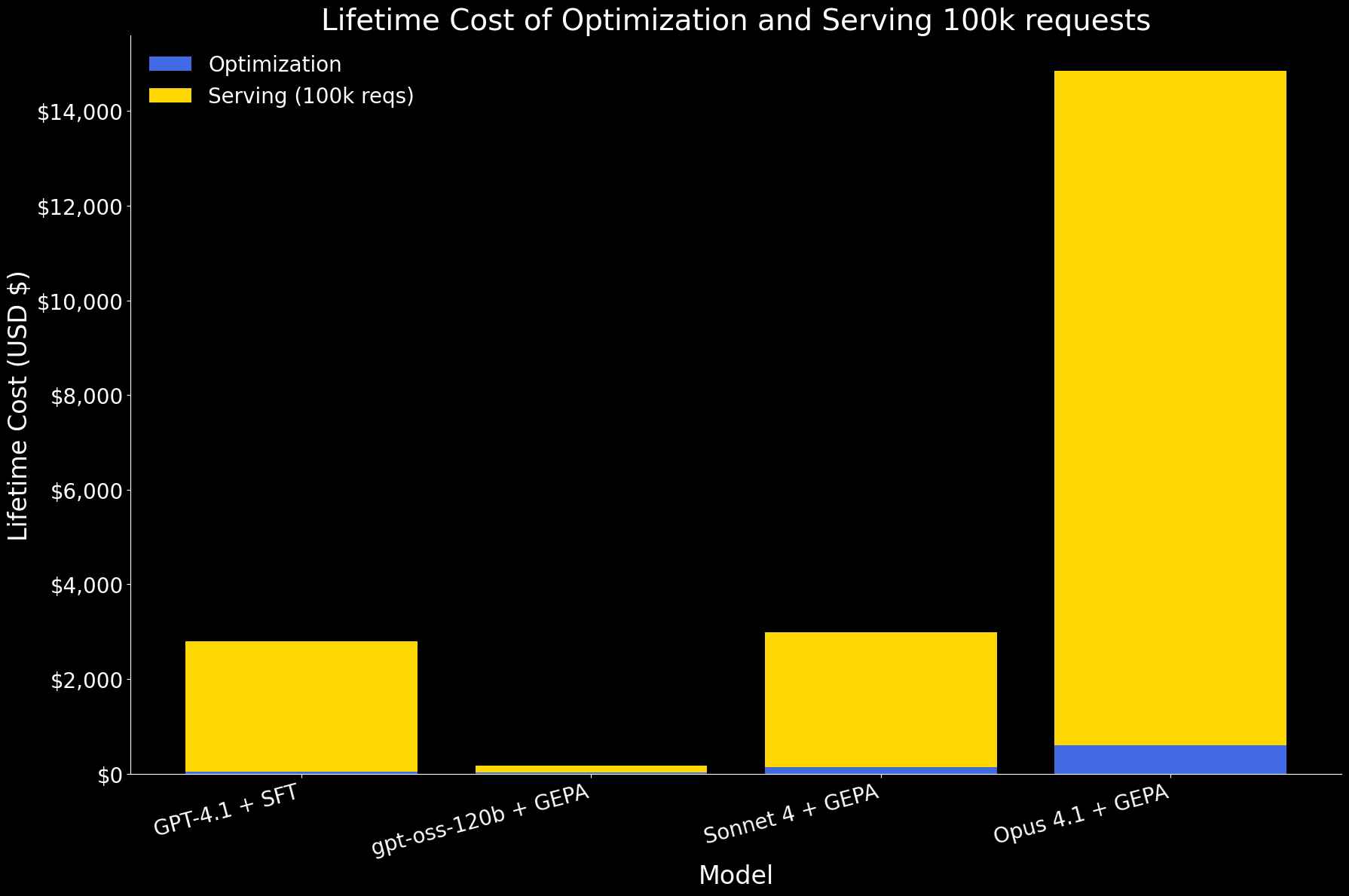
Im ersten Diagramm unten zeigen wir die Lebenszykluskosten für die Optimierung eines Agenten und die Bedienung von 100.000 Anfragen, aufgeteilt in Optimierungs- und Bedienungskomponenten. In dieser Größenordnung dominieren die Bedienungskosten den Gesamtbetrag. Unter den Modellen:
- gpt-oss-120b mit GEPA ist mit Abstand am effizientesten, mit Kosten, die um eine Größenordnung niedriger sind, sowohl für die Optimierung als auch für die Bedienung.
- GPT 4.1 mit SFT und Sonnet 4 mit GEPA haben ähnliche Lebenszykluskosten.
- Opus 4.1 mit GEPA ist am teuersten, hauptsächlich aufgrund seines hohen Bedienungspreises.
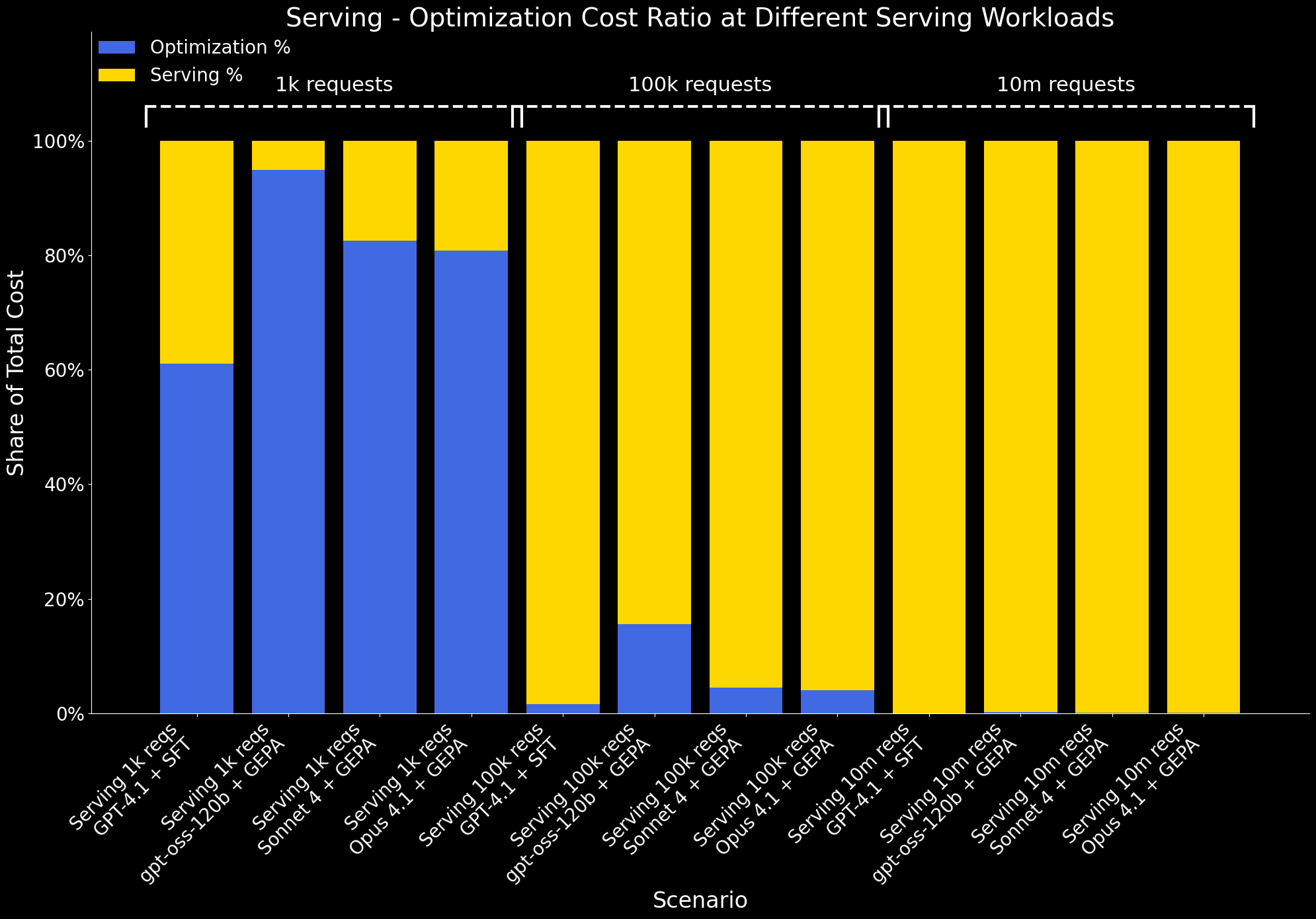
Wir untersuchen auch, wie sich das Verhältnis von Optimierungs- zu Bedienungskosten bei verschiedenen Arbeitslastskalen ändert:
- Bei 1.000 Bedienungsanfragen sind die Bedienungskosten minimal, sodass die Optimierung einen großen Teil der Gesamtkosten ausmacht.
- Bei 100.000 Anfragen steigen die Bedienungskosten erheblich an und der Optimierungs-Overhead wird amortisiert. In dieser Größenordnung überwiegen die Vorteile der Optimierung – bessere Leistung zu geringeren Bedienungskosten – bei weitem ihre einmaligen Kosten.
- Bei 10 Millionen Anfragen werden die Optimierungskosten im Vergleich zu den Bedienungskosten vernachlässigbar und sind im Diagramm nicht mehr sichtbar.
Zusammenfassung
In diesem Blogbeitrag haben wir gezeigt, dass die automatisierte Prompt-Optimierung ein mächtiges Werkzeug zur Verbesserung der LLM-Leistung bei Enterprise-KI-Aufgaben ist:
- Wir haben IE Bench entwickelt, eine umfassende Bewertungssuite, die reale Domänen abdeckt und komplexe Herausforderungen bei der Informationsgewinnung erfasst.
- Durch die Anwendung der automatisierten Prompt-Optimierung GEPA steigern wir die Leistung des führenden Open-Source-Modells gpt-oss-120b so, dass sie die Leistung des hochmodernen proprietären Modells Claude Opus 4.1 um ~3 % übertrifft, während die Bedienung 90x günstiger ist.
- Die gleiche Technik gilt für proprietäre Spitzenmodelle und verbessert Claude Sonnet 4 und Claude Opus 4.1 um 6-7 %.
- Im Vergleich zu Supervised Fine-Tuning (SFT) bietet GEPA-Optimierung einen überlegenen Qualitäts-Kosten-Kompromiss für den Unternehmenseinsatz. Sie liefert eine Leistung, die mit SFT vergleichbar oder besser ist, und reduziert gleichzeitig die Betriebskosten um 20 %.
- Die Analyse der Lebenszykluskosten zeigt, dass bei der Bedienung im großen Maßstab (z. B. 100.000 Anfragen) der einmalige Optimierungs-Overhead schnell amortisiert wird und die Vorteile die Kosten bei weitem überwiegen. Insbesondere liefert GEPA auf gpt-oss-120b eine um eine Größenordnung niedrigere Lebenszykluskosten im Vergleich zu anderen Spitzenmodellen, was es zu einer äußerst attraktiven Wahl für Enterprise-KI-Agenten macht.
Zusammengenommen zeigen unsere Ergebnisse, dass die Prompt-Optimierung die Qualitäts-Kosten-Pareto-Grenze für Enterprise-KI-Systeme verschiebt und sowohl Leistung als auch Effizienz steigert.
Die automatisierte Prompt-Optimierung ist jetzt zusammen mit den bereits veröffentlichten TAO, RLVR und ALHF in Agent Bricks verfügbar. Das Kernprinzip von Agent Bricks ist es, Unternehmen beim Aufbau von Agenten zu unterstützen, die präzise auf Ihren Daten schlussfolgern und branchenspezifische Aufgaben mit modernster Qualität und Kosteneffizienz erfüllen. Durch die Vereinheitlichung von Evaluierung, automatisierter Optimierung und gesteuertem Deployment ermöglicht Agent Bricks Ihren Agenten, sich an Ihre Daten und Aufgaben anzupassen, aus Feedback zu lernen und Ihre branchenspezifischen Aufgaben kontinuierlich zu verbessern. Wir ermutigen Kunden, Information Extraction und andere Agent Bricks-Funktionen auszuprobieren, um Agenten für Ihre eigenen Unternehmensanwendungsfälle zu optimieren.
1 Für die Modellreihen gpt-oss und gpt-5 folgen wir den Best Practices des Harmony-Formats von OpenAI, das das Ziel-JSON-Schema in die Entwicklernachricht einfügt, um strukturierte Ausgaben zu generieren.
Wir untersuchen auch die verschiedenen Schlussfolgerungsaufwände für die gpt-oss-Serie (gering, mittel, hoch) und die gpt-5-Serie (minimal, gering, mittel, hoch) und berichten die beste Leistung jedes Modells über alle Schlussfolgerungsaufwände hinweg.
2 Für Schätzungen der Serving-Kosten verwenden wir die veröffentlichten Preise der Plattformen der Modell-Anbieter (OpenAI und Anthropic für proprietäre Modelle) und von Artificial Analysis für Open-Source-Modelle. Die Kosten werden berechnet, indem diese Preise auf die Eingabe- und Ausgabetoken-Verteilungen angewendet werden, die in IE Bench beobachtet wurden, was uns die Gesamtkosten für das Serving jedes Modells ergibt.
3 Die tatsächliche Laufzeit der automatisierten Prompt-Optimierung ist schwer abzuschätzen, da sie von vielen Faktoren abhängt. Hier geben wir eine grobe Schätzung basierend auf unserer empirischen Erfahrung.
4 Wir schätzen die Serving-Kosten von SFT gpt-4.1 anhand der veröffentlichten Preise für feinabgestimmte Modelle von OpenAI. Für GEPA-optimierte Modelle berechnen wir die Serving-Kosten basierend auf der gemessenen Eingabe- und Ausgabe-Token-Nutzung der optimierten Prompts.
Autoren: Arnav Singhvi, Ivan Zhou, Erich Elsen, Krista Opsahl-Ong, Michael Bendersky, Matei Zaharia, Xing Chen, Omar Khattab, Xiangrui Meng, Simon Favreau-Lessard
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.