Die Stärke von RLVR: Trainieren eines führenden SQL-Reasoning-Modells auf Databricks
Ein einfaches Rezept für Enterprise Reasoning
Update: Sie können mehr über unsere Ergebnisse in unserem neuen technischen Bericht lesen, der hier auf arXiv verfügbar ist.
Update (12. August 2025): Unser mit RLVR trainiertes Modell erzielt nun die Spitzenleistung im Bird Bench in der Kategorie „Single Model“ in Kombination mit Self-Consistency! Wir übertreffen die Ergebnisse von Single Models sowohl mit als auch ohne Self-Consistency (mehrere LLM-Aufrufe erlaubt). Unten haben wir diskutiert, wie wir das beste Modell in der Kategorie „Single Model, Single LLM-Call“ (d. h. ohne Self-Consistency) erzielt haben. Dies zeigt, dass die Stärke des RLVR-Trainings und die Verwendung von Testzeit-Berechnungsstrategien wie Self-Consistency gut kombiniert werden können. Sowohl Best-of-N als auch RLVR werden in Agent Bricks für unsere Kunden eingeführt.
Bei Databricks nutzen wir Reinforcement Learning (RL), um Reasoning-Modelle für Probleme zu entwickeln, mit denen unsere Kunden konfrontiert sind, sowie für unsere Produkte, wie den Databricks Assistant und AI/BI Genie. Zu diesen Aufgaben gehören die Code-Generierung, Datenanalyse, Integration von Organisationswissen, domänenspezifische Evaluierung und Informationsextraktion (IE) aus Dokumenten. Aufgaben wie Codierung oder Informationsextraktion haben oft überprüfbare Belohnungen – die Korrektheit kann direkt überprüft werden (z. B. durch Bestehen von Tests, Übereinstimmung mit Labels). Dies ermöglicht Reinforcement Learning ohne ein gelerntes Belohnungsmodell, bekannt als RLVR (Reinforcement Learning with Verifiable Rewards). In anderen Domänen kann ein benutzerdefiniertes Belohnungsmodell erforderlich sein – was Databricks ebenfalls unterstützt. In diesem Beitrag konzentrieren wir uns auf das RLVR-Setting.
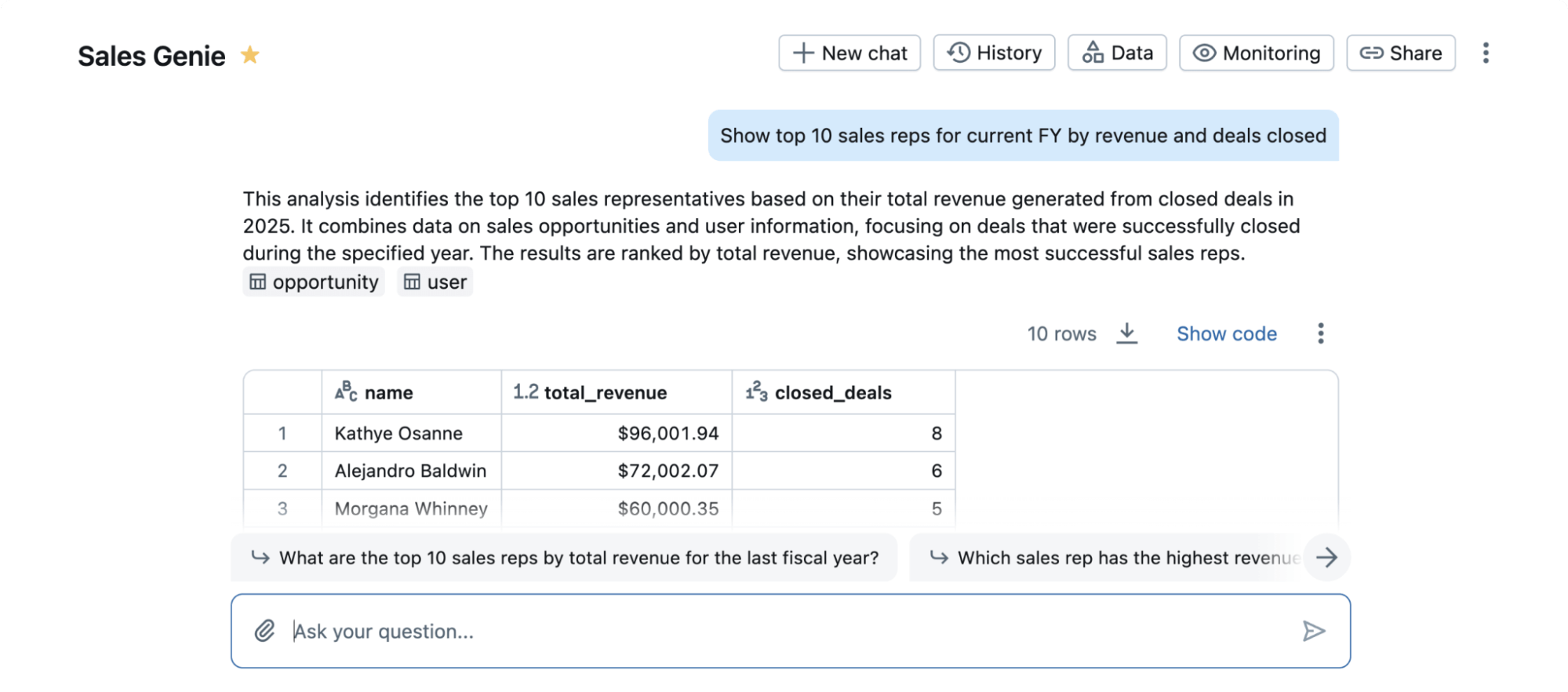
Als Beispiel für die Stärke von RLVR haben wir unseren Trainings-Stack auf einen beliebten akademischen Benchmark in der Datenwissenschaft namens BIRD angewendet. Dieser Benchmark untersucht die Aufgabe, eine natürliche Sprachabfrage in SQL-Code umzuwandeln, der auf einer Datenbank ausgeführt wird. Dies ist ein wichtiges Problem für Databricks-Benutzer, da es Nicht-SQL-Experten ermöglicht, mit ihren Daten zu interagieren. Es ist auch eine herausfordernde Aufgabe, bei der selbst die besten proprietären LLMs nicht sofort gut funktionieren. Obwohl BIRD weder die reale Komplexität dieser Aufgabe noch die volle Bandbreite von Produkten wie Databricks AI/BI Genie (Abbildung 1) vollständig erfasst, ermöglicht uns seine Popularität, die Wirksamkeit von RLVR für die Datenwissenschaft auf einem gut verstandenen Benchmark zu messen.
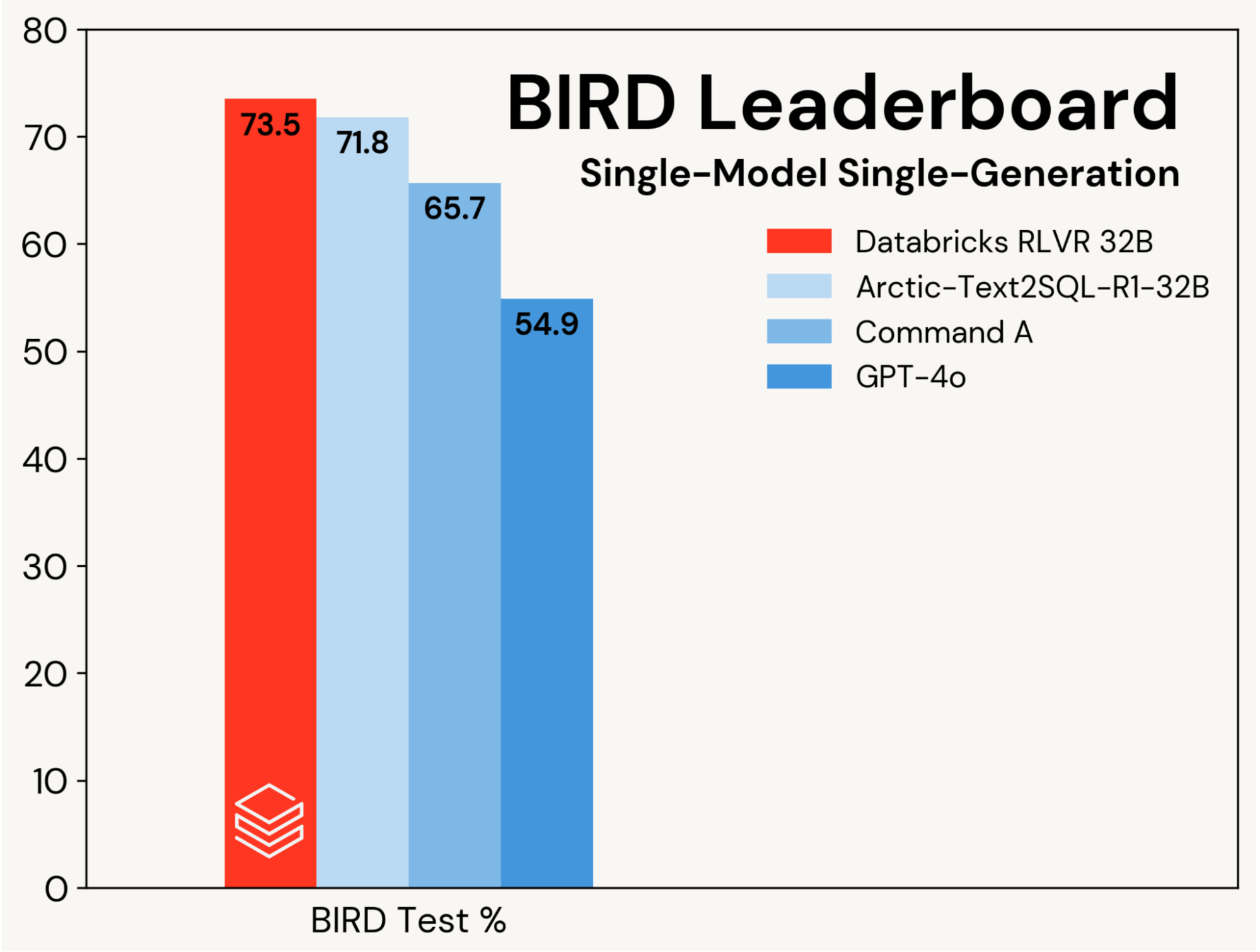
Wir konzentrieren uns darauf, ein Basis-SQL-Coding-Modell mit RLVR zu verbessern und diese Gewinne von Verbesserungen durch Agenten-Designs zu isolieren. Der Fortschritt wird auf der Single-Model, Single-Generation-Spur des BIRD-Leaderboards (d. h. ohne Self-Consistency) gemessen, die auf einem privaten Testdatensatz evaluiert.
Wir haben eine neue State-of-the-Art-Testgenauigkeit von 73,5 % auf diesem Benchmark erreicht. Dies haben wir mit unserem Standard-RLVR-Stack erreicht und nur auf dem BIRD-Trainingsdatensatz trainiert. Der bisherige Bestwert auf dieser Spur lag bei 71,8 %[1], erzielt durch die Erweiterung des BIRD-Trainingsdatensatzes um zusätzliche Daten und die Verwendung eines proprietären LLM (GPT-4o). Unsere Punktzahl ist erheblich besser als die des ursprünglichen Basismodells und proprietärer LLMs (siehe Abbildung 2). Dieses Ergebnis zeigt die Einfachheit und Allgemeinheit von RLVR: Wir haben diese Punktzahl mit handelsüblichen Daten und den Standard-RL-Komponenten erzielt, die wir in Agent Bricks einführen, und das bei unserer ersten Einreichung bei BIRD. RLVR ist ein leistungsfähiger Baseline, den KI-Entwickler in Betracht ziehen sollten, wann immer genügend Trainingsdaten verfügbar sind.
Wir haben unsere Einreichung basierend auf dem BIRD-Dev-Set erstellt. Wir fanden heraus, dass Qwen 2.5 32B Coder Instruct der beste Ausgangspunkt war. Wir haben dieses Modell sowohl mit Databricks TAO – einer Offline-RL-Methode – als auch mit unserem RLVR-Stack feinabgestimmt. Dieser Ansatz, zusammen mit sorgfältiger Prompt- und Modellauswahl, reichte aus, um uns an die Spitze des BIRD-Benchmarks zu bringen. Dieses Ergebnis ist eine öffentliche Demonstration derselben Techniken, die wir zur Verbesserung beliebter Databricks-Produkte wie AI/BI Genie und Assistant verwenden und um unseren Kunden zu helfen, Agenten mit Agent Bricks zu erstellen.
Unsere Ergebnisse unterstreichen die Stärke von RLVR und die Wirksamkeit unseres Trainings-Stacks. Databricks-Kunden haben ebenfalls großartige Ergebnisse mit unserem Stack in ihren Reasoning-Domänen berichtet. Wir denken, dass dieses Rezept leistungsfähig, komponierbar und für eine Reihe von Aufgaben breit anwendbar ist. Wenn Sie RLVR auf Databricks vorab testen möchten, kontaktieren Sie uns hier.
1Siehe Tabelle 1 in https://arxiv.org/pdf/2505.20315
Autoren: Alnur Ali, Ashutosh Baheti, Jonathan Chang, Ta-Chung Chi, Brandon Cui, Andrew Drozdov, Jonathan Frankle, Abhay Gupta, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Kumar Misra, Jose Javier Gonzalez Ortiz, Krista Opsahl-Ong
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.