TAO: Test-Time-Compute zum Trainieren effizienter LLMs ohne gelabelte Daten verwenden
Große Sprachmodelle (Large Language Models, LLMs) sind schwer an neue Unternehmensaufgaben anzupassen. Prompting ist fehleranfällig und erzielt nur begrenzte Qualitätssteigerungen, während Fine-Tuning große Mengen menschlich gelabelter Daten erfordert, die für die meisten Unternehmensaufgaben nicht verfügbar sind. Heute stellen wir eine neue Methode zur Modelloptimierung vor, die nur ungelabelte Nutzungsdaten benötigt. Damit können Unternehmen die Qualität und Kosten von KI verbessern, indem sie nur die Daten verwenden, die sie bereits haben. Unsere Methode, Test-time Adaptive Optimization (TAO), nutzt Test-Zeit-Rechenleistung (wie von o1 und R1 popularisiert) und Reinforcement Learning (RL), um einem Modell beizubringen, eine Aufgabe basierend auf vergangenen Eingabebeispielen besser zu lösen. Das bedeutet, dass sie mit einem einstellbaren Optimierungs-Rechenbudget skaliert, nicht mit menschlichem Labeling-Aufwand. Entscheidend ist, dass TAO zwar Test-Zeit-Rechenleistung nutzt, dies aber als Teil des Prozesses zur Trainierung eines Modells tut; dieses Modell führt dann die Aufgabe direkt mit geringen Inferenzkosten aus (d. h. es ist keine zusätzliche Rechenleistung zur Inferenzzeit erforderlich). Überraschenderweise kann TAO selbst ohne gelabelte Daten eine bessere Modellqualität erzielen als traditionelles Fine-Tuning und kann kostengünstige Open-Source-Modelle wie Llama auf die Qualität teurer proprietärer Modelle wie GPT-4o und o3-mini bringen.
TAO ist Teil des Programms unseres Forschungsteams zu Data Intelligence – dem Problem, KI in spezifischen Domänen mithilfe der Daten, die Unternehmen bereits haben, exzellent zu machen. Mit TAO erzielen wir drei spannende Ergebnisse:
- Bei spezialisierten Unternehmensaufgaben wie der Beantwortung von Dokumentenfragen und der SQL-Generierung übertrifft TAO das traditionelle Fine-Tuning mit Tausenden von gelabelten Beispielen. Es bringt effiziente Open-Source-Modelle wie Llama 8B und 70B auf eine ähnliche Qualität wie teure Modelle wie GPT-4o und o3-mini1, ohne dass Labels benötigt werden.
- Wir können auch Multi-Task-TAO verwenden, um ein LLM breit über viele Aufgaben hinweg zu verbessern. Ohne Labels verbessert TAO die Leistung von Llama 3.3 70B um 2,4 % in einem breiten Unternehmens-Benchmark.
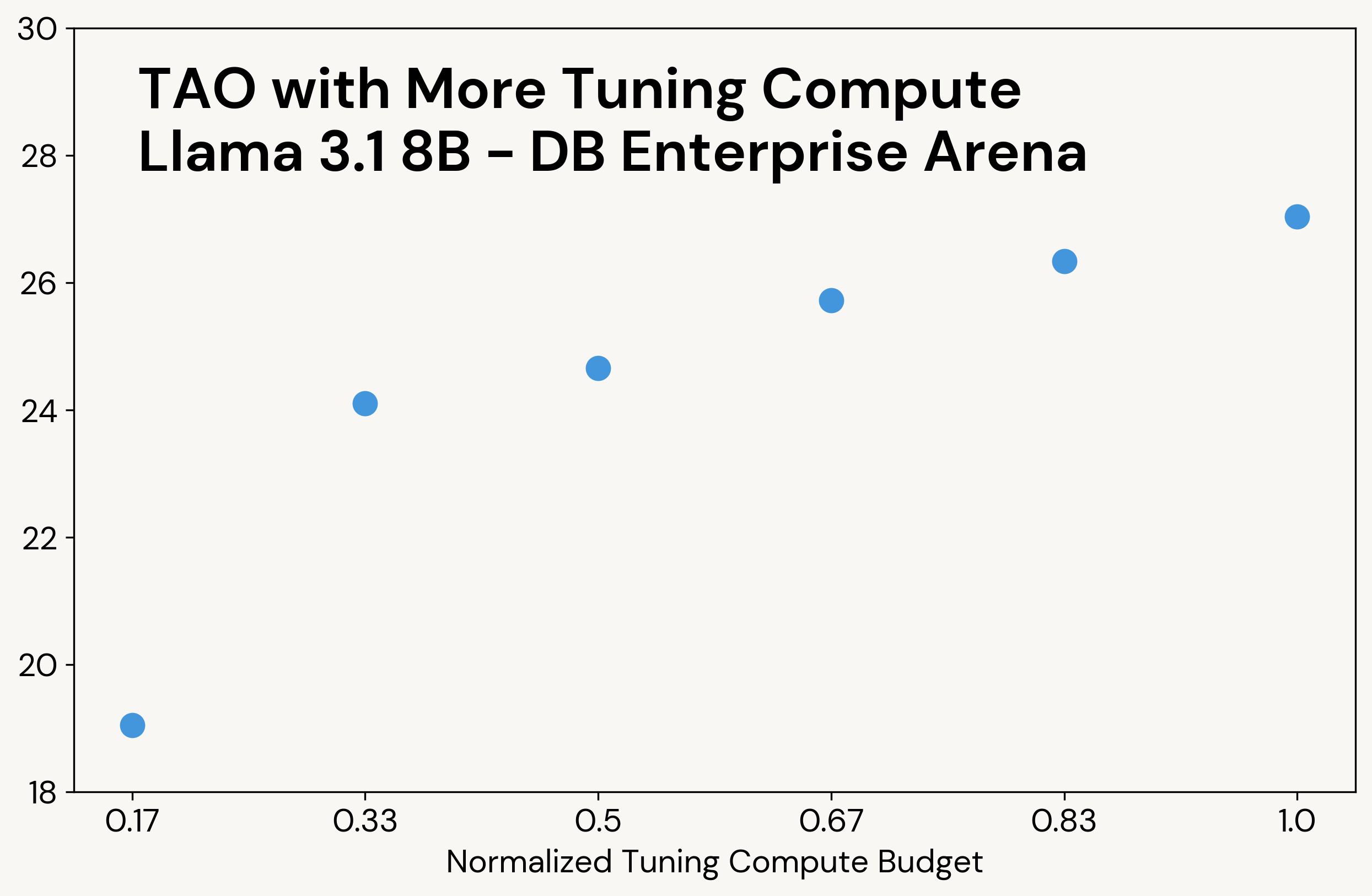
- Die Erhöhung des Rechenbudgets von TAO zur Optimierungszeit führt zu besserer Modellqualität bei gleichen Daten, während die Inferenzkosten des optimierten Modells gleich bleiben.
Abbildung 1 zeigt, wie TAO Llama-Modelle bei drei Unternehmensaufgaben verbessert: FinanceBench, DB Enterprise Arena und BIRD-SQL (unter Verwendung des Databricks SQL-Dialekts)². TAO übertrifft trotz des ausschließlichen Zugriffs auf LLM-Eingaben das traditionelle Fine-Tuning (FT) mit Tausenden von gelabelten Beispielen und bringt Llama in den gleichen Bereich wie teure proprietäre Modelle.
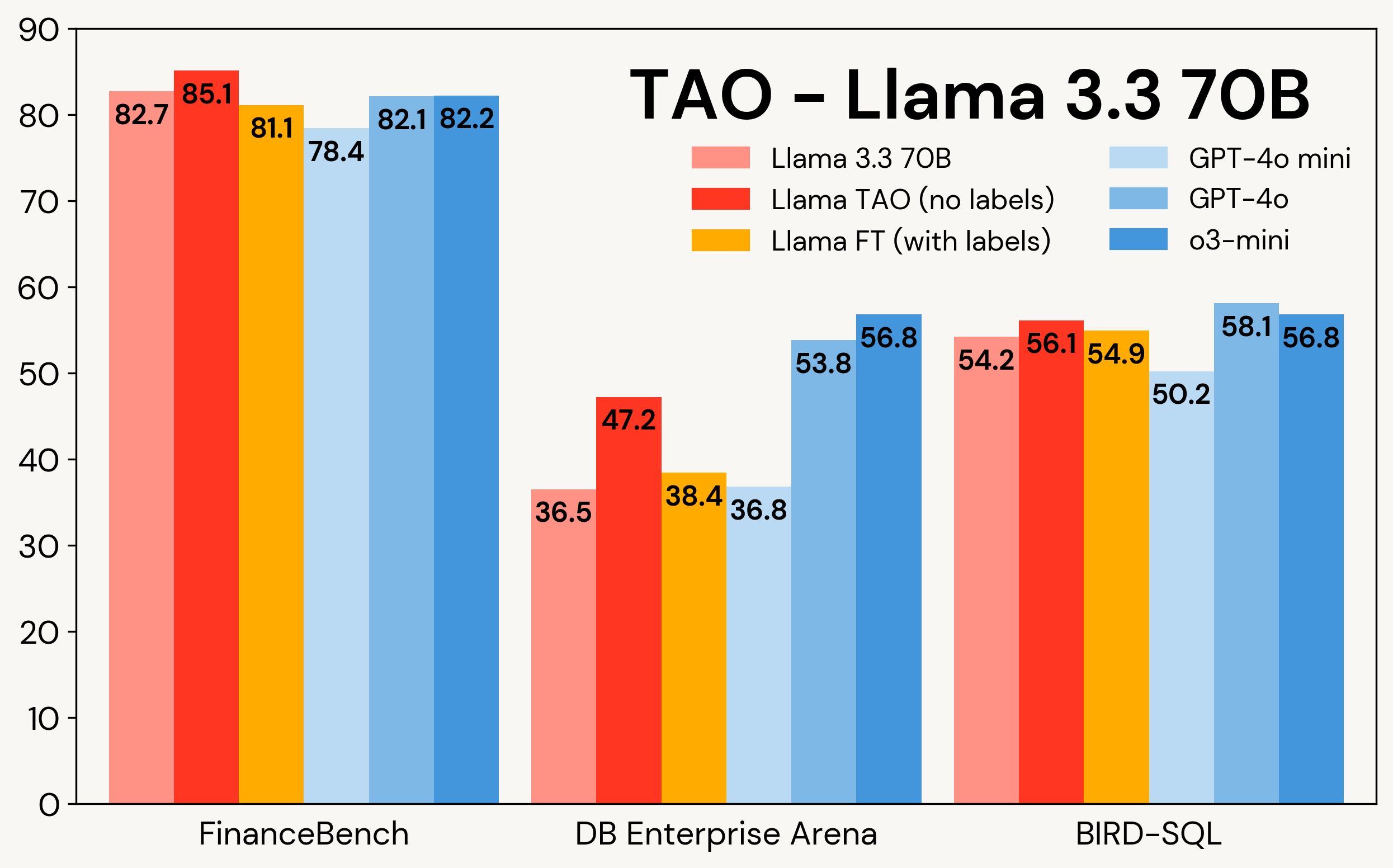
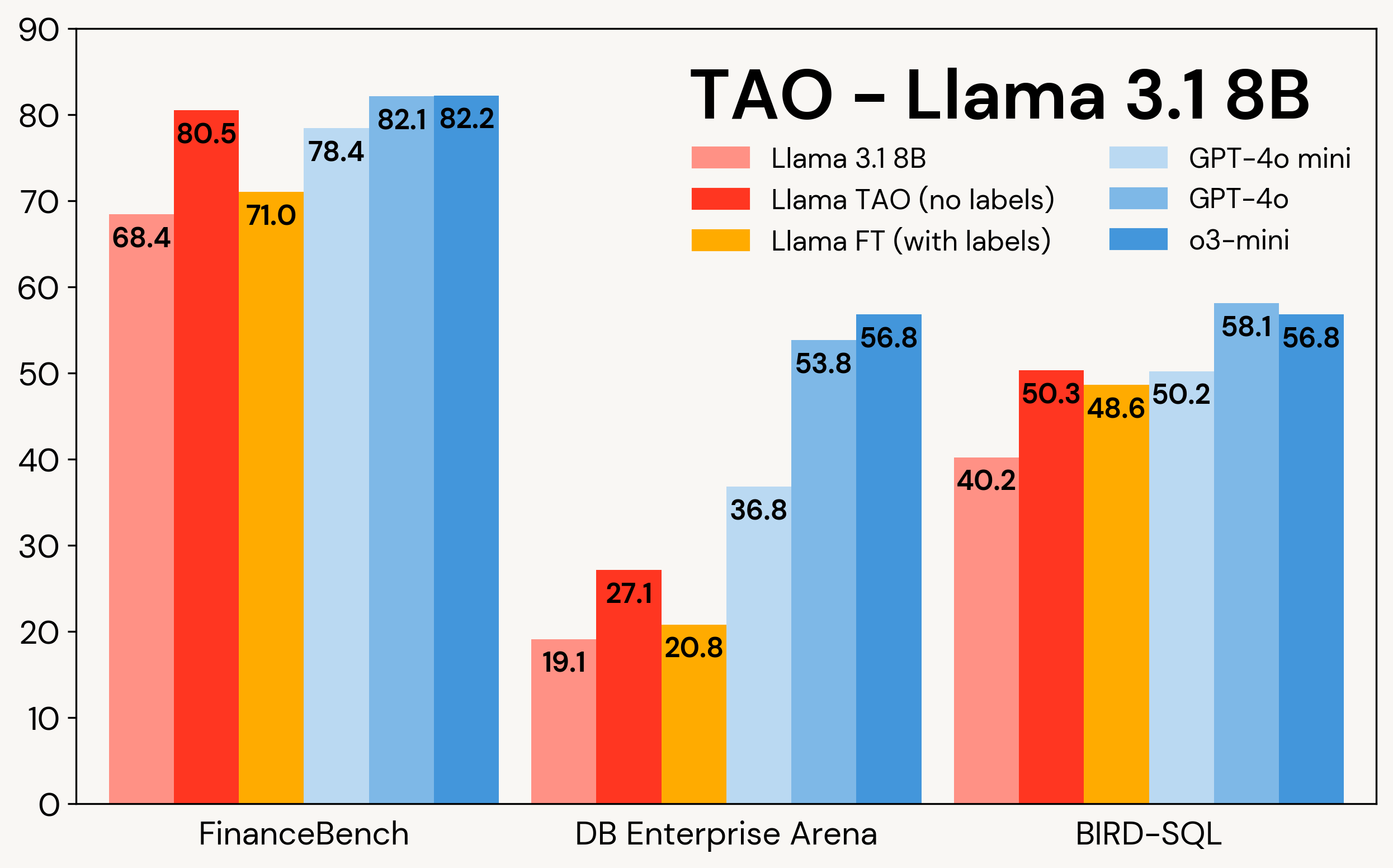
Abbildung 1: TAO auf Llama 3.1 8B und Llama 3.3 70B über drei Unternehmens-Benchmarks. TAO führt zu erheblichen Qualitätsverbesserungen, übertrifft Fine-Tuning und fordert teure proprietäre LLMs heraus.
TAO ist jetzt in der Vorschau für Databricks-Kunden verfügbar, die Llama optimieren möchten, und wird mehrere kommende Produkte unterstützen. Füllen Sie dieses Formular aus, um Ihr Interesse an der Ausprobierung für Ihre Aufgaben im Rahmen der privaten Vorschau zu bekunden. In diesem Beitrag beschreiben wir genauer, wie TAO funktioniert und welche Ergebnisse wir damit erzielt haben.
Wie funktioniert TAO? Test-Zeit-Rechenleistung und Reinforcement Learning zur Modelloptimierung nutzen
Anstatt menschlich annotierter Ausgabedaten zu benötigen, besteht die Kernidee von TAO darin, Test-Zeit-Rechenleistung zu nutzen, damit ein Modell plausible Antworten für eine Aufgabe erkunden kann. Anschließend wird Reinforcement Learning verwendet, um ein LLM basierend auf der Bewertung dieser Antworten zu aktualisieren. Diese Pipeline kann mithilfe von Test-Zeit-Rechenleistung anstelle von teurem menschlichem Aufwand skaliert werden, um die Qualität zu verbessern. Darüber hinaus kann sie einfach mit aufgabenspezifischen Erkenntnissen (z. B. benutzerdefinierten Regeln) angepasst werden. Überraschenderweise führt die Anwendung dieser Skalierung mit hochwertigen Open-Source-Modellen in vielen Fällen zu besseren Ergebnissen als menschliche Labels.
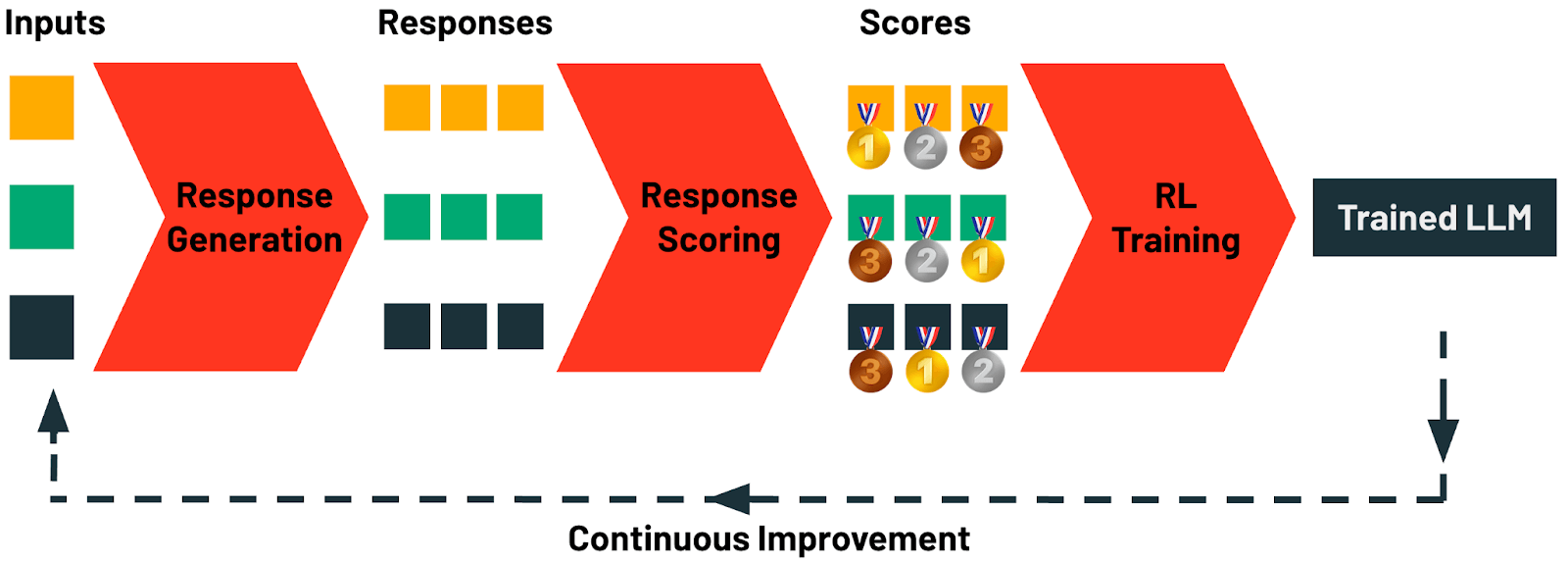
Konkret umfasst TAO vier Stufen:
- Antwortgenerierung: Diese Stufe beginnt mit dem Sammeln von Beispiel-Eingabeaufforderungen oder Abfragen für eine Aufgabe. Auf Databricks können diese Prompts automatisch aus jeder KI-Anwendung über unser AI Gateway gesammelt werden. Jeder Prompt wird dann verwendet, um eine vielfältige Reihe von Kandidatenantworten zu generieren. Hier kann ein breites Spektrum von Generierungsstrategien angewendet werden, das von einfachen Chain-of-Thought-Prompts bis hin zu ausgefeilten Reasoning- und strukturierten Prompting-Techniken reicht.
- Antwortbewertung: In dieser Stufe werden die generierten Antworten systematisch bewertet. Die Bewertungs-Methoden umfassen eine Vielzahl von Strategien, wie z. B. Reward Modeling, präferenzbasierte Bewertung oder aufgabenspezifische Verifizierung mithilfe von LLM-Juroren oder benutzerdefinierten Regeln. Diese Stufe stellt sicher, dass jede generierte Antwort quantitativ auf Qualität und Übereinstimmung mit den Kriterien bewertet wird.
- Reinforcement Learning (RL)-Training: In der letzten Stufe wird ein RL-basierter Ansatz angewendet, um das LLM zu aktualisieren und das Modell so zu steuern, dass es Ausgaben produziert, die eng mit den in der vorherigen Stufe identifizierten, hoch bewerteten Antworten übereinstimmen. Durch diesen adaptiven Lernprozess verfeinert das Modell seine Vorhersagen zur Qualitätssteigerung.
- Kontinuierliche Verbesserung: Die einzige Datenquelle, die TAO benötigt, sind Beispiel-LLM-Eingaben. Benutzer erstellen diese Daten natürlich durch die Interaktion mit einem LLM. Sobald Ihr LLM bereitgestellt ist, beginnen Sie mit der Generierung von Trainingsdaten für die nächste Runde von TAO. Auf Databricks kann Ihr LLM dank TAO mit zunehmender Nutzung besser werden.
Entscheidend ist, dass TAO zwar Test-Zeit-Rechenleistung nutzt, dies aber zur Trainierung eines Modells tut, das dann eine Aufgabe direkt mit geringen Inferenzkosten ausführt. Das bedeutet, dass die von TAO produzierten Modelle die gleichen Inferenzkosten und die gleiche Geschwindigkeit wie das ursprüngliche Modell haben – erheblich weniger als Test-Zeit-Rechenleistungsmodelle wie o1, o3 und R1. Wie unsere Ergebnisse zeigen, können effiziente Open-Source-Modelle, die mit TAO trainiert wurden, führende proprietäre Modelle in Bezug auf die Qualität herausfordern.
TAO bietet eine leistungsstarke neue Methode im Werkzeugkasten zur Optimierung von KI-Modellen. Im Gegensatz zum Prompt Engineering, das langsam und fehleranfällig ist, und zum Fine-Tuning, das die Erstellung teurer und qualitativ hochwertiger menschlicher Labels erfordert, ermöglicht TAO KI-Ingenieuren, großartige Ergebnisse zu erzielen, indem sie einfach repräsentative Eingabebeispiele ihrer Aufgabe bereitstellen.
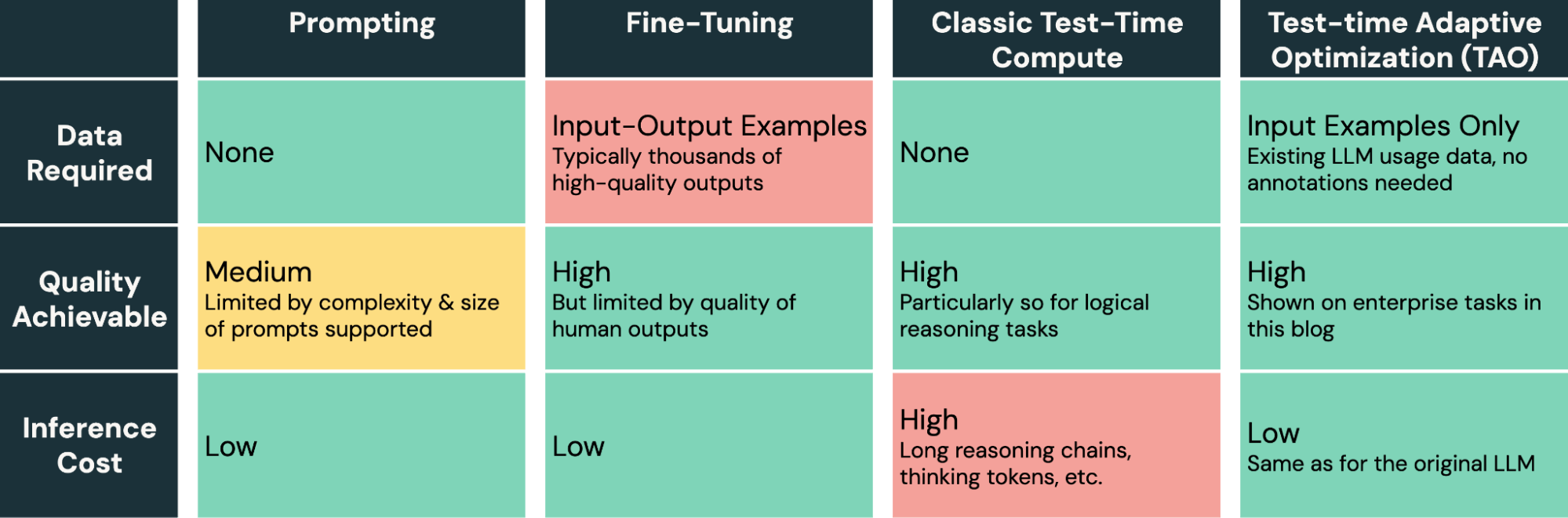
TAO ist eine äußerst flexible Methode, die bei Bedarf angepasst werden kann, aber unsere Standardimplementierung in Databricks funktioniert bei vielfältigen Unternehmensaufgaben gut. Im Kern unserer Implementierung stehen neue Reinforcement Learning- und Reward Modeling-Techniken, die unser Team entwickelt hat und die es TAO ermöglichen, durch Exploration zu lernen und dann das zugrunde liegende Modell mithilfe von RL zu optimieren. Ein Bestandteil von TAO ist beispielsweise ein benutzerdefiniertes Reward-Modell, das wir für Unternehmensaufgaben trainiert haben, DBRM, das genaue Bewertungssignale für eine Vielzahl von Aufgaben liefern kann.
Verbesserung der Aufgabenleistung mit TAO
In diesem Abschnitt gehen wir näher darauf ein, wie wir TAO zur Optimierung von LLMs für spezialisierte Unternehmensaufgaben eingesetzt haben. Wir haben drei repräsentative Benchmarks ausgewählt, darunter beliebte Open-Source-Benchmarks und interne, die wir im Rahmen unserer Domain Intelligence Benchmark Suite (DIBS) entwickelt haben.

Für jede Aufgabe haben wir mehrere Ansätze evaluiert:
- Verwendung eines Open-Source-Llama-Modells (Llama 3.1-8B oder Llama 3.3-70B) ohne weitere Anpassung.
- Fine-Tuning auf Llama. Dazu haben wir große, realistische Eingabe-Ausgabe-Datensätze mit Tausenden von Beispielen verwendet oder erstellt, was normalerweise erforderlich ist, um mit Fine-Tuning eine gute Leistung zu erzielen. Dazu gehörten:
- 7200 synthetische Fragen zu SEC-Dokumenten für FinanceBench.
- 4800 von Menschen geschriebene Eingaben für DB Enterprise Arena.
- 8137 Beispiele aus dem BIRD-SQL-Trainingsdatensatz, modifiziert für den Databricks SQL-Dialekt.
- TAO auf Llama, nur mit den Eingabebeispielen aus unseren Fine-Tuning-Datensätzen, aber ohne die Ausgaben, und unter Verwendung unseres DBRM-Reward-Modells mit Fokus auf Unternehmensanwendungen. DBRM selbst wird nicht auf diesen Benchmarks trainiert.
- Hochwertige proprietäre LLMs – GPT 4o-mini, GPT 4o und o3-mini.
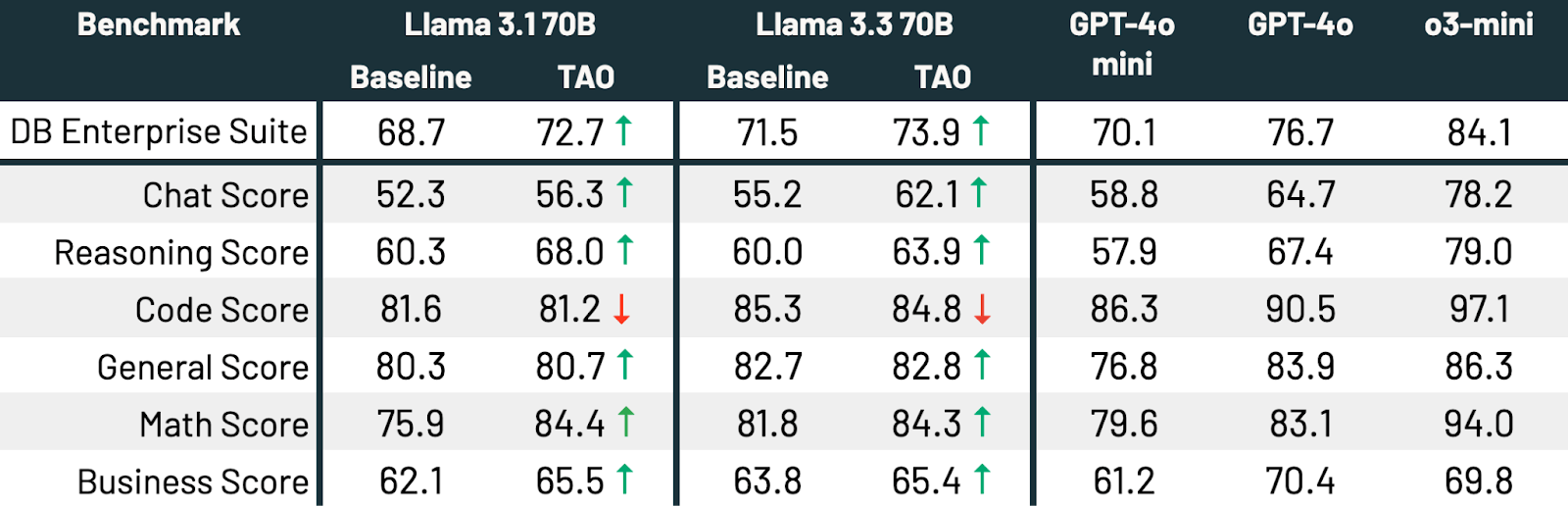
Wie in Tabelle 3 gezeigt, verbessert TAO über alle drei Benchmarks und beide Llama-Modelle hinweg die Leistung des Basis-Llama-Modells signifikant, sogar über die des Fine-Tunings hinaus.

Ähnlich wie bei klassischem Test-Time-Compute liefert TAO qualitativ hochwertigere Ergebnisse, wenn mehr Rechenleistung zur Verfügung steht (siehe Abbildung 3 als Beispiel). Im Gegensatz zum Test-Time-Compute wird diese zusätzliche Rechenleistung jedoch nur während der Tuning-Phase verwendet; das endgültige LLM hat die gleichen Inferenzkosten wie das ursprüngliche LLM. Beispielsweise erzeugt o3-mini 5-10x mehr Ausgabetokens als die anderen Modelle bei unseren Aufgaben, was zu proportional höheren Inferenzkosten führt, während TAO die gleichen Inferenzkosten wie das ursprüngliche Llama-Modell hat.
Verbesserung der Multitask-Intelligenz mit TAO
Bisher haben wir TAO verwendet, um LLMs für einzelne, eng definierte Aufgaben wie die SQL-Generierung zu verbessern. Da Agenten jedoch immer komplexer werden, benötigen Unternehmen zunehmend LLMs, die mehr als eine Aufgabe ausführen können. In diesem Abschnitt zeigen wir, wie TAO die Modellleistung über eine Reihe von Unternehmensaufgaben hinweg breit verbessern kann.
In diesem Experiment haben wir 175.000 Prompts gesammelt, die eine Vielzahl von Unternehmensaufgaben widerspiegeln, darunter Codierung, Mathematik, Fragenbeantwortung, Dokumentenverständnis und Chat. Anschließend haben wir TAO auf Llama 3.1 70B und Llama 3.3 70B ausgeführt. Schließlich haben wir eine Reihe von unternehmensrelevanten Aufgaben getestet, darunter gängige LLM-Benchmarks (z. B. Arena Hard, LiveBench, GPQA Diamond, MMLU Pro, HumanEval, MATH) und interne Benchmarks in mehreren für Unternehmen relevanten Bereichen.
TAO verbessert die Leistung beider Modelle sinnvoll[t][u]. Llama 3.3 70B und Llama 3.1 70B verbessern sich um 2,4 bzw. 4,0 Prozentpunkte. TAO bringt Llama 3.3 70B bei Unternehmensaufgaben signifikant näher an GPT-4o heran[v][w]. All dies wird ohne Kosten für menschliche Beschriftungen erreicht, nur mit repräsentativen LLM-Nutzungsdaten und unserer Produktionsimplementierung von TAO. Die Qualität verbessert sich bei allen Subscores, außer bei der Codierung, wo die Leistung statisch ist.
TAO in der Praxis verwenden
TAO ist eine leistungsstarke Tuning-Methode, die bei vielen Aufgaben überraschend gut funktioniert, indem sie Test-Time-Compute nutzt. Um sie erfolgreich für Ihre eigenen Aufgaben einzusetzen, benötigen Sie:
- Ausreichend Beispiel-Inputs für Ihre Aufgabe (mehrere Tausend), entweder gesammelt aus einer bereitgestellten KI-Anwendung (z. B. Anfragen an einen Agenten) oder synthetisch generiert.
- Eine ausreichend genaue Bewertungsmethode: Für Databricks-Kunden ist ein leistungsfähiges Werkzeug hier unser benutzerdefiniertes Belohnungsmodell, DBRM, das unsere Implementierung von TAO antreibt. Sie können DBRM jedoch mit benutzerdefinierten Bewertungsregeln oder Verifizierern ergänzen, falls diese für Ihre Aufgabe relevant sind.
Eine Best Practice, die TAO und andere Methoden zur Modellverbesserung ermöglicht, ist die Erstellung eines Daten-Flywheels für Ihre KI-Anwendungen. Sobald Sie eine KI-Anwendung bereitstellen, können Sie über Dienste wie Databricks Inference Tables Inputs, Modellausgaben und andere Ereignisse sammeln. Sie können dann nur die Inputs verwenden, um TAO auszuführen. Je mehr Leute Ihre Anwendung nutzen, desto mehr Daten haben Sie zum Trainieren, und dank TAO wird Ihr LLM immer besser.
Fazit und Erste Schritte auf Databricks
In diesem Blog haben wir Test-time Adaptive Optimization (TAO) vorgestellt, eine neue Modell-Tuning-Technik, die hochwertige Ergebnisse ohne die Notwendigkeit von gelabelten Daten erzielt. Wir haben TAO entwickelt, um eine zentrale Herausforderung zu lösen, mit der Enterprise-Kunden konfrontiert waren: Ihnen fehlten die für das Standard-Fine-Tuning benötigten gelabelten Daten. TAO nutzt Test-Time-Compute und Reinforcement Learning, um Modelle mithilfe von Daten zu verbessern, die Unternehmen bereits haben, wie z. B. Eingabebeispiele. Dies erleichtert die Verbesserung der Qualität jeder bereitgestellten KI-Anwendung und die Reduzierung der Kosten durch die Verwendung kleinerer Modelle. TAO ist eine äußerst flexible Methode, die die Leistungsfähigkeit von Test-Time-Compute für die spezialisierte KI-Entwicklung zeigt, und wir glauben, dass sie Entwicklern ein leistungsfähiges und einfaches neues Werkzeug neben Prompting und Fine-Tuning bietet.
Databricks-Kunden nutzen TAO auf Llama bereits in der privaten Vorschau. Füllen Sie dieses Formular aus, um Ihr Interesse an der Ausprobierung für Ihre Aufgaben im Rahmen der privaten Vorschau zu bekunden. TAO wird auch in viele unserer bevorstehenden KI-Produktupdates und -einführungen integriert – bleiben Sie dran!
¹ Autoren: Raj Ammanabrolu, Ashutosh Baheti, Jonathan Chang, Xing Chen, Ta-Chung Chi, Brian Chu, Brandon Cui, Erich Elsen, Jonathan Frankle, Ali Ghodsi, Pallavi Koppol, Sean Kulinski, Jonathan Li, Dipendra Misra, Jose Javier Gonzalez Ortiz, Sean Owen, Mihir Patel, Mansheej Paul, Cory Stephenson, Alex Trott, Ziyi Yang, Matei Zaharia, Andy Zhang, Ivan Zhou
² Wir verwenden o3-mini-medium in diesem Blog.
³ Dies ist der BIRD-SQL-Benchmark, modifiziert für das SQL-Dialekt und die Produkte von Databricks.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.