AiChemy: Nächste Generation von Agenten mit MCP, Skills und benutzerdefinierten Daten für die Wirkstoffentdeckung
AiChemy beschleunigt die Medikamentenentdeckung durch die Integration benutzerdefinierter und externer Daten (OpenTargets, PubChem, PubMed) über ein Multi-Agenten-System, das MCP, Skills, Vektorsuche und Genie auf Databricks nutzt
von Yen Low und Sean Zhang
- Ein Leitfaden zum Erstellen von AiChemy, einem Multi-Agenten-System auf Databricks, das externes Wissen (OpenTargets, PubChem, PubMed) über das Model Context Protocol (MCP) mit strukturierten und unstrukturierten Daten auf Databricks integriert.
- Die Herausforderung, die es löst: Es beschleunigt die interdisziplinäre Medikamentenentdeckungsforschung, indem es die autonome Zusammenarbeit zwischen verschiedenen KI-Agenten ermöglicht, damit diese riesige, disparate Datensätze durchsuchen und nachvollziehbare, evidenzbasierte Ergebnisse liefern können.
- Ergebnisse: Forscher können Krankheitsziele identifizieren, Medikamentenkandidaten bewerten, detaillierte Eigenschaften abrufen und Sicherheitsbewertungen durchführen, was zu einer effizienteren Medikamentenentdeckung und Lead-Generierung führt.
Multi-Agent-Systeme beschleunigen die interdisziplinäre Forschung
Stellen Sie sich Multi-Agenten-KI-Systeme vor, die wie ein Team von interdisziplinären Experten zusammenarbeiten und autonom riesige Datensätze durchforsten, um neue Muster und Hypothesen aufzudecken. Dies ist jetzt bequem mit dem Model Context Protocol (MCP) erreichbar, einem neuen Standard für die einfache Integration verschiedener Datenquellen und Tools. Das wachsende Ökosystem von MCP-Servern – von Wissensdatenbanken bis hin zu Berichtsgeneratoren – bietet endlose Möglichkeiten.
Was AiChemy tut
Lernen Sie AiChemy, einen Multi-Agenten-Assistenten kennen, der externe MCP-Server wie OpenTargets, PubChem und PubMed mit Ihren eigenen chemischen Bibliotheken auf Databricks kombiniert, sodass die kombinierten Wissensdatenbanken besser gemeinsam analysiert und interpretiert werden können. Es verfügt außerdem über Skills, die optional geladen werden können, um detaillierte Anweisungen für die Erstellung aufgabenspezifischer Berichte zu liefern, die konsistent für Forschungs-, Regulierungs- oder Geschäftsanforderungen formatiert sind.
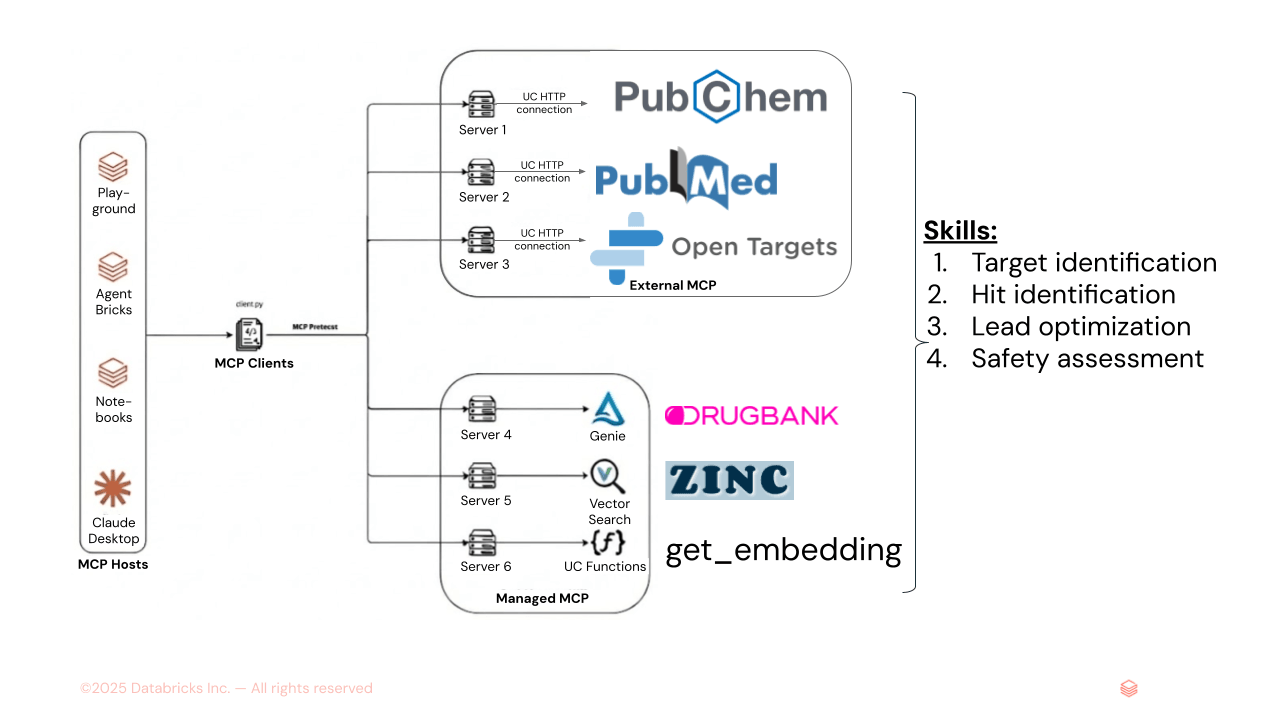
Abbildung 1. AiChemy ist ein Multi-Agenten-Supervisor, der externe MCP-Server PubChem, PubMed und OpenTargets sowie von Databricks verwaltete MCP-Server von Genie Space (Text-zu-SQL für strukturierte DrugBank-Daten) und AI Search (für unstrukturierte Daten wie ZINC-Moleküleinbettungen) umfasst. Skills können auch geladen werden, um die Aufgabenreihenfolge und Berichtsformatierung und -stil festzulegen, um konsistente Ergebnisse zu gewährleisten.
Zu seinen Hauptfunktionen gehören die Identifizierung von Krankheitszielen und Wirkstoffkandidaten, die Abfrage detaillierter chemischer und pharmakokinetischer Eigenschaften sowie die Bereitstellung von Sicherheits- und Toxizitätsbewertungen. Entscheidend ist, dass AiChemy seine Ergebnisse mit unterstützenden Beweisen untermauert, die auf überprüfbare Datenquellen zurückgeführt werden können, was es ideal für die Forschung macht.
Anwendungsfall 1: Krankheitsmechanismen verstehen, druggable Targets finden und Lead-Generierung
Das Panel "Guided Tasks" (Geführte Aufgaben) bietet die notwendigen Prompts und Agent Skills, um die wichtigsten Schritte in einem Wirkstoffentdeckungs-Workflow von Krankheit -> Ziel -> Medikament -> Literaturvalidierung durchzuführen.
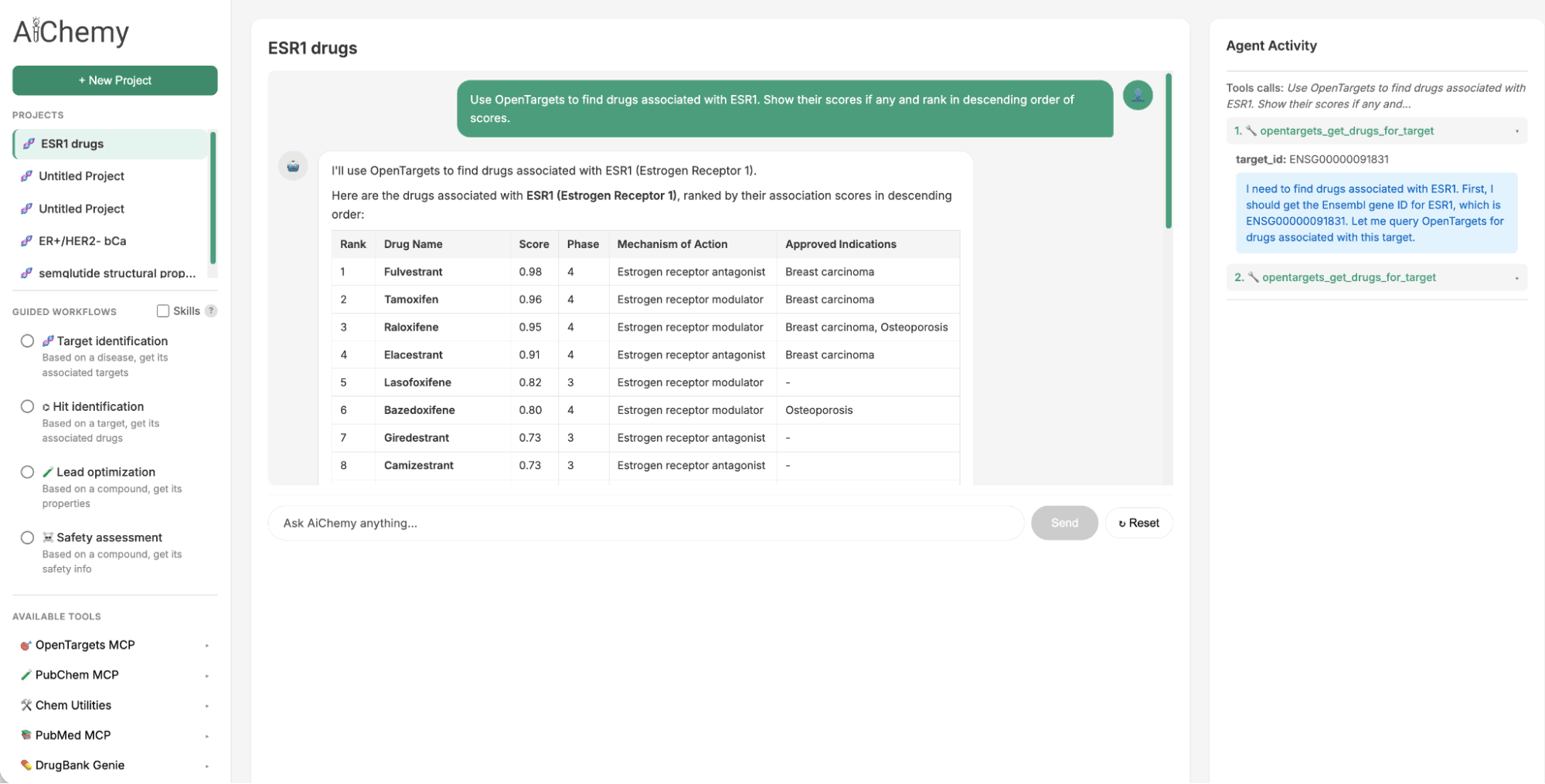
- Therapeutische Ziele identifizieren: Ausgehend von einem bestimmten Krankheitssubtyp, wie z. B. Estrogenrezeptor-positivem (ER+)/HER2-negativem (HER2-) Brustkrebs (wobei ER und HER2 wichtige Proteinbiomarker sind), identifizieren Sie assoziierte therapeutische Ziele (z. B. ESR1).
- Assoziierte Medikamente finden: Verwenden Sie das identifizierte Ziel (z. B. ESR1), um potenzielle Wirkstoffkandidaten zu finden.
- Mit Literatur validieren: Überprüfen Sie für einen gegebenen Wirkstoffkandidaten (z. B. Camizestrant) die wissenschaftliche Literatur auf unterstützende Beweise.
Anwendungsfall 2: Lead-Generierung durch chemische Ähnlichkeit
Um einen Nachfolger für den 2023 zugelassenen oralen selektiven Estrogenrezeptormodulator (SERM) Elacestrant zu identifizieren, können wir die chemische Ähnlichkeit nutzen. Wir durchsuchen die große ZINC15-Chemikalienbibliothek nach medikamentenähnlichen Molekülen, die strukturell Elacestrant ähneln, da Quantitative Struktur-Wirkungs-Beziehungs-Prinzipien (QSAR) nahelegen, dass sie ähnliche Eigenschaften teilen. Dies wird durch Abfragen der Databricks AI Search erreicht, die die 1024-Bit Extended-Connectivity Fingerprint (ECFP)-Moleküleinbettung von Elacestrant (als Abfragevektor) verwendet, um die ähnlichsten Einbettungen im 250.000 Moleküle umfassenden Index von ZINC zu finden.
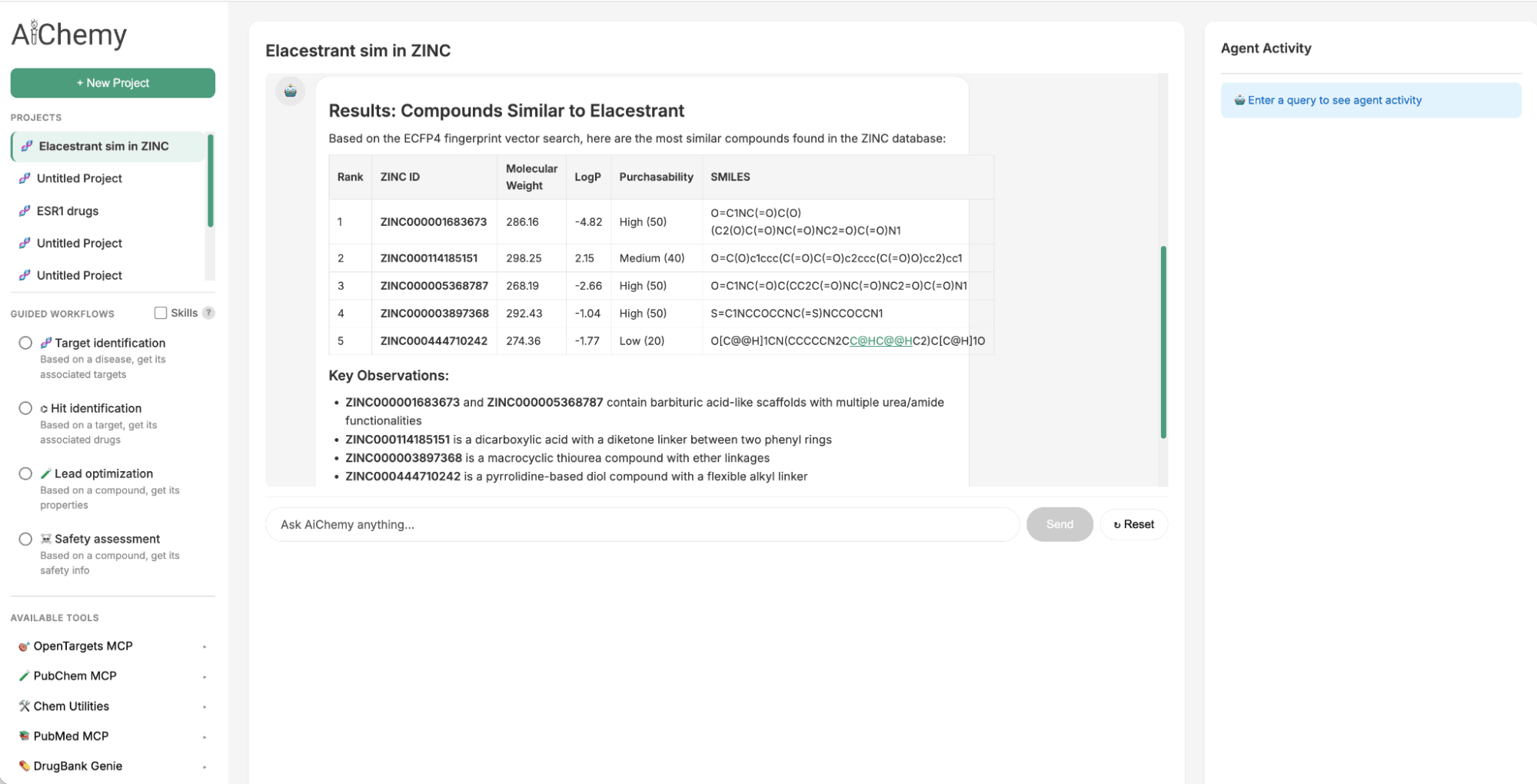
Abbildung 2. AiChemy umfasst die Vektorsuche der ZINC-Datenbank mit 250.000 kommerziell erhältlichen Molekülen. Dies ermöglicht uns die Generierung von Leitstrukturen durch chemische Ähnlichkeit. In diesem Screenshot haben wir AiChemy gebeten, in der ZINC-Vektorsuche die Moleküle zu finden, die Elacestrant am ähnlichsten sind, basierend auf der ECFP4-Moleküleinbettung.
Erstellen Sie Ihren eigenen Multi-Agenten-Forschungs-Supervisor
Wir werden einen Multi-Agenten-Supervisor auf Databricks anpassen, indem wir öffentliche MCP-Server mit proprietären Daten auf Databricks integrieren. Dazu haben Sie die Möglichkeit, entweder No-Code Agent Bricks oder Coding-Optionen wie Notebooks zu verwenden. Die Databricks Playground ermöglicht schnelles Prototyping und Iteration Ihrer Agenten.
Schritt 1: Vorbereiten der Komponenten für den Multi-Agenten-Supervisor
Das Multi-Agenten-System hat 5 Worker:
- OpenTargets: externer MCP-Server eines Wissensgraphen für Krankheiten, Ziele und Medikamente
- PubMed: externer MCP-Server für biomedizinische Literatur
- PubChem: externer MCP-Server für chemische Verbindungen
- Drug Library (Genie): Eine chemische Bibliothek mit strukturierten Medikamenteneigenschaften, die zu einem Genie Space gemacht wurde, um Text-zu-SQL-Funktionen bereitzustellen.
- Chemical Library (AI Search): Eine proprietäre Bibliothek unstrukturierter chemischer Daten mit Molekülfingerabdruck-Einbettungen, die als Vektorindex vorbereitet wurde, um die Ähnlichkeitssuche anhand von Einbettungen zu erleichtern.
Schritt 1a: Sichere Verbindung zu öffentlichen MCP-Servern über Unity Catalog (UC) Connections in der UI oder in einem Databricks Notebook (z. B. 4_connect_ext_mcp_opentarget.py).
Schritt 1b: Stellen Sie sicher, dass Ihre strukturierten Tabellen (z. B. DrugBank) mithilfe der Genie Space mit Text-zu-SQL-Funktionalität in der UI umgewandelt werden. Siehe 1_load_drugbank and descriptors.py
Schritt 1c: Stellen Sie sicher, dass Ihre unstrukturierte chemische Bibliothek als Vektorindex in der UI oder in einem Notebook erstellt wird, um die Ähnlichkeitssuche zu ermöglichen. Siehe 2_create VS zinc15.py
Schritt 2 (Einfache Option): Erstellen Sie den Multi-Agenten-Supervisor mit dem No-Code Supervisor Agent in 2 Minuten
Um sie zusammenzustellen, probieren Sie die No-Code Agent Bricks aus, die über die Benutzeroberfläche einen Supervisor-Agenten mit den obigen Komponenten erstellen und ihn in wenigen Minuten an einen REST-API-Endpunkt bereitstellen.
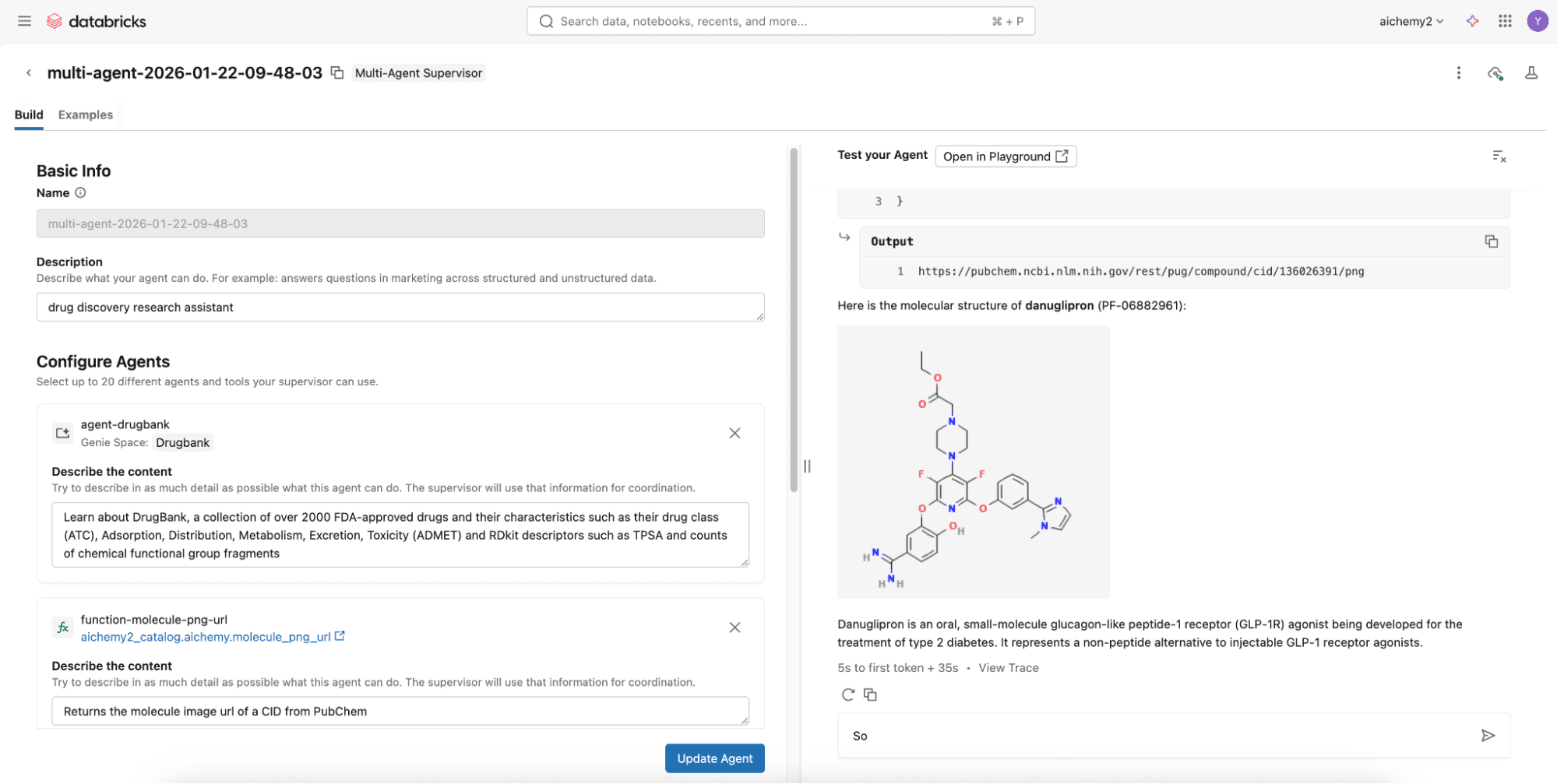
Schritt 2 (Erweiterte Option): Erstellen Sie den Multi-Agent-Supervisor mit Databricks Notebooks
Für erweiterte Funktionen wie Agentenspeicher und Skills entwickeln Sie einen Langgraph-Supervisor auf Databricks Notebooks, um eine Verbindung zu Lakebase, der Databricks Serverless Postgres-Datenbank, herzustellen. Sehen Sie sich dieses Code-Repository an, in dem Sie die Multi-Agent-Komponenten (siehe Schritt 1) einfach in der config.yml definieren können.
Sobald die config.yml definiert ist, können Sie den Multi-Agent-Supervisor als MLflow AgentServer (FastAPI-Wrapper) mit einer React-Webbenutzeroberfläche (UI) bereitstellen. Stellen Sie beide über die Databricks Apps UI oder die Databricks CLI bereit. Legen Sie die entsprechenden Berechtigungen für Benutzer fest, um die Databricks App zu verwenden, und für das Service Principal der App, um auf die zugrunde liegenden Ressourcen zuzugreifen (z. B. Experiment für die Protokollierung von Traces, Secret Scope, falls vorhanden).
Schritt 3: Bewerten und überwachen Sie Ihren Agenten
Jede Aufrufung des Agenten wird automatisch protokolliert und gemäß den OpenTelemetry-Standards in einem Databricks MLflow-Experiment getraced. Dies ermöglicht eine einfache Bewertung der Antworten offline oder online, um den Agenten im Laufe der Zeit zu verbessern. Darüber hinaus verwendet Ihr bereitgestellter Multi-Agent den LLM hinter AI Gateway, sodass Sie die Vorteile zentralisierter Governance, integrierter Schutzmaßnahmen und vollständiger Beobachtbarkeit für die Produktionsreife nutzen können.
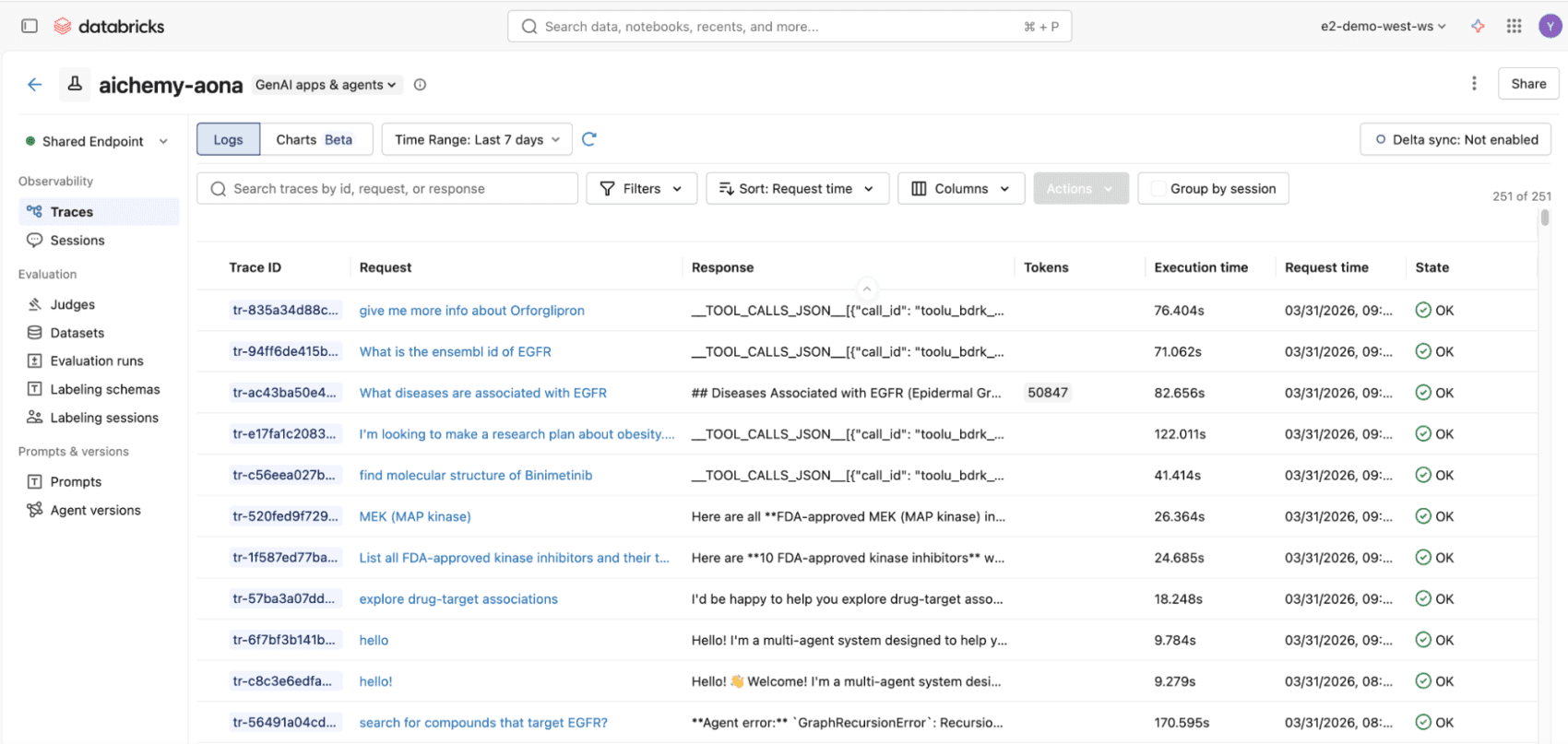
Abbildung 3. Alle Aufrufe an den Multi-Agenten, sei es über die React-Benutzeroberfläche oder die REST-API, werden gemäß den OpenTelemetry-Standards in MLflow-Traces protokolliert, um eine End-to-End-Beobachtbarkeit zu gewährleisten.
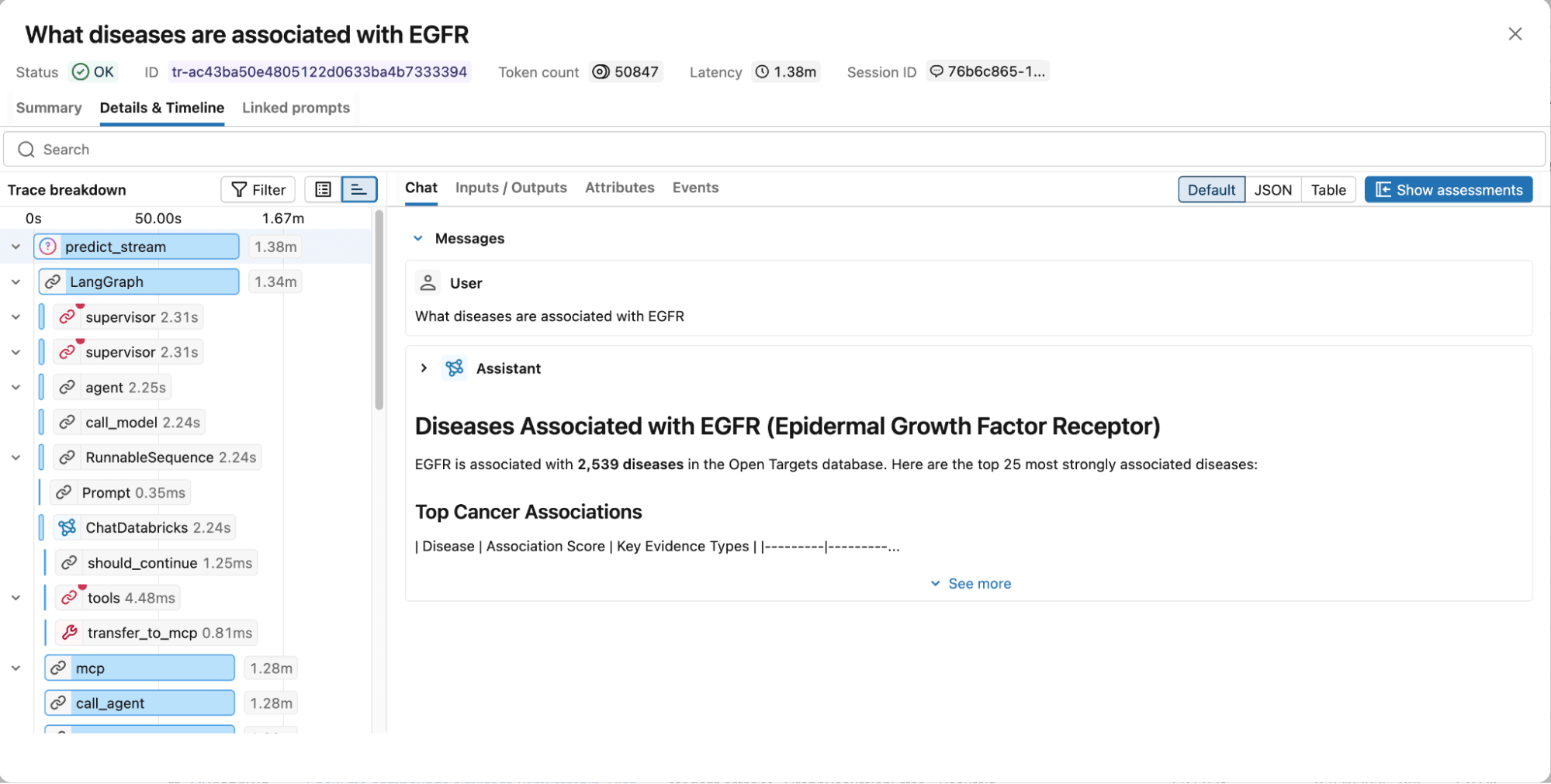
Abbildung 4. MLflow-Traces erfassen den vollständigen Ausführungs-Graphen, einschließlich der Begründungsschritte, Tool-Aufrufe, abgerufenen Dokumente, Latenz und Token-Nutzung zur einfachen Fehlerbehebung und Optimierung.
Nächste Schritte
Wir laden Sie ein, die AiChemy Web-App und das Github-Repository zu erkunden. Beginnen Sie mit dem Erstellen Ihres benutzerdefinierten Multi-Agenten-Systems mit dem intuitiven No-Code Agent Bricks-Framework auf Databricks, damit Sie aufhören können zu suchen und mit der Entdeckung beginnen können!

(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.