Ankündigung von Automatic Liquid Clustering
Optimiertes Datenlayout für bis zu 10x schnellere Abfragen
von Cindy Jiang, Supun Nakandala, Naga Raju Bhanoori, Eric Liang und Parimarjan Negi
- Automatic Liquid Clustering, angetrieben durch Predictive Optimization, automatisiert die Auswahl von Clustering-Schlüsseln, um die Abfrageleistung kontinuierlich zu verbessern und die Kosten zu senken.
- Robuste Auswahlprozesse und kontinuierliche Überwachung halten Tabellen optimiert.
- Die Gesamtbetriebskosten (TCO) werden minimiert, indem automatisch bewertet wird, ob die Leistungssteigerungen die Kosten überwiegen.
Wir freuen uns, die öffentliche Vorschau von Automatic Liquid Clustering bekannt zu geben, das von Predictive Optimization angetrieben wird. Diese Funktion wendet automatisch Liquid Clustering-Spalten für von Unity Catalog verwaltete Tabellen an und aktualisiert diese, wodurch die Abfrageleistung verbessert und die Kosten gesenkt werden.
Automatic Liquid Clustering vereinfacht die Datenverwaltung, indem die Notwendigkeit manueller Abstimmung entfällt. Zuvor mussten Datenteams das spezifische Datenlayout für jede ihrer Tabellen manuell entwerfen. Jetzt nutzt Predictive Optimization die Leistung von Unity Catalog, um Ihre Daten und Abfragemuster zu überwachen und zu analysieren.
Um Automatic Liquid Clustering zu aktivieren, konfigurieren Sie Ihre UC-verwalteten, unpartitionierten oder Liquid-Tabellen, indem Sie den Parameter CLUSTER BY AUTO setzen.
Nach der Aktivierung analysiert Predictive Optimization, wie Ihre Tabellen abgefragt werden, und wählt intelligent die effektivsten Clustering-Schlüssel basierend auf Ihrer Workload aus. Anschließend clustert es die Tabelle automatisch, um sicherzustellen, dass die Daten für eine optimale Abfrageleistung organisiert sind. Jede Engine, die von der Delta-Tabelle liest, profitiert von diesen Verbesserungen, was zu deutlich schnelleren Abfragen führt. Darüber hinaus passt Predictive Optimization das Clustering-Schema dynamisch an, wenn sich Abfragemuster ändern, wodurch manuelle Abstimmung oder Entscheidungen über das Datenlayout vollständig entfallen, wenn Sie Ihre Delta-Tabellen einrichten.
Während der Private Preview haben Dutzende von Kunden Automatic Liquid Clustering getestet und starke Ergebnisse erzielt. Viele schätzten seine Einfachheit und Leistungssteigerungen, wobei einige es bereits für ihre Gold-Tabellen verwendeten und planten, es auf alle Delta-Tabellen auszuweiten.
Vorschau-Kunden wie Healthrise berichten von signifikanten Verbesserungen der Abfrageleistung mit Automatic Liquid Clustering:
„Wir haben Automatic Liquid Clustering auf alle unsere Gold-Tabellen angewendet. Seitdem liefen unsere Abfragen bis zu 10x schneller. Alle unsere Workloads sind viel effizienter geworden, ohne dass manuelle Arbeit bei der Gestaltung des Datenlayouts oder der Ausführung von Wartungsarbeiten erforderlich war.“ —Li Zou, Principal Data Engineer, Brian Allee, Director, Data Services | Technology & Analytics, Healthrise
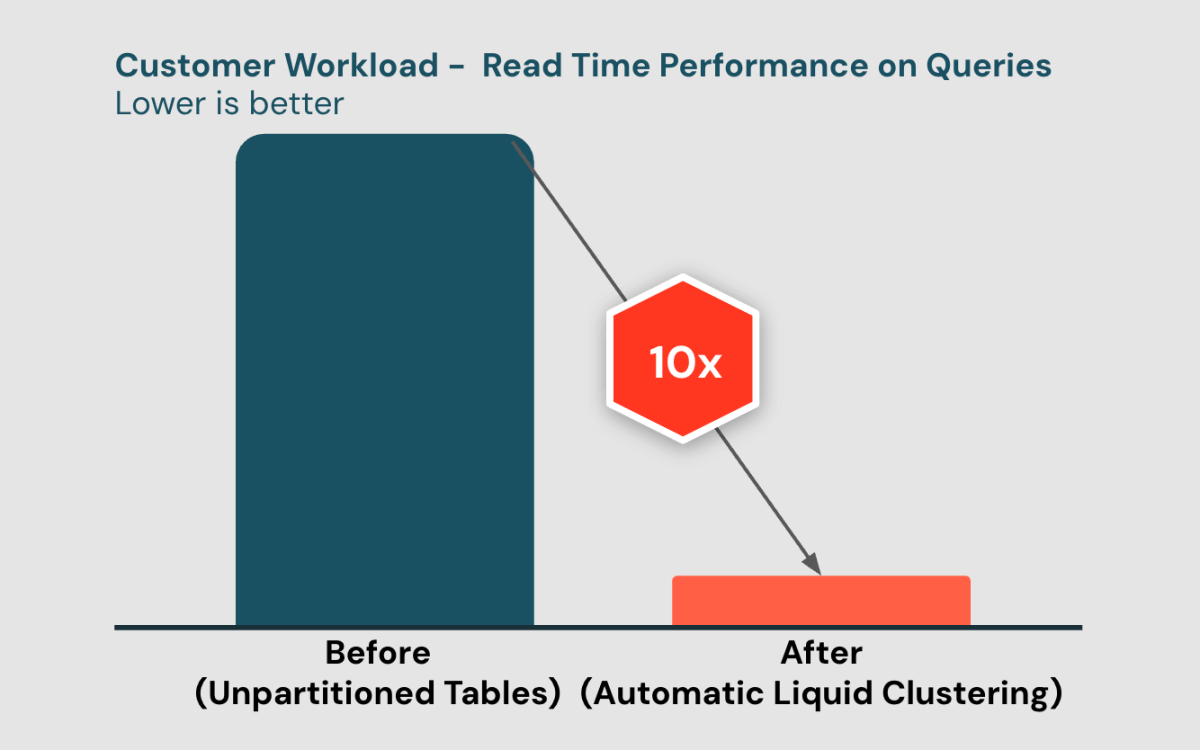
Die Wahl des besten Datenlayouts ist ein schwieriges Problem
Die Anwendung des besten Datenlayouts auf Ihre Tabellen verbessert die Abfrageleistung und Kosteneffizienz erheblich. Traditionell war es für Kunden mit Partitionierung schwierig, die richtige Partitionierungsstrategie zu entwerfen, um Datenverzerrungen und Nebenläufigkeitskonflikte zu vermeiden. Um die Leistung weiter zu verbessern, könnten Kunden ZORDER über die Partitionierung verwenden, aber ZORDER ist sowohl teuer als auch noch komplizierter zu verwalten.
Liquid Clustering vereinfacht Entscheidungen im Zusammenhang mit dem Datenlayout erheblich und bietet die Flexibilität, Clustering-Schlüssel ohne Daten-Rewrites neu zu definieren. Kunden müssen nur Clustering-Schlüssel rein basierend auf Abfragezugriffsmustern auswählen, ohne sich um Kardinalität, Schlüsselreihenfolge, Dateigröße, potenzielle Datenverzerrungen, Nebenläufigkeit und zukünftige Änderungen der Zugriffsmuster kümmern zu müssen. Wir haben mit Tausenden von Kunden zusammengearbeitet, die von einer besseren Abfrageleistung mit Liquid Clustering profitiert haben, und wir haben jetzt über 3000 aktive monatliche Kunden, die jeden Monat über 200 PB Daten in Liquid-geclusterte Tabellen schreiben.
Selbst mit den Fortschritten im Liquid Clustering müssen Sie jedoch immer noch die Spalten auswählen, nach denen Sie Ihre Tabelle clustern möchten, basierend darauf, wie Sie sie abfragen. Datenteams müssen herausfinden:
- Welche Tabellen profitieren von Liquid Clustering?
- Was sind die besten Clustering-Spalten für diese Tabelle?
- Was passiert, wenn sich meine Abfragemuster ändern, wenn sich die Geschäftsanforderungen weiterentwickeln?
Darüber hinaus müssen Data Engineers innerhalb einer Organisation oft mit mehreren nachgelagerten Verbrauchern zusammenarbeiten, um zu verstehen, wie Tabellen abgefragt werden, während sie gleichzeitig mit sich ändernden Zugriffsmustern und sich entwickelnden Schemata Schritt halten. Diese Herausforderung wird exponentiell komplexer, wenn Ihr Datenvolumen mit mehr Analyseanforderungen skaliert.
Wie Automatic Liquid Clustering Ihr Datenlayout weiterentwickelt
Mit Automatic Liquid Clustering kümmert sich Databricks um alle Entscheidungen im Zusammenhang mit dem Datenlayout für Sie – von der Tabellenerstellung über das Clustering Ihrer Daten bis hin zur Weiterentwicklung Ihres Datenlayouts –, sodass Sie sich auf die Gewinnung von Erkenntnissen aus Ihren Daten konzentrieren können.
Sehen wir uns Automatic Liquid Clustering anhand einer Beispieltabelle an.
Betrachten wir eine Tabelle example_tbl, die häufig nach Datum und Kunden-ID abgefragt wird. Sie enthält Daten vom 5. bis 6. Februar und Kunden-IDs A bis F. Ohne jegliche Datenlayoutkonfiguration werden die Daten in Einfügungsreihenfolge gespeichert, was zu folgendem Layout führt:
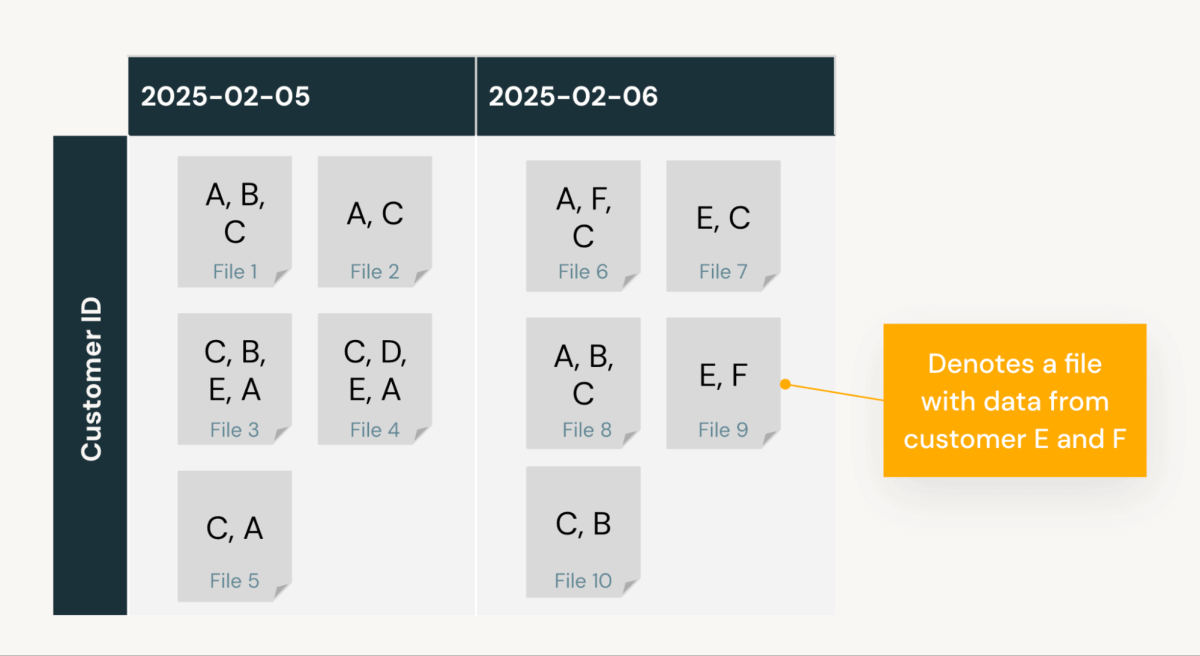
Angenommen, der Kunde führt SELECT * FROM example_tbl WHERE date = '2025-02-05' AND customer_id = 'B' aus. Die Abfrage-Engine nutzt Delta Data Skipping-Statistiken (Min/Max-Werte, Null-Anzahl und Gesamtdatensätze pro Datei), um die relevanten zu scannenden Dateien zu identifizieren. Das Beschneiden unnötiger Dateilesevorgänge ist entscheidend, da es die Anzahl der während der Abfrageausführung gescannten Dateien reduziert, was die Abfrageleistung direkt verbessert und die Rechenkosten senkt. Je weniger Dateien eine Abfrage lesen muss, desto schneller und effizienter wird sie.
In diesem Fall identifiziert die Engine 5 Dateien für den 5. Februar, da die Hälfte der Dateien einen Min/Max-Wert für die Spalte date hat, der diesem Datum entspricht. Da die Data Skipping-Statistiken jedoch nur Min/Max-Werte liefern, haben diese 5 Dateien alle einen Min/Max customer_id, der darauf hindeutet, dass Kunde B irgendwo in der Mitte liegt. Infolgedessen muss die Abfrage alle 5 Dateien scannen, um Einträge für Kunde B zu extrahieren, was zu einer Dateibereinigungsrate von 50 % führt (Lesen von 5 von 10 Dateien).

Wie Sie sehen, liegt das Kernproblem darin, dass die Daten von Kunde B nicht in einer einzigen Datei zusammenliegen. Das bedeutet, dass die Extraktion aller Einträge für Kunde B auch das Lesen einer erheblichen Menge von Einträgen für andere Kunden erfordert.
Gibt es eine Möglichkeit, die Dateibereinigung und die Abfrageleistung hier zu verbessern? Automatic Liquid Clustering kann beides verbessern. Hier ist, wie:
Hinter den Kulissen von Automatic Liquid Clustering: So funktioniert es
Nach der Aktivierung führt Automatic Liquid Clustering kontinuierlich die folgenden drei Schritte aus:
- Sammeln von Telemetriedaten, um festzustellen, ob die Tabelle von der Einführung oder Weiterentwicklung von Liquid Clustering-Schlüsseln profitieren wird.
- Modellieren der Workload, um berechtigte Spalten zu verstehen und zu identifizieren.
- Anwenden der Spaltenauswahl und Weiterentwicklung der Clustering-Schemata basierend auf einer Kosten-Nutzen-Analyse.

Schritt 1: Telemetrieanalyse
Predictive Optimization sammelt und analysiert Abfrage-Scan-Statistiken wie Abfrageprädikate und JOIN-Filter, um festzustellen, ob eine Tabelle von Liquid Clustering profitieren würde.
Bei unserem Beispiel erkennt Predictive Optimization, dass die Spalten 'date' und 'customer_id' häufig abgefragt werden.
Schritt 2: Workload-Modellierung
Predictive Optimization wertet die Abfrage-Workload aus und identifiziert die besten Clustering-Schlüssel, um Data Skipping zu maximieren.
Es lernt aus vergangenen Abfragemustern und schätzt die potenziellen Leistungssteigerungen verschiedener Clustering-Schemata. Durch die Simulation vergangener Abfragen prognostiziert es, wie effektiv jede Option die Menge der gescannten Daten reduzieren würde.
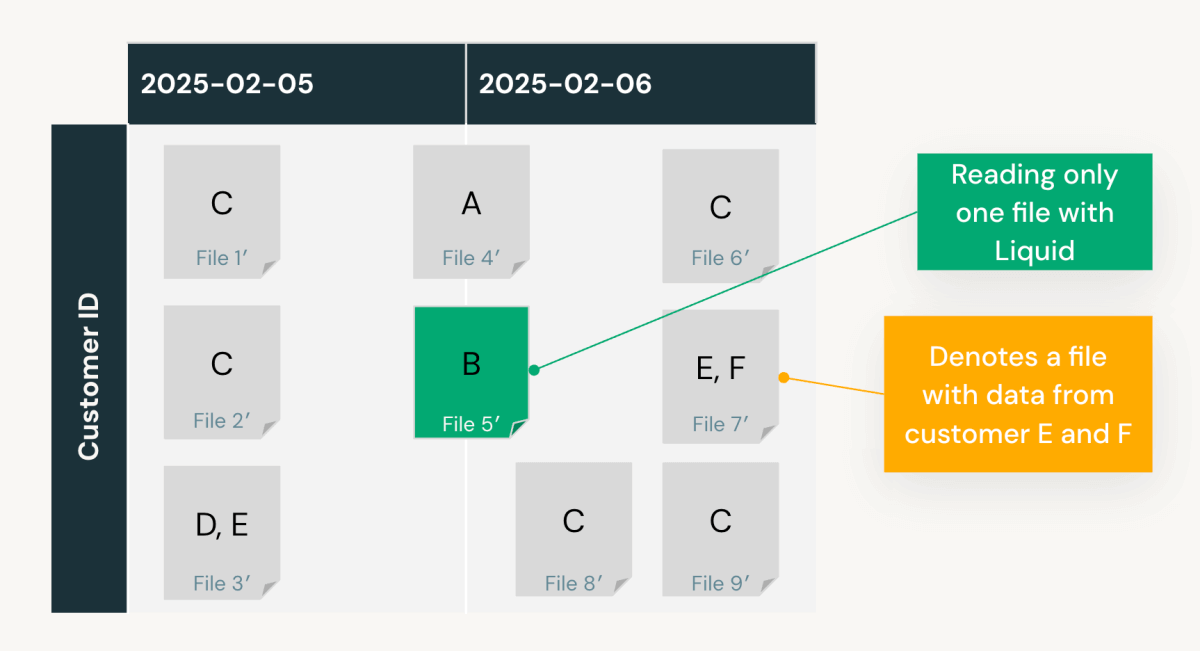
In unserem Beispiel, unter Verwendung von registrierten Scans auf ‘date’ und ‘customer_id’ und unter Annahme konsistenter Abfragen, berechnet Predictive Optimization, dass:
- Clustering nach
‘date’liest 5 Dateien mit 50% Pruning-Raten. - Clustering nach
‘customer_id’liest ~2 Dateien (eine Schätzung) mit einer 80% Pruning-Rate.- Clustering nach beiden
‘date’und‘customer_id’(siehe Datenlayout unten) liest nur 1 Datei mit einer 90% Pruning-Rate.
- Clustering nach beiden

Schritt 3: Kosten-Nutzen-Optimierung
Die Databricks Platform stellt sicher, dass jede Änderung an den Clustering-Schlüsseln einen klaren Leistungsvorteil bringt, da Clustering zusätzlichen Overhead verursachen kann. Sobald neue Kandidaten für Clustering-Schlüssel identifiziert sind, bewertet Predictive Optimization, ob die Leistungsgewinne die Kosten überwiegen. Wenn die Vorteile signifikant sind, aktualisiert es die Clustering-Schlüssel für Unity Catalog-verwaltete Tabellen.
In unserem Beispiel führt das Clustering nach ‘date’ und ‘customer_id’ zu einer Daten-Pruning-Rate von 90%. Da diese Spalten häufig abgefragt werden, rechtfertigen die reduzierten Rechenkosten und die verbesserte Abfrageleistung den Clustering-Overhead.
Preview-Kunden haben die Kosteneffizienz von Predictive Optimization hervorgehoben, insbesondere den geringen Overhead im Vergleich zur manuellen Gestaltung von Datenlayouts. Unternehmen wie CFC Underwriting haben von einem geringeren Gesamtbetriebskosten und erheblichen Effizienzsteigerungen berichtet.
„Wir lieben Databricks' Automatic Liquid Clustering, weil es uns die Gewissheit gibt, dass wir das optimierteste Datenlayout out-of-the-box haben. Es hat uns auch viel Zeit gespart, da wir keinen Ingenieur mehr für die Wartung des Datenlayouts benötigen. Dank dieser Funktion haben wir festgestellt, dass unsere Rechenkosten gesunken sind, obwohl wir unser Datenvolumen skaliert haben.“ —Nikos Balanis, Head of Data Platform, CFC
Die Funktion auf den Punkt gebracht: Predictive Optimization wählt Liquid-Clustering-Schlüssel in Ihrem Namen aus, sodass die prognostizierten Kosteneinsparungen durch Data Skipping die prognostizierten Kosten des Clusterings überwiegen.
Jetzt loslegen
Wenn Sie Predictive Optimization noch nicht aktiviert haben, können Sie dies tun, indem Sie unter Einstellungen > Feature-Aktivierung in der Account Console die Option „Aktiviert“ neben Predictive Optimization auswählen.

Neu bei Databricks? Seit dem 11. November 2024 hat Databricks Predictive Optimization standardmäßig für alle neuen Databricks-Konten aktiviert und führt Optimierungen für alle Ihre Unity Catalog-verwalteten Tabellen durch.
Starten Sie noch heute, indem Sie CLUSTER BY AUTO für Ihre Unity Catalog-verwalteten Tabellen festlegen. Databricks Runtime 15.4+ ist erforderlich, um neue AUTO-Tabellen zu erstellen oder bestehende Liquid-/unpartitionierte Tabellen zu ändern. In naher Zukunft wird Automatic Liquid Clustering für neu erstellte Unity Catalog-verwaltete Tabellen standardmäßig aktiviert. Bleiben Sie dran für weitere Details.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.