Wir stellen das Databricks-Speicher-Ökosystem vor: Governance für den Datenbestand des Unternehmens – ganz gleich, wo er sich befindet.
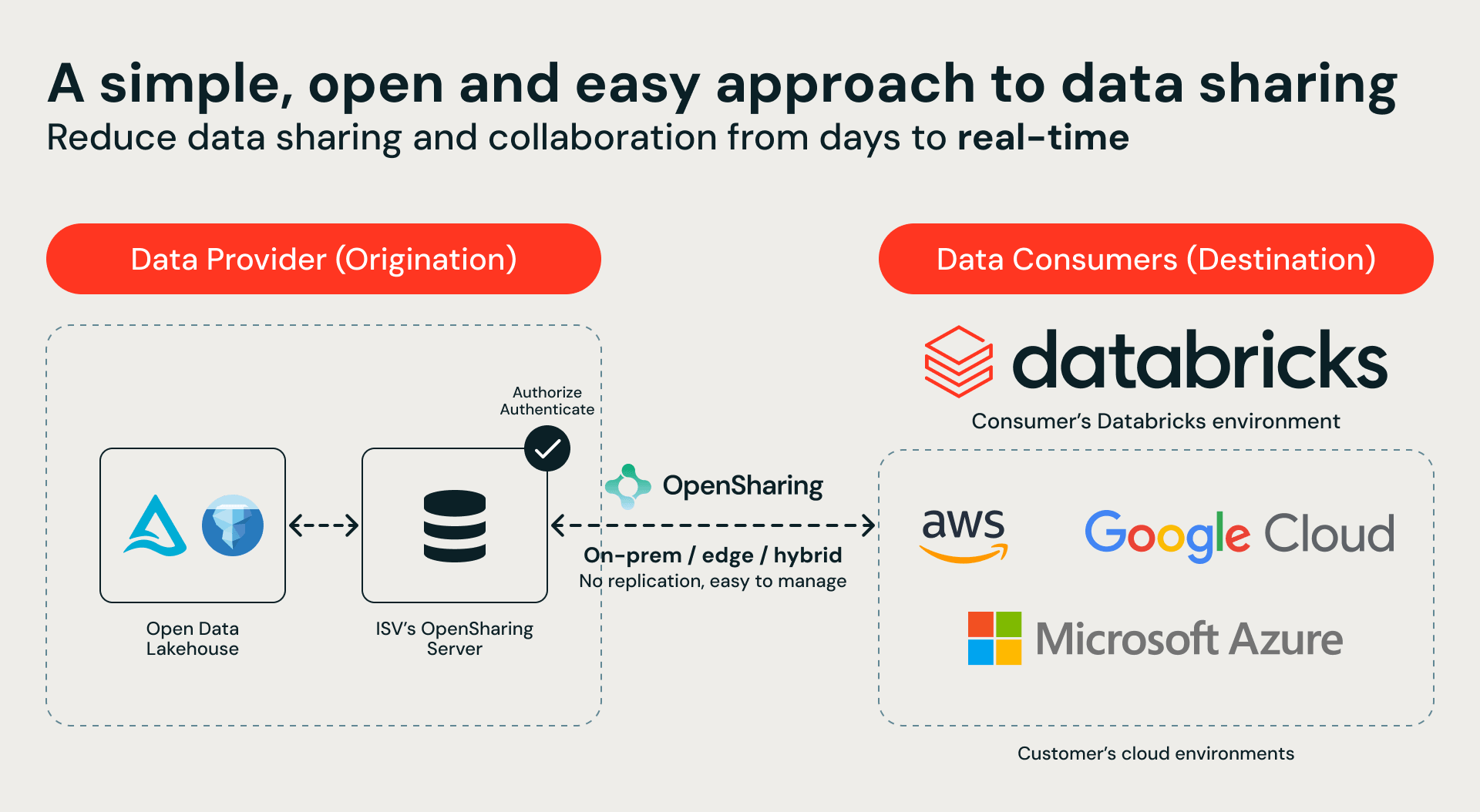
Angetrieben von Open-Source-OpenSharing bringt unser neues Storage-Partner-Ökosystem die Databricks Data Intelligence Platform direkt in Ihre On-Premises- und Hybrid-Infrastruktur – ohne ein einziges Byte zu kopieren.
von Rupal Jain und Denis Dubeau
- Die Herausforderung: Unternehmen müssen riesige Datenmengen On-Premises, in Private Clouds und in Edge-Umgebungen speichern, um strenge Anforderungen an Datensouveränität und gesetzliche Vorgaben zu erfüllen, niedrige Latenzzeiten am Edge zu gewährleisten oder eine immense Datengravitation zu bewältigen – und das alles, während sie gleichzeitig moderne Cloud-AI und Governance in diese Umgebungen bringen.
- Was es ist: Das Databricks Storage Ecosystem verbindet hybride und On-Premises-Speicherplattformen nativ mit Databricks über das OpenSharing-Protokoll. Dies ermöglicht es Unternehmen, eine zentralisierte Data Governance einzurichten und GenAI über ihre gesamte hybride Infrastruktur hinweg zu skalieren.
- Das Ergebnis: Dank einer Zero-Copy-Architektur können Unternehmen Databricks Serverless Compute, Genie und LLMs direkt auf ihren On-Premises-Datensätzen ausführen, ohne eine einzige Datei zu kopieren. Dadurch werden isolierte Daten sofort in aktive, AI-bereite Assets für fortgeschrittene Anwendungsfälle verwandelt, wie das Trainieren von Modellen auf klassifizierten Entwicklungsdaten oder das Analysieren von Netzwerktelemetrie direkt vor Ort.
Die Daten, die sich nicht bewegen lassen
Jahrelang war die Datenstrategie von Unternehmen einfach: Alles in die Cloud verschieben. Die Data Lakes und Warehouses in die Cloud migrieren, und die Governance folgt von selbst. Es war eine saubere Geschichte – bis sie es nicht mehr war.
Heute sagen uns einige der anspruchsvollsten Unternehmen der Welt ganz klar: Sie können – und wollen – nicht alle ihre Daten in die Cloud verschieben. Führende Halbleiterhersteller trainieren Modelle auf als vertraulich eingestuften Entwicklungsdaten, die niemals ihre Standorte verlassen dürfen. Globale Handelsunternehmen sitzen auf riesigen Mengen historischer Tick-Daten, bei denen die wirtschaftlichen Aspekte des Cloud-Egress eine Migration unmöglich machen. Tier-1-Banken haben „Hybrid Forever“-Strategien eingeführt, bei denen sie ihre On-Premises-Speicher modernisieren und gleichzeitig eine strenge Datensouveränität wahren. Große Pharmaunternehmen führen täglich Millionen von Medikamentenexperimenten auf On-Premises-Datenbeständen im Petabyte-Bereich durch, die strengen regulatorischen Kontrollen unterliegen.
Dies sind keine Einzelfälle. Sie stehen für einen strukturellen Wandel im Denken von Unternehmen über Daten: weg von "Migrate Everything" zu "Govern Everything."
Die Treiber dahinter sind real und verstärken sich gegenseitig:
- Datensouveränität & Regulierung: Finanzdienstleister, das Gesundheitswesen und staatliche Organisationen unterliegen strengen Vorgaben – wie GDPR, HIPAA, NIS2 und branchenspezifischen Regeln zur Datenresidenz –, die vorschreiben, dass Daten in bestimmten Ländern oder in Air-Gap-Umgebungen verbleiben müssen. Eine Cloud-Migration ist hier keine Option, sondern für bestimmte Datensätze gesetzlich verboten.
- Data Gravity & Kosten: Im Petabyte- und Exabyte-Bereich bricht die Wirtschaftlichkeit der Cloud-Migration völlig zusammen. Egress-Gebühren, Speicherkosten und das schiere Datenvolumen machen das Modell „Einmal verschieben“ finanziell untragbar. Einige der weltweit größten Einzelhändler repatriieren aus genau diesem Grund aktiv Analyse-Workloads aus der Cloud zurück auf On-Premises-Infrastrukturen.
- Latenz & Edge-Workloads: Workloads im Einzelhandel, in der Fertigung und im Telekommunikationsbereich erfordern einen Zugriff mit geringer Latenz auf On-Premises- und Edge-Daten. Telekommunikationsanbieter erfassen täglich enorme Mengen an Netzwerktelemetrie vor Ort, um KI-gestützte Netzwerkoperationen zu betreiben, die keine Verzögerungen durch Cloud-Roundtrips tolerieren können.
- KI auf Dark Data: Riesige Bestände an Backup-Daten, unstrukturierten Archiven und sekundären Datensätzen – die unternehmensweit Hunderte von Exabytes ausmachen – bergen einen immensen KI-Wert, der bisher ungenutzt blieb, weil die Governance sie nicht erreichte.
Das Signal ist unmissverständlich. Wir haben Anfragen von Hunderten von Kunden erhalten, die explizit nach On-Premises- und hybrider Speicheranbindung an Unity Catalog verlangen. Der Markt für Software-Defined Storage (SDS) wird im Jahr 2026 ein Volumen von Hunderten Milliarden Dollar erreichen, und die Unternehmenspartner, die diese Bestände verwalten – und zusammen mehr als 2 Zettabyte an verwalteten Daten halten –, entwickeln gemeinsam mit uns Lösungen.
Wir stellen vor: Das Databricks Storage Ecosystem
Heute freuen wir uns, das Databricks Software-Defined Storage (SDS) Ecosystem vorzustellen – eine neue Partnerkategorie, die speziell dafür entwickelt wurde, die Databricks Intelligence Platform direkt zu den Unternehmensdaten zu bringen, wo auch immer sie sich befinden: On-Premises, in Private Clouds und in Edge-Umgebungen. Wenn Sie als Unternehmen heute Petabytes an Daten auf diesen Plattformen betreiben, müssen Sie sich nicht mehr zwischen Ihrer bestehenden Non-Cloud-Speicherinfrastruktur und Databricks AI entscheiden.
Viel zu lange mussten sich Unternehmen zwischen der On-Premises-Speicherinfrastruktur, auf die sie angewiesen sind, und der Cloud-nativen KI, die sie entwickeln wollen, entscheiden. Kunden zu zwingen, riesige Datenmengen über komplexe Pipelines zu migrieren, nur um diese Intelligenz zu nutzen, ist ein fehlerhaftes Modell. Durch den Zusammenschluss dieser branchenführenden Partner beenden wir diesen Kompromiss und bringen Databricks Intelligence direkt dorthin, wo die Unternehmensdaten liegen. Aber dieser Launch ist erst der Anfang. Wir schaffen das Fundament, um sicherzustellen, dass bald alle hybriden Daten – ob strukturiert oder unstrukturiert – sofort für generative KI bereitstehen, ohne dass auch nur ein einziges Byte kopiert werden muss. —Stephen Orban, SVP, Product Partnerships & Ecosystem, Databricks
Das Herzstück dieses Ökosystems ist OpenSharing, ein Open-Source-Protokoll für den sicheren und kontrollierten Datenaustausch. Unsere Speicherpartner implementieren OpenSharing-Server, um ihre Datenbestände direkt für Databricks Serverless Compute bereitzustellen. Der Weg dorthin ist einfach: Der Speicherpartner stellt einen OpenSharing-Endpunkt bereit, Sie verbinden ihn mit Unity Catalog und erhalten sofort sicheren, kontrollierten Zugriff auf Ihre On-Premises-Daten in Databricks – ganz ohne Datenmigration.
Diese Integration bietet einen einzigen, einheitlichen Katalog für Ihre gesamte hybride Umgebung. Kunden können jetzt Databricks Serverless Compute, Genie, AgentBricks und das Modelltraining nutzen, um Daten abzufragen und zu analysieren, die die eigenen Räumlichkeiten nie verlassen. Das Ergebnis? Keinerlei Datenverschiebung, keine Datenduplizierung und null Compliance-Risiko.
Dies ist keine bloße Zukunftsvision. Kunden können diese Integrationen schon heute testen. Partner, die diese Integrationen entwickeln, folgen dem Partner Well-Architected Framework – einem technischen Leitfaden, der Architektur-, Sicherheits- und Zertifizierungskriterien abdeckt.
Kunden möchten Datensilos aufbrechen und ihre gesamten Daten- und KI-Bestände zusammenführen – einschließlich großer Datenmengen, die sich nach wie vor On-Premises befinden. Dank der On-Premises-Speicherpartner, die das Open-Source-Protokoll Open Sharing nutzen, können Kunden nun ihren gesamten Datenbestand nahtlos in Databricks Unity Catalog zusammenführen, verwalten und analysieren. So schöpfen sie den vollen Wert ihrer Daten in der Databricks Data Intelligence Platform aus. —Jonathan Keller, VP, Product Management, Databricks
Unsere Launch-Partner
Wir sind stolz darauf, Integrationen mit den folgenden führenden Speicheranbietern anzukündigen:

MinIO — Allgemeine Verfügbarkeit (Demo, Blog)
MinIO AIStor ist das Bindeglied, das die Databricks Data Intelligence Platform nahtlos mit Unternehmensdaten verbindet, die nicht in die Cloud verschoben werden können. Durch die native Implementierung des offenen Open-Sharing-Protokolls auf der Speicherebene eliminiert AIStor Komplexität und ermöglicht es Databricks-Kunden, Live-On-Premises-Tabellen von Apache Iceberg™️ und Delta unter der vollständigen Governance von Unity Catalog effizient abzufragen. Es erweitert Serverless Compute, Genie und Agent Bricks auf On-Premises-Daten und bringt so die volle Leistung der Databricks-Plattform auf die kritischsten Daten eines Unternehmens.
KI- und Analyseinitiativen sind oft dadurch eingeschränkt, wo sich die Daten befinden – insbesondere in Umgebungen mit strengen Sicherheits-, Souveränitäts- oder Betriebsanforderungen. Indem wir natives OpenSharing in AIStor integrieren, ermöglichen wir es Unternehmen, Daten dort sicher bereitzustellen, wo sie liegen, während Databricks über offene Standards nahtlos darauf zugreifen kann. Dies beseitigt eine große Barriere zwischen Unternehmensdaten und KI und erlaubt es Organisationen, bisher unzugängliche Daten für KI, Analysen und agentische Anwendungen zu aktivieren, ohne die Kontrolle zu verlieren. —Ugur Tigli, Chief Technology Officer, MinIO
Everpure (ehemals Pure Storage) — Private Preview (Demo, Blog)
Everpure und Databricks ermöglichen es Unternehmen, On-Premises-Daten direkt in der Cloud zu nutzen, wodurch eine Datenreplikation oder -duplizierung überflüssig wird. Dies wird über einen OpenSharing-Connector realisiert, der Daten im Objektspeicher auf sichere und kontrollierte Weise mit den Databricks-Core-Workspaces verbindet.
Everpure und Databricks ermöglichen es Unternehmen, direkt aus der Cloud auf On-Premises-Daten zuzugreifen und diese zu analysieren, ohne dass eine Replikation oder Duplizierung erforderlich ist. Daten kontinuierlich zwischen Umgebungen zu verschieben, ist kostspielig und auf Dauer nicht tragbar. Kunden suchen nach einem einfacheren Ansatz, der Kosten, Compliance und Datensouveränität in Einklang bringt und gleichzeitig die betriebliche Komplexität reduziert. —Chadd Kenney, VP of Product Management, Everpure
Qumulo — Private Preview im Juli 2026 (Blog)
Qumulo hat OpenSharing in sein neues NeuralSearch integriert. So können Kunden auf Qumulo gespeicherte Daten sicher und ohne Replikation, zusätzliche Kosten oder Komplexität in Core-, Cloud- und Edge-Umgebungen mit Databricks teilen. Mit NeuralSearch können Benutzer relevante Datensätze, einschließlich unstrukturierter Inhalte, über Abfragen in natürlicher Sprache finden und diese kuratierten Tabellen nahtlos über OpenSharing mit Databricks teilen.
Unternehmen können sich die Kosten, die Komplexität und die Verzögerungen beim Kopieren riesiger Datensätze über verschiedene Umgebungen hinweg nicht mehr leisten, nur um AI und Analysen zu unterstützen. Durch die Kombination von Qumulo NeuralSearch mit Databricks OpenSharing können Kunden sowohl tabellarische als auch unstrukturierte Daten in Core-Rechenzentren, Edge-Standorten und Public Clouds sicher finden, verwalten und teilen – in Echtzeit und ohne die Daten selbst zu verschieben. Gemeinsam helfen wir Unternehmen, AI-Initiativen zu beschleunigen, die Governance zu vereinheitlichen und schnellere Erkenntnisse aus global verteilten Daten zu gewinnen, während gleichzeitig eine Single Source of Truth erhalten bleibt. —Brandon Whitelaw, SVP und Head of Product bei Qumulo
VAST Data — Private Preview im August 2026
VAST Data erweitert das VAST AI Operating System um OpenSharing-Unterstützung. Dies hilft Unternehmen, Databricks-Workflows mit Daten zu verknüpfen, die sich in On-Premises- und Hybrid-Infrastrukturen befinden – ohne dass massive Datenverschiebungen oder Migrationen erforderlich sind. Die Integration bietet Kunden mehr Flexibilität beim Zugriff, der Verarbeitung und der Operationalisierung von Daten in Cloud-, Rechenzentrums- und neuen AI-Infrastrukturumgebungen, während gleichzeitig moderne hybride AI- und Analyse-Workloads unterstützt werden.
AI-Infrastruktur wird von Grund auf hybrid. Kunden möchten zunehmend die Möglichkeit haben, Daten dort zu verarbeiten, wo es wirtschaftlich und operativ am sinnvollsten ist, und gleichzeitig einen nahtlosen Zugriff über verschiedene Umgebungen hinweg beizubehalten. Die OpenSharing-Unterstützung erweitert die Fähigkeit des VAST AI Operating System, Databricks-Workflows mit Daten zu verknüpfen, die in Cloud- und On-Premises-Infrastrukturen für moderne AI- und Analyseanwendungen liegen. Im Gegensatz zu herkömmlichen Speicherplattformen kombiniert VAST Datendienste, verteilte Verarbeitung und die Orchestrierung von AI-Infrastrukturen in einem einheitlichen Betriebssystem für AI-Daten im großen Stil. —John Mao, Vice President, Global Technology Alliances bei VAST Data
Wie es weitergeht
Integrationen in Kürze verfügbar
Zusätzlich zu unseren Launch-Partnern nimmt die Dynamik im gesamten Storage-Ökosystem weiter zu. Wir haben Zusagen von Cohesity, Commvault, HPE, NetApp, Nutanix und Rubrik erhalten, bis Ende des Jahres native Integrationen zu entwickeln.
Zusammen verwalten diese Partner, gemeinsam mit den Launch-Partnern, Hunderte von Exabyte an Unternehmensdaten. Dies umfasst hochperformante unstrukturierte Medien, sekundäre Backup-Archive, kostengünstigen Cloud-Speicher und hyperkonvergente Private-Cloud-Umgebungen.
Unstrukturierte Daten nutzbar machen
Der heutige Launch etabliert strukturierte, tabellarische Daten als vollständig verwaltet und zugänglich in diesem Ökosystem. Wir wissen jedoch, dass die eigentlichen Chancen in unstrukturierten Daten liegen: Bilder, PDFs, Videos, medizinische Scans, technische Simulationen und Backup-Archive, die den Großteil der verwalteten Unternehmensdaten ausmachen – und das Rohmaterial für die nächste Generation von RAG-Pipelines und feinabgestimmten Modellen darstellen.
Wir arbeiten aktiv daran, das OpenSharing-Protokoll um Volumes-APIs zu erweitern, um unstrukturierte Dateien aus dem On-Premises-Speicher direkt für GenAI-Workloads in Databricks bereitzustellen. Damit werden Partner, die riesige Mengen unstrukturierter Daten verwalten – von Medien- und Bildarchiven bis hin zu Backup-Repositories von Unternehmen –, eine völlig neue Klasse von AI-Anwendungsfällen für ihre Kunden erschließen.
Das bedeutet es, alles zu verwalten.
Werden Sie Teil des Ökosystems
Wenn Sie ein Speicheranbieter sind und an der Entwicklung einer OpenSharing-Integration interessiert sind, besuchen Sie das Partner Well Architected Framework oder wenden Sie sich an das Databricks-Partner-Team, um loszulegen.
Wenn Sie ein Unternehmenskunde sind und Ihre On-Premises-Speicherumgebung mit Databricks verbinden möchten, wenden Sie sich an Ihr Account-Team, um mehr zu erfahren.
Die Ära von „Alles migrieren“ ist vorbei. Die Ära von „Alles verwalten“ beginnt heute.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.