Apache Spark Echtzeitmodus für Gaming: Eine bessere Methode zur Echtzeit-Sessionisierung
Erstellen Sie zustandsbehaftete Streaming-Pipelines in Apache Spark, die Millionen aktiver Gaming-Gerätesitzungen verfolgen und Echtzeit-Heartbeats mit einer Latenz im Subsekundenbereich generieren.
von Neha Prabhu und Murali Talluri
- Erfahren Sie, wie der Real-Time-Modus von Apache Spark™ eine Echtzeit-Gaming-Sessionisierung für Millionen aktiver Gerätesitzungen ermöglicht
- Erfahren Sie, wie transformWithState-Timer proaktive, timergesteuerte Heartbeats antreiben – und so Ausgaben nach einem festen Zeitplan und unabhängig von eingehenden Daten generieren
- Sehen Sie, wie der Real-Time-Modus in Kombination mit transformWithState maßgeschneiderte interne Anwendungen und externe Streaming-Engines ersetzt – und eine Präzision im Subsekundenbereich sowohl für die Eingabeverarbeitung als auch für die timergesteuerte Ausgabe liefert.
In der Gaming-Branche zählt jede Millisekunde. Um die Personalisierung im Spiel voranzutreiben, Empfehlungs-Engines zu füttern und dynamische Entscheidungen für die Inhaltsplanung zu treffen, müssen Plattformen Sitzungsdaten für Millionen von Spielern weltweit mit einer Latenz von unter einer Sekunde verarbeiten.
Heute erfordert die Erfüllung dieser extrem niedrigen Latenzanforderungen keine unzusammenhängende Architektur mit mehreren Engines mehr. In diesem Blog untersuchen wir eine reale Implementierung des Apache Spark Real-Time Mode. Durch die Nutzung des neuen Operators transformWithState für komplexe zustandsabhängige Logik zeigen wir, wie Spark eine durchgängige Millisekunden-Performance liefert. Erfahren Sie, wie Ihr Team die Entwicklung beschleunigen und geschäftskritische operative Anwendungen mit dem vertrauten Structured Streaming-Ökosystem erstellen kann.
Überblick über den Anwendungsfall
Vom Spielstart bis zum Spielende – Warum Session-Tracking wichtig ist
Für Gaming-Plattformen ist das Wissen darüber, welche Geräte wie lange aktiv sind, nicht nur eine Frage der Infrastruktur – es treibt das Geschäft an. Echtzeit-Sitzungsdaten ermöglichen personalisierte Erlebnisse im Spiel, füttern Empfehlungs-Engines, unterstützen Entscheidungen bei der Inhaltsplanung und liefern Statussignale für Geräte auf Millionen von Konsolen und PCs. Betriebsteams nutzen diese Daten, um Kindersicherungen durchzusetzen und ungewöhnliche Sitzungsmuster zu erkennen.
Grundlagen von Sitzungsereignissen
Sitzungsereignisse von Konsolen und PCs fließen in Kafka-Topics. Jedes Ereignis enthält eine device ID und eine session ID. Die device ID identifiziert die Konsole oder den PC; die session ID identifiziert die Spielsitzung. Es kann zu jedem Zeitpunkt nur eine Sitzung pro Gerät aktiv sein.
Die Pipeline deckt vier Szenarien ab:
- Sitzungsstart (GameStart): Ein Start-Ereignis geht ein. Die Pipeline speichert die Sitzungs-ID und die Startzeit, gibt ein SessionActive-Ereignis aus und registriert einen Verarbeitungszeit-Timer von 30 Sekunden. Wenn für dieses Gerät bereits eine andere Sitzung aktiv war, wird die alte zuerst beendet.
- Sitzungs-Heartbeat (Active): Der Timer wird alle 30 Sekunden ausgelöst. Die Pipeline berechnet jetzt - start_time, gibt einen SessionActive-Heartbeat mit der aktuellen Dauer aus und registriert den Timer erneut.
- Sitzungsende (GameEnd): Ein End-Ereignis geht ein, das mit der aktiven Sitzung übereinstimmt. Die Pipeline gibt ein SessionEnd mit der endgültigen Dauer aus und löscht den Zustand.
- Sitzungs-Timeout (GameSessionTimeout): Der Timer wird ausgelöst und die berechnete Dauer überschreitet ein konfigurierbares Maximum. Anstatt einen Heartbeat auszugeben, gibt die Pipeline ein SessionEnd mit einem Timeout-Grund aus und bereinigt den Zustand.
Warum Spark mit Real-Time Mode ein echter Gamechanger ist
Spark Structured Streaming im Micro-Batch-Modus kann zustandsabhängiges Sessionizing verarbeiten. Wenn der Anwendungsfall jedoch eine Präzision im Subsekundenbereich sowohl für die Eingabeverarbeitung als auch für die timergesteuerte Ausgabe erfordert, stößt Micro-Batch an seine Grenzen. In der Vergangenheit führte diese Lücke dazu, dass Teams eine zusätzliche spezialisierte Engine verwalten oder benutzerdefinierte Lösungen entwickeln mussten.
Mit Apache Flink: Zustandsverwaltung und Timer können zwar implementiert werden, aber die Einführung von Flink bedeutet die Übernahme eines völlig parallelen Ökosystems: ein separater Cluster, ein separates State-Backend, ein eigenes Bereitstellungsmodell, ein eigener Monitoring-Stack und eine eigene Codebasis – und das alles parallel zur Databricks-Plattform. Das Ergebnis sind eine Fragmentierung der Infrastruktur, betriebliche Komplexität sowie die Kosten für den Betrieb und das Personal für eine zweite Streaming-Engine.
Mit maßgeschneiderten Inhouse-Lösungen: Einige Teams entwickeln ihren eigenen Sessionizing-Dienst – beispielsweise ein Akka-basiertes Akteursmodell (Actor System), bei dem jedes Gerät einen Akteur erhält, der den Sitzungszustand, die Timer und die Heartbeat-Ausgabe verwaltet. Diese Lösungen bringen denselben Infrastruktur- und Betriebsaufwand wie Flink mit sich, bergen jedoch eine zusätzliche Herausforderung: Sie skalieren nicht. Die Verteilung von Millionen zustandsabhängiger Akteure über Knoten hinweg müssen Sie selbst entwickeln. Diese Systeme funktionieren anfangs, landen aber im Laufe der Zeit im reinen Wartungsmodus – stabil genug für den Betrieb, aber nicht einfach erweiterbar.
Heute schließt der Real-Time Mode diese Lücke für Kunden – und liefert Präzision im Subsekundenbereich mit denselben Spark-APIs, die Teams bereits verwenden, und das alles in einer einzigen, vereinheitlichten Engine.
Real-Time Mode mit transformWithState
transformWithState ist ein Operator der nächsten Generation in Spark Structured Streaming, der komplexe zustandsabhängige Verarbeitung flexibel und skalierbar macht. Zu den wichtigsten Funktionen gehören objektorientierte Zustandsverwaltung, zusammengesetzte Datentypen, timergesteuerte Logik, automatische TTL-Unterstützung und Schema-Evolution. In Kombination mit dem Real-Time Mode liefert er eine Präzision im Subsekundenbereich sowohl für die Eingabeverarbeitung als auch für die timergesteuerte Ausgabe.
Der Anwendungsfall des Gaming-Sessionizing erfordert zwei Dinge:
- Reaktive Verarbeitung: Verarbeitung von Sitzungsstarts und -enden direkt bei deren Eingang.
- Proaktive Ausgabe: Erstellung eines Heartbeats für jede aktive Sitzung nach einem festen Zeitplan, unabhängig von eingehenden Daten.
transformWithState liefert beides in einer einzigen StatefulProcessor-Klasse mit zwei dedizierten Methoden.
handleInputRows() reagiert auf eingehende Kafka-Ereignisse – verarbeitet Sitzungsstarts und -enden und verwaltet den Sessionizing-Zustand, während Ereignisse eingehen.
handleExpiredTimer() kümmert sich um alles, was dazwischen passiert – es wird ausgelöst, um proaktive Ausgaben wie Heartbeats und Timeouts zu erzeugen, unabhängig davon, ob neue Daten eingegangen sind.
So funktioniert es: Aufbau einer Echtzeit-Gaming-Sessionizing-Pipeline
Überblick über die Pipeline-Architektur
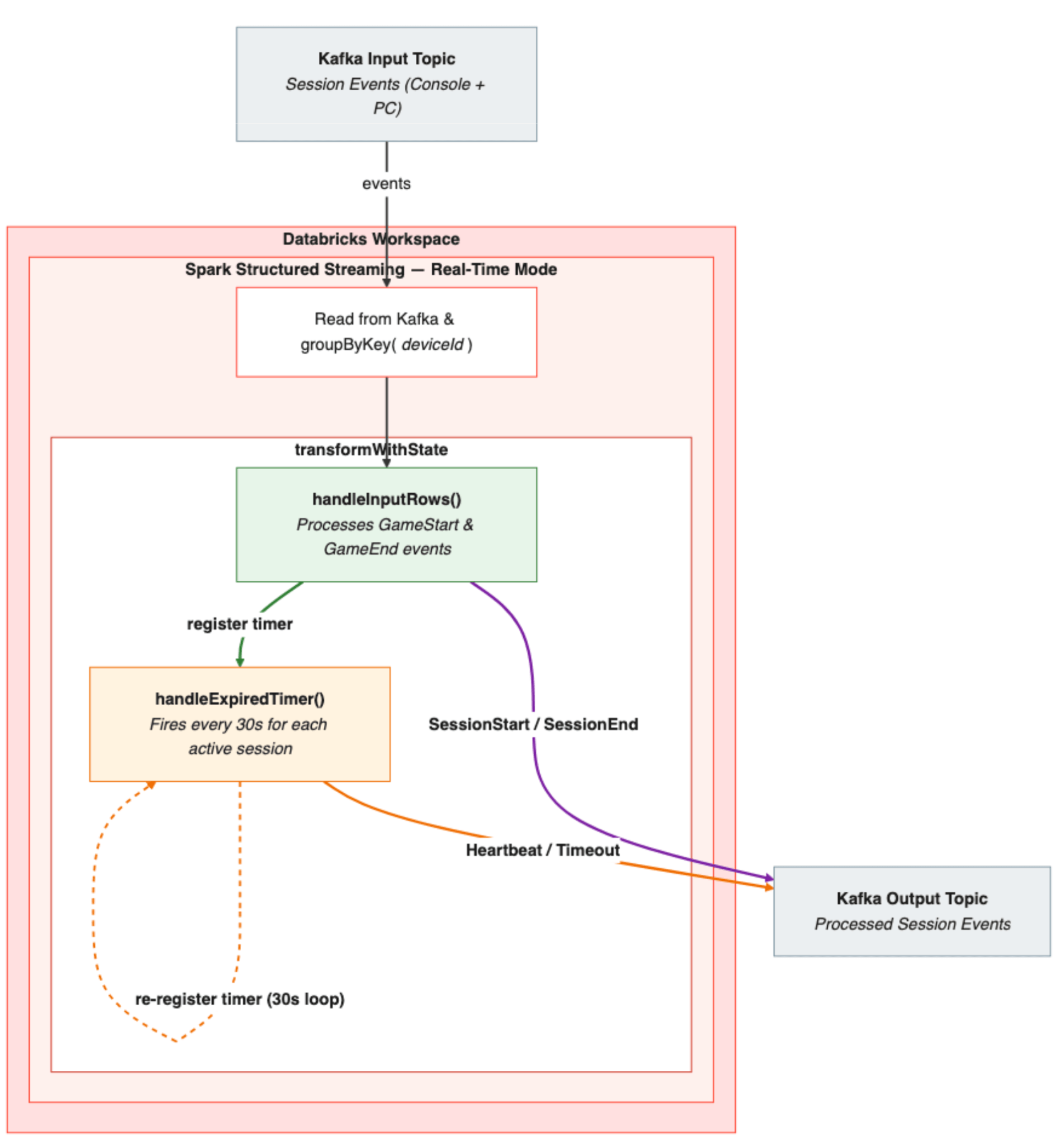
- Ereignis-Ingestion: Sitzungsereignisse (Starts und Enden) von Konsolen und PCs gehen in Kafka-Topics ein. Jedes Ereignis wird analysiert, und eine deviceId wird aus der gerätespezifischen Kennung abgeleitet.
- Zustandsabhängige Gruppierung: Der Stream wird nach deviceId gruppiert – so wird sichergestellt, dass alle Ereignisse für ein bestimmtes Gerät an dieselbe zustandsabhängige Prozessorinstanz weitergeleitet werden.
- Verarbeitung: transformWithState wendet den Sessionizing-Prozessor an, der ein MapState mit der Sitzungs-ID als Schlüssel verwendet, um die aktive Sitzung pro Gerät zu verfolgen. Wenn ein Sitzungsstart eingeht, speichert handleInputRows() den Sitzungszustand, gibt ein SessionActive-Ereignis aus und registriert den ersten 30-Sekunden-Timer. Von diesem Zeitpunkt an übernimmt handleExpiredTimer() – gibt alle 30 Sekunden Heartbeats aus und prüft auf Timeouts. Wenn ein Sitzungsende-Ereignis eingeht, übernimmt handleInputRows() wieder – gibt ein SessionEnd mit der endgültigen Dauer aus, löscht den Zustand und stoppt die Timer-Schleife.
- Ausgabe: Verarbeitete Sitzungsereignisse – Starts, Heartbeats, Enden und Timeouts – werden als JSON in ein Kafka-Ausgabe-Topic geschrieben, bereit für die nachgelagerte Nutzung.
Deep-Dive in die Implementierung
Eine detaillierte Anleitung zur Architektur, Code-Implementierung und Überlegungen für die Produktion finden Sie in diesem begleitenden Blogbeitrag – dort gehen wir auf den StatefulProcessor-Code, den Timer-Lebenszyklus, Zustandsverwaltungsmuster und das Monitoring mit dem StreamingQueryListener ein. Die folgenden Ergebnisse veranschaulichen die Durchsatz- und Latenzeigenschaften der Pipeline und heben die signifikanten Latenzunterschiede zwischen dem Micro-Batch-Modus (MBM) und dem Real-Time Mode (RTM) hervor:
Durchsatz
Um die Pipeline unter realistischer Last zu validieren, haben wir mit dem folgenden kontinuierlichen Durchsatz getestet:
Metrik (pro Minute) | Wert |
Eingangsereignisse (Sitzungsstarts + -enden) | ~500K |
Anzahl aktiver Sitzungen | ~4M |
Ausgegebene Heartbeat-Datensätze | ~8M |
Verstärkung von Eingang zu Ausgang | ~16x |
Der weitaus größte Teil der Ausgabe wird nicht durch eingehende Daten ausgelöst – er wird vollständig von handleExpiredTimer() generiert, das proaktiv Heartbeats nach einem Zeitplan ausgibt.
Latenz
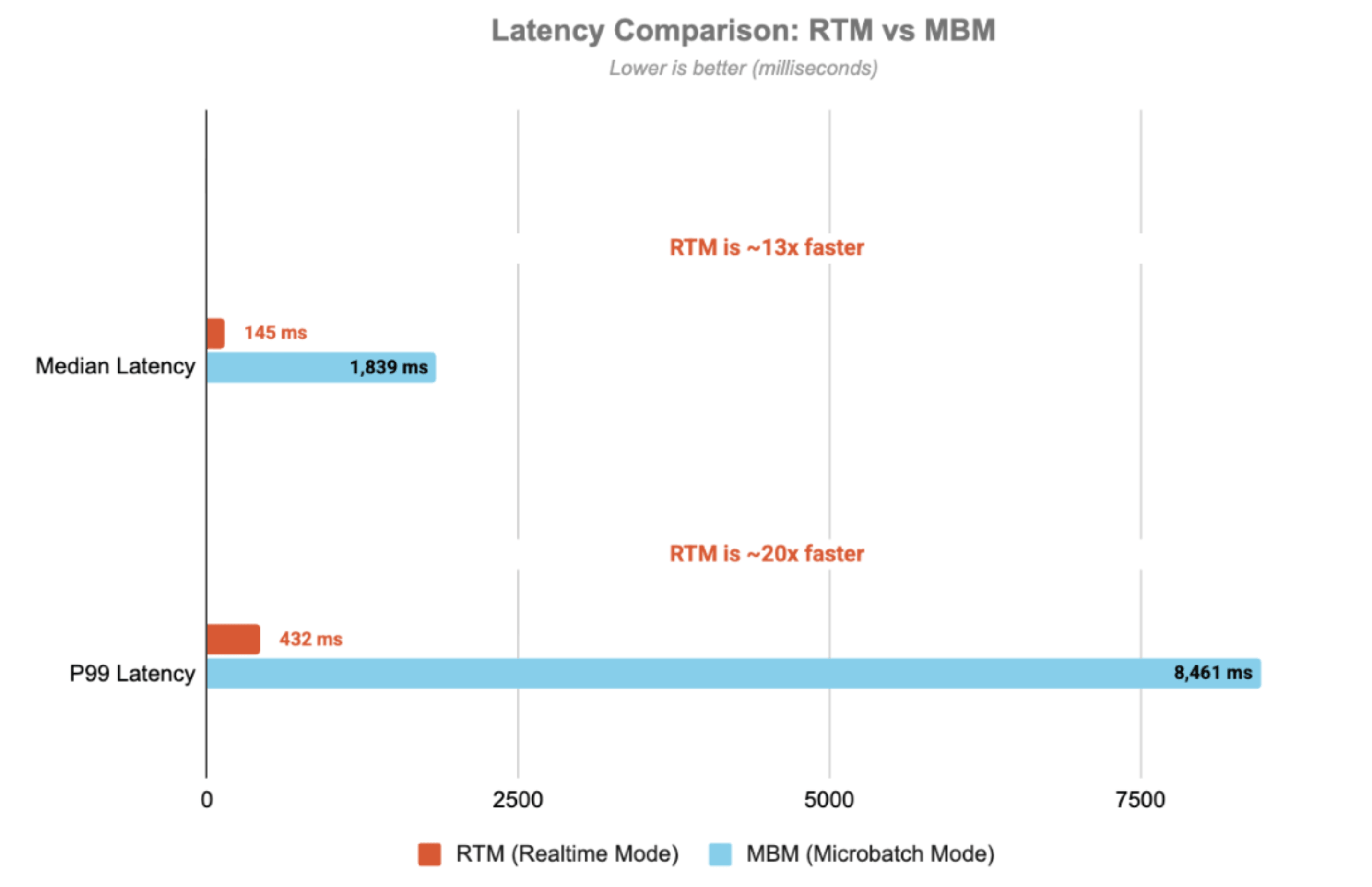
Die Latenz wird durchgängig gemessen – vom Zeitstempel des Kafka-Eingangs-Topics bis zum Zeitstempel des Ausgabe-Topics. Mit dem Real-Time Mode erreicht die Pipeline eine p99-Latenz von 432 ms – 20-mal schneller als im Micro-Batch-Modus.
Fazit
Anwendungsfälle wie die Gaming-Sessionisierung erfordern Pipelines, die über die bloße Verarbeitung eingehender Ereignisse hinausgehen – sie müssen proaktiv regelmäßige Heartbeats senden, Millionen von gleichzeitigen Sessions verfolgen und den Zustand effizient verwalten. Dieses Muster beschränkt sich nicht nur auf Gaming. Jeder Workload, der eine Timer-gesteuerte Ausgabe erfordert – wie IoT-Heartbeats, Session-Tracking, Echtzeit-Alarmierung oder Geräteüberwachung –, kann auf dieselbe Weise aufgebaut werden.
Timer in transformWithState machen dies möglich. Eine einzige StatefulProcessor-Klasse verarbeitet den gesamten Session-Lebenszyklus – von der reaktiven Eingabeverarbeitung bis zur proaktiven, Timer-gesteuerten Ausgabe. In Kombination mit dem Real-Time Mode werden Eingabedatensätze verarbeitet und Timer mit einer Präzision im Subsekundenbereich ausgelöst – nicht erst beim nächsten Batch-Intervall, sondern sofort. Alles direkt in Databricks, ohne eine zweite Engine.
Wenn Sie bereits Structured Streaming-Pipelines im Micro-Batch-Modus ausführen und eine zweite Engine nutzen möchten, um geringere Latenzen zu erzielen, testen Sie zuerst den Real-Time Mode. Der Wechsel erfordert lediglich eine einzige Trigger-Änderung – kein Umschreiben von Code, kein Plattformwechsel:
Probieren Sie es selbst aus:
- Begleitendes Notebook mit Daten-Generator: Führen Sie die gesamte Gaming-Sessionisierungspipeline aus und vergleichen Sie die Latenz von MBM und RTM selbst.
- Leitfaden zur transformWithState-API: State-Variablen, Timer, TTL und Schema-Evolution
- Referenz zum Real-Time Mode: unterstützte Operatoren, Ausführungsmodi, Quellen, Sinks und Sprachunterstützung
Der Real-Time Mode ist jetzt allgemein verfügbar.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.