Einführung des Echtzeitmodus in Apache Spark™ Structured Streaming
Verarbeiten Sie Ereignisse in Millisekunden mit Triggers für Echtzeitverarbeitung in Spark
von Jerry Peng, Siying Dong, Abhay Bothra, Fatih Emekci, Karthikeyan Ramasamy, Navneeth Nair, Indrajit Roy, Matt Jones, Craig Lukasik und Ryan Nienhuis
- Stream-Verarbeitung in Millisekunden: Spark Structured Streaming führt den Echtzeitmodus zur Verarbeitung von Daten in Millisekunden ein und ermöglicht eine neue Klasse von Low-Latency-Apps.
- Keine Neuschreibungen erforderlich: Teams können den Echtzeitmodus mit einer einfachen Konfigurationsänderung aktivieren – keine Umstellung der Plattform oder Code-Überarbeitungen nötig.
- Jetzt in Public Preview: Verfügbar auf Databricks mit Unterstützung für gängige Quellen und Senken; ideal für Betrugserkennung, Live-Personalisierung und ML-Feature-Serving.
Apache Spark™ Structured Streaming unterstützt seit langem geschäftskritische Pipelines in großem Maßstab, von Streaming-ETL bis hin zu Near-Real-Time-Analysen und maschinellem Lernen. Jetzt erweitern wir diese Fähigkeit auf eine völlig neue Klasse von Workloads mit dem Echtzeitmodus, einem neuen Trigger-Typ, der Ereignisse verarbeitet, sobald sie eintreffen, mit Latenzen im zweistelligen Millisekundenbereich.
Im Gegensatz zu bestehenden Micro-Batch-Triggern, die entweder Daten nach einem festen Zeitplan verarbeiten (ProcessingTime-Trigger) oder alle verfügbaren Daten verarbeiten, bevor sie heruntergefahren werden (AvailableNow-Trigger), verarbeitet der Echtzeitmodus kontinuierlich Daten und gibt Ergebnisse aus, sobald sie fertig sind. Dies ermöglicht Anwendungsfälle mit extrem niedriger Latenz wie Betrugserkennung, Live-Personalisierung und Echtzeit-Serving von Machine-Learning-Features, und das alles, ohne Ihren bestehenden Code zu ändern oder eine Umstellung der Plattform vorzunehmen.
Dieser neue Modus wird als Open Source zu Apache Spark beigetragen und ist jetzt in der Public Preview auf Databricks verfügbar.
In diesem Beitrag behandeln wir:
- Was der Echtzeitmodus ist und wie er funktioniert
- Die Arten von Anwendungen, die er ermöglicht
- Wie Sie ihn noch heute nutzen können
Was ist der Echtzeitmodus?
Der Echtzeitmodus liefert kontinuierliche Verarbeitung mit geringer Latenz in Spark Structured Streaming, mit p99-Latenzen von bis zu wenigen Millisekunden. Teams können ihn mit einer einzigen Konfigurationsänderung aktivieren – keine Neuschreibungen oder Umstellungen erforderlich – und dabei die gleichen Structured Streaming APIs verwenden, die sie heute nutzen.
Wie der Echtzeitmodus funktioniert
Der Echtzeitmodus führt langlebige Streaming-Jobs aus, die Stages parallel planen. Daten werden über einen Streaming-Shuffle speicherintern zwischen Tasks übertragen, was:
- den Koordinationsaufwand reduziert
- die festen Planungsverzögerungen des Micro-Batch-Modus eliminiert
- eine konsistente Leistung unter einer Sekunde liefert
In internen Databricks-Tests lagen die p99-Latenzen je nach Komplexität der Transformation zwischen wenigen Millisekunden und ca. 300 ms:
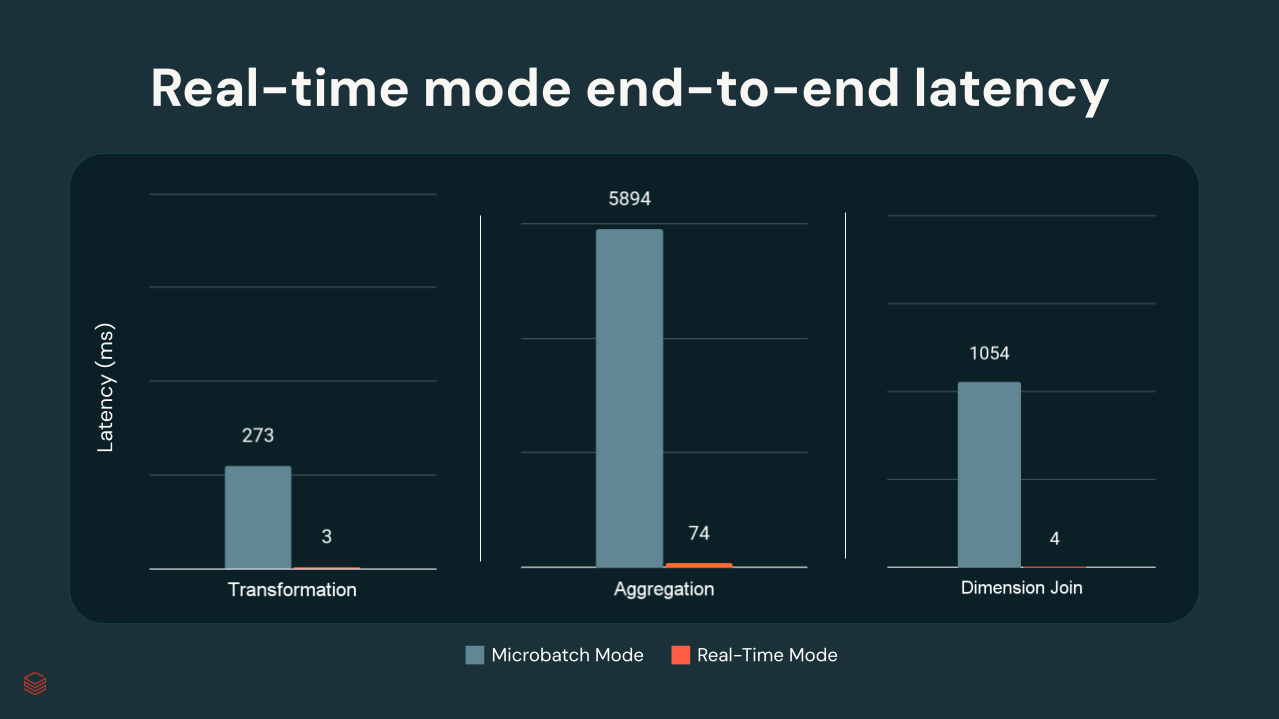
{kind=link}
Anwendungen und Anwendungsfälle
Der Echtzeitmodus ist für Streaming-Anwendungen konzipiert, die eine Verarbeitung mit extrem niedriger Latenz und schnelle Reaktionszeiten erfordern, oft im kritischen Pfad von Geschäftsabläufen.
Der Echtzeitmodus in Spark Structured Streaming hat in unseren ersten Tests bemerkenswerte Ergebnisse geliefert. Für eine geschäftskritische Zahlungsautorisierungs-Pipeline, bei der wir Verschlüsselung und andere Transformationen durchführen, erreichten wir eine P99-End-to-End-Latenz von nur 15 Millisekunden. Wir sind zuversichtlich, diese Low-Latency-Verarbeitung über unsere Datenflüsse hinweg zu skalieren und gleichzeitig strenge SLAs konsequent einzuhalten. —Raja Kanchumarthi, Lead Data Engineer, Network International

Zusätzlich zum oben zitierten Anwendungsfall für Zahlungsautorisierungen von Network International haben bereits mehrere frühe Anwender ihn genutzt, um eine breite Palette von Workloads zu betreiben:
Betrugserkennung im Finanzwesen: Eine globale Bank verarbeitet Kreditkartentransaktionen in Echtzeit von Kafka und kennzeichnet verdächtige Aktivitäten innerhalb von 200 Millisekunden – reduziert Risiko und Reaktionszeit ohne Umstellung der Plattform.
Personalisierte Erlebnisse im Einzelhandel und Medien: Ein OTT-Streaming-Anbieter aktualisiert Inhaltsempfehlungen unmittelbar nach dem Ansehen einer Sendung durch einen Nutzer. Eine führende E-Commerce-Plattform berechnet Produktangebote neu, während Kunden browsen – und hält das Engagement durch Feedbackschleifen unter einer Sekunde hoch.
Live-Sitzungsstatus und Suchverlauf: Eine große Reise-Website verfolgt und zeigt die letzten Suchen jedes Nutzers über Geräte hinweg in Echtzeit an. Jede neue Abfrage aktualisiert den Sitzungscache sofort und ermöglicht personalisierte Ergebnisse und Autovervollständigung ohne Verzögerung.
Echtzeit-ML-Feature-Serving: Eine Food-Delivery-App aktualisiert Features wie Fahrerstandort und Zubereitungszeiten in Millisekunden. Diese Updates fließen direkt in Machine-Learning-Modelle und benutzerseitige Apps ein und verbessern die Genauigkeit der ETA und das Kundenerlebnis.
Dies sind nur einige Beispiele. Der Echtzeitmodus kann jeden Workload unterstützen, der davon profitiert, Daten innerhalb von Millisekunden in Entscheidungen umzuwandeln, von IoT-Sensorwarnungen und Lieferkettentransparenz bis hin zu Live-Gaming-Telemetrie und In-App-Personalisierung.
Erste Schritte mit dem Echtzeitmodus
Der Echtzeitmodus ist jetzt in der Public Preview auf Databricks verfügbar. Wenn Sie bereits Structured Streaming verwenden, können Sie ihn mit einer einzigen Konfigurations- und Trigger-Aktualisierung aktivieren – keine Neuschreibungen erforderlich.
Um ihn in DBR 16.4 oder höher auszuprobieren:
- Erstellen Sie einen Cluster (wir empfehlen den Dedizierten Modus) auf Databricks mit Public Preview-Zugang.
Aktivieren Sie den Echtzeitmodus durch Setzen der folgenden Konfiguration:
Verwenden Sie den neuen Trigger in Ihrer Abfrage:
Checkpointing
Die Option trigger(RealTimeTrigger.apply(...)) aktiviert den neuen Echtzeit-Ausführungsmodus und ermöglicht Ihnen, Latenzen unter einer Sekunde zu erreichen. RealTimeTrigger akzeptiert ein Argument, das angibt, wie oft die Abfrage checkpoints. Zum Beispiel trigger(RealTimeTrigger.apply(“x Minuten”)) Standardmäßig beträgt das Checkpoint-Intervall 5 Minuten, was für die meisten Anwendungsfälle gut funktioniert. Eine Verringerung dieses Intervalls erhöht die Checkpoint-Häufigkeit, kann aber die Latenz beeinträchtigen. Die meisten Streaming-Quellen und -Senken werden unterstützt, einschließlich Kafka, Kinesis und forEach zum Schreiben in externe Systeme.
Zusammenfassung
Der Echtzeitmodus ist ideal für Anwendungsfälle, die die geringstmögliche Latenz erfordern. Für viele analytische Workloads kann der Standard-Micro-Batch-Modus kostengünstiger sein und dennoch die Latenzanforderungen erfüllen. Der Echtzeitmodus verursacht einen geringen System-Overhead, daher empfehlen wir ihn für latenzkritische Pipelines wie die oben genannten Beispiele. Die Unterstützung für zusätzliche Quellen und Senken wird erweitert, und wir arbeiten aktiv daran, die Kompatibilität zu erweitern und die Latenz weiter zu reduzieren.
Weitere Details finden Sie in der Dokumentation zum Echtzeitmodus mit vollständigen Implementierungsdetails, unterstützten Quellen und Senken sowie Beispielabfragen. Dort finden Sie alles, was Sie benötigen, um den neuen Trigger zu aktivieren und Ihre Streaming-Workloads zu konfigurieren.
Für einen umfassenderen Überblick über die Neuerungen in Apache Spark, einschließlich der Einordnung des Echtzeitmodus in die Entwicklung der Engine, sehen Sie sich die Spark Keynote von Michael Armbrust auf der DAIS 2025 an. Sie behandelt die architektonischen Veränderungen hinter Spark's nächstem Kapitel, wobei der Echtzeitmodus ein Kernbestandteil der Geschichte ist.
Um tiefer in die Technik hinter dem Echtzeitmodus einzutauchen, sehen Sie sich unsere technische Deep-Dive-Session unserer Ingenieure an, die den Entwurf und die Implementierung erläutert.
Und um zu sehen, wie der Echtzeitmodus in die breitere Streaming-Strategie auf Databricks passt, lesen Sie den Umfassenden Leitfaden zu Streaming auf der Data Intelligence Platform.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.