Architektur für globale Datenkollaboration mit Delta Sharing
Ermöglichen Sie Ihrem Unternehmen die Skalierung, indem Sie Daten sicher und effizient über Clouds, Plattformen und Regionen hinweg teilen.
von Matei Zaharia, Bilal Obeidat, Tianyi Huang und Giselle Goicochea
Delta Sharing hat sich zu OpenSharing weiterentwickelt, dem ersten offenen, herstellerneutralen Protokoll für die sichere Freigabe von KI-Assets, einschließlich Agent Skills, KI-Modellen und unstrukturierten Daten. Lesen Sie die Ankündigung.
In der heutigen vernetzten digitalen Landschaft sind Datenaustausch und Zusammenarbeit über Organisationen und Plattformen hinweg entscheidend für moderne Geschäftsabläufe. Delta Sharing, ein innovatives offenes Protokoll für den Datenaustausch, ermöglicht es Organisationen, Daten sicher über verschiedene Plattformen hinweg freizugeben und darauf zuzugreifen, wobei Sicherheit und Skalierbarkeit ohne Einschränkungen durch Anbieter oder Datenformate im Vordergrund stehen.
Dieser Blog befasst sich mit den Optionen zur Datenreplikation innerhalb von Delta Sharing und untersucht Architekturrichtlinien, die auf spezifische Datenaustausch-Szenarien zugeschnitten sind. Basierend auf unseren Erfahrungen mit zahlreichen Delta Sharing-Kunden ist es unser Ziel, die Egress-Kosten zu senken und die Performance zu verbessern, indem wir spezifische Alternativen zur Datenreplikation aufzeigen. Während Live-Sharing für viele regionenübergreifende Datenaustausch-Szenarien weiterhin gut geeignet ist, gibt es Fälle, in denen die Replikation des gesamten Datensatzes und die Einrichtung eines Datenaktualisierungsprozesses für lokale regionale Replikate kosteneffizienter ist. Delta Sharing erleichtert dies durch die Nutzung von Cloudflare R2-Speicher, Change Data Feed (CDF) Delta Sharing und Delta Deep Cloning-Funktionen. Dank dieser Funktionen wird Delta Sharing von Kunden sehr geschätzt, da es den Nutzern mehr Möglichkeiten bietet und eine außergewöhnliche Flexibilität bei der Erfüllung ihrer Anforderungen an den Datenaustausch gewährleistet.
Delta Sharing ist offen, flexibel und kosteneffizient
Databricks und die Linux Foundation haben Delta Sharing entwickelt, um den ersten Open-Source-Ansatz für den Datenaustausch über Daten, Analysen und KI hinweg bereitzustellen. Kunden können Live-Daten über Plattformen, Clouds und Regionen hinweg mit hoher Sicherheit und Governance freigeben. Unabhängig davon, ob Sie das Open-Source-Projekt selbst hosten oder das vollständig verwaltete Delta Sharing auf Databricks nutzen – beide bieten eine plattformunabhängige, flexible und kosteneffiziente Lösung für die globale Datenbereitstellung. Databricks-Kunden profitieren von zusätzlichen Vorteilen in einer verwalteten Umgebung, die den administrativen Aufwand minimiert und sich nativ in Databricks Unity Catalog integrieren lässt. Diese Integration bietet eine optimierte Benutzererfahrung für den Datenaustausch innerhalb und außerhalb von Organisationen.
Delta Sharing auf Databricks hat seit seiner allgemeinen Verfügbarkeit im August 2022 in verschiedenen Szenarien der Zusammenarbeit eine breite Akzeptanz gefunden.
In diesem Blog werden wir zwei gängige Architekturmuster untersuchen, bei denen Delta Sharing eine entscheidende Rolle bei der Ermöglichung und Verbesserung kritischer Geschäftsszenarien gespielt hat:
- Unternehmensinterner, regionenübergreifender Datenaustausch
- Datenaggregator-Modell (Hub-and-Spoke)
Im Rahmen dieses Blogs werden wir auch zeigen, dass die Bereitstellungsarchitektur von Delta Sharing flexibel ist und nahtlos erweitert werden kann, um neue Anforderungen an den Datenaustausch zu erfüllen.
Unternehmensinterner, regionenübergreifender Datenaustausch
In diesem Anwendungsfall veranschaulichen wir ein gängiges Bereitstellungsmuster von Delta Sharing bei unseren Kunden, bei dem die geschäftliche Notwendigkeit besteht, einen Teil der Daten regionenübergreifend freizugeben – beispielsweise wenn ein QA-Team in verschiedenen Regionen arbeitet oder ein Reporting-Team an globalen Geschäftsaktivitätsdaten interessiert ist. Normalerweise umfasst die Freigabe unternehmensinterner Tabellen Folgendes:
- Freigabe großer Tabellen: Es besteht die Anforderung, große Tabellen in Echtzeit für die Empfänger freizugeben, wobei die Zugriffsmuster variieren. Empfänger führen häufig unterschiedliche Abfragen mit verschiedenen Prädikaten aus. Ein gutes Beispiel sind Clickstream- und Benutzeraktivitätsdaten, bei denen in diesen Fällen ein Remote-Zugriff besser geeignet ist.
- Lokale Replikation: Um die Performance zu verbessern und die Egress-Kosten besser zu verwalten, sollten einige Daten repliziert werden, um eine lokale Kopie der Daten zu erstellen – insbesondere wenn in der Region des Empfängers eine erhebliche Anzahl von Benutzern häufig auf diese Tabellen zugreift.
In diesem Szenario nutzen die Geschäftsbereiche des Datenbereitstellers und des Datenempfängers dasselbe Unity Catalog-Konto, verfügen jedoch über unterschiedliche Metastores auf Databricks.
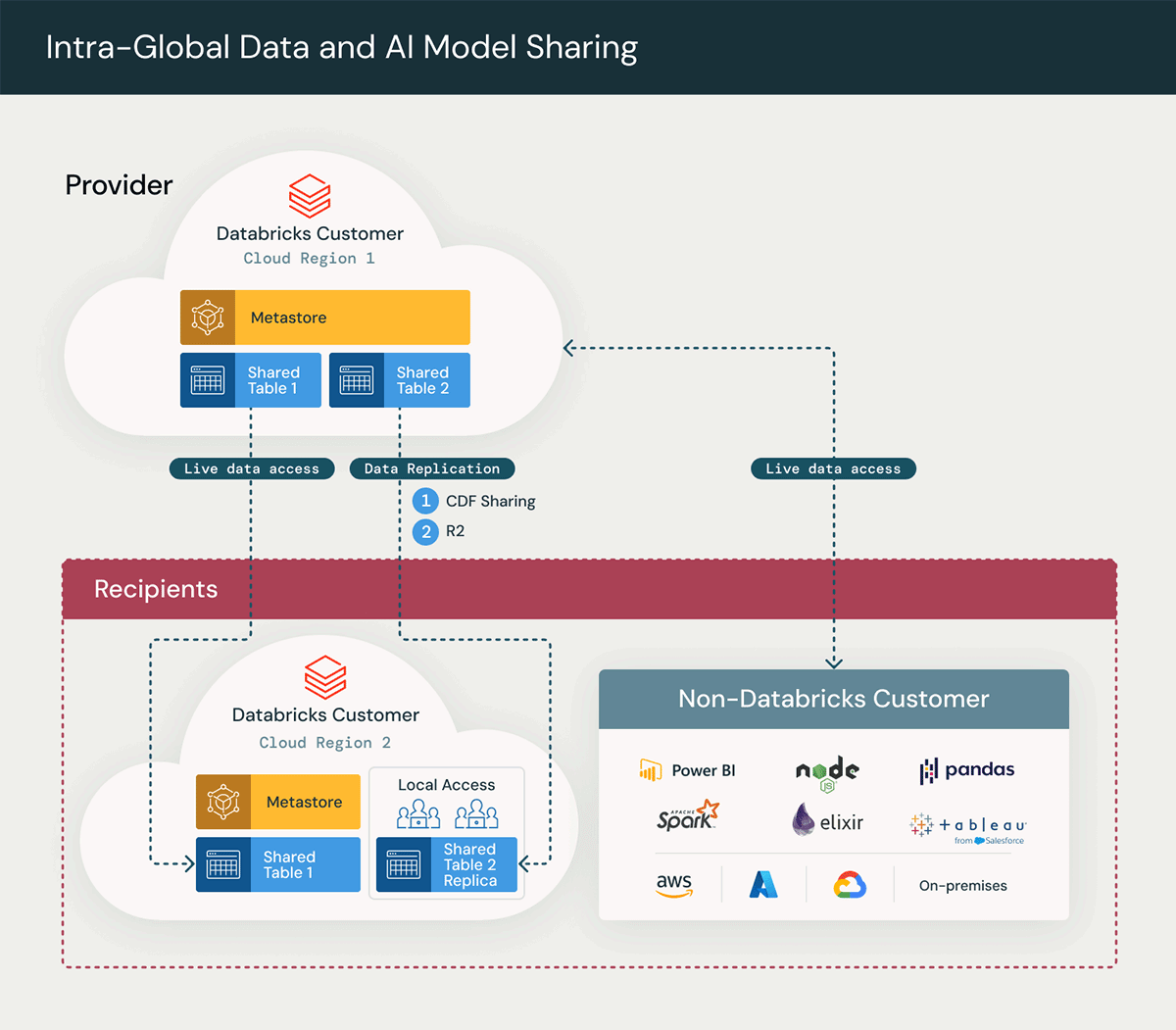
Das obige Diagramm veranschaulicht eine High-Level-Architektur der Delta Sharing-Lösung und hebt die wichtigsten Schritte im Delta Sharing-Prozess hervor:
- Erstellung eines Shares: Live-Tabellen werden für den Empfänger freigegeben, was einen sofortigen Datenzugriff ermöglicht.
- On-Demand-Datenreplikation: Die Implementierung einer On-Demand-Datenreplikation umfasst die Erstellung eines regionalen Duplikats der Daten, um die Performance zu verbessern, den Bedarf an regionenübergreifendem Netzwerkzugriff zu verringern und die damit verbundenen Egress-Gebühren zu minimieren. Dies wird durch die Nutzung der folgenden Ansätze zur Datenreplikation erreicht:
A. Change Data Feed für eine freigegebene Tabelle
Diese Option erfordert die Freigabe des Tabellenverlaufs und die Aktivierung des Change Data Feeds (CDF), der im Setup-Code explizit aktiviert werden muss, indem die Tabelleneigenschaft delta.enableChangeDataFeed = true mithilfe der Befehle Create/Alter Table festgelegt wird.
Stellen Sie außerdem beim Hinzufügen der Tabelle zum Share sicher, dass sie mit der Option CDF hinzugefügt wird, wie im folgenden Beispiel gezeigt.
Sobald Daten hinzugefügt oder aktualisiert wurden, kann auf die Änderungen wie in diesem Beispiel zugegriffen werden
Auf der Empfängerseite kann auf ähnliche Weise wie in diesem Notebook auf Änderungen zugegriffen und diese in eine lokale Kopie der Daten zusammengeführt werden. Die Übertragung der Änderungen von der freigegebenen Tabelle auf ein lokales Replikat kann mithilfe eines Databricks-Workflow-Jobs orchestriert werden.
B. Cloudflare R2 mit Databricks
R2 ist eine hervorragende Option für alle Delta Sharing-Szenarien, da Kunden das Potenzial der Freigabe voll ausschöpfen können, ohne sich über unvorhersehbare Egress-Gebühren Gedanken machen zu müssen. Dies wird später in diesem Blog ausführlich besprochen.
C. Delta Deep Clone
Eine weitere Option für Sonderfälle beim unternehmensinternen Austausch ist die Verwendung von Delta Deep Clone bei der Freigabe innerhalb desselben Databricks-Cloud-Kontos. Deep Cloning ist eine Delta-Funktion, die sowohl die Quelltabellendaten als auch die Metadaten der vorhandenen Tabelle in das Klonziel kopiert. Darüber hinaus kann der Deep-Clone-Befehl neue Daten identifizieren und entsprechend aktualisieren. Hier ist die Syntax:
Der vorherige Befehl wird auf der Empfängerseite ausgeführt, wobei source_table_name die freigegebene Tabelle und table_name die lokale Kopie der Daten ist, auf die Benutzer zugreifen können.
Ein einfacher Databricks Workflows-Job kann für eine inkrementelle Aktualisierung der Daten mit den neuesten Updates unter Verwendung des folgenden Befehls geplant werden:
Derselbe Anwendungsfall kann problemlos erweitert werden, um Daten mit externen Partnern und Kunden auf der Databricks-Plattform oder einer anderen Plattform freizugeben. Dies ist ein weiteres gängiges erweitertes Muster, bei dem Partner und externe Kunden, die nicht auf Databricks sind, über Excel, Power BI, Pandas und andere kompatible Software wie Oracle auf diese Daten zugreifen möchten.
Datenaggregator-Modell (Hub-and-Spoke-Modell)
Ein weiteres gängiges Szenariomuster ergibt sich, wenn sich ein Unternehmen auf die Freigabe von Daten für Kunden konzentriert, insbesondere in Fällen, in denen Datenaggregator-Unternehmen beteiligt sind oder die primäre Geschäftsfunktion darin besteht, Daten im Auftrag von Kunden zu sammeln. Ein Datenaggregator ist ein Unternehmen, das sich darauf spezialisiert hat, Daten aus verschiedenen Quellen zu sammeln und in einem einheitlichen, kohärenten Datensatz zusammenzuführen. Diese Datenfreigaben sind hilfreich, um verschiedene geschäftliche Anforderungen wie geschäftliche Entscheidungsfindung, Marktanalysen, Forschung und die Unterstützung des allgemeinen Geschäftsbetriebs zu erfüllen.
Das Datenaustauschmodell in diesem Muster bewirkt Folgendes:
- Verbindet Empfänger, die über verschiedene Clouds verteilt sind, einschließlich AWS, Azure und GCP.
- Unterstützt die Datennutzung auf verschiedenen Plattformen, deren Komplexität von Python-Code bis hin zu Excel-Tabellen reicht.
- Ermöglicht die Skalierbarkeit für die Anzahl der Empfänger, die Menge der Freigaben und das Datenvolumen.
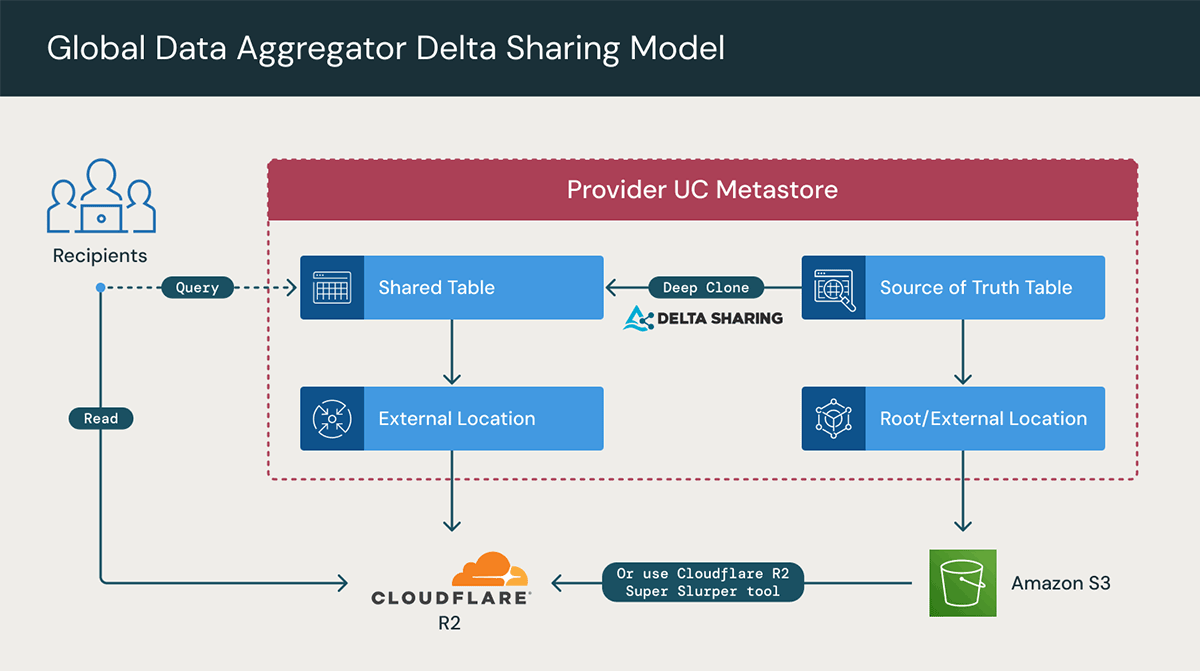
Im Allgemeinen lässt sich dies in der Regel dadurch erreichen, dass der Anbieter in jeder Cloud einen Databricks-Workspace einrichtet und Daten mithilfe von CDF auf einer gemeinsam genutzten Tabelle (wie oben beschrieben) über alle drei Clouds hinweg repliziert, um die Performance zu verbessern und die Egress-Kosten zu senken. Innerhalb jeder Cloud-Region können die Daten dann mit den entsprechenden Kunden und Partnern geteilt werden.
Es gibt jedoch einen neuen, effizienteren und einfacheren Ansatz: die Nutzung von R2 über Cloudflare mit Databricks, das sich derzeit in der Private Preview befindet.
Die Integration von Cloudflare R2 mit Databricks ermöglicht es Unternehmen, Live-Daten sicher, einfach und kostengünstig zu teilen und gemeinsam zu bearbeiten. Mit Cloudflare und Databricks können gemeinsame Kunden die Komplexität und die dynamischen Kosten beseitigen, die dem vollen Potenzial von Multi-Cloud-Analytics- und AI-Initiativen im Weg stehen. Konkret fallen keine Egress-Gebühren an, und komplexe Datentransfers oder kostspielige Replikationen von Datensätzen über Regionen hinweg sind nicht mehr erforderlich.
Die Nutzung dieser Option erfordert die folgenden Schritte:
- Cloudflare R2 as an external storage location hinzufügen (während die Source of Truth für die Daten in S3/ADLS/etc. verbleibt)
- Neue Tabellen in Cloudflare R2 erstellen und Daten inkrementell synchronisieren
- Delta Deep Clone
- R2 Super Slurper
- Wie gewohnt einen Delta Share auf der R2-Tabelle erstellen
Wie oben erläutert, zeigen diese Ansätze verschiedene Methoden der On-Demand-Datenreplikation, die jeweils ihre eigenen Vorteile und spezifischen Anforderungen haben und sich somit für unterschiedliche Anwendungsfälle eignen.
Vergleich von Datenreplikationsmethoden für das regionsübergreifende Teilen
Alle drei zuvor genannten Mechanismen ermöglichen es Delta Sharing-Benutzern, eine lokale Kopie zu erstellen, um Egress-Gebühren zu minimieren, insbesondere über Clouds und Regionen hinweg. Die folgende Tabelle bietet eine kurze Zusammenfassung zur Unterscheidung dieser Optionen.
| Datenreplikationstool | Wichtigste Highlights | Empfehlung |
|---|---|---|
| Change Data Feed auf einer freigegebenen Tabelle |
| Für das externe Teilen mit Partnern/Kunden über Regionen hinweg verwenden |
| Cloudflare R2 mit Databricks |
| Dringend empfohlen für Delta Sharing im großen Stil in Bezug auf die Anzahl der Freigaben und bei 2 oder mehr Regionen |
| Delta Deep Clone |
| Empfohlen für das interne Teilen über Regionen hinweg |
Delta Sharing ist offen, flexibel und kosteneffizient. Auf Databricks unterstützt es ein breites Spektrum an Daten-Assets, einschließlich Notebooks, Volumes und AI-Modellen. Darüber hinaus haben mehrere Optimierungen die Performance der Delta Sharing-Protokolle erheblich verbessert. Die kontinuierlichen Investitionen von Databricks in Delta Sharing-Funktionen, einschließlich verbesserter Überwachung, Skalierbarkeit, Benutzerfreundlichkeit und Observability, unterstreichen das Engagement des Unternehmens, die Benutzererfahrung zu verbessern und sicherzustellen, dass Delta Sharing auch in Zukunft eine führende Rolle bei der Zusammenarbeit an Daten einnimmt.
Nächste Schritte
In diesem Blog haben wir Empfehlungen zur Architektur gegeben, die auf unseren Erfahrungen mit zahlreichen Delta Sharing-Kunden basieren. Unser Hauptaugenmerk liegt dabei auf Kostenmanagement und Performance. Während Live-Sharing für viele regionsübergreifende Szenarien zur Datenfreigabe geeignet ist, haben wir Fälle untersucht, in denen die Replikation des gesamten Datensatzes und die Einrichtung eines Datenaktualisierungsprozesses für lokale regionale Replikate kosteneffizienter ist. Delta Sharing erleichtert dies durch die Nutzung der Delta Sharing-Funktionen von R2 und CDF und bietet Benutzern so eine höhere Flexibilität.
Im Anwendungsfall des unternehmensinternen, regionsübergreifenden Teilens von Daten zeichnet sich Delta Sharing beim Teilen großer Tabellen mit unterschiedlichen Zugriffsmustern aus. Die lokale Replikation, die durch das Teilen via CDF ermöglicht wird, sorgt für optimale Performance und effizientes Kostenmanagement. Darüber hinaus bietet R2 über Cloudflare mit Databricks eine effiziente Option für Delta Sharing im großen Stil über mehrere Regionen und Clouds hinweg.
Um mehr darüber zu erfahren, wie Sie Delta Sharing in Ihre Strategie zur Zusammenarbeit an Daten integrieren können, werfen Sie einen Blick auf die neuesten Ressourcen:
- Lesen Sie den technischen Leitfaden von O'Reilly, „Data Sharing and Collaboration with Delta Sharing“ (Early Release)
- Tauchen Sie tiefer in die Databricks Delta Sharing-Dokumentation ein.
- Erfahren Sie mehr über Delta Sharing: ein offener Standard für den sicheren Datenaustausch
- Sehen Sie sich die Videoankündigung für Delta Sharing mit Matei Zaharia an (Keynote Data + AI Summit 2021)
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.