Sind LLM-Agenten gut in der Join-Reihenfolge-Optimierung?
von Eric Liang, Ryan Marcus, Sid Taneja und Yuhao Zhang
- Was es ist: Wir untersuchen die Anwendung von fortschrittlichen Large Language Model (LLM) Agenten auf das klassische Datenbankproblem der SQL Join Order Optimierung.
- Die Herausforderung: Traditionelle Query-Optimierer haben oft Schwierigkeiten mit der Join-Reihenfolge, wobei die Anzahl der möglichen Pläne mit der Anzahl der Tabellen exponentiell wächst, was oft zu schlechter Leistung aufgrund falsch geschätzter Kardinalitäten führt. LLM-Agenten lösen dieses Problem, indem sie wie ein datengesteuerter DBA agieren und tatsächliche Laufzeitstatistiken und semantischen Kontext berücksichtigen, die automatisierte Heuristiken oft übersehen.
- Ergebnisse & Errungenschaften: In experimentellen Benchmarks verbesserte der Prototyp-Agent den Databricks-Optimierer in 80% der Fälle und steigerte die Abfragelatenz insgesamt um den Faktor 1,3x.
Einleitung
Auf der Databricks-Plattform für künstliche Intelligenz erforschen und nutzen wir regelmäßig neue KI-Techniken, um die Motorleistung zu verbessern und die Benutzererfahrung zu vereinfachen. Hier präsentieren wir experimentelle Ergebnisse zur Anwendung von Frontier-Modellen auf eine der ältesten Herausforderungen von Datenbanken: die Join-Reihenfolge.
Dieser Blog ist Teil einer Forschungskooperation mit der UPenn.
Das Problem: Join-Reihenfolge
Seit ihrer Einführung haben Query-Optimierer in relationalen Datenbanken Schwierigkeiten, gute Join-Reihenfolgen für SQL-Abfragen zu finden. Um die Schwierigkeit der Join-Reihenfolge zu veranschaulichen, betrachten wir die folgende Abfrage:
Wie viele Filme wurden von Sony produziert und Scarlett Johansson waren darin zu sehen?
Angenommen, wir möchten diese Abfrage über das folgende Schema ausführen:
| Tabellenname | Tabellenspalten |
|---|---|
| Actor | actorID, actorName, actorDOB, … |
| Company | companyID, companyName, … |
| Stars | actorID, movieID |
| Produces | companyID, movieID |
| Movie | movieID, movieName, movieYear , … |
Die Entitätstabellen Actor, Company und Movie sind über die Beziehungstabellen Produces und Stars verbunden (z. B. über Fremdschlüssel). Eine Version dieser Abfrage in SQL könnte lauten:
Logisch wollen wir eine einfache Join-Operation durchführen: Actor ⋈ Stars ⋈ Movie ⋈ Produces ⋈ Company. Aber physikalisch, da jeder dieser Joins kommutativ und assoziativ ist, haben wir viele Optionen. Der Query-Optimierer könnte wählen:
- Zuerst alle Filme finden, in denen Scarlett Johansson mitspielte, und dann nur die Filme herausfiltern, die von Sony produziert wurden,
- Zuerst alle von Sony produzierten Filme finden und dann diejenigen herausfiltern, in denen Scarlett Johansson mitspielte,
- Parallel Sony-Filme und Scarlett-Johansson-Filme berechnen und dann die Schnittmenge bilden.
Welcher Plan optimal ist, hängt von den Daten ab: Wenn Scarlett Johansson in deutlich weniger Filmen mitgespielt hat, als Sony produziert hat, könnte der erste Plan optimal sein. Leider ist die Schätzung dieser Menge genauso schwierig wie die Ausführung der Abfrage selbst (im Allgemeinen). Noch schlimmer ist, dass es normalerweise weitaus mehr als 3 Pläne zur Auswahl gibt, da die Anzahl der möglichen Pläne mit der Anzahl der Tabellen exponentiell wächst – und Analyseabfragen regelmäßig 20-30 verschiedene Tabellen verknüpfen.
Wie funktioniert die Join-Reihenfolge heute? Traditionelle Query-Optimierer lösen dieses Problem mit drei Komponenten: einem Kardinalitätsschätzer, der dazu dient, schnell die Größe von Unterabfragen zu schätzen (z. B. um zu schätzen, wie viele Filme Sony produziert hat), einem Kostenmodell zum Vergleichen verschiedener potenzieller Pläne und einem Suchverfahren, das den exponentiell großen Raum durchsucht. Die Kardinalitätsschätzung ist besonders schwierig und hat zu einer breiten Palette von Forschungsarbeiten geführt, die versuchen, die Genauigkeit der Schätzung mit einer Vielzahl von Ansätzen zu verbessern [A].
All diese Lösungen fügen einem Query-Optimierer erhebliche Komplexität hinzu und erfordern erheblichen technischen Aufwand für die Integration, Wartung und Produktion. Aber was wäre, wenn LLM-gestützte Agenten mit ihren Fähigkeiten, sich durch Prompting an neue Domänen anzupassen, der Schlüssel zur Lösung dieses jahrzehntealten Problems wären?
Agentenbasierte Join-Reihenfolge
Wenn Query-Optimierer eine schlechte Join-Reihenfolge wählen1, können menschliche Experten dies beheben, indem sie das Problem diagnostizieren (oft eine falsch geschätzte Kardinalität) und den Query-Optimierer anweisen, eine andere Reihenfolge zu wählen. Dieser Prozess erfordert oft mehrere Testrunden (z. B. Ausführung der Abfrage) und die manuelle Inspektion der Zwischenergebnisse.
Query-Optimierer müssen Join-Reihenfolgen normalerweise in wenigen hundert Millisekunden auswählen, daher ist die Integration eines LLM in den „Hot Path“ des Query-Optimierers, obwohl potenziell vielversprechend, heute nicht möglich. Aber der iterative und manuelle Prozess der Optimierung der Join-Reihenfolge für eine Abfrage, der einem menschlichen Experten mehrere Stunden dauern kann, könnte potenziell mit einem LLM-Agenten automatisiert werden! Dieser Agent versucht, diesen manuellen Tuning-Prozess zu automatisieren.
Um dies zu testen, haben wir einen Prototyp eines Query-Optimierungsagenten entwickelt. Der Agent hat Zugriff auf ein einziges Werkzeug, das eine potenzielle Join-Reihenfolge für eine Abfrage ausführt und die Laufzeit der Join-Reihenfolge (mit einem Timeout der Laufzeit der ursprünglichen Abfrage) und die Größe jedes berechneten Teilplans zurückgibt (z. B. den EXPLAIN EXTENDED Plan).
Wir lassen den Agenten 50 Iterationen laufen und erlauben ihm, verschiedene Join-Reihenfolgen frei auszuprobieren. Der Agent kann diese 50 Iterationen nutzen, um vielversprechende Pläne zu testen („Exploitation“) oder riskante, aber informative Alternativen zu erkunden („Exploration“). Danach sammeln wir die beste getestete Join-Reihenfolge des Agenten, die unser Endergebnis wird. Aber woher wissen wir, dass der Agent eine gültige Join-Reihenfolge gewählt hat? Um die Korrektheit zu gewährleisten, generiert jeder Werkzeugaufruf eine Join-Reihenfolge unter Verwendung strukturierter Modellausgaben, die das Modell zwingen, eine von uns angegebene Grammatik zu erfüllen, um nur gültige Join-Neuanordnungen zuzulassen. Beachten Sie, dass dies von früheren Arbeiten [B] abweicht, die das LLM bitten, sofort eine Join-Reihenfolge im „Hot Path“ des Query-Optimierers zu wählen; stattdessen kann das LLM wie ein Offline-Experimentator agieren, der viele Kandidatenpläne ausprobiert und aus den beobachteten Ergebnissen lernt – genau wie ein Mensch, der eine Join-Reihenfolge von Hand optimiert!.
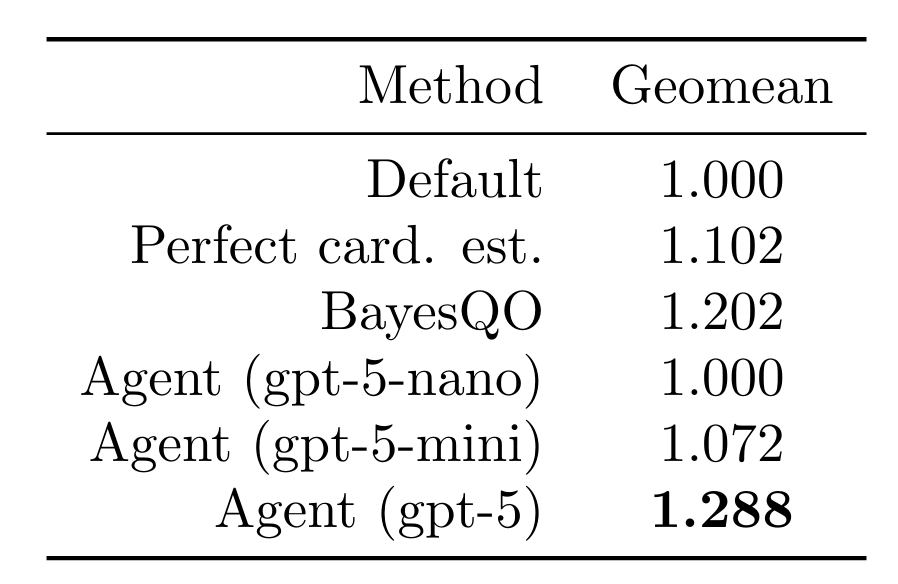
Um unseren Agenten in DBR zu evaluieren, haben wir den Join Order Benchmark (JOB) verwendet, eine Reihe von Abfragen, die darauf ausgelegt waren, schwer zu optimieren zu sein. Da der von JOB verwendete Datensatz, der IMDb-Datensatz, nur etwa 2 GB groß ist (und Databricks daher auch schlechte Join-Reihenfolgen recht schnell verarbeiten konnte), haben wir den Datensatz skaliert, indem wir jede Zeile 10 Mal dupliziert haben [C].
Wir ließen unseren Agenten 15 Join-Reihenfolgen (Rollouts) pro Abfrage für alle 113 Abfragen im Join-Order-Benchmark testen. Wir berichten über die Ergebnisse der besten Join-Reihenfolge, die für jede Abfrage gefunden wurde. Bei Verwendung eines Frontier-Modells konnte der Agent die Abfragelatenz um den Faktor 1,288 (geomean) verbessern. Dies übertrifft die Verwendung perfekter Kardinalitätsschätzungen (in der Praxis nicht realisierbar), kleinerer Modelle und des neueren BayesQO-Offline-Optimierers (obwohl BayesQO für PostgreSQL und nicht für Databricks entwickelt wurde).
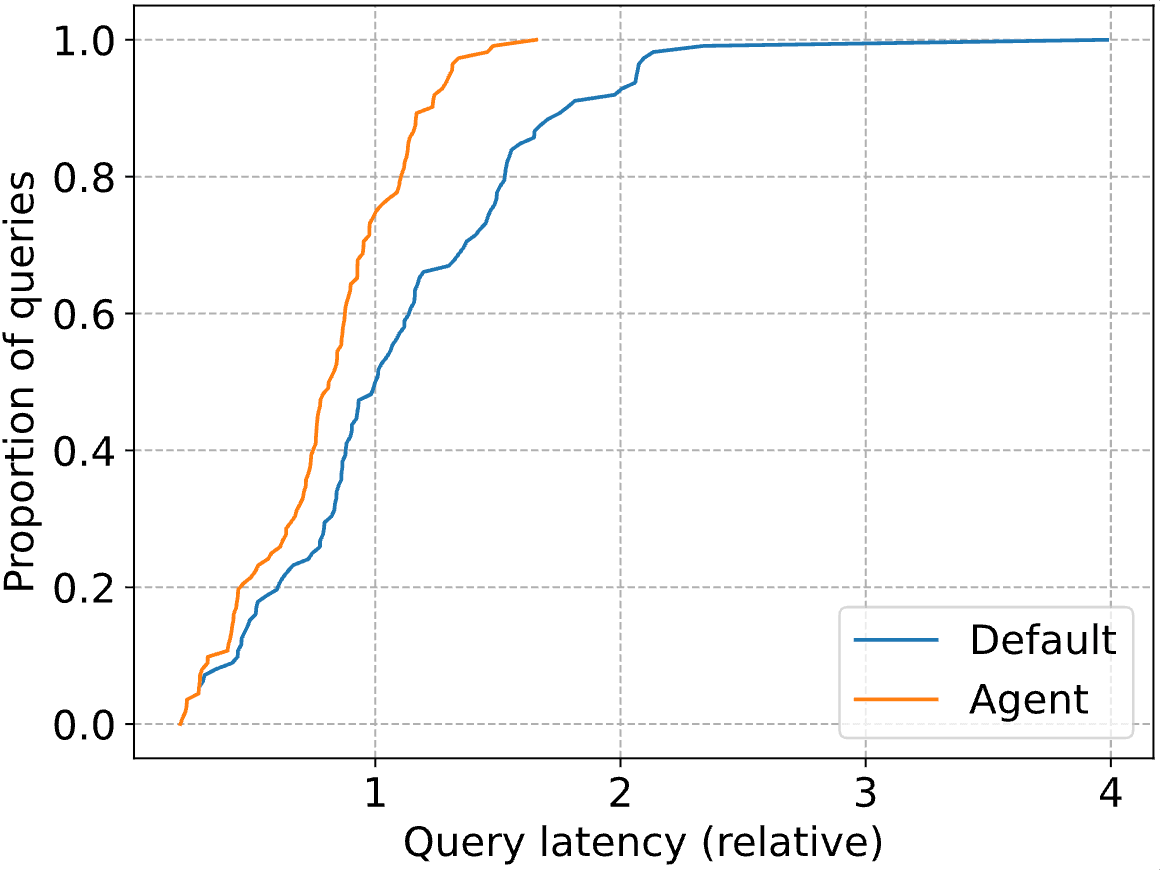
Die wirklich beeindruckenden Gewinne liegen im Schwanz der Verteilung, wobei die P90-Abfragelatenz um 41 % sinkt. Unten stellen wir die gesamte CDF sowohl für den Standard-Databricks-Optimierer („Default“) als auch für unseren Agenten („Agent“) dar. Die Abfragelatenzen sind auf die mediane Latenz des Databricks-Optimierers normalisiert (d. h. bei 1 erreicht die blaue Linie einen Anteil von 0,5).
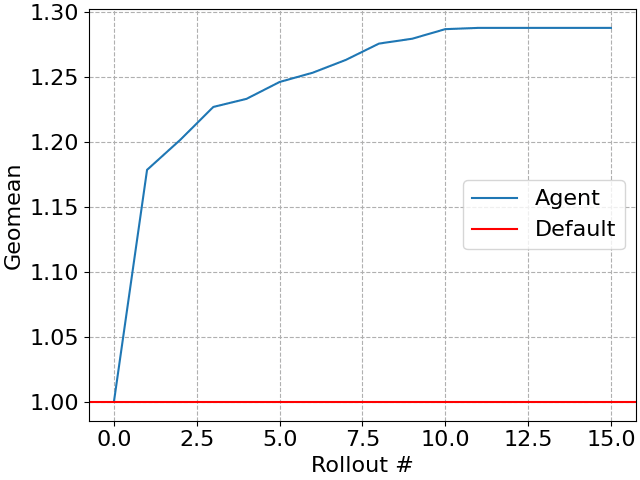
Unser Agent verbessert die Workload mit jedem getesteten Plan (manchmal auch als Rollout bezeichnet) fortschrittlich, wodurch ein einfacher „Anytime-Algorithmus“ entsteht, bei dem größere Zeitbudgets in weitere Abfrageleistungen umgewandelt werden können. Natürlich wird sich die Abfrageleistung irgendwann nicht mehr verbessern.
Eine der größten Verbesserungen, die unser Agent feststellte, war bei Abfrage 5b, einem einfachen 5-Wege-Join, der nach amerikanischen Produktionsfirmen sucht, die einen Film nach 2010 auf VHS veröffentlicht haben und in einer Notiz auf 1994 verweisen. Der Databricks-Optimierer konzentrierte sich zuerst auf die Suche nach amerikanischen VHS-Produktionsfirmen (was tatsächlich selektiv ist und nur 12 Zeilen ergibt). Der Agent findet einen Plan, der zuerst nach VHS-Veröffentlichungen sucht, die sich auf 1994 beziehen, was sich als deutlich schneller erweist. Dies liegt daran, dass die Abfrage LIKE-Prädikate verwendet, um VHS-Veröffentlichungen zu identifizieren, die für Kardinalitätsschätzer außergewöhnlich schwierig sind.
Unser Prototyp demonstriert das Potenzial von Agentensystemen zur autonomen Reparatur und Verbesserung von Datenbankabfragen. Diese Übung warf mehrere Fragen zur Agentengestaltung in unseren Köpfen auf:
- Welche Werkzeuge sollten wir dem Agenten geben? In unserem aktuellen Ansatz kann der Agent Kandidaten-Join-Reihenfolgen ausführen. Warum lassen wir den Agenten nicht spezifische Kardinalitätsabfragen ausgeben (z. B. die Größe eines bestimmten Teilplans berechnen) oder Abfragen, um bestimmte Annahmen über die Daten zu testen (z. B. um festzustellen, dass es vor 1995 keine DVD-Veröffentlichungen gab)?
- Wann sollte diese agentische Optimierung ausgelöst werden? Sicherlich kann ein Benutzer eine problematische Abfrage manuell zur Intervention kennzeichnen. Aber könnten wir diese Optimierung auch proaktiv auf regelmäßig laufende Abfragen anwenden? Wie können wir feststellen, ob eine Abfrage "Optimierungspotenzial" hat?
- Können wir Verbesserungen automatisch verstehen? Wenn der Agent eine bessere Join-Reihenfolge findet als die vom Standardoptimierer gefundene, kann diese Join-Reihenfolge als Beweis dafür angesehen werden, dass der Standardoptimierer eine suboptimale Reihenfolge wählt. Wenn der Agent einen systematischen Fehler im zugrunde liegenden Optimierer korrigiert, können wir dies entdecken und zur Verbesserung des Optimierers nutzen?
Natürlich sind wir nicht die Einzigen, die über das Potenzial von LLMs für die Abfrageoptimierung nachdenken [D]. Bei Databricks sind wir begeistert von der Möglichkeit, die Generalisierbarkeit von LLMs zu nutzen, um Datensysteme selbst zu verbessern.
Wenn Sie an diesem Thema interessiert sind, lesen Sie auch unseren Folgebeitrag im UCB-Blog über "Wie denken LLM-Agenten über SQL-Join-Reihenfolgen nach?".
Komm zu uns
Mit Blick auf die Zukunft freuen wir uns darauf, die Grenzen dessen, wie KI Datenbankoptimierungen gestalten kann, weiter zu verschieben. Wenn Sie leidenschaftlich daran interessiert sind, die nächste Generation von Datenbank-Engines zu entwickeln, schließen Sie sich uns an!
1 Databricks verwendet Techniken wie Laufzeitfilter, um die Auswirkungen schlechter Join-Reihenfolgen abzumildern. Die hier präsentierten Ergebnisse beinhalten diese Techniken.
Anmerkungen
A. Techniken zur Kardinalitätsschätzung umfassen beispielsweise adaptive Rückmeldung, Deep Learning, Verteilungsmodellierung, Datenbanktheorie, Lerntheorie und Faktorzerlegungen. Frühere Arbeiten haben auch versucht, die traditionelle Query-Optimizer-Architektur vollständig durch Deep Reinforcement Learning, Multi-Armed Bandits, Bayesian Optimization oder fortschrittlichere Join-Algorithmen zu ersetzen.
B. Zum Beispiel wurden RAG-basierte Ansätze verwendet, um "LLM in the hot path"-Systeme zu bauen.
C. Obwohl grob, wurde dieser Ansatz in früheren Arbeiten verwendet.
D. Andere Forscher haben RAG-basierte Query-Reparatur-Systeme, LLM-gestützte Query-Rewrite-Systeme und sogar ganze Datenbanksysteme synthetisiert durch LLMs vorgeschlagen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.