Backstage mit Lakebase
Verzweigung des Entwicklungszyklus (Teil 1)
von Cameron Casher und Kevin Hartman
Seit dreißig Jahren sind die operative Datenbank und die analytische Datenbank zwei Artefakte, zwei Governance-Ebenen, zwei Budgets und normalerweise zwei Bereitschaftsrotationen, verbunden durch einen ETL-Job, den jemand in Eile geschrieben hat und den niemand besitzen möchte. Diese Trennung war nie eine Designentscheidung; sie war eine physikalische Einschränkung. OLTP und OLAP hatten tatsächlich unterschiedliche Speicherlayouts, unterschiedliche Rechenprofile und unterschiedliche Ausfallmodi, also bauten wir zwei Plattformen und verbanden sie nachträglich.
Diese Einschränkung löst sich auf. Wenn der Speicher gemeinsam genutzt wird, die Rechenleistung serverlos und pro Workload isoliert ist und die Governance auf der Katalogebene liegt, hören „operativ“ und „analytisch“ auf, architektonische Kategorien zu sein, und werden zu Zugriffsmustern auf derselben Grundlage.
Um zu testen, ob das in der Praxis tatsächlich stimmt, haben wir Backstage, Spotifys bekanntermaßen zustandsintensives Internal Developer Portal, von seiner Standard-Postgres-Datenbank abgekoppelt und auf Databricks Lakebase umgeleitet. In dieser dreiteiligen Serie untersuchen wir, was mit Deployment-Zyklen (Teil 1), Governance (Teil 2) und FinOps (Teil 3) passiert, wenn wir die Mauer zwischen der operativen Anwendung und der Datenplattform einreißen.
Das Setup: Backstage auf Lakebase zeigen
Lakebase stellt eine serverlose Postgres-Oberfläche bereit (die Neon's Architektur im Hintergrund nutzt), die sich innerhalb der Databricks-Plattform befindet. Da sie das Wire-Protokoll von Postgres spricht, weiß oder kümmert sich Backstage nicht darum, dass es nicht mit RDS spricht.
Die Verbindung herzustellen erforderte, dass app-config.yaml auf Lakebase zeigt und die standardmäßige In-Memory-Suche von Backstage durch PgSearchEngine ersetzt wird. Eine unmittelbare Hürde: Lakebase lehnt klassische Databricks Personal Access Tokens ab und erwartet stattdessen einen OAuth JWT. Die CLI bietet databricks postgres generate-database-credential, das einen geskripteten, kurzlebigen JWT für einen bestimmten Endpunkt generiert, was der vorgesehene Ansatz für Apps und CI ist. Für dieses POC haben wir diesen Befehl in ein leichtgewichtiges Cron-Skript verpackt, das alle 50 Minuten den DATABRICKS_TOKEN in unserer .env-Datei überschrieb, um den Token-Ablauf zu handhaben.
Nachdem die Authentifizierung geklärt war, liefen die Knex-Migrationen sauber durch und das Portal war live.
Branching verändert den Datenbankentwicklungszyklus
Das am meisten unterschätzte Merkmal einer traditionellen Postgres ist nicht ihr Funktionsumfang, sondern das Tempo, das sie den Teams aufzwingt, die sie besitzen.
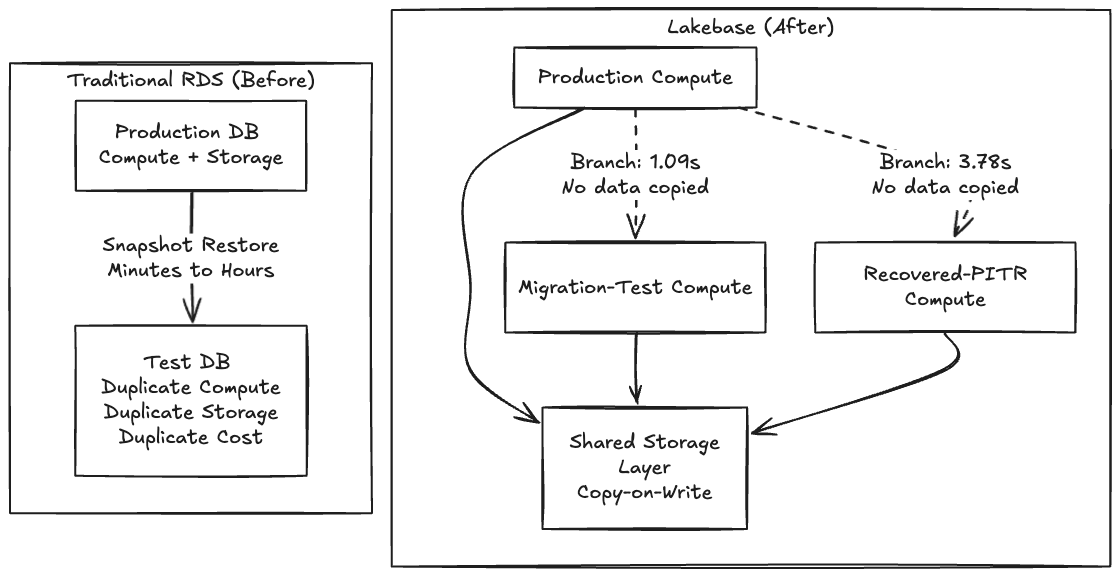
Thoughtworks ist ein konsequenter Verfechter von Backstage als Grundlage für IDPs durch den Technology Radar. Daher haben wir Backstage für dieses POC gewählt, da wir das Tool sehr gut kennen und seine Schema-Migrationen notorisch fragil sind, was es zu einer perfekten Gelegenheit machte, eine Lakebase-Integration zu testen. Auf traditionellem RDS bedeutet das Testen einer riskanten Migration, Minuten oder Stunden auf die Wiederherstellung eines Snapshots auf einer parallelen Instanz zu warten. Da das Erstellen einer Kopie langsam und teuer ist, testen Teams einfach nicht. Sie drücken die Daumen und führen die Migration in einem Wartungsfenster durch.
Wenn das Erstellen einer Kopie kostenlos wird, hört man auf zu fragen: „Ist diese Änderung sicher genug, um sie auszuführen?“ und beginnt zu fragen: „Welche Abzweigung der Produktion möchte ich zuerst darauf ausprobieren?“
Da Lakebase Speicher von Rechenleistung trennt und eine Copy-on-Write-Architektur verwendet, kopiert das Erstellen eines Branches keine Daten, sondern erstellt einen Zeiger auf dieselben zugrunde liegenden Seiten und weicht nur beim Schreiben ab. Deshalb ist der Vorgang sofortig.
Ein Stolperstein, den die Dokumentation nicht offensichtlich macht: Der Request Body muss alles in einem `spec`-Objekt verschachteln, und Sie müssen `ttl`, `expire_time` oder `no_expiry` angeben. Ohne dies gibt die API zurück: „Expiration must be specified.“
Die Steuerungsebene bestätigte dies sofort. Die eigentliche Daten-Ebene-Kopie des ~63 MB großen Backstage-Katalogs wurde in 1,09 Sekunden gelandet.
Point-in-Time Recovery: Die Rückgängig-Taste
Branching und Point-in-Time Recovery (PITR) sind im Wesentlichen dasselbe Primitive: Branching ist nur PITR mit source_branch_time = now. Um die Wiederherstellung gegen tatsächlich gelöschte Daten zu testen, haben wir unsere final_entities-Tabelle geleert, wodurch die Anzahl von 32 auf 0 sank.
Dann erstellten wir einen Wiederherstellungs-Branch aus einem Zeitstempel, der Sekunden vor dem Löschen erfasst wurde:
Die verstrichene Zeit von Ende zu Ende betrug 3,78 Sekunden.
Die Überprüfung der Daten bestätigte, dass der wiederhergestellte Branch alle 32 Entitäten zurück hatte; die Produktion war immer noch bei Null, was das Löschen als real und die Branches als vollständig isoliert bestätigte. Bemerkenswerterweise fragten wir nach 22:56:02 Uhr, aber Lakebase sprang auf 22:55:50 Uhr, 12 Sekunden früher, und sprang zurück zum nächstgelegenen WAL-Datensatz. Diese WAL-Level-Granularität ist ein wichtiger Vorbehalt für zeitkritische Wiederherstellungs-Workflows, aber der Incident-Zyklus lief trotzdem in weniger als einer Minute ab.
Wenn der Datenbankzustand zu einem billigen, verzweigbaren Artefakt statt zu einem 2 TB EBS-Volume wird, erhält jede riskante Operation einen Probelauf und jeder Vorfall eine Rückgängig-Funktion.
Von der Infrastrukturfähigkeit zum Entwickler-Workflow
Wie oben gezeigt, beweist dies, dass Datenbank-Branching funktioniert – eine 1-Sekunden-Kopie, eine 4-Sekunden-Wiederherstellung und eine echte Anwendung, die den Unterschied nicht kennt. Aber es gibt eine Lücke zwischen „die Datenbank kann verzweigen“ und „mein Team verzweigt die Datenbank so natürlich wie Code“. Das Schließen dieser Lücke ist dort, wo die massiven Auswirkungen auf die Entwicklerproduktivität in objektiven Gewinnen realisiert werden können.
Wir haben die letzten Monate damit verbracht, mit Entwicklungsteams zusammenzuarbeiten, um eine spezifische Frage zu beantworten: Was passiert mit der Geschwindigkeit eines Teams, wenn Datenbank-Branching unsichtbar wird – wenn es kein CLI-Befehl ist, den man ausführt, sondern etwas, das automatisch als Teil dessen geschieht, wie man bereits in seinem bevorzugten Editor arbeitet? Es wird an einer VS Code/Cursor-Erweiterung gearbeitet, die Git- und Datenbank-Branches automatisch synchronisiert, um dies zu beweisen – aber das Tooling ist zweitrangig gegenüber dem, was es ermöglicht.
Was Branching ermöglicht
Bei den Teams, mit denen wir Erfahrung haben, sieht der Sprint-Zyklus ohne Datenbank-Branching so aus:
- Erstellen Sie einen Git-Branch für die Feature-Entwicklung
- Schreiben Sie Mock-Objekte für jede Datenbank-Schnittstelle (MockUserRepository, MockOrderService...) für Testzwecke
- Schreiben Sie Unit-Tests mit einer gemockten oder In-Memory-Datenbank (H2, SQLite)
- Reichen Sie eine PR ein, lassen Sie sie überprüfen und führen Sie Code zusammen
- Stellen Sie in einer gemeinsam genutzten Staging-Umgebung bereit
- Entdecken Sie, dass die Schema-Migration nicht mit echten Daten funktioniert oder die Datengröße ein Hindernis darstellt
- Beheben Sie die Schema-Migration, stellen Sie erneut bereit, wiederholen Sie
Mit der Verfügbarkeit von Datenbank-Branching wird der Feature-Entwicklungszyklus eines Entwicklers geändert:
- Git-Branch erstellen – ein Lakebase-Datenbank-Branch kann automatisch in weniger als 1 Sekunde erstellt werden
- Ihre IDE verbindet sich sofort mit der echten Branch-Datenbank
- Code schreiben und Migrationen gegen echte Live-Datenbankdaten ab der ersten Codezeile ausführen
- Integrationstests gegen die echte Datenbank schreiben – keine Datenbank-Mocks
- Mehrere Lösungen können experimentell getestet werden, da das Rollback von Datenbankänderungen trivial ist
- Push und PR öffnen – CI erstellt seinen eigenen Datenbank-Branch, validiert Code und Schema, veröffentlicht einen Schema-Diff
- QA-Teammitglieder können ihren eigenen Datenbank-Branch für destruktive Tests erhalten – kann in Sekunden zurückgesetzt werden
- Zusammenführen – Nach dem Zusammenführen kann die CD-Pipeline Upstream-Umgebungen wie UAT und Produktion migrieren und alle Branches bereinigen – Code und Daten.
Die Mock-Objekte verschwinden. Die Staging-Kollisionen verschwinden. Das "funktioniert auf meiner Maschine, bricht aber im Staging" verschwindet. Entwickler erhalten eine Live-Datenbank, um mehrere Lösungen auszuprobieren. Die Datenbankänderungen, die bisher erst beim Deployment entdeckt wurden, werden nun während der Entwicklung erkannt, wo sie günstig zu beheben sind. Sofortige Branches für Leistungstests, wegwerfbare und isolierte Branches für Funktionstests und ein laufender Branch für UAT-Stakeholder werden trivial.
Nach unserer Erfahrung mit mehreren Partnerteams, die diesen Workflow evaluieren, machen Mock-Objekte 20-30 % des Testcodes aus. Das ist keine Testabdeckung – das ist Testinfrastruktur. Infrastruktur, die sich im Laufe der Zeit vom Produktionsverhalten abweicht und falsche Sicherheit erzeugt. Wenn das Verzweigen einer produktionsäquivalenten Datenbank nichts kostet, wird Mocking zur teuren Wahl.
Die Frage ist nun, wie viel von Ihrem Sprint verbringen Sie mit Workarounds für eine Einschränkung, die nicht mehr existiert.
Im Teil 2 dieser Serie werden wir uns ansehen, was mit Sicherheit und Compliance geschieht, wenn diese operative Datenbank direkt in Unity Catalog, die einheitliche Governance-Schicht von Databricks, integriert wird.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.