Best Practices für Model Serving mit hoher QPS auf Databricks
Betreiben Sie Echtzeit-ML-Anwendungen nativ im Lakehouse
von Tejas Sundaresan, Anshul Gupta, Arjun DCunha und Mike Del Balso
- Model Serving unterstützt Echtzeit-Endpunkte, die auf über 300.000 QPS (CPU) skalieren, mit einer verbesserten Engine, die auf Echtzeit-ML mit geringer Latenz spezialisiert ist.
- Kunden verwenden Model Serving für Echtzeit-ML-Anwendungen mit hoher QPS wie Empfehlungssysteme, Betrugserkennung, Suche und andere Anwendungsfälle.
- Verwenden Sie routenoptimierte Endpunkte, Best Practices für Endpunkte und clientseitige Optimierungen, um bei der Bereitstellung Ihrer Modelle hohe Performanceziele zu erreichen.
Kunden erwarten bei jeder Interaktion sofortige Reaktionen, sei es eine in Millisekunden erstellte Empfehlung, eine betrügerische Abbuchung, die vor der Verrechnung blockiert wird, oder ein Suchergebnis, das für den Nutzer unmittelbar erscheint. Bei Scale hängt die Bereitstellung dieser Erfahrungen von Model-Serving-Systemen ab, die selbst bei anhaltender und ungleichmäßiger Last schnell, stabil und vorhersehbar bleiben.
Wenn der Traffic auf Zehntausende oder Hunderttausende von Anfragen pro Sekunde anwächst, stoßen viele Teams auf dieselben Herausforderungen. Die Latenz wird inkonsistent, die Infrastrukturkosten steigen und Systeme erfordern eine ständige Feinabstimmung, um Bedarfsspitzen und -einbrüche zu bewältigen. Fehler sind zudem schwerer zu diagnostizieren, je mehr Komponenten miteinander verknüpft sind. Dies lenkt die Teams von der Verbesserung der Modelle ab und zwingt sie, sich stattdessen auf den laufenden Betrieb der Produktionssysteme zu konzentrieren.
Dieser Beitrag erklärt, wie Model Serving on Databricks Echtzeit-Workloads mit hoher QPS unterstützt, und beschreibt konkrete Best Practices, die Sie anwenden können, um niedrige Latenz, hohen Throughput und vorhersagbare Performance in der Produktion zu erzielen.
Databricks Model Serving: Einfach und skalierbar für Workloads mit hohen QPS
Databricks Model Serving bietet eine vollständig verwaltete, skalierbare Serving-Infrastruktur direkt in Ihrem Databricks Lakehouse. Nehmen Sie einfach ein bestehendes Modell aus Ihrer Modellregistrierung, stellen Sie es bereit und erhalten Sie einen REST-Endpunkt auf einer verwalteten Infrastruktur, die hoch skalierbar und für Datenverkehr mit hohen QPS optimiert ist.
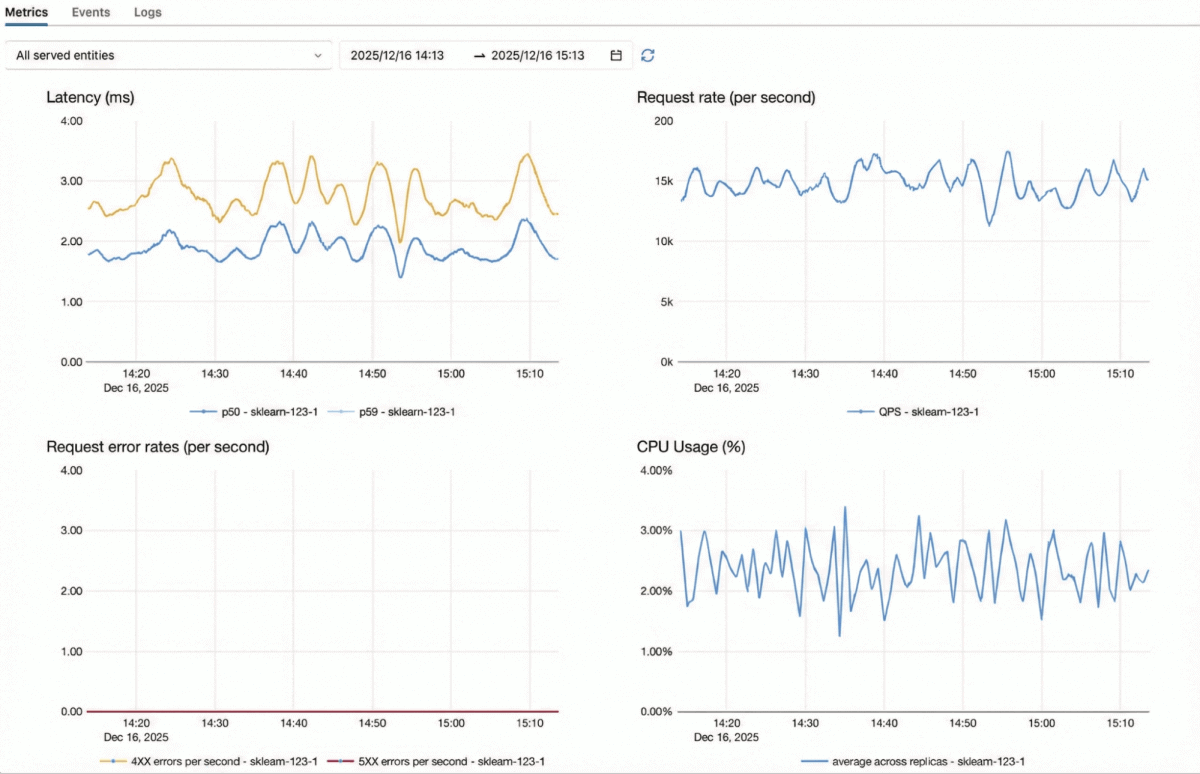
Databricks Model Serving ist für geschäftskritische Workloads mit hoher QPS optimiert:
- Echtzeit Adaptive Engine – Ein selbstoptimierender Modellserver, der sich an die Arbeitslast jedes Modells anpasst und so einen höheren Durchsatz und eine bessere Ressourcennutzung mit derselben Hardware erzielt.
- Vollständig horizontal skalierbare Architektur – Unser Inferenzserver, unsere Authentifizierungsebene, unser Proxy und unser Ratenbegrenzer sind alle so konzipiert, dass sie unabhängig voneinander horizontal skalieren können, sodass das System sehr hohe Anfragevolumen bewältigen kann.
- Schnelle elastische Skalierung – Inferenzserver können nach oben und unten skalieren und sich so an plötzliche Traffic-Spitzen oder -Einbrüche anpassen, ohne dass eine Überbereitstellung erforderlich ist.
- Native Feature Store-Integration: Databricks Feature Serving lässt sich nahtlos in Model Serving integrieren, sodass Sie Features und Modelle zusammen als eine vollständige Anwendung bereitstellen können.
- Lakehouse Native: Kunden können Features, Training, MLOps über MLFlow, Serving und Echtzeit-Monitoring ihrer produktiven ML-Systeme in einem einheitlichen Stack zentralisieren, was zu einer geringeren Betriebskomplexität und schnelleren Deployments führt.
Databricks Model Serving ermöglicht unserem Team, Machine-Learning-Modelle mit der Zuverlässigkeit und Skalierbarkeit bereitzustellen, die für Echtzeitanwendungen erforderlich sind. Es ist darauf ausgelegt, Workloads mit hohem QPS-Wert zu bewältigen und gleichzeitig die Hardwareauslastung zu maximieren. Darüber hinaus bietet Databricks eine SOTA-Feature-Store-Lösung mit superschnellen Lookups, die für solche Workloads benötigt werden. Mit diesen Funktionen können sich unsere ML-Ingenieure auf das Wesentliche konzentrieren: die Verfeinerung der Modell-Performance und die Verbesserung der Benutzererfahrung. —Bojan Babic, Research Engineer, You.com
Best Practices für eine hohe QPS-Leistung beim Model-Serving
Auf dieser Grundlage besteht der nächste Schritt darin, Ihre Endpunkte, Modelle und Client-Anwendungen zu optimieren, um insbesondere bei zunehmendem Traffic konsistent einen hohen Durchsatz und eine geringe Latenz zu erzielen. Die folgenden Best Practices unterstützen reale Kunden-Deployments, die täglich Millionen bis Milliarden von Inferenzen ausführen.
Weitere Informationen finden Sie in unserem Leitfaden für Best Practices.
Best Practice 1: Geringere Latenz durch die Verwendung von routenoptimierten Endpunkten
Ein wichtiger erster Schritt ist die Sicherstellung, dass die Netzwerkebene für hohen Durchsatz/QPS und geringe Latenz optimiert ist. Model Serving erledigt dies für Sie durch routenoptimierte Endpunkte. Wenn Sie die Routenoptimierung für einen Endpunkt aktivieren, optimiert Databricks Model Serving das Netzwerk und das Routing für Inferenzanfragen, was zu einer schnelleren und direkteren Kommunikation zwischen Ihrem Client und dem Modell führt. Dies verkürzt die Zeit, die eine Anfrage benötigt, um das Modell zu erreichen, erheblich und ist besonders nützlich für Anwendungen mit geringer Latenz wie Empfehlungssysteme, Suche und Betrugserkennung.

{kind=link}
Best Practice 2: Das Modell optimieren und die Endpunkte effizient gestalten
In Szenarien mit hohem Durchsatz helfen die Reduzierung der Modellkomplexität, die Auslagerung der Verarbeitung vom Serving-Endpunkt und die Wahl der richtigen Parallelitätsziele Ihrem Endpunkt, auf große Anforderungsvolumen zu skalieren – und das mit genau der richtigen Menge an benötigtem Compute. So sind Ihre Endpoints kosteneffizient, können aber dennoch skalieren, um Performance-Ziele zu erreichen.
- Modellgröße und -komplexität: Kleinere, weniger komplexe Modelle führen im Allgemeinen zu schnelleren Inferenzzeiten und höherer QPS. Ziehen Sie Techniken wie Modellquantisierung oder Pruning in Betracht, wenn Ihr Modell groß ist.
- Vorverarbeitung und Nachverarbeitung: Lagern Sie komplexe Vorverarbeitungs- und Nachverarbeitungsschritte nach Möglichkeit vom Serving-Endpunkt aus. Dadurch wird sichergestellt, dass Ihr Model Serving-Endpunkt nur den entscheidenden Schritt der Inferenz durchführt.
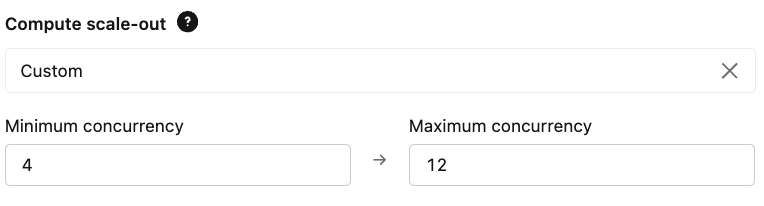
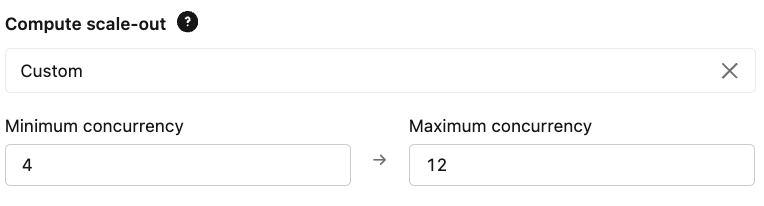
- Skalierung: Konfigurieren Sie Ihre Bereitstellungs-Gleichzeitigkeitsgrenzen basierend auf Ihren erwarteten QPS- und Latenzanforderungen. Dadurch wird sichergestellt, dass der endpoint für die Bewältigung der Grundlast ausreicht und das Maximum Spitzenlasten abdeckt.
{kind=link}
Mit Databricks Model Serving können wir Workloads mit hohen QPS-Raten wie Personalisierung und Empfehlungen in Echtzeit bewältigen. Es bietet unseren Marken die erforderliche Scale und Geschwindigkeit, um unseren Millionen von Lesern maßgeschneiderte Content-Erlebnisse zu bieten. – Oscar Celma, SVP für Data Science und Produktanalytik bei Conde Nast
Best Practice 3: Clientseitigen Code optimieren
Die Optimierung des clientseitigen Codes stellt sicher, dass Anfragen schnell verarbeitet werden und Ihre Endpunkt-Recheninstanzen vollständig ausgelastet sind – was zu einem besseren QPS-Durchsatz, Kosteneinsparungen und geringerer Latenz führt.
- Verbindungspooling: Verwenden Sie clientseitiges Verbindungspooling, um den Overhead beim Herstellen neuer Verbindungen für jede Anfrage zu reduzieren. Das Databricks SDK wendet immer die Best Practices für Verbindungen an. Wenn Sie jedoch Ihren eigenen Client verwenden müssen, achten Sie auf die Strategie für das Verbindungsmanagement.
- Payload-Größe: Halten Sie die Payloads für Anfragen und Antworten so klein wie möglich, um die Netzwerkübertragungszeit zu minimieren.
- Clientseitiges Batching: Wenn Ihre Anwendung mehrere Anfragen in einem einzigen Aufruf senden kann, aktivieren Sie das Batching auf der Client-Seite. Dies kann den Overhead pro Vorhersage erheblich reduzieren.
Fassen Sie Anfragen in Batches zusammen, wenn Sie Databricks Model Serving Endpoints aufrufen
Starten Sie noch heute
- Testen Sie Databricks Model Serving! Stellen Sie ML-Modelle als REST-API bereit.
- Weitere Informationen: Weitere Informationen finden Sie in der Databricks- Dokumentation zu Custom Model Serving.
- Leitfaden für hohe QPS: Lesen Sie den Leitfaden für Best Practices für das Serving mit hohen QPS auf Databricks Model Serving auf Databricks.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.