BI-Bereitstellungshinweise; Maximierung von Leistung und TCO
Ein Bottom-up-Leitfaden für den Databricks BI Serving Stack – vom physischen Layout über gesteuerte Metriken bis hin zur aggregationsbewussten Materialisierung
von Chris Koester
- Strukturieren Sie Ihre physische Ebene mit Sternschemata, Liquid Clustering und Predictive Optimization, um BI-Abfragen zu beschleunigen.
- Definieren Sie gesteuerte Geschäftsmetriken einmalig mit Unity Catalog Metric Views – einer Headless-Semantikschicht, die jedes BI-Tool, jeden Genie-Bereich und jeden KI-Agenten aus einer einzigen Quelle der Wahrheit bedient.
- Aktivieren Sie aggregationsbewusste Materialisierung, um OLAP-ähnliche Leistung mit vortaggregierten Daten zu erzielen, ohne separate Aggregattabellen erstellen und pflegen zu müssen.
Ihre BI-Dashboards sind langsam, und die Optimierung kostet zu viel Zeit und Geld.
Es ist ein bekanntes Muster. Eine Dashboard-Abfrage dauert 30 Sekunden, also erstellt jemand eine Aggregationstabelle, um sie zu beschleunigen. Diese Tabelle benötigt eine Aktualisierungspipeline. Die Pipeline muss überwacht werden. Dann benötigt ein zweites BI-Tool dieselben Daten in einer leicht anderen Form, also erstellt jemand eine weitere Aggregationstabelle mit einer separaten Pipeline. Bald verwalten Sie eine Ansammlung von Aggregationen, Extrakten und tool-spezifischen semantischen Ebenen – jede mit ihrem eigenen Aktualisierungsfenster, ihren eigenen Governance-Lücken und ihrem eigenen Posten auf der Compute-Rechnung.
BI-Workloads unterscheiden sich von anderen analytischen Workloads. Sie sind hochgradig nebenläufig, latenzempfindlich und wiederholen ihre Abfragemuster. Diese Kombination erfordert einen durchdachten Ansatz für die Modellierung, Speicherung, Optimierung und Bereitstellung von Daten. Die gute Nachricht: Databricks bietet einen vollständigen Stack für die BI-Bereitstellung – vom physischen Datenlayout bis zu einer gesteuerten semantischen Ebene – und jede Ebene verstärkt die Leistungsgewinne der darunter liegenden Ebene.
Dieser Beitrag führt Sie von unten nach oben durch diesen Stack, mit praktischen Anleitungen, wo Sie sich für die größten Verbesserungen bei Abfrageleistung und Kosten konzentrieren sollten.
Der BI-Bereitstellungs-Stack
Bevor wir uns mit jeder Ebene befassen, hier das Gesamtbild:
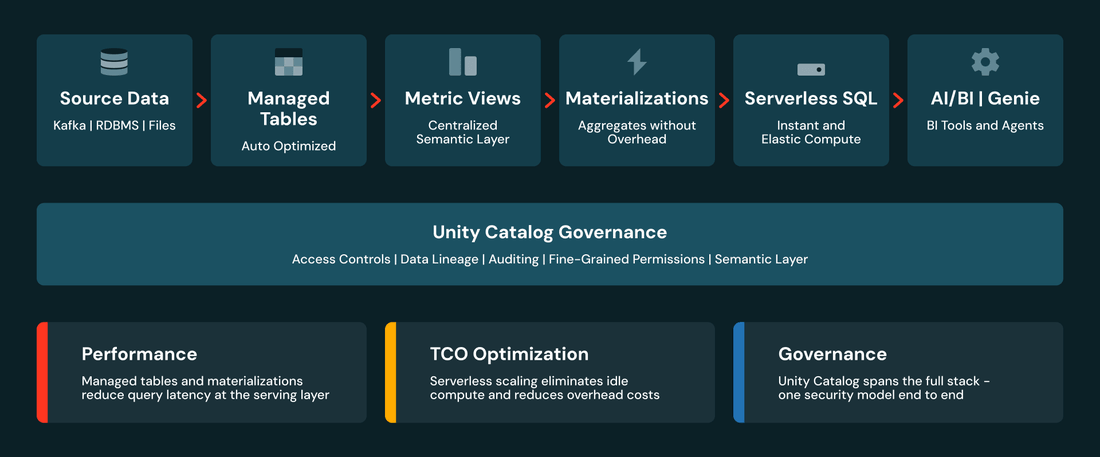
Unity Catalog bietet durchgängig Governance – Lineage und Zugriffskontrolle von Rohdaten über Semantik bis zum Verbrauch. Jede Ebene adressiert einen anderen Aspekt von Leistung und Kosten. Lassen Sie uns sie durchgehen.
Optimieren Sie die physische Ebene
Die physische Ebene ist, wo die meiste BI-Leistung gewonnen oder verloren wird. Wenn Sie diese richtig gestalten, profitiert jede Abfrage – bevor Sie die semantische Ebene berührt haben.
Beginnen Sie mit dimensionalem Modellieren
Sternschemata bleiben der Goldstandard für die BI-Abfrageleistung. Breite, denormalisierte Dimensionstabellen, die über Surrogat-Schlüssel mit Faktentabellen verbunden sind, geben dem Abfrageoptimierer saubere, vorhersagbare Join-Pfade.
Databricks unterstützt vollständig die relationalen Modellierungskonstrukte, die Sie benötigen: Primär- und Fremdschlüsselbeschränkungen (mit RELY für Optimizer-Hinweise), Identitätsspalten für Surrogat-Schlüssel und CHECK und NOT NULL Beschränkungen. Wenn Sie eine Medaillon-Architektur verfolgen, behalten Sie Ihre normalisierten oder Data Vault-Modelle in Silver und erstellen Sie denormalisierte Sternschemata in Gold für den BI-Verbrauch.
Detaillierte Implementierungsmuster – SCD Typ-1 und Typ-2-Verarbeitung, Faktentabellen-ETL mit MERGE, späte Dimensionen – finden Sie in der Blog-Serie Implementing a Dimensional Data Warehouse in Databricks SQL.
Verwenden Sie verwaltete Tabellen
Unity Catalog verwaltete Tabellen sind die Grundlage für alles andere in diesem Stack. Unity Catalog verwaltet alle Lese-, Schreib-, Speicher- und Optimierungsaufgaben für verwaltete Tabellen. Dies ermöglicht automatische Funktionen, die Sie mit externen Tabellen nicht erhalten: Predictive Optimization (weiter unten beschrieben) ist standardmäßig aktiviert. Automatische Liquid Clustering wählt Clustering-Schlüssel aus, die sich an sich ändernde Abfragemuster anpassen. Metadaten-Caching ist immer aktiv, reduziert Cloud-Speicheranfragen und beschleunigt die Abfrageplanung.
Verwenden Sie verwaltete Tabellen auf der gesamten Plattform – nicht nur für die BI-Bereitstellung, sondern auch in den Bronze-, Silver- und Gold-Schichten. Sie sind der Standard-Tabellentyp in Unity Catalog, und die Leistungs- und Governance-Vorteile verstärken sich mit jeder anderen Optimierung in diesem Stack.
Wenden Sie Liquid Clustering an
Liquid Clustering ersetzt statische Partitionierung und manuelle Z-ORDER – und im Gegensatz zu diesen Ansätzen können Sie Clustering-Schlüssel neu definieren, ohne vorhandene Daten neu zu schreiben. Fügen Sie CLUSTER BY (col1, col2) bei der Tabellenerstellung hinzu oder verwenden Sie ALTER TABLE für vorhandene Tabellen. Wenn Sie sich nicht sicher sind, welche Spalten Sie auswählen sollen, lässt CLUSTER BY AUTO Predictive Optimization Schlüssel basierend auf beobachteten Abfragemustern auswählen.
Für BI-Workloads clustern Sie nach Ihren häufigsten Filter- und Join-Spalten – Datumsangaben, Region, Produktkategorie. Sie können bis zu vier Spalten auswählen, und wenn zwei Spalten stark korreliert sind, nehmen Sie nur eine auf. Wenn Dashboards nach Cluster-Spalten filtern, verbessert Liquid Clustering die Abfrageleistung durch Datenüberspringen.
Lassen Sie Predictive Optimization den Rest erledigen
Predictive Optimization führt automatisch OPTIMIZE, VACUUM und Statistiksammlung für Tabellen aus, die von diesen Operationen profitieren würden – Sie müssen diese Jobs also nicht selbst planen. Es sammelt sowohl Delta-Datenüberspringungsstatistiken als auch Abfrageoptimierer-Statistiken während Photon-Schreibvorgängen und füllt Statistiken für vorhandene Tabellen nach. In beobachteten Workloads führte dies zu einer durchschnittlichen Leistungssteigerung von 22 %. Für BI-Workloads mit wiederkehrenden Filtermustern ist der Effekt besonders signifikant – bessere Statistiken bedeuten besseres Datenüberspringen und effizientere Abfragepläne.
Aktivieren Sie Predictive Optimization auf Katalogebene und lassen Sie es laufen. Die Verwendung von Predictive Optimization ist eine der optimierungen mit dem höchsten Ertrag und dem geringsten Aufwand, die Sie vornehmen können.
Das Ergebnis: BI-Abfragen scannen weniger Daten, joinen effizienter und sind kostengünstiger im Betrieb – und Sie haben die semantische Ebene noch nicht einmal berührt.
Metric Views: Definieren Sie Ihre Metriken einmal
Hier wird es interessant. Die meisten Organisationen haben dieselben Geschäftsmetriken an mehreren Stellen definiert – eine Umsatzberechnung in einem BI-Tool, eine leicht andere in einem anderen, eine dritte Variante in einem SQL-Notebook, das jemand letztes Quartal geschrieben hat. Jede Definition driftet unabhängig. Niemand ist sicher, welche die richtige ist.
Metric Views in Unity Catalog lösen dieses Problem, indem sie eine Headless-BI-Schicht bereitstellen – eine einzige, gesteuerte semantische Ebene, auf der Sie Ihr Datenmodell und Ihre KPIs einmal definieren, unabhängig von einem bestimmten BI-Tool. Sie definieren sie zentral in SQL oder über die Point-and-Click-Oberfläche im Unity Catalog Explorer. AI/BI-Dashboards, Genie, SQL-Notebooks und Drittanbieter-BI-Tools lösen Metriken aus denselben Definitionen. Definieren Sie eine Metrik einmal, und jeder Verbraucher – Mensch oder KI – erhält dieselbe Antwort.
Metric Views gehen über zentralisierte Metrikdefinitionen hinaus – die semantischen Metadaten machen den Unterschied. Felder wie display_name, comment und synonyms geben KI-Systemen den Kontext, den sie benötigen, um Geschäftsfragen korrekt zu interpretieren. Wenn ein Benutzer Genie fragt: „Wie hoch war unser Umsatz letzte Woche?“, sind diese Annotationen der Grund, warum Genie natürliche Sprache auf die richtige Kennzahl und Dimensionen abbildet. Keine benutzerdefinierten Prompts, kein separates Glossar. Dasselbe gilt für KI-Agenten, die auf Databricks basieren – jeder Agent mit Zugriff auf Unity Catalog kann gesteuerte Metriken über die semantische Ebene entdecken und abfragen, anstatt hartcodiertes SQL zu verwenden. Je reicher Ihre Metadaten sind, desto genauer liefert die KI die richtige Antwort.
Hier ist ein Beispiel, das eine Systemtabelle verwendet, da jeder Databricks-Kunde Zugriff darauf hat – aber dasselbe Muster gilt für Geschäfts-KPIs wie Umsatz, Bestellvolumen oder Kundenbindung. Diese Metric View berechnet DBSQL-Warehouse-Metriken:
Verbraucher fragen die Metric View mit MEASURE() ab, um auf die gesteuerten Metrikdefinitionen zu verweisen:
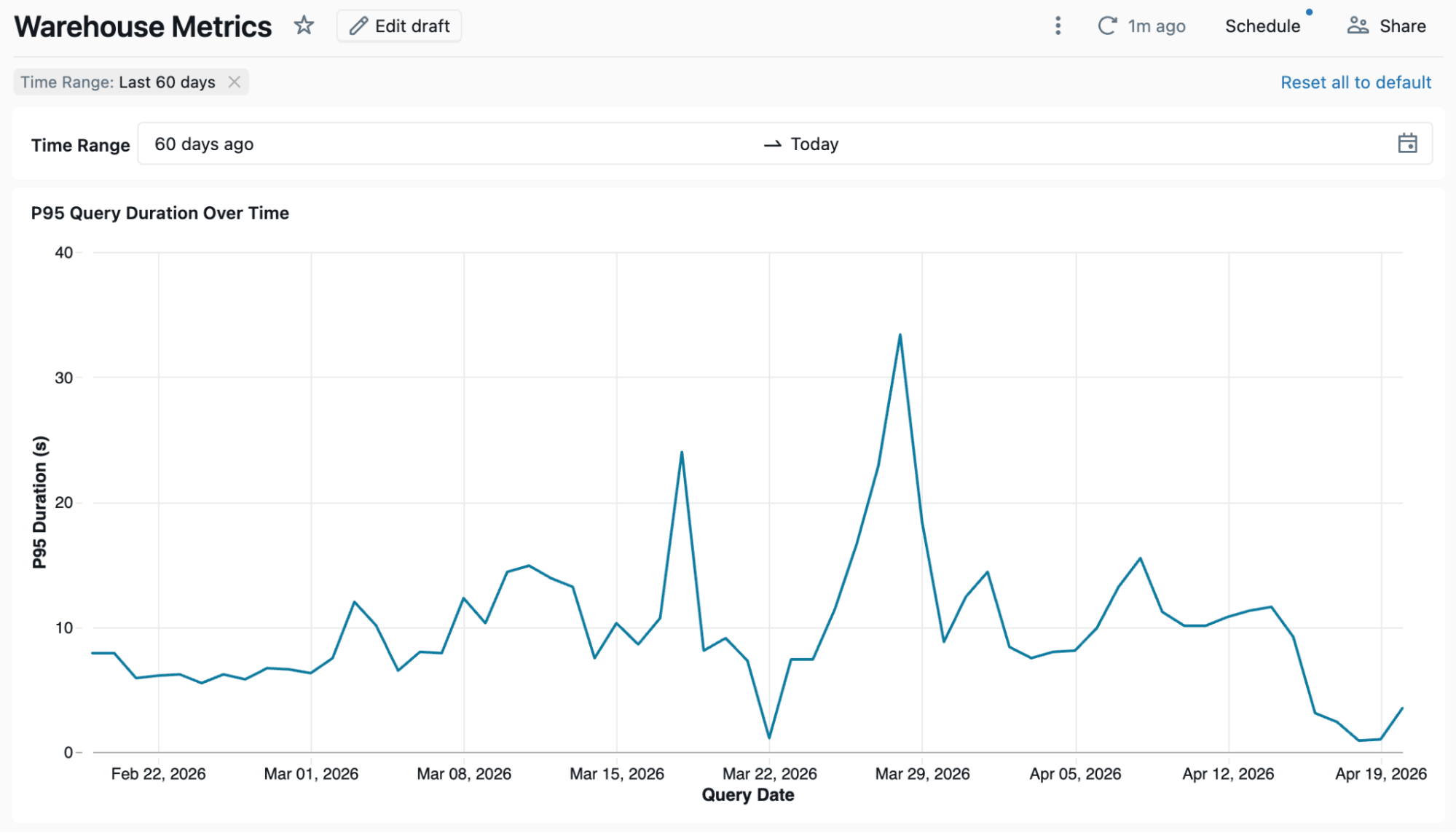
Die Metriken werden einmal in der Metric View definiert. Jedes Dashboard, jeder Genie-Bereich oder jedes Notebook, das metv_dbsql_metrics abfragt, liefert dasselbe Ergebnis. Unten sehen Sie ein Dashboard, das die Metric View als Quelle verwendet.
Hier ist Genie, das dieselbe Metrikansicht verwendet.
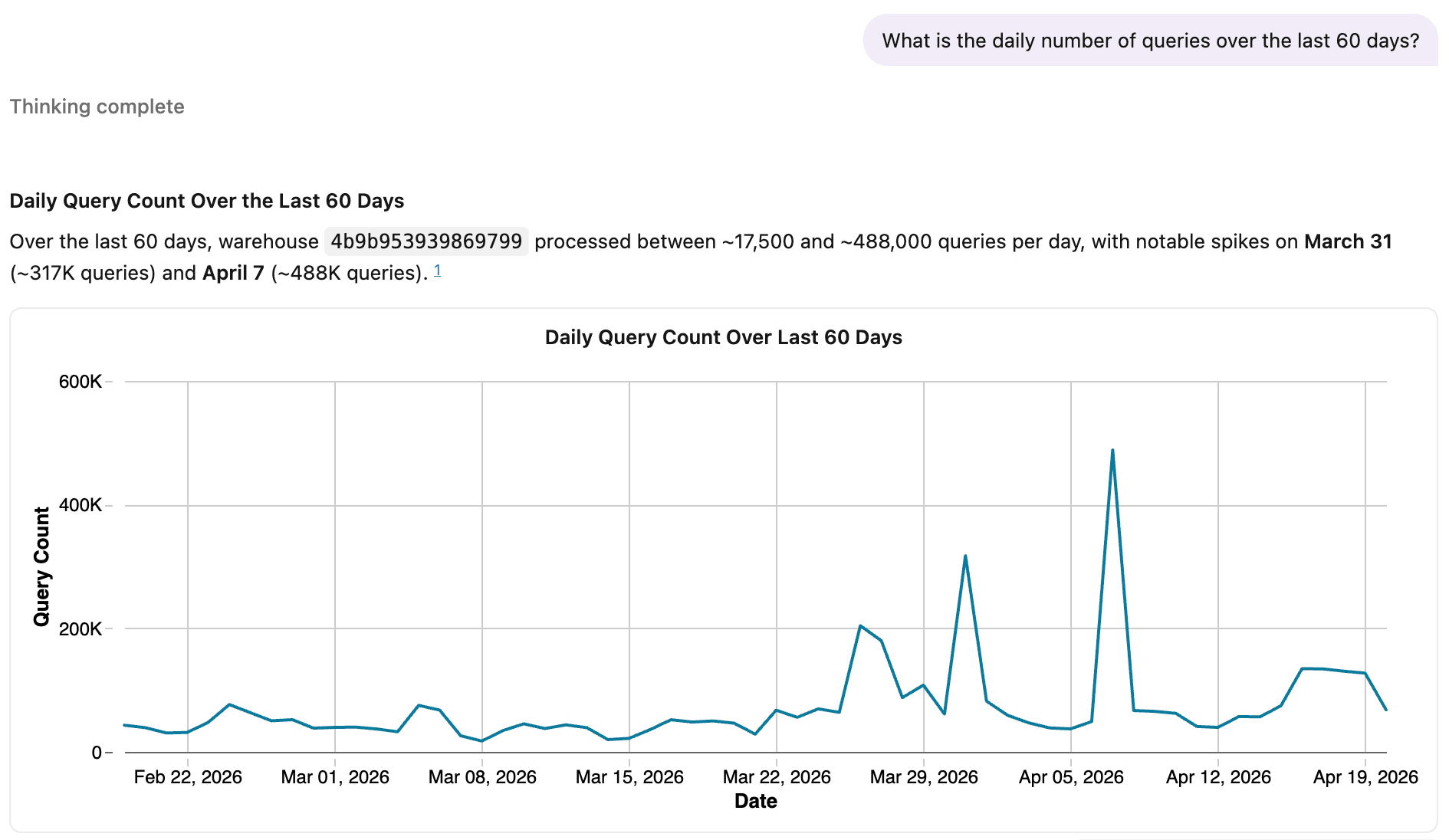
Für Teams, deren Metrikdefinitionen über mehrere BI-Tools verstreut sind, bieten Metrikansichten einen Weg, die semantische Schicht in Databricks zu konsolidieren. Anstatt separate Metriklogik in jedem Tool zu pflegen, definieren Sie sie einmal in Unity Catalog und verbinden Ihre BI-Tools mit dieser gesteuerten Quelle.
Die Kernimplementierung ist Open Source in Apache Spark™ (SPARK-54119), mit kommender Unity Catalog OSS-Unterstützung — Sie bauen also auf einem offenen Standard ohne Vendor Lock-in auf. Diese Offenheit wird noch wichtiger, da KI immer mehr BI-Aufgaben übernimmt. Agenten, die Ihre Daten abfragen, benötigen eine konsistente, maschinenlesbare Definition dessen, was jede Metrik bedeutet, und ein offener Standard ermöglicht es jedem Tool oder Agenten — nicht nur anbieterspezifischen —, dieselben gesteuerten Metriken zu verarbeiten.
Materialisierung von Metrikansichten: OLAP-Leistung ohne den Mehraufwand
Traditionell war die Antwort, wenn BI-Dashboards zu langsam waren, die Erstellung von Aggregattabellen. Sie würden materialisierte Ansichten oder benutzerdefinierte Voraggregattabellen über Ihrem Sternschema erstellen, Aktualisierungspipelines einrichten und Ihre BI-Tools auf die neuen Tabellen umleiten. Es funktionierte, aber es fügte eine ganze Ebene von Objekten und Pipelines hinzu, die gepflegt werden mussten — und jedes Mal, wenn sich die Aggregationslogik änderte, mussten Sie die BI-Tool-Abfragen entsprechend aktualisieren.
Die Materialisierung von Metrikansichten bietet eine einfachere Alternative. Wenn Sie die Materialisierung für eine Metrikansicht aktivieren, verwaltet die Plattform automatisch voraggregierte Ergebnisse hinter denselben Metrikdefinitionen, die Ihre BI-Tools bereits abfragen — keine separaten Aggregattabellen zu erstellen, keine BI-Tool-Abfragen zu refaktorieren. Hier ist, was unter der Haube passiert:
- Automatische Voraggregation: Metrikergebnisse werden vorab berechnet und gespeichert
- Inkrementelle Aktualisierung: Metriken bleiben aktuell, ohne vollständige Neuberechnung
- Intelligentes Umschreiben von Abfragen: Die Engine leitet Abfragen zur besten verfügbaren Materialisierung weiter
- Transparente Weiterleitung: Benutzer fragen Metriken auf die gleiche Weise ab — das System liefert den schnellsten Weg
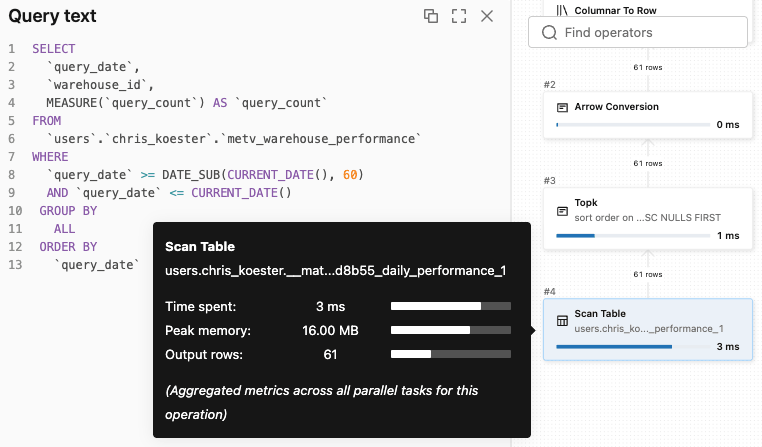
Dashboard-Abfragen, die zuvor vollständige Faktentabellen gescannt haben, greifen nun auf voraggregierte Materialisierungen zu — mit geringerer Latenz und geringeren Rechenkosten. Die obigen Dashboard- und Genie-Beispiele haben beide dieselbe Metrikansicht abgefragt, und beide wurden transparent an eine Materialisierung weitergeleitet. Der unten stehende Abfrageplan von Genie zeigt dies in Aktion.
Praktische TCO-Hinweise
Schnellere Abfragen und geringere Kosten sind keine konkurrierenden Ziele — jede Optimierung, die gescannte Daten reduziert, reduziert auch die Rechenleistung, für die Sie bezahlen. Und jede Optimierung im Stack verstärkt sich gegenseitig. Liquid Clustering und bessere Statistiken verbessern das Datenüberspringen und die Abfragepläne. Materialisierungen können inkrementell aktualisiert werden, wodurch die Rechenleistung, die SQL-Warehouses für die Bereitstellung von Dashboards benötigen, reduziert wird. Hier sind einige weitere Möglichkeiten, die Kosten zu senken:
- Passen Sie Ihr SQL-Warehouse richtig an. Verwenden Sie Serverless SQL-Warehouses mit Autoskalierung für BI-Concurrency-Bursts. Sie zahlen für das, was Sie verwenden, nicht für die Spitzenkapazität.
- Nutzen Sie die Caching-Stufen von DBSQL. Der Festplattencache hält Hot Data lokal für das Warehouse, und der Abfrageergebnis-Cache (QRC) bedient wiederholte Abfragen ohne erneute Ausführung. Für Dashboards mit konsistenten Abfragemustern verwandelt Caching viele Anfragen in Millisekunden-Latenz-Antworten bei nahezu null Rechenkosten.
- Eliminieren Sie redundante Datenbewegungen. Bedienen Sie BI direkt vom Lakehouse über DirectQuery oder Live-Verbindungen, anstatt Extrakte oder Importe zu verwenden.
- Überwachen Sie mit Systemtabellen. Systemtabellen wie
system.billing.usageundsystem.query.historykönnen verwendet werden, um die BI-Nutzung nach Dashboard, Benutzer und Warehouse zu verfolgen. Erstellen Sie Metrikansichten und ein KI/BI-Dashboard über Systemtabellen, um Einblick in Ihre BI-Nutzung zu erhalten.
Erste Schritte
Sie müssen nicht den gesamten Stack auf einmal implementieren. Beginnen Sie dort, wo Sie den größten Einfluss erzielen werden:
- Erstellen (oder validieren) Sie Ihr Gold-Layer-Sternschema mit verwalteten Tabellen, Primär-/Fremdschlüsseln und Liquid Clustering
- Aktivieren Sie Predictive Optimization für Ihren Katalog, um
OPTIMIZE,VACUUMund die Sammlung von Statistiken automatisch zu verwalten - Definieren Sie Metrikansichten für Ihre wichtigsten Business-KPIs — beginnen Sie mit SQL oder der UC Explorer UI
- Aktivieren Sie die Materialisierung von Metrikansichten für Ihre meistbesuchten Metriken
- Überwachen Sie die Ergebnisse — richten Sie Dashboards auf Metrikansichten aus und verfolgen Sie die Abfrageleistung über Systemtabellen
Databricks bietet Optimierungen auf jeder Ebene des BI-Serving-Stacks. Verwaltete Tabellen, Liquid Clustering und Predictive Optimization minimieren gescannte Daten und verbrauchte Rechenleistung. Metrikansichten zentralisieren Ihre Geschäftslogik in einer gesteuerten semantischen Schicht, die Dashboards, Genie und KI-Agenten konsistent bedient. Materialisierung liefert Abfrageleistung im Subsekundenbereich ohne manuelle Voraggregations-Pipelines. Zusammen verstärken sich diese Schichten — und senken sowohl die Abfragelatenz als auch die Gesamtbetriebskosten.
Beginnen Sie mit der Definition Ihrer ersten Metrikansicht für eine vorhandene Gold-Layer-Tabelle und aktivieren Sie die Materialisierung. Sehen Sie sich die unten stehenden Ressourcen an, um loszulegen.
- Unity Catalog Metric Views Übersicht
- Metrikansichten in KI/BI anzeigen
- Metrikansichten aus einem SQL-Editor abfragen
- Implementierung eines dimensionalen Data Warehouse in Databricks SQL
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.