Implementierung eines dimensionalen Data Warehouses mit Databricks SQL: Teil 1
Definieren der Datenobjekte
von Bryan Smith, Lorenz Verzosa, Krishna Satyavarapu, Peyman Mohajerian und Jesse Heravi
- Implementieren Sie dimensionale Data Warehouses in Databricks SQL, um die Abfrageleistung zu optimieren.
- Die physische Modellstruktur in Databricks SQL, einschließlich der Erstellung von Dimensions- und Faktentabellen, erfolgt mit SQL CREATE TABLE-Anweisungen.
- Es ist wichtig, beschreibende Kommentare zu Tabellen und Spalten für eine bessere Metadatenverwaltung hinzuzufügen.
Immer mehr Unternehmen verlagern ihre Data-Warehouse-Workloads zu Databricks. Die elastische Natur der Plattform und erhebliche Verbesserungen an ihrer Abfrageausführungs-Engine haben es Databricks ermöglicht, Weltrekorde sowohl bei der Abfrageleistung von Data Warehouses als auch bei der Kostenleistung aufzustellen, was sie zu einer zunehmend attraktiven Option für die Konsolidierung von Analyseinfrastrukturen macht.
Um diese Bemühungen zu unterstützen, haben wir bereits darüber gebloggt, wie Databricks verschiedene Data-Warehouse-Designansätze unterstützt. In dieser Blog-Reihe möchten wir uns einen der beliebtesten Ansätze für Data Warehousing genauer ansehen: das dimensionale Modellieren, ein Entwurfsmuster, das sich durch
Stern-und Schneeflockenschemataauszeichnet und uns eingehend mit den standardisierten Extraktions-, Transformations- und Lademuster (ETL) befassen, die zur Unterstützung dieses Ansatzes weit verbreitet sind.Um dies für die Community des dimensionalen Modellierens breit zugänglich zu machen, werden wir uns eng an die klassischen Muster halten, die mit diesem Modellierungsansatz verbunden sind. Diese Informationen werden auf die folgenden Blogbeiträge verteilt:
- Teil 1: Definieren der (dimensionalen) Datenobjekte (dieser Beitrag)
- Teil 2: Erstellen der Dimension-ETL-Workflows
- Teil 3: Erstellen der Fakt-ETL-Workflows
Darüber hinaus werden wir unsere Design-Diskussionen auf eines der gängigeren Sternschemata (Abbildung 1) in der
AdventureWorksDWDatenbank konzentrieren, einer von Microsoft erstellten Beispieldatenbank, die häufig für Schulungszwecke im Bereich Data Warehouse und Business Intelligence verwendet wird.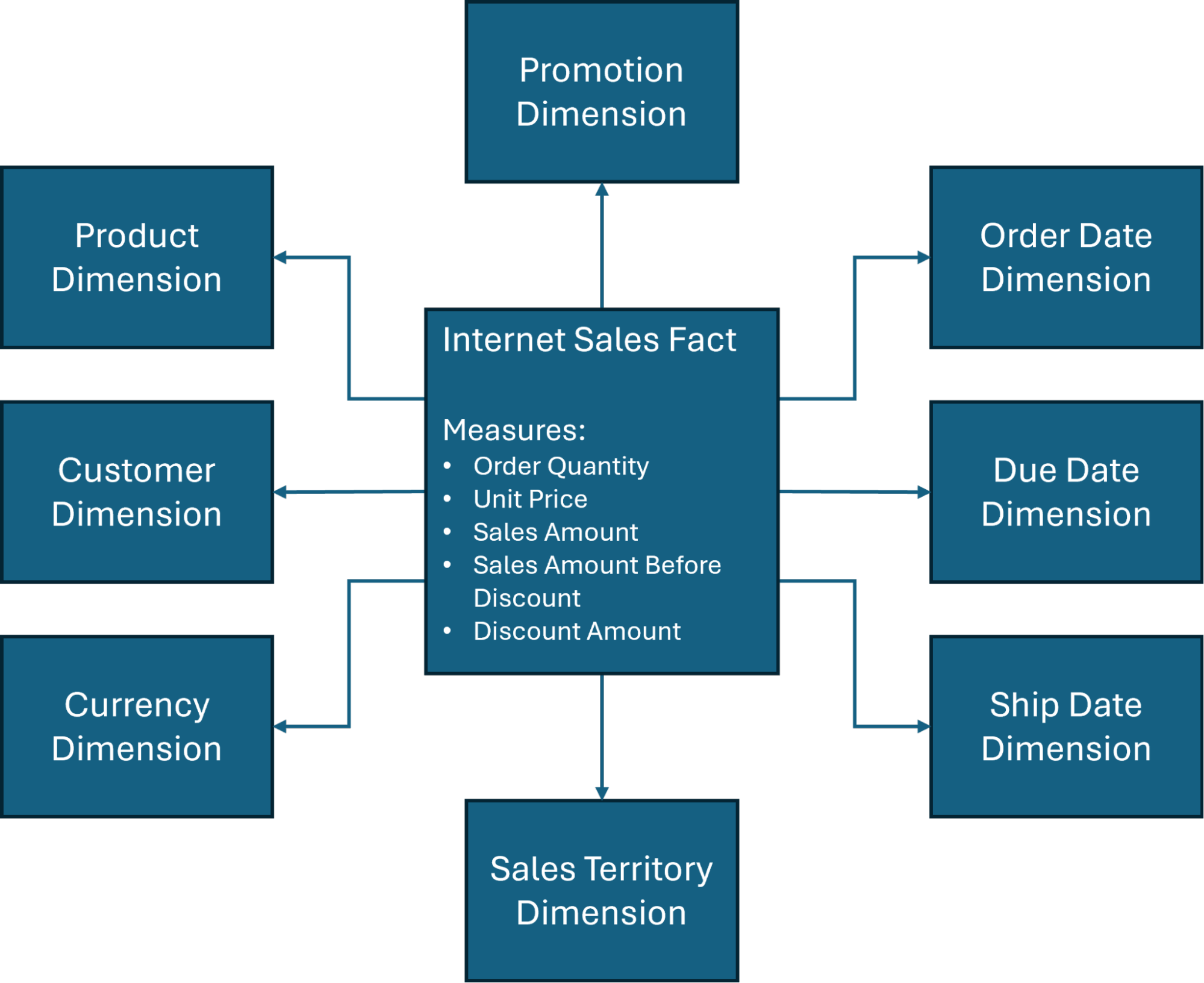
Was ist dimensionales Modellieren im Data Warehousing?
Dimensionales Modellieren optimiert die Datenspeicherung für schnelle Abfrageleistung. Durch die Strukturierung von Daten in Fakten und Dimensionen können Sie Daten einfach aus mehreren Perspektiven analysieren. Es ermöglicht Ihnen auch, Daten aus verschiedenen Blickwinkeln gleichzeitig zu untersuchen (multidimensionale Analyse).
Was sind die vier Dimensionen eines Data Warehouse?
Wie Abbildung 1 zeigt, sind mehrere Dimensionen am Sternschema des Data Warehousing beteiligt, aber die vier Hauptdimensionen des Data Warehousing umfassen typischerweise Folgendes:
Zeit: Dies bietet einen Rahmen für die historische Nachverfolgung und ist unerlässlich für die Bewertung von Trends oder die Durchführung von Vergleichen. Sie können Daten nach bestimmten Zeitintervallen – Tagen, Wochen, Jahren – kategorisieren, um saisonale Geschäftsänderungen oder die Bestandsverwaltung zu optimieren.
Kunde: Unternehmen benötigen genaue Einblicke, wer ihre Produkte kauft. Informationen wie Name, Kontaktinformationen und demografische Daten können eine hilfreiche Marktsegmentierung bieten und Entscheidungen wie Werbeausgaben oder allgemeine Marketingstrategien bestimmen.
Produkt: Diese Dimension definiert, welche Waren oder Dienstleistungen analysiert werden, und kann hilfreich sein, um eine Leistungsanalyse durchzuführen, um festzustellen, wie viel verkauft wird, die Verkaufsrate und mögliche Chancen für zukünftiges Wachstum.
Standort: Die Kontextualisierung, wo Ereignisse stattgefunden haben – sei es geografisch oder operativ – kann Unternehmen helfen, kritische Entscheidungen auf der Grundlage dessen zu treffen, wo ihre Kunden wahrscheinlich leben.
Das physische Modell
Innerhalb der Databricks-Plattform werden Fakten und Dimensionen als physische Tabellen implementiert. Diese sind innerhalb von
Katalogen organisiert, ähnlich wie Datenbanken, aber mit größerer Flexibilität für die Bandbreite der Informationsressourcen, die die Plattform unterstützt. Die Kataloge werden dann inSchemas unterteilt, wodurch logische und sicherheitsbezogene Grenzen um Teilmengen von Objekten im Katalog geschaffen werden (Abbildung 2).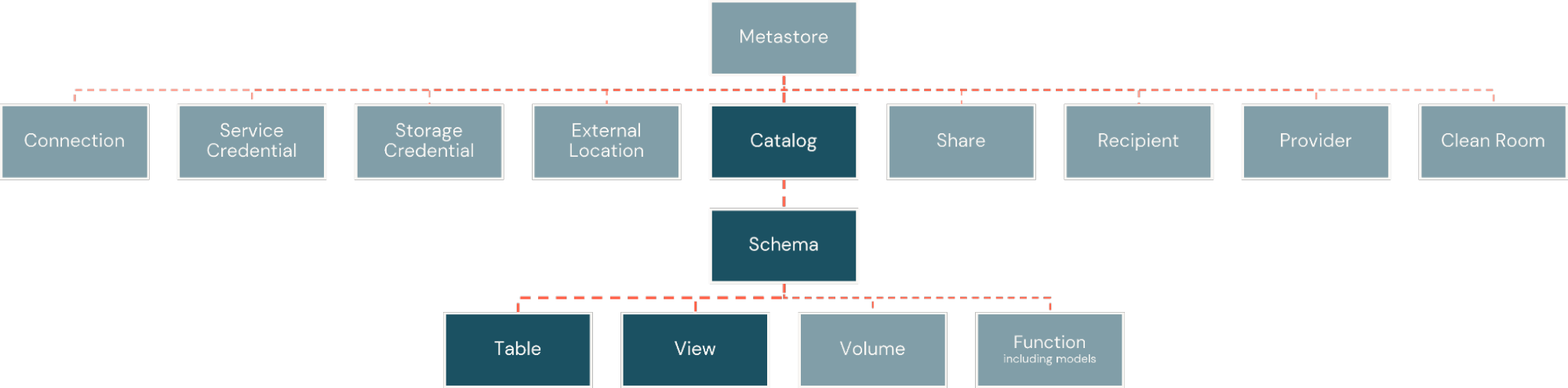
Dimensionstabellen
Dimensionstabellen halten sich an einen relativ starren Satz von Strukturmustern. Ein sequenzieller Bezeichner, einSurrogatschlüssel, wird typischerweise definiert, um eine stabile und effiziente Verknüpfung zwischen Faktentabellen und der Dimension zu unterstützen. Eindeutige Bezeichner aus operativen Systemen (oft als natürliche Schlüssel oder Geschäftsattribute bezeichnet) zusammen mit einer denormalisierten Sammlung zugehöriger Geschäftsattribute folgen typischerweise. Hinter den Bezeichnern stehen normalerweise eine Reihe von Metadaten-Spalten, die zur Unterstützung laufender ETL-Prozesse dienen. Innerhalb der Databricks-Plattform können wir eine Dimensionstabelle mit derCREATE TABLE-Anweisung implementieren, wie hier für die Kundendimension gezeigt:
Identitätsspalten
In diesem Beispiel verwenden wir für die Surrogatschlüsselspalte CustomerKey eine Identitätsspalte, die automatisch einen sequenziellen BIGINT-Wert für das Feld generiert, wenn wir Zeilen einfügen. Ob wir die Option ALWAYS oder BY DEFAULT mit der Identitätsspalte verwenden, hängt davon ab, ob wir das Einfügen eigener Werte für dieses Feld verbieten oder zulassen möchten.
Eintrag für fehlendes Mitglied
Ein gängiges Muster bei Dimensionstabellen ist die Erstellung eines Eintrags für fehlende Mitglieder. Dieser Eintrag wird in Szenarien verwendet, in denen Faktendatensätze mit fehlender oder unbekannter Verknüpfung zu einer Dimension ankommen. Er kann mit einem vordefinierten Surrogatschlüsselwert erstellt werden, wie hier gezeigt, wenn die Option BY DEFAULT verwendet wird:
Identitätsfelder
Als bewährte Methode gilt, dass beim Einfügen von Werten in ein Identitätsfeld die Metadaten für das Identitätsfeld am besten durch die Verwendung einer ALTER TABLE-Anweisung mit der Option SYNC IDENTITY aktualisiert werden:
Datentypen
Für den Geschäfts-/Naturschlüssel und andere Felder, die mit Daten in Quellsystemen verknüpft sind, müssen wir die Datentypen des Quellsystems an die von der Databricks Platform unterstützten Datentypen (Tabelle 1) anpassen. Bei Metadatenfeldern, bei denen ein Bitwert verwendet wird, wie 0 oder 1, beachten Sie bitte, dass wir oft einen INT-Datentyp anstelle der Datentypen BOOLEAN oder TINYINT verwenden, um die Handhabung von Literalen zu vereinfachen.
|
BIGINT |
DECIMAL |
INTERVAL |
TIMESTAMP |
MAP |
|
BINARY |
DOUBLE |
VOID |
TIMESTAMP_NTZ |
STRUCT |
|
BOOLEAN |
FLOAT |
SMALLINT |
TINYINT |
VARIANT |
|
DATE |
INT |
STRING |
ARRAY |
OBJECT |
Tabelle 1. Die von der Databricks Platform unterstützten Datentypen
Faktentabellen
Auch Faktentabellen folgen ihren strukturellen Konventionen. Hauptsächlich aus Messwerten und Fremdschlüsselreferenzen zu verwandten Dimensionen bestehend, können Faktentabellen auch eindeutige Identifikatoren für Transaktionsdatensätze (oder andere beschreibende Attribute in einer nahezu eins-zu-eins-Beziehung mit den Faktendatensätzen) enthalten, die als entartete Dimensionen bezeichnet werden. Sie können auch Metadatenfelder zur Unterstützung des inkrementellen Ladens (auch bekannt als Delta-Extraktion) von Daten aus Quellsystemen enthalten. Innerhalb der Databricks Platform könnten wir eine Faktentabelle mit der CREATE TABLE-Anweisung implementieren, ähnlich wie hier für den Internet-Sales-Fakt gezeigt:
Fremdschlüsselreferenzen
Wie im vorherigen Abschnitt über Dimensionstabellen erwähnt, werden Datentypen in der Databricks-Umgebung lose an die von Quellsystemen verwendeten Datentypen angepasst. Die Fremdschlüsselreferenzen zwischen den Fakten- und Dimensionstabellen können auch explizit mit der ALTER TABLE Anweisung hergestellt werden, wie hier gezeigt:
Hinweis: Wenn Sie die Fremdschlüsselbeschränkungen lieber als Teil der CREATE TABLE-Anweisung definieren möchten, können Sie einfach eine durch Kommas getrennte Liste von FOREIGN KEY-Klauseln (in der Form FOREIGN KEY (fremdschlüssel) REFERENCES tabellenname (primärschlüssel) direkt nach der Spaltendefinitionsliste hinzufügen.
Metadaten und weitere Überlegungen
Der Reiz des dimensionalen Modells liegt in seiner relativen Zugänglichkeit für Business-Analysten. Mit diesem Gedanken im Hinterkopf übernehmen viele Organisationen Namenskonventionen für Fakten und Dimensionen, wie die Fact und Dim Präfixe in den obigen Beispielen, und ermutigen die Verwendung langer, selbsterklärender Namen für Tabellen und Felder, die oft erheblich von den Namen in operativen Quellsystemen abweichen.
In diesem Zusammenhang ist es wichtig, die Einschränkungen von Databricks bei der Benennung von Objekten zu beachten. Dazu gehören:
- Objektnamen dürfen 255 Zeichen nicht überschreiten
- Die folgenden Sonderzeichen sind nicht erlaubt:
- Punkt (.)
- Leerzeichen ( )
- Schrägstrich (/)
- Alle ASCII-Steuerzeichen (00-1F Hex)
- Das DELETE-Zeichen (7F Hex)
Zusätzlich ist zu beachten, dass Objektnamen nicht case-sensitiv sind und tatsächlich im Metadaten-Repository in Kleinbuchstaben gespeichert werden. Wenn dies Probleme mit der Lesbarkeit von Objekten verursachen könnte, sollten Sie eine Snake-Case-Konvention in Betracht ziehen, um die Lesbarkeit einiger Objektnamen zu verbessern.
Unabhängig von Ihren Namenskonventionen ist es eine gute Idee, beschreibende Kommentare für alle Objekte und Felder im Data Warehouse zu definieren. Dies geschieht durch die Verwendung der COMMENT ON-Anweisung für Tabellenobjekte und der ALTER TABLE-Anweisung für einzelne Felder, wie hier gezeigt:
Diese und andere Metadaten (einschließlich Lineage-Informationen) sind über die Databricks Catalog Explorer Benutzeroberfläche (Abbildung 3) und über Objekte im integrierten Informationsschema innerhalb jedes Katalogs zugänglich.
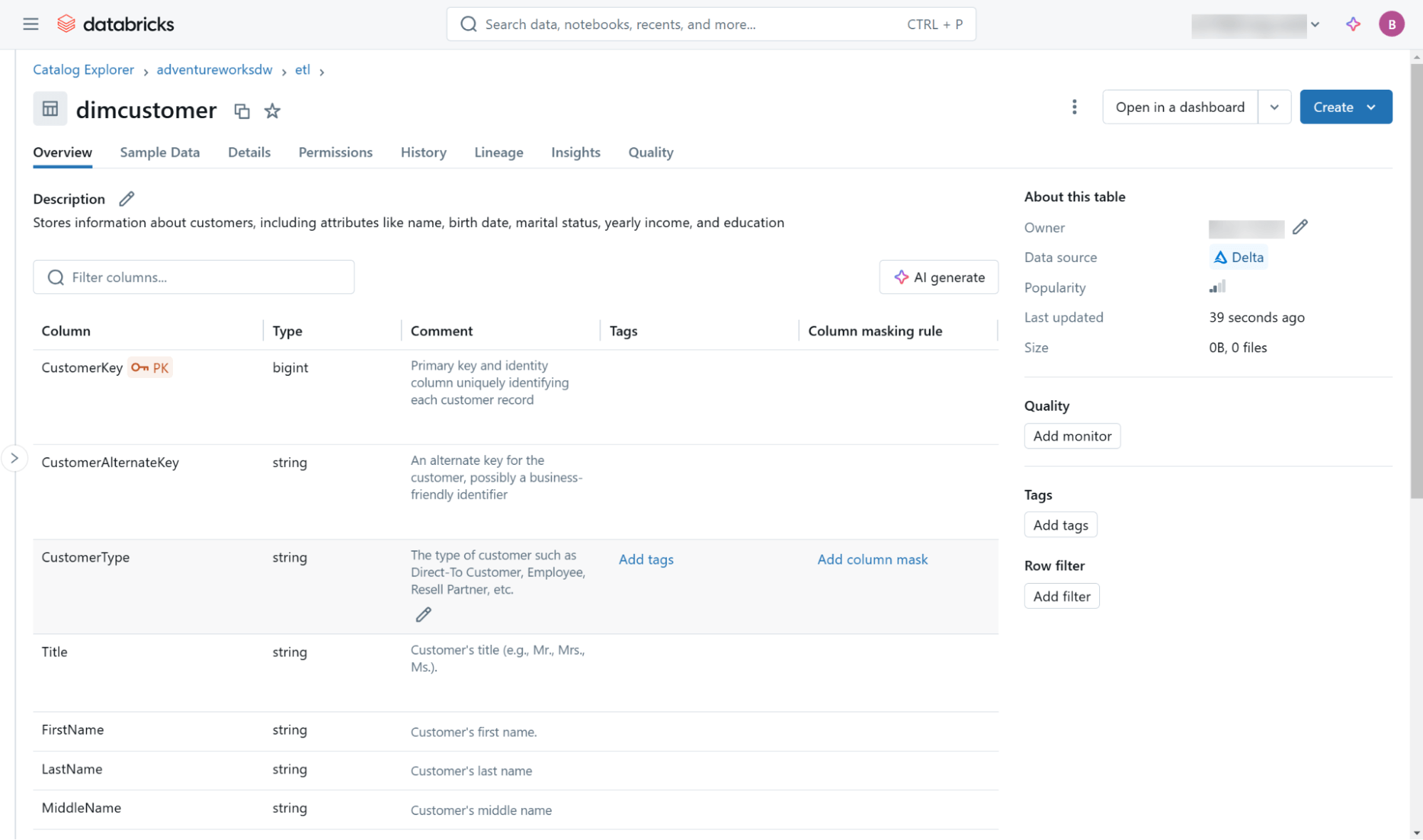
Zuletzt behandelt dieser Blog die Erstellung von Fakten- und Dimensionstabellen rein aus der Perspektive der Einhaltung von Dimensional Design Principles. Wenn Sie zusätzliche Optionen für die Tabellendefinition erkunden möchten, die Leistungs- und Wartungsoptimierungen berücksichtigen, lesen Sie bitte diesen Blog zur Optimierung der Sternschema-Performance.
Nächste Schritte: Implementierung des Dimensionstabellen-ETL
Nachdem wir die Grundlagen der Erstellung von Fakten- und Dimensionstabellen behandelt haben, widmen wir uns im nächsten Blogbeitrag der Implementierung der ETL-Muster, die Dimensionstabellen unterstützen, mit besonderem Schwerpunkt auf den Slowly Changing Dimension (SCD) Mustern Typ 1 und Typ 2 unter Verwendung von Python und SQL. Abschließend wird Teil 3 behandeln, wie die ETL für diese Tabellen implementiert werden kann.
Um mehr über Databricks SQL zu erfahren, besuchen Sie unsere Website oder lesen Sie die Dokumentation. Sie können auch die Produkttour für Databricks SQL ansehen. Wenn Sie Ihr bestehendes Warehouse zu einem hochleistungsfähigen, serverlosen Data Warehouse mit großartiger Benutzererfahrung und niedrigeren Gesamtkosten migrieren möchten, ist Databricks SQL die Lösung — probieren Sie es kostenlos aus.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.