Fünf einfache Schritte zum Implementieren eines Sternschemas in Databricks mit Delta Lake
Eine aktualisierte Methode, um mit Delta Lake konsistent die beste Performance aus Sternschema-Datenbanken in Data Warehouses und Data Marts zu erzielen
von Cary Moore, Lucas Bilbro und Brenner Heintz
- Verwenden Sie Delta Tables, um Ihre Fakten- und Dimensionstabellen zu erstellen.
- Verwenden Sie Liquid Clustering, um die beste Dateigröße bereitzustellen.
- Verwenden Sie Liquid Clusters für Ihre Faktentabellen.
Wir aktualisieren diesen Blog, um Entwicklern zu zeigen, wie sie die neuesten Features von Databricks und die Fortschritte in Spark nutzen können.
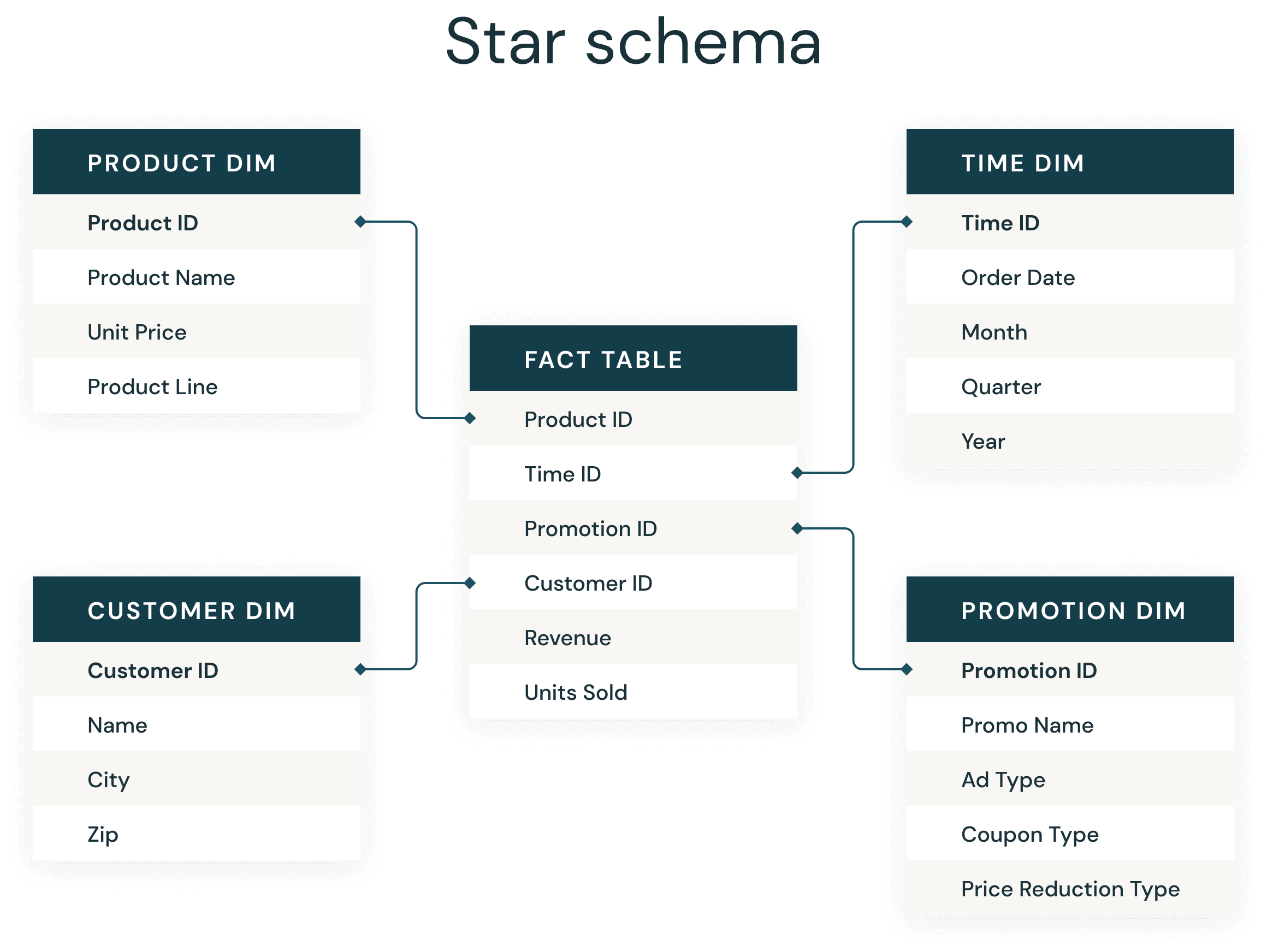
Die meisten Data-Warehouse-Entwickler sind mit dem allgegenwärtigen Sternschema sehr vertraut. Ein Sternschema, das in den 1990er Jahren von Ralph Kimball eingeführt wurde, wird verwendet, um Geschäftsdaten in Dimensionen (wie Zeit und Produkt) und Fakten (wie Transaktionen in Beträgen und Mengen) zu denormalisieren. Ein Sternschema speichert Daten effizient, pflegt den Verlauf und aktualisiert Daten, indem es die Duplizierung sich wiederholender Geschäftsdefinitionen reduziert, was eine schnelle Aggregation und Filterung ermöglicht.
Die gängige Implementierung eines Sternschemas zur Unterstützung von Business-Intelligence-Anwendungen ist so routinemäßig und erfolgreich geworden, dass viele Datenmodellierer sie praktisch im Schlaf erstellen können. Bei Databricks haben wir so viele Datenanwendungen entwickelt und sind ständig auf der Suche nach Best-Practice-Ansätzen, die als Faustregel dienen – eine Basisimplementierung, die uns garantiert zu einem hervorragenden Ergebnis führt.
Genau wie in einem herkömmlichen Data Warehouse gibt es auch bei Delta Lake einige einfache Faustregeln, die Ihre Delta-Sternschema-Joins erheblich verbessern.
Hier sind die grundlegenden Schritte zum Erfolg:
- Verwenden Sie Delta Tables, um Ihre Fakten- und Dimensionstabellen zu erstellen.
- Verwenden Sie Liquid Clustering, um die beste Dateigröße bereitzustellen
- Verwenden Sie Liquid Clustering für Ihre Faktentabellen
- Verwenden Sie Liquid Clustering für die Keys und wahrscheinlichen Prädikate Ihrer größeren Dimensionstabelle.
- Nutzen Sie die Prädiktive Optimierung, um Tabellen zu pflegen und Statistiken zu erfassen
1. Verwenden Sie Delta Tables, um Ihre Fakten- und Dimensionstabellen zu erstellen
Delta Lake ist eine offene Speicherformatebene, die Einfügungen, Aktualisierungen und Löschungen sowie ACID-Transaktionen für Ihre Data-Lake-Tabellen ermöglicht, was die Wartung und Überarbeitung vereinfacht. Delta Lake bietet außerdem die Möglichkeit, dynamisches File Pruning durchzuführen, um SQL-Abfragen zu beschleunigen.
Die Syntax ist in Databricks Runtimes 8.x und neuer einfach (die aktuelle Long Term Support-Runtime ist jetzt 15.4), in denen Delta Lake das defaultmäßige Tabellenformat ist. Sie können eine Delta-Tabelle mit SQL wie folgt erstellen:
CREATE TABLE MY_TABLE (COLUMN_NAME STRING) CLUSTER BY (COLUMN_NAME);
Vor der 8.x-Laufzeit erforderte Databricks die Erstellung der Tabelle mit der USING DELTA -Syntax.
Vor der 8.x-Runtime erforderte Databricks das Erstellen der Tabelle mit der USING DELTA -Syntax.
2. Verwenden Sie Liquid Clustering, um die beste Dateigröße bereitzustellen
Zwei der größten Zeitfresser bei einer Apache Spark™-Abfrage sind der Zeitaufwand für das Lesen von Daten aus dem Cloud-Speicher und die Notwendigkeit, alle zugrunde liegenden Dateien zu lesen. Mit Data Skipping in Delta Lake können Abfragen selektiv nur die Delta-Dateien mit relevanten Daten lesen, was erheblich Zeit spart. Data Skipping kann beim statischen File Pruning, dynamischen File Pruning, statischen Partition Pruning und dynamischen Partition Pruning helfen.
Vor Liquid Clustering war dies eine manuelle Einstellung. Es gab Faustregeln, um sicherzustellen, dass die Dateien eine angemessene Größe hatten und für Abfragen effizient waren. Mit Liquid Clustering werden die Dateigrößen jetzt automatisch durch die Optimierungsroutinen bestimmt und beibehalten.
Wenn Sie diesen Artikel gerade lesen (oder die vorherige Version gelesen haben) und bereits Tabellen mit ZORDER erstellt haben, müssen Sie die Tabellen mit Liquid Clustering neu erstellen.
Zusätzlich optimiert Liquid Clustering, um zu kleine oder zu große Dateien (Skew und Balance) zu verhindern, und aktualisiert die Dateigrößen, wenn neue Daten hinzugefügt werden, um Ihre Tabellen optimiert zu halten.
3. Verwenden Sie Liquid Clustering für Ihre Faktentabellen
Um die Abfragegeschwindigkeit zu verbessern, unterstützt Delta Lake die Möglichkeit, das Layout von in Cloud-Speichern abgelegten Daten mit Liquid Clustering zu optimieren. Clustern Sie nach den Spalten, die Sie in ähnlichen Situationen wie geclusterte Indizes in der Datenbankwelt verwenden würden, obwohl es sich dabei nicht wirklich um eine Hilfsstruktur handelt. Eine mit Liquid Clustering geclusterte Tabelle clustert die Daten in der CLUSTER BY-Definition, sodass Zeilen mit gleichen Spaltenwerten aus der CLUSTER BY-Definition gemeinsam im optimalen Satz von Dateien abgelegt werden.
Die meisten Datenbanksysteme führten die Indizierung ein, um die Abfrageperformance zu verbessern. Indizes sind Dateien, und wenn die Datenmenge wächst, können sie zu einem weiteren Big-Data-Problem werden, das es zu lösen gilt. Stattdessen ordnet Delta Lake die Daten in den Parquet-Dateien an, um die Bereichsauswahl im Objektspeicher effizienter zu gestalten. In Kombination mit dem Prozess der Statistiksammlung und dem Data Skipping ähneln Liquid Clustered Tables den Seek- vs. Scan-Operationen in Datenbanken, die durch Indizes gelöst wurden, ohne einen weiteren Compute-Engpass bei der Suche nach den von einer Abfrage gesuchten Daten zu schaffen.
Bei Liquid-Clustered-Tabellen ist es die beste Vorgehensweise, die Anzahl der Spalten in der CLUSTER BY-Klausel auf die 1 bis 4 besten zu beschränken. Wir haben die Fremdschlüssel (Fremdschlüssel nach Verwendung, nicht tatsächlich erzwungene Fremdschlüssel) der 3 größten Dimensionen gewählt, die zu groß waren, um sie an die Worker zu übertragen.
Schließlich ersetzt Liquid Clustering die Notwendigkeit von ZORDER und Partitionierung. Wenn Sie also Liquid Clustering verwenden, müssen Sie die Tabellen nicht mehr explizit nach Hive-Art partitionieren oder können dies auch nicht mehr tun.
4. Verwenden Sie Liquid Clustering für die Keys Ihrer größeren Dimension und wahrscheinliche Prädikate
Da Sie diesen Blog lesen, haben Sie wahrscheinlich Dimensionen und einen Ersatz-Key oder einen Primär-Key in Ihren Dimensionstabellen. Ein Key, der ein Big Integer ist, validiert wird und eindeutig sein muss. Seit databricks runtime 10.4 sind Identitätsspalten allgemein verfügbar und Teil der CREATE TABLE -Syntax.
Databricks hat außerdem nicht erzwungene Primärschlüssel und Fremdschlüssel in Runtime 11.3 eingeführt, die in für Unity Catalog aktivierten Clustern und Workspaces sichtbar sind.
Eine der Dimensionen, mit denen wir arbeiteten, hatte über 1 Milliarde Zeilen und profitierte vom File Skipping und Dynamic File Pruning, nachdem wir unsere Prädikate in die geclusterten Tabellen eingefügt hatten. Unsere kleineren Dimensionen wurden nach dem Dimensions-Key-Feld geclustert und im Join mit den Fakten gebroadcastet. Ähnlich wie bei den Ratschlägen zu Faktentabellen sollten Sie die Anzahl der Spalten in der „Cluster By“-Klausel auf die 1–4 Felder in der Dimension beschränken, die am wahrscheinlichsten zusätzlich zum Schlüssel in einem Filter enthalten sind.
Zusätzlich zum File Skipping und der einfachen Wartung ermöglicht Liquid Clustering das Hinzufügen von mehr Spalten als ZORDER und ist flexibler als die Partitionierung im Hive-Stil.
5. Analysieren der Tabelle, um Statistiken für den Adaptive Query Execution Optimizer zu erfassen und die prädiktive Optimierung zu aktivieren
Eine der größten Weiterentwicklungen in Apache Spark™ 3.0 war die Adaptive Query Execution, oder kurz AQE. Ab Spark 3.0 gibt es drei Haupt-Features in AQE, darunter das Coalescing von Post-Shuffle-Partitionen, die Konvertierung von Sort-Merge-Joins in Broadcast-Joins und die Skew-Join-Optimierung. Zusammen ermöglichen diese Features die beschleunigte Performance von dimensionalen Modellen in Spark.
Damit AQE weiß, welchen Plan es für Sie auswählen soll, müssen wir Statistiken über die Tabellen erfassen. Sie tun dies, indem Sie den ANALYZE TABLE -Befehl ausführen. Kunden haben berichtet, dass das Erfassen von Tabellenstatistiken die Abfrageausführung für dimensionale Modelle, einschließlich komplexer Joins, erheblich reduziert hat.
ANALYZE TABLE MY_BIG_DIM COMPUTE STATISTICS FOR ALL COLUMNS
Sie können Analyze table weiterhin als Teil Ihrer Laderoutinen nutzen, aber es ist jetzt besser, einfach Predictive Optimization für Ihr Account, Ihren Katalog und Ihr Schema zu aktivieren.
ALTER CATALOG [catalog_name] {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
ALTER {SCHEMA | DATABASE} schema_name {ENABLE | DISABLE} PREDICTIVE OPTIMIZATION;
Predictive Optimization macht die manuelle Verwaltung von Wartungsvorgängen für von Unity Catalog verwaltete Tabellen auf Databricks überflüssig.
Wenn Predictive Optimization aktiviert ist, identifiziert Databricks automatisch Tabellen, die von Wartungsvorgängen profitieren würden, und führt diese für den Benutzer aus. Wartungsbetriebsabläufe werden nur bei Bedarf ausgeführt, wodurch unnötige Ausführungen von Wartungsbetriebsabläufen und der mit der Leistungsüberwachung und -fehlerbehebung verbundene Aufwand entfallen.
Aktuell führen Predictive Optimizations Vacuum und Optimize für Tabellen aus. Achten Sie auf Updates für Predictive Optimization und bleiben Sie auf dem Laufenden, wann das Feature zusätzlich zum automatischen Anwenden von liquid clustered Keys auch analyze table und gather stats integriert.
Fazit
Indem sie die oben genannten Richtlinien befolgen, können Unternehmen die Abfragezeiten verkürzen. In unserem Beispiel haben wir die Abfrage-Performance auf demselben Cluster um das Neunfache verbessert. Die Optimierungen haben die E/A erheblich reduziert und sichergestellt, dass nur die erforderlichen Daten verarbeitet wurden. Wir profitierten auch von der flexiblen Struktur von Delta Lake, da sie sowohl skalierbar ist als auch die Arten von Ad-hoc-Abfragen verarbeiten kann, die von Business-Intelligence-Tools gesendet werden.
Seit der ersten Version dieses Blogs ist Photon jetzt für unser Databricks SQL Warehouse standardmäßig und für All-Purpose- und Jobs-Cluster verfügbar. Erfahren Sie mehr über Photon und die Leistungssteigerung, die es für all Ihre Spark SQL-Abfragen mit Databricks bietet.
Kunden können durch die Aktivierung von Photon in der Databricks Runtime eine verbesserte Performance ihrer ETL/ELT- und SQL-Querys erwarten. Wenn Sie die hier beschriebenen Best Practices mit der Photon-fähigen Databricks Runtime kombinieren, können Sie eine Query-Performance mit geringer Latenz erwarten, die die besten Cloud Data Warehouses übertreffen kann.
Erstellen Sie noch heute Ihre Sternschema-Datenbank mit Databricks SQL.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.