Bringen Sie Databricks mit der Power des AI Dev Kit in die Kiro-IDE
Zwei Wege zur Verbindung der Kiro IDE mit der Databricks Data Intelligence Platform – die vier von Databricks verwalteten MCP-Server für eine 10-minütige Einrichtung oder das neue Databricks AI Dev Kit Power für den vollen Funktionsumfang.
- Zwei Wege zur Verbindung der Kiro IDE mit Databricks: die vier von Databricks verwalteten MCP-Server (Genie, SQL, Unity Catalog Functions, Vector Search) für eine 10-minütige, PAT-basierte Einrichtung oder das neue Databricks AI Dev Kit Power – ein Klick, alle wichtigen Tools und Skills, vier Authentifizierungsoptionen.
- KI-gestützte Entwicklung basierend auf echten Workspace-Metadaten: Beide Wege übernehmen die Zeilen-, Spalten- und Tag-basierten Berechtigungen von Unity Catalog, sodass der Assistent SQL mit Ihren tatsächlichen Spalten schreibt und nur das sieht, was Sie sehen dürfen – keine Halluzinationen, keine unbefugten Lesezugriffe.
- Auswahl nach Funktionsumfang: Pfad A ist die schlankeste Einrichtung für Analysten und SQL-fokussierte Entwickler; Pfad B eröffnet die gesamte Databricks-Plattform (Pipelines, Jobs, Mosaic AI, Agent Bricks, Lakebase, Asset Bundles) direkt in der IDE.
Warum das wichtig ist
Die KI-gestützte Entwicklung scheitert in dem Moment, in dem der Assistent Spaltennamen, Tabellenlayouts oder die Kataloge, auf die Sie zugreifen können, erraten muss. Die Lösung ist die Verankerung: Verbinden Sie den Assistenten über das Model Context Protocol (MCP) mit Live-Workspace-Metadaten. So nutzt das generierte SQL die tatsächlich vorhandenen Spalten, dbt-Modelle verknüpfen echte Tabellen und jede Abfrage übernimmt die bereits in Unity Catalog definierten Berechtigungen. Nichts verlässt die Plattform. Die KI sieht nur das, was Sie auch sehen können.
Zwei Meilensteine wurden gerade erreicht, die dies in der Kiro-IDE praxistauglich machen:
Erstens hat das Databricks AI Dev Kit in PR #511 die Kiro-Unterstützung upstream hinzugefügt. Der einheitliche Installer behandelt kiro als erstklassiges Ziel neben claude, cursor, copilot, codex und gemini. Ein einziger Befehl genügt, und Kiro übernimmt das vollständige Toolkit unter ~/.kiro/skills/ und ~/.kiro/settings/mcp.json.
Zweitens wurde das Databricks AI Dev Kit Power im Kiro-Powers-Katalog in PR #129 veröffentlicht. Öffnen Sie das Powers-Panel, klicken Sie auf „Try“ und die Power führt das gesamte Onboarding durch: Installer, MCP-Anbindung, Erkennung der Authentifizierung und Laden von Skills.
Zusammen mit den vier von Databricks verwalteten Remote-MCP-Servern, die bereits in der Plattform enthalten sind, haben Sie zwei Möglichkeiten, Kiro mit Databricks zu verbinden. Beide führen zum selben Ergebnis: Entwickler können Analysen, Pipelines und Agent-Workflows schneller bereitstellen, wenn der Assistent echte Workspace-Berechtigungen übernimmt, anstatt Schemata, Spalten und Berechtigungen zu erraten.
Warum Databricks für die KI-gestützte Entwicklung
Die beiden oben genannten Meilensteine machen Kiro × Databricks praxistauglich. Der Grund, warum das wichtig ist, liegt in der zugrunde liegenden Technologie. Drei Dinge machen Databricks zur Plattform der Wahl für die KI-gestützte Entwicklung, unabhängig davon, welchen Weg Sie wählen.
Unity Catalog ist die einzige Governance-Ebene, die KI auf Datenebene verankert. Jeder MCP-Aufruf – Pfad A oder Pfad B – übernimmt zeilen-, spalten- und tagbasierte Berechtigungen. Der Assistent hat keinen privilegierten Zugriff auf Ihre Daten; er sieht genau das, was Sie sehen können. Es muss keine separate Zugriffskontrollebene verwaltet werden, und es besteht kein Risiko, dass die KI Abfragen für Tabellen schreibt, von deren Existenz sie gar nichts wissen sollte.
Eine Datenkopie, ein Satz von Definitionen. Da Databricks ein Lakehouse ist, ist die Tabelle, die der Assistent über databricks-sql abfragt, dieselbe Tabelle, in die Ihr dbt-Modell schreibt, dieselbe Tabelle, die Ihr Genie-Space bereitstellt, und dieselbe Tabelle, aus der Ihr AI/BI-Dashboard liest. Es gibt keine Warehouse-to-Lake-Synchronisierung, die fehlschlagen kann, und keine separate semantische Ebene, die synchron gehalten werden muss. Wenn sich der Assistent in samples.tpch.lineitem verankert, nutzt er dieselbe Definition wie jedes andere Tool.
Der gesamte KI-Stack ist integriert und nicht nur nachträglich aufgesetzt. Mosaic AI Gateway leitet Modellaufrufe weiter. Agent Bricks orchestriert Multi-Agenten-Workflows. MLflow verfolgt Experimente und Evaluierungen. Vector Search ermöglicht die semantische Suche. Lakebase verwaltet den Transaktionsstatus. All dies wird in der Power bereitgestellt, alles auf demselben UC. Sie müssen nicht fünf verschiedene Produkte zusammenflicken, sondern nutzen eine einzige Plattform.
Es gibt noch einen vierten Punkt, der erwähnenswert ist: Die Power selbst wurde von Databricks entwickelt. Keine andere Datenplattform bietet eine Ein-Klick-IDE-Power für Kiro, Cursor, Claude, Copilot, Codex und Gemini. Die MCP-Ebene ist offen, das Protokoll ist offen, die Integration ist offen – aber die Benutzeroberfläche, die alles umschließt, wurde von Databricks speziell für die Arbeitsweise unserer Kunden entwickelt.
Die beiden Pfade im Überblick
Dimension | Pfad A: Verwaltete MCP-Server | Pfad B: Databricks AI Dev Kit Power |
|---|---|---|
Funktionsumfang | 4 Server: Genie, SQL, UC Functions, Vector Search | Alle wichtigen Databricks-Tools und -Skills |
Vorteile | SQL in natürlicher Sprache, semantische Suche, kontrollierte Funktionsausführung | Funktionsumfang von Pfad A plus Pipelines, Jobs, Dashboards, Lakebase, Mosaic AI, Agent Bricks, Asset Bundles, MLflow, Model Serving, Apps |
Hosting | Von Databricks verwaltet (Remote-HTTPS) | Lokaler Python-MCP-Server über den AI Dev Kit-Installer |
Authentifizierung | PAT in Shell-Umgebung | OAuth U2M (empfohlen), OAuth M2M, .databrickscfg-Profil oder PAT |
Einrichtung | Bearbeiten von | Ein-Klick-Power-Installation plus geführter Authentifizierungs-Flow |
Ideal für | Analysten und SQL-fokussierte Entwickler, die in 10 Minuten Fragen an ihr Warehouse stellen möchten | Data Engineers und Plattform-Entwickler, die den gesamten Databricks-Funktionsumfang in einer einzigen IDE benötigen |
Integrationsarchitektur im Überblick
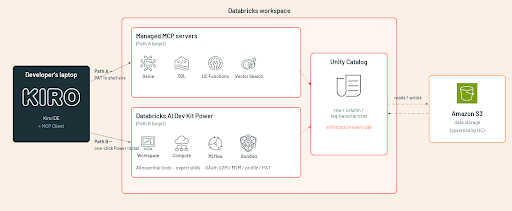
Beide Pfade nutzen dasselbe Backend: die Durchsetzung von Unity Catalog-Berechtigungen und die Databricks-Workspace-Identität. Sie unterscheiden sich im Funktionsumfang und im Authentifizierungsmodell.
Pfad A: Verbindung zu den vier verwalteten MCP-Servern herstellen
Dies ist die einfachste Einrichtung. Eine mcp.json-Datei, ein Databricks Personal Access Token und eine Anpassung des Shell-Profils. In weniger als 10 Minuten kommuniziert Kiro mit Genie, SQL, Unity Catalog Functions und Vector Search.
Voraussetzungen
- Ein Databricks-Workspace auf AWS mit aktiviertem Unity Catalog.
- Ein Databricks Personal Access Token (PAT) oder OAuth-Token, das für die MCP-Server konfiguriert ist, die Sie verwenden möchten (
sql,unity-catalog,genie,vector-search). Nicht verwendete PATs werden nach 90 Tagen automatisch widerrufen. - Kiro muss installiert und mindestens einmal gestartet worden sein, damit
~/.kiro/existiert. - Ihr Workspace-Hostname im Format
<workspace>.cloud.databricks.com.
Ein Databricks-PAT generieren
Gehen Sie im Databricks-Workspace zu Settings > Developer > Access tokens > Manage > Generate new token. Legen Sie ein Ablaufdatum fest, das den Rotationsrichtlinien Ihres Teams entspricht. Wählen Sie nur die API-Berechtigungen (Scopes) aus, die Sie benötigen; das Prinzip der minimalen Rechtevergabe (Least Privilege) ist sicherer als die Bequemlichkeit von „Alles“. Kopieren Sie das Token sofort. Databricks zeigt es nicht noch einmal an.
Wo Kiro die MCP-Konfiguration speichert
Kiro liest die MCP-Konfiguration aus JSON-Dateien in zwei Bereichen; der Workspace-Bereich überschreibt den Benutzer-Bereich.
- Benutzer-Bereich (User scope):
~/.kiro/settings/mcp.jsongilt für jeden Workspace. - Workspace-Bereich (Workspace scope):
$PWD/.kiro/settings/mcp.jsongilt nur für den aktuellen Workspace und überschreibt den Eintrag mit demselben Schlüssel im Benutzer-Bereich.
Ein-Klick-Installation aus dem Kiro-Server-Verzeichnis
Öffnen Sie kiro.dev/docs/mcp/servers/, suchen Sie die Zeile für Databricks und klicken Sie auf „Add to Kiro“. Der Browser startet Kiro und öffnet einen Bestätigungsdialog mit einer vorausgefüllten Konfiguration. Bestätigen Sie, um den Eintrag databricks-sql in ~/.kiro/settings/mcp.json zu schreiben. Der Eintrag verweist auf zwei Umgebungsvariablen, die noch nicht existieren; diese richten wir als Nächstes ein.
Überprüfen Sie den databricks-sql-Eintrag (oder fügen Sie ihn hinzu)
Umgebungsvariablen festlegen
Im Shell-Profil, das Kiro startet (normalerweise ~/.zshrc unter macOS):
Laden Sie das Profil neu (source ~/.zshrc), bevor Sie Kiro starten. Beenden Sie Kiro vollständig (Cmd+Q unter macOS) und öffnen Sie es erneut. „Reload Window“ liest die Umgebungsvariablen nicht neu ein; dies geschieht nur bei einem Neustart des Prozesses.
Genie, UC Functions und Vector Search hinzufügen
Alle vier von Databricks verwalteten Server werden als Remote-HTTP-MCP verbunden. Der Initialisierungs-Handshake ist selbst mit einer Platzhalter-URL erfolgreich; der Server validiert die Ressource erst, wenn ein Tool aufgerufen wird. Ein Zustand, bei dem die Verbindung zwar steht, aber fehlerhaft ist (wenn tools/call RESOURCE_DOES_NOT_EXIST oder PERMISSION_DENIED zurückgibt), ist die häufigste Fehlerursache. Führen Sie zuerst diese Vorabprüfungen durch:
- Genie: Bestätigen Sie, dass ein Genie-Space existiert und Sie ihn öffnen können. Die Space-ID wird in der URL angezeigt.
- UC-Funktionen: Bestätigen Sie, dass die Funktion existiert und Sie über
EXECUTEverfügen. Listen Sie Funktionen mitSELECT * FROM system.information_schema.routines WHERE routine_type = 'FUNCTION'auf. - Vector Search: Bestätigen Sie, dass ein Endpunkt mit mindestens einem zugänglichen Index unter „Catalog, Vector Search“ existiert.
- PAT-Scope: Ein auf den Workspace beschränkter PAT kann immer noch
PERMISSION_DENIEDauf Genie-Spaces oder Vektorindizes aufrufen, wenn dem Benutzer die Berechtigung „Can View“ für die spezifische Ressource fehlt. Genie-Spaces werden einzeln freigegeben.
Fügen Sie die zusätzlichen Umgebungsvariablen (DATABRICKS_GENIE_MCP_URL, DATABRICKS_UC_FUNCTIONS_MCP_URL, DATABRICKS_VECTOR_SEARCH_MCP_URL) hinzu und aktualisieren Sie mcp.json auf die vollständige Konfiguration:
URL-Formate nach Server:
Server | URL-Muster |
|---|---|
databricks-genie | https:// |
databricks-sql | https:// |
databricks-uc-functions | https:// |
databricks-vector-search | https:// |
Beenden Sie Kiro und starten Sie es erneut. Öffnen Sie den Bereich „MCP SERVERS“ im Kiro-Panel; die vier Einträge für databricks-* werden mit grünen Statusanzeigen angezeigt. Klicken Sie bei allen roten Einträgen auf „Erneut verbinden“ und überprüfen Sie den Pre-Flight-Check erneut. Versuchen Sie eine risikoarme erste Abfrage im Chat-Panel: „List the catalogs I have access to.“
Pfad B: Installieren Sie das Databricks AI Dev Kit Power
Die vier verwalteten Server decken SQL, semantische Suche und Analysen in natürlicher Sprache ab, was für viele Entwickler ausreicht. Wenn Ihr Workflow Pipelines, Jobs, Model Serving, Lakebase, Asset Bundles, Mosaic AI, Agent Bricks, AI/BI-Dashboards, MLflow oder Databricks Apps umfasst, führt das Setup mit vier Servern dazu, dass Sie den ganzen Tag Daten hin und her in die Workspace-Benutzeroberfläche kopieren müssen.
Das Databricks AI Dev Kit Power löst dieses Problem. Eine einzige Installation. Alle wichtigen Tools und Skills, vier Authentifizierungsoptionen, alle bei Bedarf ladbar.
Was Sie erhalten
Bereich | Abdeckung |
|---|---|
SQL & Compute | Führen Sie SQL auf Warehouses aus; führen Sie Python oder Scala auf Clustern aus; verwalten Sie den Compute-Lebenszyklus |
Pipelines & Jobs | Spark Declarative Pipelines (Streaming-Tabellen, CDC, SCD Typ 2, Auto Loader); Multi-Task-Job-DAGs |
Unity Catalog | Tabellen, Volumes, Grants, Tags, Speicher-Anmeldeinformationen, Systemtabellen, Metrikansichten, External Iceberg Reads |
AI/BI-Dashboards | Visualisierungen, KPIs, Analyse-Dashboards |
Genie-Spaces | Datenexploration in natürlicher Sprache über kontrollierte Datensätze |
Agent Bricks | Wissensassistenten (RAG) und Multi-Agenten-Supervisoren |
Vector Search | Semantische Suche und RAG mit verwalteten Indizes |
Model Serving | ML-Modelle, KI-Agenten und Pay-per-Token Foundation Model APIs (FMAPI), weiterleitbar über das AI Gateway |
MLflow | Experimente, Evaluierungen, Trace-Instrumentierung, Metrikabfragen |
Lakebase | Bereitgestelltes und automatisch skalierendes verwaltetes PostgreSQL für OLTP-Workloads |
Databricks Apps | Full-Stack-Web-Apps auf dem Lakehouse |
Asset Bundles | Infrastructure-as-Code für Databricks-Ressourcen |
Mit einem Klick installieren
Öffnen Sie in Kiro den Bereich „Powers“, suchen Sie nach databricks und klicken Sie auf „Try“. Das Power führt das offizielle Installationsprogramm für das Databricks AI Dev Kit im nicht-interaktiven Kiro-Modus aus:
Das Installationsprogramm lädt den MCP-Server herunter, erstellt eine virtuelle uv-Umgebung und zieht die Experten-Skill-Bibliothek in ~/.kiro/skills/. Das Power kopiert die Skills in sein eigenes steering/-Verzeichnis, sodass sie je nach anstehender Aufgabe bei Bedarf geladen werden. Im Power selbst sind keine Inhalte gebündelt; alles wird von Upstream abgerufen, sodass die Skills aktuell bleiben.
Die vier Authentifizierungsoptionen
Der Onboarding-Prozess des Powers erkennt vorhandene Anmeldeinformationen und führt Sie durch die richtige Auswahl. Alle vier sind inline dokumentiert:
Option | Beschreibung | Ideal für |
|---|---|---|
A: OAuth U2M (empfohlen für die interaktive Nutzung) | Die Databricks CLI öffnet einen Browser, Sie authentifizieren sich selbst, das SDK wird stündlich automatisch aktualisiert | Ein einzelner menschlicher Entwickler auf einer Workstation. Sicherster interaktiver Ablauf, da keine langlebigen Secrets offengelegt werden können |
B: OAuth M2M | Ein Databricks-Service-Principal authentifiziert sich mit | Headless-, CI/CD- oder Produktions-Agenten |
C: Vorhandenes | Verweisen Sie das Power auf ein Profil, das Sie bereits für die Databricks CLI oder andere Tools verwenden | Sie verfügen bereits über ein funktionierendes Profil und möchten die Authentifizierung nicht erneut einrichten |
D: Personal Access Token (Legacy) | Bearer-Token im | Tools, die OAuth nicht unterstützen, oder Workspaces, bei denen OAuth U2M nicht aktiviert ist |
Die mcp.json des Powers wird mit disabled: true ausgeliefert, bis Sie eine Option auswählen. Es wird keine Verbindung hergestellt, bis Sie Ihre Anmeldeinformationen explizit ausgewählt und konfiguriert haben. Die Erkennung von Anmeldeinformationen ist neutral. Wenn mehrere Anmeldeinformationen erkannt werden, werden alle vier Optionen der Reihe nach angezeigt, ohne Standardeinstellung und ohne stillschweigende Wiederverwendung.
Installation überprüfen
Starten Sie Kiro neu, öffnen Sie den Bereich „MCP SERVERS“ und bestätigen Sie, dass der Eintrag databricks verbunden ist (grün). Fragen Sie den Chat: „Get my current Databricks user.“ Dieser einzelne Aufruf testet die Authentifizierung, die Auflösung von Umgebungsvariablen und die Serveraktivierung. Wenn es funktioniert, ist die gesamte Kette intakt.
So wählen Sie zwischen den beiden Pfaden
Ein einfacher Entscheidungsbaum:
- Sie möchten nur SQL ausführen, über Genie Fragen in natürlicher Sprache zu kontrollierten Datensätzen stellen und Vektorindizes durchsuchen? Verwenden Sie Pfad A. Die vier verwalteten Server tun genau das, und die Einrichtung dauert 10 Minuten.
- Erstellen von Pipelines, Verwalten von Jobs, Bereitstellen von Asset Bundles, Arbeiten mit Lakebase, Erstellen von Databricks Apps oder Aufrufen von Mosaic AI / Agent Bricks? Verwenden Sie Pfad B. Das gesamte Toolkit bietet einen zu großen Funktionsumfang, um ihn über einzelne Remote-MCP-Server anzubinden.
- Hybrid? Nutzen Sie beide. Pfad A und Pfad B stehen nicht im Konflikt. Die Power schreibt ihren eigenen
mcpServers.databricks-Eintrag, während die vier Server von Pfad A (databricks-genie,databricks-sql,databricks-uc-functions,databricks-vector-search) separate Schlüssel sind. Kiro zeigt sie alle im MCP-Panel an.
Für Entwickler, die täglich mit Kiro an Databricks-Workloads arbeiten möchten, ist Pfad B langfristig die bessere Lösung. Pfad A ist die richtige Wahl, wenn Sie nur 10 Minuten Zeit haben und mit einem SQL-Warehouse chatten möchten.
Aus der Sicht des Entwicklers
Beide Pfade wirken unterschiedlich, je nachdem, wer die IDE nutzt. Vier Personas, vier Schmerzpunkte, vier Antworten.
Der Analytics Engineer. Sie verbringen den halben Tag damit, Tabellen abzufragen, die Sie noch nie gesehen haben, und die andere Hälfte mit Copy-Paste zwischen Ihrem Editor und der Workspace-Benutzeroberfläche. Pfad A löst dies in 10 Minuten. Die Genie- und SQL-Server verankern jede Abfrage in echten Schema-Metadaten; der Assistent schreibt Code basierend auf Ihren tatsächlichen Spalten, nicht auf Vermutungen; und jedes Ergebnis übernimmt Ihre Unity Catalog-Berechtigungen. Das ständige Wechseln zwischen den Tabs hat ein Ende.
Der Data Engineer. Ihr Alltag besteht aus Pipelines, Jobs, Asset Bundles und den umgebungsübergreifenden Bereitstellungen, die mit allen dreien einhergehen. Das manuelle Erstellen der databricks.yml und das Ausführen von databricks bundle deploy in einer Terminal-Seitenleiste ist der langsame Weg. Pfad B ist der schnelle Weg. Die Fähigkeiten der Power für Pipelines + Jobs + Asset Bundles erstellen, validieren und stellen IaC direkt aus einer Konversation heraus bereit. Spark Declarative Pipelines, CDC, SCD Typ 2, Auto Loader – alles generiert auf Basis Ihrer tatsächlichen UC-Tabellen und bereit zum Committen.
Der KI-/Agenten-Entwickler. Sie verknüpfen Modellaufrufe, Evaluierung, Governance und Agenten-Orchestrierung über drei oder vier Tools hinweg, die sich nicht ganz einig über das Schema sind. Pfad B deckt den gesamten Databricks-KI-Bereich ab – Mosaic AI Gateway für Routing und Fallbacks, Agent Bricks für Multi-Agenten-Supervisoren und Wissensassistenten, MLflow für die Evaluierung, Vector Search für das Retrieval – alles durchgängig von UC gesteuert. Ihr Agent übernimmt dieselben Berechtigungen wie sein Aufrufer, und Ihre Evaluierungs-Traces landen im selben Workspace wie Ihre Trainingsläufe.
Der Plattform-Entwickler. Sie verwalten Databricks-Ressourcen als Code, stellen sie über Dev/Stage/Prod bereit und beantworten wöchentlich die Frage „Gibt es Abweichungen?“. Die Asset Bundles-Fähigkeit von Pfad B sowie die Unity Catalog-Verwaltungsfähigkeiten generieren das vollständige Bundle, validieren es mit dem tatsächlichen Zustand Ihres Workspace und decken Abweichungen auf, bevor sie Probleme verursachen. Sie müssen nicht mehr ein Set von YAML manuell pflegen und ein anderes in einem Dokument.
Ein Workflow, den Sie noch heute ausführen können
Unabhängig davon, welchen Pfad Sie gewählt haben, verankert diese Übung den Assistenten in echten Workspace-Metadaten unter Verwendung des samples.tpch-Katalogs, der in jedem Databricks-Workspace verfügbar ist.
Sie fragen: „Welche Spalten und Typen hat samples.tpch.lineitem und wie sieht die Datenverteilung nach l_shipdate-Jahr aus?“
Kiro liefert das tatsächliche Schema und ein Histogramm aus einer einzigen, über MCP ausgeführten Abfrage. Echte Spaltennamen, echte Verteilung, keine Halluzinationen.
Sie fragen: „Entwirf ein dbt-Modell, das lineitem mit orders verknüpft und den Umsatz nach Nation pro Quartal aggregiert.“
Kiro erstellt SQL unter Verwendung der tatsächlichen Spaltennamen (l_extendedprice, l_discount, o_orderdate) anstelle von Vermutungen. Da es zuerst das Schema abgefragt hat, kennt es die genauen Typen und die Granularität.
Sie fragen: „Führe meine neue Aggregation für samples.tpch aus und vergleiche die Zeilenanzahl mit dem Snapshot der letzten Woche in poc.gold.revenue_by_nation_qtr.“
Kiro führt beide Abfragen aus und zeigt die Unterschiede an. Wenn eine Zahl nicht stimmt, ruft „Zeige mir die Lineage für gold.revenue_by_nation_qtr“ Upstream-Tabellen aus system.access.table_lineage ab. Nach der Überprüfung generiert Kiro die Databricks-Job-JSON für das Modell und listet auf, welche Kataloge und Schemata berührt werden.
Auf Pfad B lässt sich derselbe Workflow auf „Generiere das Asset Bundle für diesen Job und stelle es in Staging bereit“, „Erstelle ein AI/BI-Dashboard basierend auf dieser Aggregation“ oder „Binde dies in einen Mosaic AI Gateway-Endpunkt mit einem Fallback-Modell ein“ erweitern – und das alles, ohne die IDE zu verlassen.
Best Practices, unabhängig vom Pfad
- Least-Privilege-Authentifizierung. Generieren Sie ein separates PAT pro Workstation und pro Scope-Set. Bevorzugen Sie auf Pfad B für die interaktive Nutzung OAuth U2M gegenüber PATs.
- Anmeldedaten niemals committen. Speichern Sie
DATABRICKS_ACCESS_TOKENin Ihrem Shell-Profil oder einem Secrets Manager. Fügen Sie es niemals inmcp.jsonein, das in die Versionsverwaltung eingecheckt ist. - Gültigkeitsbereich pro Projekt. Behalten Sie Genie-Space-IDs und Vector Search-Indexpfade in
$PWD/.kiro/settings/mcp.json, sodass jedes Projekt seine eigenen Ressourcenbindungen trägt. - Vertrauen Sie auf UC-Berechtigungen. Alle Pfade erzwingen zeilen-, spalten- und tagbasierte Freigaben in Unity Catalog. Die KI übernimmt bei jedem Aufruf Ihre effektiven Berechtigungen. Es muss keine separate Zugriffskontrollschicht verwaltet werden.
- Neustarten, nicht neu laden. Kiro liest Umgebungsvariablen einmal beim Prozessstart. Beenden Sie Kiro nach dem Bearbeiten Ihres Shell-Profils oder dem Hinzufügen einer Authentifizierung vollständig (Cmd+Q auf macOS) und öffnen Sie es erneut.
Fehlerbehebung
„Server nicht gefunden“ oder roter Status bei einem MCP-Eintrag.
Pfad A: Überprüfen Sie echo $DATABRICKS_SQL_MCP_URL in der Shell, die Kiro gestartet hat. Ein leerer Wert bedeutet, dass Kiro die URL nicht auflösen kann. Vergewissern Sie sich, dass die Workspace-weite mcp.json Ihre benutzerweite Konfiguration nicht überschreibt. Überprüfen Sie unter „Settings“, „Developer“, „Access tokens“, ob das PAT noch gültig ist.
Pfad B: Starten Sie den Ablauf zur Erkennung von Anmeldedaten aus dem Onboarding der Power erneut. Wenn der MCP-Server Invalid access token oder 401 zurückgibt, pausiert der integrierte 401-Wiederherstellungs-Hook der Power die Tool-Aufrufe und zeigt die Authentifizierungsoptionen erneut an.
Mit MCP verbunden, aber Tool-Aufrufe geben RESOURCE_DOES_NOT_EXIST oder PERMISSION_DENIED zurück.
Der häufigste Fehler bei Pfad A. Der Initialisierungs-Handshake ist mit einer Platzhalter-URL erfolgreich, da der Server die Ressourcenvalidierung bis zum Aufruf aufschiebt. Führen Sie die Pre-Flight-Checks für den spezifischen Server erneut aus (Genie-Space existiert und ist für Sie freigegeben, Funktion existiert und Sie haben EXECUTE, Vektorindex existiert und Sie haben die Berechtigung „Can View“).
Try it today. Die Databricks AI Dev Kit Power ist der schnellste Weg, um die gesamte Plattform – Pipelines, Jobs, Lakebase, Mosaic AI, Agent Bricks und alles andere oben Genannte – in Kiro zu nutzen. Installieren Sie sie direkt aus dem Kiro Powers-Katalog unter github.com/kirodotdev/powers oder besuchen Sie github.com/databricks-solutions/ai-dev-kit, um das zugrunde liegende Toolkit für Kiro oder eine andere unterstützte IDE (Claude, Cursor, Copilot, Codex, Gemini) zu installieren. Für die vier von Databricks verwalteten MCP-Server befindet sich die Ein-Klick-Installation unter kiro.dev/docs/mcp/servers/.
Haben Sie Feedback oder sind Sie auf ein Problem gestoßen? Erstellen Sie ein Issue auf databricks-solutions/ai-dev-kit – wir lesen jedes einzelne.
Die hier geteilten Meinungen und Ideen sind unsere eigenen und stellen keine offizielle Richtlinie von Databricks dar.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.