Aufbau eines A/B-Testing-Analyse-Frameworks für Mobile Gaming auf Databricks
Wie HARDlight die Experimentanalyse mit automatisierter statistischer Modellierung, gesteuerten Einblicken, einem täglich aktualisierten Dashboard und LLM-generierten Zusammenfassungen skalierte.
von Sanjay Ashok, Jack Holdsworth, Tingting Wan, Joel Dias, Richard Carr und Monika Kolodziejczyk
- Von Daten zu Entscheidungen: Wie Sega HARDlight die A/B-Testanalyse auf Databricks durch standardisierte Experimentaufnahme, statistische Modellierung und Ergebnisveröffentlichung automatisierte – wodurch manuelle Arbeitsabläufe reduziert und die monatliche Experimentierkapazität ohne zusätzliches Personal verdoppelt wurde.
- Einblicke für jedes Publikum: Tägliche Überwachung mit einer LLM-Zusammenfassung und zunehmend granularen Metriken, Diagnosen und empfohlenen Aktionen, die den Zugriff auf umsetzbare Erkenntnisse im gesamten Unternehmen demokratisieren.
- Vertrauen durch Transparenz: Konsistente statistische Schlussfolgerungen und zugängliche KI/BI-Ansichten halfen den Teams, die Ergebnisse zu verstehen, Vertrauen aufzubauen und einen gemeinsamen wissenschaftlichen Ansatz für Experimente zu verfolgen.
Einleitung
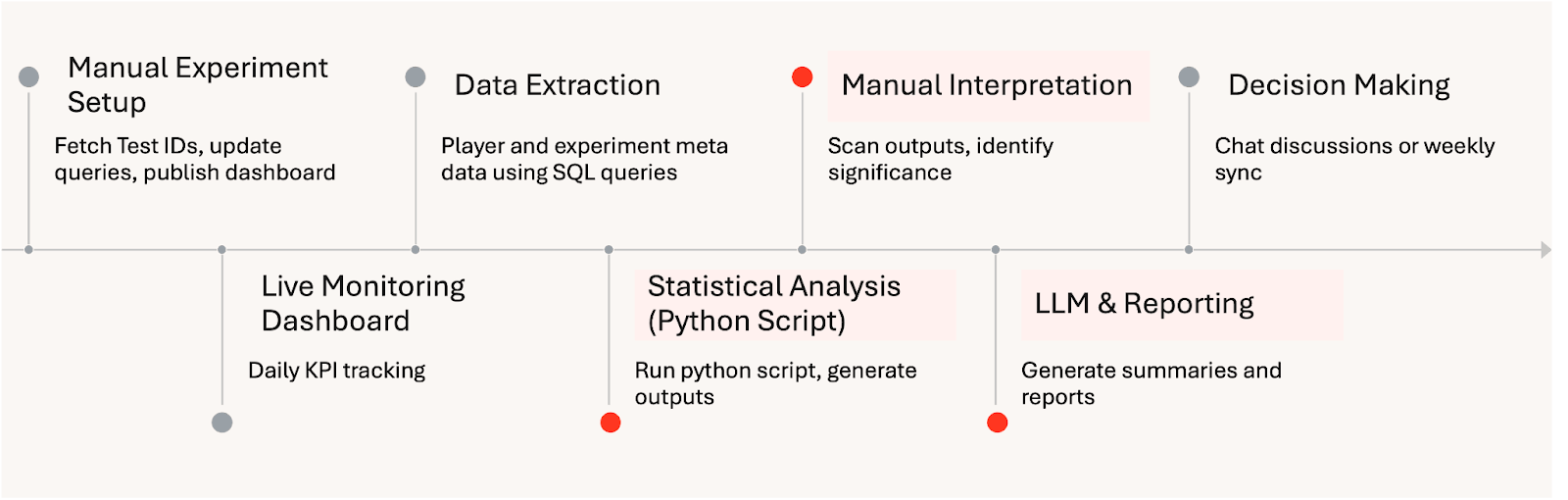
Mobile Game Studios sind auf kontinuierliche Experimente angewiesen, um Gameplay, Monetarisierung und Live-Operationen zu verfeinern. Wenn die Experimente skaliert werden, wird die Analyse oft zum limitierenden Faktor. Ergebnisse werden oft manuell zusammengestellt, statistische Ansätze variieren je nach Analyst und Erkenntnisse kommen Tage nach dem Auftreten wichtiger Signale. Mit der Zeit führt dies zu Reibungsverlusten: langsamere Iteration, inkonsistente Schlussfolgerungen und schwindendes Vertrauen in A/B-Tests als zuverlässiges Entscheidungswerkzeug.
Die Herausforderung
Bei HARDlight ging es nicht nur um Geschwindigkeit, sondern auch um Vertrauen. Unterschiedliche Ansätze führten zu unterschiedlichen Interpretationen, was die Abstimmung erschwerte und das Vertrauen in Experimente als wissenschaftliches Entscheidungswerkzeug schwächte. Einige Stakeholder benötigten einen einfachen täglichen Status, andere wollten das Spieler-Verhalten oder die Geschäftsauswirkungen verstehen, und eine kleinere Gruppe benötigte eine tiefgehende Validierung spezifischer Spielhebel. Die bestehenden Dashboards und Berichte konnten dieses breite Spektrum an Bedürfnissen nicht effektiv bedienen. Damit Experimente skaliert werden konnten, benötigte HARDlight eine Möglichkeit, die Inferenz zu standardisieren, Ergebnisse auf verschiedenen Detailebenen zugänglich zu machen und das Vertrauen in A/B-Tests als gemeinsamen, wissenschaftlichen Entscheidungsprozess wiederherzustellen.
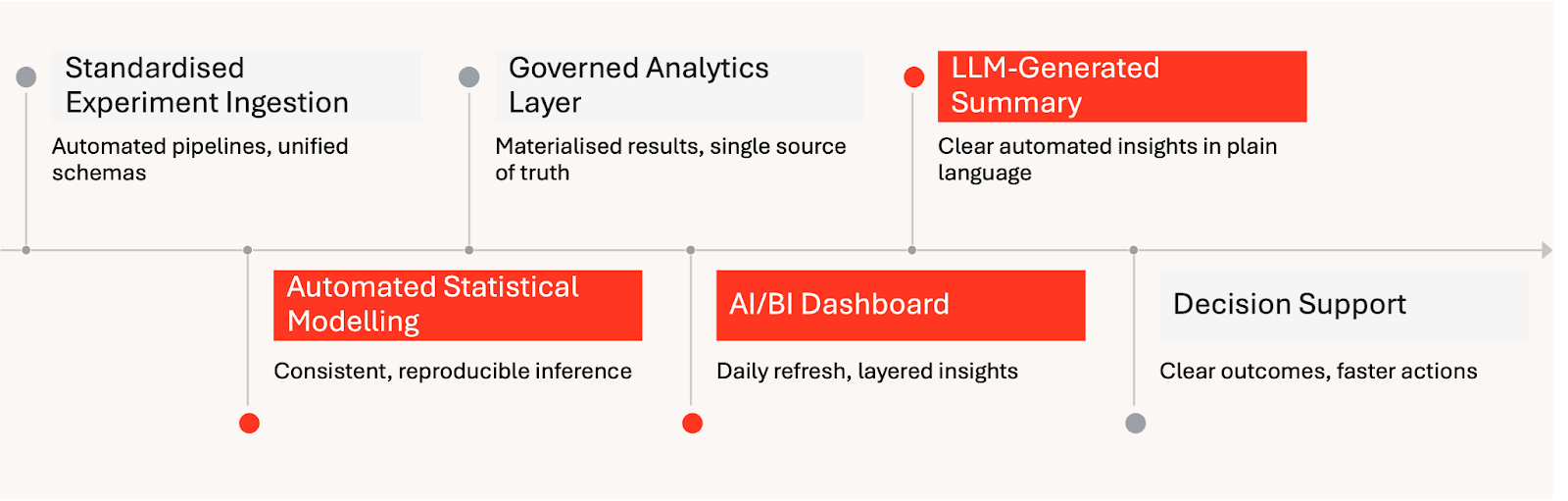
Um dies zu erreichen, hat HARDlight ein Databricks-natives A/B-Testing-Analyse-Framework entwickelt, das den Weg von Experimentdaten zu entscheidungsreifen Erkenntnissen automatisiert. Statistische Analysen wurden im Vorfeld auf wiederholbare, transparente Weise durchgeführt, und Databricks AI/BI stellte die Ergebnisse über eine täglich aktualisierte Oberfläche bereit, die mit einer LLM-generierten Zusammenfassung begann und tiefere Erkundungen mit zunehmend granulareren Ansichten ermöglichte. Am Ende jedes Experiments wurden die Ergebnisse eingefroren und gespeichert, um sicherzustellen, dass Entscheidungen, Kontext und Lernergebnisse lange nach Abschluss des Tests verfügbar bleiben.
Die Lösung: Automatisiertes A/B-Testing auf Databricks
Das Framework von HARDlight automatisiert die Experimentierung von der Erfassung bis zur Entscheidungsunterstützung. Innerhalb von Databricks werden Experimentdefinitionen und Telemetriedaten standardisiert, statistische Modellierung konsistent angewendet und Ergebnisse in einem geschichteten Dashboard veröffentlicht, das während des Laufzeitfensters täglich aktualisiert wird. Eine LLM-Zusammenfassung oben bietet eine zugängliche Übersicht über den Experimentstatus, während tiefere Abschnitte KPIs, Diagnosen und empfohlene Aktionen für Experten bereitstellen.
Die Wahl von Databricks ermöglicht Governance und Wiederholbarkeit über Teams hinweg. Unity Catalog bietet eine einzige Steuerungsebene für Berechtigungen und Lineage von Experiment-Assets; Spark Declarative Pipelines orchestriert zuverlässige Pipelines für die Erfassung und Transformation von Experimenten; und MLflow unterstützt Experiment-Tracking und Modell-Packaging für reproduzierbare Analysen. Zusammen halten diese Funktionen Daten und Analysen in der Lakehouse gouverniert, konsistent und einfach zu bedienen.
Eine Schlüsselinnovation ist das „eingefrorene Dashboard“ am Ende des Laufs. Anstatt zur nächsten Aktualisierung überzugehen, speichert das Framework den endgültigen Snapshot und die getroffenen Entscheidungen zusammen mit den empfohlenen Aktionen. Dies institutionalisiert Erkenntnisse aus früheren Experimenten und ermöglicht es Stakeholdern, Ergebnisse ohne Mehrdeutigkeiten zu überprüfen.
Technische Architektur
Das Experimentier-Framework ist als Databricks-natives System aufgebaut, das Datenverarbeitung, statistische Inferenz und Konsum trennt und gleichzeitig alle Ausgaben standardmäßig gouverniert und reproduzierbar hält. Dieses Design stellt sicher, dass die analytische Strenge skaliert, ohne den operativen Aufwand zu erhöhen oder die Interpretation über Teams hinweg zu fragmentieren.
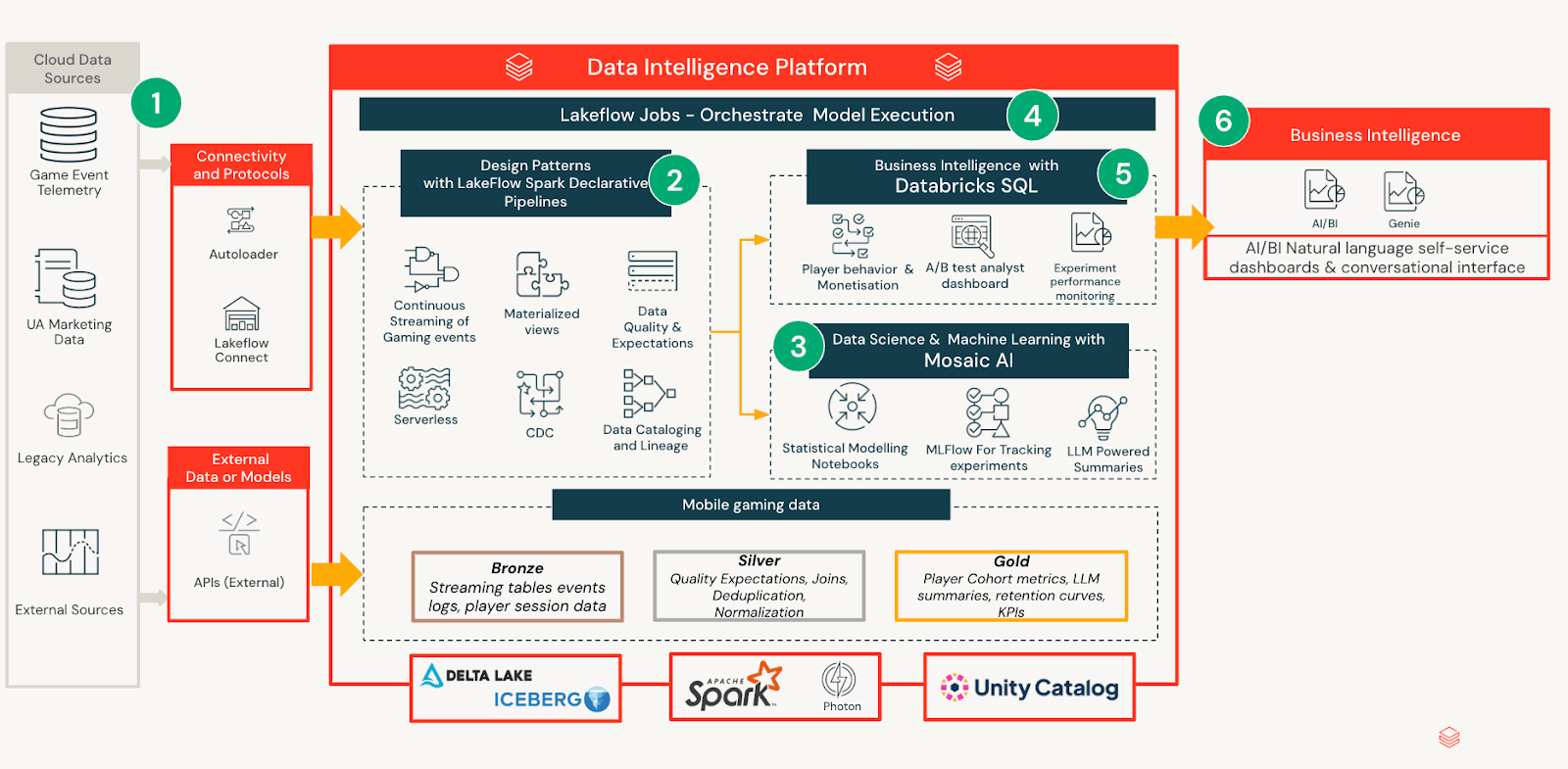
Datenerfassung & Modellierung
Experimentdefinitionen, Spieler-Telemetrie und Ergebnismetriken werden aus internen Pipelines erfasst und in kuratierten Tabellen mit konsistenten Schemata zusammengefasst. Diese Standardisierung ermöglicht es Analysten und Produktteams, Experimente konsistent zu bewerten, unabhängig von Design oder Dauer. Notebooks werden verwendet, um statistische Modelle zu berechnen, die Effekt-Schätzungen, Unsicherheiten und Auswirkungen auf Segmentebene im Laufe der Zeit ermitteln. Anstatt Logik in Dashboards oder Berichten einzubetten, werden alle Analyseergebnisse in einem einheitlichen Experiment-Analysemodell materialisiert. Dies schafft eine stabile semantische Schicht, auf die nachgelagerte Konsumenten vertrauen können, ohne die Analyse neu auszuführen oder die Ergebnisse neu zu interpretieren.
KI/BI-gestützte Erkenntnisbereitstellung
Auf dieser kuratierten Analyseschicht bietet Databricks AI/BI eine zugängliche Schnittstelle für die Nutzung von Experimentergebnissen. Jede tägliche Aktualisierung generiert eine prägnante LLM-Zusammenfassung für nicht-technische Stakeholder, die validierte statistische Ergebnisse in natürlicher Sprache übersetzt. Das Dashboard verwendet progressive Offenlegung: Benutzer können bei der Zusammenfassung aufhören, wenn sie zufrieden sind, oder tiefere Ebenen von Metriken, Diagnosen und Segmentanalysen erkunden, wenn ihre Neugier steigt. Diese geschichtete Erfahrung ermöglicht schnelles Scannen, während analytische Tiefe für Experten-Validierung verfügbar bleibt.

Experiment-Lebenszyklus und Persistenz
Während der Live-Phase wird das Dashboard täglich aktualisiert, damit Teams den Verlauf verfolgen und auf Signale reagieren können. Nach Abschluss wird das Dashboard eingefroren, um Ergebnisse, Entscheidungen und empfohlene Aktionen zu speichern. Dieser Lebenszyklus schafft eine prüfbare Aufzeichnung, die das Onboarding beschleunigt und doppelte Analysen bei zukünftigen Experimenten reduziert.
Dashboard-Ebenen erklärt
Das Dashboard ist so konzipiert, dass es Benutzer in einer klaren, bewussten Reihenfolge durch die Ergebnisse eines Experiments führt. Es beginnt mit Einfachheit und enthüllt schrittweise mehr Details für diejenigen, die weiter erkunden möchten. Jeder Abschnitt beantwortet eine andere Frage, und es ist völlig in Ordnung, aufzuhören, sobald der Leser die benötigten Informationen erhalten hat.
LLM-generierte Experiment-Zusammenfassung: Oben im Dashboard befindet sich eine LLM-generierte Zusammenfassung. Solange ein Experiment live ist, bietet dies einen einfachen, übergeordneten Überblick über den Fortschritt und hebt frühe Signale hervor, ohne voreilige Schlüsse zu ziehen.
Sobald das Experiment abgeschlossen ist, ändert sich die Rolle der Zusammenfassung. Sie wird zu einer klaren Erklärung dessen, was passiert ist, und hebt die Metriken hervor, die mit hoher Zuverlässigkeit, in priorisierter Reihenfolge und in einfacher Sprache bewegt wurden. Ziel ist es, Teams zu helfen, das Ergebnis schnell zu verstehen und warum es wichtig ist.
Bestätigte Ergebnisse und statistische Auswirkungen: Für technischere Zielgruppen bietet der nächste Abschnitt eine strukturierte Ansicht statistisch signifikanter Ergebnisse. Wichtige Metriken wie Lifetime Value (LTV) der Spieler und Bindung werden neben Effektgrößen und Konfidenzniveaus aufgeführt, sodass Schlussfolgerungen leicht validiert werden können, ohne sich in Rohanalysen vertiefen zu müssen.
Geschätzter Lifetime-Value-Effekt: Das Dashboard zeigt dann die geschätzten Auswirkungen auf den Lifetime Value der Spieler für die Kontroll- und Varianten-Gruppen. Unsicherheiten und Fehlermargen werden explizit angezeigt, was unterstreicht, dass es sich um fundierte Schätzungen handelt, nicht um absolute Prognosen.
Umsatzentwicklung nach Quelle: Die Ergebnisse werden nach Einnahmequellen aufgeschlüsselt, einschließlich Werbung, In-App-Käufe und Gesamteinnahmen. Dies hilft Teams zu verstehen, ob Änderungen breit gefächert sind oder von bestimmten Monetarisierungskanälen angetrieben werden.
Spieler-Engagement und Verhalten: Über die Einnahmen hinaus werden Engagement-Metriken wie Bindung und Sitzungsverhalten angezeigt, um sicherzustellen, dass Geschäftsgewinne neben dem Spielerlebnis und der langfristigen Gesundheit berücksichtigt werden.
Segment-Level-Analyse: Die Segmentierung ist zentral für die Art und Weise, wie HARDlight Experimente entwirft und bewertet. Dieser Abschnitt zeigt, wie verschiedene Spielersegmente auf eine Änderung reagieren, sei es durch Bindung, Fortschritt oder andere Verhaltensmerkmale definiert. Es hilft Teams zu bestätigen, dass gezielte Erlebnisse wie beabsichtigt funktionieren, ohne andere Teile der Spielerbasis zu beeinträchtigen.
Monetarisierungsmechanismen und Spielökonomie: Tiefere Ebenen untersuchen, wie Experimente In-Game-Systeme beeinflussen, einschließlich Anzeigenleistung nach Platzierung, In-App-Kauf-Leistung nach Produktkategorie und Änderungen der Hard- und Soft-Currency-Flüsse über Quellen und Senken hinweg.
Kern-Gameplay-Schleifen und Anhänge: Auf der tiefsten Ebene decken detaillierte Diagramme und Tabellen Gameplay-Mechaniken wie Rennen, Charaktere und Gegenstände ab, zusammen mit unterstützenden statistischen Visualisierungen. Diese Ebene richtet sich an Experten, die vollständige Transparenz wünschen oder Erkenntnisse in zukünftiger Arbeit wiederverwenden müssen.
Zusammen ermöglichen diese Ebenen die natürliche Entfaltung von Erkenntnissen. Teams können schnell vorgehen, wenn die Antwort klar ist, oder tiefer gehen, wenn Fragen auftreten, und das alles auf der Grundlage derselben kuratierten, vertrauenswürdigen Datenquelle.
Diese Struktur wird durch Databricks AI/BI ermöglicht, das es ermöglicht, komplexe Analyseergebnisse sauber darzustellen, ohne benutzerdefinierten Code oder nur für Analysten zugängliche Workflows in Dashboards einzubetten. Statistische Ergebnisse, Projektionen und Segment-Level-Analysen werden im Vorfeld in Notebooks berechnet und in kuratierten Tabellen materialisiert, während AI/BI eine flexible Präsentationsschicht darüber bietet. Dies eliminiert die Notwendigkeit, Python in Dashboards auszuführen, vereinfacht die Wartung und ermöglicht es einem schlanken Team, das System im Laufe der Zeit zu iterieren und weiterzuentwickeln.
Ebenso wichtig ist, dass AI/BI es ermöglicht, sehr unterschiedliche Zielgruppen mit denselben zugrunde liegenden Daten zu bedienen. Narrative Zusammenfassungen, tabellarische Ergebnisse, Diagramme und tiefe Diagnosen können koexistieren, ohne Logik zu duplizieren oder die Interpretation zu fragmentieren. Dies war eine wichtige Abkehr von früheren Ansätzen, bei denen Tooling-Beschränkungen Kompromisse zwischen analytischer Tiefe, Zugänglichkeit und Nachhaltigkeit erzwangen.
Auswirkungen & Ergebnisse
Das Framework hat die Art und Weise, wie Experimente bei HARDlight durchgeführt werden, grundlegend verändert. Durch die Automatisierung der Analyse und die Standardisierung der statistischen Inferenz konnte das Datenteam den manuellen Aufwand um mehr als acht Stunden pro Woche reduzieren. Durch die Standardisierung von Experimentläufen mit Databricks Workflows hat das Team einen Großteil der manuellen Einrichtung eliminiert, die zuvor für jede Analyse erforderlich war. Dies spart etwa einen Tag pro Experiment und hat eine gezielte Verdopplung der monatlichen A/B-Testkapazität ermöglicht, ohne die Mitarbeiterzahl zu erhöhen.
Manueller Workflow für Experimentanalysen:
Automatisierte Bereitstellung von Experimenteinblicken auf Databricks:
Über die Effizienzsteigerung hinaus hat das System die Konsistenz und das Vertrauen in die Ergebnisse verbessert. Das archivierte Dashboard dient nun als verlässliche Quelle für abgeschlossene Experimente, reduziert wiederholte Analysen und erleichtert es Teams, vergangene Entscheidungen mit vollem Kontext zu überprüfen. Dies hat den Aufwand für die Pflege historischer Kenntnisse teamübergreifend erheblich reduziert.
Am wichtigsten ist vielleicht, dass das Framework die Art und Weise verändert hat, wie Erkenntnisse im Studio genutzt werden. Bei mehreren parallel laufenden Experimenten erhalten die Teams nun tägliche, KI/BI-gestützte Updates, die mehrtägige manuelle Aggregation und Interpretation ersetzen. Genie wird direkt auf dem Dashboard aktiviert, sodass Benutzer Fragen zu dem stellen können, was sie sehen, und Ergebnisse in eigenen Worten erkunden können, ohne das zugrunde liegende Datenmodell verstehen zu müssen. Zusammenfassend lässt sich sagen, dass klare Zusammenfassungen, verwaltete Metriken, transparente statistische Ausgaben und konversationeller Zugriff dazu beigetragen haben, Vertrauen zwischen Produkt-, LiveOps- und Engineering-Teams aufzubauen und Experimente als eine gemeinsame, wissenschaftliche Arbeitsweise zu stärken.
Wie geht es weiter?
HARDlight plant, das Framework um eine Prognoseanwendung zu erweitern und es von deskriptiver und inferenzieller Analytik zu zukunftsweisender Anleitung auszubauen. Die breitere Vision sind prädiktive Experimente und eine Closed-Loop-Optimierung – die Nutzung des Lakehouse, um mehr vom Zyklus von der Hypothese bis zur Bereitstellung zu automatisieren, während Governance und Konsistenz mit Unity Catalog, Spark Declarative Pipelines und MLflow erhalten bleiben. Dieser Dashboard-zentrierte Ansatz kann für andere Studios mit ähnlichen Bedürfnissen erhebliche Auswirkungen haben, indem LLM-Zusammenfassungen über verwalteten Metriken und Diagnosen geschichtet werden, um Experimente mit Zuversicht auf Databricks zu skalieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.