Aufbau, Verbesserung und Bereitstellung von Knowledge-Graph-RAG-Systemen auf Databricks
von Andrea Santurbano, Chandhana Padmanabhan, Jiayi Wu und Dan Pechi
- Überblick über GraphRAG: Der Blog untersucht, wie Retrieval-Augmented Generation (RAG)-Systeme mit Graphdatenbanken wie Neo4j verbessert werden können, was präzisere KI-Ergebnisse ermöglicht, indem semantische Beziehungen zwischen Entitäten in strukturierten Daten erfasst werden.
- Anwendungsfälle & Vorteile: GraphRAG kann in der Cybersicherheit zur Bedrohungserkennung sowie in Branchen wie der Fertigung für vorausschauende Wartung und Lieferkettenmanagement eingesetzt werden und liefert tiefere Einblicke in komplexe Datensätze.
- Implementierung auf Databricks: Der Blog beschreibt, wie ein GraphRAG-System auf Databricks mit Neo4j erstellt und bereitgestellt wird, und zeigt die Integration von LLMs, Delta Tables und dem Agent Bricks Custom Agents für die End-to-End-Bereitstellung.
GraphRAG verstehen
Was ist ein Wissensgraph?
Um zu verstehen, warum man einen Wissensgraphen (KG) anstelle einer anderen strukturierten Datenrepräsentation verwenden könnte, ist es wichtig, dessen Fokus auf explizite Beziehungen zwischen Entitäten – wie Unternehmen, Personen, Maschinen oder Kunden – und deren zugehörigen Attributen oder Merkmalen zu erkennen. Im Gegensatz zu Embeddings oder Vektorsuche, die die Ähnlichkeit in hochdimensionalen Räumen priorisieren, zeichnet sich ein Wissensgraph durch die Darstellung der semantischen Verbindungen und des Kontexts zwischen Datenpunkten aus. Eine Basiseinheit eines Wissensgraphen ist eine Tatsache. Fakten können als Tripel auf eine der folgenden Arten dargestellt werden:
- HRT: <head, relation, tail>
- SPO: <subject, predicate, object>
Zwei einfache KG-Beispiele sind unten dargestellt. Das linke Beispiel einer Tatsache könnte <Andrea, liebt, Irene> sein. Sie können sehen, dass der KG nichts anderes als eine Sammlung mehrerer solcher Fakten ist. Aber wie Sie vielleicht bemerken, haben Graphen Semantik, da das linke Beispiel keine romantische Beziehung zwischen zwei Personen beschreibt, während das rechte Beispiel eine romantische Beziehung zwischen zwei Personen beschreibt.

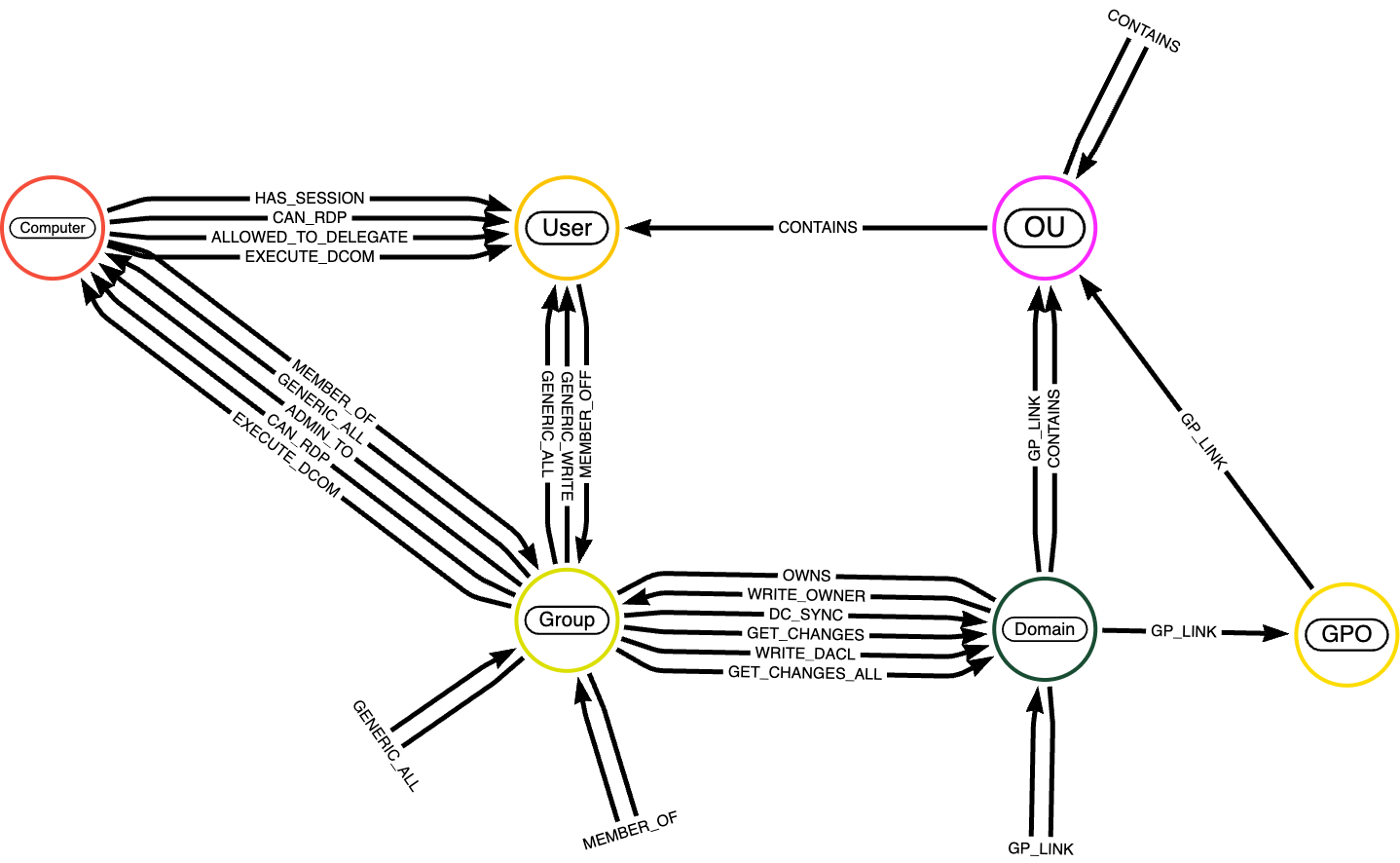
Nachdem Sie nun die Bedeutung von Semantik in Wissensgraphen verstanden haben, stellen wir Ihnen den Datensatz vor, den wir in den kommenden Codebeispielen verwenden werden: den BloodHound-Datensatz. BloodHound ist ein spezialisierter Datensatz zur Analyse von Beziehungen und Interaktionen in Active Directory-Umgebungen. Er wird häufig für Sicherheitsaudits, Angriffsanalysen und zur Gewinnung von Einblicken in potenzielle Schwachstellen in Netzwerkstrukturen verwendet.
Knoten im BloodHound-Datensatz repräsentieren Entitäten in einer Active Directory-Umgebung. Dazu gehören typischerweise:
- Benutzer: Repräsentiert einzelne Benutzerkonten in der Domäne.
- Gruppen: Repräsentiert Sicherheits- oder Verteilergruppen, die Benutzer oder andere Gruppen für Berechtigungszuweisungen zusammenfassen.
- Computer: Repräsentiert einzelne Maschinen im Netzwerk (Workstations oder Server).
- Domänen: Repräsentiert die Active Directory-Domäne, die Benutzer, Computer und Gruppen organisiert und verwaltet.
- Organisationseinheiten (OUs): Repräsentiert Container, die zur Strukturierung und Verwaltung von Objekten wie Benutzern oder Gruppen verwendet werden.
- GPOs (Group Policy Objects): Repräsentiert Richtlinien, die auf Benutzer und Computer innerhalb der Domäne angewendet werden.
Eine detaillierte Beschreibung der Knoteneinheiten finden Sie hier. Beziehungen im Graphen definieren Interaktionen, Mitgliedschaften und Berechtigungen zwischen Knoten; eine vollständige Beschreibung der Kanten finden Sie hier.
Wann GraphRAG gegenüber traditionellem RAG wählen?
Der Hauptvorteil von GraphRAG gegenüber Standard-RAG liegt in seiner Fähigkeit, während des Abrufschrifts exakte Übereinstimmungen durchzuführen. Dies wird teilweise dadurch ermöglicht, dass die Semantik von natürlichsprachlichen Abfragen explizit in nachgelagerten Graphabfragesprachen beibehalten wird. Während dichte Abfragetechniken, die auf Kosinus-Ähnlichkeit basieren, hervorragend darin sind, unscharfe Semantik zu erfassen und verwandte Informationen abzurufen, auch wenn die Abfrage keine exakte Übereinstimmung ist, gibt es Fälle, in denen Präzision entscheidend ist. Dies macht GraphRAG besonders wertvoll in Bereichen, in denen Mehrdeutigkeit inakzeptabel ist, wie z. B. bei Compliance-, Rechts- oder stark kuratierten Datensätzen.
Das heißt, die beiden Ansätze schließen sich nicht gegenseitig aus und werden oft kombiniert, um ihre jeweiligen Stärken zu nutzen. Dichte Abfragen können ein weites Netz für semantische Relevanz werfen, während der Wissensgraph die Ergebnisse mit exakten Übereinstimmungen oder durch Schlussfolgerungen über Beziehungen verfeinert.
Wann traditionelles RAG gegenüber GraphRAG wählen
Während GraphRAG einzigartige Vorteile hat, bringt es auch Herausforderungen mit sich. Eine wichtige Hürde ist die korrekte Definition des Problems – nicht alle Daten oder Anwendungsfälle eignen sich gut für einen Wissensgraphen. Wenn die Aufgabe hochgradig unstrukturierte Texte beinhaltet oder keine expliziten Beziehungen erfordert, ist die zusätzliche Komplexität möglicherweise nicht lohnenswert und führt zu Ineffizienzen und suboptimalen Ergebnissen.
Eine weitere Herausforderung ist die Strukturierung und Pflege des Wissensgraphen. Das Entwerfen eines effektiven Schemas erfordert sorgfältige Planung, um Detail und Komplexität auszubalancieren. Ein schlechtes Schema-Design kann Leistung und Skalierbarkeit beeinträchtigen, während die laufende Wartung Ressourcen und Fachwissen erfordert.
Echtzeit-Leistung ist eine weitere Einschränkung. Graphdatenbanken wie Neo4j können bei Echtzeitabfragen auf großen oder häufig aktualisierten Datensätzen aufgrund komplexer Traversierungen und Mehrfachsprungabfragen Schwierigkeiten haben, was sie langsamer als dichte Abfragesysteme macht. In solchen Fällen kann ein hybrider Ansatz – die Verwendung dichter Abfragen für Geschwindigkeit und Graphverfeinerung für die Post-Query-Analyse – eine praktischere Lösung bieten.
GraphDB und Embeddings
Graph-Datenbanken wie Neo4j bieten oft auch Vektor-Suchfunktionen über HNSW-Indizes. Der Unterschied liegt darin, wie sie diesen Index verwenden, um bessere Ergebnisse als Vektordatenbanken zu erzielen. Wenn Sie eine Abfrage durchführen, verwendet Neo4j den HNSW-Index, um die am nächsten liegenden übereinstimmenden Embeddings basierend auf Maßen wie Kosinus-Ähnlichkeit oder Euklidischem Abstand zu identifizieren. Dieser Schritt ist entscheidend, um einen Ausgangspunkt in Ihren Daten zu finden, der semantisch mit der Abfrage übereinstimmt, und nutzt die implizite Semantik, die durch die Vektorsuche gegeben ist.
Was Graphdatenbanken auszeichnet, ist ihre Fähigkeit, diese anfängliche vektorbasierte Abfrage mit ihren leistungsstarken Traversierungsfunktionen zu kombinieren. Nach dem Auffinden des Einstiegspunkts mithilfe des HNSW-Index nutzt Neo4j die explizite Semantik, die durch die Beziehungen im Wissensgraphen definiert ist. Diese Beziehungen ermöglichen es der Datenbank, den Graphen zu durchlaufen und zusätzlichen Kontext zu sammeln, wodurch aussagekräftige Verbindungen zwischen Knoten aufgedeckt werden. Diese Kombination aus impliziter Semantik aus Embeddings und expliziter Semantik aus Graphbeziehungen ermöglicht es Graphdatenbanken, präzisere und kontextreichere Antworten zu liefern, als es jeder Ansatz allein könnte.
End-to-End GraphRAG in Databricks
GraphRAG ist ein großartiges Beispiel für Compound AI-Systeme in Aktion, bei denen mehrere KI-Komponenten zusammenarbeiten, um die Abfrage intelligenter und kontextbewusster zu gestalten. In diesem Abschnitt werfen wir einen allgemeinen Blick darauf, wie alles zusammenpasst.
GraphRAG-Architektur
Unten sehen Sie ein Architekturdiagramm, das zeigt, wie die natürlichsprachlichen Fragen eines Analysten Informationen aus einem Neo4j-Wissensgraphen abrufen können.
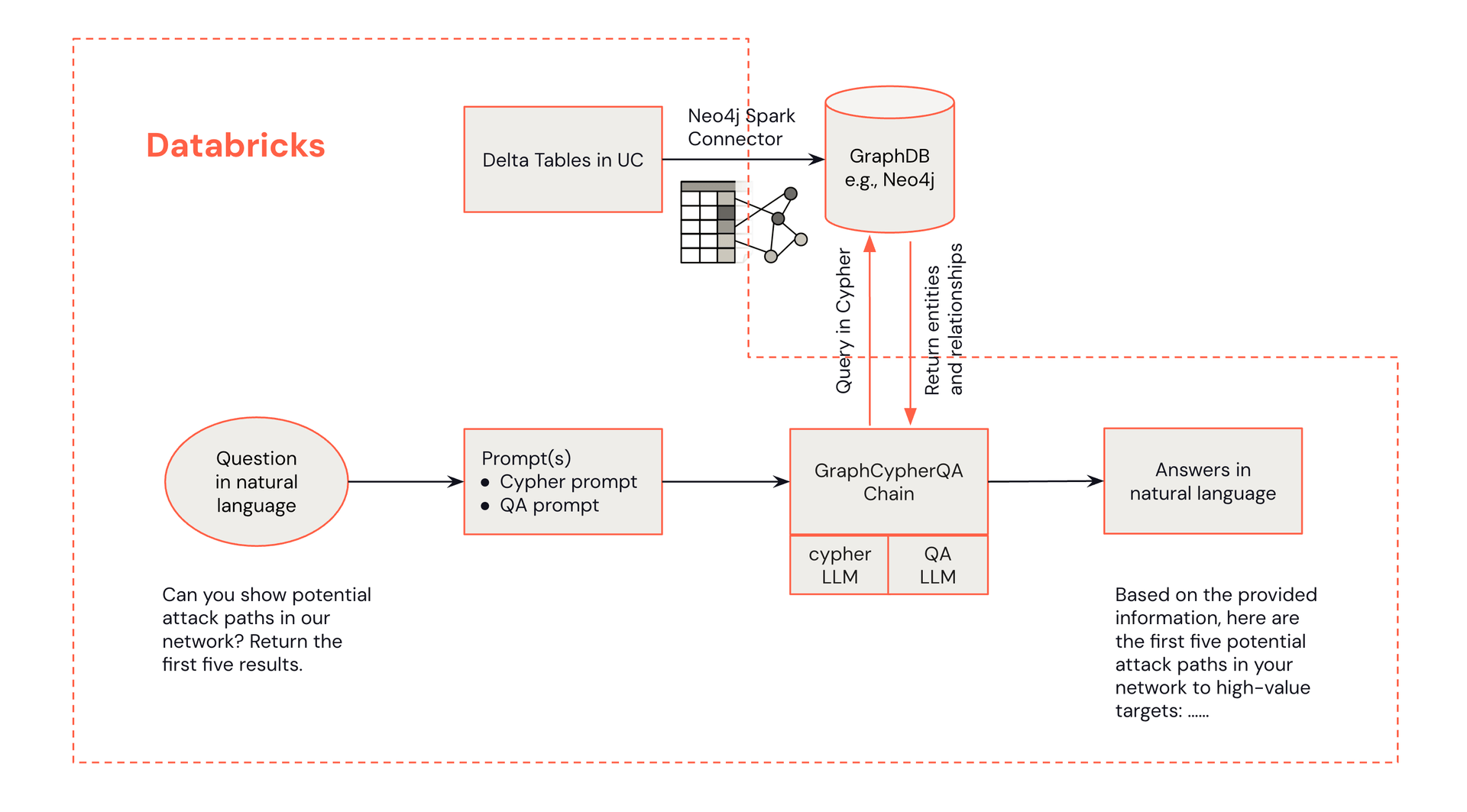
Die Architektur für GraphRAG-gestützte Bedrohungserkennung kombiniert die Stärken von Databricks und Neo4j:
- Sicherheitsoperationszentrum (SOC) Analysten-Interface: Analysten interagieren mit dem System über Databricks, initiieren Abfragen und erhalten Alarmempfehlungen.
- Databricks-Verarbeitung: Databricks übernimmt die Datenverarbeitung, die LLM-Integration und dient als zentrale Drehscheibe für die Lösung.
- Neo4j Wissensgraph: Neo4j speichert und verwaltet den Cybersicherheits-Wissensgraphen und ermöglicht komplexe Beziehungsabfragen.
Implementierungsübersicht
Für diesen Blog überspringen wir die Code-Details – werfen Sie einen Blick in das GitHub Repository für die vollständige Implementierung. Gehen wir die wichtigsten Schritte zum Erstellen und Bereitstellen eines GraphRAG-Agenten durch.
- Erstellen eines Wissensgraphen aus Delta-Tabellen: Im Notebook haben wir Szenarien mit strukturierten und unstrukturierten Daten besprochen. Der Neo4j Spark Connector bietet eine sehr einfache Möglichkeit, Daten in Unity Catalog in Graph-Entitäten (Knoten/Beziehungen) umzuwandeln.
- Bereitstellen von LLMs für Cypher-Abfragen und QA: GraphRAG benötigt LLMs für die Abfragegenerierung und Zusammenfassung. Wir haben gezeigt, wie gpt-4o, llama-3.x, ein feinabgestimmtes text2cypher-Modell von HuggingFace bereitgestellt und über einen Provisioned Throughput-Endpunkt bereitgestellt werden.
- Erstellen und Testen der GraphRAG-Kette: Wir haben gezeigt, wie verschiedene LLMs für Cypher und QA LLMs sowie Prompts über GraphCypherQAChain verwendet werden können. Dies ermöglicht uns, mit Glass-Box-Tracing-Ergebnissen über MLflow Tracing weiter zu optimieren.
- Agent mit dem Agent Bricks Custom Agents bereitstellen: Verwenden Sie das Agent Bricks Custom Agents und MLflow, um den Agenten bereitzustellen. Im Notebook umfasst der Prozess das Protokollieren des Modells, die Registrierung im Unity Catalog, die Bereitstellung an einem Serving-Endpunkt und den Start einer Review-App zum Chatten.

Fazit
GraphRAG ist ein leistungsstarker und dennoch hochgradig anpassbarer Ansatz zum Erstellen von Agenten, die deterministischere und kontextbezogenere KI-Ausgaben liefern. Sein Design ist jedoch fallspezifisch und erfordert eine durchdachte Architektur und problemspezifische Abstimmung. Durch die Integration von Wissensgraphen mit der skalierbaren Infrastruktur und den Tools von Databricks können Sie End-to-End Compound AI-Systeme erstellen, die strukturierte und unstrukturierte Daten nahtlos kombinieren, um umsetzbare Erkenntnisse mit tieferem kontextuellem Verständnis zu generieren.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.