Die Konvergenz von offenen Tabellenformaten und offenen Katalogen: Catalog Commits ist allgemein verfügbar
Catalog Commits ist die nächste Evolutionsstufe des offenen Lakehouse
von Benjamin Mathew, Michelle Leon, Lukas Rupprecht und Ryan Johnson
Catalog Commits machen einen großen Schritt zur Vereinheitlichung des Lakehouse, indem sie Delta mit dem katalogorientierten Modell von Iceberg in Einklang bringen. Mit Catalog Commits werden Kataloge zum Koordinationssystem für Delta-Tabellen und vermitteln Tabellenerkennung, -zugriff und -zustand über verschiedene Engines hinweg.
Heute freuen wir uns, die allgemeine Verfügbarkeit von Catalog Commits für UC-verwaltete Tabellen bekannt zu geben. Dies ist ein wichtiges Plattform-Upgrade, das die Interoperabilität von UC-verwalteten Tabellen erweitert, die Governance-Funktionen von UC stärkt und neue Funktionen wie Multi-Statement- und Multi-Table-Transaktionen ermöglicht.
In diesem Blog behandeln wir…
- Wie Delta und Unity Catalog sich gemeinsam entwickeln
- Die Probleme, die Catalog Commits lösen
- Wie Catalog Commits funktionieren
- Wie Catalog Commits für Unity Catalog-verwaltete Tabellen aktiviert werden
Die Entwicklung von Delta Lake und Unity Catalog
Als Delta Lake entwickelt wurde, benötigte das Lakehouse zunächst zuverlässige Transaktionen auf offenem Cloud-Speicher. Damals waren Kataloge nicht für die Koordination moderner Daten-Workloads ausgelegt, daher traf Delta eine revolutionäre architektonische Entscheidung: Es brachte ACID-Garantien direkt in Dateisysteme von Data Lakes. Diese Grundlage machte das Lakehouse möglich.
Da das Lakehouse zum Aufzeichnungssystem für immer mehr Teams, Engines und KI-Workloads wurde, wurde die Notwendigkeit einer einheitlichen Governance über diese verschiedenen Assets hinweg kritisch. Unity Catalog bot diese fehlende Governance-Schicht: ein einziger Ort, um Daten- und KI-Assets über Clouds, Formate und Engines hinweg zu entdecken, zu sichern, zu auditieren und den Zugriff darauf zu koordinieren.
Zusammen bildeten Delta Lake und Unity Catalog die Grundlage des modernen Lakehouse. Sie arbeiteten jedoch nebeneinander – Delta verwaltete den Transaktionszustand auf der Speicherebene und Unity Catalog steuerte den Zugriff auf der Katalogebene. Diese Architektur war anfangs ausreichend, aber als Organisationen über immer mehr Engines und Workloads skalierten, führte dieses Design zu neuen Koordinationsherausforderungen.
Heutige Herausforderungen bei der Koordination zwischen Tabellen und Katalogen
Die ursprüngliche dateisystemorientierte Architektur von Delta war leistungsstark, um Transaktionen in Data Lakes zu ermöglichen, aber sie war nicht für eine Welt konzipiert, in der der Katalog die Tabellenidentität, den Zugriff und den Zustand über viele Engines hinweg konsistent koordinieren muss. Da Organisationen immer höhere Anforderungen an ihre Daten stellen, hat der Mangel an Katalogkoordination drei anhaltende Herausforderungen offengelegt:
- Das „Split-Brain“-Problem: Externe Engines, die direkt in Objektspeicher auf Delta-Tabellen schreiben, führen dazu, dass Metadaten des Katalogs, wie Schemas, stillschweigend vom tatsächlichen Tabellenzustand abweichen.
- Fragmentierung des Zugriffs über mehrere Engines und Agenten: Jede Engine, jedes Tool und jeder Agent kann auf Tabellen unterschiedlich zugreifen, was zu fragmentierter Tabellenerkennung, inkonsistenten Audits und keiner standardisierten Durchsetzung von Zeilen- oder Spaltenkontrollen über Systeme hinweg führt.
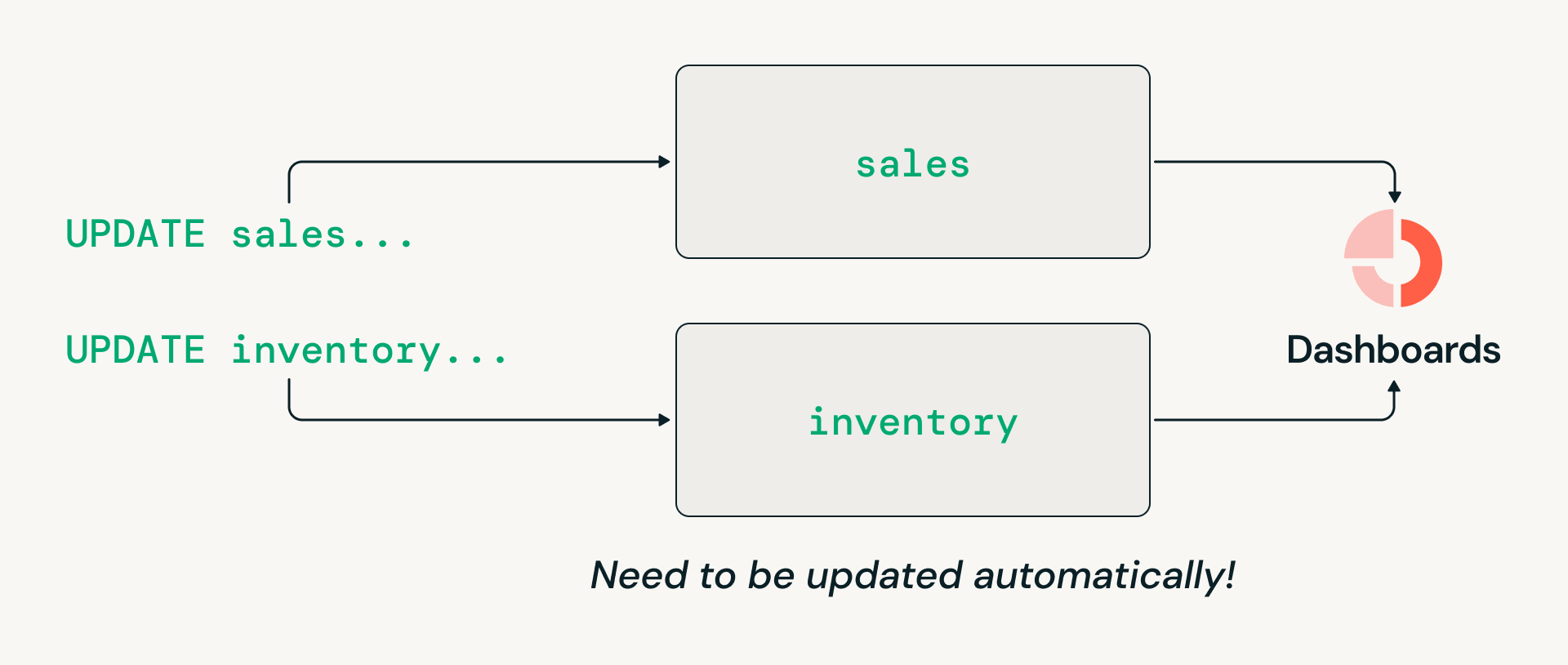
- Koordinierung von Transaktionen über mehrere Tabellen hinweg: Offene Lakehouse-Architekturen unterstützten historisch keine atomaren Schreibvorgänge, die mehrere Tabellen umfassen, sodass Organisationen Legacy-Data-Warehouses speziell für transaktionale Workloads unterhalten mussten.
Herausforderung Nr. 1: „Split-Brain“-Problem – Synchronisierung von verwaltenden Katalogen und Tabellen
Heute sind Kataloge nicht im Lese- oder Schreibpfad für Delta-Engines. Wenn also eine Engine wie Apache Flink eine Schemaänderung an einer Tabelle vornehmen möchte, indem sie direkt in die Speicherebene schreibt, bleibt der Katalog über diese Änderungen im Unklaren, was zu einem „Split-Brain“-Zustand führt, in dem die Metadaten des Katalogs und der tatsächliche Tabellenzustand voneinander abweichen. Dies kann zu stillschweigender Metadaten-Drift und fehlgeschlagenen nachgelagerten Pipelines führen.
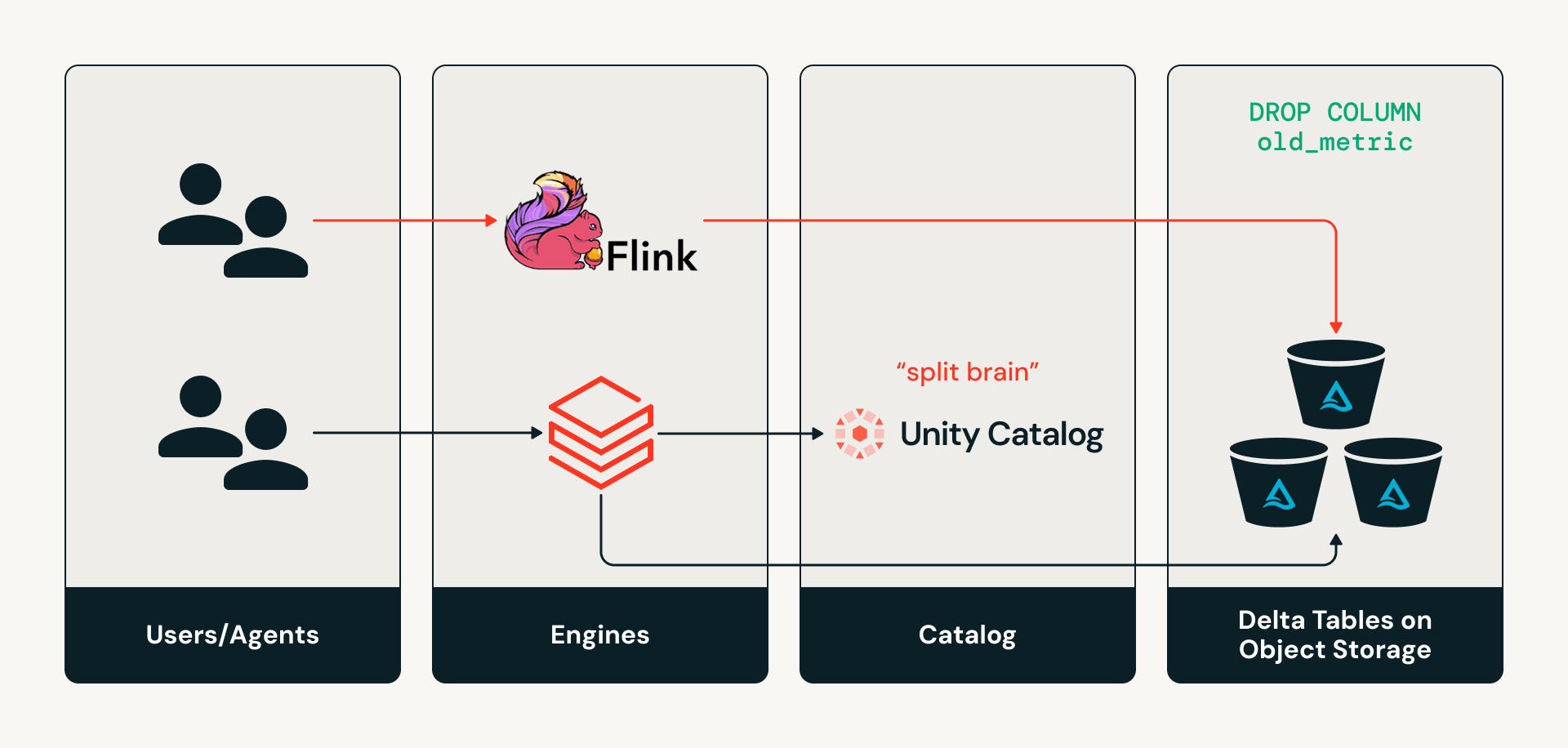
Herausforderung Nr. 2: Fragmentierung des Zugriffs über mehrere Engines und Agenten
Moderne Organisationen nutzen viele Engines und Tools zur Datenanalyse, zum Erstellen von Pipelines und zur Bereitstellung von KI. Historisch gesehen haben diese Systeme direkt über statische Pfade auf Daten im Objektspeicher zugegriffen. Dies koppelt Workloads eng an den physischen Speicher, was die Tabellenerkennung erschwert. Da jede Engine Delta-Tabellen direkt aus der Speicherebene liest, die normalerweise nur grobkörnige Berechtigungen unterstützt, ist es außerdem sehr schwierig, konsistente Zeilen-/Spalten-Governance über alle Engines hinweg durchzusetzen. Ebenso bleibt die Überwachung des Datenzugriffs fragmentiert, da es keine konsistente Zugriffsebene gibt, um Aktivitäten über Engines hinweg zu erfassen. Administratoren haben möglicherweise keinen konsistenten Überblick darüber, wie Daten tatsächlich verwendet werden.
Organisationen benötigen einen zentralen Ort für die Entdeckung, Governance und Überwachung ihrer Daten. Dieser Bedarf wird noch dringlicher, da KI-Agenten als Hauptverbraucher von Unternehmensdaten aufkommen.
Herausforderung Nr. 3: Koordinierung von Transaktionen über mehrere Tabellen hinweg
Data-Warehousing-Workloads erfordern oft Transaktionen über mehrere Tabellen hinweg, wie z. B. das atomare Aktualisieren von Verkaufs- und Inventur-Tabellen, damit nachgelagerte Leser immer eine konsistente Ansicht sehen. Die historische dateisystemorientierte Architektur von Delta Lake beschränkte Transaktionen jedoch auf einzelne Tabellen. Daher mussten viele Organisationen, obwohl sie das Lakehouse-Architekturmodell konsolidieren wollten, Legacy-Data-Warehouses speziell für diese Workloads unterhalten.
Catalog Commits ist die nächste Evolution des offenen Lakehouse
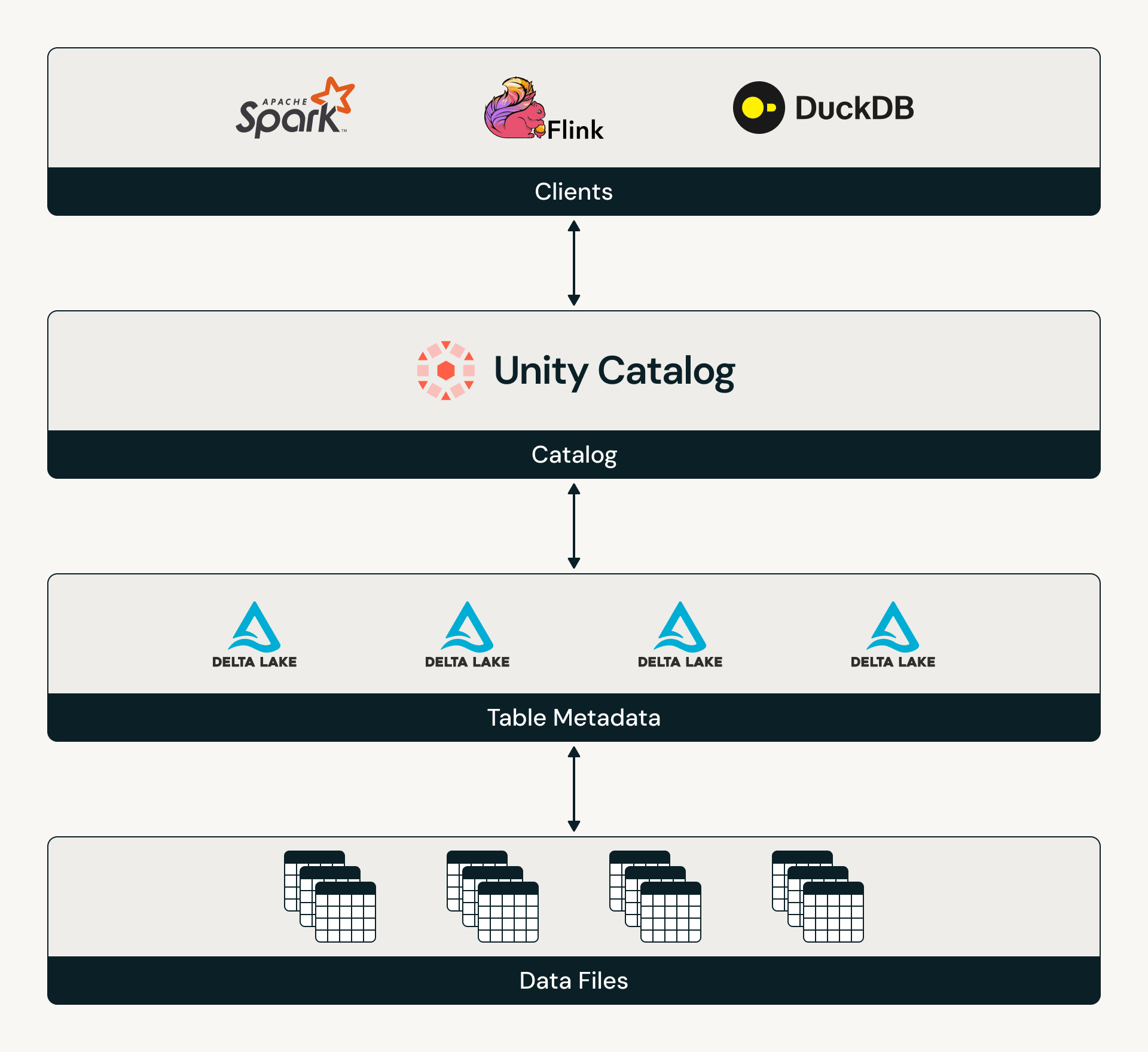
Catalog Commits ist der offene Standard für Delta-Tabellen zur Integration mit einem Katalog, wodurch der Katalog für die Koordinierung des Tabellenzugriffs und die Verfolgung des neuesten Tabellenzustands verantwortlich ist. Da nun sowohl Delta als auch Iceberg katalogorientiert sind, können Kunden darauf vertrauen, dass ihre Tabellen ein standardisiertes Modell für Tabellenerkennung und Governance haben. Um mehr über die Catalog Commits-Spezifikation zu erfahren, lesen Sie das Delta-Protokoll und sehen Sie sich die Referenzimplementierung von Catalog Commits in Unity Catalog an.
Auf Databricks können Catalog Commits für UC-verwaltete Delta-Tabellen aktiviert werden. Nach der Aktivierung vermittelt Unity Catalog alle Tabellenzugriffe und schafft ein konsistentes Erkennungs- und Autorisierungsmodell für jede Engine. Dies ermöglicht es Organisationen, die Governance über ihre gesamten Bestände hinweg wirklich zu zentralisieren.
Catalog Commits löst langjährige Probleme mit Split-Brain, Multi-Engine-Fragmentierung und Multi-Table-Koordination.
1. Beseitigung des „Split-Brain“-Problems: Der Tabellenzustand und der Katalog bleiben synchron, da alle Engines über dieselben APIs auf Tabellen zugreifen, wodurch jedes Risiko einer stillschweigenden Metadaten-Drift entfällt.
Ermöglicht externen Engines das Schreiben auf Unity Catalog-verwaltete Delta-Tabellen
„Historisch gesehen bedeutete das Streamen von Daten in ein verwaltetes Lakehouse die Abgleichung von Katalogmetadaten außerhalb des Bandes und die Hoffnung, dass nichts abweicht. Catalog Commits beseitigt diese Lücke vollständig. Mit dem nativen Kafka-Dienst von StreamNative – angetrieben von Ursa für die disklose, leaderlose Architektur von Kafka – werden Daten direkt über Unity Catalog gestreamt und committet, sodass jeder Datensatz als verwaltete Zeile landet, die sofort von jeder Engine abgefragt werden kann.“—Sijie Guo, Mitbegründer & CEO, StreamNative
2. Lösung der Fragmentierung des Zugriffs über mehrere Engines: Da jede Engine und jeder Agent standardisierte Katalog-APIs zur Auflösung von Tabellen verwendet, müssen Organisationen keine Speicherpfade mehr fest codieren oder Berechtigungen auf Dateisystemebene verwalten.
Ermöglicht konsistente und verbesserte Governance über alle Engines hinweg
3. Ermöglicht traditionelle Data-Warehousing-Workloads auf dem Lakehouse: Die Databricks-Engine und Unity Catalog können atomare Schreibvorgänge koordinieren, die mehrere Tabellen umfassen. Dies bringt Multi-Table-ACID-Semantik in das Lakehouse und ermöglicht traditionelle Data-Warehousing-Workloads.
Ermöglicht die Durchführung von Multi-Table-Transaktionen auf Databricks
„Transaktionen, kombiniert mit all den neuen SQL-Funktionen wie SQL Scripting und Stored Procedures, ermöglichen es uns, unsere kritischsten Data-Warehousing-Workloads vertrauensvoll auf Databricks zu migrieren. Diese Workloads bilden die Grundlage für wesentliche Analysen in unserem gesamten Unternehmen, und robuste Transaktionsgarantien auf dem Lakehouse sind ein echter Game-Changer.“ —Gal Doron, Head of Data, AnyClip
Darüber hinaus ermöglicht die Aktivierung von Catalog Commits für UC-verwaltete Tabellen auch:
- Ganzheitliche Auditierbarkeit: Unity Catalog zentralisiert Tabellenmetadaten und Zugriffsrichtlinien, sodass Teams Berechtigungen und Tabellenbesitz über eine konsistente Katalogoberfläche überprüfen können, anstatt sich ausschließlich auf Low-Level-Speicherprotokolle zu verlassen.
- Automatisierte Tabellenoptimierungen: Unity Catalog nutzt seine Sichtbarkeit aller Tabellenzugriffe, um die Daten von Organisationen optimal für ihre spezifischen Abfragemuster durch Liquid Clustering und Predictive Optimization zu organisieren.
- Grundlagen für bessere Leistung: Unity Catalog kann Engines direkt mit Tabellenmetadaten versorgen, ohne dass die Engine Metadaten aus dem Cloud-Speicher abrufen muss, wodurch eine Hauptquelle für Metadatenlatenz entfällt.
Zusammen machen diese Funktionen UC-verwaltete Tabellen mit Catalog Commits zur offensten, am besten verwalteten und performantesten Grundlage für das moderne Lakehouse.
Aktivieren Sie Catalog Commits noch heute für Ihre Tabellen
Catalog Commits auf Databricks ist ab sofort allgemein verfügbar! Durch die Aktivierung von Catalog Commits auf Unity Catalog-verwalteten Tabellen werden die folgenden Funktionen freigeschaltet:
- Verbesserte Interoperabilität: Schreiben externer Engines in UC-verwaltete Delta-Tabellen
- Stärkere Governance: Ermöglicht konsistente und verbesserte Governance über alle Engines hinweg
- Neue Funktionen: Mehrere Anweisungen, mehrere Tabellen-Transaktionen
Databricks-Produkte, die UC-verwaltete Tabellen lesen oder schreiben, von der Aufnahme bis zum Gold-Level-Konsum, unterstützen jetzt Catalog Commits. Dazu gehören Streaming Tables, Delta Sharing, Zerobus, Lakeflow Connect, AI Gateway, MLflow und Lakeflow Job Triggers. Ebenso wird Catalog Commits derzeit von Engines im gesamten Ökosystem unterstützt, darunter Delta Spark, Delta Flink, Starburst Trino, DuckDB und StreamNative.
Es ist auch für jede Engine einfach, Catalog Commits zu unterstützen, indem sie sich mit Delta Kernel integriert, einer gemeinsamen Bibliothek von APIs, die Protokoll-Level-Details abstrahiert. Delta Kernel erleichtert Connectors die Unterstützung der neuesten Delta-Funktionen durch einfache Versions-Upgrades.
Das Erstellen einer UC-verwalteten Delta-Tabelle mit aktivierten Catalog Commits ist einfach. Führen Sie mit Databricks Runtime 16.4+ Folgendes aus:
Um eine vorhandene UC-verwaltete Delta-Tabelle für Catalog Commits zu aktualisieren, verwenden Sie Databricks Runtime 18.0+ und führen Sie Folgendes aus:
Beginnen Sie mit Catalog Commits und nehmen Sie am Data and AI Summit teil, um mehr über unsere Arbeit beim Aufbau des offenen Lakehouse zu erfahren!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.