Schutz vor Datenexfiltration mit Azure Databricks
Erfahren Sie im Detail, wie Sie eine sichere Azure Databricks-Architektur einrichten, um Datenexfiltration zu verhindern
von Ganesh Rajagopal, Bruce Nelson und Bhavin Kukadia
Zuletzt aktualisiert am: 30. Oktober 2025
Wichtige Lektüre
Bitte stellen Sie sicher, dass Sie mit diesen Themen vertraut sind, bevor Sie beginnen
- Azure Databricks Serverless Compute Architektur
- Wichtige Databricks Terminologie
- Was ist Front-End und Back-End Azure Databricks Private Link (PL)?
- Anforderungen für einen Private Link-aktivierten Workspace
- Was sind Service Endpoint Policies für Azure Workspaces?
- IP-Zugriffsliste für den Ingress-Controller
- Secure Cluster-Konnektivität
- Databricks Netzwerk
- Unity Catalog
Die Azure Databricks Lakehouse Platform bietet eine einheitliche Sammlung von Tools zum Erstellen, Bereitstellen, Teilen und Verwalten von unternehmensgerechten Datenlösungen in großem Maßstab. Databricks integriert sich in den Cloud-Speicher und die Sicherheit in Ihrem Cloud-Konto und verwaltet und stellt Cloud-Infrastruktur in Ihrem Namen bereit.
Das übergeordnete Ziel dieses Artikels ist es, die folgenden Risiken zu mindern:
- Datenzugriff von einem Browser im Internet oder einem nicht autorisierten Netzwerk über die Databricks-Webanwendung.
- Datenzugriff von einem Client im Internet oder einem nicht autorisierten Netzwerk über die Databricks-API.
- Datenzugriff von einem Client im Internet oder einem nicht autorisierten Netzwerk über Azure Private Link oder Service Endpoints.
- Eine kompromittierte Workload auf dem Azure Databricks-Cluster schreibt Daten in eine nicht autorisierte Speicherressource in Azure oder im Internet.
Azure Databricks ist ein First-Party-Dienst und unterstützt die nativen Tools und Dienste von Azure, die Daten während der Übertragung und im Ruhezustand schützen. Azure Databricks unterstützt Netzwerksicherheitskontrollen wie benutzerdefinierte Routen, Firewall-Regeln und Network Security Groups.
Zusätzlich zu den technischen Zielen dieses Blogs möchten wir sicherstellen, dass die von uns vorgestellten Konzepte Folgendes berücksichtigen:
- Einfachheit: Jedes Sicherheitsdesign sollte gut verstanden und wartbar sein und zu den Fähigkeiten Ihrer Organisation passen. Eine Sicherheitslösung, die implementiert, aber nicht vollständig verstanden wird, kann unbeabsichtigt kompromittiert werden.
- Betriebskosten der Lösung sollten immer berücksichtigt werden. Wenn ein Sicherheitsdesign aufgegeben wird, weil die Kosten zu hoch sind, war die Lösung nicht effektiv. Sicherheit sollte kostengünstig und nachhaltig sein.
Wir werden Bereiche für Kosteneinsparungen oder Kostenbedenken aufzeigen und versuchen zu klären, warum und wie die Dinge funktionieren, wann immer wir können.
Bevor wir beginnen, werfen wir einen kurzen Blick auf die Azure Databricks-Bereitstellungsarchitektur hier:
Azure Databricks ist so strukturiert, dass eine sichere Zusammenarbeit zwischen Teams gefördert wird, während es die Verwaltung vieler Backend-Dienste übernimmt, sodass Sie sich auf Data Science, Datenanalyse und Data Engineering konzentrieren können.
Azure Databricks ist um zwei Schlüsselkomponenten herum aufgebaut: die Steuerungsebene (Control Plane) und die Rechenebene (Compute Plane).
Steuerungsebene (Control Plane):
Die Azure Databricks-Steuerungsebene, die von Databricks in seinem eigenen Azure-Konto verwaltet wird, fungiert als Kernintelligenz der Plattform. Sie stellt Backend-Dienste für die Benutzerauthentifizierung, die Cluster- und Job-Orchestrierung sowie die Workspace-Verwaltung bereit und bietet die Webschnittstelle und API-Endpunkte für die Service-Interaktion.
Während sie den Lebenszyklus von Computeressourcen orchestriert, verarbeitet sie keine Daten direkt. Stattdessen leitet die Steuerungsebene die Datenverarbeitung an die separate Rechenebene weiter, die entweder innerhalb des Azure-Abonnements des Kunden oder im Databricks-Mandanten für serverlose Bereitstellungen betrieben wird. Notebook-Befehle und viele andere Workspace-Konfigurationen werden in der Steuerungsebene gespeichert und verschlüsselt im Ruhezustand.
Rechenebene (Compute Plane):
Die Rechenebene ist für die Verarbeitung Ihrer Daten verantwortlich. Die spezifische Art der verwendeten Rechenleistung, serverlos oder klassisch, hängt von Ihren gewählten Computeressourcen und Ihrer Workspace-Konfiguration ab. Sowohl serverlose als auch klassische Rechenleistung teilen sich einige Ressourcen wie den standardmäßigen Workspace-Speicher (dbfs) und verwaltete Identitäten, die an Ihren Azure-Mandanten gebunden sind.
Serverless Compute
Bei serverloser Rechenleistung laufen Ressourcen in einer von Databricks verwalteten Compute-Ebene in Azure. Azure Databricks kümmert sich um fast die gesamte zugrunde liegende Infrastruktur, einschließlich Bereitstellung, Skalierung und Wartung. Dieser Ansatz bietet:
- Vereinfachte Bedienung: Benutzer können sich auf Data Engineering- und Data Science-Aufgaben konzentrieren, ohne Cluster oder virtuelle Maschinen verwalten zu müssen.
- Kosteneffizienz: Benutzer zahlen nur für die Computeressourcen, die während der Ausführung von Workloads aktiv verbraucht werden, wodurch Kosten für Leerlauf-Cluster entfallen.
Serverlose Ressourcen stehen nach Bedarf zur Verfügung, wodurch Kosten für Leerlaufzeiten reduziert werden. Sie laufen auch innerhalb einer sicheren Netzwerkgrenze im Azure Databricks-Konto mit mehreren Ebenen von Sicherheits- und Netzwerksteuerungen.
Klassische Azure Databricks Compute
Bei klassischer Azure Databricks-Rechenleistung befinden sich die Ressourcen in Ihrem Azure Cloud-Mandanten. Dies bietet vom Kunden verwaltete Rechenleistung, bei der Databricks-Cluster auf Ressourcen in Ihrem Azure-Abonnement und nicht im Databricks-Mandanten ausgeführt werden. Dies bietet:
- Natürliche Isolation: Operationen finden in Ihrem eigenen Azure-Abonnement und virtuellen Netzwerk statt.
- Sichere Verbindungen: Ermöglicht sichere Verbindungen zu anderen Azure-Diensten über Service Endpoints oder Private Endpoints, die Sie verwalten und kontrollieren.
Wichtiger Hinweis: Klassische Cluster, einschließlich klassischer SQL-Warehouses, können aufgrund der Notwendigkeit, Ressourcen aus Ihrem Azure-Abonnement bereitzustellen, längere Startzeiten als serverlose Optionen aufweisen.
Nur Serverless Databricks Workspace-Bereitstellung (neu): Serverless-only Workspaces sind Workspaces, die nur serverlose Rechenleistung ausführen können. Es gibt keine klassische Rechenleistung, sodass alle Systemressourcen von Azure Databricks verwaltet werden, das die gesamte zugrunde liegende Infrastruktur, einschließlich des standardmäßigen Workspace-Speichers, verwaltet.
High-level Architecture
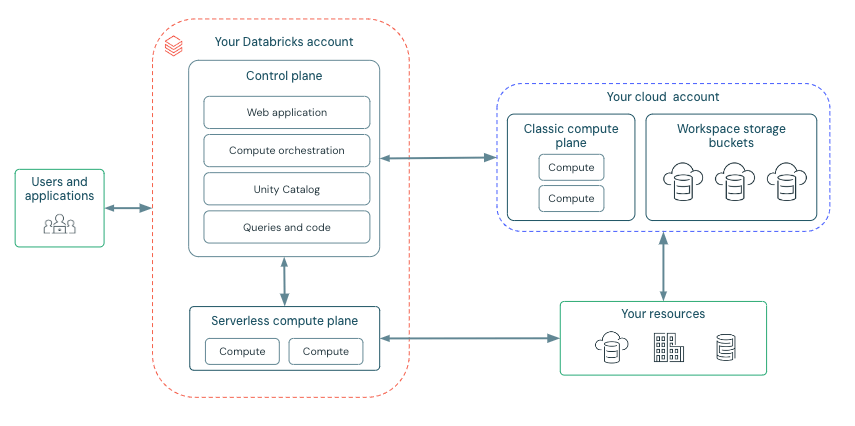
Network Communication Path
Lassen Sie uns den Kommunikationspfad verstehen, den wir sichern möchten. Azure Databricks kann auf verschiedene Weise von Benutzern und Anwendungen genutzt werden, wie unten gezeigt:
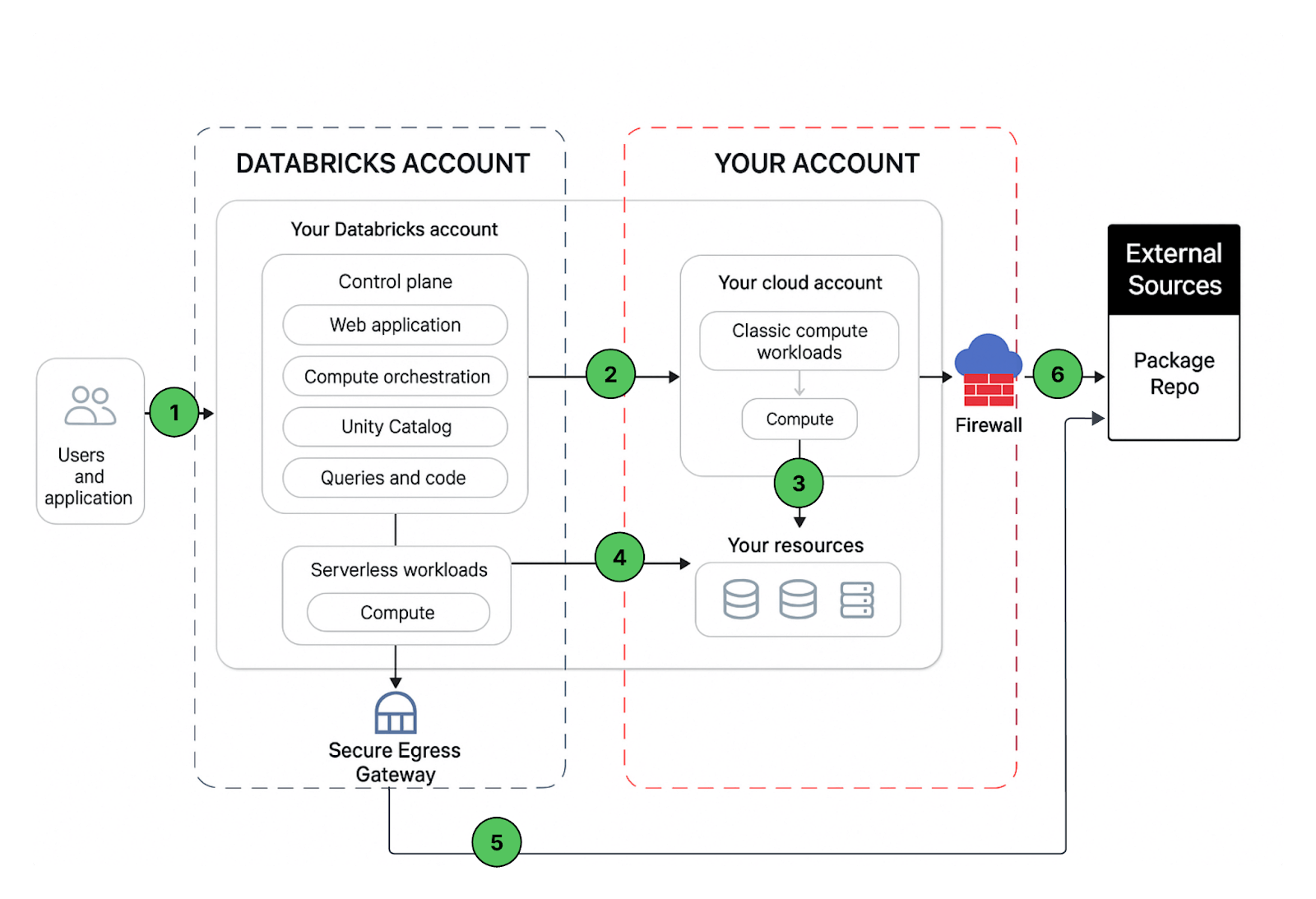
Eine Databricks-Workspace-Bereitstellung umfasst die folgenden Netzwerkpfade, die Sie sichern können:
- Benutzer oder Anwendungen zur Azure Databricks-Webanwendung, auch bekannt als Workspace, oder zu Databricks REST-APIs
- Azure Databricks Classic Compute Plane Virtual Network zur Azure Databricks Control Plane-Dienst. Dies umfasst den Secure Cluster Connectivity Relay und die Workspace-Verbindung für die REST-API-Endpunkte.
- Klassische Compute Plane zu Ihren Speicherdiensten (z. B. ADLS gen2, SQL-Datenbank)
- Serverless Compute Plane zu Ihren Speicherdiensten (z. B. ADLS gen2, SQL-Datenbank)
- Sichere Egress von der Serverless Compute Plane über Netzwerkrichtlinien (Egress-Firewall) zu externen Datenquellen, z. B. Paket-Repositories wie pypi oder maven
- Sichere Egress von der klassischen Compute Plane über eine Egress-Firewall zu externen Datenquellen, z. B. Paket-Repositories wie pypi oder maven (es könnte sich um ein beliebiges Egress-Gerät handeln, das in Azure ausgeführt wird, z. B. Palo Alto)
Aus Sicht des Endbenutzers erfordert Punkt 1 Ingress-Steuerungen, und die Punkte 2 bis 6 erfordern Egress-Steuerungen.
In diesem Artikel konzentrieren wir uns auf die Sicherung des Egress-Datenverkehrs von Ihren Databricks-Workloads, geben dem Leser eine präskriptive Anleitung zur vorgeschlagenen Bereitstellungsarchitektur und teilen dabei Best Practices zur Sicherung des Ingress-Datenverkehrs (Benutzer/Client zu Databricks).
Workspace Deployment Options
Es gibt mehrere Optionen, um eine sichere Azure Databricks-Arbeitsumgebung zu erstellen, auf die von lokalen oder VPN-Verbindungen aus zugegriffen werden kann (kein Internetzugang). Als bewährte Methode empfehlen wir die Sicherung des Zugriffs auf die Arbeitsumgebung mittels privater Endpunkte (Private Link), entweder über eine Standard- oder vereinfachte Bereitstellung. Die empfohlene Option ist die Standard-Bereitstellung. Die Arbeitsumgebung kann über das Azure Portal oder All-in-One-ARM-Vorlagen oder mithilfe von Terraform-Vorlagen für die Security Reference Architecture (SRA) bereitgestellt werden, die die Bereitstellung von Databricks-Arbeitsumgebungen und Cloud-Infrastrukturen ermöglicht, die mit bewährten Sicherheitspraktiken konfiguriert sind.
Front-End vs. Back-End Private Link: Front-End Private Link, auch bekannt als Benutzer zu Arbeitsumgebung. Back-End Private Link, auch bekannt als Compute-Ebene zu Steuerebene:
Standardbereitstellung (empfohlen): Für verbesserte Sicherheit empfiehlt Databricks die Verwendung eines separaten privaten Endpunkts für Ihre Front-End-Verbindungen (Client) von einem separaten Transit-VNet. Sie können sowohl Front-End- als auch Back-End-Private-Link-Verbindungen implementieren oder nur die Back-End-Verbindung. Verwenden Sie ein separates VNet, um den Benutzerzugriff zu kapseln, getrennt von dem VNet, das Sie für Ihre Compute-Ressourcen in der klassischen Datenebene verwenden. Erstellen Sie separate Private-Link-Endpunkte für den Back-End- und Front-End-Zugriff. Befolgen Sie die Anweisungen unter Azure Private Link als Standardbereitstellung aktivieren.
Für System-Speicher, Messaging und Metadatenzugriff von der Compute-Ebene sind zusätzliche Überlegungen erforderlich, da auf diese Dienste nicht über den Back-End-privaten Endpunkt zugegriffen werden kann.
Vom System verwaltete Speicherkonten (nur klassische Compute-Ebene): Diese Speicherkonten werden zum Booten und Überwachen von Databricks-Clustern benötigt. Diese Speicherkonten befinden sich im Databricks-Mandanten und müssen über Service-Endpunkt-Richtlinien (empfohlen) zugelassen werden. Alternativen wären die Verwendung von Storage-Service-Tags, die tendenziell zu breit gefasst sind und die Datenexfiltration erleichtern, oder die individuelle Zulassung der FQDN oder IP-Adressen (nicht empfohlen):
- Artefakt: Nur Lesezugriff auf Databricks Runtime-Images > 11 GB / Cluster-Knoten
- Protokollierung: Lese-/Schreibzugriff auf speicherintensive Nachrichten, einschließlich Audit-Protokollierung.
- Systemtabellen: Nur Lesezugriff auf Audit-, UC- und Systemdaten.
Standard-Speicher der Arbeitsumgebung (DBFS): Gemeinsames verteiltes Dateisystem, das für Scratch-Bereiche, Dienste, temporäre SQL-Ergebnisse (Cloud-Abruf) und Treiber verwendet wird. Kann über private Endpunkte mit der privaten DBFS-Funktion für die klassische Compute-Ebene und Service-Endpunkt oder privaten Endpunkt für serverlose Compute-Ebene gesichert werden.
Messaging: (Event Hub, nur klassische Compute-Ebene) Dies ist eine öffentlich zugängliche Ressource, die für die Nachverfolgung von Datenherkunft und andere leichte Nachrichten verwendet wird. Kann über das EventHub-Service-Tag bei der UDR und/oder Firewall zugelassen werden.
Metadaten: (SQL, nur klassische Compute-Ebene): Dies ist eine öffentlich zugängliche Ressource, die für den Legacy-Hive-Metastore-Verkehr verwendet wird.
Speicherkontozugriff auf Benutzerebene: ALDS- und Blob-Speicherkonten, die für Kundendaten im Gegensatz zu Systemdaten verwendet werden.
First-Party-Ressourcen: Cosmos DB, Azure SQL, DataFactory usw.
Externe Ressourcen: S3, BigQuery, Snowflake usw.
Architektur zum Schutz vor Datenexfiltration
Wir empfehlen eine Hub-and-Spoke-Referenzarchitektur. In diesem Modell hostet das Hub-virtuelle Netzwerk die gemeinsam genutzte Infrastruktur, die für die Verbindung mit validierten Quellen und optional mit lokalen Umgebungen erforderlich ist. Die Spoke-virtuellen Netzwerke werden mit dem Hub verbunden und enthalten isolierte Azure Databricks-Arbeitsumgebungen für verschiedene Geschäftseinheiten oder Teams.
Diese Hub-and-Spoke-Architektur ermöglicht die Erstellung mehrerer Spoke-VNets, die für verschiedene Zwecke und Teams zugeschnitten sind. Die Isolierung kann auch durch die Erstellung separater Subnetze für verschiedene Teams innerhalb eines einzelnen, großen virtuellen Netzwerks erreicht werden. In diesen Fällen können Sie mehrere isolierte Azure Databricks-Arbeitsumgebungen einrichten, jede innerhalb ihres eigenen Subnetzpaares, und Azure Firewall in einem separaten Subnetz innerhalb desselben virtuellen Netzwerks bereitstellen.
Voraussetzungen
| Element | Details |
|---|---|
| Virtuelles Netzwerk |
|
| Subnetze | Drei Subnetze: Host (öffentlich), Container (privat) und Private Endpoint Subnet (zum Speichern privater Endpunkte für Speicher, DBFS und andere Azure-Dienste, die Sie möglicherweise verwenden) |
| Routing-Tabellen | Leiten Sie den ausgehenden Datenverkehr von den Databricks-Subnetzen an die Netzwerk-Appliance, das Internet oder lokale Datenquellen weiter. |
| Azure Firewall | Überprüfen Sie den ausgehenden Datenverkehr und ergreifen Sie Maßnahmen gemäß den Zulassungs-/Ablehnungsrichtlinien. |
| Private DNS-Zonen | Bieten Sie einen zuverlässigen und sicheren DNS-Dienst zur Verwaltung und Auflösung von Domänennamen in einem virtuellen Netzwerk (können während der Bereitstellung automatisch erstellt werden, falls nicht vorhanden). |
| Service-Endpunkt-Richtlinien | Richtlinien für den Zugriff auf alle Speicherkonten, die keine privaten Endpunkte verwenden, einschließlich Systemspeicher für das Speicherkonto der Arbeitsumgebung (DBFS), Artefakt- und Protokollierungsspeicher sowie Systemtabellen. |
| Azure Key Vault | Speichert die CMK zur Verschlüsselung von DBFS, Managed Disk und Managed Services. |
| Azure Databricks Access Connector | Erforderlich, wenn Unity Catalog aktiviert ist. Zum Verbinden von verwalteten Identitäten mit einem Azure Databricks-Konto, um auf in Unity Catalog registrierte Daten zuzugreifen. |
| Liste der Azure Databricks-Dienste, die in der Firewall zugelassen werden sollen | Bitte folgen Sie diesem öffentlichen Dokument und erstellen Sie eine Liste aller IP-Adressen und Domänennamen, die für Ihre Databricks-Bereitstellung relevant sind. |
Bereitstellungsarchitektur
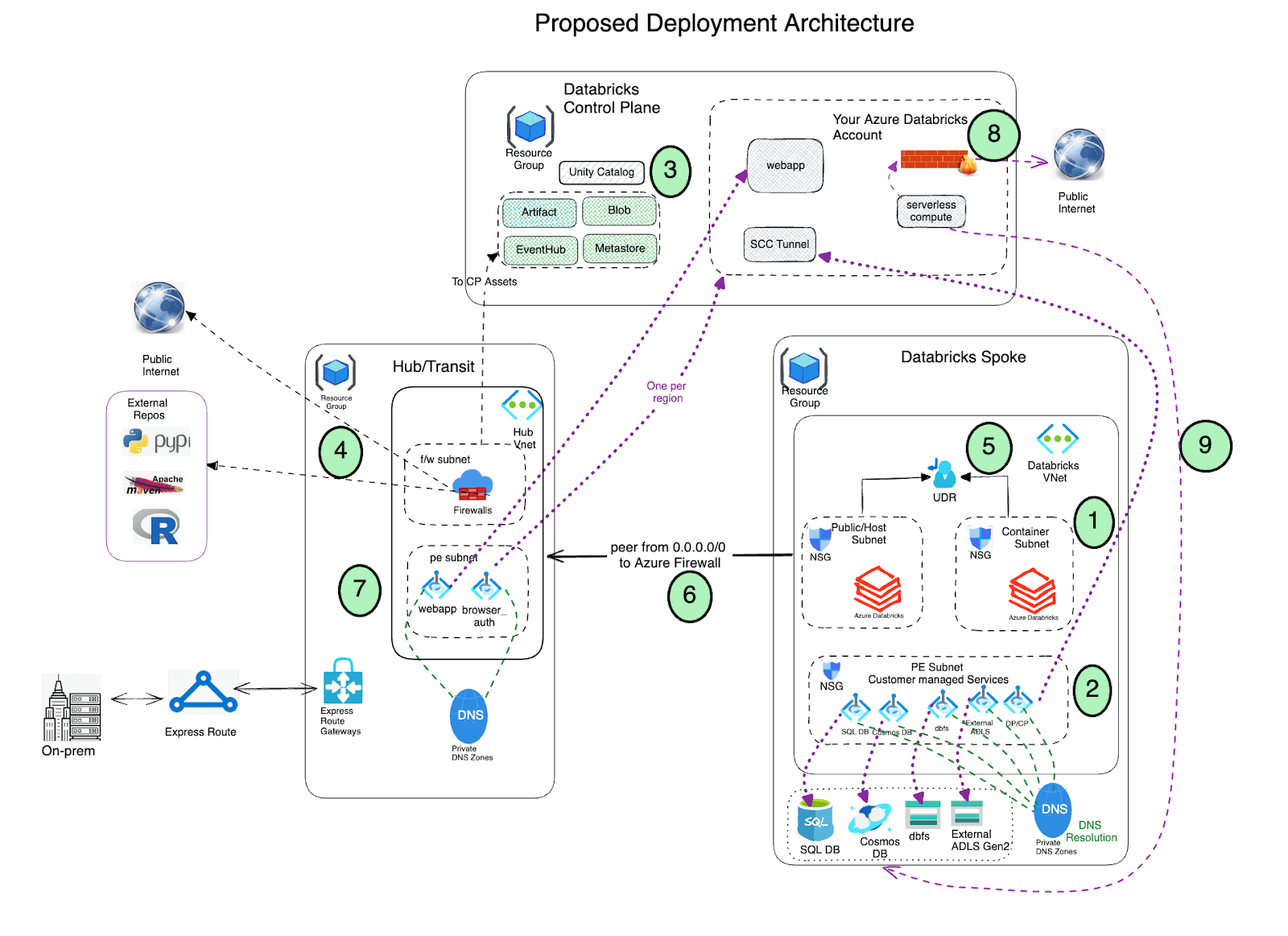
- Stellen Sie Azure Databricks mit aktivierter Secure Cluster Connectivity (SCC) in einem Spoke-virtuellen Netzwerk mithilfe von VNet Injection und Private Link bereit.
- Das virtuelle Netzwerk muss zwei Subnetze für jede Azure Databricks-Arbeitsumgebung enthalten: ein privates Subnetz und ein öffentliches Subnetz (verwenden Sie gerne eine andere Nomenklatur). Beachten Sie, dass es eine Eins-zu-eins-Beziehung zwischen diesen Subnetzen und einer Azure Databricks-Arbeitsumgebung gibt. Sie können nicht mehrere Arbeitsumgebungen über dasselbe Subnetzpaar teilen und müssen für jede verschiedene Arbeitsumgebung ein neues Subnetzpaar verwenden.
- Azure Databricks erstellt während des Bereitstellungsprozesses einen Standard-Blob-Speicher (auch bekannt als Root-Speicher) zur Speicherung von Protokollen und Telemetriedaten. Obwohl der öffentliche Zugriff auf diesen Speicher aktiviert ist, verhindert die auf diesem Speicher erstellte Deny-Zuweisung jeglichen direkten externen Zugriff auf den Speicher; er kann nur über die Databricks-Arbeitsumgebung abgerufen werden. Azure Databricks-Bereitstellungen unterstützen jetzt die private Konnektivität zum Standard-Speicherkonto der Arbeitsumgebung (DBFS).
- Wichtig: Als bewährte Methode wird NICHT empfohlen, Anwendungsdaten im Root-Container (DBFS) zu speichern. Der Zugriff auf den DBFS-Root-Container kann jetzt deaktiviert werden, und stattdessen empfehlen wir die Verwendung von Unity Catalog Volumes. Unity Catalog Volumes bieten moderne Governance und Sicherheit über den DBFS-Root-Speicher.
- Richten Sie Private Link-Endpunkte für Ihre Azure Data Services (Speicherkonten, Eventhub, SQL-Datenbanken usw.) in einem separaten Subnetz innerhalb des Azure Databricks Spoke-Virtual-Networks ein. Dies stellt sicher, dass auf alle Workload-Daten sicher über das Azure-Netzwerk-Backbone zugegriffen wird, wobei der standardmäßige Schutz vor Datenexfiltration vorhanden ist (weitere Details finden Sie in diesem Blogbeitrag). Außerdem ist es im Allgemeinen völlig in Ordnung, diese Endpunkte in einem anderen virtuellen Netzwerk bereitzustellen, das mit dem virtuellen Netzwerk, das den Azure Databricks-Arbeitsbereich hostet, verbunden ist. Beachten Sie, dass Private Endpunkte zusätzliche Kosten verursachen und es in Ordnung ist, (basierend auf den Sicherheitsrichtlinien Ihrer Organisation) Service Endpoints anstelle von Private Endpoints zu verwenden, um auf die Azure Data Services zuzugreifen, insbesondere unter Verwendung von Service Endpoint Policies für den sicheren Zugriff auf Speicherkonten.
- Nutzen Sie Azure Databricks Unity Catalog für eine einheitliche Governance-Lösung.
Stellen Sie Azure Firewall (oder eine andere Network Virtual Appliance) in einem Hub-Virtual-Network bereit. Mit Azure Firewall können Sie Folgendes konfigurieren:
- Anwendungsregeln, die vollqualifizierte Domänennamen (FQDNs) definieren, auf die über die Firewall zugegriffen werden kann. Es wird dringend empfohlen, Anwendungsregeln für die Azure Databricks Control Plane-Ressourcen zu verwenden, z. B. Control Plane, Web App und SCC Relay.
- Netzwerkregeln, die IP-Adresse, Port und Protokoll für Endpunkte definieren, die nicht über FQDNs konfiguriert werden können. Einige des erforderlichen Azure Databricks-Datenverkehrs müssen über die Netzwerkregeln auf die Whitelist gesetzt werden.
Wenn Sie eine Firewall-Appliance eines Drittanbieters anstelle von Azure Firewall verwenden, funktioniert das ebenfalls. Beachten Sie jedoch, dass jedes Produkt seine eigenen Besonderheiten hat und es am besten ist, die entsprechenden Produkt-Support- und Netzwerksicherheitsteams zu konsultieren, um etwaige relevante Probleme zu beheben.
- Der AzureDatabricks Service Tag ist nicht erforderlich, wenn für den Arbeitsbereich Private Endpoints aktiviert sind.
- Bei Verwendung von Service Endpoint Policies sind keine Netzwerkregeln für Databricks Service-Speicherkonten (Artefakte, Protokollierung und Systemtabellen) in der Firewall erforderlich. Ebenso sind keine Speicher-Service-Tags erforderlich oder empfohlen.
- Azure Databricks führt auch zusätzliche Aufrufe an NTP-Dienste, CDN, Cloudflare, GPU-Treiber und externe Speicher für Demo-Datensätze durch, die entsprechend auf die Whitelist gesetzt werden müssen.
Nicht-lokaler Netzwerkverkehr von den Databricks Compute Plane-Subnetzen sollte über ein Egress-Gerät wie Azure Firewall mittels einer benutzerdefinierten Route (z. B. eine Standardroute 0.0.0.0/0) geleitet werden. Dies stellt sicher, dass der gesamte ausgehende Datenverkehr inspiziert wird. Der Egress zur Control Plane, der Private Endpoints nutzt, umgeht jedoch diese Routentabellen und Egress-Geräte. Andere Control Plane-Komponenten wie SQL, Event Hubs und Speicher werden jedoch über Ihr Egress-Gerät geleitet.
- Für Databricks Service-Speicherkonten (Artefakte, Protokollierung und Systemtabellen) können Sie erwägen, Ihr Egress-Gerät (NVA oder Firewall) zu umgehen, um potenzielle Drosselung zu vermeiden und die Datenübertragungskosten zu senken. Der Zugriff auf Artefakt-Speicher allein kann bis zu 11 GB pro Cluster-Knoten ausmachen. Wir empfehlen die Verwendung von Service Endpoints für Speicher in Verbindung mit Service Endpoint Policies. Diese Richtlinien stellen sicher, dass der Arbeitsbereich nur auf die bestimmten Artefakt-, Protokollierungs- und Systemtabellen-Speicherkonten zugreifen kann, die in seiner angehängten Richtlinie über sein Subnetz enthalten sind. Service Endpoint Policies sind auch mit anderem Speicher-Zugriff, der nicht über Private Link erfolgt, kompatibel. Mit Service Endpoint Policies sind keine Speicher-Service-Tags erforderlich oder empfohlen.
- Alternativ kann der ausgehende Datenverkehr zu Control Plane-Assets direkt ins Internet geleitet werden, indem Service-Tag-Regeln zur Routentabelle hinzugefügt werden, wodurch die Firewall umgangen wird. Dies kann helfen, Drosselung und zusätzliche Datenübertragungskosten im Zusammenhang mit Network Virtual Appliances zu vermeiden.
Wichtiger Hinweis: Bitte beachten Sie, dass dies den Egress zu Speicherkonten und Diensten in der gesamten Region ermöglicht und nicht nur zu denen, die Sie erreichen möchten. Dies ist ein kritischer Faktor, der bei der Gestaltung Ihrer Sicherheitsarchitektur sorgfältig berücksichtigt werden muss.
- Konfigurieren Sie Virtual Network Peering zwischen den Azure Databricks Spoke- und Azure Firewall-Hub-Virtual-Networks.
- Stellen Sie Private Endpunkte für das Frontend und die Browser-Authentifizierung (für SSO) im Hub-VNet (Private Endpoint-Subnetz) bereit.
- Konfigurieren Sie die Netzwerkrichtlinien für Serverless Compute, um den ausgehenden Netzwerkverkehr zu steuern. Beachten Sie, dass Serverless Compute an Ihr Azure Databricks-Konto gebunden ist.
- Konfigurieren Sie die Azure Databricks Network Connectivity Config (NCC), um eine sichere Verbindung zwischen Ihren Serverless Compute-Ressourcen und Ihren Azure-Speicherdiensten (wie ADLS Gen2 und SQL Database) mithilfe von Azure Private Link herzustellen.
Häufig gestellte Fragen zum Datenschutzarchitektur-Schutz
Kann ich Service Endpoints verwenden, um den Datenausgang zu Azure Data Services zu sichern?
Ja, Service Endpoints bieten eine sichere und direkte Konnektivität zu von Kunden verwalteten Azure-Diensten (z. B. ADLS Gen2, Azure KeyVault oder Eventhub) über eine optimierte Route im Azure Backbone-Netzwerk. Service Endpoints können verwendet werden, um die Konnektivität zu externen Azure-Ressourcen nur auf Ihr virtuelles Netzwerk zu beschränken.
Kann ich Service Endpoint Policies mit von Databricks verwalteten Speicherdiensten verwenden?
Ja, Service Endpoint Policies sind ab dem 01.10.2025 in der öffentlichen Vorschau verfügbar. Siehe: Konfigurieren von Azure Virtual Network Service Endpoint Policies für den Speicherzugriff von Classic Compute
Kann ich eine Network Virtual Appliance (NVA) außer Azure Firewall verwenden?
Ja, Sie können eine NVA eines Drittanbieters verwenden, solange die Netzwerkverkehrsregeln wie in diesem Artikel beschrieben konfiguriert sind. Bitte beachten Sie, dass wir dieses Setup nur mit Azure Firewall getestet haben, obwohl einige unserer Kunden andere Appliances von Drittanbietern verwenden. Es ist ideal, die Appliance in der Cloud bereitzustellen, anstatt sie On-Premises zu haben.
Kann ich ein Firewall-Subnetz im selben virtuellen Netzwerk wie Azure Databricks haben?
Ja, das können Sie. Gemäß der Azure Referenzarchitektur ist es ratsam, eine Hub-Spoke-Virtual-Network-Topologie zu verwenden, um besser für die Zukunft zu planen. Wenn Sie das Azure Firewall-Subnetz im selben virtuellen Netzwerk wie die Azure Databricks-Arbeitsbereich-Subnetze erstellen, müssen Sie kein Virtual Network Peering konfigurieren, wie in Schritt 6 oben beschrieben.
Kann ich den Azure Databricks Control Plane SCC Relay IP-Verkehr über Azure Firewall filtern?
Ja, das können Sie, aber wir möchten Sie bitten, Folgendes zu beachten:
- Bei Verwendung von Private Endpoints für die Databricks Control Plane bleibt der Datenverkehr zwischen Azure Databricks-Clustern (Dataplane) und dem SCC Relay-Dienst privat über das Azure-Netzwerk und fließt nicht über das öffentliche Internet. Dies ist hauptsächlich Verwaltungsverkehr, um sicherzustellen, dass der Azure Databricks-Arbeitsbereich ordnungsgemäß funktioniert.
- Bei Verwendung von Nicht-Private-Link-Zugriff auf die Databricks Control Plane sind die SCC Relay- und WebUI-CIDR-Bereiche durch den AzureDatabricks-Dienst-Tag abgedeckt. Für andere Firewall-/NVA-Typen siehe die neueste Version von IP-Adressen und Domänen für Azure Databricks-Dienste und -Assets. Wir empfehlen dringend die Verwendung einer Anwendungsregel-FQDN für den SCC-Tunnel in Ihren Firewall-Regelkonfigurationen.
- Der SCC Relay-Dienst und die Datenebene benötigen eine stabile und zuverlässige Netzwerkkommunikation. Eine Firewall oder eine virtuelle Appliance dazwischen einzufügen, schafft einen Single Point of Failure, z. B. bei Fehlkonfigurationen von Firewall-Regeln oder geplanten Ausfallzeiten, was zu übermäßigen Verzögerungen beim Cluster-Bootstrap (vorübergehendes Firewall-Problem) führen kann oder neue Cluster nicht erstellt werden können oder die Planung und Ausführung von Jobs beeinträchtigt.
Kann ich den akzeptierten oder blockierten Datenverkehr von Azure Firewall analysieren?
Ja, für diese Anforderung empfehlen wir die Verwendung von Azure Firewall Logs und Metriken.
Kann ich ein bestehendes Nicht-NPIP (verwaltete Databricks-Bereitstellung) auf eine NPIP- oder PL-fähige Arbeitsbereich-Instanz aktualisieren?
Ja, eine verwaltete Databricks-Bereitstellung kann aktualisiert werden, um eine VNet-Injected-Arbeitsbereich-Instanz zu werden.
Warum benötigen wir zwei Subnetze pro Arbeitsbereich-Instanz?
Eine Arbeitsbereich-Instanz benötigt zwei Subnetze, die allgemein als „Host“ (auch „öffentlich“) und „Container“ (auch „privat“) bekannt sind. Jedes Subnetz stellt eine IP-Adresse für den Host (Azure VM) und den Container (Databricks Laufzeit, auch dbr genannt) bereit, der innerhalb der VM ausgeführt wird.
Haben die öffentlichen oder Host-Subnetze öffentliche IPs?
Nein, wenn Sie eine Arbeitsbereich-Instanz mit Secure Cluster Connectivity (SCC) erstellen, haben keine der Databricks-Subnetze öffentliche IP-Adressen. Es ist nur so, dass der Standardname des Host-Subnetzes public-subnet ist. SCC stellt sicher, dass kein Netzwerkverkehr von außerhalb Ihres Netzwerks in die Databricks-Compute-Instanzen der Arbeitsbereich-Instanz gelangt, z. B. per SSH.
Ist es möglich, die Subnetzgrößen nach der Bereitstellung zu ändern?
Ja, es ist möglich, die Subnetzgrößen nach der Bereitstellung zu ändern. Es ist auch möglich, das virtuelle Netzwerk zu ändern oder die Subnetznamen zu ändern (gated public preview). Bitte wenden Sie sich an den Azure-Support und reichen Sie einen Supportfall für die Größenänderung der Subnetze ein.
Ist es möglich, virtuelle Netzwerke nach der Bereitstellung auszutauschen/zu ändern?
Ja, bitte beachten Sie die öffentlichen Dokumente.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.