Databricks auf der SIGMOD 2026
von Indrajit Roy
- Entdecken Sie, wie Databricks die nächste Generation der Datenverarbeitung mit Spark Declarative Pipelines (SDP) vorantreibt und komplexe ETL- und Streaming-Workloads vereinfacht.
- Erhalten Sie einen detaillierten Einblick in Enzyme, unsere Engine für inkrementelle View-Pflege, die auf der SIGMOD-Konferenz eine lobende Erwähnung erhielt.
- Treffen Sie unsere Ingenieure auf der Konferenz, um diese branchenführenden Innovationen zu besprechen.
Databricks ist weiterhin führend in der technischen Innovation und verschiebt konsequent die Grenzen des Möglichen im Bereich Daten und KI. Wir freuen uns, Ihnen mitteilen zu können, dass unsere Arbeit an Spark Declarative Pipelines auf der SIGMOD 2026 vorgestellt wird und auf der Konferenz eine lobende Erwähnung erhalten hat. Wir sind als Platin-Sponsor auf der SIGMOD vom 1. bis 5. Juni vertreten. Die SIGMOD findet in Bangalore, Indien, statt, einem großen Forschungs- und Entwicklungszentrum von Databricks.
Unsere bevorstehenden Veröffentlichungen zur Datenverarbeitung zeigen, wie Databricks die inkrementelle Verarbeitung für Kunden vereinfacht hat. Es gibt zwei Möglichkeiten, inkrementelle Programme in Spark Declarative Pipelines (SDP) zu schreiben, und Kunden können diese innerhalb einer Pipeline mischen und anpassen:
- Daten-Ingenieure können Materialized Views für Transformationen angeben. Die Enzyme-Engine pflegt diese inkrementell, sobald neue Daten eintreffen. Die gesamte Komplexität der inkrementellen Verarbeitung ist für die Ersteller der Materialized Views vollständig verborgen. Das SIGMOD 2026-Paper „Enzyme: Incremental View Maintenance for Data Engineering“ diskutiert einige dieser Ideen.
- Daten-Ingenieure, die sich gut mit Stream-Verarbeitung auskennen, können stattdessen die Streaming-Engine von SDP verwenden, um Daten inkrementell zu verarbeiten. Die Streaming-APIs bieten eine Vielzahl von Konstrukten – von zustandsbehafteten Operatoren bis hin zu Watermarks –, die es einfach machen, komplexe Geschäftslogik wie benutzerdefinierte Aggregationen auszudrücken. Wichtige Ideen aus unserem Streaming-Produkt werden im VLDB 2026-Paper „A Decade of Apache Spark Structured Streaming: How We Evolved the Architecture To Meet Real-world Needs“ erscheinen.
Hier ist ein erster Einblick in das Enzyme-Paper und woran das Team gearbeitet hat:
Enzyme auf der SIGMOD 2026
Inkrementelle View-Pflege
Nehmen wir an, Sie sind Analyst in einem Unternehmen und möchten die Gesamtzahl der in einer Region verkauften Bestellungen analysieren. Die unten stehende Materialized View liefert die Antwort.
CREATE MATERIALIZED VIEW order_report as
SELECT region, sum(orders)
FROM customer_and_order_table
GROUP by region
Wenn neue Bestellungen hinzugefügt werden, erwarten Sie, dass die Materialized View aktuell bleibt. Diese Datenpflege ist im Wesentlichen das Problem der inkrementellen View-Pflege. Während die Aktualisierung der obigen einfachen MV einfach erscheint, stellen Sie sich vor, die MV müsste Daten aus mehreren Tabellen verknüpfen, Fensterfunktionen enthalten oder Aufrufe von LLM-Funktionen tätigen.
Enzyme-Innovationen
Materialized Views (MVs) sind beliebt für die Abeschleunigung von Abfragen – sie beschleunigen Dashboards auf Daten in Data Warehouses. Bei der Erstellung von Spark Declarative Pipelines haben wir uns entschieden, über die Abeschleunigung von Abfragen hinauszugehen und Materialized Views für Extract-Transform-Load (ETL)-Anwendungsfälle zu verwenden. Unsere wichtigste Erkenntnis ist, dass, wenn MVs effizient und inkrementell gepflegt werden können, dies ETL-Workloads erheblich vereinfacht, die ansonsten das Schreiben komplexen benutzerdefinierten Codes erfordern würden.
Enzyme ergänzt die reiche Literatur zur inkrementellen Pflege von Materialized Views und zeigt, wie diese Techniken für Produktions-Workloads skaliert werden können. Einige der Innovationen, an denen das Team gearbeitet hat, sind:
- Unterstützung für umfangreiche MV-Muster: Enzyme pflegt komplexe MVs in der Produktion inkrementell, einschließlich solcher mit Joins, Fensterfunktionen, Aggregationen und deren Kombinationen. Im Gegensatz zu anderen Branchenlösungen unterstützt Enzyme auch nicht-deterministische Funktionen wie current_date() und KI-spezifische Funktionen.
- Mehrsprachige Unterstützung: Während sich die meisten Branchenlösungen nur auf SQL konzentrieren, unterstützt Enzyme auch MVs, die in Python angegeben sind. Python ist heute die bevorzugte Sprache für die meisten Datenverarbeitungs- und KI-Workloads. Enzyme löst viele interessante Herausforderungen, die die mehrsprachige Unterstützung mit sich bringt, wie z. B. die genaue Erkennung von Änderungen in der MV-Definition.
- Leistungsoptimierungen: Enzyme verfügt über mehrere Optimierungen, um die zu verarbeitende Datenmenge zu reduzieren, einschließlich Techniken, die automatisch bestimmen, ob Updates auf Partitions- statt auf Zeilenebene angewendet werden sollen, wodurch der Aufwand für das Umschreiben reduziert wird. Es speichert Zwischenergebnisse selektiv zwischen, um die E/A-Kosten zu senken. Es verwendet ein Kostenmodell, das Planinformationen und frühere Ausführungen nutzt, um die effizienteste Inkrementalisierungsstrategie zu bestimmen.
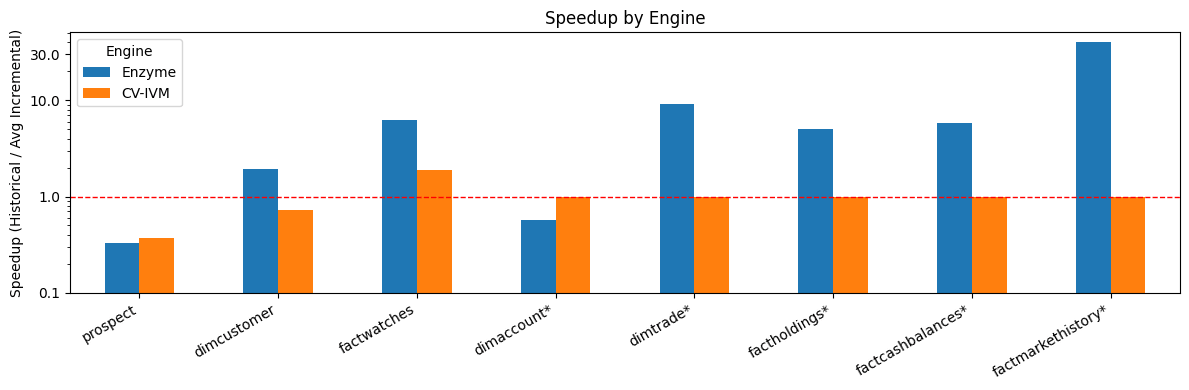
Abbildung 1: Enzyme hat eine deutlich bessere Leistung als eine andere konkurrierende Branchenlösung (Name aufgrund von Lizenzbeschränkungen anonymisiert zu CV-IVM).
Möchten Sie mehr erfahren? Schauen Sie sich das Paper an und besuchen Sie unseren Vortrag auf der SIGMOD für weitere Details.
Treffen Sie das Team auf der SIGMOD:
Besuchen Sie unseren Stand, um das Team zu treffen und mehr über die Innovationen bei Databricks zu erfahren. Verpassen Sie außerdem nicht die Gelegenheit, direkt von Ritwik Yadav während seines Vortrags auf der SIGMOD zu hören!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.