Durch Design entkoppelt: Vektorsuche im Milliardenmaßstab
von Zero Qu, Erik Lindgren, Sheng Zhan, Ankit Vij, Sergei Tsarev und Dima Kotlyarov
Einführung
Die Vektorsuche ist zu einer grundlegenden Infrastruktur für KI-Anwendungen geworden – von der produktspezifischen Suche über Empfehlungssysteme und Entitätsauflösung bis hin zur Retrieval-Augmented Generation. Wenn Datensätze jedoch von Millionen auf Milliarden von Vektoren anwachsen, beginnen die für ihre Bereitstellung entwickelten Systeme auf kostspielige Weise zu versagen: Speicherkosten explodieren, die Aufnahme blockiert die Bereitstellung und für die Skalierung muss alles repliziert werden.
Bei Databricks stießen wir mit unserem ursprünglichen Vektorsuchangebot auf diese Grenzen – also sind wir zu den Grundprinzipien zurückgekehrt und haben es von Grund auf neu entwickelt. Heute bietet Databricks AI Search zwei Bereitstellungsoptionen: Standard -Endpunkte, die Vektoren mit voller Präzision vollständig im Arbeitsspeicher halten für eine Latenz im zweistelligen Millisekundenbereich, und speicheroptimierte Endpunkte, die Speicher und Rechenleistung trennen, um Milliarden von Vektoren zu einem Bruchteil der Kosten bereitzustellen – mit Abfragelatenzen im hunderter Millisekundenbereich, ein bewusster Kompromiss für Workloads, bei denen Kosten und Scale wichtiger sind als Reaktionszeiten im niedrigen Millisekundenbereich.
Speicheroptimierte Vektorsuche wurde von drei zentralen Engineering-Entscheidungen geprägt:
- Speicher von compute trennen. Vektorindizes befinden sich im Cloud-Objektspeicher und werden nur zur Bereitstellung in den Arbeitsspeicher geladen. Die Aufnahme erfolgt auf ephemeren, serverlosen Spark-Clustern, die vollständig vom Abfragepfad isoliert sind.
- Verteilte Indizierungsalgorithmen auf Spark erstellen. Anstatt uns auf Indizierungsbibliotheken für einzelne Maschinen zu verlassen, haben wir unsere eigenen entwickelt – verteiltes Clustering, Vektorkomprimierung und partitionsausgerichtetes Datenlayout – als native Spark-Jobs, die linear mit der Clustergröße skalieren.
- Abfragen von einer Rust-Engine mit einer Dual-Runtime-Architektur bereitstellen. Eine speziell entwickelte Abfrage-Engine verwendet separate Thread-Pools für asynchrone I/O und CPU-gebundene Vektorberechnung, sodass keiner den anderen blockiert.
Das Ergebnis: Milliarden-Vektor-Indizes in unter 8 Stunden erstellt, 20x schnellere Indizierung und bis zu 7x geringere Bereitstellungskosten.
Dieser Beitrag ist die Engineering-Geschichte, wie wir sie entwickelt haben.
Das Problem mit herkömmlichen Vektordatenbanken
Die Grenzen der engen Kopplung
Viele produktionsreife Vektordatenbanken – einschließlich unserer Standard-Vektorsuche – folgen einer Shared-Nothing-Architektur, die von der verteilten Schlagwortsuche übernommen wurde. Jeder Knoten besitzt einen zufälligen Shard des Datasets und verwaltet einen unabhängigen In-Memory-HNSW-Graphen (Hierarchical Navigable Small World) über Vektoren mit voller Präzision. HNSW liefert eine hervorragende Suchqualität, aber der Graph selbst muss vollständig im Arbeitsspeicher liegen, was ihn zu einer der teuersten Komponenten bei der Skalierung macht. Dieses Design bietet eine niedrige Latenz und unterstützt transaktionale Updates. Das funktioniert gut bis zu Hunderten von Millionen von Vektoren.
Bei Milliarden bricht es zusammen.
Das Kernproblem ist die Kopplung. Der Index, die Rohdaten und die compute, die sie bedienen, sind alle an denselben Knoten gebunden. Skalierung bedeutet, alles zu replizieren: Mehr Vektoren erfordern mehr Speicher, was mehr Knoten erfordert, wobei jeder eine vollständige Kopie des Index und der Daten seines Shards enthält. Es gibt keine Möglichkeit, den Speicher unabhängig von compute zu skalieren.
Die Kopplung erstreckt sich auch auf die Ingestion. Die Indexerstellung findet innerhalb der Suchmaschine selbst statt – dieselben Compute-Ressourcen, die Abfragen bearbeiten, übernehmen auch die Datenreorganisation, die Neuerstellung von Indizes und die Kompaktierung. Unter schreibintensiven Workloads verschlechtert sich die Abfragelatenz. Unter abfrageintensiven Workloads verlangsamt sich die Ingestion bis zum Stillstand. Schlimmer noch, jede Datenänderung – ein Upsert, ein Delete, eine Kompaktierung – löst die Neuerstellung von Teilindizes aus, wodurch CPU-Zyklen für die Wartung verbraucht werden, anstatt für die Bearbeitung von Abfragen.
Speicherresidente Indizes sind teuer
Diese Speicherung im Arbeitsspeicher macht die Architektur schnell – und teuer. Bei 768 Dimensionen mit 32-Bit-Floats verbrauchen 100 Millionen Vektoren etwa 286 GiB RAM, nur für die Vektoren, vor jeglichem Index-Overhead. Eine Milliarde Vektoren würden Terabytes erfordern. Im Gegensatz zu Festplatten- oder Objektspeichern, bei denen die Kosten pro Gigabyte vernachlässigbar sind, ist der Arbeitsspeicher die teuerste Ressource im Stack. Jeder hinzugefügte Vektor erhöht direkt die RAM-Kosten.
Zufälliges Sharding verschärft das Problem. Da Vektoren ohne Rücksicht auf semantische Ähnlichkeit verteilt werden, muss jede Abfrage auf alle Shards verteilt werden und die Ergebnisse zusammenführen, unabhängig davon, wie relevant die einzelnen Shards sind. CPU-, Netzwerk-Overhead und Tail-Latency nehmen mit der Anzahl der Shards zu. Das Hinzufügen von Vektoren bedeutet das Hinzufügen von Shards, und jeder neue Shard enthält seinen eigenen speicherresidenten Index.
Entkoppelt durch Design
Die Lösung besteht nicht darin, innerhalb dieser Architektur zu optimieren, sondern darin, die Kopplung selbst aufzuheben.
Die speicheroptimierte Vektorsuche geht von einer einzigen Prämisse aus: Alle Daten befinden sich im Cloud-Objektspeicher und die Abfrageknoten sind zustandslos. Dies teilt das System entlang zweier Grenzen – Speicher von Compute, sodass Query-Knoten keine Daten besitzen; Ingestion von Bereitstellung, sodass die Erstellung von Indizes niemals mit Live-Queries konkurriert – und führt zu einer dreischichtigen Architektur:
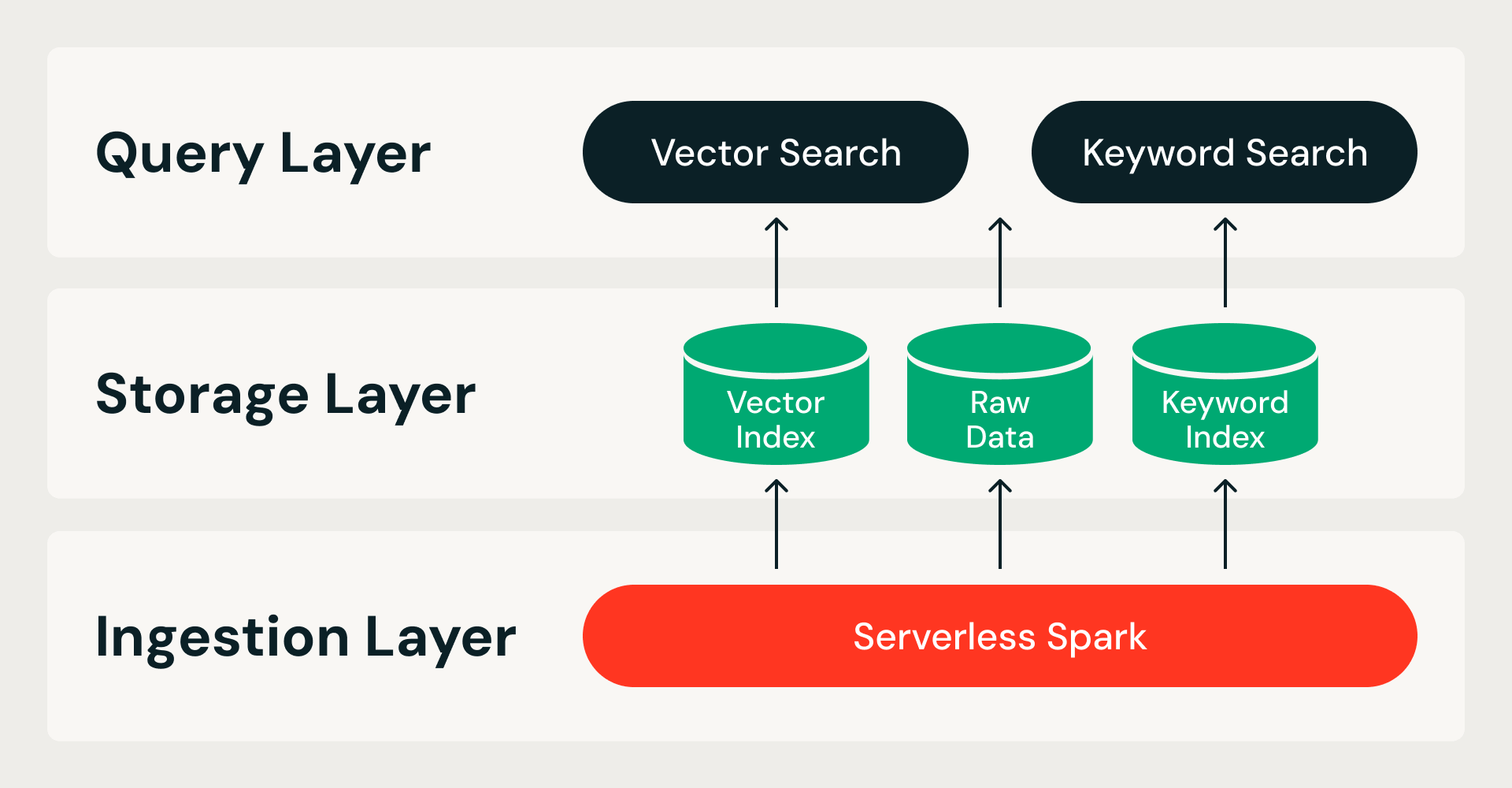
- Ingestion-Schicht. Eine verteilte Pipeline auf Serverless Spark übernimmt den gesamten Indexaufbau, von den Rohdaten bis zum fertigen Index. Jede Ausführung ist idempotent und wiederholbar.
- Speicherschicht. Ein benutzerdefiniertes, cloudnatives Speicherformat dient als Aufzeichnungssystem. Es kombiniert ein spaltenorientiertes Dateiformat für Rohdaten und Vektor-Indizes mit einem invertierten Indexformat für die Schlagwortsuche – alles unter ACID-Transaktionen mit unveränderlichen Datenfragmenten.
- Abfrageebene. Zwei zustandslose Dienste übernehmen Lesezugriffe. Der Vektorsuchdienst hält einen komprimierten Index im Arbeitsspeicher und ruft bei Bedarf Daten mit voller Präzision aus dem Objektspeicher ab. Die Schlagwortsuche stellt invertierte Indizes für die Metadatenfilterung und Schlagwortsuche bereit. Beide Dienste skalieren unabhängig voneinander, sodass die Ressourcen an den Workload angepasst werden können.
Eine Indexstruktur für Objektspeicher
Wenn Daten in einem Objektspeicher liegen, muss der Index partitionierbar sein – die Abfrage-Engine muss nur die relevanten Slices abrufen und nicht die gesamte Struktur in den Speicher laden.
HNSW-Graphen haben diese Eigenschaft nicht. Jeder Suchsprung kann an eine beliebige Stelle im Graphen springen, daher muss die gesamte Struktur im Arbeitsspeicher vorhanden sein, um eine einzelne Abfrage zu bedienen. Es gibt keine natürliche Möglichkeit, einen HNSW-Graphen in Fragmente aufzuteilen, die auf Objektspeicherdateien abgebildet werden.
IVF (Inverted File Index) verfolgt einen anderen Ansatz: Es clustert Vektoren nach Nähe um gelernte Zentroide und durchsucht zur Abfragezeit nur die nächstgelegenen Cluster. Jeder Cluster wird direkt auf ein Datenfragment im Objektspeicher abgebildet – unabhängig abrufbar, ohne den Rest des Index zu laden.
Diese Algorithmuswahl ergibt sich direkt daraus, wo die Daten gespeichert sind. Die Standard-Vektorsuche hält den vollständigen Index aus Geschwindigkeitsgründen im Speicher, was Speicher und Rechenleistung miteinander verbindet. Die speicheroptimierte Suche verschiebt Daten zur Scale in den Objektspeicher, was diese voneinander trennt – erfordert aber einen Index, der sich in eigenständige, abrufbare Partitionen zerlegen lässt. IVF bietet genau das:
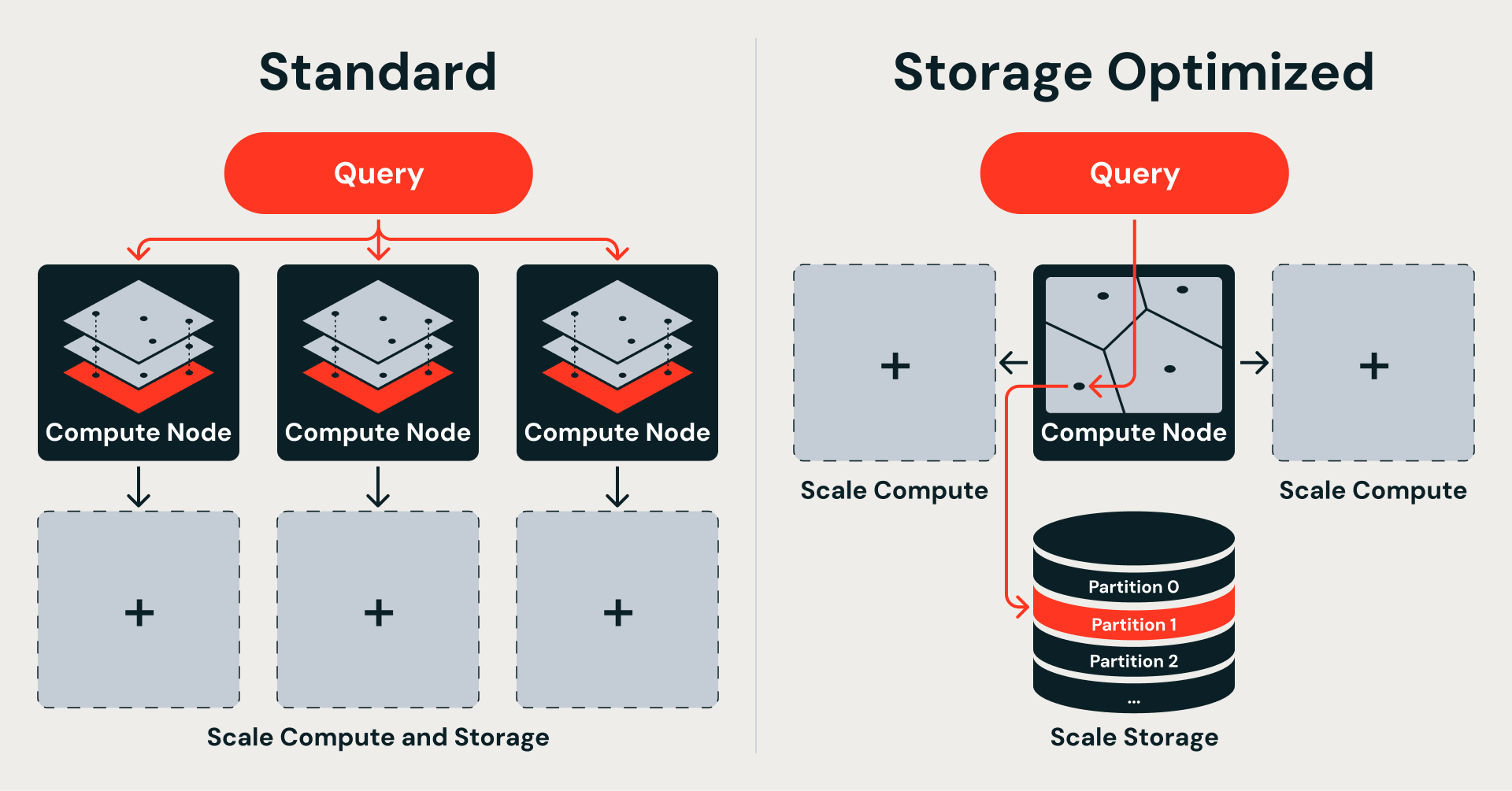
Verteilte Vektorindizierung auf Spark
IVF gibt uns die richtige Indexstruktur für getrennten Speicher. Die Engineering Herausforderung ist die Erstellung in Scale. Die meisten Vektorindexierungsbibliotheken – FAISS, ScaNN, Annoy – gehen davon aus, dass alle Ihre Daten auf eine einzige Maschine passen. Das funktioniert bei zig Millionen von Vektoren. Bei einer Milliarde Vektoren mit 768-dimensionalen Embeddings hat man es mit Terabytes an rohen Gleitkommadaten zu tun, noch bevor man überhaupt mit der Indexerstellung startet. Keine einzelne Maschine kann das reibungslos bewältigen, und selbst wenn, wird Ihre Ingestionszeit zu einem seriellen Engpass, der mit jeder neuen Zeile wächst.
Wir benötigten eine Indexierung, die horizontal skaliert. Also haben wir jeden Indexierungsalgorithmus von Grund auf neu implementiert – verteiltes K-Means, Product Quantization und partition-aligned Data Layout – als native PySpark-Jobs, die auf ephemeren serverlosen Spark-Clustern ausgeführt werden. Keine Single-Machine-Indexierungsbibliotheken im kritischen Pfad. Das Hinzufügen von weiteren Executors reduziert linear die Zeit für die aufwendigsten Schritte.
Die Ingestion-Pipeline
Jeder Ingestion-Lauf wird als gerichteter azyklischer Graph von Stufen ausgeführt, der in eine ACID-Transaktion eingebettet ist.
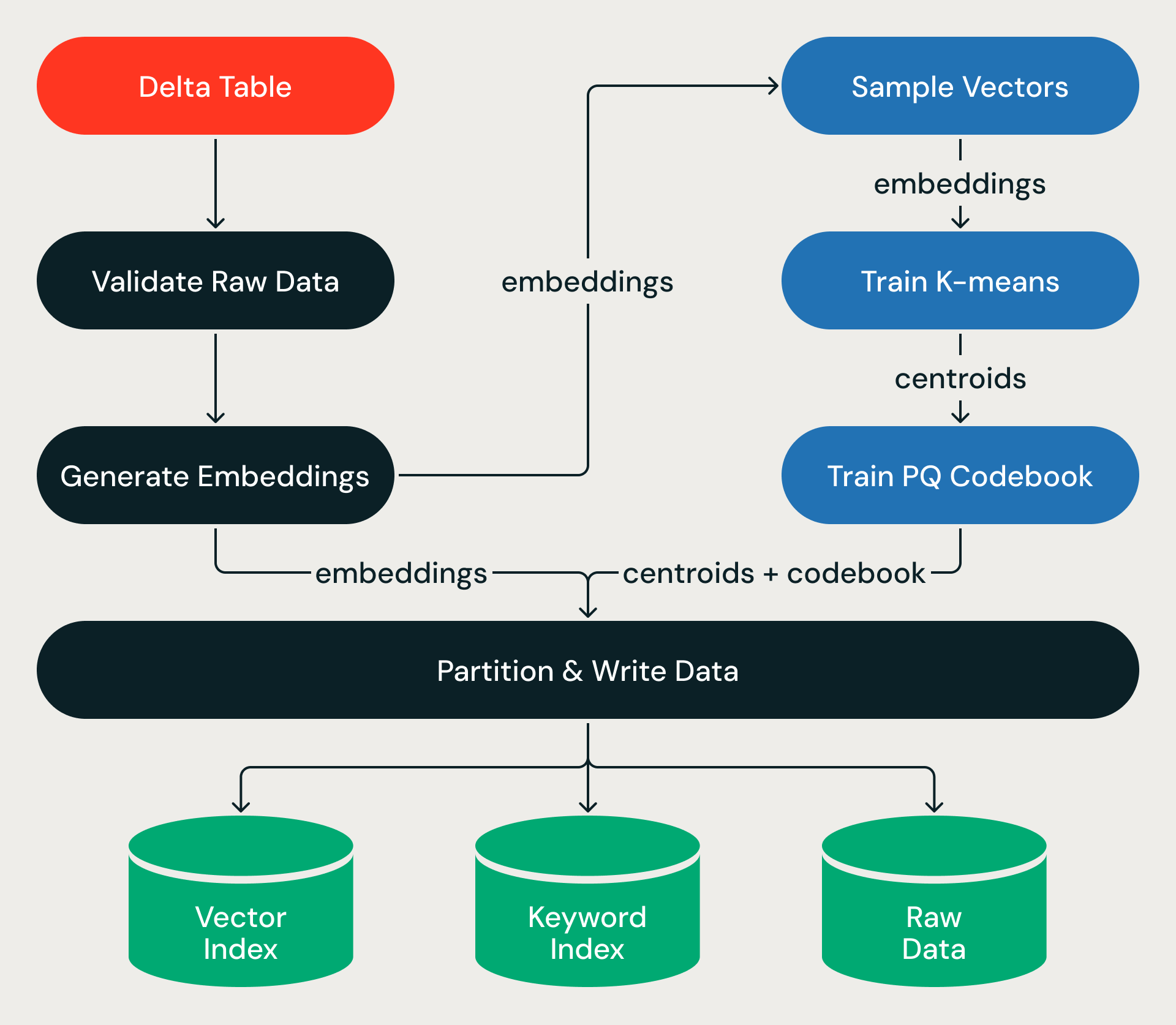
Die Pipeline startet mit einer Quell- Delta-Tabelle. Für Indizes, die auf Quelltext basieren (anstelle von vorab berechneten Vektoren), ruft die Pipeline nach der Validierung der Quelldaten Databricks Model Serving auf, um Vektor-Embeddings für neue oder aktualisierte Zeilen zu generieren – und wandelt so Milliarden von Textdatensätzen in großem Scale in hochdimensionale Vektoren um.
Von dort aus trainiert die Pipeline mit einer kleinen Stichprobe – um die Struktur des Vektorraums zu lernen – und wendet diese Struktur dann auf das gesamte Dataset an, indem sie jeden Vektor einer Partition zuweist, ihn komprimiert und die Ergebnisse in den Objektspeicher schreibt. Das Training ist günstig; der Durchlauf über das gesamte Dataset, bei dem Terabytes an Daten über Executors verteilt werden, ist der Teil, der die meiste Zeit in Anspruch nimmt.
K-means: Partitionierung im großen Maßstab
K-Means-Clustering partitioniert den Vektorraum in Regionen – die IVF-Partitionen, die es ermöglichen, dass Abfragen einen Bruchteil der Daten anstelle der Gesamtheit durchsuchen. Für ein Billionen-Zeilen-Dataset erstellen wir etwa 32.000 Partitionen. Die Frage ist: Wie führt man K-Means in diesem Scale aus, wenn die Standardimplementierungen davon ausgehen, dass alle Daten auf eine einzige Maschine passen?
Sie erstellen es von Grund auf auf Spark.
Unsere Implementierung verwendet ein Hybridmodell: Spark übernimmt die verteilte Datenbewegung, während JAX – eine numerische Berechnungsbibliothek mit hardwarebeschleunigter linearer Algebra – die Mathematik innerhalb jedes Executors übernimmt. Jede K-Means-Iteration ist eine dreistufige Spark-Pipeline:
- Zuweisen – jeder Executor berechnet die Abstände von seinem lokalen Vektor-Batch zu allen aktuellen Zentroiden und findet so den nächstgelegenen Cluster für jeden Vektor.
- Shuffle – Spark partitioniert die Daten nach der Centroid-ID neu und platziert alle Vektoren, die demselben Cluster zugewiesen sind, am selben Ort.
- Aggregieren — jeder Executor berechnet neue Zentroide-Positionen aus seinen gemeinsam platzierten Vektoren.
Die Distanzberechnung ist die „Hot Loop“. JAX kompiliert sie in eine einzige Batch-Matrix-Operation pro Executor – wobei die gesamte Batch-nach-Zentroid-Distanzmatrix auf einmal berechnet wird, anstatt über einzelne Vektoren zu iterieren.
Das Training wird auf einer Stichprobe durchgeführt, nicht auf dem gesamten Dataset – bei einer Milliarde Zeilen sind das etwa 8 Millionen Vektoren (~0,8 % der Daten). Das ist nicht willkürlich: Die Kosten pro Iteration von K-Means betragen O(n × k × d), wobei n die Stichprobengröße, k die Anzahl der Cluster und d die Dimension ist. Wenn man sowohl n als auch k proportional zu √N setzt, betragen die gesamten Trainingskosten O(N × d) – linear zur Dataset-Größe, unabhängig von der Scale.
Diese Wahl ist auch statistisch fundiert: Die Coreset-Theorie zeigt, dass O(k)-Stichproben für hochwertiges K-Means-Clustering auf gut verteilten Daten ausreichen, und da k mit √N skaliert, ist unsere Stichprobengröße nachweislich angemessen. Das Training ist in wenigen Iterationen abgeschlossen und speichert die Zentroide als Checkpoints im Objektspeicher für die nachgelagerten Pipeline-Phasen.
Produktquantisierung: 64-fache Speicherkomprimierung
K-Means liefert uns grobe Partitionen. Die Produktquantisierung (PQ) komprimiert die Vektoren, damit wir sie auch im großen Scale durchsuchen können. Die Idee: jeden 768-dimensionalen Vektor in 48 Teilvektoren mit jeweils 16 Dimensionen aufteilen und jeden Teilvektor durch ein einzelnes Byte ersetzen, das auf den nächstgelegenen Eintrag in einem gelernten Codebuch verweist. Ein 3.072-Byte-Vektor wird zu 48 Byte – ein Kompressionsverhältnis von 64x. Für eine Milliarde 768-dimensionale Vektoren reduziert das fast 3 TiB an Rohdaten auf etwa 45 GiB.
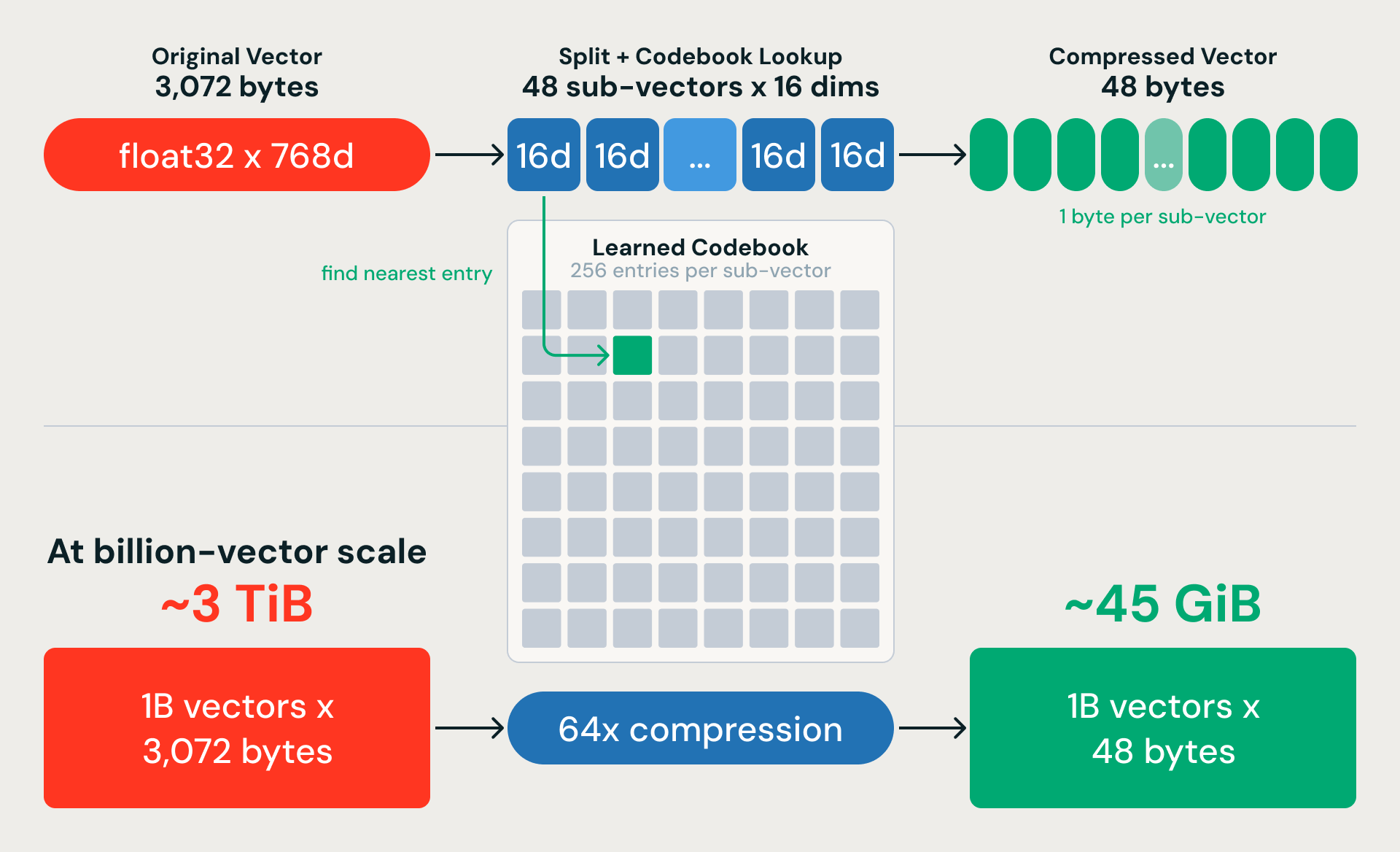
Die Komprimierung ist verlustbehaftet, aber eine wichtige Designentscheidung stellt den größten Teil der Genauigkeit wieder her: Wir trainieren PQ auf Residualvektoren (der Differenz zwischen jedem Embedding und seinem nächstgelegenen K-Means-Zentroid) anstatt auf den rohen Embeddings. K-Means erfasst die grobe Struktur; PQ muss nur die feinkörnige Variation innerhalb jeder Partition kodieren.
Vom Training zur Speicherung
Mit den auf der Stichprobe trainierten Zentroiden und PQ-Codebüchern verarbeitet die Pipeline nun jede Zeile – wobei jedem Vektor eine Partitions-ID (sein nächstgelegener Zentroid) und ein komprimierter PQ-Code zugewiesen wird. Bei einem Dataset mit einer Milliarde Zeilen ist dies die datenintensivste Phase der Pipeline – ein Spark-Job für das gesamte Dataset, der Distanzen und Kodierungen auf jedem Executor berechnet.
Dann kommt der Shuffle. Die Pipeline partitioniert das gesamte Dataset nach Partitions-ID neu und platziert Vektoren aus derselben IVF-Partition physisch in denselben Datenfragmenten im Objektspeicher. Das ist aufwendig – Terabytes an Daten werden zwischen Executoren verschoben –, aber genau das macht Abfragen schnell. Ohne gemeinsame Platzierung würde das Abfragen einer einzelnen IVF-Partition Lesezugriffe auf Tausende von Dateien verteilen. Damit trifft dieselbe Abfrage auf eine Handvoll zusammenhängender Fragmente.
Der Schreibvorgang erzeugt drei Ausgaben, die jeweils für einen anderen Abfragepfad optimiert sind:
- Vektorindex – komprimierte PQ-Codes und Partitionsmetadaten, geschrieben in einem Format, das die Abfrage-Engine für eine schnelle KNN-Suche in den Arbeitsspeicher lädt.
- Schlagwortindex – invertierte Indexdateien für die Metadatenfilterung und hybride Schlagwortsuche.
- Rohdaten – Embeddings mit voller Präzision, die in einem spaltenorientierten Format gespeichert sind, das sowohl für sequenzielle Scans als auch für wahlfreien Zugriff optimiert ist und bei Bedarf während des Re-Ranking abgerufen wird.
Alle drei werden als unveränderliche Fragmente geschrieben – einmal geschrieben, nie wieder geändert. Wenn der Schreibvorgang abgeschlossen ist, veröffentlicht ein Versionsmanifest atomar den neuen Index. Das ist der Vertrag zwischen Ingestion und Serving: ein Satz unveränderlicher, partitionsausgerichteter Datenfragmente im Objektspeicher, die von der Query-Engine direkt gelesen werden können.
Datenaufnahme im großen Scale
„Storage Optimized“ unterstützt Indizes von über einer Milliarde Vektoren mit 768 Dimensionen – eine sprunghafte Veränderung gegenüber „Standard AI Search“, das auf 320 Millionen Vektoren begrenzt ist.
Da die Ingestion auf ephemeren Spark-Clustern läuft und vollständig vom Serving entkoppelt ist, ist die Skalierung eine Frage des Hinzufügens von Executors. In der Praxis führt dies zu Verbesserungen um Größenordnungen bei der Erstellung von Produktionsindizes:

Nachdem der Index geschrieben und atomar im Objektspeicher veröffentlicht wurde, ist die nächste Frage: Wie führt man Abfragen dagegen schnell genug für die Produktion aus?
Eine Abfrage-Engine für Objektspeicher
Die Trennung von Speicher und Compute löst das Kostenproblem. Aber es führt zu einem neuen Problem: Jede Abfrage erfordert jetzt Netzwerk-Roundtrips zum Objektspeicher. Der komprimierte Index – klein genug, um in den Speicher zu passen – wird beim startup geladen, aber Embeddings mit voller Präzision bleiben im Blob-Speicher und werden bei Bedarf abgerufen oder aus einem lokalen Festplatten-Cache bereitgestellt. Die Bereitstellungsebene muss schnell genug sein, sodass das Verlagern von Daten aus dem Knoten die Abfragelatenz nicht beeinträchtigt.
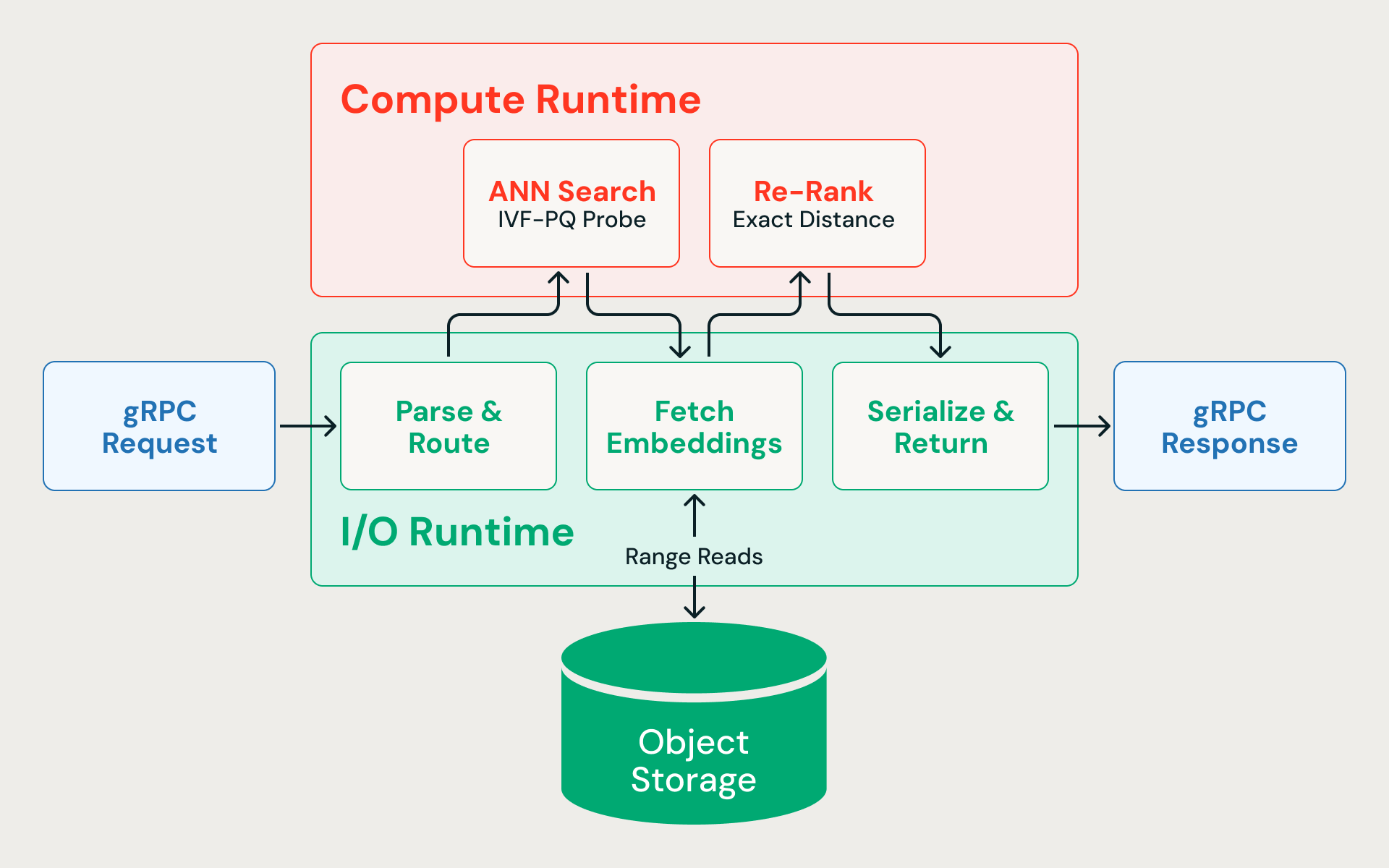
Anatomie einer Abfrage
Folgendes passiert, wenn eine Nächste-Nachbarn-Suche die Engine erreicht:
- Parsen & Routen (E/A). Die gRPC-Anfrage kommt in der asynchronen E/A-Laufzeitumgebung an, wird deserialisiert und an den richtigen Index weitergeleitet.
- KNN-Suche (CPU). Der Query-Vektor wird mit den IVF-Cluster-Zentroiden verglichen, um die relevantesten Partitionen zu identifizieren. Nur diese Partitionen werden untersucht, wobei komprimierte Vektoren gescannt werden, um ungefähre Abstände zu berechnen. Die Suche ruft absichtlich zu viele Kandidaten ab – zum Beispiel werden 400 abgerufen, wenn der Aufrufer 10 anfordert –, weil quantisierte Abstände nur Annäherungswerte sind und ein breiteres anfängliches Netz den endgültigen Recall nach dem Re-Ranking verbessert.
- Vektoren mit voller Präzision abrufen (E/A). Gleichzeitige Lesevorgänge von Byte-Bereichen rufen die rohen Einbettungen für jeden Kandidaten aus dem Cloud-Speicher ab. Da die Ingestion-Pipeline Zeilen aus derselben IVF-Partition im selben Datenfragment platziert, sind diese Lesevorgänge partitionsbereinigt – sie greifen auf eine kleine Anzahl von Dateien zu und nicht per Zufallszugriff auf dem gesamten Dataset. Dieser Schritt dominiert die End-to-End-Latenz.
- Re-Rank (CPU). Die Embeddings mit voller Präzision werden mittels exakter Distanzberechnung bewertet, wodurch die durch Komprimierung verlorene Genauigkeit wiederhergestellt wird.
- Serialisieren & zurückgeben (I/O). Die endgültigen Top-N-Ergebnisse werden mit ihren zugehörigen Metadaten serialisiert und an den Aufrufer zurückgesendet.
Jede Abfrage wechselt zwischen asynchroner I/O und CPU-gebundener Berechnung. Wenn Distanzberechnungen die asynchrone Laufzeitumgebung blockieren, stauen sich ausstehende Lesevorgänge vom Speicher und die Latenz steigt sprunghaft an.
Zwei Runtimes
Die Lösung besteht darin, sie niemals um dieselben Threads konkurrieren zu lassen. Die Abfrage-Engine – in Rust geschrieben für vorhersagbare Latenz ohne GC-Pausen – teilt die Ausführung auf zwei dedizierte Thread-Pools auf: einen für asynchrone I/O, einen für CPU-gebundene Vektormathematik. Keine der beiden Arbeitslasten kann die andere blockieren.
Die I/O-Laufzeitumgebung läuft auf dem asynchronen Executor von Tokio und übernimmt das Parsen von gRPC-Anfragen, Bereichslesezugriffe auf den Blob-Speicher, die Kommunikation zwischen Diensten und die Serialisierung von Antworten. Da Lesevorgänge aus dem Speicher der Latenz-Engpass sind, muss diese Laufzeitumgebung Hunderte von gleichzeitigen Anfragen aktiv halten, ohne zu blockieren.
Die Compute-Laufzeit führt Berechnungen von Vektorabständen, Partitionsprüfungen und Neusortierungen in ihrem eigenen Thread-Pool durch. Eine Teilmenge der CPU-Kerne ist explizit für die I/O-Laufzeit reserviert – Compute darf niemals die gesamte Maschine beanspruchen.
Lese-Coalescing
Über die Thread-Isolierung hinaus musste auch der I/O-Pfad selbst optimiert werden. Frühes Profiling ergab, dass die Engine viele kleine Bereichslesevorgänge für einzelne Vektoren im Objektspeicher durchführte. Jeder Aufruf bringt einen Overhead pro Anfrage und eine Latenzvariabilität mit sich – mit langen Ausläufern, die Hunderte von Millisekunden erreichen –, sodass viele winzige Anfragen eine hohe Latenzvarianz pro Abfrage bedeuteten.
Die Lösung war Read Coalescing: Anstatt einen Bereichslesevorgang pro Vektor auszuführen, sortiert die Speicherschicht ausstehende Byte-Bereichs-Anfragen nach Datei-Offset und mergt alle, die in ein konfigurierbares Blockgrößenfenster fallen, zu einem einzigen Lesevorgang. Weniger, dafür größere Anfragen bedeuten weniger Overhead pro Aufruf, aber jeder zusammengeführte Lesevorgang ruft auch Bytes ab, die die Abfrage nicht benötigt – eine Read Amplification. Der Kompromiss erforderte eine empirische Feinabstimmung.
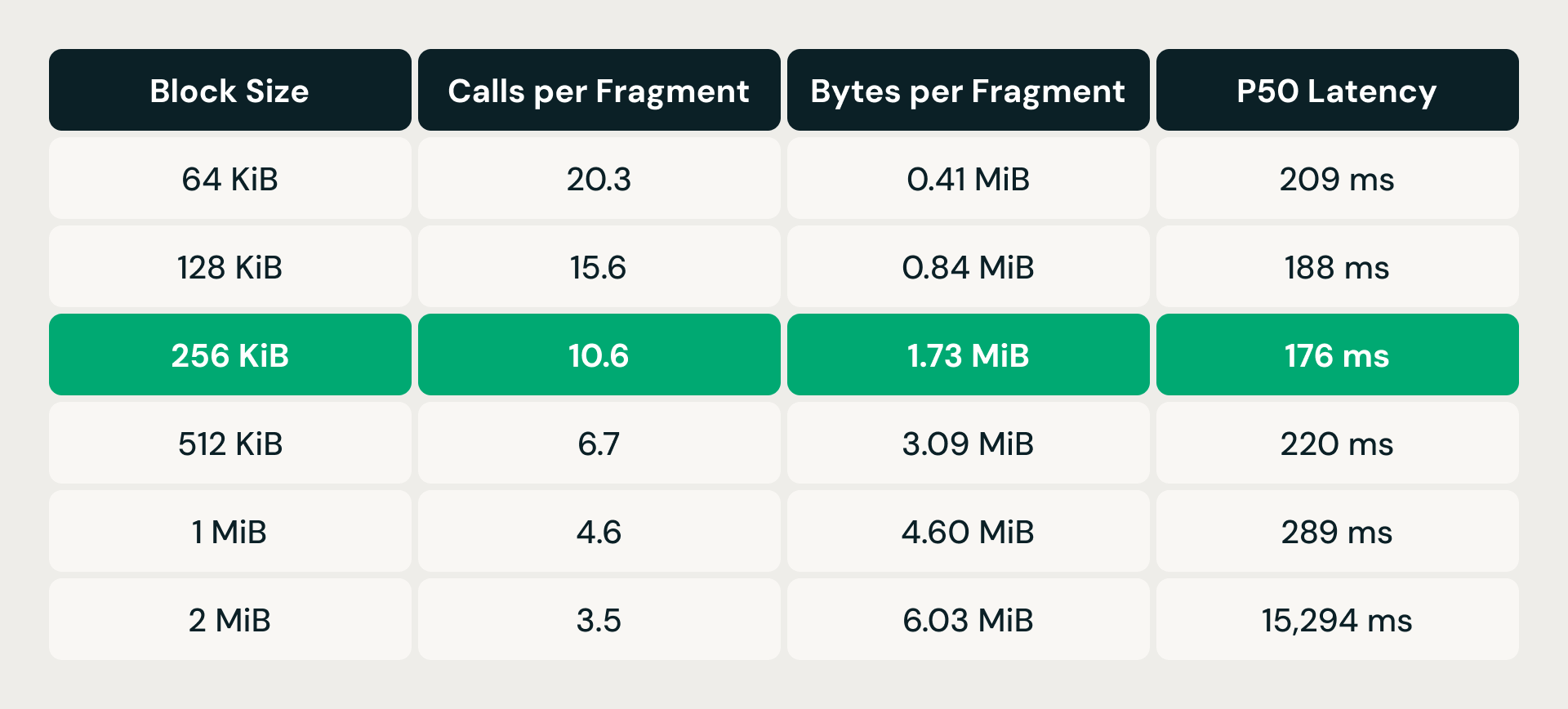
Bei 64 KiB erforderte jedes Datenfragment über 20 Speicheraufrufe, rief aber weniger als ein halbes Megabyte ab – der pro-Anfrage-Overhead dominierte. Die Verdopplung der Blockgröße reduzierte die Anzahl der Aufrufe stetig, und die Latenz verbesserte sich bis 256 KiB. Aber über diesen Punkt hinaus setzte die Leseverstärkung ein: Bei 512 KiB stieg die Latenz trotz weitaus weniger Aufrufen wieder über die 64-KiB-Basislinie. Bei 2 MiB explodierte sie auf über 15 Sekunden. Der Sweet Spot von 256 KiB halbierte die Aufrufe in etwa und hielt gleichzeitig die Leseverstärkung unter 2 MiB pro Fragment, was die niedrigste p50-Latenz aller getesteten Konfigurationen lieferte.
Zusammenfassung
Alles in dieser Architektur tauscht Abfragelatenz gegen Scale und Kosten ein. Bei 768 Dimensionen und Top-10-Ergebnissen bleibt der Recall – der Anteil der zurückgegebenen wirklich nächsten Nachbarn – bei 10 Millionen Vektoren über 94 %, bei 100 Millionen über 91 % und hält sich selbst bei einer Milliarde bei 90 %: Der Re-Ranking-Schritt, der Vektoren mit voller Präzision aus dem Objektspeicher abruft und exakte Abstände neu berechnet, stellt die Genauigkeit wieder her, die komprimierte Codes allein bei Scale verlieren würden. Dieser Re-Ranking-Roundtrip dominiert auch die Query-Zeit – Queries werden bei 10 Mio. Vektoren in etwa 300 Millisekunden und bei einer Milliarde in etwa 500 Millisekunden zurückgegeben, verglichen mit 20–50 Millisekunden bei Standard-Endpunkten, die alles im Arbeitsspeicher halten.
Das bekommen Sie für diese zusätzlichen Millisekunden: Index-Builds im Milliarden-Vektor-Scale sind in unter 8 Stunden abgeschlossen, 20x schneller als Standard bei großen Datasets. Produkt Quantization komprimiert den In-Memory-Footprint um mehr als eine Größenordnung, die Ingestion läuft auf ephemeren Spark-Clustern, die nach jedem Build Ressourcen freigeben, und die Entkopplung von Speicherung und Bereitstellung bedeutet, dass keine Seite überprovisioniert ist. Das Ergebnis sind bis zu 7x geringere Kosten für Kunden bei gleichem Scale.
Für viele Workloads – semantische Suche, Empfehlungspipelines, Retrieval-Augmented Generation – begünstigt dieser Kompromiss klar Scale und Kosten. Nachgelagerte Abrufstufen (Ranking, Filterung, LLM-Generierung) dominieren oft die End-to-End-Zeit, wodurch der Unterschied zwischen 40 und 400 Millisekunden für den Endbenutzer unsichtbar wird. Für latenzempfindliches Serving, bei dem jede Millisekunde zählt, bleibt Standard AI Search das bessere Werkzeug. Die beiden Optionen ergänzen sich — unterschiedliche Werkzeuge für unterschiedliche Workloads.
Was wir gelernt haben
Ein Vektorsuchsystem von Grund auf neu zu entwickeln – anstatt das vorhandene zu optimieren – erzwang eine Reihe von Wetten, die sich nur in Kombination auszahlen.
Die Trennung von Speicher und compute funktioniert nur, wenn die Abfrage-Engine schnell genug ist. Das Verlagern von Daten aus dem Knoten spart Geld, aber es fügt jeder Abfrage I/O hinzu – seien es Netzwerk-Roundtrips zum Objektspeicher oder Lesevorgänge aus einem lokalen Festplatten-Cache. Die Dual-Runtime-Rust-Engine dient speziell dazu, diese Latenz zu absorbieren: Asynchrone E/A hält Hunderte von Lesevorgängen gleichzeitig aktiv, während CPU-Threads die Distanzberechnung ohne Blockieren durchführen. Ohne diese Engine würde die Architektur günstigen Speicher und langsame Abfragen liefern – kein überzeugender Kompromiss.
Verteilte Indexierung funktioniert nur, wenn das Indexformat sie unterstützt. Die Erstellung von K-Means und PQ auf Spark ermöglicht uns eine horizontale Scale für die Ingestion, aber die Ausgabe muss etwas sein, das die Abfrage-Engine direkt aus dem Objektspeicher ohne einen Rebuild-Schritt bereitstellen kann. Das benutzerdefinierte Speicherformat – unveränderliche Datenfragmente, getrennte Transaktionsmanifeste, ACID-Semantik im Cloud-Speicher – schließt diesen Kreislauf. Die Ingestion schreibt direkt in das Format, das die Abfrage-Engine liest.
Komprimierung ist der wirtschaftliche Hebel. Produktquantisierung reduziert nicht nur die Speicherkosten. Sie verändert die Rentabilität der Architektur. Ohne dieses Komprimierungsniveau würde die Speicherung quantisierter Codes für eine Milliarde Vektoren im Arbeitsspeicher immer noch Terabytes an RAM erfordern, und der Kostenvorteil gegenüber der Standard-Vektorsuche würde verschwinden. PQ ermöglicht es, die KNN-Suchphase im Arbeitsspeicher zu halten, während alles andere in den Objektspeicher verschoben wird.
Dies sind keine unabhängigen Optimierungen. Entfernt man eine davon, kostet das System entweder zu viel, wird zu langsam erstellt oder ist für die praktische Anwendung zu langsam in der Bereitstellung.
Fazit
Die kommenden Herausforderungen ergeben sich direkt aus diesen Abwägungen. Die Abfrage-Performance weiter steigern – schnellere Antworten, höherer Durchsatz, bessere Gleichzeitigkeit – durch intelligenteres Caching, gestuften Speicher und dichtere In-Memory-Darstellungen. Updates nahezu in Echtzeit im Milliarden-Scale. Über die reine Vektordistanz als finales Ranking-Signal hinausgehen – hin zu einem gelernten, mehrstufigen Ranking, das Vektorähnlichkeit, Schlagwort-Relevanz und Domänenkontext zu Ergebnissen kombiniert, die nicht nur die nächstgelegenen, sondern die nützlichsten sind.
Wir glauben, dass die nächste Generation von KI-Produkten auf einer Infrastruktur aufbauen wird, die noch nicht erfunden wurde – und dass die Ingenieure, die diese Infrastruktur entwickeln, gestalten werden, was KI leisten kann. Wenn Sie einer von ihnen sein möchten, bauen Sie mit uns!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.