Delta UniForm: ein universelles Format für Lakehouse-Interoperabilität
von Bilal Obeidat, Sirui Sun, Adam Wasserman, Susan Pierce, Fred Liu, Ryan Johnson und Himanshu Raja
Update: BigQuery bietet jetzt native Unterstützung für Delta Lake über BigLake. Weitere Informationen finden Sie in der Dokumentation.
Eine der größten Herausforderungen für Unternehmen bei der Einführung des offenen Data Lakehouse ist die Auswahl des optimalen Formats für ihre Daten. Unter den verfügbaren Optionen sind Linux Foundation Delta Lake, Apache Iceberg und Apache Hudi allesamt hervorragende Speicherformate, die Daten-Demokratisierung und Interoperabilität ermöglichen. Jedes dieser Formate ist besser, als Ihre Daten in einem proprietären Format abzulegen. Die Wahl eines einzigen Speicherformats zur Standardisierung kann jedoch eine entmutigende Aufgabe sein, die zu Entscheidungsermüdung und der Angst vor irreversiblen Folgen führen kann.
Delta UniForm (kurz für Delta Lake Universal Format) bietet eine einfache, leicht zu implementierende und nahtlose Vereinheitlichung von Tabellenformaten, ohne zusätzliche Datenkopien oder Silos zu erstellen. In diesem Blog behandeln wir Folgendes:
- Eine Einführung in Delta UniForm und seine Vorteile
- Lesen von Delta UniForm als Iceberg-Tabellen mit
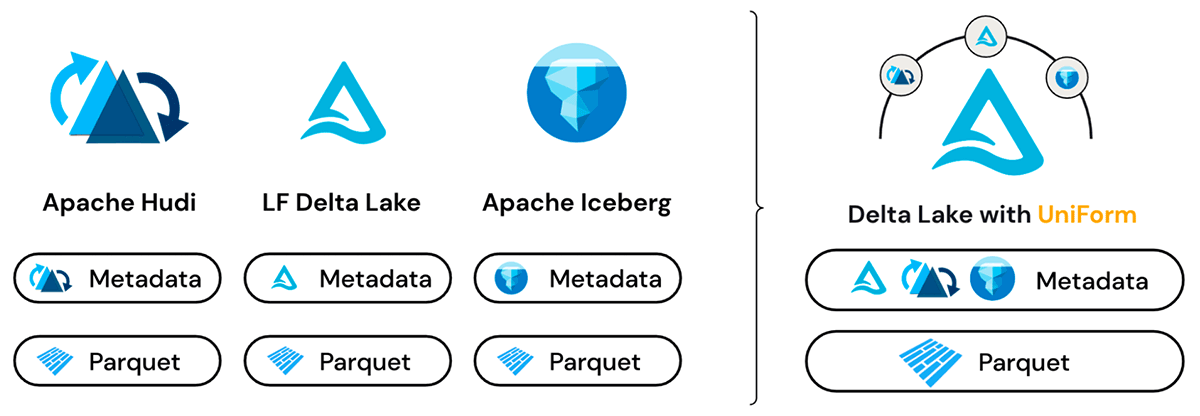
Mehrere Formate, eine einzige Datenkopie
Delta UniForm nutzt die Tatsache, dass Delta Lake, Iceberg und Hudi alle auf Apache Parquet-Datendateien basieren. Der Hauptunterschied zwischen den Formaten liegt in der Metadatenschicht, und selbst dort sind die Unterschiede subtil. Die Metadaten für alle drei Formate dienen demselben Zweck und enthalten überlappende Informationssätze.
Vor der Veröffentlichung von Delta UniForm waren die Möglichkeiten zum Wechseln zwischen offenen Tabellenformaten kopier- oder konvertierungsbasiert und boten nur eine Momentaufnahme der Daten. Im Gegensatz dazu löst Delta UniForm Interoperabilitätsanforderungen eleganter, indem es eine Live-Ansicht der Daten für alle Leser bereitstellt, unabhängig vom Format.
Unter der Haube generiert Delta UniForm automatisch die Metadaten für Iceberg und Hudi neben Delta Lake – alles auf Basis einer einzigen Kopie der Parquet-Daten. Infolgedessen können Teams das am besten geeignete Tool für jede Daten-Workload verwenden und alle auf einer einzigen Datenquelle arbeiten, mit perfekter Interoperabilität zwischen den drei verschiedenen Ökosystemen.
Schnelle Einrichtung, minimaler Overhead
Delta UniForm ist extrem einfach einzurichten und funktioniert nach der Aktivierung nahtlos und automatisch.
Zuerst erstellen wir eine Delta UniForm-Tabelle, um Iceberg-Metadaten zu generieren:
Bei Delta UniForm-Tabellen werden die Metadaten für die zusätzlichen Formate automatisch bei der Tabellenerstellung erstellt und bei jeder Änderung der Tabelle aktualisiert. Das bedeutet, dass keine manuellen Aktualisierungsbefehle oder unnötige Rechenleistung zum Übersetzen von Tabellenformaten erforderlich sind. Schreiben wir zum Beispiel eine Zeile in diese Tabelle:
Dieser Befehl löst einen Delta Lake-Commit aus, der dann automatisch und asynchron die Iceberg-Metadaten für diese Tabelle generiert. Dadurch stellt Delta UniForm sicher, dass Datenpipelines unterbrechungsfrei laufen, und ermöglicht allen Lesern den nahtlosen Zugriff auf die aktuellsten Informationen.
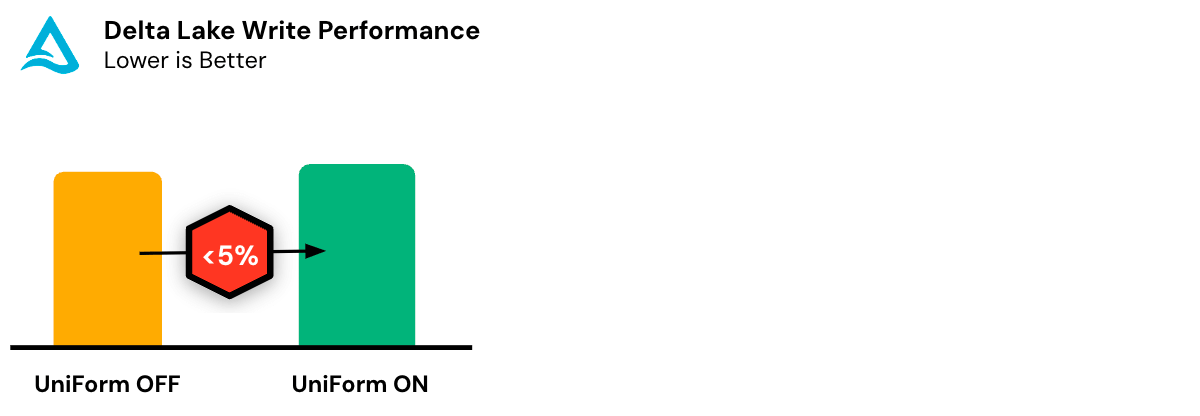
Delta UniForm hat einen vernachlässigbaren Leistungs- und Ressourcen-Overhead, was eine optimale Nutzung der Rechenressourcen gewährleistet. Selbst bei Petabyte-großen Tabellen machen die Metadaten typischerweise nur einen winzigen Bruchteil der Datendateigröße aus. Darüber hinaus kann Delta UniForm Metadaten inkrementell generieren, die nur auf die Änderungen seit dem letzten Commit beschränkt sind.
Lesen von Delta UniForm als Iceberg
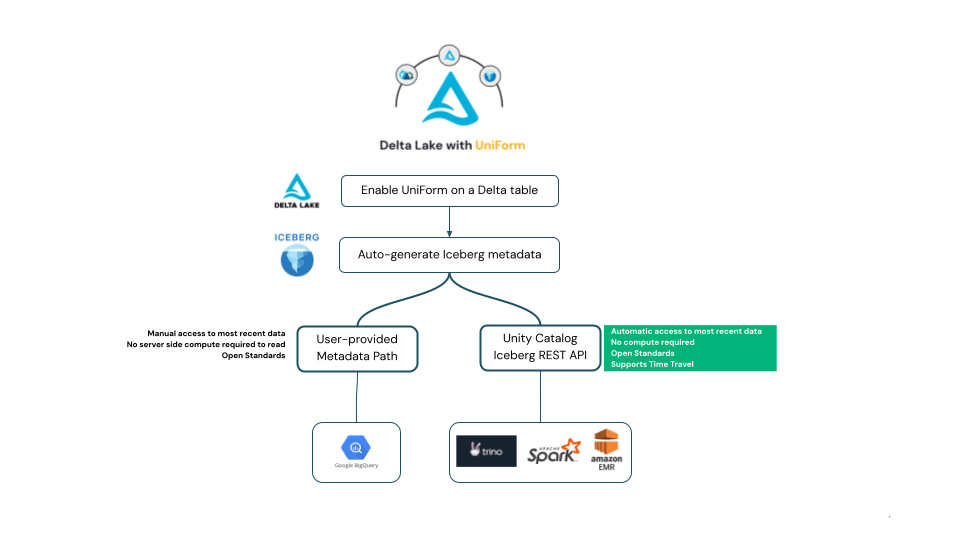
Delta UniForm generiert Iceberg-Metadaten gemäß der Apache Iceberg-Spezifikation. Das bedeutet, wenn Daten in eine Delta UniForm-Tabelle geschrieben werden, kann die Tabelle als Iceberg von jedem Client im Iceberg-Ökosystem gelesen werden, der die Open-Source-Iceberg-Spezifikation einhält.
Gemäß der Iceberg-Spezifikation müssen Reader-Clients herausfinden, welche Iceberg-Metadaten die neueste, aktuellste Version der Iceberg-Tabelle darstellen. Im Iceberg-Ökosystem haben wir gesehen, dass Clients zwei verschiedene Ansätze verfolgen, die beide von UniForm unterstützt werden. Wir werden die Unterschiede hier erläutern und dann im nächsten Abschnitt Beispiele geben.
Einige Iceberg-Reader verlangen von Benutzern, dass sie den Pfad zu einer Metadatendatei angeben, die den neuesten Snapshot der Iceberg-Tabelle darstellt. Dieser Ansatz kann für Kunden umständlich sein, da Benutzer bei jeder Änderung der Tabelle aktualisierte Metadaten-Dateipfade angeben müssen.
Alternativ empfiehlt die Iceberg-Community die Verwendung der REST Catalog API. Der Client kommuniziert mit dem Katalog, um den neuesten Status der Tabelle abzurufen, sodass Benutzer den neuesten Status einer Iceberg-Tabelle ohne manuelle Aktualisierungen oder Sorgen um Metadatenpfade lesen können.
Unity Catalog implementiert jetzt die offene Iceberg Catalog REST API gemäß der Apache Iceberg-Spezifikation. Dies steht im Einklang mit dem Engagement von Unity Catalog zur Unterstützung offener APIs und baut auf der Dynamik der HMS API-Unterstützung von Unity Catalog auf. Die Unity Catalog Iceberg REST API bietet offenen Zugriff auf UniForm-Tabellen im Iceberg-Format ohne zusätzliche Kosten für Databricks-Compute, während sie Interoperabilität und Auto-Refresh-Unterstützung für den Zugriff auf die neuesten Daten ermöglicht. Als Nebenprodukt sollte dies anderen Katalogen ermöglichen, sich mit Unity Catalog zu vernetzen und Delta UniForm-Tabellen zu unterstützen.
Die Apache Iceberg-Client-Bibliotheken sind mit der Fähigkeit vorinstalliert, mit der Iceberg REST API Catalog zu interagieren. Das bedeutet, dass jeder Client, der den Apache Iceberg-Standard vollständig implementiert und die Konfiguration von Catalog-Endpunkten unterstützt, problemlos auf den Unity Catalog Iceberg REST API Catalog zugreifen und die neuesten Metadaten für seine Tabellen abrufen kann. Dies eliminiert die Aufgabe der Verwaltung von Tabellenmetadaten.
Im nächsten Abschnitt werden wir Beispiele für die Unterstützung von Delta UniForm für die Ansätze mit Metadatenpfad und Iceberg REST Catalog API durchgehen.
Beispiel: Lesen von Delta Lake als Iceberg in BigQuery durch Angabe des Metadaten-Speicherorts
Beim Lesen von Iceberg in einem vorhandenen Katalog verlangt BigQuery von Ihnen, dass Sie einen Zeiger auf die JSON-Datei angeben, die den neuesten Iceberg-Snapshot darstellt (BigQuery-Dokumentation), wie im Folgenden:
In BigQuery:
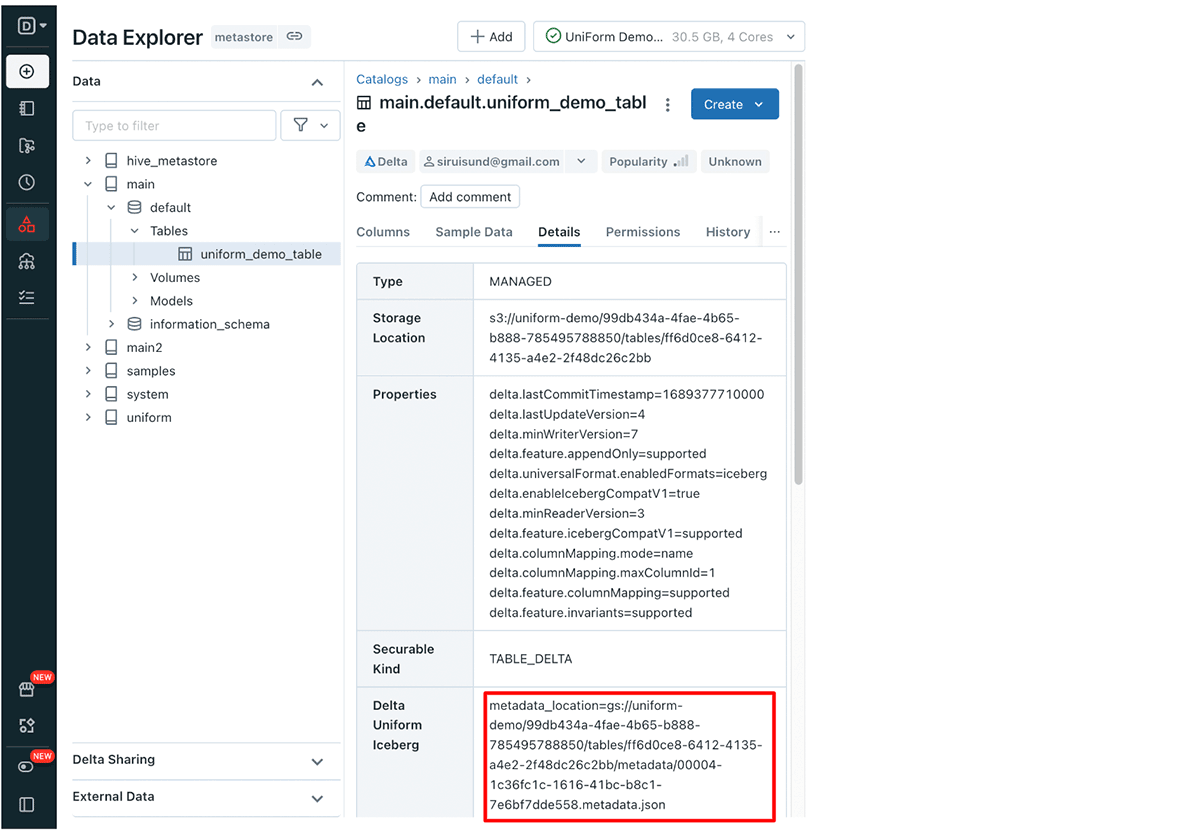
Delta UniForm mit Unity Catalog erleichtert Ihnen das Auffinden des erforderlichen Iceberg-Metadaten-Dateipfads. Unity Catalog stellt eine Reihe von Delta Lake-Tabelleneigenschaften bereit, einschließlich dieses Pfads. Sie können den Metadaten-Speicherort für Ihre Delta UniForm-Tabelle über die Benutzeroberfläche oder die API abrufen.
Abrufen des Delta UniForm Iceberg-Metadatenpfads über die Benutzeroberfläche:
Navigieren Sie in Databricks zum Data Explorer zu Ihrer Delta UniForm-Tabelle und klicken Sie dann auf die Registerkarte Details. Hier finden Sie die Zeile Delta UniForm Iceberg, die den Metadatenpfad enthält.
In Databricks:
Abrufen des Delta UniForm Iceberg-Metadaten-Speicherorts über die API:
Senden Sie von einem Tool Ihrer Wahl aus die folgende GET-Anfrage, um den Iceberg-Metadaten-Speicherort Ihrer Delta UniForm-Tabelle abzurufen.
Das Feld delta_uniform_iceberg.metadata_location in der Antwort enthält den Metadaten-Speicherort für den neuesten Iceberg-Snapshot.
Fügen Sie einfach den Speicherort aus der Benutzeroberfläche oder den oben beschriebenen API-Methoden in den genannten BigQuery-Befehl ein, und BigQuery liest den Snapshot als Iceberg.
Wenn Ihre Tabelle aktualisiert wird, müssen Sie BigQuery den aktualisierten Metadatenstandort mitteilen, um die neuesten Daten zu lesen. Für Produktionsanwendungsfälle sollten Sie Ihrer Erfassungspipeline einen Schritt hinzufügen, der BigQuery bei jeder Schreiboperation auf die Delta UniForm-Tabelle mit dem/den neuesten Iceberg-Metadatenpfad/Pfaden aktualisiert. Beachten Sie, dass die Notwendigkeit von Metadatenpfad-Updates eine allgemeine Einschränkung dieses Ansatzes ist und nicht spezifisch für UniForm ist.
Beispiel: Delta Lake als Iceberg in Trino über die REST Catalog API lesen
Lassen Sie uns nun dieselbe Delta UniForm-Tabelle, die wir zuvor erstellt haben, über Trino mithilfe der Iceberg REST Catalog API von Unity Catalog lesen.
Hinweis: UniForm ist nicht erforderlich, um Delta-Tabellen mit Trino zu lesen, da Trino Delta-Tabellen direkt unterstützt. Dies dient nur zur Veranschaulichung, wie UniForm die Interoperabilität im Open-Source-Ökosystem weiter erweitert.
Nachdem Sie Trino eingerichtet haben, können Sie die Iceberg-Eigenschaften anpassen, indem Sie die Datei etc/catalog/iceberg.properties aktualisieren, um Trino für die Verwendung des Iceberg REST API Catalog-Endpunkts von Unity Catalog zu konfigurieren:
Dabei gilt:
- UNITY_CATALOG_ICEBERG_URL - die URL zum Iceberg REST API-Endpunkt von Unity Catalog - sie hat das Format: https://{DATABRICKS_WORKSPACE_URL}/api/2.1/unity-catalog/iceberg
- DATABRICKS_WORKSPACE_URL - die URL Ihres Databricks-Arbeitsbereichs, die Sie finden, indem Sie Ihren Databricks-Arbeitsbereich in einem Webbrowser aufrufen; sie hat das Format: mydatabricksworkspace.cloud.databricks.com/?o=1231231231231231
- PERSONAL_ACCESS_TOKEN - ein Databricks Personal Access Token, das in einem Databricks-Arbeitsbereich gemäß dieser Anleitung generiert werden kann
Sobald Ihre Eigenschaften-Datei konfiguriert ist, können Sie die Trino CLI ausführen und eine Iceberg-Abfrage an die Delta UniForm-Tabelle senden:
Da Trino die Apache Iceberg REST Catalog API implementiert, haben wir keine externe Tabelle erstellt und mussten auch nicht den Pfad zu den neuesten Iceberg-Metadaten angeben. Trino ruft automatisch die neuesten Iceberg-Metadaten von UC ab und liest dann die neuesten Daten in der Delta UniForm-Tabelle.
Es ist wichtig zu beachten, dass aus Trinos Sicht hier nichts Delta UniForm-spezifisches geschieht. Es liest eine Iceberg-Tabelle, deren Metadaten gemäß Spezifikation generiert wurden, und ruft diese Metadaten mit einem Standard-REST-API-Aufruf an einen Iceberg-Katalog ab.
Das ist die Einfachheit von Delta UniForm. Für Delta Lake-Schreiber und -Leser ist die Delta UniForm-Tabelle eine Delta Lake-Tabelle. Für Iceberg-Leser ist die Delta UniForm-Tabelle eine Iceberg-Tabelle – alles auf einem einzigen Satz von Datendateien ohne unnötige Kopien von Daten und Tabellen.
Delta UniForm-Auswirkungen
Während seiner Vorschau haben wir vielen Kunden bereits geholfen, die Interoperabilität mit Delta UniForm im Open Data Lakehouse zu beschleunigen. Organisationen können einmal in Delta Lake schreiben und dann auf diese Daten zugreifen, wie sie möchten, und so optimale Leistung, Kosteneffizienz und Datenflexibilität für verschiedene Workloads wie ETL, BI und AI erzielen – und das alles ohne die Belastung durch kostspielige und komplexe Migrationen.
"Bei Instacart ist unsere Vision, ein offenes Data Lakehouse mit einer einzigen Datenkopie zu haben, die mit allen Compute-Plattformen interoperabel ist. Delta UniForm ist entscheidend für dieses Ziel. Mit Delta UniForm können wir schnell und einfach Tabellen generieren, die entweder als Delta Lake oder Iceberg gelesen werden können, und so die Interoperabilität mit allen Tools in unserem Ökosystem erschließen." —Doug Hyde, Sr. Staff Software Engineer bei Instacart, teilte seine Erfahrungen mit Delta UniForm
Die Mission von Databricks ist es, Datenteams dabei zu helfen, die schwierigsten Probleme der Welt zu lösen, und das beginnt damit, dass sie das richtige Werkzeug für die richtige Aufgabe verwenden können, ohne ihre Daten kopieren zu müssen. Wir freuen uns über die Verbesserungen der Interoperabilität, die Delta UniForm mit sich bringt, und werden auch in den kommenden Jahren weiter in diesen Bereich investieren.
Delta UniForm ist als Teil des Preview Release Candidate für Delta Lake 3.0 verfügbar. Databricks-Kunden können auch Delta UniForm mit Databricks Runtime Version 13.2 oder dem Databricks SQL 2023.35 Preview-Kanal testen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.