Schnellster Weg, Echtzeit-SAP-HANA-Daten mit Spark JDBC in Databricks zu föderieren
SAP's jüngste Ankündigung einer strategischen Partnerschaft mit Databricks hat bei SAP-Kunden für große Begeisterung gesorgt. Databricks, die Experten für Daten und KI, bieten eine überzeugende Möglichkeit, Analyse- und ML/KI-Funktionen durch die Integration von SAP HANA mit Databricks zu nutzen. Angesichts des immensen Interesses an dieser Zusammenarbeit freuen wir uns, eine ausführliche Blog-Reihe zu starten.
In vielen Kundenszenarien dient ein SAP-HANA-System als primäre Entität für die Datenbasis aus verschiedenen Quellsystemen, darunter SAP CRM, SAP ERP/ECC, SAP BW. Nun ergibt sich die spannende Möglichkeit, dieses robuste SAP-HANA-Analyse-Sidecar-System nahtlos in Databricks zu integrieren und so die Datenkapazitäten des Unternehmens weiter zu verbessern. Durch die Verbindung von SAP HANA (mit HANA Enterprise Edition Lizenz) mit Databricks können Unternehmen die fortschrittlichen Analyse- und Machine-Learning-Funktionen (wie MLflow, AutoML, MLOps) von Databricks nutzen und gleichzeitig die reichhaltigen und konsolidierten Daten in SAP HANA einsetzen. Diese Integration eröffnet Unternehmen eine Welt voller Möglichkeiten, um wertvolle Erkenntnisse zu gewinnen und datengesteuerte Entscheidungen über ihre SAP-Systeme hinweg zu treffen.
Mehrere Ansätze stehen zur Verfügung, um SAP-HANA-Tabellen, SQL-Views und Calculation Views in Databricks zu föderieren. Der schnellste Weg ist jedoch die Verwendung von SparkJDBC. Der größte Vorteil ist, dass SparkJDBC parallele JDBC-Verbindungen von Spark-Worker-Knoten zum entfernten HANA-Endpunkt unterstützt.
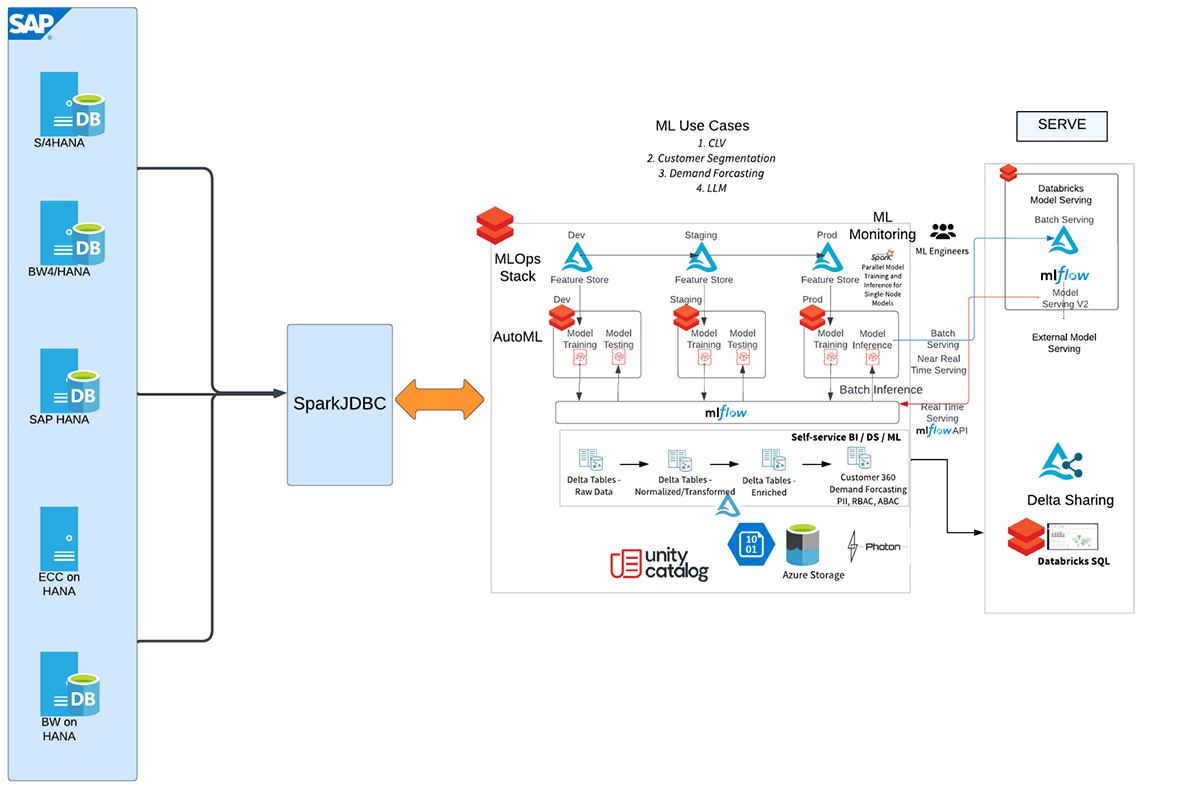
Beginnen wir mit der SAP-HANA- und Databricks-Integration
Zuerst wird SAP HANA 2.0 in der Azure Cloud installiert und wir haben die Integration mit Databricks getestet.
Installierte SAP-HANA-Infos in Azure:
| Version | 2.00.061.00.1644229038 |
| Branch | fa/hana2sp06 |
| Betriebssystem | SUSE Linux Enterprise Server 15 SP1 |
Hier ist der High-Level-Workflow, der die verschiedenen Schritte dieser Integration darstellt.
Siehe das beigefügte Notebook für detailliertere Anweisungen zur Extraktion von Daten aus SAP-HANA-Calculation-Views und -Tabellen in Databricks mit SparkJDBC.

Konfigurieren Sie das SAP-HANA-JDBC-JAR (ngdbc.jar) wie in der folgenden Abbildung gezeigt
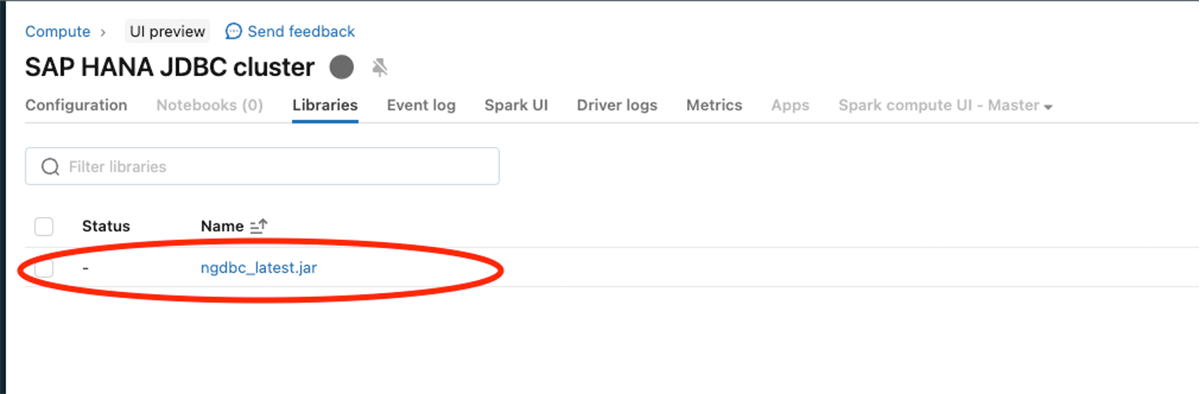
Nachdem die obigen Schritte ausgeführt wurden, führen Sie einen Spark-Read mit dem SAP-HANA-Server und dem JDBC-Port durch.
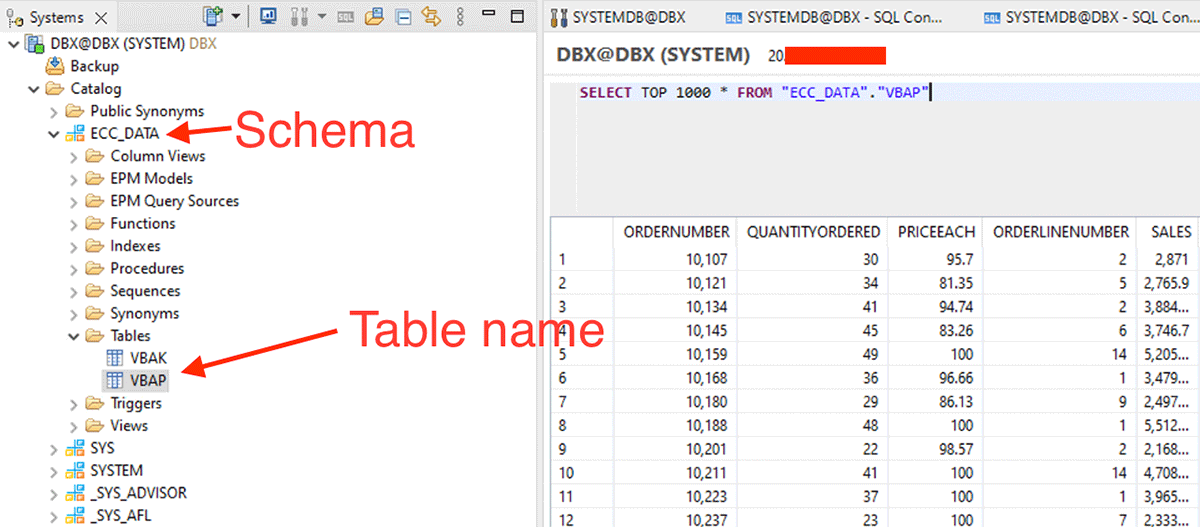
Beginnen Sie mit der Erstellung der DataFrames mit dem unten gezeigten Schema und Tabellennamen.
Außerdem können wir ein Filter-Pushdown durchführen, indem wir SQL-Anweisungen in der dbtable-Option übergeben.
Um Daten aus dem Calculation View zu erhalten, müssen wir Folgendes tun:
Zum Beispiel ist dieser XS-Classic Calculation View im internen Schema "_SYS_BIC" erstellt.
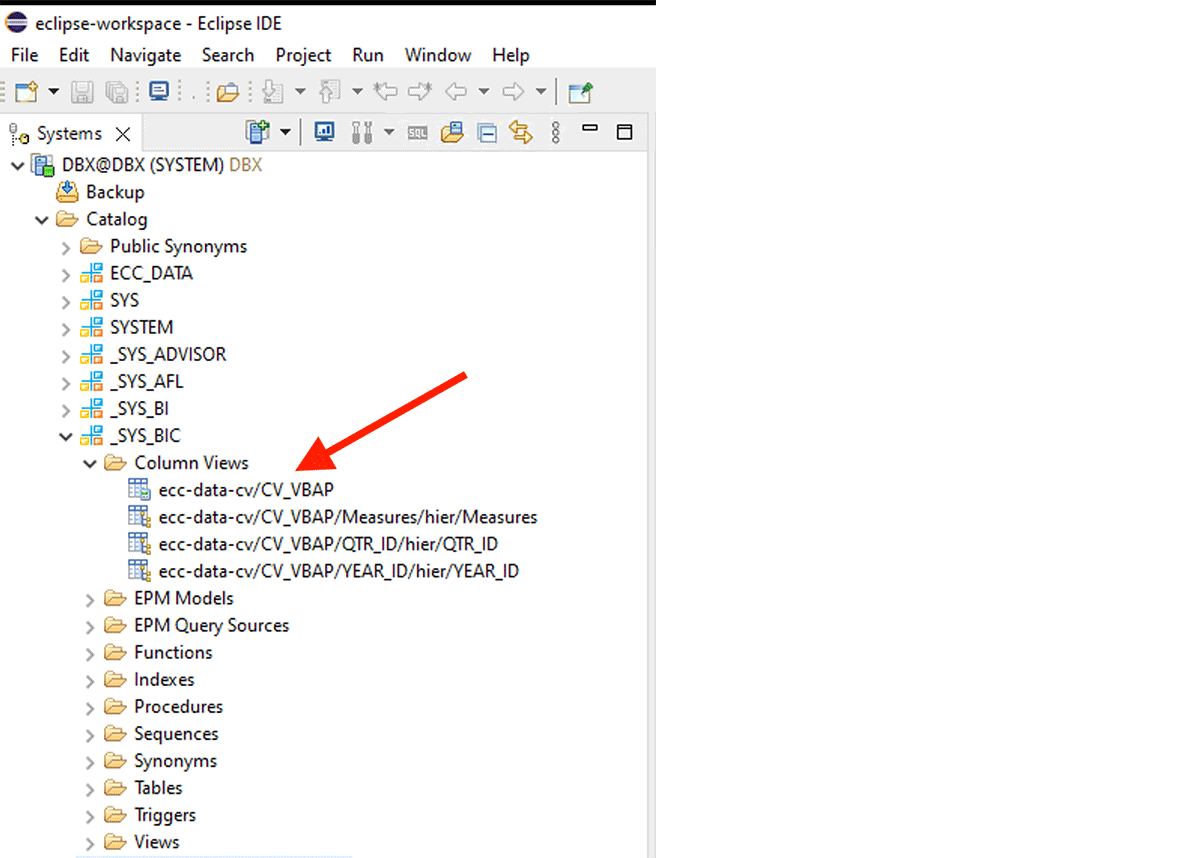
Dieser Code-Schnipsel erstellt ein PySpark-DataFrame namens "df_sap_ecc_hana_cv_vbap" und füllt es aus einem Calculation View des SAP-HANA-Systems (in diesem Fall CV_VBAP).
Nachdem das PySpark-DataFrame generiert wurde, nutzen Sie die endlosen Möglichkeiten von Databricks für explorative Datenanalysen (EDA) und Machine Learning/Künstliche Intelligenz (ML/KI).
Zusammenfassung der obigen DataFrames:
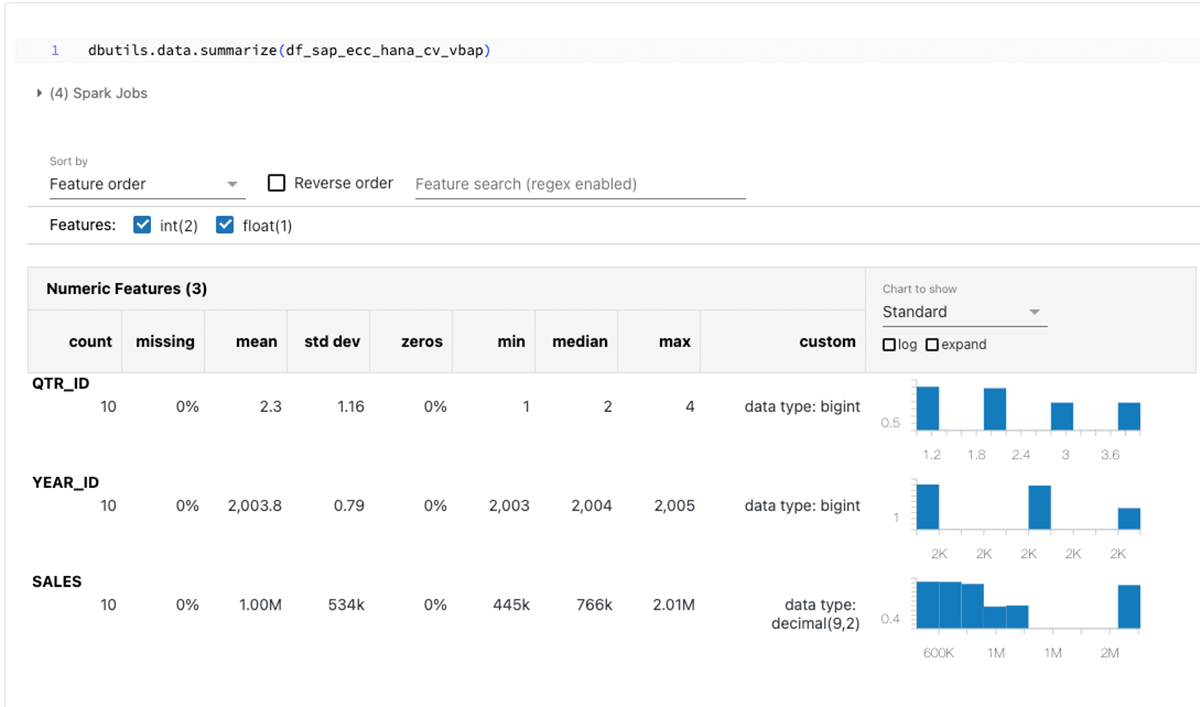
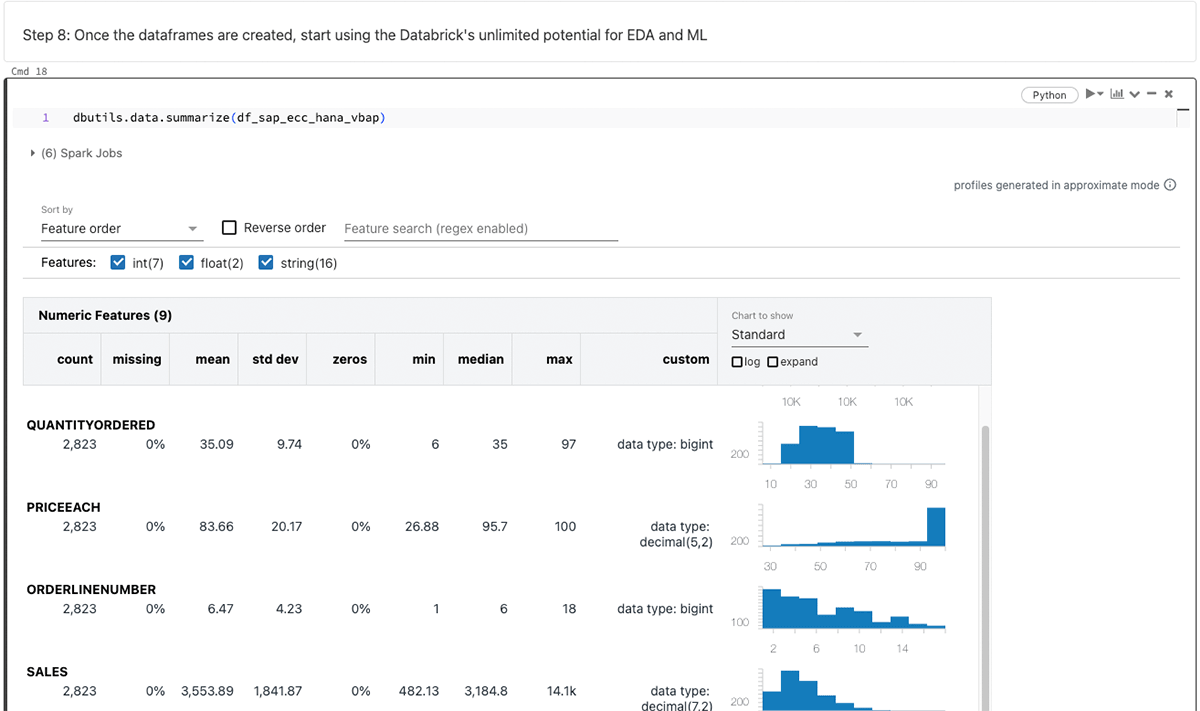
Der Schwerpunkt dieses Blogs liegt auf SparkJDBC für SAP HANA, aber es ist erwähnenswert, dass alternative Methoden wie FedML, hdbcli und hana_ml für ähnliche Zwecke verfügbar sind.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.