Granulare Nutzungszuordnung für dbt-Pipelines mit Query-Tags
Taggen, verfolgen und optimieren Sie jedes dbt-Modell — von der Kostenzuordnung und dem Performance-Debugging bis hin zur Umgebungsüberwachung — mit einer einzigen Konfigurationszeile oder Genie.
von Heeren Sharma, Lennart Reschke und JooHo Yeo
- Versehen Sie jede dbt-Abfrage mit Tags für Team, Kostenstelle, Projekt und Umgebung – ganz ohne Codeänderungen an Ihren SQL-Modellen
- Fragen Sie system.query.history ab, um genau zu sehen, welche dbt-Modelle die höchsten Kosten verursachen und wo Rechenzeit aufgewendet wird
- Stellen Sie ein vollständiges Referenzprojekt mit Declarative Automation Bundles bereit: dbt-Pipeline, Query-Tag-Analyse-Dashboard und geplanter Job – alles aus einem einzigen GitHub-Repository
Ihr dbt-Projekt führt jede Nacht 80 Modelle aus. Die Warehouse-Rechnung hat sich im letzten Quartal verdoppelt. Die Modellleistung variiert stark, und die Auswirkungen der jüngsten Optimierungen sind unklar. Die Finanzabteilung fragt, welches Team dafür verantwortlich ist. Sie öffnen den Abfrageverlauf und sehen ... 80 identische Zeilen mit der Bezeichnung „Databricks Dbt“. Viel Glück.
Mit Query Tags (jetzt in der Public Preview) können Datenteams nun von standardmäßig automatisch eingefügten Tags wie dbt_model_name profitieren, die jeden Durchlauf anreichern. Sie können auch Ihre eigenen benutzerdefinierten Tags – Team, Kostenstelle, Umgebung, was auch immer – an jede Abfrage anhängen, die Ihre Pipeline generiert.
Tags werden in system.query.history erfasst, sodass Kostenzuordnung, Performance-Debugging und Workload-Überwachung nur eine einfache SQL-Abfrage entfernt sind (vollständige Details finden Sie in der Dokumentation).
Dieser Blog führt Sie durch ein vollständiges Open-Source-dbt-Projekt, das Query Tags durchgängig demonstriert: von der Konfiguration bis hin zu Dashboards für die Kostenzuordnung. Alles, was hier beschrieben wird, ist als GitHub-Repository verfügbar, das Sie klonen und in Ihrem eigenen Workspace bereitstellen können, oder fragen Sie einfach Genie.
Wie sich dbt-databricks in Query Tags integriert
Der dbt-databricks-Adapter (Version 1.11+) unterstützt Query Tags nativ. Es gibt drei Ebenen, auf denen Tags angewendet werden können, wobei jede auf der vorherigen aufbaut:
Automatisch eingefügte Tags
Zusätzlich zu Ihren benutzerdefinierten Tags fügt dbt-databricks automatisch Metadaten zu jeder Modellausführung ein:
Tag | Beispielwert | Beschreibung |
@@dbt_model_name | fct_daily_usage_by_sku | Das ausgeführte dbt-Modell |
@@dbt_materialized | table | Materialisierungsstrategie (table, view, incremental, metric_view) |
@@dbt_core_version | 1.11.6 | dbt-core-Version |
@@dbt_databricks_version | 1.12.0a1 | dbt-databricks-Adapterversion |
Diese Auto-Tags bedeuten, dass Sie ohne jegliche Konfiguration Sichtbarkeit auf Modellebene erhalten – der Adapter erledigt das für Sie.
Tags auf Profilebene
Der einfachste Ansatz: Fügen Sie ein query_tags-Feld zu einem bestimmten Ziel in Ihrem dbt-Profil hinzu. Jede Abfrage im Projekt erbt diese Tags automatisch.
Diese einzelne Zeile versieht beispielsweise jede Abfrage mit vier Dimensionen: wem sie gehört (team), wohin die Kosten fließen (cost_center), zu welcher Pipeline sie gehört (project_name) und in welcher Umgebung sie ausgeführt wird (env).
Tags auf Modellebene
Für eine präzisere Zuordnung können Sie Tags für bestimmte Modelle in dbt_project.yml oder in der Modellkonfiguration in der zugehörigen SQL-Definition angeben.
Tags auf Modellebene werden mit Tags auf Profilebene zusammengeführt. Wenn beide denselben Schlüssel definieren, hat der Wert auf Modellebene Priorität.
Wo Tags angezeigt werden – system.query.history
Nach dem Ausführen von dbt run erscheint jede SQL-Anweisung in system.query.history, wobei die Spalte query_tags als MAP gefüllt ist. Sie können sie mit der Standard-Map-Zugriffssyntax abfragen:
Dies gibt jede getaggte Abfrage der letzten 7 Tage zurück, wobei die benutzerdefinierten und automatisch eingefügten Tags in einzelne Spalten extrahiert werden – bereit für die Aggregation.
Sie finden die Query Tags für die ausgeführte Abfrage auch in der Query History-UI oder der SQL Warehouse-Monitoring-UI.

Unten rechts im Query Profile sehen Sie die von Ihnen definierten Query Tags, sodass Sie alle erforderlichen Informationen auf einen Blick haben.

Kostenzuordnung mit Query Tags
Query Tags ermöglichen es, die detaillierte Nutzungsauslastung direkt über SQL-Abfragen zu ermitteln, sodass keine manuelle Protokollanalyse oder Aufteilung von Warehouse-Ressourcen mehr erforderlich ist.
Welche dbt-Modelle verbrauchen die meisten Warehouse-Ressourcen?
Sie können dies auf zwei Arten beantworten: Fragen Sie Genie in natürlicher Sprache für Ad-hoc-Untersuchungen oder schreiben Sie das SQL selbst für ein wiederholbares, Dashboard-fähiges Ergebnis. Beide lesen aus denselben system.query.history-Daten.
Option 1: Genie

Genie schreibt und führt die entsprechende Abfrage aus, und Sie können weitere Detailfragen stellen, ohne SQL anzufassen.
Option 2: SQL
Beide Wege führen zum selben Ergebnis. In unserem Referenzprojekt dominieren die vier Mart-Tabellen (materialisiert als table) die Rechenzeit, während Staging-Views und Metric-Views nahezu verzögerungsfrei sind. Dies zeigt Ihnen sofort, worauf sich die Optimierungsbemühungen konzentrieren sollten.

Erstellung eines selbstüberwachenden Dashboards
Unser Referenzprojekt umfasst ein AI/BI-Dashboard, das system.query.history gefiltert nach den projekteigenen Query Tags abfragt. Das Ergebnis: Die Pipeline, die Abrechnungsdaten analysiert, verfolgt auch ihre eigenen Kosten – ein praktischer Selbsttest (Dogfooding) für Query Tags.
Das Dashboard umfasst:
- KPIs: Gesamtzahl der getaggten Abfragen, gesamte Rechensekunden, eindeutige dbt-Modelle
- Tägliche Aktivität: Anzahl der Abfragen und Rechenzeit pro Tag, aufgeteilt nach Umgebung
- Modellaufschlüsselung: Rechenzeit pro Modell, farblich gekennzeichnet nach Materialisierungstyp
- Aufteilung der Materialisierung: Kreisdiagramm, das zeigt, wie sich die Rechenleistung auf Table, View und metric_view verteilt
- Abfragedetailtabelle: Jede getaggte Abfrage mit Modell, Dauer, Umgebung und Executor
In unserem Referenzprojekt machten die vier Mart-Modelle 92 % der Rechenzeit aus – ohne Query Tags wäre diese Erkenntnis unsichtbar geblieben.
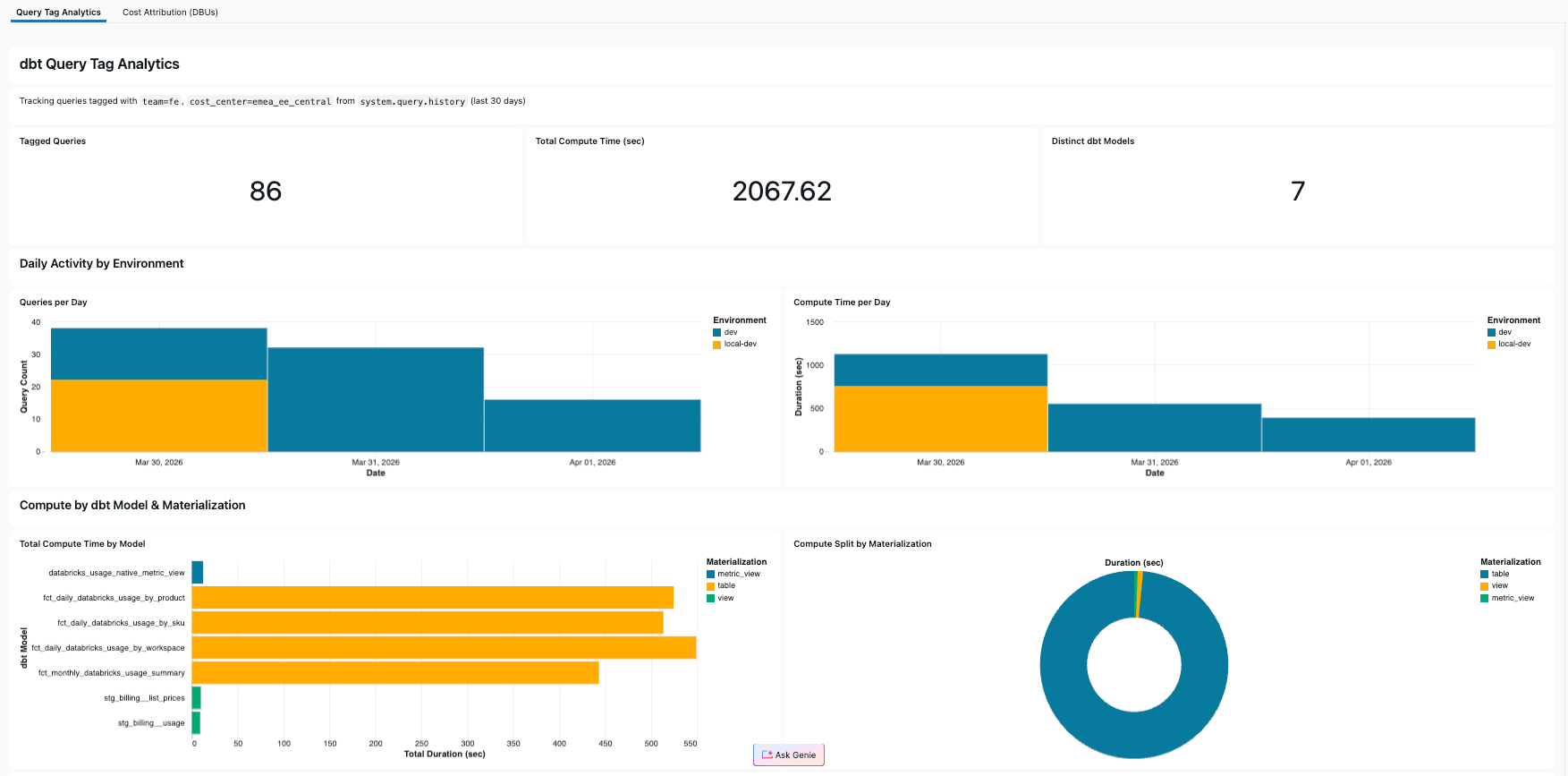
Mit Genie Code erstellen Sie dieses Dashboard in wenigen Minuten selbst: Fragen Sie einfach nach der Rechenzeit pro dbt-Modell aus system.query.history, gefiltert nach Ihren Query-Tags, und das Tool schreibt das SQL und erstellt die Visualisierungen. Wenn Sie lieber direkt zum fertigen Ergebnis springen möchten, ist das Dashboard auch im Referenzprojekt enthalten und lässt sich mit einem einzigen databricks bundle deploy zusammen mit dem dbt-Job bereitstellen (siehe das GitHub-Repository für eine detaillierte Anleitung).
Tagging von Metric Views
Databricks-Metric-Views (verfügbar ab dbt-databricks 1.12+) sind ein neuer Materialisierungstyp, der wiederverwendbare Geschäftssemantik in Form von Dimensionen und Kennzahlen (Measures) direkt in Unity Catalog definiert (siehe vollständige Dokumentation). Sie können wie jedes andere Modell Query Tags tragen, indem sie den Konfigurationsparameter query_tags verwenden:
Beachten Sie den Unterschied: query_tags sind an die SQL-Abfragen angehängt, die die Metric View erstellen oder aktualisieren (erfasst in system.query.history), während databricks_tags Unity Catalog-Tags auf dem Objekt selbst sind (für Governance und Discovery). Ersteres dient der Nachverfolgung auf Abfrageebene, während Letzteres auf Unity Catalog-Objektebene für die allgemeine Datenauffindbarkeit gedacht ist.
Best Practices für das Tagging von dbt-Projekten
In diesem Artikel haben wir den ganzheitlichen Prozess zum Aufbau einer soliden FinOps-Praxis beschrieben, bei der Query Tags die Grundlage für die Kostenzuordnung bilden. Das haben wir beim Erstellen des Referenzprojekts und im Gespräch mit dbt-Power-Usern gelernt:
- Verwenden Sie eine konsistente Tag-Hierarchie. Definieren Sie unternehmensweite Tags auf Profilebene (team, cost_center, project_name, env) und reservieren Sie Tags auf Modellebene für Ausnahmefälle. Dies hält Tags vorhersehbar und vermeidet eine unübersichtliche Konfiguration pro Modell.
- Taggen Sie immer die Umgebung. Verwenden Sie unterschiedliche env-Werte für die lokale Entwicklung (local-dev) und bereitgestellte Jobs (dev, staging, prod). Auf diese Weise können Sie Ad-hoc-Entwicklungsabfragen von geplanten Produktionsläufen in Ihren Analysen trennen. In unserem Referenzprojekt setzt das lokale Profil "env": "local-dev", während das bereitgestellte Profil "env": "dev" setzt.
- Verwenden Sie `project_name`, um Pipelines zu unterscheiden. Wenn sich mehrere dbt-Projekte ein Warehouse teilen, können Sie mit project_name die Kosten pro Pipeline zuordnen, ohne Warehouses aufteilen zu müssen. In Kombination mit dem automatisch eingefügten @@dbt_model_name erhalten Sie volle Rückverfolgbarkeit: Projekt → Modell → Materialisierung.
- Übertreiben Sie es nicht mit dem Tagging. Die automatisch eingefügten Tags decken bereits Modellname, Materialisierungstyp und Adapterversionen ab. Sie müssen diese Informationen selten in benutzerdefinierten Tags duplizieren. Konzentrieren Sie benutzerdefinierte Tags auf den Geschäftskontext, den dbt nicht ableiten kann: Teamzugehörigkeit, Kostenstelle, Projektidentität.
- Taggen Sie Metric Views explizit. Da Metric Views eine neuere Materialisierung sind, ist es nützlich, sie mit einem feature-Schlüssel zu taggen (z. B. "feature": "metric_view"), damit Sie in Ihrer Kostenanalyse einfach nach Abfragen zur Erstellung von Metric Views filtern können.
Probieren Sie es selbst aus
Das vollständige Referenzprojekt ist auf GitHub verfügbar: github.com/databricks-solutions/dbt-query-tags
Erste Schritte:
- Klonen Sie das Repository
- Erstellen Sie eine virtuelle Python 3.12-Umgebung und installieren Sie die Abhängigkeiten: pip install dbt-databricks>=1.12.0a1
- Aktualisieren Sie profiles.yml mit Ihrem Workspace-Host, dem HTTP-Pfad des SQL-Warehouse, dem Katalog und benutzerdefinierten Query-Tags
- Führen Sie dbt deps && dbt run --profiles-dir . aus, um die Pipeline auszuführen
- Fragen Sie system.query.history ab, um Ihre Tags in Aktion zu sehen
- Aktualisieren Sie dbt_profiles/profiles.yml und databricks.yml, um auf die richtige Konfiguration zu verweisen.
- Führen Sie die Bereitstellung mit databricks bundle deploy für geplante Läufe und das Analyse-Dashboard durch
Setzen Sie Ihre eigenen Werte für Team und Kostenstelle ein. Das Muster funktioniert für jedes dbt-Projekt auf Databricks.
Klonen Sie das Repository noch heute! Es braucht nur eine Zeile in Ihrem Profil, um die Sichtbarkeit der Nutzungszuordnung auf Modellebene für Ihr gesamtes Warehouse freizuschalten.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.