Query-Tags: Der Kontext, der Ihren Warehouse-Abfragen gefehlt hat
Teilen Sie Kosten auf, verfolgen Sie Abfragen von Partner-Tools und kennzeichnen Sie Workloads – mit benutzerdefinierten Metadaten bei jeder SQL-Ausführung.
- Teilen Sie die Kosten für gemeinsam genutzte Warehouses nach Team, Projekt, Dashboard oder einer beliebigen benutzerdefinierten Dimension auf
- Überwachen oder beheben Sie Abfragen von Partner-Tools mit automatischer Kennzeichnung für dbt (Modellname), PowerBI (Berichts-ID), Tableau (Arbeitsmappenname) und mehr
- Kennzeichnen Sie Abfragen von überall: SQL-Editor, Notebooks, Dashboards, APIs, Connectors und Treiber
Databricks SQL erfasst automatisch wichtige Attribute jeder Abfrage: wer sie ausgeführt hat, auf welchem Warehouse und von welchem Tool. Aber das ist oft nicht genug.
Wenn eine Power BI-Abfrage langsam läuft, wissen Sie, dass sie von Power BI stammt, aber nicht, welches Dashboard Sie reparieren müssen. Wenn die Kosten steigen, können Sie sehen, welche Benutzer Abfragen ausgeführt haben, aber nicht, welchem Kosten-Center oder Projekt Sie diese zuordnen können. Das fehlende Element ist der benutzerdefinierte Kontext, und genau das fügt Query Tags hinzu.
Heute stellen wir Query Tags in Public Preview vor. Mit Query Tags können Sie jeder SQL-Ausführung Geschäftskontext als mehrere Schlüssel-Wert-Paare zuordnen und alles über Systemtabellen mit Standard-SQL abfragen — oder einfach, indem Sie Genie fragen. Query Tags sind auch in der Query Profile UI sichtbar (Unterstützung für die Suche in der Query History UI wird bald verfügbar sein).
Query Tags verzeichnen bereits eine starke Akzeptanz, wobei Hunderte von Kunden wöchentlich Millionen von Abfragen taggen.
Einfach taggen: Einführung von Query Tags
Mit Query Tags ordnen Sie jeder SQL-Ausführung benutzerdefinierte Schlüssel-Wert-Paare zu (z. B. „Projekt“ : „finanzplanung“). Diese Tags reisen mit der Abfrage und werden in der Query History System Table aufgezeichnet, wodurch sie zum Gruppieren, Filtern und Analysieren von Workloads verfügbar sind.
Tags bieten in drei Szenarien einen Mehrwert:
- Partner-Tools: Bei der Verwendung von dbt, Power BI oder Tableau, propagieren Sie Identifikatoren wie dbt-Modellnamen, Power BI-Berichts-IDs oder Tableau-Arbeitsmappen-Namen in jede Abfrage.
- Benutzerdefinierte Anwendungen: Beim Erstellen von Apps über die SQL Statement Execution API oder Connectors, fügen Sie jeder Ausführung Metadaten wie `customerid`, `applicationname` oder `app_version` hinzu.
- Ad-hoc-Arbeit in der Databricks UI: Taggen Sie Abfragen mit Dimensionen, die für Sie relevant sind — Entwicklung vs. Produktionsumgebung, Kostenstelle, Experimentname oder Team.
Lassen Sie uns tiefer in diese Szenarien eintauchen.
(1) Verfolgen Sie jede Partner-Tool-Abfrage zu ihrer Quelle zurück
Abfragen von dbt, Power BI und Tableau fließen in Ihr Warehouse ein — aber ohne Tags sind sie über eine Benutzer-ID und das verwendete Tool hinaus nicht nachverfolgbar. Diese Tools lösen dieses Problem, indem sie Query Tags automatisch injizieren, ohne dass eine manuelle Tagging erforderlich ist.
dbt taggt jede Abfrage automatisch mit dem Modellnamen, der Kernversion, der Adapterversion und dem Materialisierungstyp. Wenn ein dbt-Modell plötzlich Leistungseinbußen aufweist, können Sie genau bestimmen, welches Modell, welche Version und wann:
Staff Engineering Leads Dipesh Bhundia und Dave Couse bei ASOS fügten hinzu:
"Ohne Konfiguration können wir jede SQL-Workload dem dbt-Modell zuordnen, aus dem sie stammt. Mit Query Tags können wir endlich die Kosten des Data Warehouses genau nach den Teams aufteilen, die dbt darauf ausführen."
Power BI und Tableau unterstützen benutzerdefinierte Query Tags auf Connection-Ebene. Richten Sie sie einmal ein, und jede Abfrage von dieser Connection trägt sie automatisch. Für Tableau haben Kunden es als nützlich empfunden, Parameter wie [WorkbookName] als Tag-Wert zu verwenden, sodass die Zuordnung auch dann erhalten bleibt, wenn die Arbeitsmappe umbenannt wird.
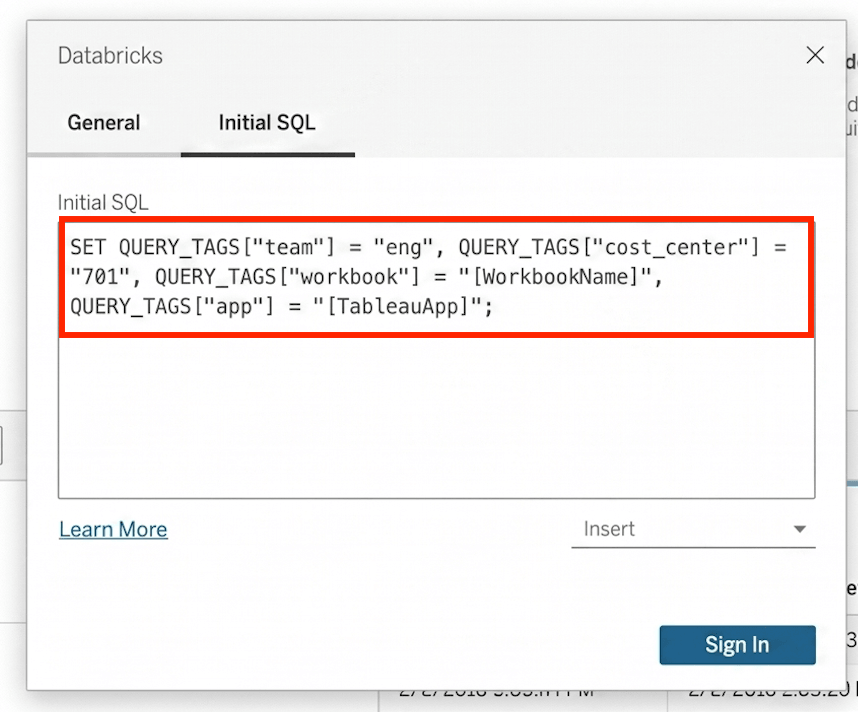
Eine vollständige Liste der Partner-Tools, die Query Tags unterstützen, finden Sie in der Dokumentation. Wenn Ihr Tool nicht aufgeführt ist, wenden Sie sich an Ihr Account-Team.
(2) Wandeln Sie anonyme API-Abfragen in nachverfolgbare Workloads um
Benutzerdefinierte Anwendungen greifen über APIs und Connectors auf Ihr Warehouse zu, aber die von ihnen generierten Abfragen enthalten keinen Anwendungs-Kontext — keinen App-Namen, kein Team-Namen, keine Kunden-ID. Query Tags ermöglichen es Ihnen, diese Metadaten auf Connection- oder Statement-Ebene hinzuzufügen.
Die SQL Statement Execution API unterstützt das Tagging auf Statement-Ebene. Als Parameter übergebene Tags gelten für diese spezifische Ausführung:
Der Python Connector unterstützt sowohl Connection- als auch Statement-Level-Tagging. Legen Sie einen Teamnamen für die Connection fest; überschreiben Sie ihn bei Bedarf pro Statement:
Matthew Haber, DevOps Engineer, Unit21 teilte mit:
"Wir sind von einem Warehouse pro Team zu gemeinsamen Warehouses übergegangen, um Kosten zu senken, haben aber die Sichtbarkeit verloren, welches Team die Ausgaben verursacht hat. Mit Query Tags übergeben wir einfach den Teamnamen von unserem Databricks SQL Connector für Python-Workloads und haben diese Zuordnung zurück – keine Notwendigkeit, die Warehouses erneut aufzuteilen."
Die vollständige Liste der Connector- und Treiberunterstützung (Node.js, Go, JDBC usw.) finden Sie in der Dokumentation.
(3) Kennzeichnen Sie Ihre eigene Arbeit, damit sie nicht im Rauschen untergeht
Analysten führen Hunderte von Abfragen pro Woche aus (Exploration, Produktion, Debugging usw.) und ohne Labels sehen sie in Systemtabellen alle gleich aus. Query Tags ermöglichen es Praktikern, während der Arbeit mit einer Zeile SQL zu taggen, wo immer sie Abfragen einreichen: SQL Editor, Notebooks, Dashboards und Alerts.
Sobald sie festgelegt sind, tragen alle nachfolgenden Anweisungen in der Sitzung automatisch diese Tags. Sie müssen nicht jede Abfrage einzeln annotieren. Zum Beispiel fügt die Anweisung SET QUERY_TAGS zu jeder Dataset-Abfrage in einem AI/BI-Dashboard hinzu, dass jede Abfrage von diesem Dashboard mit „environment: production“ getaggt wird.
Datenpraktiker können dies verwenden, um:
- Ad-hoc-Analysen nach Projekt oder Team zu taggen
- Experimente oder A/B-Tests zu kennzeichnen
- Entwicklungs- vs. Produktions-Workloads zu identifizieren
- Debugging-Kontext beim Untersuchen von Problemen hinzuzufügen
Von Tags zu Antworten: Überwachung mit Systemtabellen
Sobald Abfragen getaggt sind, werden die Tags in der Spalte query_tags der Query History System Table aufgezeichnet. Jetzt werden die schwierigen Fragen zu einfachen SQL-Abfragen.
Welches Team verursacht die Kosten für das Warehouse?
Viele Organisationen müssen gemeinsame Warehouse-Kosten nach Team oder Produkt aufteilen. Mit Query Tags ist dies eine einzige Abfrage – keine Warehouse-Aufteilung oder Rätselraten.
Welches dbt-Modell hat eine Regression eingeführt?
Wenn eine Pipeline langsamer wird, müssen Sie wissen, welches Modell, nicht nur welches Warehouse. Filtern Sie system.query.history nach dem automatisch eingefügten dbt-Modellnamen-Tag, um das Problem zu isolieren.
Oder überspringen Sie das Schreiben von SQL, indem Sie Genie fragen. Da Query Tags Geschäftskontext in System Tabellen speichern, kann Genie Ihre Workload-Daten in natürlicher Sprache analysieren. Zum Beispiel: "Welches dbt-Modell hatte die meisten Abfragen? Welches hatte die längste durchschnittliche Abfragezeit?"
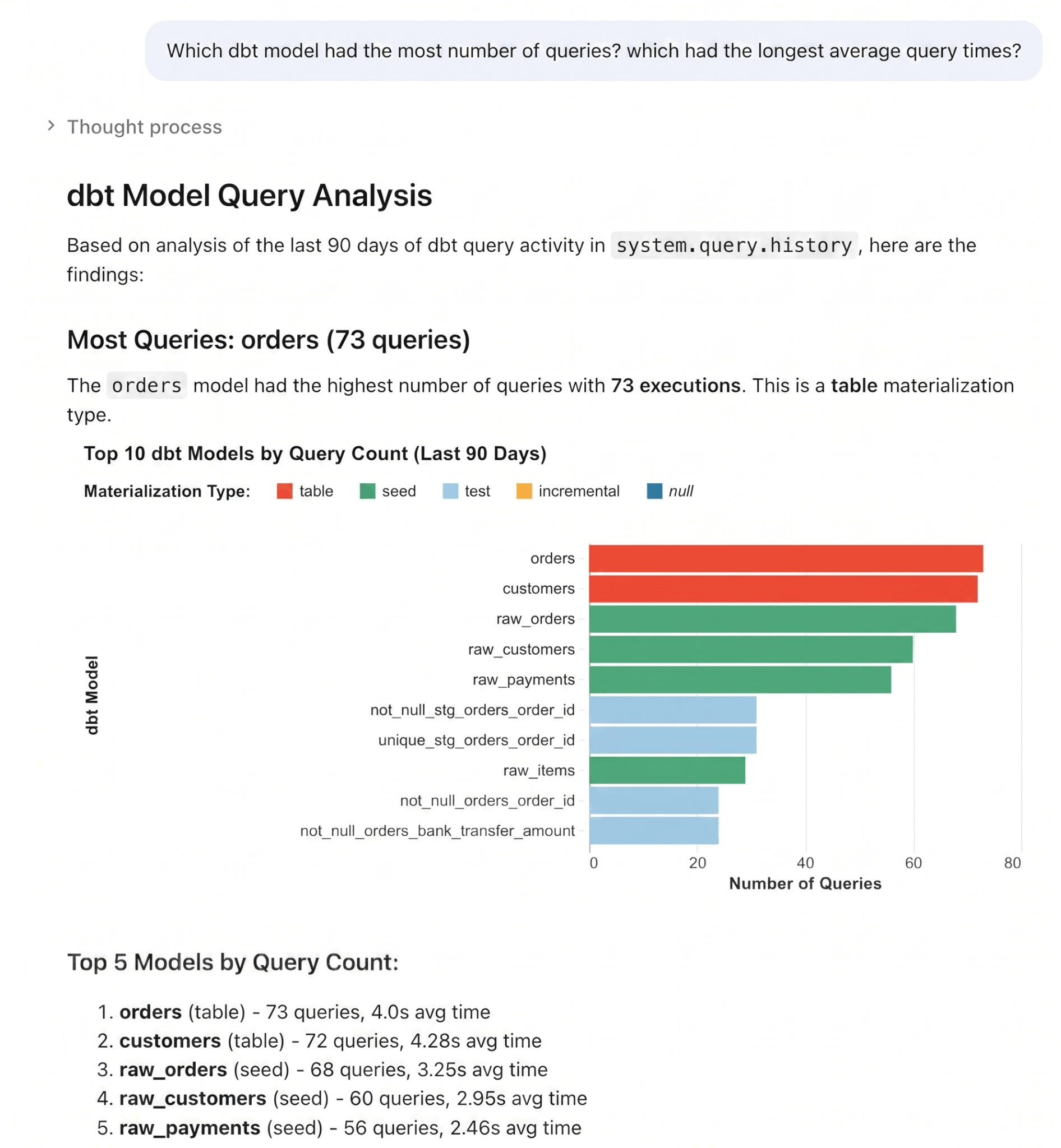
Query Tags schalten viele weitere Monitoring-Anwendungsfälle frei:
- Gruppieren nach query_tags['cost_center'] für die Kostenverrechnung
- Filtern nach query_tags['@@dbt_model_name'] zur Überwachung der Pipeline-Gesundheit
- Identifizieren von langlaufenden Abfragen pro Tableau-Arbeitsmappe
- Vergleichen von query_tags['env'] zur Trennung von Dev- und Prod-Traffic
Was kommt als Nächstes
Query Tags sind heute in der Public Preview für SQL Warehouses verfügbar, und wir arbeiten bereits daran, sie für die Monitoring-Erfahrungen unserer Kunden noch hilfreicher zu machen. Bitte beachten Sie die Dokumentation für Updates.
- Automatische Power BI-Tagging: Power BI fügt automatisch Metadaten wie DatasetId und ReportId zu jeder Abfrage hinzu, ohne Konfiguration. Sie können dies heute manuell aktivieren, indem Sie die Schritte in der Dokumentation befolgen. Automatisches Tagging wird in der nächsten Power BI-Version standardmäßig aktiviert sein.
- Breitere Connector-Unterstützung: Zusätzlich zu Python ist Statement-Level-Tagging jetzt für Go und Node.js verfügbar.
- Suchbarkeit in der Benutzeroberfläche: Wir werden bald die Suche in der Abfrageverlauf-Benutzeroberfläche unterstützen, damit Sie nach Abfragen mit einem bestimmten Tag suchen können (z. B. "@@dbt_model_name": "my_model").
- Unterstützung über SQL Warehouses hinaus: Wir bringen Query Tags zu Serverless Notebooks und Jobs, sodass dasselbe Tagging- und Zuordnungsmodell für Notebook-Workloads gilt.ads.
Probieren Sie Query Tags noch heute aus
Jede nicht getaggte Abfrage ist eine verpasste Gelegenheit zur Zuordnung. Egal, ob Sie Warehouse-Kosten nach Team aufteilen, eine langsame Abfrage auf ein bestimmtes Dashboard zurückführen oder Analystenarbeit nach Projekt kennzeichnen müssen – Query Tags liefern Ihnen den Kontext dafür.
Wenn Sie dbt verwenden, taggen Sie bereits (überprüfen Sie Ihre Query History System Table). Für Power BI, Tableau und benutzerdefinierte Anwendungen dauert die Einrichtung Minuten. Für Ad-hoc-Arbeiten ist eine Zeile SQL erforderlich.
Query Tags sind heute in der Public Preview über alle Clouds hinweg verfügbar. Beginnen Sie mit der Dokumentation.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.