Wie Databricks-Systemtabellen Data Engineers helfen, erweiterte Observability zu erreichen
System Tables bieten die Breite und Tiefe, die Data Engineers benötigen, um den Zustand ihrer Datenpipelines auf Scale einfach zu überwachen und so kostengünstigere und zuverlässigere Workloads zu erzielen.
von Theresa Hammer
- Erfahren Sie, wie Systemtabellen Plattform-Telemetriedaten als abfragbare Tabellen bereitstellen, einschließlich Metadaten und Ausführungsinformationen für Lakeflow-Jobs und -Pipelines.
- Verwenden Sie Beispielabfragen, um diese Telemetriedaten in Erkenntnisse über Zuverlässigkeit, Kosten und Effizienzpotenziale für Lakeflow-Jobs in großem Maßstab umzuwandeln.
- Zentralisieren Sie diese Erkenntnisse in einer gemeinsamen, täglichen Betriebsansicht für Datenverarbeitungsteams mit der Lakeflow-Dashboard-Vorlage.
Das 3-Uhr-Problem
Es ist 3 Uhr morgens und etwas ist kaputt gegangen. Das Dashboard ist veraltet, ein SLA wurde nicht eingehalten, und jeder rätselt, welcher Teil der Plattform aus dem Ruder gelaufen ist. Vielleicht lief ein Job stundenlang ohne Timeout. Vielleicht hat eine Pipeline eine Tabelle aktualisiert, die seit Monaten niemand mehr gelesen hat. Vielleicht läuft ein Cluster noch auf einer alten Runtime. Vielleicht ist die einzige Person, die den Besitzer des Jobs kennt, im Urlaub.
Das sind die Muster, die Datenteams belasten: verschwendete compute durch ungenutzte Pipelines, Zuverlässigkeitslücken durch fehlende Zustandsregeln, Hygieneprobleme durch veraltete Laufzeitumgebungen und Verzögerungen durch unklare Zuständigkeiten. Sie treten unbemerkt auf, wachsen langsam und werden dann plötzlich zu dem, was dem diensthabenden Ingenieur den Schlaf raubt.
Databricks-Systemtabellen bieten eine konsistente Ebene, um diese Probleme frühzeitig zu erkennen, indem sie Job-Metadaten, Task-Zeitpläne, Ausführungsverhalten, Konfigurationsverlauf, Lineage, Kostensignale und Zuständigkeiten an einem zentralen Ort bereitstellen.
Mit den neu eingeführten Systemtabellen für Lakeflow-Jobs haben Sie jetzt Zugriff auf erweiterte Schemata, die umfassendere Ausführungsdetails und Metadatensignale liefern und eine erweiterte Observability ermöglichen.
Detailliertere und zentralisierte Einblicke in all Ihre Daten – leicht gemacht mit Systemtabellen
Was sind Systemtabellen?
Databricks-Systemtabellen sind ein Satz schreibgeschützter, von Databricks verwalteter Tabellen im system -Katalog, die Betriebs- und Beobachtbarkeitsdaten für Ihr Konto bereitstellen. Sie sind sofort einsatzbereit und decken eine breite Palette von Daten ab, darunter Jobs, Pipelines, Cluster, Abrechnung, Herkunft und mehr.
Kategorie | Was es erfasst |
Lakeflow Jobs | Job-Konfigurationen, Taskdefinitionen, Ausführungszeitpläne |
Lakeflow Spark Declarative Pipelines | Pipeline-Metadaten, Updateverlauf |
Abrechnung | Nutzung, Kostenzuordnung nach Workload |
Herkunft | Lese-/Schreibabhängigkeiten auf Tabellenebene |
Cluster | Compute-Konfigurationen, Auslastung |
Warum Systemtabellen für die Observability wichtig sind
Systemtabellen unterstützen workspace-übergreifende Analysen innerhalb einer Region und ermöglichen es Data-Engineering-Teams, Workload-Verhalten und Betriebsmuster jeder Art ganz einfach und im großen Stil über eine einzige, abfragbare Oberfläche zu analysieren. Mithilfe dieser Tabellen können Datenexperten den Zustand all ihrer Pipelines zentral überwachen, Kosteneinsparungspotenziale aufdecken und Ausfälle für eine bessere Zuverlässigkeit schnell identifizieren.
Einige Systemtabellen verwenden die SCD-Typ-2 -Semantik, bei der der vollständige Änderungsverlauf durch das Einfügen einer neuen Zeile für jede Aktualisierung erhalten bleibt. Dies ermöglicht die Konfigurationsprüfung und die Verlaufsanalyse des Plattformzustands im Zeitverlauf.
Lakeflow-Systemtabellen
Lakeflow-Systemtabellen enthalten Daten der letzten 365 Tage und bestehen aus den folgenden Tabellen.
Eine vollständige Liste der Systemtabellen und ihrer Beziehungen finden Sie in der Dokumentation.
Job-Observability-Tabellen (allgemein verfügbar)
system.lakeflow.jobs– SCD2-Metadaten für Jobs, einschließlich Konfiguration und Tags. Nützlich für Bestandsaufnahme, Governance und Konfigurationsdrift-Analyse.system.lakeflow.job_tasks– Eine SCD2-Tabelle, die alle Job-Tasks, ihre Definitionen und Abhängigkeiten beschreibt. Nützlich, um Task-Strukturen in Scale zu verstehen.system.lakeflow.job_run_timeline– Unveränderliche Zeitleiste von Job-Ausführungen mit Status, Compute und Timing. Ideal für die SLA- und Performance-Trendanalyse.system.lakeflow.job_task_run_timeline– Zeitachse der einzelnen Task-Ausführungen innerhalb jedes Jobs. Hilft, Engpässe und Probleme auf Task-Ebene zu identifizieren.
Tabellen zur Pipeline-Beobachtbarkeit (Öffentliche Vorschau)
system.lakeflow.pipelines– SCD2-Metadatentabelle für SDP-Pipelines, die eine Workspace-übergreifende Pipeline-Sichtbarkeit und Änderungsverfolgung ermöglicht.system.lakeflow.pipeline_update_timeline– Unveränderliche Ausführungs-logs für Pipeline-Updates, die das historische Debugging und die Optimierung unterstützen.
Die Lakeflow-Systemtabellen erfreuen sich schnell wachsender Beliebtheit, wobei täglich zig Millionen Abfragen ausgeführt werden, was einem 17-fachen Anstieg im Jahresvergleich entspricht. Dieser Anstieg unterstreicht den Wert, den Dateningenieure aus den Lakeflow-Systemtabellen ziehen, die für viele Kunden von Databricks Lakeflow zu einer entscheidenden Komponente der täglichen Beobachtbarkeit geworden sind.
Sehen wir uns nun Anwendungsfälle an, die durch die kürzlich erweiterten und jetzt allgemein verfügbaren Jobs System Tables ermöglicht werden.
Systemtabellen in der Praxis: Betriebszustand für Lakeflow-Jobs
Als Data Engineer in einem zentralen Plattformteam sind Sie für die Verwaltung von Hunderten von Jobs über mehrere Teams hinweg verantwortlich. Ihr Ziel ist es, die Datenplattform kosteneffizient, zuverlässig und leistungsstark zu halten und gleichzeitig sicherzustellen, dass die Teams die Best Practices für Governance und Betrieb befolgen.
Dazu überprüfen Sie Ihre Lakeflow-Jobs und -Pipelines anhand von vier Kernzielen:
- Kosten optimieren: Identifizieren Sie geplante Jobs, die Datensätze aktualisieren, die nachgelagert nie verwendet werden.
- Zuverlässigkeit gewährleisten: Setzen Sie Timeouts und Laufzeitschwellenwerte durch, um aus dem Ruder laufende Jobs und SLA-Verletzungen zu verhindern.
- Hygiene aufrechterhalten: Konsistente Laufzeitversionen und Konfigurationsstandards überprüfen.
- Zuständigkeiten zuweisen: Bestimmen Sie Verantwortliche für die Jobs, um die Nachverfolgung und Problembehebung zu vereinfachen.
Muster 1: Jobs finden, die ungenutzte Daten erzeugen
Das Problem: Geplante Jobs werden zuverlässig ausgeführt und aktualisieren Tabellen, die kein nachgelagerter Consumer jemals liest. Dies sind oft die einfachsten Kosteneinsparungen, wenn man sie finden kann.
Der Ansatz: Join die Tabellen der Lakeflow-Jobs mit den Lineage- und Abrechnungstabellen, um Produzenten ohne Konsumenten zu identifizieren, geordnet nach Kosten.
Nächste Schritte: Überprüfen Sie die Hauptverursacher mit ihren Besitzern. Einige können möglicherweise sofort sicher pausiert werden. Andere benötigen möglicherweise einen Deprecation-Plan, wenn externe Systeme außerhalb von Databricks von ihnen abhängig sind.
Muster 2: Jobs ohne Zeitüberschreitungen oder Laufzeitschwellenwerte finden
Das Problem: Jobs ohne Timeouts können unbegrenzt laufen. Ein festgefahrener Task verbraucht stunden- oder sogar tagelang compute, bevor es jemand bemerkt. Dies erhöht nicht nur die Kosten, sondern kann auch zu SLA-Verletzungen führen. Daher müssen Sie Überschreitungen frühzeitig erkennen und Maßnahmen ergreifen, bevor Fristen oder nachgelagerte Prozesse beeinträchtigt werden.
Der Ansatz: Aktuelle Job-Konfigurationen auf fehlende Einstellungen für Zeitüberschreitung und Laufzeitschwellenwerte Query.
Nächste Schritte: Führen Sie einen Quervergleich mit den historischen Laufzeiten aus job_run_timeline durch, um realistische Schwellenwerte festzulegen. Ein Job, der normalerweise 20 Minuten läuft, rechtfertigt möglicherweise ein Timeout von 1 Stunde und einen Schwellenwert für die Laufzeit von 30 Minuten. Ein Job, dessen Laufzeit stark schwankt, muss möglicherweise zuerst untersucht werden.
Muster 3: Veraltete Laufzeitversionen erkennen
Das Problem: Bei veralteten Runtimes fehlen Sicherheitspatches und Performance-Verbesserungen und sie unterliegen bevorstehenden EOL-Fristen. Aber bei Hunderten von Jobs ist die Nachverfolgung, wer noch alte Versionen verwendet, mühsam.
Der Ansatz: Fragen Sie die Konfigurationen von Job-Aufgaben nach Laufzeitversionen ab und kennzeichnen Sie alles, was unter Ihrem Schwellenwert liegt.
Nächste Schritte: Priorisieren Sie Upgrades basierend auf EOL-Zeitplänen. Teilen Sie diese Liste mit den Job-Besitzern und verfolgen Sie den Fortschritt in Folgeabfragen.
Muster 4: Job-Verantwortliche zur Behebung identifizieren
Das Problem: Wenn ein Job fehlschlägt oder nicht richtig konfiguriert ist, müssen Sie wissen, an wen Sie sich wenden müssen, um das Problem zu beheben.
Der Ansatz: Fragen Sie Systemtabellen ab, um die Job-Besitzer für jede auszuführende Aktion einfach zu identifizieren.
Nächste Schritte: Wenden Sie sich an die Job-Besitzer, um die Zuständigkeit für Probleme zuzuweisen, die eine Maßnahme erfordern.
Gemeinsam helfen Ihnen diese Muster dabei, Kosten zu optimieren, Daten aktuell zu halten, Zuverlässigkeitsleitplanken durchzusetzen und eine klare Zuständigkeit für die Fehlerbehebung zuzuweisen. Sie bilden die Grundlage für die betriebliche Beobachtbarkeit.
Zusammenfassung: Operationalisierung von Einblicken mit Dashboards
Das Ausführen dieser Abfragen ad hoc ist nützlich.Für den täglichen Betrieb benötigen Sie jedoch eine gemeinsame Ansicht, auf die Ihr gesamtes Team zugreifen kann.
Das Lakeflow-Dashboard gibt mir einen Überblick über die Jobs in all meinen Workspaces – nicht nur auf Kostenebene, sondern auch für die Pipeline-Hygiene und den Betrieb: Tracking der Ausgaben, Identifizierung veralteter Pipelines, Monitoring von Fehlern und das Erkennen von Optimierungsmöglichkeiten. – Zoe Van Noppen, Data Solution Architect, Cubigo
Für den Einstieg importieren Sie das Dashboard in Ihren Workspace. Eine schrittweise Anleitung finden Sie in der offiziellen Dokumentation.
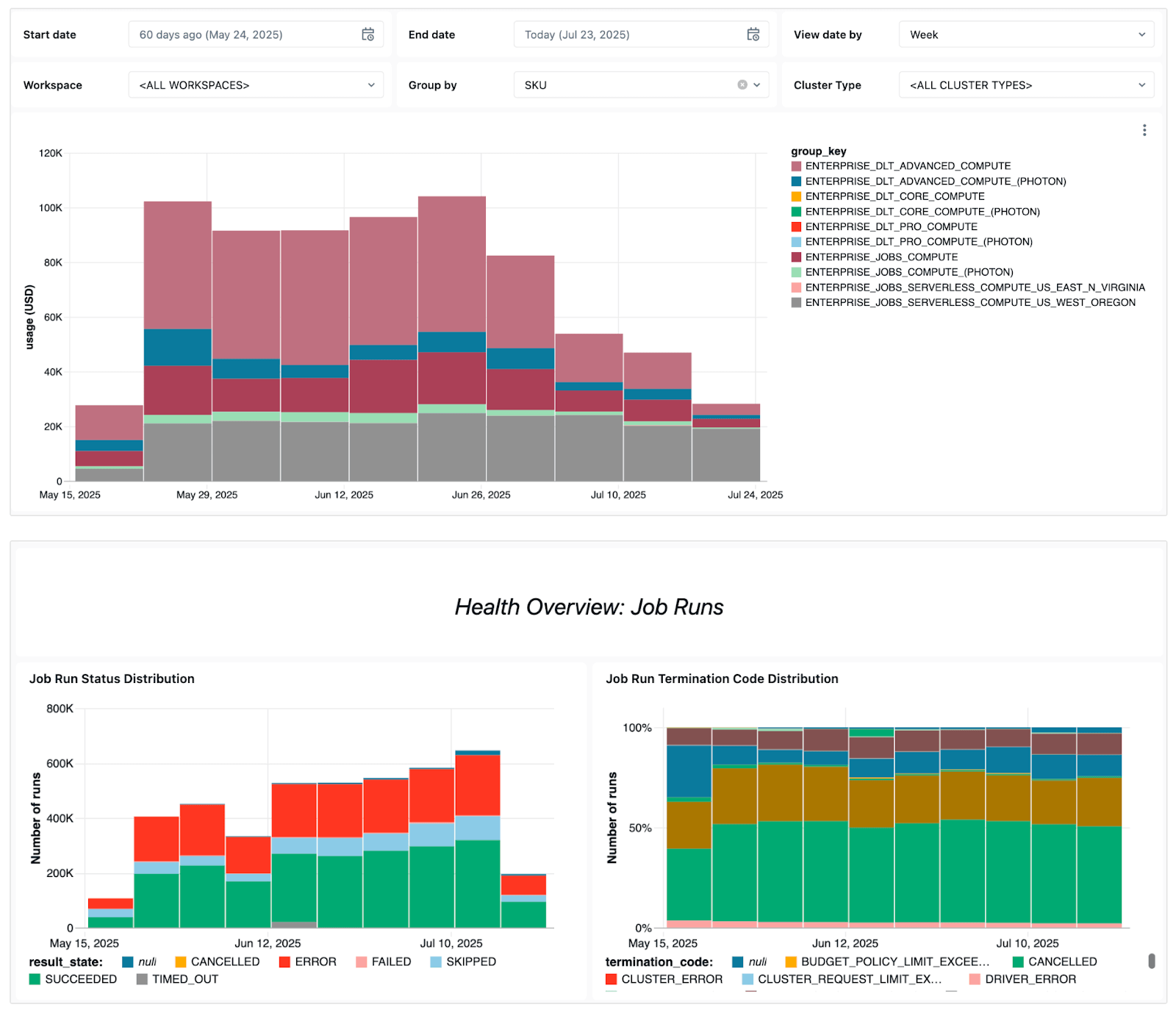
Das Dashboard zeigt mehrere Key Betriebssignale an, darunter:
- Fehlertrends – zeigen Ihnen, welche Jobs am häufigsten fehlschlagen, allgemeine Fehlertrends und häufige Fehlermeldungen.
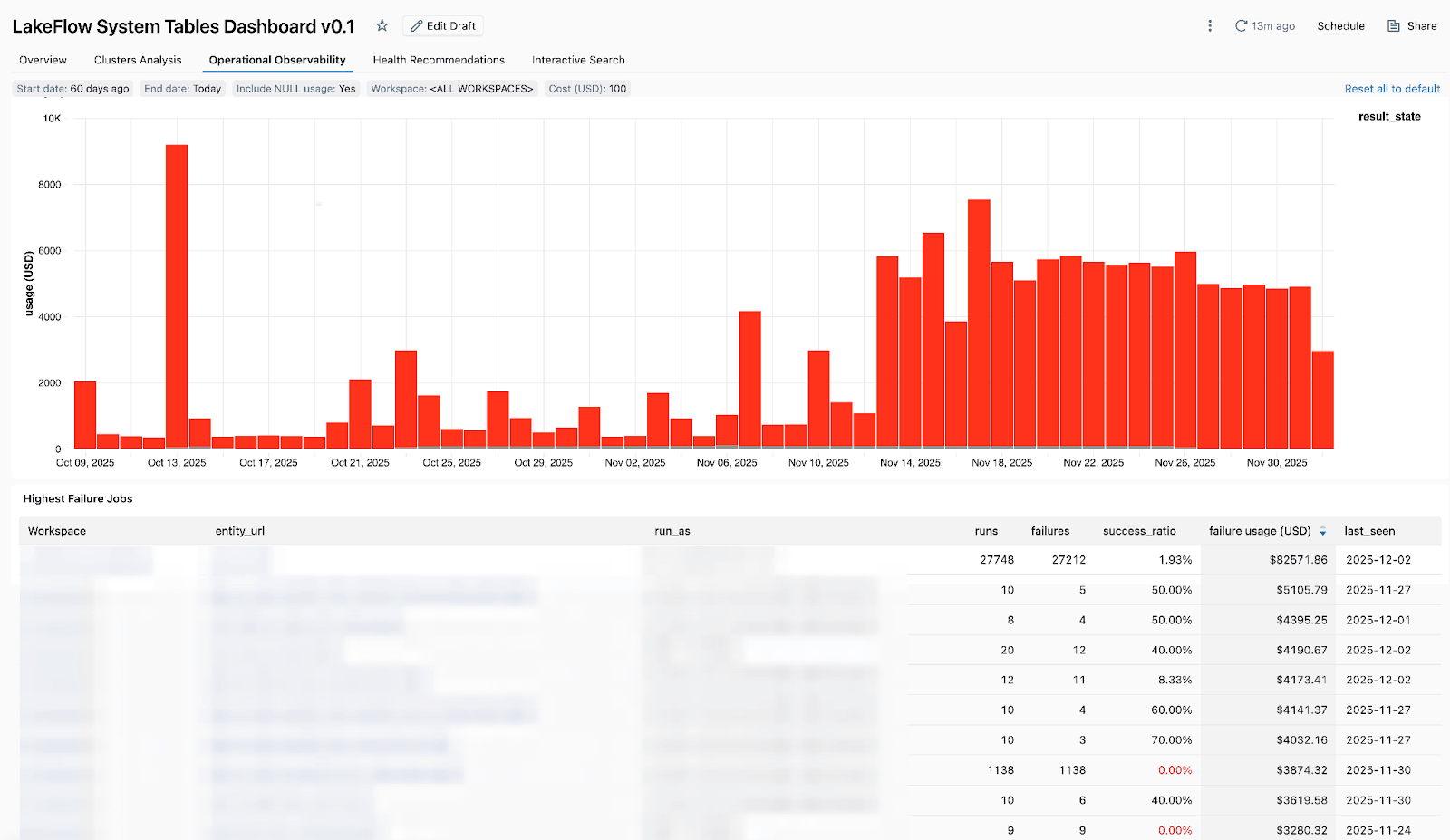
- Kostenintensive Jobs – so können Sie die teuersten Jobs und einzelnen Ausführungen der letzten 30 Tage oder im Zeitverlauf identifizieren. Die folgende Tabelle ist nach den kostenintensivsten Jobs im ausgewählten Zeitraum sortiert und zeigt deren Kostentrends im Zeitverlauf.
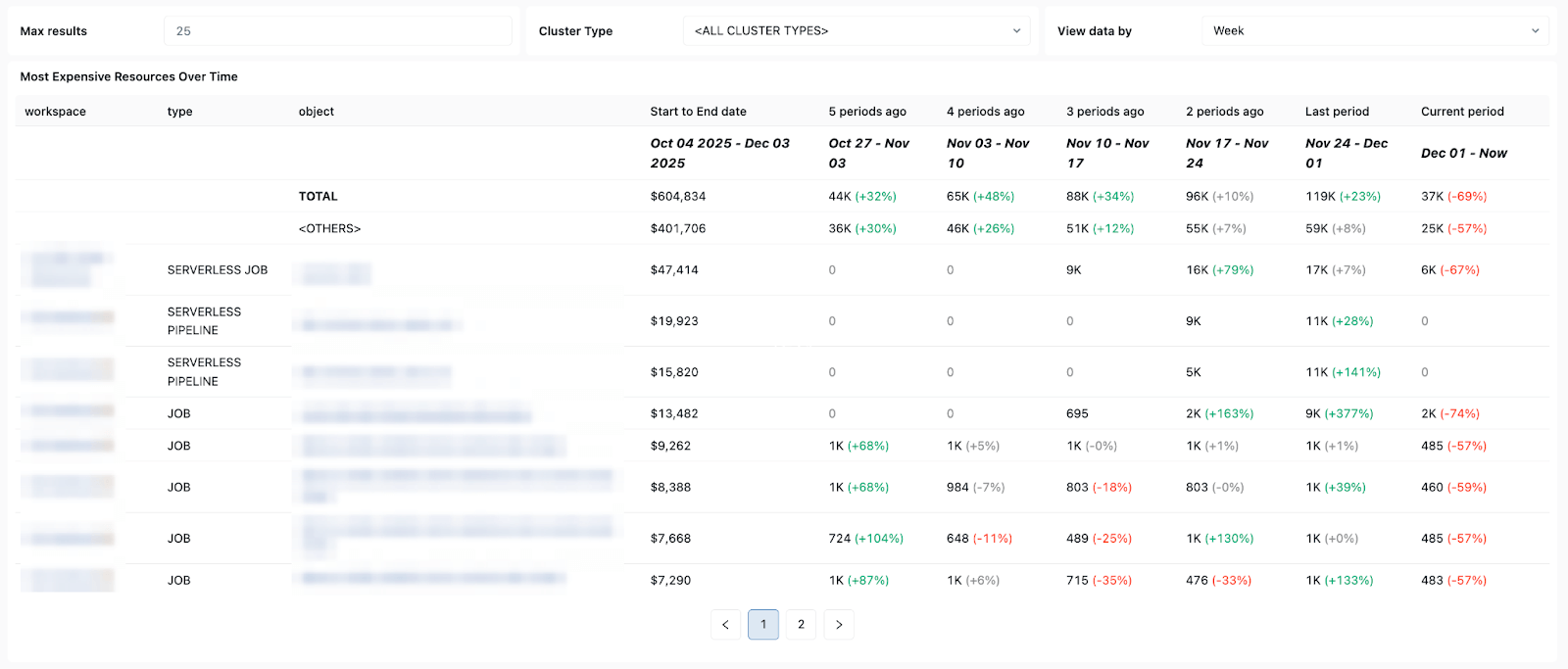
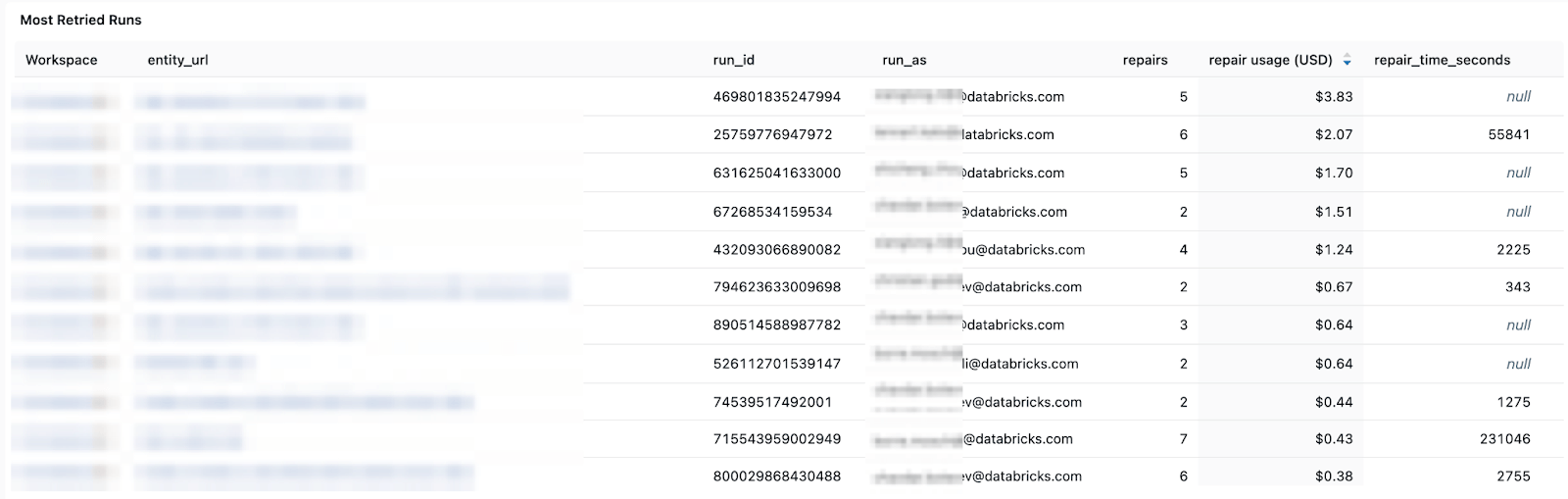
Kosten- und Wiederholungsmuster – helfen Ihnen dabei, Kostentrends und die Auswirkungen von Wiederholungen oder Reparaturläufen auf die Gesamtausgaben zu verfolgen.
- Konfigurationseinblicke – ermöglichen die Überprüfung von Cluster-Effizienz, Integritätsregeln, Timeouts und Laufzeitversionen für einen ordnungsgemäßen Betrieb.
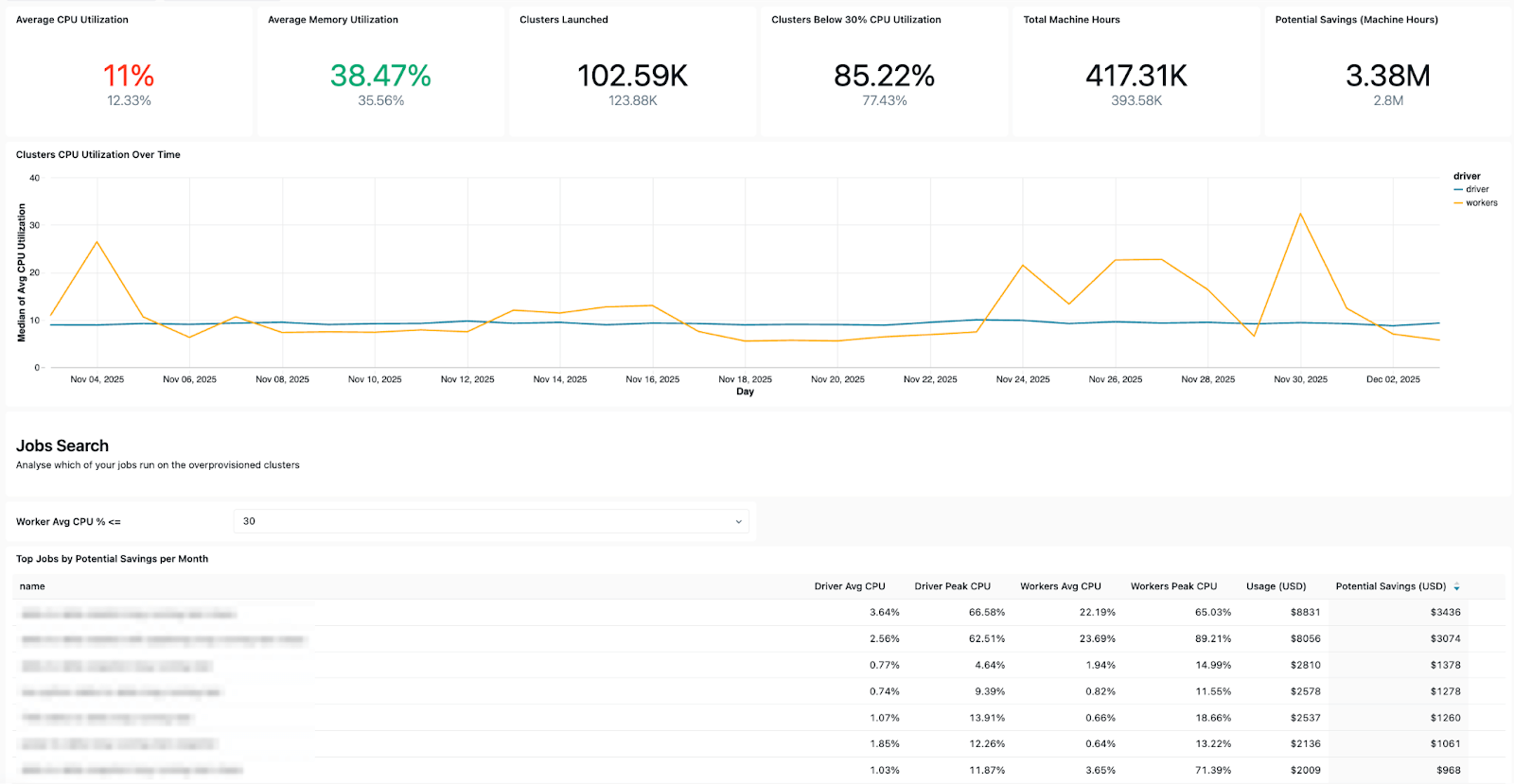
- Eigentümerdetails – damit Sie die „Ausführung-as“-Benutzer und Job-Ersteller leicht finden können, um zu wissen, an wen Sie sich wenden müssen.
Kurz gesagt, Databricks System Tables erleichtert die effiziente Überwachung, Prüfung und Fehlerbehebung von Lakeflow-Jobs im großen Maßstab und über Arbeitsbereiche hinweg. Mit klaren, einfachen und zugänglichen Visualisierungen Ihrer Jobs und Pipelines, die in der Dashboard-Vorlage verfügbar sind, kann jeder Dateningenieur, der Lakeflow verwendet, eine erweiterte Observability erreichen und konsistent produktionsreife, kostengünstige und zuverlässige Pipelines sicherstellen.
System Tables verwandeln die Telemetriedaten Ihrer Plattform in ein abfragbares Asset. Anstatt Signale von fünf verschiedenen Tools zusammenzufügen, schreiben Sie SQL-Abfragen für ein einheitliches Schema und erhalten in Sekundenschnelle Antworten.
Ihr Zukunfts-Ich wird es Ihnen um 3 Uhr morgens danken.
Weitere Informationen zu Systemtabellen finden Sie in den folgenden Ressourcen:
Neu bei Databricks? Testen Sie Databricks noch heute kostenlos!
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.