Wie Ontologien der Kernenergie dabei helfen zu Scale, um den globalen Energiebedarf zu decken
Implizites Anlagenwissen für eine Flotte, die sich auf eine Vervierfachung vorbereitet, explizit und abfragbar machen
von Dave Geyer, Mark Ghattas, Alex Hunt, Ben Mumma und Mark Gilbert
- Die Kernkraftwerksflotte wird unter verkürzten Genehmigungsfristen auf 400 GW ausgebaut. Der Anlagenkontext, über den erfahrene Mitarbeiter verfügen, muss in einer Form erfasst werden, die mit der Scale skaliert.
- Eine Ontologie kodiert Komponentenidentität, Systembeziehungen und die Quellen von Einschränkungen in einer strukturierten Schicht, die über Ausfälle, Änderungen und Personalwechsel hinweg bestehen bleibt.
- Auf Databricks und offenen Standards aufgebaut, unterstützt die Ontologie Konfigurationssteuerung, Lizenzierungsnachweise und Analysen aus verwalteten, versionierten und prüfbaren Daten.
Kernreaktoren gehören zu den komplexesten technischen Systemen, die wir im großen Scale betreiben. Ein sicherer, zuverlässiger Betrieb hängt von eng gekoppelter Physik, technischen Barrieren, rotierenden Maschinen, Fluidsystemen und einer Steuerungslogik ab, die sich sowohl im Normalbetrieb als auch bei einer langen Liste von denkbaren Störfällen korrekt verhalten muss.
Stellen Sie sich folgendes Szenario vor: Ein Speisewasserventil schließt sich unerwartet. Innerhalb von Sekunden muss ein Ingenieur wissen, welche nachgelagerten Systeme zuerst an Marge verlieren, welche Grenzwerte der technischen Spezifikation relevant werden und ob die aktuelle Anlagenkonfiguration seine Optionen beeinflusst. Die Daten zur Beantwortung dieser Fragen sind auf ein Dutzend Systeme verteilt. Die Zusammenhänge, die den Daten Bedeutung verleihen, existieren in den Köpfen erfahrener Mitarbeiter.
Die Kluft zwischen verfügbaren Daten und nutzbarem Wissen stellt heute eine der zentralen Herausforderungen im Betrieb von Kernkraftwerken dar. Eine Ontologie schließt diese Lücke, indem sie die Beziehungen in der Anlage explizit, abfragbar und nachvollziehbar macht.
Die Vereinigten Staaten erleben eine „nukleare Renaissance“, wie es sie seit Jahrzehnten nicht mehr gegeben hat. Ab 2024 sorgte eine Welle von Gesetzen und Exekutivmaßnahmen für Rückenwind für die Kernenergie, um alles von Anlagen der nationalen Sicherheit bis hin zum massiven Energiebedarf des KI-Wettlaufs mit Energie zu versorgen. Der ADVANCE Act modernisierte das Genehmigungsverfahren der U.S. Nuclear Regulatory Commission (NRC), senkte die Gebühren und wies die Kommission an, Brachflächen, wie zum Beispiel ehemalige Kohlekraftwerke, für Neubauten zu bewerten. Executive Order (EO) 14300 ging noch weiter: Sie verlagerte die Mission der NRC grundlegend von der Risikominimierung hin zur Abwägung der Vorteile der Kernenergie für die wirtschaftliche und nationale Sicherheit und verkürzte das derzeitige, durchschnittlich 42 Monate dauernde Genehmigungsverfahren auf eine verbindliche Frist von 18 Monaten für neue Reaktoren. EO 14302 berief sich auf den Defense Production Act (DPA), um die heimische nukleare Industriebasis wiederzubeleben, wobei der Schwerpunkt auf Brennstofflieferketten und der Wiederinbetriebnahme stillgelegter Anlagen lag. EO 14299 verknüpfte den Einsatz fortschrittlicher Kerntechnik ausdrücklich mit der Nachfrage von KI-Rechenzentren und wies diese als kritische Verteidigungseinrichtungen aus, die durch Reaktoren vor Ort mit Strom versorgt werden sollen. Unterdessen hat das US-Energieministerium (DOE) US-amerikanische Nuklearunternehmen mit Milliarden von Dollar gefördert, um den Fortschritt bei bestehenden Anlagen zu beschleunigen und Neulingen, die kleine modulare Reaktoren (SMRs) bauen, Starthilfe zu geben.
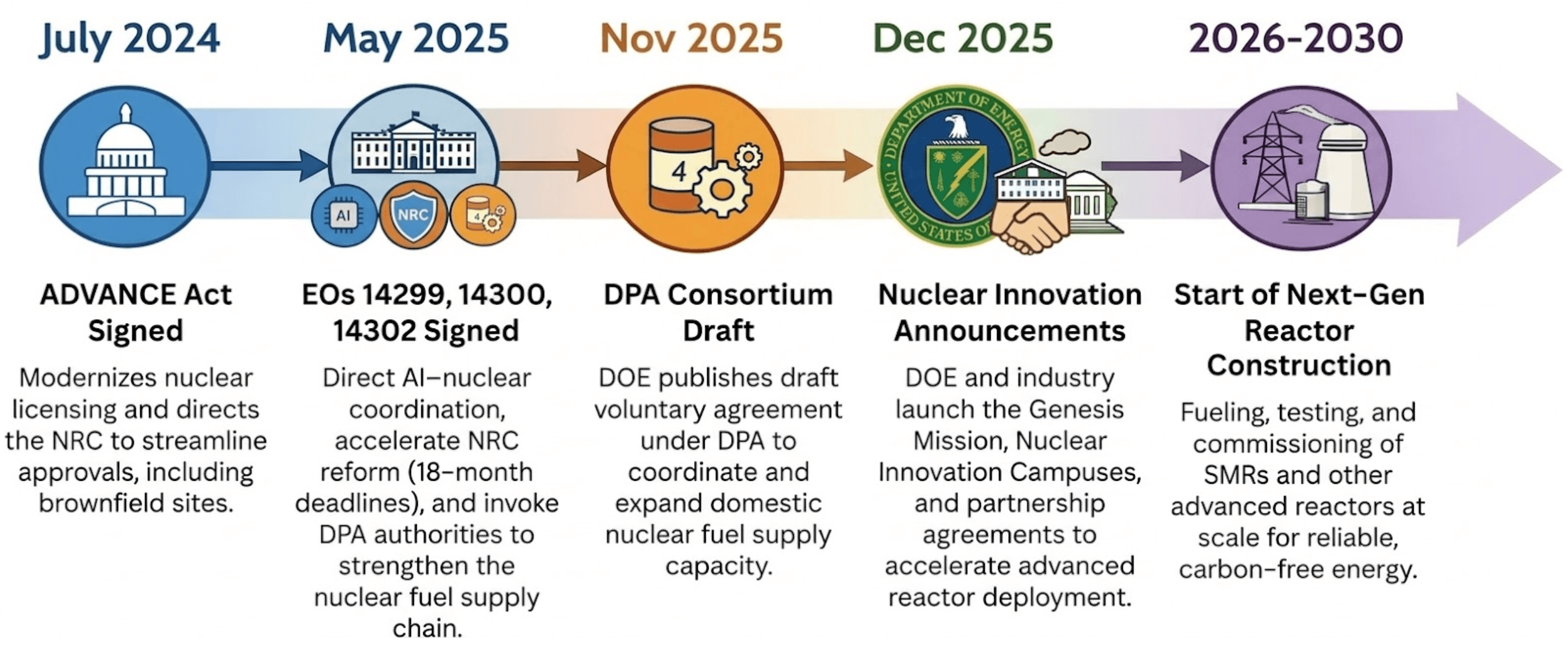
Diese Expansion trifft auf eine Belegschaft, die sich in die entgegengesetzte Richtung entwickelt. Die Zahl der verfügbaren Fachkräfte für die Entwicklung und Verteidigung von Genehmigungsanträgen schrumpft jährlich um etwa 10 %, und derselbe Druck reicht weit über das Genehmigungsverfahren hinaus. Neue Designs, Leistungssteigerungen, Arbeiten zur Lebensdauerverlängerung und digitale Modernisierungen beruhen alle auf derselben Argumentationskette: welche Ausrüstung angerechnet wird, welche Einschränkungen in der aktuellen Konfiguration gelten und welche kontrollierten Quellen die Schlussfolgerung stützen. Diese Kette zieht sich durch jede Phase des Lebenszyklus der Anlage, vom Design über die Inbetriebnahme bis hin zum täglichen Betrieb. Heute beruht sie immer noch weitgehend auf den Menschen, die sie anwenden.
Die Kosten von implizitem Wissen
Erfahrene Anlagenführer und Ingenieure verfügen über bemerkenswerte mentale Modelle ihrer Anlagen. Wenn ein leitender Reaktoroperator eine ansteigende Vibration an einer Umwälzwasserpumpe feststellt, bringt er dieses Signal sofort mit der Rolle der Pumpe in der aktuellen Konfiguration, bekannten Fehlermustern für diese Anlagenklasse, dem jüngsten Arbeitsverlauf und den Konsequenzen in Verbindung, die er bei einer Verschlechterung des Zustands erwarten würde. Sie wissen, welche bestätigenden Anzeichen wichtig sind, welche in die Irre führen und welche Fragen als Nächstes zu stellen sind.
Dieses mentale Modell repräsentiert Jahrzehnte an gesammeltem Kontext. Es stellt auch eine Schwachstelle dar.
Die Internationale Atomenergie-Organisation (IAEO) prognostiziert, dass die weltweite Kernenergiekapazität bis 2050 992 GWe erreichen könnte, was etwa dem 2,6-fachen des heutigen Niveaus entspricht. Neubauten bedeuten neue Designs, mehr Instrumentierung und mehr Konfigurationszustände, die Betreiber und Ingenieure verstehen müssen. Gleichzeitig zeigen Personaldaten des DOE, dass sich erfahrenes Personal in den älteren Altersgruppen konzentriert. Die Mitarbeiter mit dem fundiertesten Wissen über die Anlage gehen in den Ruhestand und nehmen ihre mentalen Modelle mit.
Neuere Mitarbeiter bringen zwar technische Fähigkeiten mit, es fehlt ihnen jedoch oft an Erfahrung mit standortspezifischen Fehlersignaturen und historischen Konfigurationen. Um den Betrieb in einer Anlage zu optimieren, benötigen sowohl neue als auch bestehende Mitarbeiter direkten Zugriff auf präzise, aktualisierte empirische Daten. Dieser Zugriff ermöglicht es den Mitarbeitern, fundierte Entscheidungen zu treffen. Die Herstellung dieser Datenverfügbarkeit unterstützt die Energieziele des DOE, indem die Belegschaft darauf vorbereitet wird, hoch instrumentierte Designs zu verwalten.
Die heutige Art und Weise, wie Kernkraftwerke Wissen verwalten, hat sich bewährt. Dadurch konnte die US-Flotte jahrzehntelang sicher betrieben werden. Die Ingenieure, die den Anlagenkontext im Kopf haben, sind kein Problem, das gelöst werden muss, sondern ein Asset (Vermögenswert), der erhalten und ausgebaut werden sollte. Reine Bewahrung reicht nicht aus, wenn der Auftrag von der Aufrechterhaltung von 100 GW auf 400 GW erweitert wird. Der derzeitige Ansatz kann nicht die Geschwindigkeit erreichen, die die Flotte heute erfordert. Nicht, weil er falsch ist, sondern weil er für ein anderes Tempo ausgelegt war.
Eine Ontologie, die die Lücke schließt
Die nukleare Branche hat dieses Problem erkannt, und mehrere Organisationen arbeiten bereits daran. Das Idaho National Laboratory hat DeepLynx entwickelt, ein Open-Source-Integrationsframework, das dafür konzipiert wurde, Engineering-Tools zu verbinden und den Kontext über den gesamten Lebenszyklus hinweg zu erhalten. Ihre DIAMOND -Initiative hat Datenstrukturen speziell für nukleare Auslegungs- und Betriebsdaten entwickelt. ISO 15926 und IEC 81346 etablierten gemeinsame Rahmenwerke für Lebenszyklusdaten und die Anlagenidentifikation. Die NRC-Leitlinien für digitale Systeme dr�ängen weiterhin auf Transparenz, Rückverfolgbarkeit und Performance-basierte Nachweise.
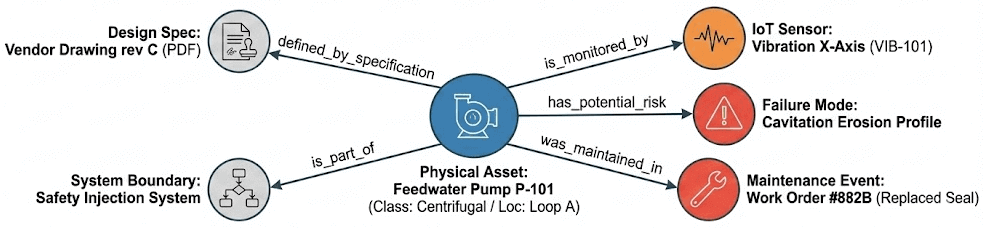
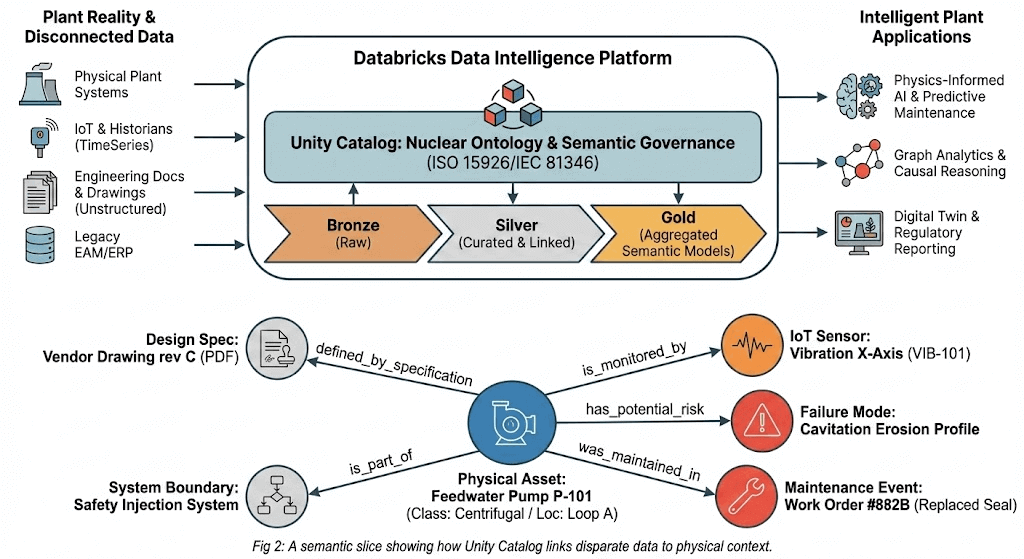
Was diese Bemühungen gemeinsam haben, ist ein gemeinsamer Ansatz. Der Ansatz beginnt mit der Definition der Objekte, die eine Anlage betrachtet (Systeme, Komponenten, Sensoren, Dokumente, Einschränkungen, Lizenzierungsverpflichtungen), und definiert dann, wie diese miteinander verbunden sind. Eine Pumpe gehört zu einem System. Ein Sensor misst eine Variable an einer Komponente. Ein Ventil definiert einen Teil einer Isolationsgrenze. Eine Komponente erbt Qualifikationsanforderungen von ihrem Installationsort. Eine Lizenzverpflichtung lässt sich auf die Konfigurationsannahmen zurückführen, die sie stützen. Diese Struktur ist eine Ontologie.
Zurück zu unserem bereits erwähnten Szenario: Der Austausch eines einzigen motorbetriebenen Ventils erfordert, dass ein Ingenieur Informationen aus mehr als 6 Systemen abruft, 3 bis 4 Namenskonventionen abgleicht und etwa 12 Dokumentenrevisionen überprüft, was 4 bis 8 Stunden dauern kann. Diese Arbeit geht verloren, wenn die nächste Frage oder das nächste Problem zur selben Komponente wieder auftaucht. Kerntechnische Systeme funktionieren durch Ausführung von Beziehungen und Abhängigkeiten. Eine Ontologie macht diese Beziehungen explizit, durchsuchbar und nachvollziehbar. Die Beziehungen in einem Kernkraftwerk sind nicht tabellarisch. Eine Änderung an einer Komponente wirkt sich auf die von ihr unterstützte Systemgrenze, den Strang, zu dem sie gehört, und die von ihr geerbten Einschränkungen aus. Graphenstrukturen lassen sich auf natürliche Weise auf diese Art von Logik abbilden, aber das bedeutet nicht, dass Sie eine separate Graphendatenbank benötigen. Ontologien kodieren diese Beziehungen als Tripel, atomare Einheiten, die zwei Entitäten mit einer bestimmten Beziehung linken. Sie kodieren auch Geschäftsregeln direkt in die Strukturstandards, wie z. B. RDF (Resource Description Framework) und SHACL (Shape Constraint Language). Konkrete Kriterien definieren, was gültige Daten ausmacht, z. B. Sicherheitsbeschränkungen, Konfigurationsregeln und Qualifikationsanforderungen. Diese Regeln werden Teil des Datenmodells selbst, sodass Verstöße strukturell sichtbar werden und nicht erst bei einer Überprüfung von jemandem entdeckt werden müssen.
Die Ontologie und ihre kuratierten Tripel sind das dauerhafte Asset (Vermögenswert). Sie bestehen über jede spezifische Anwendung oder Benutzeroberfläche hinaus fort. Offene Standards wie RDF und OWL (Web Ontology Language) stellen sicher, dass die Daten portabel bleiben, sodass sie mit bestehenden Branchenontologien übereinstimmen und saubere Austauschformate für Lieferantendaten und Lizenzeinreichungen schaffen. Es gibt keine festen Abhängigkeiten. Die Daten müssen aber dennoch irgendwo verwaltet, versioniert und im Scale abgefragt werden.
Für Anwendungen in der Kerntechnik muss eine Ontologie drei Dinge gut erfüllen, damit sich ihr Aufbau lohnt.
- Kanonische Identität im Zeitverlauf. Dieselbe Pumpe könnte im Arbeitsmanagement als "P-123", im Historian als "P123_DIS_PRES" und in Zeichnungen als "P-123A" erscheinen. Die Ontologie führt diese zu einer einzigen Entität zusammen und verfolgt, wie sich diese Entität durch Austausche, Änderungen und Ausfälle verändert. Sie können anhand derselben Struktur beantworten, "was jetzt installiert ist" und "was installiert war, als wir diese Entscheidung getroffen haben".
- Explizite Beziehungen. Nicht nur "diese Komponente existiert", sondern "diese Komponente gehört zu Strang A, definiert einen Teil der Sicherheitseinschlussgrenze, wird von diesen Sensoren gemessen und erbt die Umgebungsqualifizierungsanforderungen (EQ) von ihrem Standort." Die Beziehungen, die erfahrene Ingenieure im Kopf haben, werden sichtbar und nachvollziehbar.
- Explizite Herkunftsangabe für Asset (Vermögenswert)-Einschränkungen. Wenn wir ein Ventil mit einem bestimmten Leckage-Grenzwert haben, ist es entscheidend zu verstehen, woher diese Einschränkung kommt und warum. Eine Ontologie führt dies explizit auf die spezifischen technischen Spezifikationen zurück, die dieser Einschränkung zugrunde liegen.
{kind=link}
Arbeiten innerhalb der regulatorischen Grenzen des Nuklearbereichs
Die Nuklearindustrie ist eine der am stärksten regulierten Branchen der Welt, und das aus gutem Grund. Es können verschiedene regulatorische Rahmenbedingungen gelten, einschließlich Ausfuhrkontrollvorschriften wie die Export Administration Regulations (EAR) und Title 10 of the Code of Federal Regulations, Part 810 (10 CFR Part 810), sowie Datenschutz und aufkommende Anforderungen an die KI-Governance wie die GDPR und das EU-KI-Gesetz. Diese Verpflichtungen können beeinflussen, wo Analysen stattfinden, wie Nachweise gespeichert werden, welche Informationen über Grenzen hinweg oder außerhalb definierter Grenzen geteilt werden können und wer darauf zugreifen kann. Zusammengenommen gestalten diese Vorschriften direkt, wie die digitale Infrastruktur in der Kernenergie konzipiert, angewendet und verwaltet wird.
Eine Ontologie bietet eine Möglichkeit, die Struktur von sensiblen Inhalten zu trennen. Anlagenbeziehungen, Einschränkungen und Konfigurationslogik können als eine eigene Schicht definiert und verwaltet werden, getrennt von den darunter liegenden operativen Daten. Ingenieure können mit dem vollständigen relationalen Kontext der Anlage arbeiten und abfragen, wie Komponenten verbunden sind, welche Einschränkungen gelten und woher diese Einschränkungen stammen, ohne dass die zugrunde liegenden operativen Daten kontrollierte Umgebungen verlassen. Bibliotheken, die auf der Ontologiestruktur aufbauen, lassen sich als verwaltete Assets (Vermögenswerte) versionieren, überprüfen und teilen, wobei sie auf realer Anlagenphysik beruhen, ohne geschützte Information preiszugeben.
Für Neubauten ist dies besonders relevant. Entwurfsverifizierung, Zusammenarbeit mit Lieferanten und Lizenzierungsanalysen erfordern allesamt den Austausch technischer Informationen zwischen mehreren Organisationen, der einer genauen Exportkontrolle unterliegt. Eine Ontologie ermöglicht es, die Struktur und die Zusammenhänge zu teilen, die Engineering-Entscheidungen zugrunde liegen, ohne sensible Betriebsdaten oder geschützte Designdetails weiterzugeben. Lieferanten, Erbauer und Betreiber können auf der Grundlage eines gemeinsamen Rahmens arbeiten, während jede Organisation die Kontrolle über ihre eigenen geschützten Informationen behält. Das reduziert die Reibungsverluste, die Nuklearprogramme mit mehreren Beteiligten typischerweise verlangsamen, und hilft dabei, neuartige Entwürfe im Schedule zu halten.
Für Betriebsanlagen gilt dasselbe Prinzip. Sie können Reasoning-Frameworks entwickeln und validieren, neue Mitarbeiter in den Anlagenkontext einarbeiten und Compliance-Pakete vorbereiten, ohne sensible Daten außerhalb der entsprechenden Grenzen zu verschieben.
Eine praktische Möglichkeit, die Funktion einer Ontologie zu verstehen, ist, einen einzelnen Workflow durchzugehen.
Anwendungsfall: Design-Validierung und Konfigurationssteuerung
Designvalidierung und Konfigurationskontrolle werfen immer wieder die gleiche Frage auf: Ist diese Änderung angesichts der aktuellen Konfiguration der Anlage zulässig und können wir dies aus kontrollierten Quellen nachweisen? Jedes Mal, wenn Sie ein sicherheitsrelevantes Bauteil anfassen, eine Entwurfseingabe aktualisieren, ein Teil austauschen oder eine Berechnung überarbeiten, müssen Sie den Kontext systemübergreifend wiederherstellen. Was genau ist dieses Bauteil in dieser Anlage? Wo ist es installiert? Welche Sicherheitsfunktion oder Grenze unterstützt es? Welche Anforderungen erbt es von diesem Standort? Welche Dokumente regeln das Arbeitsfenster? Die Daten zur Beantwortung dieser Fragen sind vorhanden. Die Verbindungen zwischen den Daten in der Regel nicht.
Stillstände sind dafür ein Härtetest. Ausrüstung wird unter Schedule-Druck ausgetauscht. Arbeiten vor Ort, Beschaffung und Engineering-Überprüfung laufen parallel ab. Die Fehler, die wirkliche Probleme verursachen, sind selten dramatisch. Es sind unauffällige Abweichungen, die erst spät zutage treten: eine Qualifikationsgrundlage, die nicht zum Installationsort passt, eine veraltete Zeichnungsrevision, eine falsche Strangzuordnung, eine geänderte Annahme zu den Systemgrenzen oder ein Grenzwert für den Betriebsbereich, der aus der falschen Quelle stammt.
Ein gängiges Beispiel ist der Austausch eines motorbetriebenen Ventils an einer sicherheitsrelevanten Leitung. Bevor ein Ingenieur den Austausch überhaupt bewerten kann, muss er den Kontext wiederherstellen: zu welchem System und welcher Teilanlage es gehört, welche Grenze oder angerechnete Funktion es unterstützt, welche EQ- und seismischen Anforderungen an diesem Standort gelten, welche Betriebsgrenzen für die Komponente gelten und welche kontrollierten Dokumente diese Grenzen festlegen.
Heute wird jeder dieser Schritte manuell ausgeführt. Der Ingenieur öffnet den Arbeitsauftrag für eine Kennzeichnungsnummer. Separat navigiert er zum Zeichnungssatz für den Abgrenzungskontext. Er ruft Qualifikations- und seismische Dateien aus einem anderen System auf. Er sucht die maßgeblichen Berechnungen für die Betriebsgrenzen heraus und prüft den Revisionsstatus. Jede Abfrage ist ein separates System, eine separate Suche, eine separate Ermessensentscheidung darüber, ob die Informationen aktuell sind. Dann fasst der Ingenieur alles im Kopf zusammen, um festzustellen, ob der Austausch akzeptabel ist. Wenn später jemand anderes die gleiche Frage stellt, ein Inspektor, ein Prüfer oder eine andere Schicht, beginnt der Prozess von neuem.
Eine Anlagenontologie ändert dies, indem sie die Nachweiskette zu einem Teil der Struktur macht. Die Komponente hat eine kanonische Identität. Diese Identität verweist auf ihren Installationsort und Konfigurationszustand und von dort aus auf die folgenden Anforderungen: Strangzuweisung, Abgrenzungsrolle, EQ- und seismische Einschränkungen, Grenzen der Betriebshüllkurve und die maßgeblichen Quellen, die sie definieren. Der Ingenieur geht von der Komponente aus, und die Beziehungen sind bereits vorhanden. Der gesamte Lebenszyklusdatensatz – Auslegungsprüfung, Beschaffung, Herstellung, Tests und Versand – ist von dieser einzigen Identität aus erreichbar. Unterstützende Qualitätsdokumente wie NDE-Berichte, Werksabnahmeprüfungen und rückverfolgbare Referenzen sind direkt mit der Komponente verknüpft, anstatt in separaten Systemen darauf zu warten, gefunden zu werden.
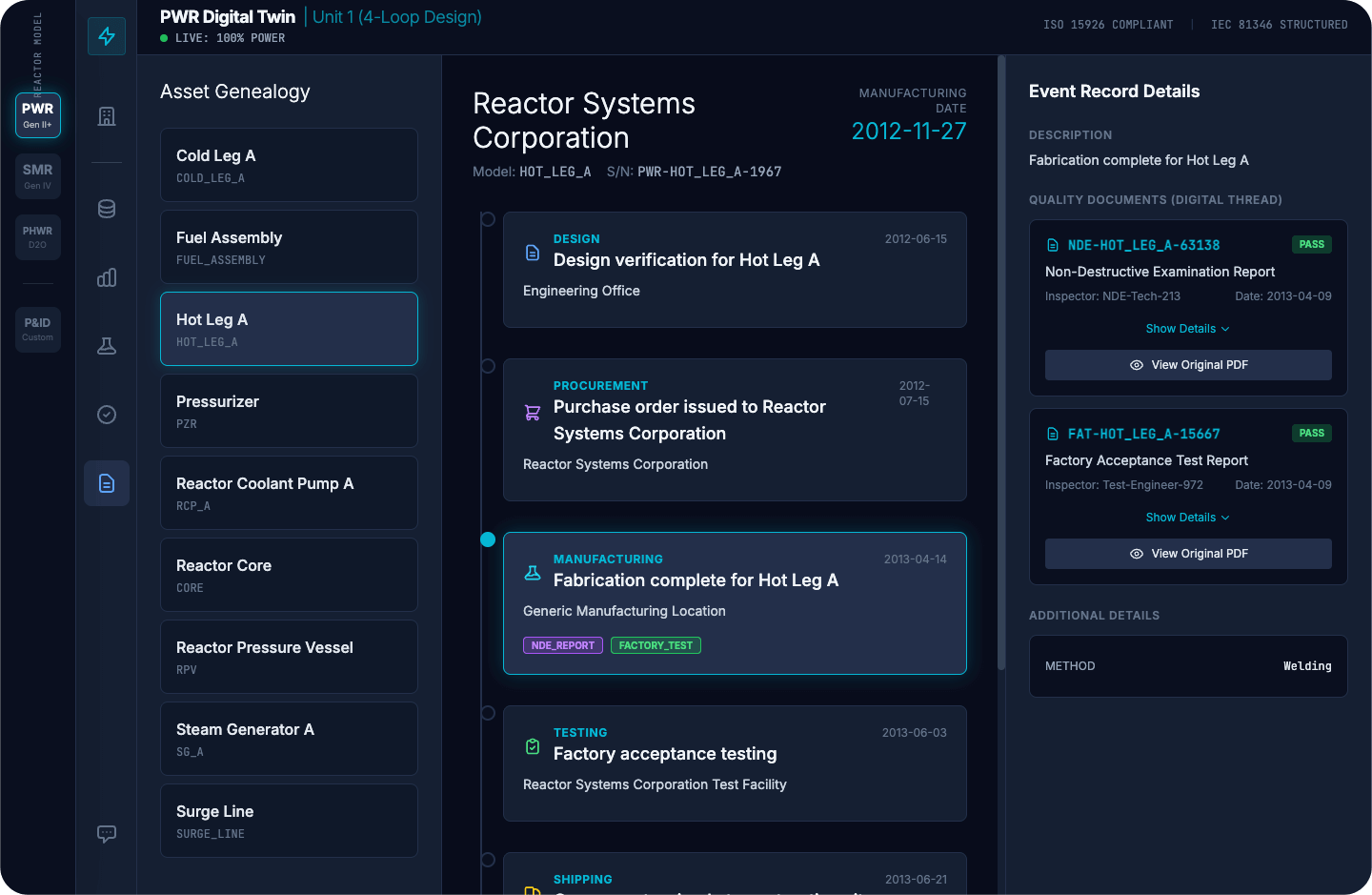
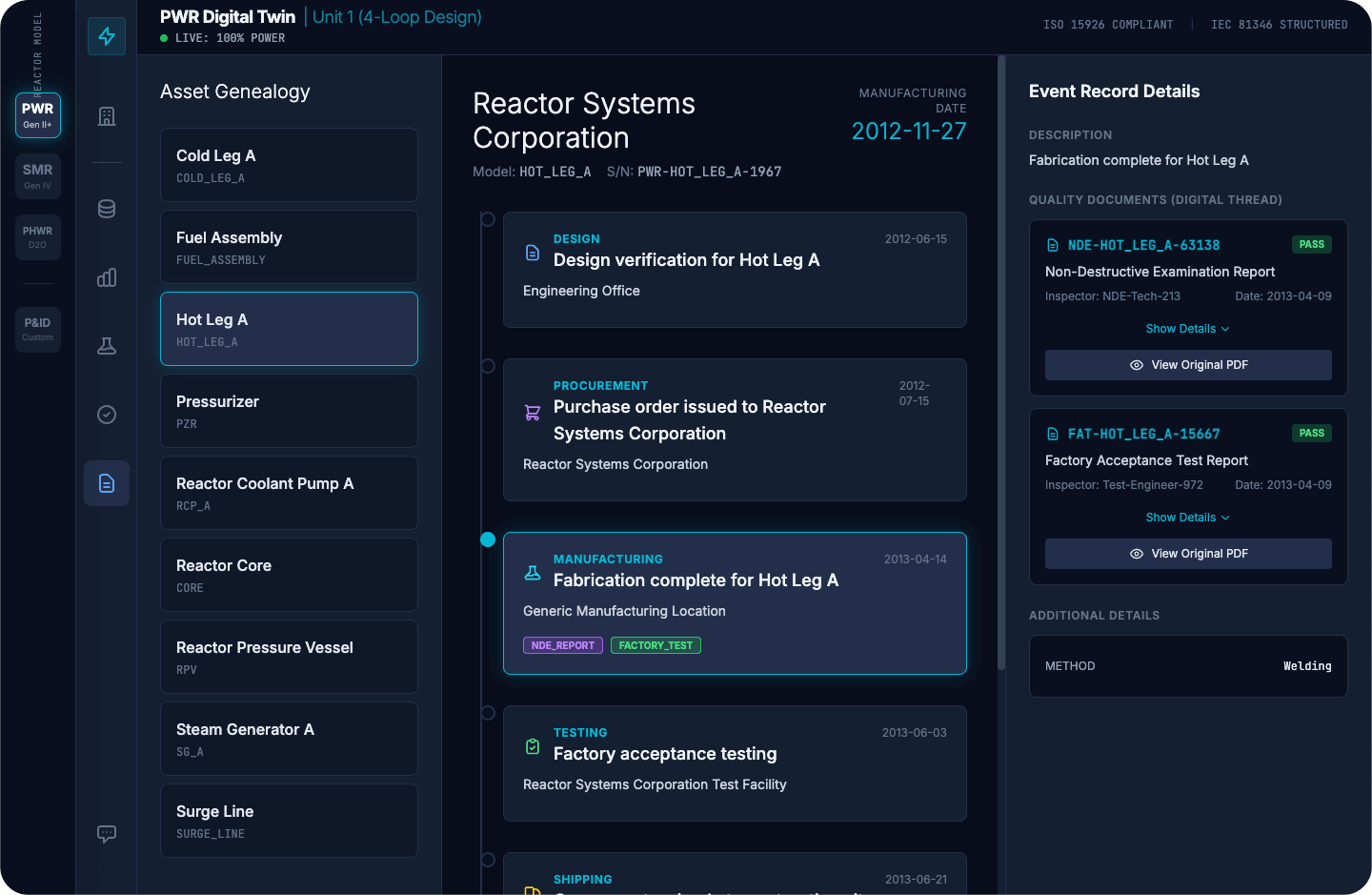{kind=link}
Da die Randbedingungen und ihre Quellen in der Struktur kodiert sind, können Tools entwickelt werden, die kennzeichnen, wenn etwas nicht übereinstimmt, wie z. B. eine falsche EQ-Basis, eine veraltete Revision oder eine nicht übereinstimmende Strangzuweisung. Die Entscheidung trifft weiterhin der Ingenieur. Die Infrastruktur bringt sie schneller ans Ziel und liefert ein vollständiges Bild anstatt eines unvollständigen, das unter Zeitdruck zusammengestellt wurde.
Betrieb der Ontologie in Scale
Eine Ontologie ist nur so nützlich wie die Plattform, auf der sie läuft. Beziehungen, Identitäten und Constraints müssen geregelt, versioniert und in Scale abfragbar sein. Die Plattform muss bei Ausfällen, Modifikationen, temporären Änderungen und Dokumentaktualisierungen mit dem tatsächlichen Zustand der Anlage abgeglichen bleiben und eine Auditierbarkeit aufweisen, die einer Überprüfung standhält. Wenn dies nicht gelingt, entsteht eine Drift in der Ontologie, und die Nutzer verlieren das Vertrauen in sie.
Die Ontologie kodiert die Beziehungen der Anlage, Einschränkungen und Konfigurationslogik in offenen Standards. Die Plattform, die sie steuert, muss dieser Offenheit entsprechen. Wenn die Governance-Schicht proprietär ist, spielt es keine Rolle, wie portabel die Ontologie auf dem Papier ist. In einer Branche, in der der Lebenszyklus-Datensatz einer Komponente von einem Betreiber prüfbar, von der NRC überprüfbar und über Jahrzehnte hinweg von einem OEM nachverfolgbar sein muss, ist die Fähigkeit, Daten sauber zwischen Organisationen und Tools auszutauschen, eine Grundvoraussetzung.
Databricks basiert auf offenen Formaten und offenen Schnittstellen. Ontologie-Tripel, Komponentenregister, Beziehungstabellen und Einschränkungsdatensätze befinden sich alle auf Delta Lake und sind über andere Tools zugänglich. Wenn Sie Teilmengen mit einem Partner oder einer Regulierungsbehörde teilen müssen, sind die Formate standardisiert. Es ist noch nichts festgelegt.
Auf dieser Grundlage werden bei Arbeiten im nuklearen Bereich immer wieder vier Funktionalitäten deutlich:
- Einheitliche Governance Wenn die QA oder die NRC fragt, wie ein bestimmtes Asset (Vermögenswert) gesteuert wurde, muss die Antwort über Komponentenidentität, Dokumentenkontrolle, Beziehungen und Referenzen zur Genehmigungsbasis hinweg konsistent sein. Das scheitert, wenn jeder dieser Bereiche einem separaten Berechtigungsmodell unterliegt. Unity Catalog bietet eine einzige Governance-Ebene für die gesamte Ontologie. Berechtigungen, Änderungsverfolgung und Auditierung gelten einheitlich für jedes Asset, sodass es eine belastbare Antwort gibt statt vier unvollständigen.
- Zeitindizierte Konfiguration. Engineering- und genehmigungsrechtliche Entscheidungen hängen vom Zustand der Anlage zu einem bestimmten Zeitpunkt ab. Gemäß 10 CFR 50.59 beurteilen Anlagen, ob eine vorgeschlagene Änderung einer vorherigen Genehmigung durch die NRC bedarf, indem sie ihre Auswirkungen auf die bestehende Genehmigungsgrundlage bewerten. Diese Bewertung ist nur so gut wie die Konfigurationsdaten, die ihr zugrunde liegen, und dasselbe gilt für die Feststellung der Betriebsfähigkeit, Fragen zur Sollwertbasis, die Validierung nach Änderungen und routinemäßige Ausfallprüfungen. Alle erfordern die Kenntnis, was installiert war und welche Revisionen zum Zeitpunkt der Entscheidung maßgeblich waren. Die Zeitreise-Funktion von Delta Lake unterstützt „As-designed“-, „As-built“-, „As-installed“- und „As-maintained“-Ansichten aus denselben zugrunde liegenden Daten, ohne dass separate manuelle Snapshots erforderlich sind. Jede Tabellenversion wird beibehalten und ist abfragbar, sodass die Rekonstruktion des Anlagenzustands zu einem beliebigen früheren Entscheidungspunkt eine Abfrage und kein Archäologieprojekt ist.
- Reproduzierbare Nachweisketten. 10 CFR 50 Appendix B legt die Anforderungen an die Qualitätssicherung für sicherheitsrelevante Systeme, Strukturen und Komponenten fest. Es reicht nicht aus, zum richtigen Schluss zu kommen, wenn man die Grundlage nicht aus kontrollierten Quellen reproduzieren kann. Die automatisierte Herkunftsverfolgung von Unity Catalog erfasst, welche Dokumentenrevisionen, Einschränkungsdatensätze und Beziehungsversionen in einem bestimmten Workflow verwendet wurden. Das Audit-Log von Delta Lake protokolliert jede Mutation der zugrunde liegenden Daten. Wenn ein Prüfer oder Inspektor wissen muss, was eine Entscheidung untermauert hat, liefert die Plattform im Zusammenspiel eine vollständige, mit Timestamp versehene Antwort, ohne dass jemand die Informationen nachträglich zusammensetzen muss.
- Analysen auf verwalteten Daten. Governance, Versionierung und Datenherkunft stellen sicher, dass sich die Daten in einem vertrauenswürdigen Zustand befinden. Die nächste Frage ist, was Sie damit anfangen können, wenn sie erst einmal vorhanden sind. Databricks Lakeflow Jobs stellen die Orchestrierungsschicht für Analyse-Pipelines bereit, die direkt auf den verwalteten Assets (Vermögenswerten) der Ontologie arbeiten. MLflow verfolgt Modellversionen, Trainingsdaten, Parameter und Ausgaben mit der gleichen Sorgfalt, die Unity Catalog auf die Daten selbst anwendet. Modelle zum Monitoring können Degradationsmuster über eine gesamte Ventilklasse hinweg verfolgen, indem sie Verlauf, Sensortrends und Konstruktionsgrenzen aus der verwalteten Struktur abrufen. Vorgeschlagene Änderungen können automatisch anhand der Lizenzierungsgrundlage überprüft werden, da die Einschränkungen und ihre Quellen bereits kodiert sind. Die Modelle und ihre Ausgaben lassen sich durch dieselbe Datenherkunft, die die Plattform für alles andere bereitstellt, bis zu den kontrollierten Quellen zurückverfolgen. Diese Rückverfolgbarkeit ist es, die Analysen, die als Entscheidungsgrundlage dienen, von Analysen unterscheidet, die in einem regulierten Umfeld tatsächlich angerechnet werden können.
Dies knüpft direkt daran an, wohin die Investitionen des DOE fließen. Die Genesis Mission des DOE entwickelt die nächste Generation digitaler Werkzeuge für den Energiesektor, die fortschrittliche Simulationen, digitale Zwillinge, KI-gestütztes Design und operative Analytik umfassen. Die Ontologie und die verwalteten Daten, die Sie heute für Konfigurationskontrolle und Compliance einrichten, sind dieselben Asset (Vermögenswert)e, auf denen diese Programme aufbauen werden. Die Infrastruktur, die die heutigen Zykluszeiten und Nacharbeiten reduziert, wird zur Grundlage für das, was als Nächstes kommt. Eine offene Plattform bedeutet, dass die Investition fortgeführt wird und nicht neu geschrieben werden muss, wenn sich die Anforderungen weiterentwickeln.
Geschäftliche und strategische Auswirkungen
Der Wert einer Ontologie potenziert sich. Da die Struktur bestehen bleibt, wird die Arbeit, die zur Klärung des Kontexts einer Komponente für eine Entscheidung geleistet wird, auf die nächste übertragen.
Im bestehenden Anlagenpark verlängern Anlagen ihren Betrieb, führen komplexere Modifikationen durch und das alles mit einem kleineren Pool an erfahrenen Mitarbeitern und unter engeren regulatorischen Zeitvorgaben. Was früher Tage dauerte, um aus getrennten Systemen Daten für ein Konformitätspaket zusammenzustellen, kann nun in einer strukturierten Abfrage zu bereits bestehenden Zusammenhängen komprimiert werden. Prüfbereite Nachweispakete, für die früher die Grundlage aus dem Gedächtnis rekonstruiert werden musste, können nun aus der bereits vorhandenen Struktur zusammengestellt werden. Der Prozentsatz der Assets mit aufgelöster kanonischer Identität über verschiedene Datenquellen hinweg steigt mit zunehmender Reife der Ontologie stetig an.
Bei Neubauten beginnen die Vorteile in der Designphase und setzen sich über das Genehmigungsverfahren hinweg fort. Wenn die Ontologie frühzeitig vorhanden ist, werden die Beziehungen zwischen Designabsicht, angerechneten Funktionen und Lizenzierungsverpflichtungen strukturiert, bevor die erste Komponente ausgeliefert wird. Widersprüche bei den Einschränkungen werden während der Entwurfsprüfung gemeldet, da die Einschränkungen und ihre Quellen in der Struktur kodiert sind. Andernfalls werden sie typischerweise bei der Installation vor Ort entdeckt, wenn die Kosten für die Korrektur um Größenordnungen höher sind. Nachweise für die Lizenzierung entstehen mit fortschreitendem Design, anstatt im Nachhinein rekonstruiert zu werden. Das Ergebnis sind weniger Nacharbeitszyklen, eine schnellere Koordination zwischen Anbietern und Konstrukteuren und geringere Kosten für den Sicherheitsnachweis. Der Sicherheitsstandard ändert sich nicht. Der erforderliche Aufwand, um dessen Einhaltung nachzuweisen, schon.
Sobald die Ontologie für die Konfigurationssteuerung funktioniert, bleibt es nicht dabei. Dieselben Beziehungen, die einen Ventilaustausch unterstützen, unterstützen auch das Programm zur Zustands-Monitoring, das die Degradation für diese Ventilklasse Tracking. Dieselbe Herkunft der Randbedingungen, die in ein Compliance-Paket einfließt, fließt auch in die Genehmigungsanalyse für die nächste Leistungssteigerung ein. Da die Ontologie auf einer standardkonformen Identität und der Herkunft von Randbedingungen aufbaut, bietet sie OEMs, Engineering und Regulierungsbehörden einen gemeinsamen Bezugspunkt anstatt eines weiteren Systems, das integriert werden muss.
Das verändert, wie sich neue Entwickler einarbeiten. Anstatt sich einen Überblick zu verschaffen, indem sie die richtige Person zum Fragen finden, können sie eine Komponente abfragen und deren Train-Zuweisung, Grenzrolle, Quellen für Einschränkungen und den Wartungsverlauf an einem Ort einsehen. Institutionelles Wissen wird zur Infrastruktur und geht nicht mehr verloren, wenn Mitarbeiter in den Ruhestand gehen. Erfahrene Mitarbeiter verbringen weniger Zeit damit, dieselben kontextbezogenen Fragen zu beantworten, und haben mehr Zeit für die Ermessensentscheidungen, die tatsächlich ihr Fachwissen erfordern.
Wenn sich die Flotte in ihrer Kapazität vervierfachen und gleichzeitig modernisieren soll, ist dies die Art von Infrastruktur, die frühzeitig geplant und weitergeführt werden muss.
Die Grundlage für die nukleare digitale Transformation schaffen
Sind Sie bereit zu erfahren, wie Ontologien das Wissensmanagement und die Entscheidungsfindung in der Kernenergiebranche stärken können? Download Sie den Databricks Solution Accelerator for Digital Twins in Manufacturing, beschleunigen Sie Ihre Implementierung mit Ontos from Databricks Labs, oder lesen Sie den Artikel So erstellen Sie digitale Zwillinge für operative Effizienz im Databricks-Blogs, um die Referenzarchitektur in der Praxis zu sehen.
Wenn Sie diese Konzepte auf Ihre eigenen Systeme, Workflows und Governance-Einschränkungen anwenden möchten, wenden Sie sich an Ihr Databricks Account-Team, um einen eingegrenzten Ausgangspunkt zu besprechen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.