Wie man Dokumentenaktivierungs-Workflows mit Genie und Agent Bricks transformiert
Verwandeln Sie Dokumente mit Databricks in wertvolle Geschäftseinblicke
von Elena Tesser
-Manuelle Dokumentenextraktions-Workflows in Branchen wie Medien, Kommunikation und Gaming verlangsamen Teams, führen zu Umsatzeinbußen und erhöhen das Compliance-Risiko.
-Unternehmen können AI/BI Genie, Agent Bricks und Unity Catalog zusammenbringen, um einen rigorosen Multi-Agenten-Workflow zu etablieren, der wichtige Dokumente aus Marketing, Recht, Finanzen, Personalwesen und mehr in verwaltete, durchsuchbare und umsetzbare Daten umwandeln kann.
-Durch den Übergang von der Extraktion zur Multi-Agenten-Orchestrierung und zum System-Write-back können Organisationen nahtlos von der Verarbeitung über das Lesen bis zur Aktivierung ihrer Dokumente übergehen.
In Unternehmen besteht eine Lücke bei der Dokumentenintelligenz
Unternehmen arbeiten mit riesigen Mengen an Dokumenten, von Verträgen über Arbeitsverträge, Talentvereinbarungen und NDAs bis hin zu Werbe-Schaltaufträgen und Rahmenverträgen und mehr. Jedes Dokument enthält wertvolle Einblicke in potenzielle Einnahmen, Risiken und Verpflichtungen, doch die Art und Weise, wie die meisten Unternehmen damit umgehen, hat sich seit Jahrzehnten kaum verändert.
Doch selbst wenn Unternehmen zunehmend KI integrieren, um schneller voranzukommen, verlassen sich viele Teams immer noch darauf, dass Menschen PDFs lesen, Felder in Tabellenkalkulationen kopieren und Daten in ERP-, CRM- und Planungssysteme eingeben. Dies birgt erhebliche Risiken. Manuelle Verarbeitungsworkflows führen zu Verzögerungen und potenziellen Einnahmeverlusten aufgrund menschlicher Fehler, während mangelnde Governance bedeutet, dass Teams ihre Berichterstattung nicht zuverlässig überprüfen können.
Punktuelle Tools und Legacy-Architekturen stoßen an ihre Grenzen
Führungskräfte verstehen, dass KI-Automatisierung ihnen helfen kann, diese Herausforderungen zu meistern. Viele zögern jedoch, KI vollständig in ihre Workflows zu integrieren, da frühe Investitionen wie OCR-Engines, Vertragsmanagement-Systeme und domänenspezifische Einzellösungen oft hinter den Erwartungen zurückgeblieben sind. Selbst wenn Unternehmen mit GenAI experimentieren, berichten viele Finanz-, Rechts- und Betriebsteams immer noch von geringem realisiertem Wert aus KI-Investitionen. Das Problem ist jedoch nicht die KI-Automatisierung selbst, sondern die fragmentierten, unvollständigen Datenfundamente, auf denen diese frühen Tools aufbauen.
Ohne ein einheitliches, gut verwaltetes Datenfundament fehlt der branchen- und unternehmensspezifische Kontext, sie sind von wichtigen Unternehmenssystemen isoliert und nur zum Lesen, nicht zur Aktivierung gedacht. Schlimmer noch, wenn Sie versuchen, darauf einen Agenten-Workflow aufzubauen, erhalten Sie eine Erfahrung, die unzusammenhängend, inkonsistent und unmöglich zu skalieren ist.
Ein Plattformansatz für die Dokumentenaktivierung
Der Wendepunkt für die Dokumentenintelligenz kommt, wenn ein Unternehmen von der Verwaltung von Workflows mit punktuellen Einzellösungen zur Erstellung auf einem einheitlichen, verwalteten Datenfundament übergeht. Dieser Wandel eröffnet die Tür zu einer wirklich einheitlichen, skalierbaren Multi-Agenten-Erfahrung, die es technischen und nicht-technischen Benutzern gleichermaßen ermöglicht, ihre strukturierten und unstrukturierten Geschäftsdaten abzufragen und dann entsprechende Maßnahmen auf diesen Daten durchzuführen.
Drei Kernfunktionen von Databricks machen dies möglich:
- AI/BI Genie: eine KI-native BI-Erfahrung, die es Benutzern ermöglicht, Fragen in natürlicher Sprache über verwaltete Delta-Tabellen zu stellen, ohne SQL schreiben zu müssen.
- Agent Bricks: wiederverwendbare Bausteine für qualitativ hochwertige, produktionsreife Agenten, einschließlich Informationsextraktion, Wissensassistenten und Orchestrierung, die auf Ihren Daten aufgebaut und optimiert sind und nicht als einmalige Prototypen.
- Unity Catalog: einheitliche Governance, Lineage und feingranulare Zugriffskontrolle über Daten, KI-Agenten und sogar MCP-Server hinweg, vom Quelldokument bis zur Agentenantwort und Systemrückschreibung.
Der Multi-Agenten-Workflow zur Dokumentenaktivierung
Aufbauend auf diesem Fundament implementieren wir einen phasenweisen Dokumentenaktivierungs-Workflow, den technische und nicht-technische Teams schrittweise übernehmen und replizieren können.
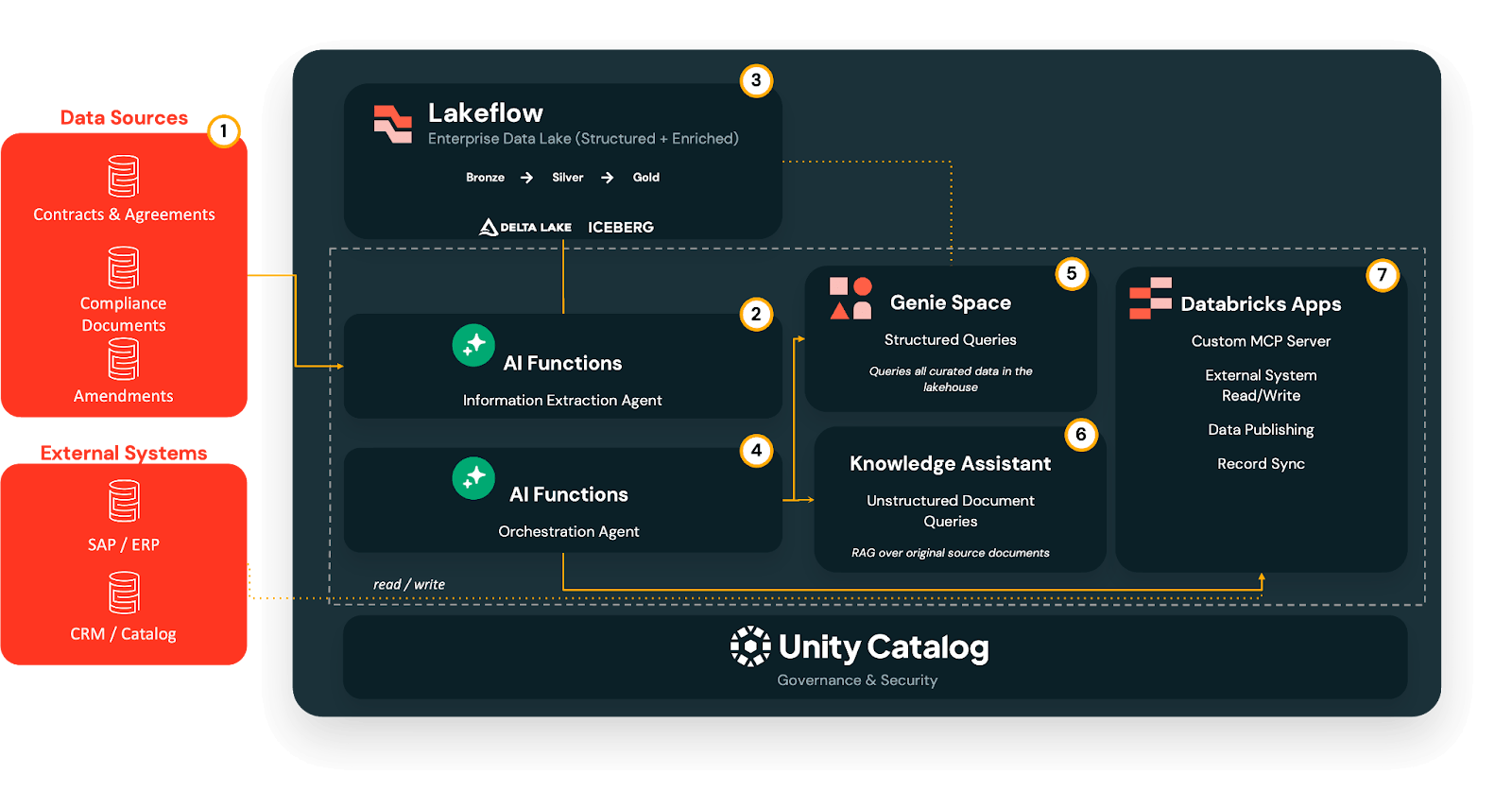
Phase 1 - Extrahieren: Von PDFs zu verwalteten Delta-Tabellen
In Phase 1 verwendet der Information Extraction Agent LLM-basierte Extraktion, um unstrukturierte Dokumente (PDF, DOC/DOCX, PPT/PPTX, Bilder) in strukturierte Felder umzuwandeln, ohne benutzerdefinierte OCR-Pipelines oder einmalige Parser erstellen zu müssen.
Die Rohausgaben landen in einer Lakeflow Medallion-Pipeline:
- Bronze: Roh extrahierte Felder wie sie sind.
- Silver: Bereinigte und standardisierte Werte, mit aufgelösten kanonischen IDs und normalisierten Codes.
- Gold: Geschäftsfertige Tabellen, optimiert für Abfragen und Analysen.
Diese Extraktion läuft zur Ingestionszeit, nicht zur Abfragezeit, sodass alles nachgelagerte auf einem konsistenten, verwalteten Datenfundament aufbaut.
Phase 2: Abfragen - Self-Service-Analysen mit Genie
Sobald Schlüsselbegriffe in Delta-Tabellen strukturiert sind, bietet AI/BI Genie Business-Benutzern eine Self-Service-Oberfläche, um Fragen in einfacher englischer Sprache zu stellen.
Richten Sie Genie auf die Tabellen der Gold-Schicht, und Benutzer können Fragen stellen wie: „Welche Verträge laufen im nächsten Quartal in EMEA aus?“ oder „Welche Verlagsvereinbarungen haben Umsatzbeteiligungsstufen, die über einem bestimmten Ausgabenschwellenwert aktiviert werden?“ Genie übersetzt diese Abfragen dann in SQL, erzwingt Unity Catalog-Berechtigungen und gibt tabellarische oder visuelle Ergebnisse zurück, wodurch der Engpass des Analysten beseitigt wird, während der Datenzugriff weiterhin verwaltet wird.
Phase 3: Verstehen - Klauselbezogene Antworten mit dem Wissensassistenten
Einige Fragen können nicht allein anhand von Aggregaten beantwortet werden. Rechts-, Rechte- und Compliance-Teams müssen oft genau wissen,was eine bestimmte Klausel besagt.
Hier läuft ein Wissensassistent, ein RAG-basierter Konversationsagent, direkt über die ursprünglichen Quelldokumente, die in Unity Catalog Volumes gespeichert sind.
Er kann Fragen beantworten wie: „Was sind die Unterlizenzbeschränkungen im Warner-Deal?“ oder „Haben wir SVOD-Rechte für Show X in Frankreich im Jahr 2027, und sind sie exklusiv?“ Der Assistent gibt dann Klausel-bezogene Snippets mit Zitaten zu den ursprünglichen PDFs zurück und behält so die vollständige Nachverfolgbarkeit bei.
Phase 4: Orchestrieren — eine einzige Anlaufstelle mit einem Multi-Agenten-Supervisor
Wenn Sie weitere Agenten hinzufügen, möchten Sie nicht, dass Benutzer entscheiden müssen, welches Tool sie für jede Frage öffnen sollen.
Der Multi-Agent Supervisor fungiert als ein einziger Konversations-Einstiegspunkt, der jede Abfrage analysiert und an den richtigen Spezialisten weiterleitet:
- Strukturierte Fragen → Genie Spaces
- Klauselbezogene Fragen → Wissensassistent
- Systemaktionen → MCP-basierte Konnektoren und nachgelagerte Flows
Benutzer stellen einfach ihre Frage und der Supervisor wählt den richtigen Weg, wobei unstrukturierte und strukturierte Kontexte bei Bedarf kombiniert werden.
Phase 5: Handeln — von der Erkenntnis zu Systemaktualisierungen mit MCP
Schließlich verwandeln MCP-Server das Dokumentenverständnis in Handeln, indem sie externe System-APIs (ERP, HRIS, CRM, Werbeplattformen, Rechteverwaltungssysteme, Slack) als Tools kapseln, die der Supervisor aufrufen kann.
Dies ermöglicht es Ihnen, die beste Vorgehensweise basierend auf den extrahierten Daten und dem organisatorischen Kontext zu wählen. Beispiele hierfür sind::
- Übermittlung validierter Rechte-Daten in SAP und Synchronisierung mit einem Titelkatalog oder CRM.
- Aktualisierung von Berechtigungen und Bundles in Abrechnungs- und Kundendienstsystemen basierend auf extrahierten Bedingungen.
- Auslösen von Workflows in Ticket- oder Projektmanagement-Tools bei Erkennung von regulatorischen Fristen oder Make-Good-Verpflichtungen.
Da all dies von Unity Catalog verwaltet wird, bleibt jedes Feld nachverfolgbar bis zu dem Dokument, aus dem es stammt, mit Lineage- und Audit-Trails über Agenten und Systemrückschreibungen hinweg.
Branchenspezifische Anwendungsfälle in Medien, Agenturen, Ad Tech und Telekommunikation
Dieser Workflow zur Dokumentenaktivierung kann in einer Vielzahl von Branchen und Anwendungsfällen angewendet werden. Er kann jedoch besonders wirkungsvoll für Branchen wie Telekommunikation sowie Medien und Unterhaltung sein, in denen Kunden auf riesigen Mengen schnell wachsender strukturierter und unstrukturierter Daten in ihren Dokumenten sitzen. Unabhängig vom Geschäftsziel oder der Rolle gibt es eine Anwendung, um relevante Dokumente in saubere, verwaltete Erkenntnisse und die entsprechende nächste Aktion umzuwandeln.
- Medienverlage und Studios
- Verfolgen Sie Rechte- und Lizenzverträge, beantworten Sie Fragen wie „Haben wir Streaming-Rechte für Titel X in Deutschland bis 2027?“ und kennzeichnen Sie proaktiv Verträge, die in den nächsten 90 Tagen auslaufen.
- Extrahieren Sie Umsatzbeteiligungs- und Vertriebsbedingungen in strukturierte Tabellen und leiten Sie validierte Zahlen in ERP- und Planungssysteme weiter.

- Medienagenturen
- Extrahieren Sie Preislisten, AVB-Schwellenwerte und Abrechnungsauslöser aus Medienkaufverträgen und gleichen Sie diese automatisch mit Lieferung und Ausgaben ab.
- Strukturieren Sie Kundenbriefings und Forschungsberichte in wiederverwendbare Daten für Planungssysteme und Kampagnenanalysen.
- Ad-Tech-Plattformen
- Aktivieren Sie Datenschutzbestimmungen und Anzeigenrichtliniendokumente, um die Frage zu beantworten: „Welche aktiven Vorschriften erfordern Opt-out-Mechanismen für verhaltensbezogene Werbung?“ und erzwingen Sie Kontrollen in Einwilligungs- und Richtlinien-Engines.
- Verfolgen Sie Datenlizenz- und API-Bedingungen, um nicht konforme Modelltrainings oder -aktivierungen zu verhindern.
- Telekommunikationsanbieter
- Verwalten Sie Service- und Großhandelsverträge, Roaming- und Interconnect-Deal-Bedingungen sowie Turmmieten mit klarer Sichtbarkeit von SLAs, Eskalationen und Verlängerungsfenstern.
- Steuern Sie Kundenberechtigungen und -pakete durchgängig und synchronisieren Sie validierte Rechte mit Abrechnungs-, CRM- und Supportsystemen.
In all diesen Szenarien verzeichnen Kunden Verbesserungen wie einen schnelleren Monatsabschluss, wiedererlangte Einnahmen, reduzierte Abflüsse und geringeres Betriebsrisiko, während gleichzeitig der manuelle Aufwand für Finanz-, Rechts-, Betriebs- und Marketingteams reduziert wird.
Was kommt als Nächstes
Wenn Ihre Teams immer noch auf manuelle Dokumenten-Workflows und getrennte Tools angewiesen sind, ist es jetzt an der Zeit, die Dokumentenintelligenz auf einer gesteuerten Daten- und KI-Plattform zu modernisieren.
- Entdecken Sie Databricks für Medien und Unterhaltung und Telekommunikation, um zu sehen, wie Verträge, Richtlinien und Vereinbarungen in Ihre breitere Datenstrategie passen.
- Sprechen Sie mit Ihrem Databricks-Account-Team über einen fokussierten Proof of Value zur Dokumentenaktivierung, beginnend mit einem einzigen, wirkungsvollen Anwendungsfall und einer einzelnen Geschäftseinheit.
- Tauchen Sie tiefer in Kundengeschichten ein wie die von SEGA, First American und Vale, um zu sehen, wie Organisationen bereits unstrukturierte Dokumente in gesteuerte, umsetzbare Daten in großem Maßstab umwandeln.
Indem Sie Extraktion, Abfrage, RAG, Orchestrierung und System-Write-Back auf Databricks vereinheitlichen, können Sie über das reine „Lesen von Dokumenten“ hinausgehen und diese aktivieren, wodurch neue Einnahmen erschlossen, Risiken reduziert und Ihre Teams entlastet werden, damit sie sich auf höherwertige Aufgaben konzentrieren können.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.