Wie Unity Catalog Managed Tables die Leistung im großen Maßstab automatisieren
Integrierte KI-Optimierungen liefern bis zu 50 % Kosteneinsparungen und 20x schnellere Abfragen – keine manuelle Abstimmung erforderlich
von Elizabeth Bowman
- Erfahren Sie, welche Funktionen Unity Catalog (UC) verwaltete Tabellen zum Standard für bewährte Datenmanagementpraktiken machen
- Reduzieren Sie Kosten um über 50 % und verbessern Sie die Abfrageleistung um das 20-fache mit Predictive Optimization auf UC verwalteten Tabellen
- Sparen Sie Zeit im Data Engineering durch automatische, intelligente Datenoptimierungen, die sich an Nutzungsmuster anpassen
Unity Catalog (UC) verwaltete Tabellen kombinieren starke Governance mit nahtloser Interoperabilität über Tools hinweg. Da die Daten im Cloud-Speicher des Kunden liegen, behalten Organisationen die volle Kontrolle über ihren physischen Speicherort und profitieren gleichzeitig von den integrierten Intelligenz- und Automatisierungsfunktionen von Databricks.
Heute sind UC-verwaltete Tabellen der am häufigsten verwendete Tabellentyp in Databricks; zwei von drei UC-Tabellen sind verwaltet. Diese Akzeptanz spiegelt ihre Fähigkeit wider, Abläufe zu vereinfachen, Kosten zu senken und die Leistung im großen Maßstab zu verbessern.
Mit UC-verwalteten Tabellen können sich Organisationen darauf verlassen, dass sie immer die neuesten Tabellenfunktionen verwenden. Diese Tabellen werden automatisch aktualisiert und verstehen im Gegensatz zu anderen Tabellentypen Nutzungsmuster, sodass neue Funktionen sicher und schrittweise ohne manuelles Eingreifen aktiviert werden können.
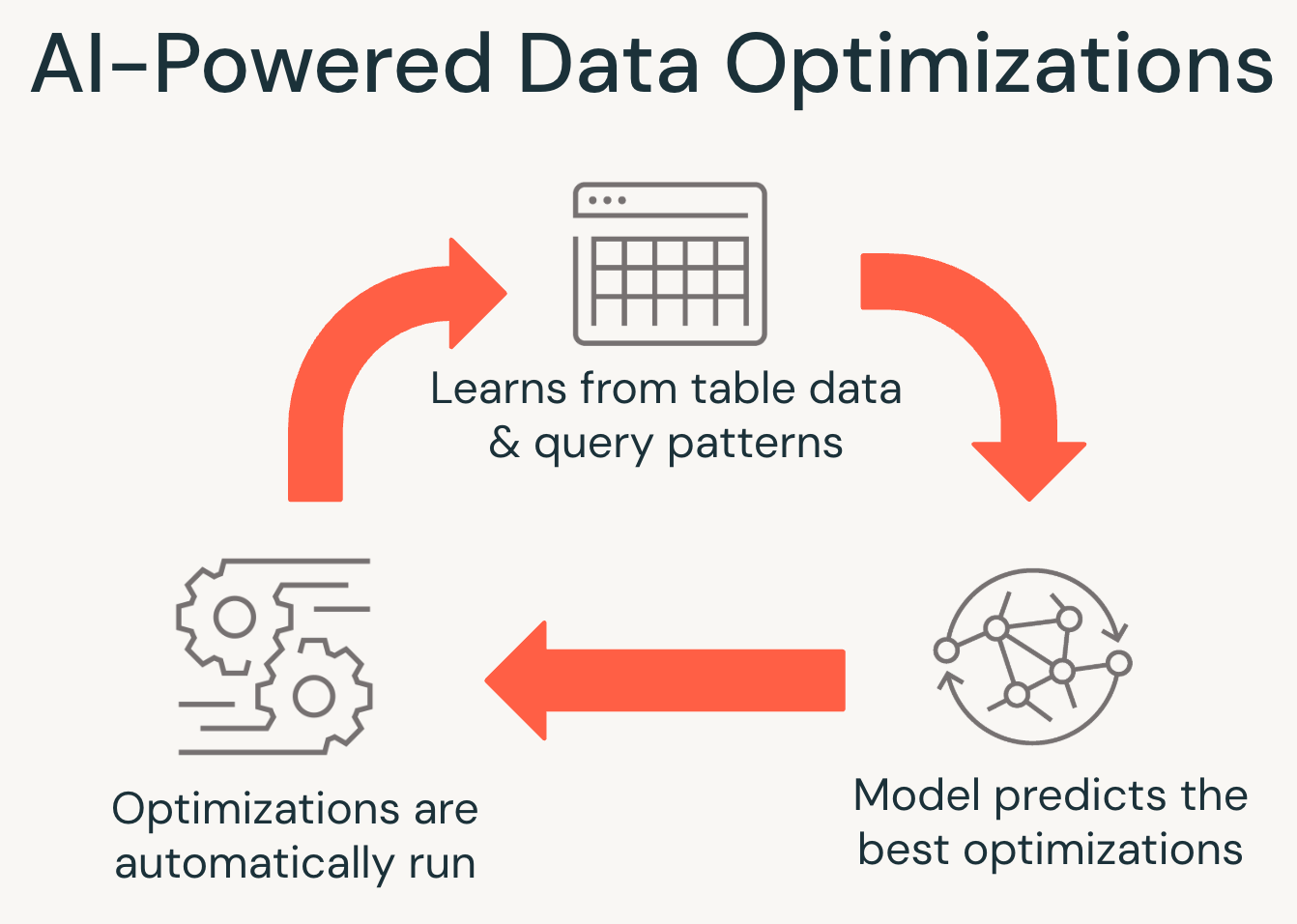
Die Struktur von UC-verwalteten Tabellen ermöglicht auch erweiterte KI-Funktionen, die bisher nicht möglich waren. Da alle Lese- und Schreibvorgänge über Unity Catalog geleitet werden, kann Databricks Daten intelligent optimieren, basierend auf der tatsächlichen Nutzung, was die Abfrageleistung verbessert, Speicherkosten senkt und die routinemäßige Wartung eliminiert.
Hauptvorteile sind:
- Automatische Upgrades mit den neuesten Funktionen
- Selbstwartung mit Kompaktierung, Clusterbildung und Bereinigung
- Speicher- und Rechenkostenersparnis durch intelligente Optimierung
- Sicherer Zugriff über Open APIs, auch für Nicht-Databricks-Clients
- Schnellere Abfragen über alle Clients hinweg, nicht nur in Databricks
In diesem Blogbeitrag werden wir uns eingehend mit den Funktionen befassen, die UC-verwaltete Tabellen effektiv machen, sowie mit den jüngsten Verbesserungen und einem Ausblick auf die Roadmap.
„Die automatischen Optimierungen der Unity Catalog-verwalteten Tabellen sparten uns jährlich über 1 Million US-Dollar an Speicherkosten und eliminierten gleichzeitig den Bedarf an mühsamer manueller Arbeit auf täglicher Basis.“ —Abhinav Raghuvanshi, Associate Director of Data Engineering bei Zepto
Was sind die Vorteile von Unity Catalog-verwalteten Tabellen?
UC-verwaltete Tabellen sind standardmäßig optimiert, ohne dass eine manuelle Abstimmung erforderlich ist. Sie passen sich kontinuierlich an Abfrageworkloads an, um die Leistung zu verbessern, die Speicherkosten zu senken und die Lebenszyklusverwaltung zu optimieren.
UC-verwaltete Tabellen vereinfachen auch den Betrieb mit integrierten Funktionen wie automatischem VACUUM, Dateikompaktierung und Metadaten-Caching. Da sie auf offenen Formaten wie Delta und Iceberg basieren, lassen sich UC-verwaltete Tabellen einfach in Drittanbieter-Tools und -Engines integrieren.
Intelligente Optimierungen treiben Kosten- und Leistungssteigerungen voran
UC-verwaltete Tabellen wenden eine Reihe von KI-gesteuerten Techniken an, um Kostenersparnisse von bis zu 50 % und 20-fach schnellere Abfragen zu erzielen:
Automatische Liquid Clustering
UC-verwaltete Tabellen clustern Daten automatisch basierend auf beobachteten Abfragemustern, ohne dass eine manuelle Konfiguration erforderlich ist. Im Gegensatz dazu erfordern UC-externe Tabellen, dass Dateningenieure OPTIMIZE-Befehle ausführen und manuell Clustering-Schlüssel definieren. Bei verwalteten Tabellen übernimmt Predictive Optimization das Clustering dynamisch, verbessert die Abfrageleistung und reduziert die Speicherkosten ohne zusätzlichen Aufwand. [Mehr lesen]

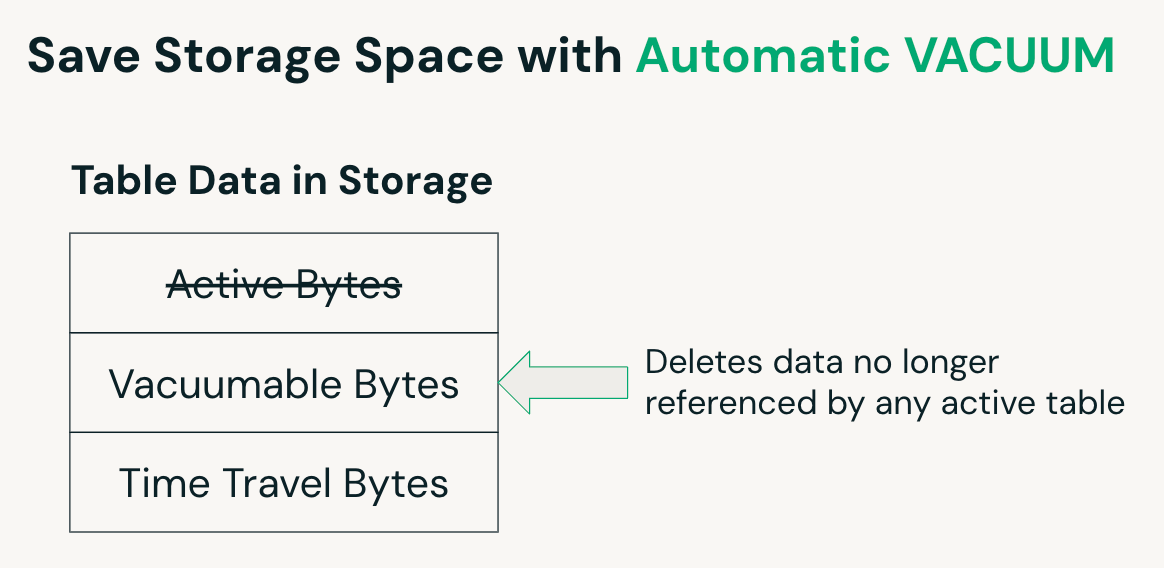
Automatisches VACUUM
Bei UC-verwalteten Tabellen erkennt Predictive Optimization automatisch, wann eine VACUUM-Operation vorteilhaft ist, und plant sie entsprechend. VACUUM entfernt Dateien, die mit gelöschten Zeilen assoziiert sind, nach einer definierten Aufbewahrungsfrist und hilft so, die Speichernutzung zu reduzieren. Bei UC-externen Tabellen muss dieser Prozess manuell durch Ausführen des VACUUM-Befehls verwaltet werden.
Deferred DROP mit automatischer Bereinigung
Wenn eine UC-verwaltete Tabelle gelöscht wird, werden die zugrunde liegenden Daten im Cloud-Speicher nach 7 Tagen automatisch gelöscht, was zur Reduzierung der Speicherkosten und zur Vermeidung von verwaisten Dateien beiträgt. Im Gegensatz dazu löscht das Löschen einer UC-externen Tabelle die Daten nicht; Benutzer müssen die Dateien manuell aus ihrem Speicher-Bucket entfernen. Wenn dieser Schritt übersehen wird, bleiben die Daten erhalten, was zu unnötiger Speichernutzung führt. Sehen Sie sich den Roadmap-Abschnitt für bevorstehende Verbesserungen dieses Verhaltens an.
Automatische Statistikenerfassung
UC-verwaltete Tabellen erfassen automatisch Statistiken, die die Abfrageleistung durch intelligenteres Überspringen von Daten und Join-Planung verbessern. Wichtige Metriken wie minimale und maximale Spaltenwerte helfen dem System, irrelevante Dateien während der Abfrageausführung zu identifizieren und zu überspringen, wodurch der Rechenaufwand reduziert wird. Während UC-externe Tabellen standardmäßig Statistiken für die ersten 32 Spalten generieren, priorisieren UC-verwaltete Tabellen dynamisch die Spalten, die für die tatsächlichen Abfrageworkloads am relevantesten sind. [Mehr lesen]

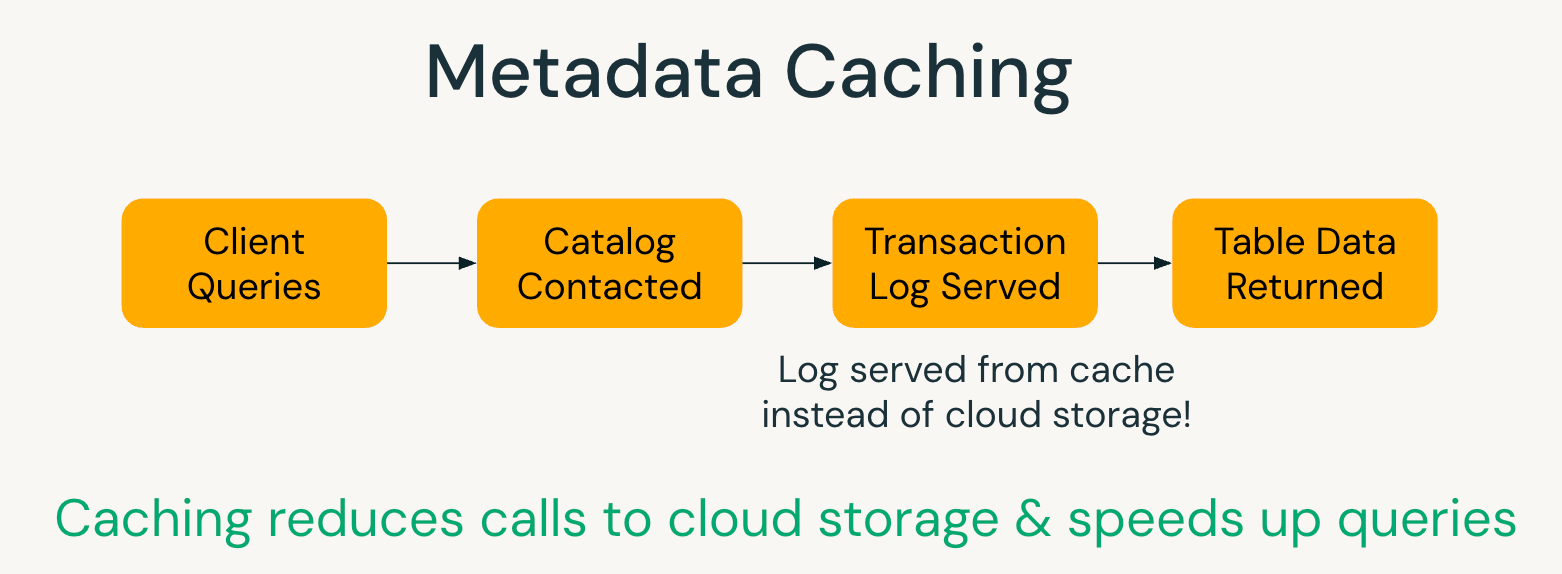
Metadaten-Caching
UC-verwaltete Tabellen verwenden In-Memory-Caching von Transaktionsmetadaten, um den Zugriff auf Cloud-basierte Transaktionsprotokolle zu reduzieren. Dies senkt die Rechenkosten und verbessert die Leistung der Abfrageplanung. Die Funktion ist exklusiv für UC-verwaltete Tabellen, bei denen Databricks alle Schreibvorgänge verfolgen und sicherstellen kann, dass die zwischengespeicherten Metadaten mit dem aktuellen Zustand konsistent bleiben.
Optimierung der Dateigröße
Databricks verwendet KI, um Dateien automatisch auf optimale Größen zu komprimieren, basierend auf Mustern, die aus Tausenden von realen Bereitstellungen gelernt wurden. Diese Optimierung erfolgt beim Schreiben der Daten und trägt zur Verbesserung der Abfrageleistung bei, indem die Dateifragmentierung und der Scan-Overhead reduziert werden. [Mehr lesen]

Offen und interoperabel per Design
UC-verwaltete Tabellen basieren auf offenen Formaten wie Delta und Iceberg und ermöglichen so eine breite Kompatibilität im modernen Daten-Ökosystem. Sie können von jeder Engine, die diese Formate unterstützt, wie z. B. Trino, DuckDB, Apache Spark™, Daft und Tools, die mit dem Iceberg REST-Katalog integriert sind, wie Dremio, aufgerufen werden.
Sicherer Zugriff wird durch Open APIs und Credential Vending ermöglicht, sodass externe Tools mit verwalteten Daten interagieren können, ohne sie zu duplizieren. Dies vereinfacht die Architektur und ermöglicht eine einzige Quelle der Wahrheit für Analyse- und KI-Workloads.
Die Unterstützung für Schreibvorgänge von Drittanbietern wird ebenfalls erweitert. In der Private Preview akzeptieren UC-verwaltete Tabellen jetzt auch Schreibvorgänge von Nicht-Databricks-Delta-Clients wie Apache Spark, was die Integration mit externen Verarbeitungs-Frameworks erleichtert und gleichzeitig die Unity Catalog-Governance beibehält.
Delta Sharing, das einzige offene Freigabeprotokoll der Branche, verbessert die Interoperabilität weiter, indem es sicheren Lesezugriff auf die zugrunde liegenden Daten ermöglicht, selbst für Empfänger, die Databricks nicht verwenden. Diese Funktionen helfen, den gesteuerten Datenzugriff über Plattformen, Partner und Anwendungen hinweg zu erweitern.
Da diese Optimierungen auf der Ebene des Datenlayouts angewendet werden, sind die Leistungssteigerungen universell. Externe Tools profitieren vom gleichen geclusterten Layout, den komprimierten Dateien und den reichhaltigen Statistiken, was zu schnelleren Abfragen und effizienteren Lesevorgängen führt, unabhängig von der Engine.
Was ist auf der Roadmap?
Mehrere neue Funktionen werden bald verfügbar sein, die UC-verwaltete Tabellen noch leistungsfähiger und flexibler machen werden:
Tabellenbasierte Beobachtbarkeit
Gewinnen Sie Einblicke in ungenutzte Tabellen, Aufbewahrungszeiträume, Tabellengrößentrends und benutzerdefinierte Metadaten, um Kosten einfacher zu verwalten und Best Practices durchzusetzen.
Konfigurierbare UNDROP-Zeiträume
Passen Sie das Aufbewahrungsfenster für gelöschte Tabellen an, einschließlich der Unterstützung für die sofortige Löschung, um die Speicherkosten weiter zu senken.
Tools zur Reorganisation von Schemata und Katalogen
Befehle zum Verschieben von Tabellen zwischen Katalogen und Schemata, die Teams helfen, Datensätze zu organisieren, wenn sich Umgebungen weiterentwickeln.
Multi-Statement- und Multi-Table-Transaktionen (Private Preview)
Unterstützung für atomare Commits über mehrere Tabellen hinweg. Wenn eine Operation fehlschlägt, wird die gesamte Transaktion zurückgerollt, was die Zuverlässigkeit bei komplexen Datenoperationen verbessert.
Erste Schritte mit UC-verwalteten Tabellen
UC-verwaltete Tabellen sind standardmäßig aktiviert und einfach zu übernehmen, egal ob Sie neue Tabellen erstellen oder vorhandene konvertieren.
Erstellen einer neuen verwalteten Tabelle
Für neue Workloads werden UC-verwaltete Tabellen erstellt, ohne dass ein Speicherort angegeben werden muss. Databricks verwaltet automatisch den Datenpfad im Cloud-Speicher des Kunden:
CREATE OR REPLACE TABLE catalog.schema.my_managed_table
Konvertieren einer vorhandenen UC-externen Tabelle in eine verwaltete Tabelle
Organisationen, die zu verwalteten Tabellen konvertieren möchten, können den folgenden Befehl verwenden, um externe UC-Tabellen zu konvertieren:
ALTER TABLE catalog.schema.my_external_table SET MANAGED
Sehen Sie sich die Dokumentation an und beantragen Sie den Zugriff auf die eingeschränkte öffentliche Vorschau über dieses Formular.
Konvertieren fremder Tabellen (nicht UC)
Für Teams, die von fremden Tabellentypen migrieren, ist die Konvertierung in UC-verwaltete Tabellen in der Private Preview verfügbar. Dies erleichtert die Konsolidierung von Governance und Optimierung unter Unity Catalog. Sie können den Zugriff auf die eingeschränkte Vorschau über dieses Formular beantragen.
Erweiterte Funktionen in der Vorschau ausprobieren
Um Funktionen wie Schreibvorgänge von Drittanbietern in verwaltete Tabellen, Multi-Table-Transaktionen oder Schema-Reorganisationen zu testen, wenden Sie sich an Ihr Databricks-Account-Team, um an den relevanten Vorschauprogrammen teilzunehmen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.