Verbessern Sie die Text2SQL-Leistung ganz einfach auf Databricks
von Matthew Hayes, Evion Kim, Linqing Liu, Alnur Ali, Ritendra Datta und Sam Shah
Möchten Sie Ihr LLM in die Top 10 von Spider bringen, einem weit verbreiteten Benchmark für Text-zu-SQL-Aufgaben? Spider bewertet, wie gut LLMs Textabfragen in SQL-Code umwandeln können.
Für diejenigen, die mit Text-zu-SQL nicht vertraut sind, liegt seine Bedeutung darin, wie Unternehmen mit ihren Daten interagieren. Anstatt sich auf SQL-Experten zum Schreiben von Abfragen zu verlassen, können Benutzer einfach Fragen in natürlicher Sprache stellen und präzise Antworten erhalten. Dies demokratisiert den Datenzugriff, verbessert die Business Intelligence und ermöglicht fundiertere Entscheidungen.
Der Spider-Benchmark ist ein weithin anerkannter Standard zur Bewertung der Leistung von Text-zu-SQL-Systemen. Er fordert LLMs heraus, natürliche Sprachabfragen in präzise SQL-Anweisungen zu übersetzen, was ein tiefes Verständnis von Datenbankschemata und die Fähigkeit zur Generierung syntaktisch und semantisch korrekter SQL-Codes erfordert.
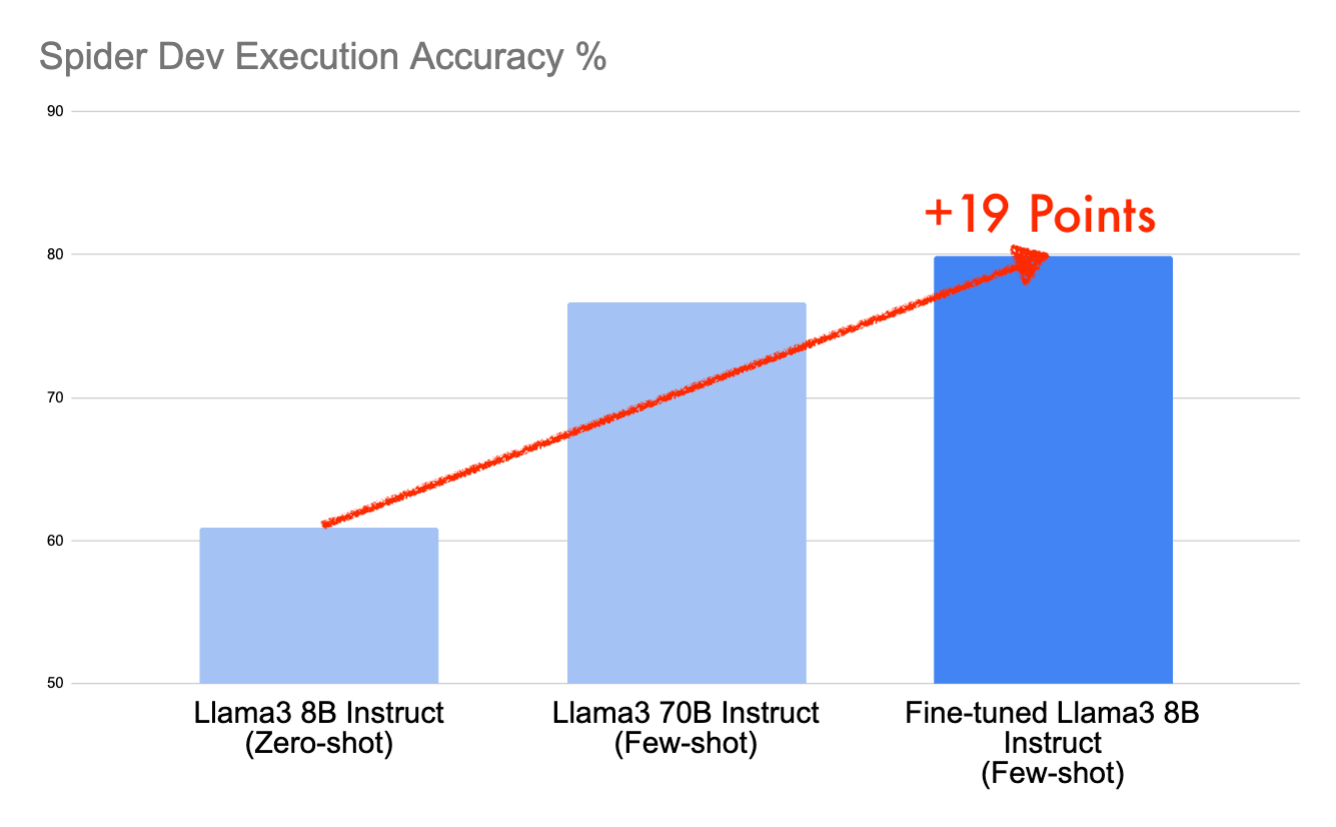
In diesem Beitrag werden wir untersuchen, wie wir mit dem Open-Source-Modell Llama3 8B Instruct Scores von 79,9 % auf dem Spider-Entwicklungsdatensatz und 78,9 % auf dem Testdatensatz in weniger als einem Arbeitstag erzielt haben – eine bemerkenswerte Verbesserung von 19 Punkten gegenüber dem Basismodell. Diese Leistung würde uns dank strategischem Prompting und Fine-Tuning auf Databricks einen Top-10-Platz auf der nun eingefrorenen Spider-Rangliste einbringen.
Zero-Shot-Prompting für Basisleistung
Beginnen wir mit der Bewertung der Leistung von Meta Llama 3 8B Instruct auf dem Spider-Entwicklungsdatensatz unter Verwendung eines sehr einfachen Prompt-Formats, das aus den CREATE TABLE-Anweisungen zur Erstellung der Tabellen und einer Frage besteht, die wir mit diesen Tabellen beantworten möchten:
Diese Art von Prompt wird oft als „Zero-Shot“ bezeichnet, da keine anderen Beispiele im Prompt enthalten sind. Für die erste Frage im Spider-Entwicklungsdatensatz erzeugt dieses Prompt-Format:
Die Ausführung des Spider-Benchmarks auf dem Entwicklungsdatensatz mit diesem Format ergibt einen Gesamtscore von 60,9, gemessen an der Ausführungsgenauigkeit und dem Greedy Decoding. Das bedeutet, dass das Modell in 60,9 % der Fälle SQL erzeugt, das bei Ausführung die gleichen Ergebnisse wie eine „Gold“-Abfrage liefert, die die korrekte Lösung darstellt.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot | 78.6 | 69.3 | 42.5 | 31.3 | 60.9 |
Nachdem der Basis-Score ermittelt wurde, versuchen wir, bevor wir uns dem Fine-Tuning widmen, verschiedene Prompting-Strategien, um den Score für das Basismodell auf dem Spider-Entwicklungs-Benchmark-Datensatz zu erhöhen.
Prompting mit Beispielzeilen
Ein Nachteil des ersten verwendeten Prompts ist, dass er über den Datentyp hinaus keine Informationen über die Daten in den Spalten enthält. Eine Studie zur Bewertung der Text-zu-SQL-Fähigkeiten von Modellen mit Spider ergab, dass das Hinzufügen von Stichprobenzeilen zum Prompt zu einem höheren Score führte. Versuchen wir das also.
Wir können das obige Prompt-Format aktualisieren, sodass die CREATE TABLE-Abfragen auch die ersten Zeilen jeder Tabelle enthalten. Für dieselbe Frage wie zuvor haben wir nun einen aktualisierten Prompt:
Das Einfügen von Beispielzeilen für jede Tabelle erhöht den Gesamtscore um etwa 6 Prozentpunkte auf 67,0:
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Zero-shot with sample rows | 80.6 | 75.3 | 51.1 | 41.0 | 67.0 |
Few-Shot-Prompting
Few-Shot-Prompting ist eine bekannte Strategie, die mit LLMs verwendet wird, um die Leistung bei Aufgaben wie der Generierung von korrektem SQL zu verbessern, indem einige Beispiele zur Veranschaulichung der auszuführenden Aufgabe aufgenommen werden. Bei einem Zero-Shot-Prompt haben wir die Schemata bereitgestellt und dann eine Frage gestellt. Bei einem Few-Shot-Prompt stellen wir einige Schemata, eine Frage, das SQL, das diese Frage beantwortet, und wiederholen diese Sequenz ein paar Mal, bevor wir zur eigentlichen Frage übergehen. Dies führt im Allgemeinen zu einer besseren Leistung als ein Zero-Shot-Prompt.
Eine gute Quelle für Beispiele, die die SQL-Generierungsaufgabe veranschaulichen, ist der Spider-Trainingsdatensatz selbst. Wir können eine zufällige Stichprobe von einigen Fragen aus diesem Datensatz mit den entsprechenden Tabellen nehmen und einen Few-Shot-Prompt erstellen, der das SQL demonstriert, das jede dieser Fragen beantworten kann. Da wir ab dem vorherigen Prompt Stichprobenzeilen verwenden, sollten wir auch sicherstellen, dass eines dieser Beispiele Stichprobenzeilen enthält, um deren Verwendung zu demonstrieren.
Eine weitere Verbesserung gegenüber dem vorherigen Zero-Shot-Prompt ist die Hinzufügung eines „System-Prompts“ am Anfang. System-Prompts werden typischerweise verwendet, um dem Modell detaillierte Anweisungen zu geben, die die auszuführende Aufgabe umreißen. Während ein Benutzer im Laufe eines Chats mit einem Modell mehrere Fragen stellen kann, wird der System-Prompt nur einmal vor der Frage des Benutzers bereitgestellt und legt im Wesentlichen die Erwartungen fest, wie sich das „System“ während des Chats verhalten soll.
Mit diesen Strategien im Hinterkopf können wir einen Few-Shot-Prompt erstellen, der auch mit einer Systemnachricht beginnt, die als großer SQL-Kommentarblock am Anfang dargestellt wird, gefolgt von drei Beispielen:
Dieser neue Prompt hat zu einem Score von 70,8 geführt, was einer weiteren Verbesserung um 3,8 Prozentpunkte gegenüber unserem vorherigen Score entspricht. Wir haben den Score durch einfache Prompting-Strategien um fast 10 Prozentpunkte gegenüber dem Ausgangspunkt erhöht.
| Easy | Medium | Hard | Extra | All | |
|---|---|---|---|---|---|
| Few-shot with sample rows | 83.9 | 79.1 | 55.7 | 44.6 | 70.8 |
Wir nähern uns wahrscheinlich dem Punkt der abnehmenden Erträge durch Anpassung unseres Prompts. Lassen Sie uns das Modell feinabstimmen, um zu sehen, welche weiteren Fortschritte erzielt werden können.
Feinabstimmung mit LoRA
Wenn wir das Modell feinabstimmen, stellt sich zuerst die Frage, welche Trainingsdaten wir verwenden sollen. Spider enthält einen Trainingsdatensatz, daher scheint dies ein guter Ausgangspunkt zu sein. Um das Modell feinabzustimmen, werden wir QLoRA verwenden, damit wir das Modell effizient auf einem einzelnen A100 80GB Databricks GPU-Cluster wie Standard_NC24ads_A100_v4 in Databricks trainieren können. Dies kann in etwa vier Stunden mit den 7.000 Datensätzen aus dem Spider-Trainingsdatensatz abgeschlossen werden. Wir haben die Feinabstimmung mit LoRA bereits in einem früheren Blogbeitrag besprochen. Interessierte Leser können sich für weitere Details an diesen Beitrag wenden. Wir können Standard-Trainingsrezepte mit den Bibliotheken trl, peft und bitsandbytes befolgen.
Obwohl wir die Trainingsdatensätze aus Spider beziehen, müssen wir sie immer noch so formatieren, dass das Modell daraus lernen kann. Ziel ist es, jeden Datensatz, der aus dem Schema (mit Beispielzeilen), der Frage und der SQL-Abfrage besteht, in einen einzigen Textstring abzubilden. Wir beginnen mit der Verarbeitung des rohen Spider-Datensatzes. Aus den Rohdaten erstellen wir einen Datensatz, bei dem jeder Datensatz aus drei Feldern besteht: schema_with_rows, question und query. Das Feld schema_with_rows wird aus den Tabellen abgeleitet, die der Frage entsprechen, und folgt der Formatierung der CREATE TABLE-Anweisung und der Zeilen, die im Few-Shot-Prompt zuvor verwendet wurden.
Laden Sie als Nächstes den Tokenizer:
Wir definieren eine Mapping-Funktion, die jeden Datensatz aus unserem verarbeiteten Spider-Trainingsdatensatz in einen Textstring umwandelt. Wir können apply_chat_template vom Tokenizer verwenden, um den Text bequem in das Chat-Format zu bringen, das vom Instruct-Modell erwartet wird. Obwohl dies nicht genau dasselbe Format ist, das wir für unseren Few-Shot-Prompt verwenden, verallgemeinert das Modell gut genug, um auch dann zu funktionieren, wenn die Boilerplate-Formatierung der Prompts leicht abweicht.
Für SYSTEM_PROMPT verwenden wir denselben System-Prompt wie im vorherigen Few-Shot-Prompt. Für USER_MESSAGE_FORMAT verwenden wir ebenfalls:
Mit dieser definierten Funktion müssen wir nur noch den verarbeiteten Spider-Datensatz damit transformieren und als JSONL-Datei speichern.
Wir sind nun bereit zum Trainieren. Wenige Stunden später haben wir ein feinabgestimmtes Llama3 8B Instruct-Modell. Wenn wir unseren Few-Shot-Prompt auf diesem neuen Modell erneut ausführen, erhalten wir eine Punktzahl von 79,9, was einer weiteren Verbesserung um 9 Prozentpunkte gegenüber unserer vorherigen Punktzahl entspricht. Wir haben die Gesamtpunktzahl damit um ca. 19 Prozentpunkte gegenüber unserer einfachen Zero-Shot-Baseline erhöht.
| Einfach | Mittel | Schwer | Extra | Alle | |
|---|---|---|---|---|---|
| Few-Shot mit Beispielzeilen (Feinabgestimmtes Llama3 8B Instruct) |
91,1 | 85,9 | 72,4 | 54,8 | 79,9 |
| Few-Shot mit Beispielzeilen (Llama3 8B Instruct) |
83,9 | 79,1 | 55,7 | 44,6 | 70,8 |
| Zero-Shot mit Beispielzeilen (Llama3 8B Instruct) |
80,6 | 75,3 | 51,1 | 41,0 | 67,0 |
| Zero-Shot (Llama3 8B Instruct) |
78,6 | 69,3 | 42,5 | 31,3 | 60,9 |
Sie fragen sich vielleicht jetzt, wie sich das Llama3 8B Instruct-Modell und die feinabgestimmte Version im Vergleich zu einem größeren Modell wie Llama3 70B Instruct schlagen. Wir haben den Bewertungsprozess mit dem Standard-70B-Modell auf dem Dev-Datensatz mit acht A100 40 GB GPUs wiederholt und die Ergebnisse unten aufgezeichnet.
| Few-Shot mit Beispielzeilen (Llama3 70B Instruct) |
89,5 | 83,0 | 64,9 | 53,0 | 76,7 |
| Zero-Shot mit Beispielzeilen (Llama3 70B Instruct) |
83,1 | 81,8 | 59,2 | 36,7 | 71,1 |
| Zero-Shot (Llama3 70B Instruct) |
82,3 | 80,5 | 57,5 | 31,9 | 69,2 |
Wie erwartet schlägt das 70B-Modell das 8B-Modell, wenn man die Standardmodelle anhand desselben Prompt-Formats vergleicht. Überraschend ist jedoch, dass das feinabgestimmte Llama3 8B Instruct-Modell um 3 Prozentpunkte besser abschneidet als das Llama3 70B Instruct-Modell. Wenn man sich auf spezifische Aufgaben wie Text-zu-SQL konzentriert, können durch Feinabstimmung kleine Modelle entstehen, die in der Leistung mit wesentlich größeren Modellen vergleichbar sind.
Bereitstellung an einem Model Serving Endpoint
Llama3 wird von Databricks Model Serving unterstützt, sodass wir unser feinabgestimmtes Llama3-Modell sogar an einen Endpunkt bereitstellen und für Anwendungen nutzen könnten. Alles, was wir tun müssen, ist, das feinabgestimmte Modell in Unity Catalog zu loggen und dann über die Benutzeroberfläche einen Endpunkt zu erstellen. Sobald es bereitgestellt ist, können wir es mit gängigen Bibliotheken abfragen.
Zusammenfassung
Wir begannen unsere Reise mit dem Llama3 8B Instruct auf dem Spider-Dev-Datensatz unter Verwendung eines Zero-Shot-Prompts und erreichten eine bescheidene Punktzahl von 60,9. Durch die Verbesserung mit einem Few-Shot-Prompt – komplett mit Systemnachrichten, mehreren Beispielen und Beispielzeilen – steigerten wir unsere Punktzahl auf 70,8. Weitere Verbesserungen ergaben sich durch die Feinabstimmung des Modells auf dem Spider-Trainingsdatensatz, was uns zu beeindruckenden 79,9 auf Spider Dev und 78,9 auf Spider Test brachte. Dieser deutliche Anstieg um 19 Punkte gegenüber unserem Ausgangspunkt und ein Vorsprung von 3 Punkten vor dem Basis-Llama3 70B Instruct zeigt nicht nur die Leistungsfähigkeit unseres Modells, sondern sichert uns auch einen begehrten Platz unter den Top-10-Ergebnissen auf Spider.
Erfahren Sie mehr darüber, wie Sie die Leistung von Open-Source-LLMs und der Data Intelligence Platform nutzen können, indem Sie sich für den Data+AI Summit anmelden.
Anhang
Evaluierungs-Setup
Die Generierung erfolgte mit vLLM, Greedy Decoding (Temperatur von 0), zwei A100 80 GB GPUs und maximal 1024 neuen Tokens. Zur Bewertung der Generierungen verwendeten wir die Testsuite aus dem taoyds/test-suite-sql-eval Repository auf Github.
Trainings-Setup
Hier sind die spezifischen Details zum Feinabstimmungs-Setup:
| Basismodell | Llama3 8B Instruct |
| GPUs | Einzelne A100 80GB |
| Max. Schritte | 100 |
| Spider-Trainingsdatensatz-Datensätze | 7000 |
| Lora R | 16 |
| Lora Alpha | 32 |
| Lora Dropout | 0,1 |
| Lernrate | 1,5e-4 |
| Lernraten-Scheduler | Konstant |
| Gradient Accumulation Steps | 8 |
| Gradient Checkpointing | True |
| Train Batch Size | 12 |
| LoRA Target Modules | q_proj,v_proj,k_proj,o_proj,gate_proj,up_proj,down_proj |
| Datenkollaborator Antwortvorlage | <|start_header_id|>assistent<|end_header_id|> |
Zero-Shot-Prompt-Beispiel
Dies ist der erste Datensatz aus dem Entwicklungsdatensatz, den wir zur Auswertung verwendet haben. Er ist als Zero-Shot-Prompt formatiert und enthält die Tabellenschemata. Die Tabellen, auf die sich die Frage bezieht, werden mithilfe der CREATE TABLE-Anweisungen dargestellt, mit denen sie erstellt wurden.
Zero-Shot mit Beispielzeilen-Prompt-Beispiel
Dies ist der erste Datensatz aus dem Entwicklungsdatensatz, den wir zur Auswertung verwendet haben. Er ist als Zero-Shot-Prompt formatiert und enthält die Tabellenschemata und Beispielzeilen. Die Tabellen, auf die sich die Frage bezieht, werden mithilfe der CREATE TABLE-Anweisungen dargestellt, mit denen sie erstellt wurden. Die Zeilen wurden mithilfe von "SELECT * {table_name} LIMIT 3" aus jeder Tabelle ausgewählt, wobei die Spaltennamen als Kopfzeile erscheinen.
Few-Shot mit Beispielzeilen-Prompt-Beispiel
Dies ist der erste Datensatz aus dem Entwicklungsdatensatz, den wir zur Auswertung verwendet haben. Er ist als Few-Shot-Prompt formatiert und enthält die Tabellenschemata und Beispielzeilen. Die Tabellen, auf die sich die Frage bezieht, werden mithilfe der CREATE TABLE-Anweisungen dargestellt, mit denen sie erstellt wurden. Die Zeilen wurden mithilfe von "SELECT * {table_name} LIMIT 3" aus jeder Tabelle ausgewählt, wobei die Spaltennamen als Kopfzeile erscheinen.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.