Schnellstart für Ihre Datenmodellierung mit Databricks Branchen-Datenmodellen
Vorgefertigte, regelgeprüfte und Silver-Layer-bereite Datenmodelle für die 40 weltweit größten Branchen – bereit für die Bereitstellung und Governance auf der Databricks-Plattform.
von Amr Ali, Drew Triplett, Franco Patano und Shelley Shaffery
- Mehr als 40 Branchendatenmodelle, sofort einsatzbereit. Vorgefertigte, regelgeprüfte Silver-Layer-Modelle für 40 Branchen in zwei Umfängen (MVM und ECM) – direkt bereitstellen oder anpassen.
- Ein vollständiges, verwaltetes Artefakt-Set. Wird als eine model.json (plus SQL-DDL, DBML, Ontologie) geliefert, die in Unity Catalog mit Delta-Tabellen, Fremdschlüsseln, Klassifizierungs-Tags und Metrik-Ansichten bereitgestellt wird.
- In wenigen Stunden bereitstellen. Verweisen Sie mit model.json auf einen Unity Catalog, wählen Sie einen Katalogisierungsstil und erhalten Sie einen klassifizierten, FK-validierten Silver-Layer.
Das Problem mit Branchendatenmodellen
Seit drei Jahrzehnten wird regulierten, datenintensiven Branchen dieselbe Abkürzung verkauft: der Kauf eines Branchendatenmodells. ACORD für Versicherungen, FHIR und HL7 für das Gesundheitswesen, ARTS für den Einzelhandel. Hunderte – manchmal Tausende – von Tabellen, die von einer Standardisierungsorganisation oder einem Anbieter veröffentlicht und als die Arbeit eines ganzen Jahres in einer einzigen Lizenz angepriesen werden.
Das Versprechen klingt überzeugend. Die Realität ist schmerzhafter. Ein Branchendatenmodell ist der Durchschnitt aller Unternehmen in einem Sektor. Es kennt weder Ihre Produktlinien, Ihre Regionen, Ihre regulatorischen Vorgaben, Ihre Altsystem-Einschränkungen, Ihre Namenskonventionen noch Ihre Organisationsstruktur – es weiß nicht, was Ihr Unternehmen auszeichnet. Teams übernehmen Hunderte von Tabellen, die sie nie befüllen werden, Namenskonventionen, die nicht zu ihrer Terminologie passen, und Beziehungsrichtungen, die ihre Workloads gar nicht benötigen. Der Großteil des Werts beim Kauf einer Vorlage geht dafür verloren, sie anzupassen, umzubenennen und neu zu verdrahten – genau die Arbeit, die die Vorlage eigentlich ersparen sollte.
Der Aufbau eines soliden analytischen Datenmodells – also eines Modells, das tatsächlich produktive Analysen und ML ausführt – dauerte in der Vergangenheit meist Monate oder sogar Jahre.
Wir veröffentlichen etwas anderes: Eine Bibliothek mit vorgefertigten Lakehouse-Branchendatenmodellen, die ab heute in einem öffentlichen Repository verfügbar sind und direkt als Silver-Layer in Databricks für die 40 weltweit größten Branchen bereitgestellt werden können. Jedes Branchendatenmodell wird in zwei Umfängen geliefert und basiert auf einem strengen strukturellen Regelwerk mit über 200 Regeln in 14 verschiedenen Modellierungsdomänen. Dies macht die Ergebnisse vom ersten Tag an produktionsreif. Die gute Nachricht ist, dass es sich nicht um starre oder feste Datenmodelle handelt – Sie können sie ganz nach Bedarf weiterentwickeln und an Ihre Organisation anpassen.
Wo diese Datenmodelle im Lakehouse angesiedelt sind
In einer Databricks-Medallion-Architektur enthält Bronze die Rohdaten, Silver das angepasste analytische Basismodell, aus dem alle Analysten, BI-Tools und Data Scientists lesen, und Gold enthält abgeleitete Metriken, KPIs und Aggregate.
Diese Basisdatenmodelle sind der Silver-Layer. Lakeflow und Auto Loader übernehmen die Datenaufnahme. Jedes Modell wird mit vorberechneten Metriken wie churn_score oder monthly_revenue_summary geliefert. Das Basismodell ist das analytische Fundament: der Ort, an dem die Konzepte des Unternehmens zu vertrauenswürdigen Tabellen werden, bereit für BI-Tools, Feature-Pipelines und nachgelagerte Aggregate.
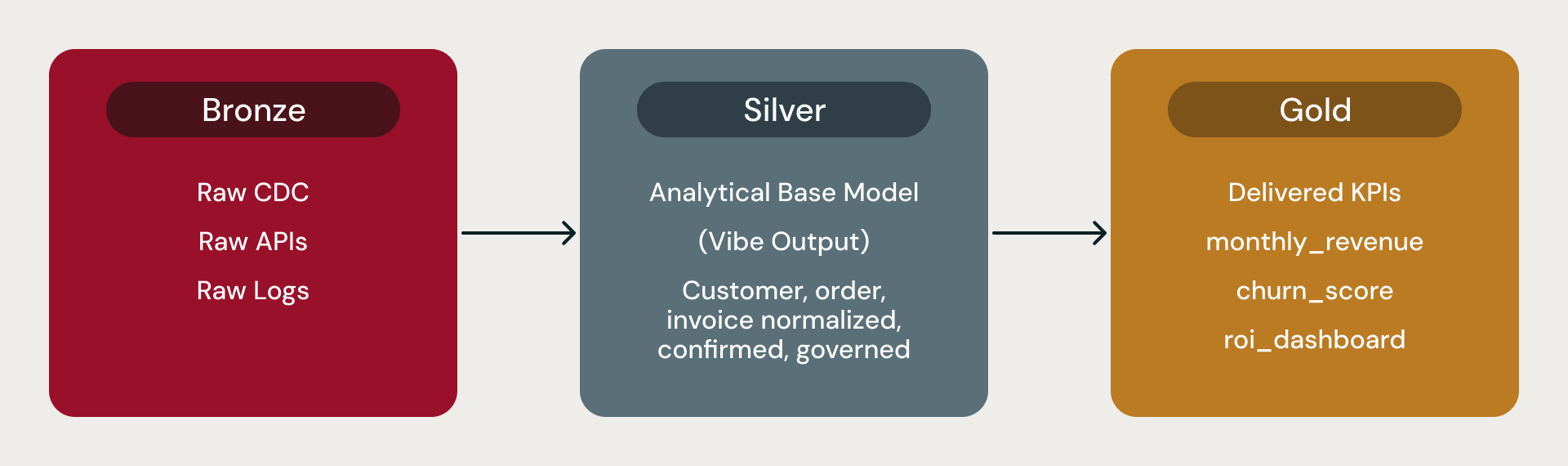
Bronze, Silver, Gold
Zwei Umfänge: MVM und ECM
Jedes Basismodell wird in zwei Umfängen veröffentlicht. Beide werden aus derselben logischen model.json bereitgestellt, folgen denselben Regeln und weisen dieselbe Attributtiefe pro Tabelle auf. Der Unterschied liegt in der Breite.
Minimum Viable Model (MVM). Dreißig bis fünfzig Prozent der Tabellenanzahl des ECM. Nur wesentliche Geschäftsfunktionen. Ideal für SMBs, schnelle Bereitstellungen, Proofs of Concept und MVPs. Ein MVM ist kein bloßes Gerüst oder ein Demo-Spielzeug – jede Tabelle bietet dieselbe Attributtiefe wie ihr ECM-Gegenstück. Die Schlankheit resultiert aus weniger Domänen und weniger Tabellen, niemals aus unvollständigen Tabellen.
Expanded Coverage Model (ECM). Vollständige Abdeckung. Alle Geschäftsbereiche, einschließlich des Corporate Backoffice. Alle Domänen, die man von einem Fortune-100-Modell erwarten würde. Maximale Breite.
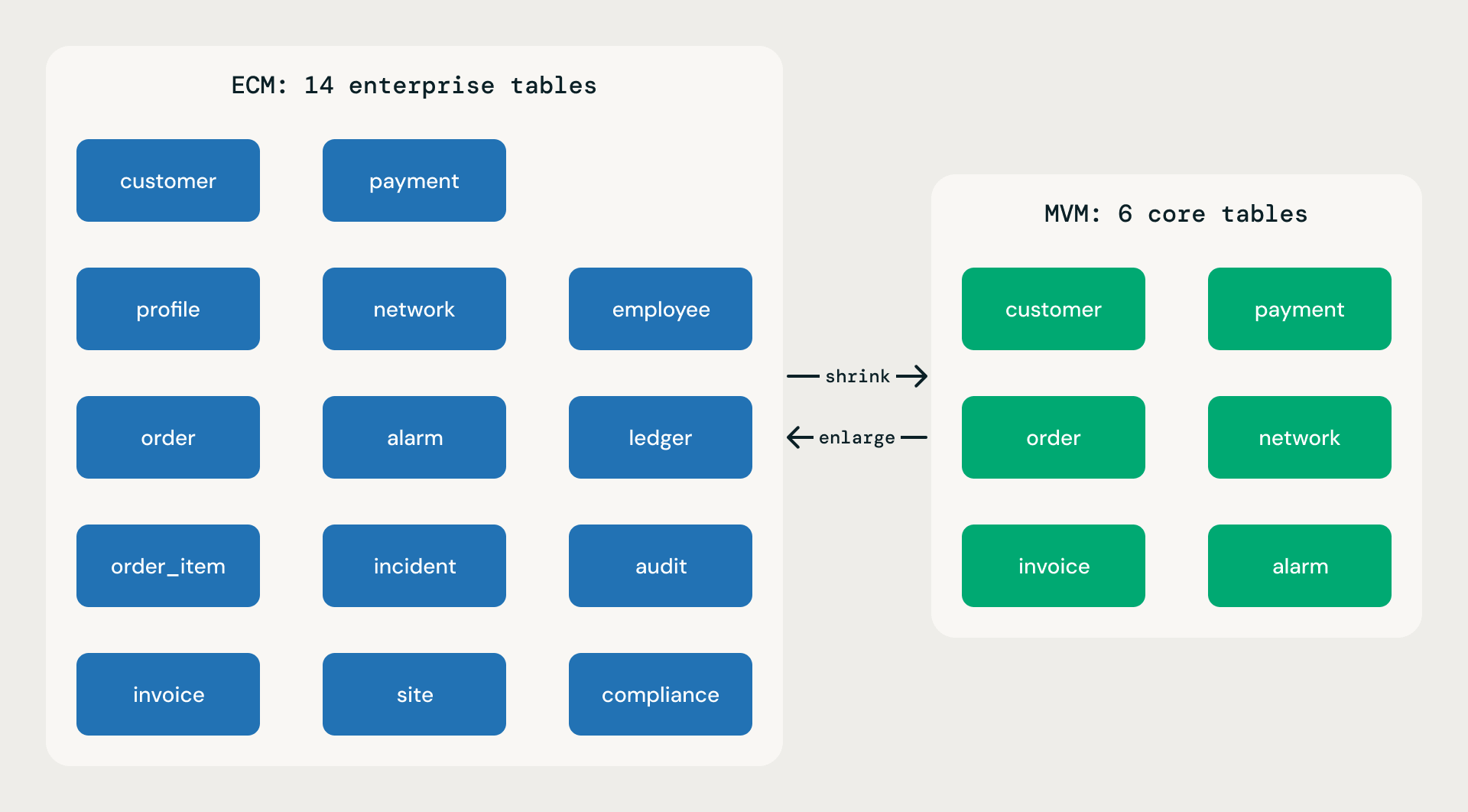
MVM- vs. ECM-Umfang
Warum sind beide Umfänge wichtig? Das Ziel ist nicht, dass Unternehmen viel Zeit damit verbringen, das Modell an ihre Geschäftsdaten anzupassen, sondern vielmehr, schnell mit Analysen im Lakehouse zu beginnen. Die Wahl des richtigen Umfangs spart also von vornherein Zeit.
Die beiden Umfänge sind keine getrennten Wartungslinien. Jedes kann durch eine einzige Transformation aus dem anderen abgeleitet werden: shrink ecm erzeugt eine MVM-Teilmenge, die Kernprodukte schützt und wichtige Fremdschlüssel beibehält; enlarge mvm bewirkt das Gegenteil. Es wird niemals eine Version überschrieben – beide Operationen erstellen eine neue nummerierte Version neben dem Original.
Was diese Modelle unterscheidet
Die von uns veröffentlichten Basismodelle sind keine umbenannten Branchenvorlagen nach Komitee-Standard. Sie werden von einem disziplinierten, regelgesteuerten KI-Agenten erstellt, der bei jedem Modellierungsschritt die strukturelle Qualität sicherstellt. Einige Highlights:
Branchenspezifische Skalierung. Jedes Modell ist auf die tatsächliche Komplexität seines Sektors zugeschnitten. Der Klassifikator nutzt sieben Dimensionen – regulatorische Dichte, Akteurskomplexität, Tiefe der Produkthierarchie, Infrastrukturmanagement, kanonisches Branchenmodell, Transaktionskomplexität und operative Systemlandschaft –, um jede Branche in eine von fünf Stufen (Tiers) einzuordnen. Dies bestimmt wiederum die Anzahl der Domänen, Produkte pro Domäne und die Attributtiefe.
| Tier | Bezeichnung | Merkmale | MVM-Domänen | ECM-Produkte/Domäne |
|---|---|---|---|---|
| tier_1 | Ultra-komplex | Banken, Versicherungen, große Pharmaunternehmen | 15–22 | 14–28 |
| tier_2 | Komplex | Telekommunikation, Energie, Gesundheitswesen | 12–18 | 14–26 |
| tier_3 | Moderat | Fertigung, Einzelhandel | 10–15 | 12–24 |
| tier_4 | Standard | Logistik, Landwirtschaft | 8–12 | 10–20 |
| tier_5 | Einfach | Beratung, SaaS, Medien | 5–8 | 8–18 |
Branchenspezifischer Jargon. Jedes Modell verwendet die Terminologie, die in der jeweiligen Branche tatsächlich gesprochen wird. Die Telekommunikation erhält msisdn, arpu, imsi, cdr. Der Bergbau erhält rom, cut_off_grade, jorc. Das Gesundheitswesen erhält icd, cpt, drg. Das Bankwesen erhält iban. Dies sind keine nachträglichen Einfälle – sie prägen Spaltennamen, Primärschlüsselkonventionen und die Struktur von Governance-Tags.
Das Drei-Bereiche-Gerüst. Jedes Modell ist in drei konzentrischen Ringen organisiert:
- Operations umfasst das, was das Unternehmen physisch tut – Netzwerk, Flotte, Anlage, Infrastruktur.
- Business definiert, wen das Unternehmen bedient und wie es Geld verdient – Kunde, Abrechnung, Produkt, Vertrieb.
- Corporate ist das unterstützende Gerüst – HR, Finanzen, Compliance.
Das Verhältnis wird durch Regeln erzwungen (Regel G06-R001): Operations plus Business müssen mindestens 80 % aller Domänen ausmachen; Corporate ist auf 20 % begrenzt. Dies verhindert das häufigste Fehlerszenario bei uneingeschränkter Modellierung – Modelle, die zur Hälfte aus HR, Finanzen und Recht bestehen und den operativen Kern, der das eigentliche Geschäft ausmacht, vernachlässigen.
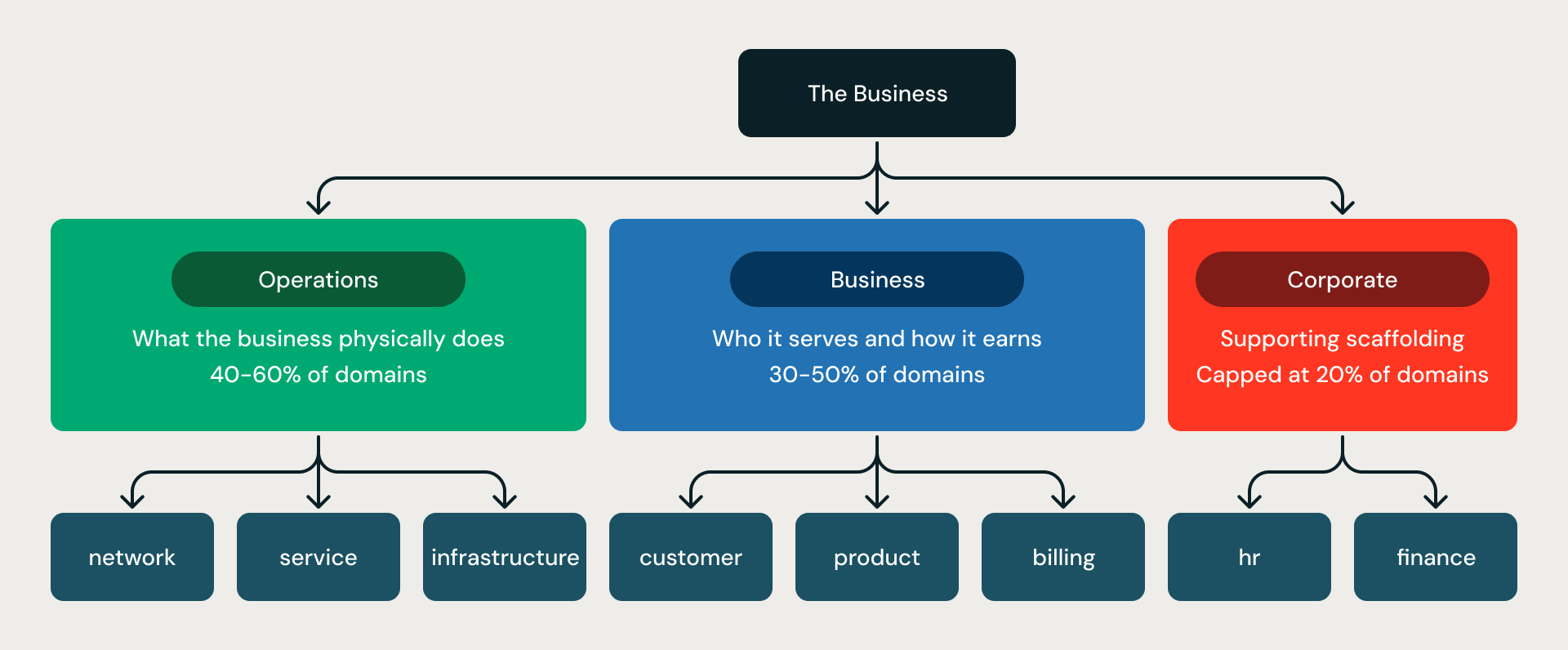
Die drei Bereiche
Die sechsstufige Hierarchie. Jedes Modell folgt derselben strengen Struktur: Organisation → Bereich → Domäne → Unterdomäne → Produkt → Attribut. Die Hierarchie ist keine bloße Empfehlung. Sie wird durch strukturelle Regeln, zwei Stufen von Architekten-Reviews und statische Analysen am Ende jeder Pipeline erzwungen.
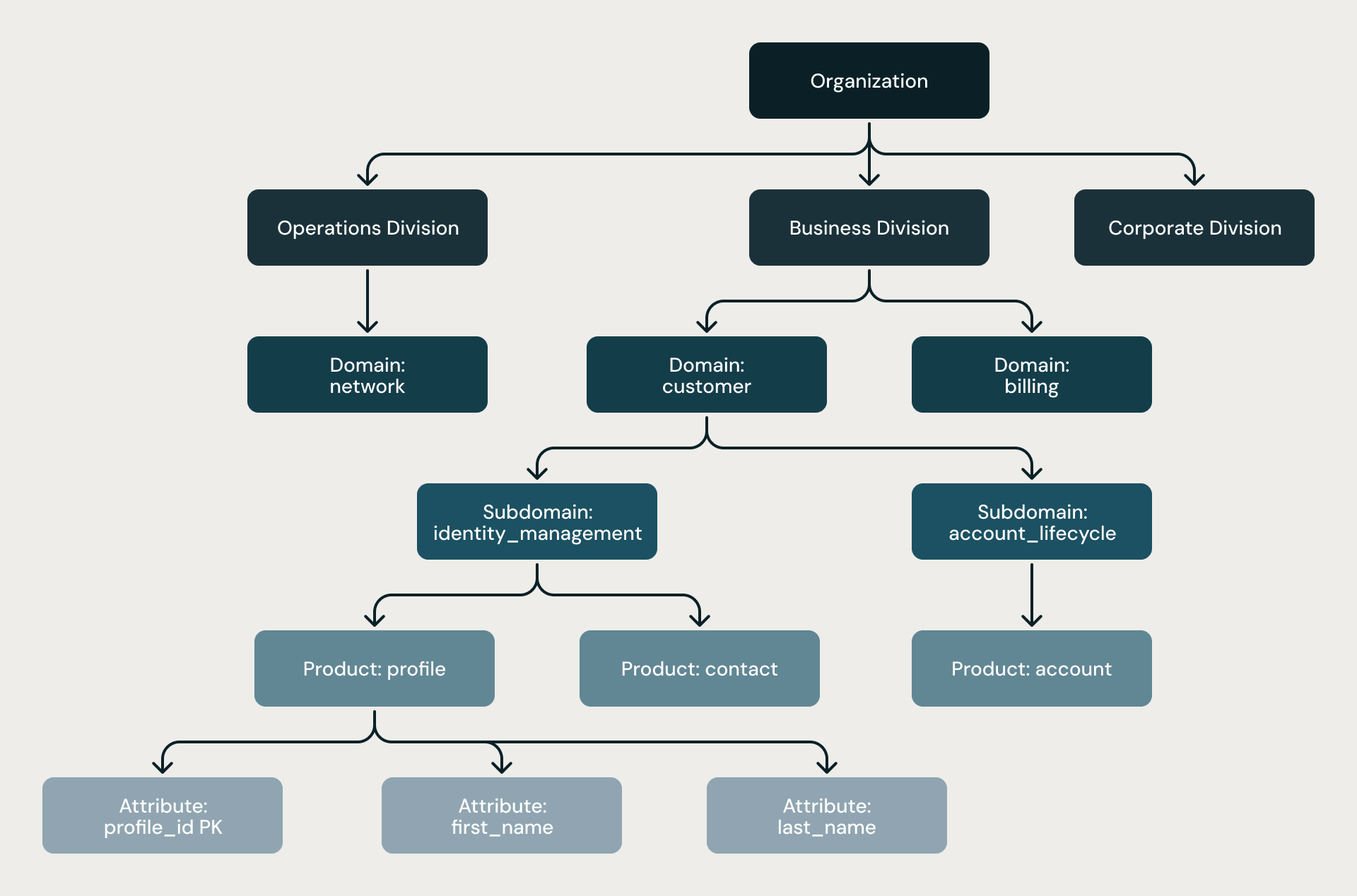
Vierstufige Hierarchie
Über 200 durchsetzbare Regeln. Jedes Basismodell wird anhand von mehr als 200 Regeln validiert, die in über 14 Gruppen unterteilt sind – Namenskonventionen, semantische Deduplizierung, Fremdschlüssel, Primärschlüssel, Normalisierung, Domänenstruktur, Datentypen, Klassifizierungs-Tags, Beziehungs-/DAG-Erzwingung, Qualität, Produktdesign, Vibe-Einschränkungen, physische Schema-Bereitstellung und Unterdomänen-Skalierung. Jede Tabelle muss einen Primärschlüssel haben. Jeder Fremdschlüssel verweist auf ein tatsächliches Ziel. Jede Domäne besteht den Organigramm-Test: „Könnte eine echte Abteilung oder ein echtes Team mit diesem Namen in der Organisation existieren?“ Keine Zyklen. Keine Silos und strikte Einhaltung des Single Source Of Truth (SSOT)-Prinzips.
Ein logisches Modell, drei physische Layouts. Jedes Basismodell wird als eine einzige, umgebungsunabhängige model.json geliefert. Dasselbe logische Modell lässt sich problemlos in Unity Catalog in drei Katalogisierungsstilen bereitstellen: ein Katalog (einzelne Governance-Grenze), Katalog pro Bereich (Operations / Business / Corporate isoliert) oder Katalog pro Domäne (Data-Mesh-freundlich). Bei der erneuten Bereitstellung in einem anderen Stil wird das logische Modell nicht verändert.
Ein konkretes Beispiel: Das Airline-ECM-Modell v1
Um dies zu veranschaulichen, finden Sie hier das Airline-ECM, das heute im Repository bereitgestellt wird.
| Metrik | Wert |
|---|---|
| Modellumfang | ECM v1 |
| Domänen insgesamt | 19 |
| Unterdomänen insgesamt | 60 |
| Produkte insgesamt | 420 |
| Attribute insgesamt | 17.278 |
| Primärschlüssel | 420 |
| Fremdschlüssel | 2.877 |
| Durchschnittliche Attribute/Produkt | 41,1 |
| Metrik-Ansichten | 203 |
Als Graph visualisiert sieht der vollständige DAG so aus (jedes Rechteck ist eine Domain, jeder winzige Kreis ist eine Tabelle und jede Linie ist eine FK-Verbindung):

Airline ECM v1 als verbundener DAG
Die neunzehn Domains lassen sich sauber auf die drei Bereiche aufteilen. Operations umfasst Flughafen, Besatzung, Flotte, Flug, Bestand, Wartung und Route. Business umfasst Zusatzleistungen, Fracht, Treueprogramm, Passagiere, Reservierung, Umsatz, Service und Ticket. Corporate umfasst Compliance, Finanzen, Sicherheit und Personal.

Airline-Domains nach Bereich
Wenn Sie tiefer in eine einzelne Domain einsteigen – den Flugbetrieb –, wird die Struktur auf Arbeitsebene verständlich. Subdomains für Ressourcenauslastung, Flugbetrieb und Passagierservices enthalten die Produkte, die ein Operations Analyst tatsächlich benötigt: leg, flight_plan, oooi_event, atc_clearance, dispatch_release, notam_brief, tech_log, weight_balance, fuel_uplift, pax_segment. (jeder Kreis ist eine Tabelle, jede Linie ist eine FK-Beziehung)

Flug-Domain
Gehen Sie noch weiter ins Detail zu einem einzelnen Datenprodukt – dem Luftfrachtbrief (awb) innerhalb der Cargo-Domain – und Sie sehen genau, wie domänenübergreifende Verknüpfungen funktionieren. awb ist mit corporate_account in der Passenger-Domain, station in Airport, leg in Flight, profit_center, ledger_account und company_code in Finance sowie screening_result in Compliance verbunden. Dies sind die Joins, die ein Analyst für Frachteinnahmen täglich ausführt, und sie sind vorhanden, weil der domänenübergreifende DAG so konzipiert wurde, dass er diese unterstützt.

Datenprodukt „Air Waybill“
Was Sie bei der Bereitstellung erhalten
Jedes Basismodell wird mit einem vollständigen Satz an Artefakten geliefert.
Logische Artefakte. Eine einzelne model.json (das primäre Austauschformat), eine für Menschen lesbare readme.md, flache Exporte von Domains, Produkten und Attributen, Excel- und CSV-Exporte, SQL-DDL-Dateien (eine pro Domain plus eine domänenübergreifende FK-Datei), ein DBML-Schemadiagramm und eine RDF/Turtle-Ontologie.
Physische Artefakte bei der Bereitstellung in einem Unity Catalog. Unity Catalog-Schemata (eines pro Domain oder Subdomain, je nach Katalogisierungsstil), Delta-Tabellen für jedes Produkt, in Abhängigkeitsreihenfolge angewendete Fremdschlüssel-Constraints, Unity Catalog-Klassifizierungstags (PII, eingeschränkt, öffentlich), Databricks-Metrik-Ansichten für wiederverwendbare KPI-Definitionen und synthetische Beispieldaten mit gültigen FK-Referenzen zur sofortigen Erkundung.
Die Datei model.json ist die gemeinsame Basis. Checken Sie sie in Git ein. Vergleichen Sie zwei Versionen. Teilen Sie sie über verschiedene Umgebungen hinweg. Übergeben Sie sie an einen Sicherheitsprüfer, ohne Produktionszugriff gewähren zu müssen. Stellen Sie sie in Dev, Staging und Prod unter drei verschiedenen Katalogisierungsstilen neu bereit und erhalten Sie drei Umgebungen, deren logischer Inhalt Byte für Byte identisch ist.
Die Stärken dieses Ansatzes
- Geschwindigkeit. Grundlagen für den Silver-Layer, die früher Monate gedauert haben, sind jetzt nur noch ein Bereitstellungsschritt.
- Spezifität. Modelle verwenden die Sprache der jeweiligen Branche – ihre Fachbegriffe, ihre regulatorischen Rahmenbedingungen und ihre betriebliche Realität.
- Regelabdeckung. Über 200 durchsetzbare Regeln sorgen für eine Konsistenz, die die meisten manuell erstellten Modelle nie erreichen.
- Governance. Jede Spalte mit sensiblen Daten wird klassifiziert und getaggt. Jedes PK/FK-Paar folgt einer einheitlichen Konvention. Jeder Katalogisierungsstil ist reproduzierbar.
- Vielseitige Verwendbarkeit. Dasselbe Artefakt ist ein relationales Schema, ein DBML-Diagramm, eine Wissensgraph-Ontologie und eine physische Unity Catalog-Bereitstellung.
- Trennung von Logik und Physis. Eine model.json, drei Katalogisierungsstile. Erneute Bereitstellung ohne jeglichen Nacharbeitsaufwand.
Was Sie beachten sollten
Die Basismodelle sind ein Ausgangspunkt, kein fertiges Endprodukt. Fachwissen ist nach wie vor wichtig – die Überprüfung durch Experten wird ein Modell immer auf eine Weise verbessern, wie es nur ein Praktiker aus diesem spezifischen Geschäftsbereich tun kann. Sehr eng gefasste Teilbranchen sind standardmäßig weniger passgenau als Hauptbranchen. Und Organisationen mit strengen Ausschüssen für die Freigabe von Datenmodellen müssen die Ergebnisse weiterhin prüfen lassen. Was sich ändert, ist die Geschwindigkeit, mit der das Artefakt bereitgestellt wird, nicht die Notwendigkeit der Governance.
Wir glauben, dass dieser Kompromiss der richtige ist. Ein Basismodell, das in wenigen Stunden bereitgestellt werden kann und strukturell solide ist, ist ein besserer Ausgangspunkt als eine Vorlage, deren Anpassung ein Jahr dauert.
Probieren Sie es noch heute aus
Das Repository für die 40 Lakehouse-Branchendatenmodelle finden Sie unter https://github.com/databricks-industry-solutions/databricks-industry-data-models Jede Branche wird sowohl mit einem MVM als auch mit einem ECM geliefert. Wählen Sie den Umfang, der zu Ihrem Unternehmen passt, verweisen Sie auf einen Unity Catalog, und schon verfügen Sie über einen bereitgestellten, klassifizierten und FK-validierten Silver-Layer, der für Analysen bereit ist.
Als Nächstes
Ein Basismodell ist ein Ausgangspunkt. Deshalb befinden sich alle Modelle derzeit in der Version v1, und das ist noch nicht die endgültige Form. Jedes Unternehmen hat eigene Begrifflichkeiten, Bereiche und Geschäftsprozesse, die selbst das beste generische Modell nicht exakt abbilden kann. In einem folgenden Beitrag zeigen wir Ihnen, wie Sie die v1-Modelle mithilfe eines KI-Modellierungsagenten für natürliche Sprache anpassen und weiterentwickeln können – indem Sie die gewünschten Änderungen in einfachem Englisch beschreiben und eine maßgeschneiderte Version (v2, v3 usw.) erstellen, während die strukturelle Strenge des Originals erhalten bleibt.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.