Vom Monolithen über Lakebase zu LTAP: Die Datenbank vom Speicher aufwärts neu gedacht
von Reynold Xin
- Fast jede traditionelle Datenbank speichert ihr Write-Ahead-Log und ihre Datendateien auf der Festplatte eines einzelnen Rechners. Dies ist die Hauptursache für das Risiko von Datenverlust, teure Read-Replikate und Hochverfügbarkeitsklone sowie Analyseabfragen, die Transaktionen verlangsamen.
- Lakebase macht Postgres-Compute zustandslos, indem es das Log und die Datendateien in unabhängige Cloud-Dienste (SafeKeeper und PageServer) auslagert. Dies ermöglicht unbegrenzten Speicher, elastischen Compute, dauerhafte Schreibvorgänge, einfachere HA und sofortiges Branching – und das alles ohne nennenswerte zusätzliche Latenz.
- LTAP geht noch einen Schritt weiter, indem es operative Daten einmalig in offenen, spaltenbasierten Formaten speichert, die sowohl von Postgres- als auch von Lakehouse-Engines gelesen werden können. So laufen Analysen auf denselben aktuellen Daten, die gerade erst durch Transaktionen geschrieben wurden – ohne CDC-Pipeline, ohne zweite Kopie und ohne Verlangsamung des transaktionalen Workloads. Im Gegensatz zu HTAP, das versucht, beide Workloads in einer einzigen Engine zu vereinen, vereinheitlicht LTAP auf der Speicherebene und nutzt weiterhin die jeweils beste Engine für jede Aufgabe.
Als ich vor 16 Jahren meine Promotion an der UC Berkeley begann, sagte mein Betreuer zu mir: „OLTP-Datenbanken sind ein gelöstes Problem. Sie funktionieren. Konzentriere dich auf Analysen.“ Wir standen ganz am Anfang der Entwicklung, weitaus mehr strukturierte und unstrukturierte Daten zu sammeln und maschinelles Lernen (das wir heute „AI“ nennen) anzuwenden. Also folgte ich dem Rat und schloss mich meinen Mitgründern bei dem Forschungsprojekt an, aus dem Apache Spark hervorging, und später gründeten wir Databricks.
Beim Aufbau von Databricks begannen wir, verschiedene bestehende Datenbanken zu nutzen, und stellten fest, dass OLTP-Datenbanken alles andere als ein gelöstes Problem waren: Sie waren klobig, schwer zu skalieren und unglaublich anfällig. Irgendwann waren wir so frustriert, dass wir uns fragten, wie eine OLTP-Datenbank aussehen würde, wenn wir sie heute entwerfen würden. Diese Frage führte zu Lakebase, unserer serverlosen Postgres-Datenbank.
Dieser Beitrag befasst sich eingehend mit der OLTP-Architektur von Lakebase. Wir beginnen bei der Speicherschicht einer traditionellen monolithischen Datenbank, um zu sehen, woher die Probleme rühren, und schauen uns dann an, wie Lakebase dieselben Komponenten in unabhängige, ausgelagerte Dienste umstrukturiert. Schließlich widmen wir uns LTAP, wo dieselbe Architektur es ermöglicht, Transaktionen und Analysen auf einer einzigen Kopie der Daten in Echtzeit auszuführen – ohne die Verzögerungen und zusätzlichen Kosten von CDC oder „Spiegelung“ (Mirroring).
Die Datenbank als Monolith
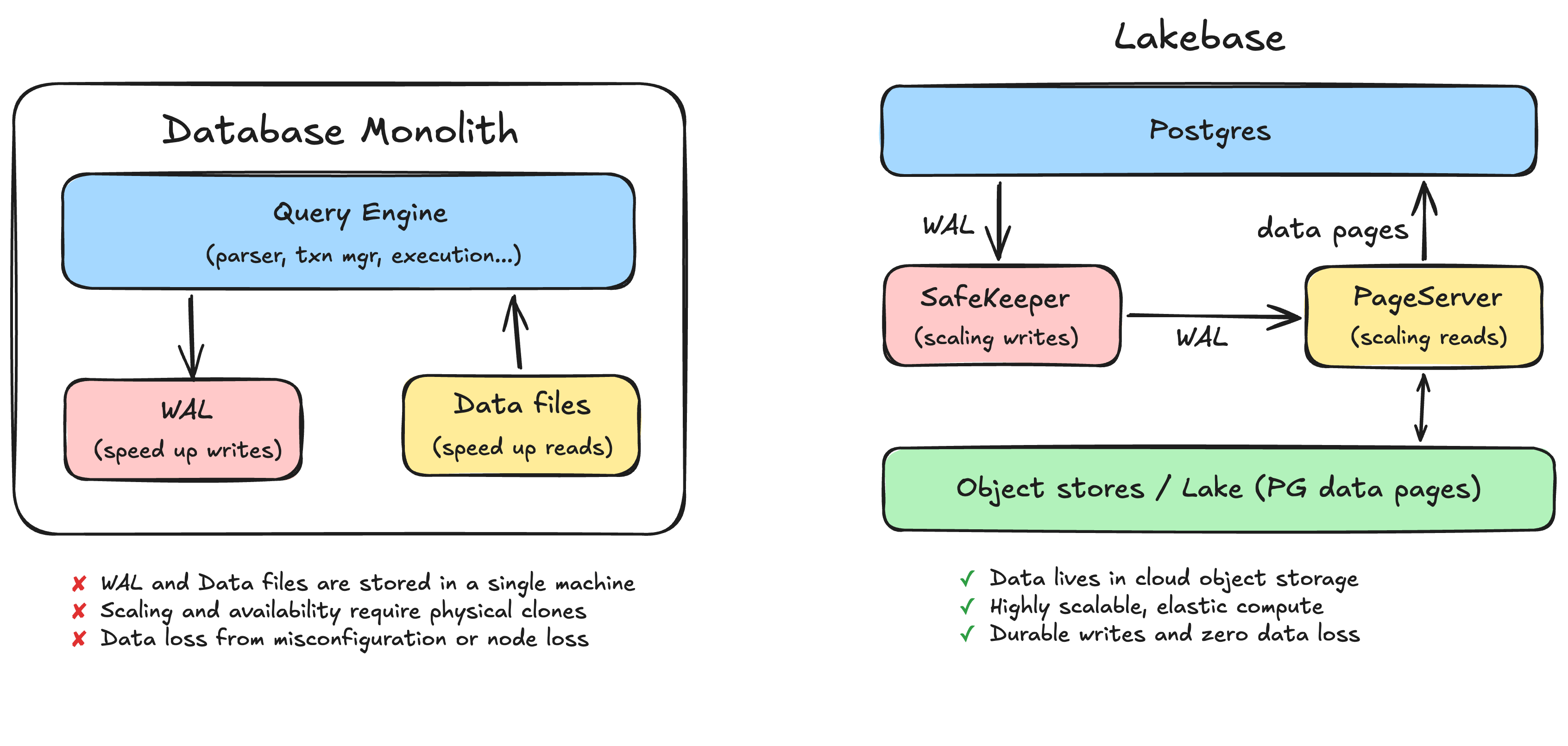
Die überwiegende Mehrheit der heute weltweit eingesetzten Datenbanken sind Monolithen. Dazu gehören MySQL, Postgres und das klassische Oracle. Lakebase basiert auf Postgres (das übrigens auch in Berkeley entwickelt wurde), daher werden wir Postgres hier als Hauptbeispiel verwenden. Die meisten Datenbanken funktionieren jedoch ähnlich: Sie stellen eine Maschine bereit, auf der die Datenbank-Engine und der Speicher laufen. Bei diesen Datenbanksystemen sind zwei Dinge auf der Festplatte am wichtigsten: das Write-Ahead-Log (WAL) und die Datendateien (Data Files).
Wenn Sie eine Transaktion bestätigen (Commit), schreibt die Datenbank die Datendateien nicht sofort neu. Das wäre langsam, da die betroffenen Zeilen über die Datei an Stellen verteilt sind, die zufällige I/O-Zugriffe erfordern. Stattdessen hängt die Datenbank zunächst eine Beschreibung der Änderung an das WAL an, bei dem es sich um ein sequenzielles Protokoll auf der Festplatte handelt. Eine Transaktion gilt in dem Moment als abgeschlossen, in dem dieser Protokolleintrag dauerhaft geschrieben wurde. Erst später, asynchron, aktualisiert die Datenbank die tatsächlichen Datendateien, um die Änderung widerzuspiegeln.
Einfach ausgedrückt: Das WAL existiert, um Schreibvorgänge schnell (und sicher) zu machen, und die Datendateien existieren, um Lesevorgänge schnell zu machen. Das Protokoll ermöglicht es Ihnen, eine Transaktion mit einem einzigen sequenziellen Anhängevorgang zu bestätigen, anstatt viele zufällige I/O-Zugriffe durchzuführen. Die Datendateien ermöglichen es Ihnen, eine Abfrage zu beantworten, indem Sie den aktuellen Zustand direkt lesen, anstatt die gesamte Historie der Datenbank von Anfang an neu abzuspielen. (Wenn Sie alle komplizierten Details dieses Entwurfs verstehen möchten, lesen Sie das 69 Seiten lange ARIES-Paper. Seien Sie gewarnt, dass dies eine der komplexesten Arbeiten in der Informatik ist.)
Da dieses Design zur Grundlage für praktisch alle Datenbanken geworden ist, bringt die monolithische Architektur auch viele Herausforderungen mit sich:
Datenverlust durch Fehlkonfiguration. Ein Commit ist nur so dauerhaft wie das Zurückschreiben (Disk Flush) auf die Festplatte dahinter. Wenn die Datenbank, das Betriebssystem oder die Speicherschicht so konfiguriert ist, dass dem Client ein Schreibvorgang in das WAL bestätigt wird, bevor er tatsächlich auf ein dauerhaftes Medium geschrieben wurde, kann ein Commit bei einem Stromausfall oder einer Kernel-Panic verloren gehen. Diese Einstellungen sind knifflig, man kann leicht Fehler machen, und der Ausfall bleibt oft unbemerkt. Das Betriebssystem entscheidet sich unter Umständen sogar dazu, Sie bezüglich des Zurückschreibens (Flushing) anzulügen!
Datenverlust durch Knotenausfall. Selbst wenn das Zurückschreiben korrekt konfiguriert ist, befinden sich das WAL und die Datendateien auf einer einzigen Maschine. Wenn die Festplatte dieser Maschine ausfällt, sind auch die darauf befindlichen Daten verloren. Beachten Sie, dass netzwerkgebundener Speicher (NAS) oder Redundanzverfahren wie RAID-1/RAID-10 die Ausfallsicherheit verbessern können, das Problem jedoch nicht grundlegend lösen. Wenn die Speicherbereitstellung (Storage Mount) ausfällt, ist auch Ihr Datenzugriff weg.
Das Skalieren von Lesevorgängen erfordert einen physischen Klon. Wenn ein einzelner Server Ihren Datenverkehr nicht mehr bewältigen kann, ist die Standardlösung das Hinzufügen eines Read-Replicas. Ein Read-Replica ist jedoch eine vollständige physische Kopie der gesamten Datenbank, die das WAL vom Primärknoten streamt und abspielt. Die Bereitstellung bedeutet, dass der gesamte Datensatz kopiert und anschließend das Protokoll nachgeholt werden muss. Bei einer großen Datenbank ist dies kein schneller Vorgang und kann die Datenbank sogar zum Absturz bringen.
Hochverfügbarkeit erfordert ebenfalls einen physischen Klon. Um den Ausfall des Primärknotens zu überstehen, muss mindestens ein zusätzlicher Standby-Knoten betrieben werden, der selbst eine vollständige physische Kopie der Datenbank ist und über das WAL synchron gehalten wird. Sie zahlen für mindestens die doppelte Infrastruktur, warten lange, bis ein Standby-Knoten online geht, und müssen eine synchrone Replikation einrichten, um Datenverluste beim Ausfall des Primärknotens zu vermeiden. (In der Praxis empfehlen viele 3 oder mehr Knoten.)
Analysen konkurrieren mit Ihrem Transaktionsverkehr. Eine schwere analytische Abfrage läuft auf denselben Hardwareressourcen wie Ihre latenzempfindlichen Transaktions-Workloads. Eine einzige große Berichtsabfrage oder eine GDPR-Bereinigung kann Ihre Haupt-OLTP-Abfragen beeinträchtigen. Sie können die analytischen Abfragen zwar in einem separaten Replikat ausführen, zahlen dann aber für das Replikat und erhalten aufgrund der zeilenorientierten Natur des OLTP-Speichers immer noch keine optimale Leistung (Analysen erfordern für eine hohe Leistung einen spaltenorientierten Speicher).
Fast jedes dieser Probleme lässt sich auf dieselbe Ursache der monolithischen Architektur zurückführen: Das WAL und die Datendateien werden auf einer einzigen Maschine gespeichert. Die Dauerhaftigkeit ist an die Festplatte dieser Maschine gebunden. Skalierung und Verfügbarkeit erfordern das physische Klonen dieser Maschine. Workloads behindern sich gegenseitig, weil sie sich diese Maschine teilen.
Lakebase-Architektur
Wenn Sie heute eine OLTP-Datenbank neu entwerfen würden, würden Sie mit den Komponenten der modernen Cloud beginnen: kostengünstiger und hochgradig ausfallsicherer Cloud-Objektspeicher gepaart mit elastischer Rechenleistung (Compute). Diesen Weg hat das Neon-Team eingeschlagen, und er bildet das Fundament dessen, was zu Lakebase wurde.
Der entscheidende Schritt besteht darin, die Postgres-Compute-Instanzen zustandslos (stateless) zu machen. Dies erreichen wir, indem wir das WAL und die Datendateien auf lokalen Festplatten in speziell entwickelte, unabhängig skalierbare Dienste auslagern. Die Compute-Schicht wird zu einer zustandslosen Postgres-Engine, die frei gestartet, gestoppt und repliziert werden kann, da sie die Daten nicht mehr selbst besitzt.
Sehen wir uns an, wie diese beiden Speicherdienste zusammenarbeiten können, um die genannten Herausforderungen ohne Leistungseinbußen zu lösen.
Schreibvorgänge skalieren: Aus WAL wird SafeKeeper
In einem Monolithen wird ein Schreibvorgang dauerhaft gemacht, indem er auf die lokale Festplatte geschrieben (flushed) wird. In Lakebase wird das WAL in einen verteilten Speicherdienst namens SafeKeeper ausgelagert. Anstatt sich bei der Dauerhaftigkeit auf das Schreiben auf die Festplatte zu verlassen, wird ein Commit dauerhaft gemacht, indem der Protokolleintrag über ein Quorum von SafeKeeper-Knoten mittels Paxos-basierter Netzwerkreplikation repliziert wird. Es gibt keine Festplatte mehr, deren Ausfall zum Datenverlust führt, und kein fehlerhaft konfiguriertes Zurückschreiben mehr, das Ihre Dauerhaftigkeitsgarantie unbemerkt untergräbt.
An dieser Stelle liegt die Frage nahe: Erhöht die Verlagerung von Commits vom WAL auf der lokalen Festplatte zum WAL auf SafeKeeper die Schreiblatenz aufgrund des zusätzlichen Netzwerkschritts (Network Hop)? Die Antwort lautet: Nein. Bei jeder ernsthaften Postgres-Bereitstellung, bei der Dauerhaftigkeit und Verfügbarkeit eine Rolle spielen, müssten Sie eine synchrone Replikation einrichten, die diesen zusätzlichen Netzwerkschritt erfordert. Die Auslagerung des WAL in SafeKeeper verursacht also keinen zusätzlichen Overhead. Tatsächlich kann die Kombination aus SafeKeeper und PageServer aufgrund der internen Funktionsweise von Postgres zu einem 5-mal höheren Schreibdurchsatz und einer 2-mal geringeren Leselatenz führen.
Lesevorgänge skalieren: Aus Datendateien wird PageServer
Die Datendateien werden in einen anderen verteilten Speicherdienst namens PageServer verlagert. Das WAL wird vom SafeKeeper in den PageServer gestreamt, und der PageServer wendet diese Änderungen asynchron auf seine Version der Daten an, wobei er Pages in kostengünstigem Cloud-Objektspeicher (dem Lake) materialisiert. Sie können sich den PageServer als Write-Through-Cache für den zugrunde liegenden Objektspeicher vorstellen.
Dies ist vergleichbar mit der Beziehung zwischen WAL und Datendateien beim Monolithen, mit dem Unterschied, dass die beiden Hälften nun in separaten, unabhängig skalierbaren Diensten über das Netzwerk verbunden sind, anstatt auf derselben Festplatte zu liegen. Wenn eine Seite vom PageServer angefordert wird und der PageServer noch nicht über die neueste Version verfügt (denken Sie daran, dass Änderungen zuerst in den SafeKeeper geschrieben werden, bevor sie zum PageServer gelangen), wendet der PageServer die Protokolle aus dem SafeKeeper an, um den neuesten Zustand zu rekonstruieren.
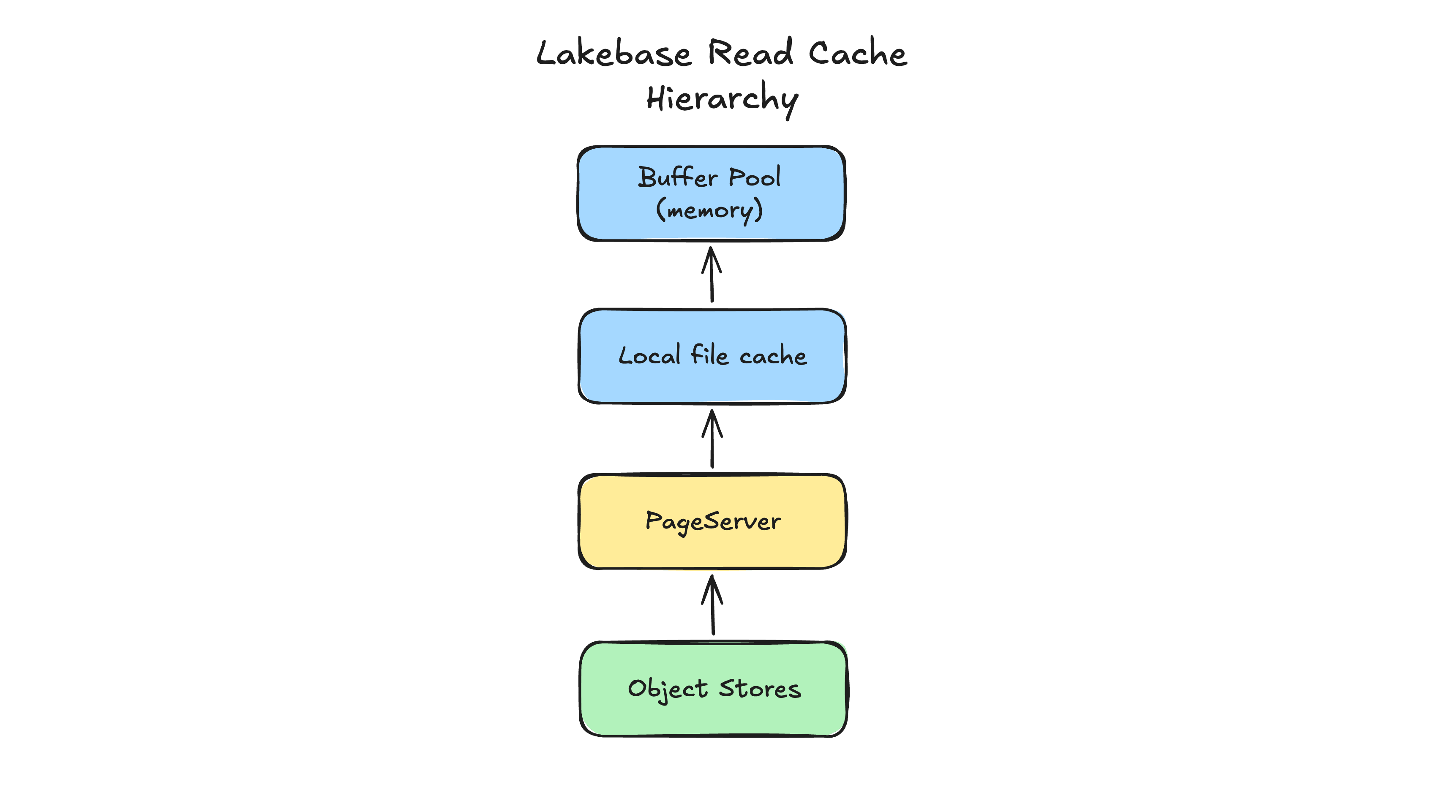
Eine ähnliche Frage: Erhöht das Verschieben von Datendateien von lokalen Festplatten zum PageServer die Leselatenz aufgrund des zusätzlichen Netzwerk-Hops? Die Antwort lautet auch hier praktisch nein. Das System ist so konzipiert, dass es die Auswirkungen auf die Latenz durch aggressives, mehrschichtiges Caching isoliert und minimiert. Um eine Seite abzurufen, sucht Postgres zuerst in seinem Buffer-Pool, der sich im lokalen Speicher des Knotens befindet. Wenn die Seite nicht vorhanden ist, sucht es in einem lokalen Festplatten-Cache. Es muss nur dann auf den PageServer zugreifen, wenn ein Cache-Miss vorliegt. Da ein Compute-Knoten mit lokalen Speicher- und Festplattenkapazitäten konfiguriert werden kann, die mit einem monolithischen Setup identisch sind, bleibt Ihre lokale Cache-Trefferquote unverändert. Bei der überwiegenden Mehrheit der Operationen ist die Leselatenz nicht von einem Monolithen zu unterscheiden, aber Sie profitieren von einem entkoppelten, praktisch unbegrenzten Speicher.
Was dies ermöglicht
Sobald das WAL im SafeKeeper und die Datendateien im PageServer liegen, ergibt sich eine lange Liste von Funktionen, die im Monolithen nur schwer oder gar nicht möglich waren, als logische Konsequenz aus der Architektur. Die folgenden sind bereits als Teil des Lakebase-Produkts sowohl auf Databricks als auch auf Neon weitgehend verfügbar:
Immer noch Postgres. Dies ist echtes Postgres, sodass das Wire-Protokoll, SQL, Treiber und Erweiterungen alle unverändert funktionieren.
Unbegrenzter Speicher. Daten liegen im Cloud-Objektspeicher statt auf einer bereitgestellten lokalen Festplatte. Sie müssen eine Box nicht mehr auf eine maximale Kapazitätsgrenze auslegen. Der Speicher ist praktisch unendlich.
Serverloses, elastisches Compute. Da Compute zustandslos ist, kann es bei Last sofort hochskaliert und im Leerlauf bis auf Null herunterskaliert werden. Sie zahlen nicht mehr für eine große Maschine, die nur darauf wartet, dass Datenverkehr entsteht.
Dauerhafte Schreibvorgänge und kein Datenverlust. Ein Commit ist dauerhaft, sobald er über Paxos auf SafeKeeper-Knoten repliziert wurde, und nicht, wenn eine einzelne lokale Festplatte behauptet, ihn geleert zu haben. Der Verlust eines einzelnen Knotens führt nicht zum Verlust bestätigter Daten.
Einfachere Hochverfügbarkeit. Im Monolithen bedeutete HA die Pflege eines zweiten vollständigen physischen Klons, doppelte Kosten und dennoch das Risiko von Datenverlusten beim Cutover. Hier befindet sich der dauerhafte Zustand bereits in einer replizierten Speicherschicht, die von jeder einzelnen Compute-Instanz unabhängig ist. Ein Failover bedeutet nicht mehr, eine separate physische Kopie der Datenbank hochzustufen und zu hoffen, dass das letzte Segment des Protokolls übertragen wurde.
Sofortiges Branching, Klonen und Wiederherstellen. Das ist mein Favorit. Für Code ist das Erstellen eines Branches eine in Sekundenschnelle erstellte, vollständig isolierte Kopie der gesamten Codebasis, und wir tun dies dutzende Male am Tag, ohne darüber nachzudenken. Bei einer monolithischen Datenbank bedeutet Klonen das physische Kopieren des gesamten Datensatzes, was langsam, teuer und riskant für das Produktionssystem ist. Wenn die Daten in einer ausgelagerten, versionierten Speicherschicht liegen, ist ein Branch oder ein Klon eine Metadatenoperation und keine physische Kopie. Sie können eine große Produktionsdatenbank in Sekundenschnelle branchen, ein Experiment oder eine riskante Migration auf dem Branch ausführen und ihn dann verwerfen. Die Wiederherstellung zu einem bestimmten Zeitpunkt funktioniert genauso. Die Datenbank bewegt sich endlich so schnell wie Ihr Code.
Die Trennung von Compute und Storage ist an sich nicht neu. Der vorherige Beitrag befasste sich mit den Cloud-Datenbanken der Generation 2, die dies bereits getan haben. Der Schlüssel bei Lakebase liegt jedoch darin, dass wir operative Daten in einem offenen Format auf Standard-Objektspeichern speichern. Damit eröffnen wir anderen Engines die Möglichkeit, diese direkt zu lesen, was zu LTAP führt.
LTAP: Eine Kopie für Transaktionen und Analysen
Bisher ging es nur darum, eine einzelne operative Datenbank besser zu machen: langlebiger, elastischer, kostengünstiger im Betrieb, schneller zu branchen. Sobald die Daten jedoch in einer ausgelagerten Speicherschicht liegen, wird etwas weitaus Interessanteres möglich. Wir können aufhören, die transaktionale Datenbank und das analytische System als zwei getrennte Welten zu betrachten.
Kehren wir kurz zum PageServer zurück. Er nimmt bereits den Änderungsstrom aus dem WAL und materialisiert Seiten asynchron im Objektspeicher. Dieser Materialisierungsschritt – der Moment, in dem die Daten im Lake landen – erweist sich als genau der richtige Ort, um ein viel älteres Problem zu lösen...
Selbst bei einer Lakebase wurden die Daten im Objektspeicher immer noch im nativen Seitenformat von Postgres geschrieben, Zeile für Zeile angeordnet. Dieses Format eignet sich hervorragend für Transaktionen, ist aber schlecht für Analysen. Jede Analyse-Engine, die diese Daten lesen wollte, musste daher entweder bei jedem Lesevorgang Konvertierungskosten in Kauf nehmen oder, was häufiger vorkommt, auf eine separate Kopie der Daten zurückgreifen, die durch eine Pipeline synchronisiert gehalten wurde. Die Pipeline kann anfällig sein, und die beiden Kopien der Daten können aufgrund unterschiedlicher Berechtigungen zu einem Governance-Albtraum werden.
Wir haben vor Kurzem LTAP (Lake Transactional/Analytical Processing) angekündigt, das das Problem der zwei Datenkopien beseitigt. Die Kernidee besteht darin, die beiden Welten auf der Speicherebene (Storage-Layer) und nicht auf der Engine-Ebene zu vereinheitlichen. Wir versuchen nicht, eine Engine zu bauen, die irgendwie sowohl für Transaktionen als auch für Analysen hervorragend geeignet ist. Wir behalten das beste Werkzeug für jede Aufgabe: Postgres mit vollständiger ACID-Semantik für Transaktionen und die Lakehouse-Engines für Analysen. Was sich ändert, sind die darunter liegenden Daten. Anstelle von zwei Kopien in zwei Formaten gibt es eine dauerhafte Kopie in offenen spaltenbasierten Formaten wie Delta und Iceberg, gespeichert als Parquet, die von beiden Seiten gelesen wird (und mit verschiedenen Cache-Ebenen für eine bessere Leistung).
Materialisierung im spaltenbasierten Format
Hinweis: Dieser Abschnitt erfordert mehr internes Postgres-Wissen als andere Abschnitte.
Während der PageServer Seiten im Objektspeicher materialisiert, transkodiert er Postgres-Daten von einem Zeilenformat in das spaltenbasierte Layout von Parquet, sobald sie im Lake landen. Wir bewahren die exakte Postgres-Darstellung jedes Wertes bis auf die Bits genau, sodass jede Postgres-kompatible Engine sie ohne Informationsverlust neu interpretieren kann. Dies unterscheidet sich vom CDC-basierten Ansatz, da CDC einen Strom logischer Änderungsereignisse in ein fremdes Schema überträgt und die physische und transaktionale Semantik von Postgres hinter sich lässt; hier behalten wir sie bei. Mit einer hyperoptimierten Engine übernimmt die freie CPU in der PageServer-Schicht die Zeilen-zu-Spalten-Transkodierung als Teil der Materialisierung der Daten im Objektspeicher, sodass die Postgres-Rechenleistung, die Ihre Transaktionen bedient, nicht zusätzlich belastet wird. Um transaktionale Lesevorgänge effizient zu bedienen, materialisiert der PageServer weiterhin traditionelle zeilenbasierte Seiten in einem lokalen Cache, aber dies ist rein ein Performance-Cache. Der zugrunde liegende dauerhafte Speicher bleibt im Lake vereinheitlicht und ist für beide Seiten zugänglich.
Die Beibehaltung der Postgres-Semantik im spaltenbasierten Format läuft auf zwei Dinge hinaus: das Typsystem und Multi-Versioning.
Typsystem. Die Mehrheit der Postgres-Typen lässt sich direkt auf native Parquet-Typen abbilden. Die Handvoll Werte ohne verlustfreies spaltenbasiertes Gegenstück, z. B. NaN und ±Infinity, NUMERICs außerhalb des Dezimalbereichs, exotische Typen oder Erweiterungstypen, werden nicht verworfen oder erzwungen. Sie werden zusammen mit den ursprünglichen Spalten in einem strukturierten Überlauffeld innerhalb derselben Tabelle mitgeführt, das den kanonischen Postgres-Text für diese Werte enthält. Dieses Feld ist sowohl von jeder Engine direkt abfragbar als auch ausreichend, um die ursprünglichen Postgres-Bytes auf dem Rückweg exakt zu rekonstruieren.
Multi-Versioning. In Postgres wird jede Zeilenversion, die eine Transaktion beobachten könnte, beibehalten, was genau das ist, was Snapshot-Isolation und Point-in-Time-Recovery ermöglicht. Im Gegensatz dazu stellen offene Tabellenformate tabellenweit konsistente Snapshots ohne zwischenzeitliche Zeilenversionen bereit. Wir nutzen die Vorteile beider Ansätze, indem wir Haltbarkeit von Sichtbarkeit trennen. Jede in ein spaltenbasiertes Format materialisierte Zeile trägt ihre physische Heap-Adresse (Block und Offset), sodass Heap-Seiten vollständig rekonstruierbar bleiben. Die klassische Postgres-Heap-Seite wird zu einem Cache, der Point-Reads beschleunigt, während die dauerhafte Source of Truth in den spaltenbasierten Dateien im Objektspeicher liegt. Postgres-Indizes werden nicht in Spalten transkodiert; sie werden aus dieser Hot-Cache-Ebene bedient und neu aufgebaut. Zwischenzeitliche Zeilenversionen werden beibehalten, um die MVCC-Semantik und PITR von Postgres zu bewahren, sind jedoch für Iceberg/Delta-Reader nicht sichtbar und werden schließlich per Garbage Collection bereinigt. Das Endergebnis: Analyse-Engines sehen saubere, Snapshot-konsistente Tabellen, während das darunter liegende Postgres-System weiterhin eine vollständige, zeitlich rückverfolgbare Versionshistorie sieht.
Es gibt auch einen angenehmen Nebeneffekt. Spaltenbasierte Daten lassen sich weitaus besser komprimieren als zeilenbasierte Daten, oft um mehr als das Zehnfache. Die Konvertierung in einen spaltenbasierten Speicher reduziert daher das Datenvolumen, das das Netzwerk zwischen der Caching-Ebene und dem Objektspeicher durchquert, so erheblich, dass es oft vernachlässigbar ist. Das Format, das Analysen schnell macht, macht auch den Speicherpfad kostengünstiger. Wir nutzen dies sogar, um während der Übergangsphase der LTAP-Einführung sowohl das Zeilen- als auch das Spaltenformat in Objektspeichern doppelt zu schreiben, um die Daten zu verifizieren (da wir bei Speicheränderungen äußerst vorsichtig sein wollen).
Die neuesten Daten lesen, ohne Postgres zu beeinträchtigen
Eine große Herausforderung ist die Aktualität. Wenn Analysen aus einer Kopie im Lake lesen, wie sehen sie dann Daten, die erst vor einem Moment freigegeben (committed) wurden und noch nicht im Objektspeicher materialisiert sind? Das ist die Frage, an der die meisten Ansätze nach dem Motto „Verweise die Analysen einfach auf den Lake“ scheitern. Es lohnt sich also, im Detail zu betrachten, wie LTAP darauf antwortet.
Wenn eine analytische Abfrage startet (z. B. über das gerade angekündigte Produkt Lakehouse//RT), fragt sie Postgres zuerst nach der aktuellen LSN – der Log Sequence Number, die die genaue Position im WAL markiert, ab der gelesen werden soll. Dies ist eine kostengünstige Metadatenabfrage. Mit dieser LSN liest die Analyse-Engine den weitaus größten Teil der Daten, einschließlich allem, was bis zu diesem Zeitpunkt bereits materialisiert ist, direkt aus dem Objektspeicher. Es bleibt nur die kleine Menge an sehr aktuellen Änderungen übrig, die noch nicht im Lake materialisiert wurden. Diese ruft sie vom PageServer ab und führt sie zusammen.
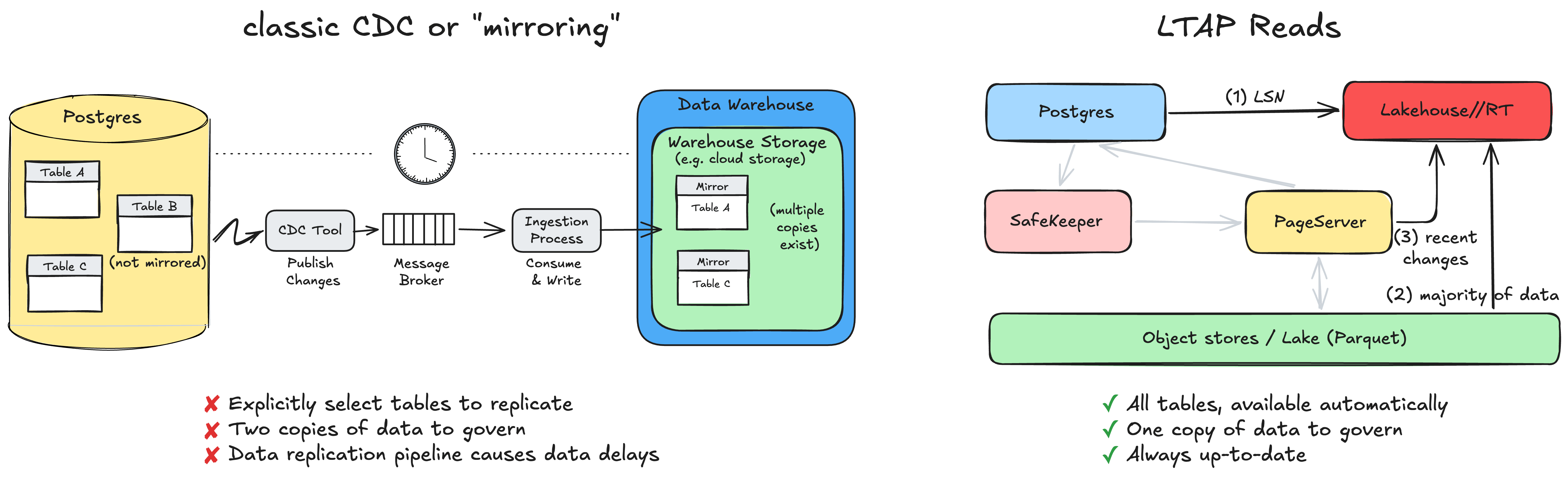
Das Ergebnis ist ein konsistentes, absolut aktuelles Lesen Ihrer Daten auf dem Stand dieser LSN. Fast die gesamte Arbeit entfällt auf den günstigen, skalierbaren Objektspeicher. Und was besonders wichtig ist: Postgres selbst bedient keinerlei analytischen Leseverkehr, abgesehen von der Rückgabe einer einzigen Zahl (LSN). Ihre transaktionale Arbeitslast verlangsamt sich nicht, nur weil jemand eine große analytische Abfrage gestartet hat.
Eine praktische Optimierung ist hier erwähnenswert: Bei sehr kleinen Tabellen, die nur eine Handvoll Zeilen enthalten, sparen wir uns die Konvertierung in das spaltenbasierte Format und die Erstellung der zugehörigen Iceberg-Metadaten. Der Verwaltungsaufwand würde mehr kosten, als er einspart, und eine so winzige Tabelle hat unabhängig von ihrem Layout keinen messbaren Einfluss auf die Analyseleistung. Diese Tabellen sind weiterhin vorhanden und können als Teil der einzigen Kopie abgefragt werden.
Jede Tabelle, ganz automatisch
Da dieses Problem so wichtig ist, gab es auf dem Markt viel Aufsehen um die Integration von OLTP und Analysen. Ein klassischer Ansatz ist CDC, bei dem Daten effektiv aus dem OLTP-Speicher in eine separate Analyse-Speicherebene repliziert werden. Vielleicht haben Sie schon andere Bezeichnungen dafür gehört, wie „Mirroring“, „Zero CDC“ oder „Zero ETL“.
Bei CDC oder „Mirroring“ kann die Datenreplikations-Pipeline, da sie Kosten verursacht, nicht auf alle Tabellen angewendet werden. Sie müssten explizit auswählen, welche Tabellen Ihnen wichtig sind, und diese Replikation ist in der Regel mit einer Verzögerung verbunden.
Bei LTAP müssen Sie sich für nichts aktiv entscheiden. Eine existierende Tabelle befindet sich konstruktionsbedingt bereits im Lake und ist direkt abfragbar. Es gibt keine Liste replizierter oder gespiegelter Tabellen, da es keine Replikation gibt. Es existiert eine einzige, kontrollierte Kopie der Daten in offenen Formaten, ohne dass eine ETL-Pipeline erstellt, überwacht oder repariert werden muss (weder von unseren Kunden noch von uns). Die transaktionalen und analytischen Engines skalieren unabhängig voneinander und sind jeweils auf ihre eigene Arbeitslast ausgelegt. Und da es keine Datenbewegung und keine zweite Kopie gibt, können die beiden Ansichten nie voneinander abweichen: Die Analyse liest immer dieselben Daten, die die Anwendung gerade geschrieben hat.
Um einen weiteren Blick darauf zu werfen, wie LTAP funktioniert, sehen Sie sich diese Demo vom Data and AI Summit an.
Was ist mit HTAP?
Wenn Sie sich in diesem Bereich auskennen, haben Sie bereits bemerkt, dass LTAP eine bewusste Anspielung auf HTAP ist: Hybrid Transactional/Analytical Processing. HTAP gilt als der heilige Gral des Datenbank-Engineerings und konzentriert sich darauf, eine einzige Engine zu entwickeln, die sowohl transaktionale als auch analytische Arbeitslasten bewältigen kann.
In der Praxis gibt es bisher kein einziges, weithin etabliertes HTAP-Datenbanksystem. Warum ist das so? Meiner Meinung nach leiden HTAP-Systeme unter einem oder mehreren der folgenden Probleme:
Unvollständiger Funktionsumfang. Eine neue, proprietäre Engine von Grund auf für eine einzige Aufgabe zu entwickeln, ist eine mehrjährige Investition. Der Versuch, eine einzige Engine zu bauen, die die Aufgaben mehrerer Engines übernehmen kann, vervielfacht die erforderlichen Investitionen, um den Funktionsumfang zu erreichen, den Entwickler bei einer ausgereiften Datenbank als selbstverständlich voraussetzen. Diese Systeme hinken oft bei Dingen hinterher, von denen man annimmt, dass sie immer vorhanden sind – von der Breite der SQL-Unterstützung (z. B. Fremdschlüssel-Unterstützung) bis hin zur Reife des Query-Optimizers.
Kein Ökosystem. Postgres und Spark stehen jeweils im Zentrum eines riesigen Ökosystems: Treiber, Erweiterungen, Tools und jahrzehntelang angesammeltes Betriebswissen. Eine brandneue Engine fängt ganz von vorne an, und eine Engine ist nur so nützlich wie das Ökosystem, auf dem ein Team tatsächlich aufbauen kann.
Keine Leistungsisolierung. Viele HTAP-Systeme führen Transaktionen und Analysen auf derselben Hardware aus, sodass die beiden Arbeitslasten um dieselbe CPU und denselben Speicher konkurrieren. Dies ist derselbe Fehler, mit dem wir beim Monolithen begonnen haben, bei dem eine analytische Abfrage die transaktionale Arbeitslast ausbremst.
Alle drei Probleme lassen sich auf dieselbe Entscheidung zurückführen, die beiden Arbeitslasten in einer einzigen Engine zu vereinen. Lakebase und LTAP umgehen diese Herausforderungen, indem sie auf der Speicherebene vereinheitlicht werden, während für die verschiedenen Arbeitslasten unterschiedliche Compute-Engines verwendet werden. Dadurch können sie deren vollen Funktionsumfang und die Unterstützung des Ökosystems nutzen – bei vollständiger Leistungsisolierung.
Schlussgedanke
Als wir im letzten Jahr die Lakebase-Architektur vorstellten, wussten wir bereits, dass sie unbegrenzten Speicherplatz, elastisches Compute, dauerhafte Schreibvorgänge, einfachere HA und sofortiges Branching ermöglichen würde – basierend auf unseren Erfahrungen mit der Neon-Plattform. Dies ergab sich fast automatisch, sobald das WAL im SafeKeeper und die Datendateien im PageServer lagen.
Die Idee für LTAP entstand erst später, nachdem sich die Teams von Neon und Databricks zusammengeschlossen hatten, um das jahrzehntealte Problem zu lösen, Analysen auf den aktuellsten transaktionalen Daten auszuführen. Während wir in den kommenden Monaten die letzten Details von LTAP klären und es einführen, werden alle Ihre Lakebase-Tabellen für Analysen genauso leistungsstark zur Verfügung stehen wie die Lakehouse-Daten.
Was mich am meisten begeistert, ist das, was vor uns liegt. Während LTAP ein natürlicher nächster Schritt ist, eröffnet dasselbe Design auch viele Optimierungsmöglichkeiten, um andere aufwendige Wartungsarbeiten von den zentralen transaktionalen Arbeitslasten zu trennen. Wir fangen gerade erst an zu erforschen, was diese Architektur alles ermöglicht, und freuen uns darauf, die nächsten Schritte mit Ihnen zu teilen.
Danksagung: Ich möchte dem Lakebase-Team dafür danken, dass es alles, was wir in diesem Blog besprochen haben, in die Realität umgesetzt, diesen Beitrag überprüft und mich bei den technischen Details auf dem Laufenden gehalten hat.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.