Eine neue Ära der Datenbanken: Lakebase
von Ali Ghodsi, Stas Kelvich, Heikki Linnakangas, Nikita Shamgunov, Arsalan Tavakoli-Shiraji, Patrick Wendell, Reynold Xin und Matei Zaharia
Seit Jahrzehnten sind Datenbanken das Rückgrat von Software: Sie treiben leise alles an, von E-Commerce-Checkout-Prozessen bis hin zur Unternehmensressourcenplanung. Jedes Stück Software auf der Welt, jede Anwendung, jeder Workflow, jede KI-generierte Codezeile hängt letztendlich von einer Datenbank im Hintergrund ab. Im Laufe der Zeit haben wir die Art und Weise, wie Anwendungen erstellt werden, komplett neu erfunden, aber die zugrunde liegenden Datenbanken haben sich seit den 1980er Jahren kaum verändert. Sie basieren größtenteils auf Architekturen, die der modernen Cloud vorausgehen, und leiden unter folgenden Problemen:
- Fragile & kostspielige Operationen: Traditionelle Datenbanken gelten als eines der empfindlichsten Infrastrukturteile, und ihr zuverlässiger Betrieb erfordert in der Regel ein Heer von Spezialisten, die „auf Eierschalen gehen“. Sie bündeln Rechenleistung und Speicher in einer starren, monolithischen Einheit. Dies zwingt Teams, für Spitzenlasten zu provisionieren, was zu teuren Leerlaufressourcen führt. Wenn die Last die provisionierte Kapazität übersteigt, können Datenbanken nicht mehr reagieren. Schlimmer noch, einfache Wartungsaufgaben wie das Erstellen eines Datenbank-Snapshots oder das Ausführen einer GDPR-Bereinigungsabfrage können die gesamte Datenbank zum Absturz bringen.
- Umständliche Entwicklungserfahrung: Traditionelle Datenbanken stehen im Widerspruch zu modernen, agilen Entwicklungs-Workflows. Für Code dauert es weniger als eine Sekunde, einen Git-Branch für die Entwicklung zu erstellen, der ein vollständig isolierter Klon der Codebasis ist. Für Datenbanken dauert es viele Minuten, wenn nicht Stunden, eine bereitzustellen, und das Erstellen eines hochpräzisen Klons der Produktionsdatenbank ist sehr kostspielig und birgt das Risiko, die Produktionsdatenbank zum Absturz zu bringen. Der Aufstieg der KI-gesteuerten Entwicklung hat diesen Druck nur noch verstärkt. KI-Agenten müssen sofort temporäre, isolierte Umgebungen für Experimente hochfahren.
- Extremer Vendor Lock-in: Datenbankmigrationen gehören zu den beängstigendsten technischen Projekten in jedem Unternehmen. Die monolithische Architektur bedeutet, dass der einzige Weg, Daten hinein- oder herauszubekommen, über die Datenbank-Engine selbst führt. Dies führt zu einem erheblichen Vendor Lock-in, wodurch Unternehmen stark vom jeweiligen Anbieter abhängig werden.
Es ist an der Zeit, dass Datenbanken sich weiterentwickeln.
Was ist eine Lakebase?
Neue Systeme beginnen aufzutauchen, die die Einschränkungen traditioneller Datenbanken adressieren. Eine Lakebase ist eine neue, offene Architektur, die die besten Elemente von Transaktionsdatenbanken mit der Flexibilität und den wirtschaftlichen Vorteilen des Data Lake kombiniert. Lakebases werden durch ein grundlegend neues Design ermöglicht: Trennung von Compute und Storage und Platzierung der Datenbankdaten direkt in kostengünstigem Cloud-Speicher („Lake“) in offenen Formaten, während die transaktionale Compute-Schicht unabhängig darauf läuft.
Diese Trennung ist der Kern des Durchbruchs. Traditionelle Datenbanken bündeln CPU und Speicher in einem monolithischen System, das als eine einzige große Maschine provisioniert, verwaltet und bezahlt werden muss. Lakebase teilt diese Schichten auf. Daten leben offen im Lake, während die Datenbank-Engine zu einer vollständig verwalteten, serverlosen Compute-Schicht (z. B. Postgres) wird, die sich sofort skalieren lässt. Diese Architektur eliminiert einen Großteil der Kosten, Komplexität und des Lock-ins, die Datenbanken seit Jahrzehnten definieren, und ist besonders leistungsfähig für moderne KI- und agentengesteuerte Workloads, bei denen Entwickler viele Instanzen starten, frei experimentieren und nur für das bezahlen möchten, was sie verwenden.
Eine Lakebase hat die folgenden Hauptmerkmale:
Storage ist von Compute getrennt: Daten werden kostengünstig in Cloud-Objektspeichern („Lake“) gespeichert, während Compute unabhängig und elastisch läuft. Dies ermöglicht massive Skalierbarkeit, hohe Nebenläufigkeit und die Möglichkeit, die Skalierung in weniger als einer Sekunde auf Null zu reduzieren (etwas, das in älteren Datenbanksystemen nicht möglich ist), wodurch die Notwendigkeit entfällt, teure Datenbankmaschinen im Leerlauf laufen zu lassen.
Unbegrenzter, kostengünstiger, langlebiger Speicher: Da die Daten im Lake liegen, ist der Speicher praktisch unbegrenzt und dramatisch günstiger als bei traditionellen Datenbanksystemen, die Infrastruktur mit fester Kapazität erfordern. Und sein Speicher wird durch die Langlebigkeit von Cloud-Objektspeichern (z. B. S3) unterstützt und bietet standardmäßig eine Langlebigkeit von 99,999999999 %. Dies ist herkömmlichen Datenbank-Setups mit Replikaten zur Speicherredundanz weit überlegen (die meist asynchron aktualisiert werden, was bedeutet, dass es in vielen Konfigurationen bei Doppel-Fehlern zu Datenverlust kommen kann).
Elastische, serverlose Postgres-Compute: Lakebase bietet vollständig verwaltetes, serverloses Postgres, das sich sofort an die Nachfrage anpasst und bei Nichtgebrauch skaliert. Die Kosten richten sich direkt nach der Nutzung, was es ideal für bursty Workloads, Entwicklungsumgebungen und KI-Agenten macht, die temporäre Instanzen hochfahren.
Sofortiges Branching, Klonen und Wiederherstellen: Datenbanken können wie Code-Branches verzweigt und geklont werden. Selbst Petabyte-große Datenbanken können in Sekunden kopiert werden, was schnelle Experimente, sichere Rollbacks und sofortige Wiederherstellung ohne Betriebsaufwand ermöglicht.
Vereinte Transaktions- und Analyse-Workloads: Lakebase integriert sich nahtlos in den Lakehouse und teilt sich die gleiche Speicherschicht für OLTP und OLAP. Dies ermöglicht die Ausführung von Echtzeit-Analysen, maschinellem Lernen und KI-gesteuerter Optimierung direkt auf Transaktionsdaten, ohne diese zu verschieben oder zu duplizieren.
Offen und Multicloud by Design: Daten, die in offenen Formaten gespeichert sind, vermeiden proprietäre Lock-ins und ermöglichen echte Portabilität über AWS, Azure und darüber hinaus. Die integrierte Multicloud-Flexibilität unterstützt Disaster Recovery, langfristige Freiheit und bessere Wirtschaftlichkeit im Laufe der Zeit.
Dies sind die Hauptmerkmale von Lakebase. Transaktionssysteme der Enterprise-Klasse erfordern zusätzliche Funktionen wie Sicherheit, Governance, Auditing und Hochverfügbarkeit – aber mit einer Lakebase müssen diese Funktionen nur einmal auf einer einzigen offenen Grundlage implementiert und verwaltet werden. Lakebase repräsentiert die nächste Evolution von Datenbanken: Transaktionssysteme neu aufgebaut für die Cloud, für Entwickler und für das KI-Zeitalter.
Entwicklung der Datenbankarchitektur
Um zu verstehen, warum eine neue Ära benötigt wird, ist es hilfreich, die Entwicklung der Datenbankarchitektur in den letzten fünfzig Jahren zu betrachten. Wir sehen diese Entwicklung in drei verschiedenen Generationen:
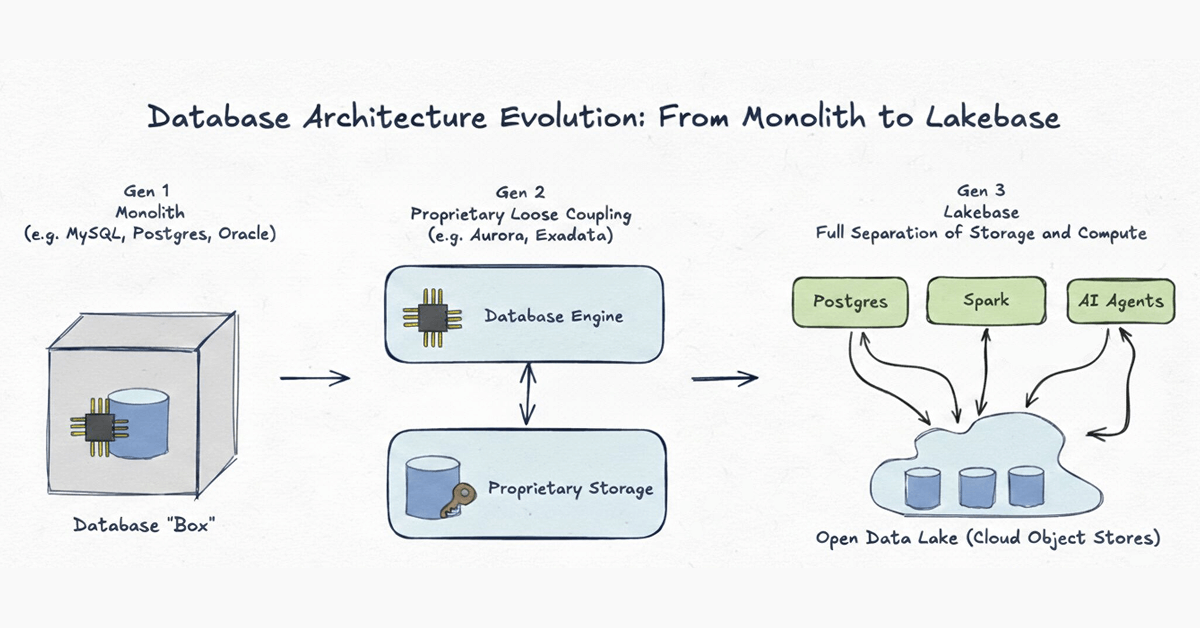
Generation 1: Monolith
Beispiele: MySQL, Postgres, klassisches Oracle
Datenbanksysteme begannen als absolute Monolithen. In der Ära vor der Cloud war das Netzwerk der langsamste Teil eines jeden Systems. Der einzige Weg, eine Hochleistungsdatenbank zu entwerfen, war, die Rechenleistung (CPU/RAM) und den Speicher (Festplatte) eng in einer einzigen physischen Maschine zu binden. Das war zwar für die Hardwarebeschränkungen der 1980er Jahre sinnvoll, schuf aber einen starren Käfig, in dem Daten in proprietären Formaten gefangen waren und Skalierung bedeutete, eine größere Box zu kaufen.
Generation 2: Proprietäre lose Kopplung von Storage
Beispiele: Aurora, Oracle Exadata
Mit der Verbesserung der Cloud-Infrastruktur trennten die Anbieter physisch Speicher und Rechenleistung und verlagerten den Speicher in proprietäre Backend-Schichten. Diese Systeme waren technische Meisterleistungen, die die Grenzen des Durchsatzes verschoben. Sie gingen jedoch nicht weit genug. Die Trennung war nur eine interne Optimierung. Da die Daten in einem proprietären Format eingeschlossen bleiben, das nur von einer einzigen Engine zugänglich ist, leiden Gen 2-Systeme unter strukturellen Sackgassen:
- Single-Engine-Chokehold: Daten sind nur über die primäre Datenbank-Engine zugänglich, die zum Engpass wird. Für KI-Agenten oder Analyse-Engines, die auf die Daten in großem Maßstab zugreifen, ist dies schwierig.
- Analytische Reibung: Da OLAP-Engines nicht direkt auf die Datenbankdateien in großem Maßstab zugreifen können, bleibt das Ausführen von Analyseabfragen schwierig und erfordert in der Regel komplexes ETL, um Daten zu verschieben.
- Cloud Lock-in: Die Speicherschicht ist oft eng an die proprietäre Infrastruktur des jeweiligen Cloud-Anbieters gekoppelt. Dies erschwert die Multicloud-Interoperabilität und macht echtes Cross-Cloud High Availability und Disaster Recovery (HADR) unmöglich. Wenn die Region des Anbieters ausfällt, sind Ihre Daten gefangen.
Wir glauben, dass diese Systeme sich in einem Übergangszustand zur ultimativen 3. Generation befinden.
Generation 3: Lakebase - Offener Speicher auf dem Lake
Eine Lakebase treibt die entkoppelte Architektur zu ihrer ultimativen, logischen Schlussfolgerung. Wie Gen 2 trennt sie Compute von Storage, aber mit einem entscheidenden Unterschied: Sowohl die Speicherinfrastruktur als auch die Datenformate sind vollständig offen.
Aufbauend auf dieser Architektur kann sie die oben genannten 3 Herausforderungen lösen:
- Bessere Zuverlässigkeit und geringere Kosten durch einfachere Vorgänge: Gängige Vorgänge wie Bereitstellung, Skalierung (hoch, runter), Verzweigung, Snapshotting und Wiederherstellung können in Sekunden abgeschlossen werden. Teure Abfragen können auf anderen elastischen Compute-Instanzen ausgeführt werden, ohne den Produktionsverkehr zu beeinträchtigen.
- Git-ähnliche Entwicklererfahrung: Das Experimentieren und Entwickeln von Anwendungen wird schneller, basierend auf einer hochgradig getreuen Kopie der Produktionsdatenbanken. Für Entwickler und KI-Agenten bedeutet dies, dass die Datenbank so schnell ist wie ihr Code.
- Löst extremes Vendor Lock-in: Mit Daten in offenen Formaten, die in Cloud-Objektspeichern gespeichert sind, sind Sie viel weniger eingeschränkt. Sie besitzen Ihre Daten, unabhängig von der Engine.
In vielerlei Hinsicht ist eine Lakebase das, was Sie bauen würden, wenn Sie heute OLTP-Datenbanken neu gestalten müssten, jetzt, da günstiger, zuverlässiger Objektspeicher und Cloud-Elastizität verfügbar sind. Da Organisationen durch die Einführung von Cloud und KI schneller werden, erwarten wir, dass dieses Modell zu einer Standardgrundlage für den Aufbau von Transaktionssystemen wird.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.