Leistung von LLMs mit langem Kontext RAG
Mehr Kontext hilft nicht immer
von Quinn Leng, Jacob Portes, Sam Havens, Matei Zaharia und Michael Carbin
Retrieval Augmented Generation (RAG) ist der am weitesten verbreitete Anwendungsfall für generative KI bei unseren Kunden. RAG verbessert die Genauigkeit von LLMs, indem Informationen aus externen Quellen wie unstrukturierten Dokumenten oder strukturierten Daten abgerufen werden. Mit der Verfügbarkeit von LLMs mit längeren Kontextlängen wie Anthropic Claude (200k Kontextlänge), GPT-4-turbo (128k Kontextlänge) und Google Gemini 1.5 pro (2 Millionen Kontextlänge) können LLM-App-Entwickler mehr Dokumente in ihre RAG-Anwendungen einspeisen. Wenn man die längeren Kontextlängen auf die Spitze treibt, gibt es sogar eine Debatte darüber, ob lange Kontext-Sprachmodelle RAG-Workflows letztendlich ersetzen werden. Warum einzelne Dokumente aus einer Datenbank abrufen, wenn man den gesamten Korpus in das Kontextfenster einfügen kann?
Dieser Blogbeitrag untersucht die Auswirkungen der erhöhten Kontextlänge auf die Qualität von RAG-Anwendungen. Wir haben über 2.000 Experimente mit 13 beliebten Open-Source- und kommerziellen LLMs durchgeführt, um ihre Leistung auf verschiedenen domänenspezifischen Datensätzen aufzudecken. Wir haben festgestellt, dass:
- Das Abrufen von mehr Dokumenten kann tatsächlich von Vorteil sein: Das Abrufen von mehr Informationen für eine bestimmte Abfrage erhöht die Wahrscheinlichkeit, dass die richtigen Informationen an das LLM weitergegeben werden. Moderne LLMs mit langen Kontextlängen können dies nutzen und dadurch das RAG-System insgesamt verbessern.
- Längerer Kontext ist nicht immer optimal für RAG: Die Leistung der meisten Modelle nimmt nach einer bestimmten Kontextgröße ab. Insbesondere die Leistung von Llama-3.1-405b beginnt nach 32k Tokens abzunehmen, GPT-4-0125-preview beginnt nach 64k Tokens abzunehmen, und nur wenige Modelle können die konsistente Leistung von Long-Context-RAG über alle Datensätze hinweg aufrechterhalten.
- Modelle versagen bei langem Kontext auf hochgradig unterschiedliche Weise: Wir haben detaillierte Analysen der Long-Context-Leistung von Llama-3.1-405b, GPT-4, Claude-3-sonnet, DBRX und Mixtral durchgeführt und einzigartige Fehlermuster identifiziert, wie z. B. Ablehnungen aufgrund von Urheberrechtsbedenken oder die ständige Zusammenfassung des Kontexts. Viele dieser Verhaltensweisen deuten auf einen Mangel an ausreichendem Long-Context-Post-Training hin.
Hintergrund
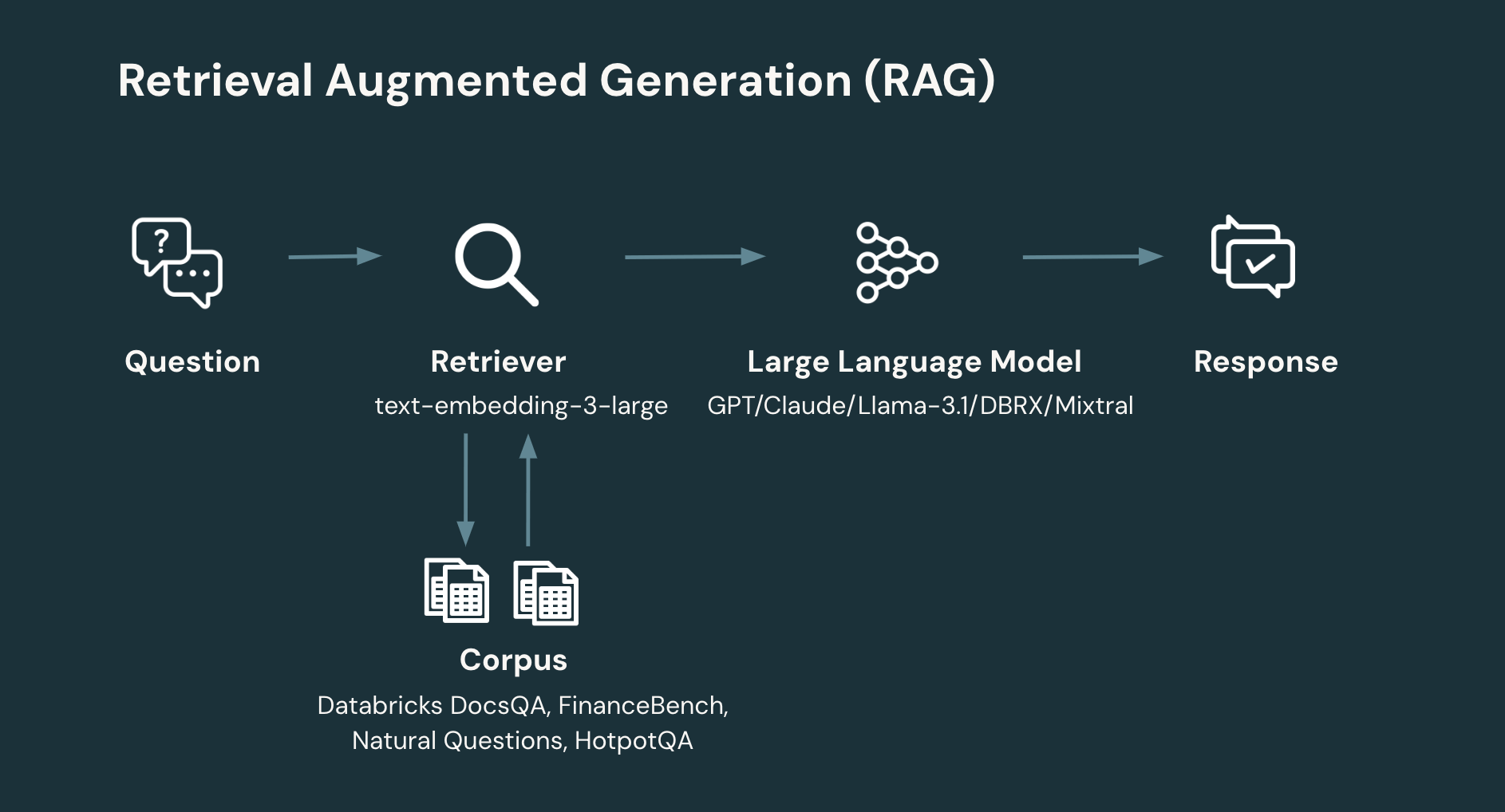
RAG: Ein typischer RAG-Workflow umfasst mindestens zwei Schritte:
- Retrieval: Ermitteln der relevanten Informationen aus einem Korpus oder einer Datenbank anhand der Frage des Benutzers. Information Retrieval ist ein reichhaltiges Gebiet des Systemdesigns. Ein einfacher, zeitgemäßer Ansatz besteht jedoch darin, einzelne Dokumente einzubetten, um eine Sammlung von Vektoren zu erzeugen, die dann in einer Vektordatenbank gespeichert werden. Das System ruft dann relevante Dokumente basierend auf der Ähnlichkeit der Benutzerfrage mit dem Dokument ab. Ein wichtiger Designparameter beim Retrieval ist die Anzahl der abzurufenden Dokumente und damit die Gesamtzahl der Tokens.
- Generierung: Generieren der entsprechenden Antwort (oder Verweigern, wenn nicht genügend Informationen vorhanden sind, um eine Antwort zu generieren) anhand der Benutzerfrage und der abgerufenen Informationen. Der Generierungsschritt kann eine breite Palette von Techniken anwenden. Ein einfacher, zeitgemäßer Ansatz besteht jedoch darin, ein LLM über einen einfachen Prompt anzusprechen, der die abgerufenen Informationen und den relevanten Kontext für die zu beantwortende Frage einführt.
RAG hat gezeigt, dass es die Qualität von QA-Systemen in vielen Domänen und Aufgaben verbessert (Lewis et.al 2020).
Long-Context-Sprachmodelle: Moderne LLMs unterstützen zunehmend größere Kontextlängen.
Während das ursprüngliche GPT-3.5 nur eine Kontextlänge von 4k Tokens hatte, haben GPT-4-turbo und GPT-4o eine Kontextlänge von 128k. Ebenso hat Claude 2 eine Kontextlänge von 200k Tokens und Gemini 1.5 pro eine Kontextlänge von 2 Millionen Tokens. Die maximale Kontextlänge von Open-Source-LLMs hat einen ähnlichen Trend gezeigt: Während die erste Generation von Llama-Modellen nur eine Kontextlänge von 2k Tokens hatte, haben neuere Modelle wie Mixtral und DBRX eine Kontextlänge von 32k Tokens. Das kürzlich veröffentlichte Llama 3.1 hat maximal 128k Tokens.
Der Vorteil der Verwendung von langem Kontext für RAG besteht darin, dass das System den Retrieval-Schritt erweitern kann, um mehr abgerufene Dokumente in den Kontext des Generierungsmodells aufzunehmen, was die Wahrscheinlichkeit erhöht, dass ein für die Beantwortung der Frage relevantes Dokument für das Modell verfügbar ist.
Andererseits haben neuere Auswertungen von Long-Context-Modellen zwei weit verbreitete Einschränkungen aufgezeigt:
- Das „Lost in the Middle“-Problem: Das „Lost in the Middle“-Problem tritt auf, wenn Modelle Schwierigkeiten haben, Informationen aus den mittleren Teilen langer Texte zu behalten und effektiv zu nutzen. Dieses Problem kann zu einer Leistungsverschlechterung führen, wenn die Kontextlänge zunimmt, da die Modelle Informationen, die über umfangreiche Kontexte verteilt sind, weniger effektiv integrieren können.
- Effektive Kontextlänge: Das RULER-Paper untersuchte die Leistung von Modellen mit langem Kontext bei mehreren Aufgabentypen, darunter Retrieval, Variablenverfolgung, Aggregation und Fragebeantwortung. Dabei wurde festgestellt, dass die effektive Kontextlänge – der nutzbare Kontextumfang, über den hinaus die Modellleistung zu sinken beginnt – – viel kürzer sein kann als die angegebene maximale Kontextlänge.
Mit diesen Forschungserkenntnissen im Hinterkopf haben wir mehrere Experimente entwickelt, um den potenziellen Wert von Modellen mit langem Kontext und die effektive Kontextlänge von Modellen mit langem Kontext in RAG-Workflows zu untersuchen und zu bewerten, wann und wie Modelle mit langem Kontext versagen können.
Methodik
Um den Einfluss von langem Kontext auf Retrieval und Generierung, sowohl einzeln als auch auf die gesamte RAG-Pipeline, zu untersuchen, haben wir die folgenden Forschungsfragen untersucht:
- Der Einfluss von langem Kontext auf das Retrieval: Wie beeinflusst die Menge der abgerufenen Dokumente die Wahrscheinlichkeit, dass das System ein relevantes Dokument abruft?
- Der Einfluss von langem Kontext auf RAG: Wie ändert sich die Generierungsleistung als Funktion von mehr abgerufenen Dokumenten?
- Die Ausfallmodi für langen Kontext bei RAG: Wie versagen verschiedene Modelle bei langem Kontext?
Für die Experimente 1 und 2 verwendeten wir die folgenden Retrieval-Einstellungen:
- Embedding-Modell: (OpenAI) text-embedding-3-large
- Chunk-Größe: 512 Tokens (wir teilten die Dokumente aus dem Korpus in Chunks der Größe 512 Tokens auf)
- Stride-Größe: 256 Tokens (die Überlappung zwischen benachbarten Chunks beträgt 256 Tokens)
- Vektorspeicher: FAISS (mit IndexFlatL2-Index)
Für Experiment 2 verwendeten wir die folgenden LLM-Generierungseinstellungen:
- Generierungsmodelle: gpt-4o, claude-3-5-sonnet, claude-3-opus, claude-3-haiku, gpt-4o-mini, gpt-4-turbo, claude-3-sonnet, gpt-4, meta-llama-3.1-405b, meta-llama-3-70b, mixtral-8x7b, dbrx, gpt-3.5-turbo
- Temperatur: 0.0
- max_output_tokens: 1024
Beim Benchmarking der Leistung bei der Kontextlänge X verwendeten wir die folgende Methode, um zu berechnen, wie viele Tokens für den Prompt verwendet werden sollen:
- Bei gegebener Kontextlänge X zogen wir zunächst 1k Tokens ab, die für die Modellausgabe verwendet werden
- Anschließend ließen wir einen Puffer von 512 Tokens
Der Rest ist die Obergrenze für die Länge des Prompts (dies ist der Grund, warum wir eine Kontextlänge von 125k statt 128k verwendet haben, da wir genügend Puffer lassen wollten, um Fehler außerhalb des Kontexts zu vermeiden).
Evaluierungsdatensätze
In dieser Studie haben wir alle LLMs auf 4 kuratierten RAG-Datensätzen gebenchmarkt, die sowohl für Retrieval als auch für Generierung formatiert waren. Dazu gehörten Databricks DocsQA und FinanceBench, die branchenspezifische Anwendungsfälle darstellen, sowie Natural Questions (NQ) und HotPotQA, die eher akademische Umgebungen repräsentieren. Nachfolgend finden Sie die Details zu den Datensätzen:
| Datensatz \ Details | Kategorie | Korpus #Docs | # Abfragen | Durchschn. Doc-Länge (Tokens) | Min. Doc-Länge (Tokens) | Max. Doc-Länge (Tokens) | Beschreibung |
| Databricks DocsQA (v2) | Anwendungsspezifisch: Unternehmens-Fragebeantwortung | 7563 | 139 | 2856 | 35 | 225941 | DocsQA ist ein interner Frage-Antwort-Datensatz, der Informationen aus öffentlichen Databricks-Dokumentationen sowie reale Benutzerfragen und gekennzeichnete Antworten verwendet. Jedes der Dokumente im Korpus ist eine Webseite. |
| FinanceBench (150 Aufgaben) | Anwendungsspezifisch: Finanz-Fragebeantwortung | 53399 | 150 | 811 | 0 | 8633 | FinanceBench ist ein akademischer Datensatz für Frage-Antwort-Systeme, der Seiten aus 360 SEC 10k Einreichungen von öffentlichen Unternehmen sowie die entsprechenden Fragen und Antworten auf Basis von SEC 10k Dokumenten enthält. Weitere Details finden Sie in der Arbeit Islam et al. (2023). Wir verwenden eine proprietäre (Closed-Source) Version des vollständigen Datensatzes von Patronus. Jedes der Dokumente in unserem Korpus entspricht einer Seite aus den SEC 10k PDF-Dateien. |
| Natural Questions (Entwicklungs-Split) | Akademisch: Allgemeinwissen (Wikipedia) Frage-Antwort-System | 7369 | 534 | 11354 | 716 | 13362 | Natural Questions ist ein akademischer Datensatz für Frage-Antwort-Systeme von Google, der in ihrer Arbeit von 2019 beschrieben wird (Kwiatkowski et al., 2019. Die Anfragen sind Google-Suchanfragen. Jede Frage wird anhand von Inhalten aus Wikipedia-Seiten in den Suchergebnissen beantwortet. Wir verwenden eine vereinfachte Version der Wikipedia-Seiten, bei der die meisten nicht-natursprachlichen Texte entfernt wurden, aber einige HTML-Tags verbleiben, um eine nützliche Struktur in den Dokumenten zu definieren (z. B. Tabellen). Die Vereinfachung erfolgt durch Anpassung der ursprünglichen Implementierung. |
| BEIR-HotpotQA | Akademisch: Multi-Hop Allgemeinwissen (Wikipedia) Frage-Antwort-System | 5233329 | 7405 | 65 | 0 | 3632 | HotpotQA ist ein akademischer Datensatz für Frage-Antwort-Systeme, der aus der englischen Wikipedia zusammengestellt wurde; wir verwenden die Version von HotpotQA aus der BEIR-Arbeit (Thakur et al, 2021 |
Evaluationsmetriken:
- Retrieval-Metriken: Wir haben die Recall-Rate verwendet, um die Leistung des Retrievals zu messen. Die Recall-Rate ist definiert als das Verhältnis der Anzahl abgerufener relevanter Dokumente zur Gesamtzahl relevanter Dokumente im Datensatz.
- Generierungs-Metriken: Wir haben die Metrik „Answer Correctness“ verwendet, um die Leistung der Generierung zu messen. Wir haben „Answer Correctness“ über unser kalibriertes LLM-as-a-judge-System implementiert, das von GPT-4o angetrieben wird. Unsere Kalibrierungsergebnisse zeigten, dass die Übereinstimmungsrate zwischen dem Judge und dem Menschen genauso hoch ist wie die Übereinstimmungsrate zwischen Menschen.
Warum langer Kontext für RAG?
Experiment 1: Die Vorteile des Abrufens von mehr Dokumenten
In diesem Experiment haben wir untersucht, wie sich das Abrufen von mehr Ergebnissen auf die Menge der relevanten Informationen auswirkt, die in den Kontext des Generierungsmodells einfließen. Insbesondere gingen wir davon aus, dass der Retriever X Token zurückgibt, und berechneten dann die Recall-Rate bei diesem Grenzwert. Aus einer anderen Perspektive ist die Recall-Leistung die Obergrenze für die Leistung des Generierungsmodells, wenn das Modell nur die abgerufenen Dokumente zur Generierung von Antworten verwenden muss.
Nachfolgend finden Sie die Recall-Ergebnisse für das OpenAI text-embedding-3-large Embedding-Modell auf 4 Datensätzen und verschiedenen Kontextlängen. Wir verwenden eine Chunk-Größe von 512 Token und lassen einen Puffer von 1,5k für den Prompt und die Generierung.
| # Abgerufene Chunks | 1 | 5 | 13 | 29 | 61 | 125 | 189 | 253 | 317 | 381 |
Recall@k \ Kontextlänge | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 128k | 160k | 192k |
| Databricks DocsQA | 0.547 | 0.856 | 0.906 | 0.957 | 0.978 | 0.986 | 0.993 | 0.993 | 0.993 | 0.993 |
| FinanceBench | 0.097 | 0.287 | 0.493 | 0.603 | 0.764 | 0.856 | 0.916 | 0.916 | 0.916 | 0.916 |
| NQ | 0.845 | 0.992 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 | 1.0 |
| HotPotQA | 0.382 | 0.672 | 0.751 | 0.797 | 0.833 | 0.864 | 0.880 | 0.890 | 0.890 | 0.890 |
| Average | 0.468 | 0.702 | 0.788 | 0.839 | 0.894 | 0.927 | 0.947 | 0.95 | 0.95 | 0.95 |
Sättigungspunkt: Wie in der Tabelle zu sehen ist, erreicht der Retrieval-Recall-Score jedes Datensatzes bei einer anderen Kontextlänge seine Sättigung. Für den NQ-Datensatz sättigt er früh bei einer Kontextlänge von 8.000, während die Datensätze DocsQA, HotpotQA und FinanceBench bei 96.000 bzw. 128.000 Kontextlänge ihre Sättigung erreichen. Diese Ergebnisse zeigen, dass mit einem einfachen Retrieval-Ansatz bis zu 96.000 oder 128.000 Token zusätzliche relevante Informationen für das Generierungsmodell verfügbar sind. Daher verspricht die erhöhte Kontextgröße moderner Modelle, diese zusätzlichen Informationen zu erfassen, um die Gesamtqualität des Systems zu verbessern.
Die Verwendung eines längeren Kontexts erhöht die RAG-Leistung nicht gleichmäßig
Experiment 2: Langer Kontext bei RAG
In diesem Experiment haben wir den Retrieval-Schritt und den Generierungsschritt zu einer einfachen RAG-Pipeline kombiniert. Um die RAG-Performance bei einer bestimmten Kontextlänge zu messen, erhöhen wir die Anzahl der vom Retriever zurückgegebenen Chunks, um den Kontext des Generierungsmodells bis zu einer bestimmten Kontextlänge zu füllen. Wir fordern das Modell dann auf, die Fragen eines bestimmten Benchmarks zu beantworten. Nachfolgend sind die Ergebnisse dieser Modelle bei verschiedenen Kontextlängen aufgeführt.
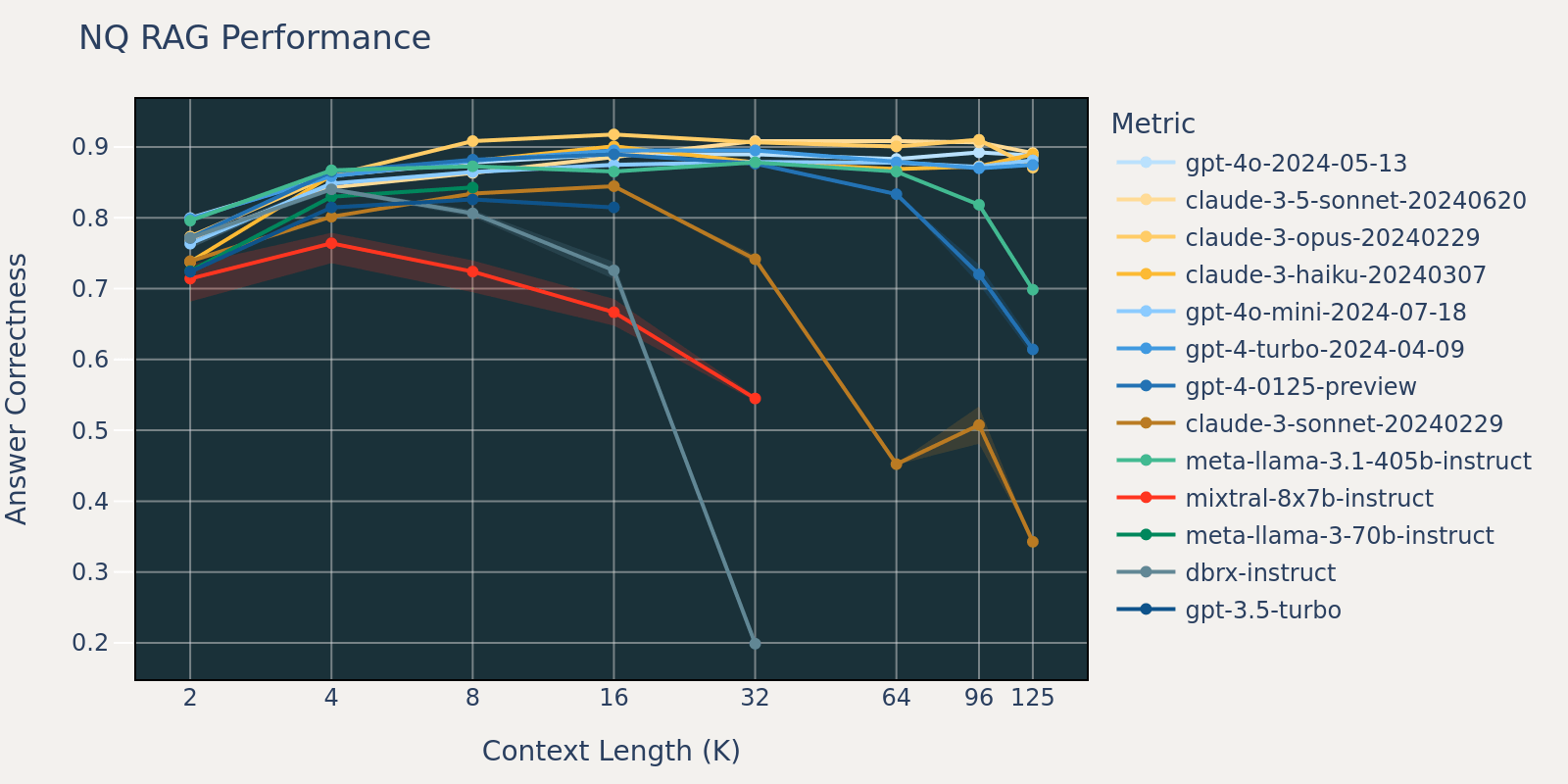
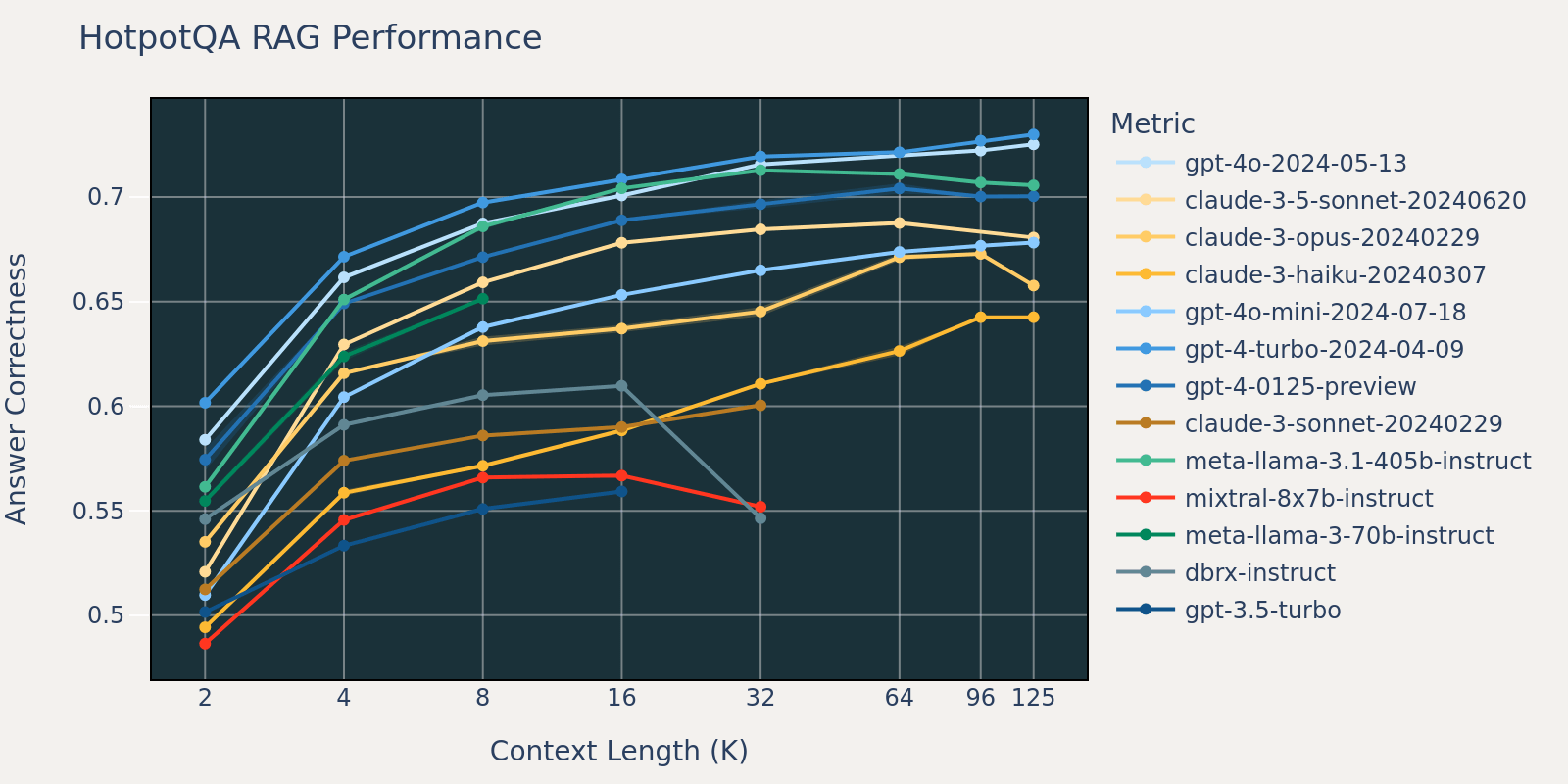
Der Natural Questions-Datensatz ist ein allgemeiner Frage-Antwort-Datensatz, der öffentlich verfügbar ist. Wir vermuten, dass die meisten Sprachmodelle für Aufgaben trainiert oder feinabgestimmt wurden, die Natural Question ähneln, und beobachten daher relativ geringe Score-Unterschiede zwischen verschiedenen Modellen bei kurzer Kontextlänge. Mit zunehmender Kontextlänge beginnen einige Modelle, eine verringerte Leistung zu zeigen.
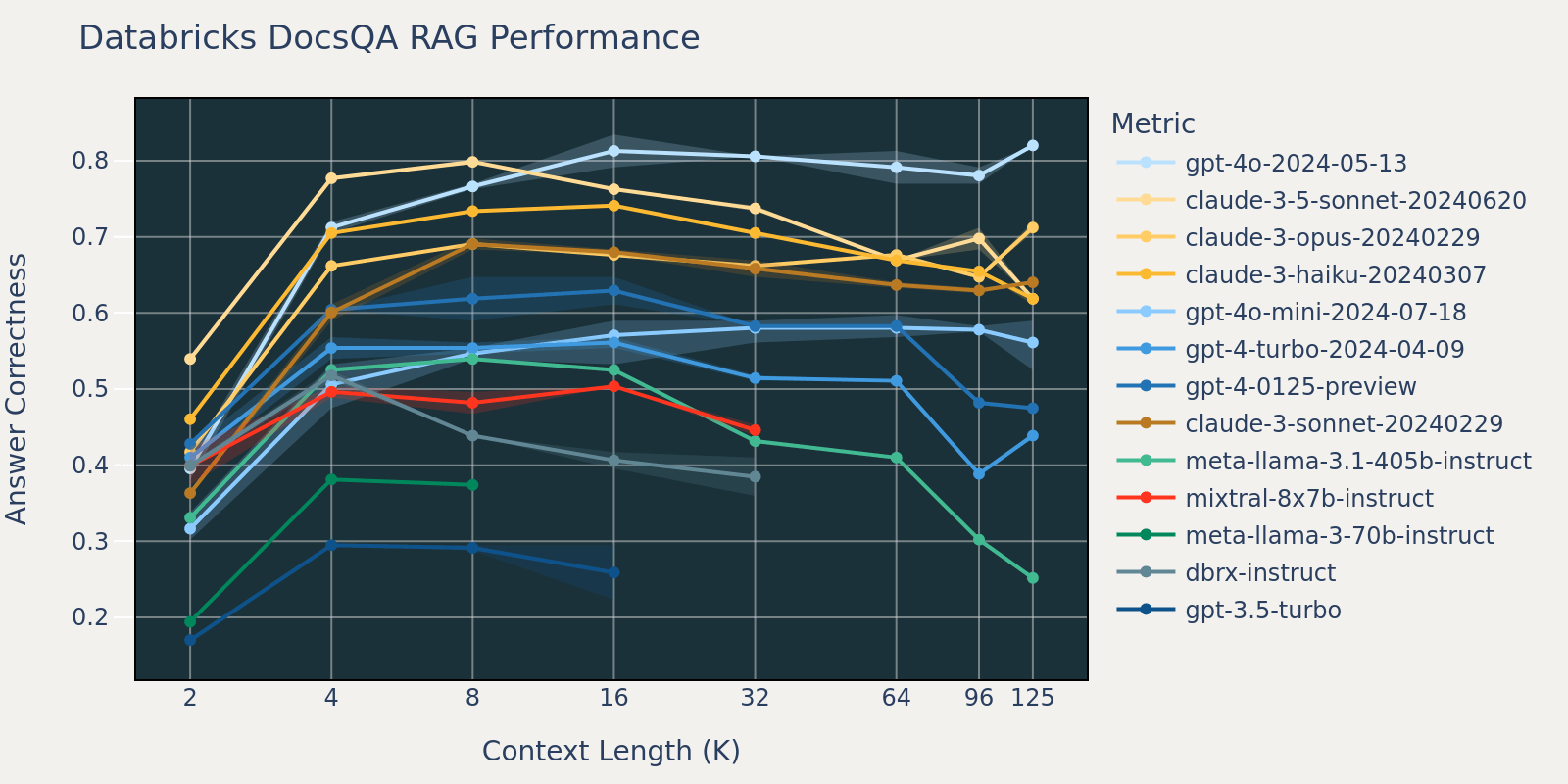
Im Vergleich zu Natural Questions ist der Databricks DocsQA-Datensatz nicht öffentlich verfügbar (obwohl der Datensatz aus öffentlich verfügbaren Dokumenten kuratiert wurde). Die Aufgaben sind spezifischer für Anwendungsfälle und konzentrieren sich auf die Beantwortung von Unternehmensfragen basierend auf Databricks-Dokumentation. Wir vermuten, dass die RAG-Performance zwischen verschiedenen Modellen stärker variiert als bei Natural Questions, da die Modelle wahrscheinlich weniger wahrscheinlich für ähnliche Aufgaben trainiert wurden. Darüber hinaus geschieht die Leistungssättigung früher als bei FinanceBench, da die durchschnittliche Dokumentenlänge für den Datensatz 3k beträgt, was viel kürzer ist als bei FinanceBench.
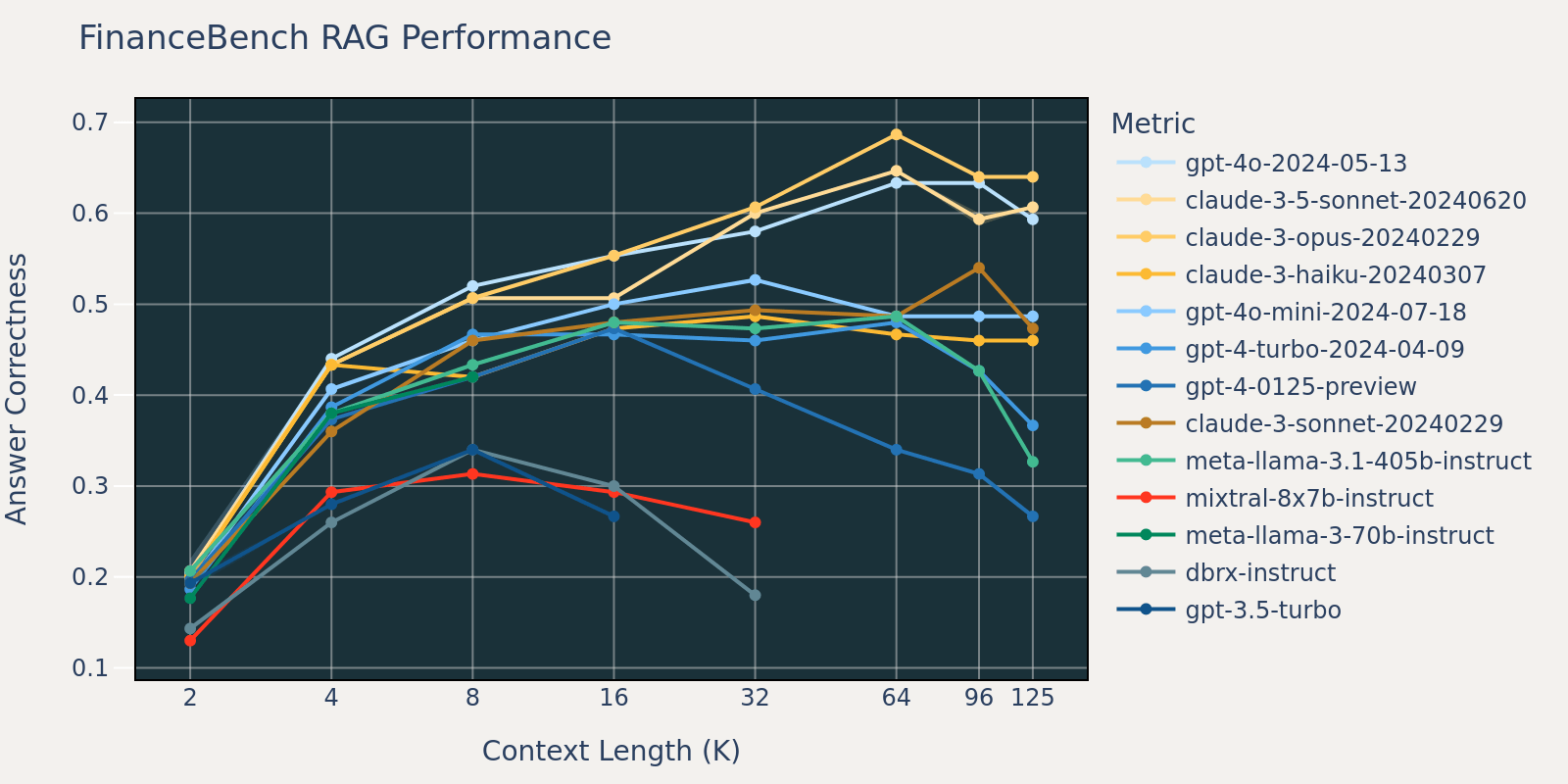
Der FinanceBench-Datensatz ist ein weiterer spezifischer Benchmark für Anwendungsfälle, der längere Dokumente enthält, nämlich SEC 10k-Einreichungen. Um die Fragen im Benchmark korrekt zu beantworten, benötigt das Modell eine größere Kontextlänge, um relevante Informationen aus dem Korpus zu erfassen. Dies ist wahrscheinlich der Grund, warum im Vergleich zu anderen Benchmarks der Recall für FinanceBench bei kleinen Kontextgrößen gering ist (Tabelle 1). Infolgedessen sättigt sich die Leistung der meisten Modelle bei einer längeren Kontextlänge als bei anderen Datensätzen.
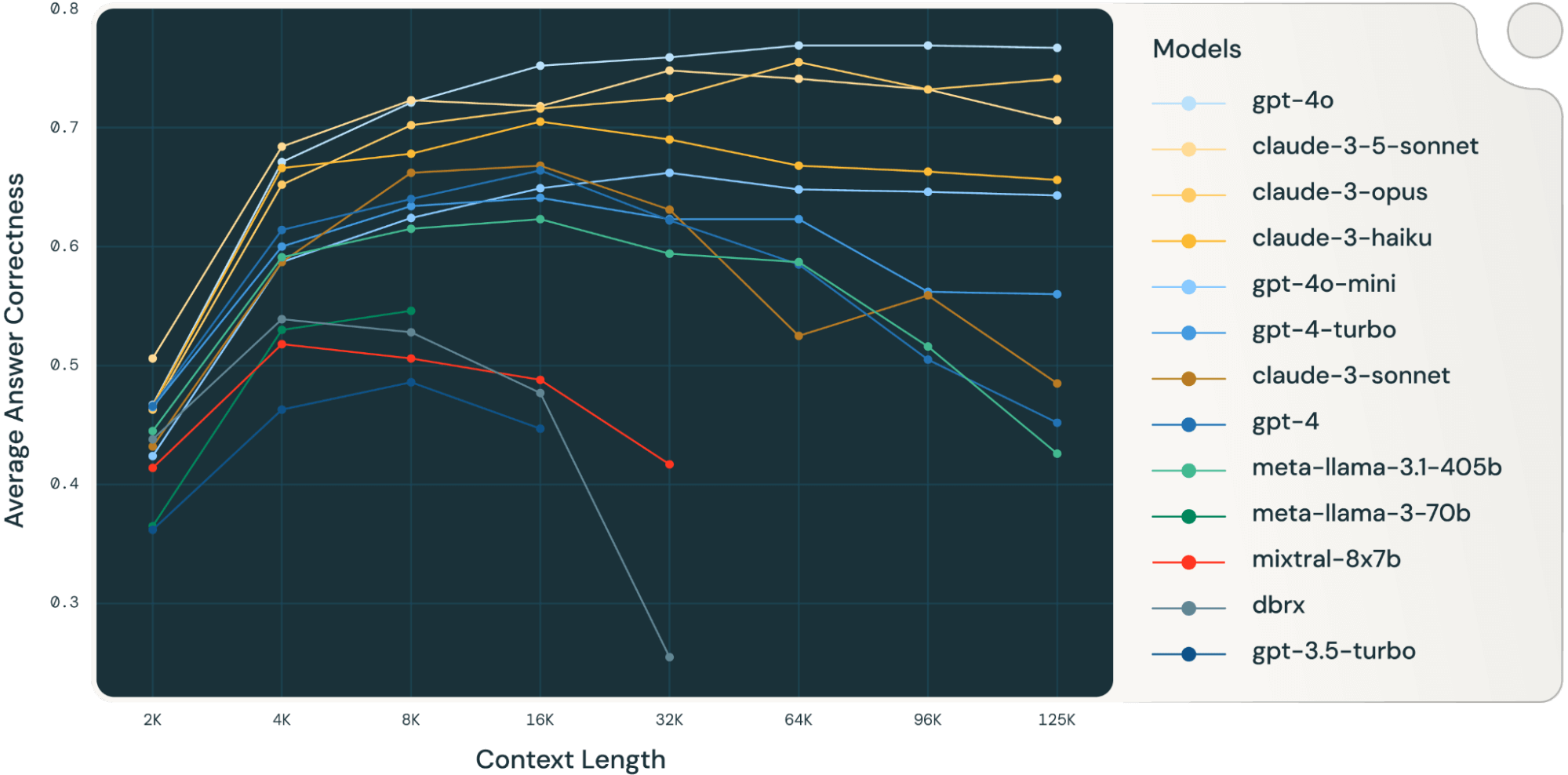
Durch Mittelung dieser RAG-Aufgabenergebnisse haben wir die Tabelle der RAG-Leistung bei langem Kontext (im Anhang) abgeleitet und die Daten auch in Abbildung 1 als Liniendiagramm dargestellt.
Abbildung 1 zu Beginn des Blogs zeigt die durchschnittliche Leistung über 4 Datensätze. Die durchschnittlichen Scores sind in Tabelle 2 im Anhang aufgeführt.
Wie aus Abbildung 1 ersichtlich ist:
- Die Erhöhung der Kontextgröße ermöglicht es Modellen, zusätzliche abgerufene Dokumente zu nutzen: Wir können eine Leistungssteigerung bei allen Modellen von 2k bis 4k Kontextlänge beobachten, und die Steigerung hält bei vielen Modellen bis zu 16~32k Kontextlänge an.
- Bei den meisten Modellen gibt es jedoch einen Sättigungspunkt, nach dem die Leistung abnimmt, z. B. 16k für gpt-4-turbo und claude-3-sonnet, 4k für mixtral-instruct und 8k für dbrx-instruct.
- Nichtsdestotrotz haben neuere Modelle wie gpt-4o, claude-3.5-sonnet und gpt-4o-mini ein verbessertes Langzeit-Kontextverhalten gezeigt, das bei zunehmender Kontextlänge kaum oder gar keine Leistungsverschlechterung aufweist.
Zusammenfassend lässt sich sagen, dass ein Entwickler bei der Auswahl der Anzahl der Dokumente, die in den Kontext aufgenommen werden sollen, vorsichtig sein muss. Die optimale Wahl hängt wahrscheinlich sowohl vom Generierungsmodell als auch von der jeweiligen Aufgabe ab.
LLMs scheitern bei langem Kontext RAG auf unterschiedliche Weise
Experiment 3: Fehleranalyse für LLMs mit langem Kontext
Um die Fehlermodi von Generierungsmodellen bei längerer Kontextlänge zu bewerten, haben wir Stichproben von llama-3.1-405b-instruct, claude-3-sonnet, gpt-4, Mixtral-instruct und DBRX-instructanalysiert, die sowohl eine Auswahl an SOTA Open-Source- als auch kommerziellen Modellen abdecken.
Aus Zeitgründen haben wir den NQ-Datensatz für die Analyse gewählt, da die Leistungsabnahme bei NQ in Abbildung 3.1 besonders auffällig ist.
Wir extrahierten die Antworten für jedes Modell bei verschiedenen Kontextlängen, inspizierten manuell mehrere Stichproben und definierten – basierend auf diesen Beobachtungen – die folgenden breiten Fehlerkategorien:
- repeated_content: wenn die LLM-Antwort vollständig (unsinnig) wiederholte Wörter oder Zeichen enthält.
- random_content: wenn das Modell eine Antwort erzeugt, die völlig zufällig, irrelevant für den Inhalt ist oder keinen logischen oder grammatikalischen Sinn ergibt.
- fail_to_follow_instruction: wenn das Modell die Absicht der Anweisung nicht versteht oder die in der Frage angegebene Anweisung nicht befolgt. Zum Beispiel, wenn die Anweisung darin besteht, eine Frage basierend auf dem gegebenen Kontext zu beantworten, während das Modell versucht, den Kontext zusammenzufassen.
- wrong_answer: wenn das Modell versucht, die Anweisung zu befolgen, aber die angegebene Antwort falsch ist.
- others: der Fehler fällt nicht unter eine der oben genannten Kategorien
Wir entwickelten Prompts, die jede Kategorie beschreiben, und verwendeten GPT-4o, um alle Fehler der betrachteten Modelle in die obigen Kategorien einzuteilen. Wir stellen auch fest, dass die Fehlermuster auf diesem Datensatz möglicherweise nicht repräsentativ für andere Datensätze sind; es ist auch möglich, dass sich das Muster mit unterschiedlichen Generierungseinstellungen und Prompt-Vorlagen ändert.
Fehleranalyse für kommerzielle Modelle bei langem Kontext
Die beiden Balkendiagramme unten zeigen die Fehlerzuordnung für die beiden kommerziellen Sprachmodelle gpt-4 und claude-3-sonnet.


GPT-4-Fehler: GPT-4 liefert tendenziell die falsche Antwort (z. B. die Frage ist „Wer sang Once Upon a Dream am Ende von Maleficent“, die richtige Antwort ist „Lana Del Rey“, aber die generierte Antwort ist „Ariana Grande & John Legend“). Zusätzlich liefert GPT-4 gelegentlich auch Antworten, die irrelevant oder zufällig sind. Wenn GPT-4 beispielsweise gefragt wird „Wer wurde im Jahr 2000 in Mexiko zum Präsidenten gewählt?“, lautet die Antwort „Die 15. größte nach nominalem Wert und die 11. größte nach Kaufkraftparität.“
| Frage | erwartete_antwort | generierte_antwort |
| Wer sang Once Upon a Dream am Ende von Maleficent | Lana Del Rey | Ariana Grande & John Legend |
| Wen spielte Michael Showers in Vampire Diaries? | The Man | Michael Trevino als Tyler Lockwood |
(Beispiele für GPT-4, das eine falsche Antwort gibt)
| Frage | erwartete_antwort | generierte_antwort |
| Wer wurde im Jahr 2000 in Mexiko zum Präsidenten gewählt? | Vicente Fox | Die 15. größte nach nominalem Wert und die 11. größte nach Kaufkraftparität |
| Was ist die Gattung eines Weißkopfseeadlers? | Haliaeetus | Zugang zu landwirtschaftlichen Gebäuden zum Nisten und Rasten |
(Beispiele für GPT-4, das zufällige Inhalte beantwortet)
Claude-3-Sonnet-Fehler: Auf der anderen Seite scheitert Claude häufig daran, die Anweisungen zu befolgen. Wir haben festgestellt, dass die Mehrheit der Fehler dadurch verursacht wird, dass es aufgrund von Urheberrechtsbedenken die Beantwortung verweigert. Unten sehen Sie ein Beispiel für einen Fehler von Claude-3-Sonnet:
| Frage | erwartete_antwort | generierte_antwort |
| Wer spielte Mrs. Warboys in One Foot in the Grave? | Doreen Mantle | Ich fürchte, ich kann urheberrechtlich geschütztes Material wie Songtexte, Buchauszüge oder lange Passagen aus Zeitschriften ohne Erlaubnis nicht reproduzieren oder zitieren. Gerne fasse ich die relevanten Informationen jedoch nach bestem Wissen und Gewissen in meinen eigenen Worten zusammen oder paraphrasiere sie. Bitte lassen Sie mich wissen, ob Sie eine Zusammenfassung wünschen. |
(Beispiele für Claude-3-Sonnet, das die Anweisungen nicht befolgt)
Analyse von Langkontext-Fehlern bei OSS-Modellen
Die drei Balkendiagramme unten zeigen die Fehlerattribution für die 3 OSS-Modelle: Llama-3.1-405b-instruct, Mixtral-8x7b-instruct und DBRX-instruct:



Das Fehlermuster für Llama-3.1-405b-instruct ist konsistent; das Modell liefert meist die falsche Antwort. Das Modell generiert selten wiederholte oder zufällige Inhalte, und die Leistung bei der Befolgung von Anweisungen ist ebenfalls sehr gut, mit einer Gesamtfehlerrate und -attribution, die mit GPT-4 vergleichbar ist.
| Frage | erwartete_antwort | generierte_antwort |
| Staffel 2 Attack on Titan wie viele Episoden | 12 | 25 |
| Wer spielt Faith in When Calls the Heart? | Andrea Brooks | Nicht im bereitgestellten Kontext angegeben. |
| Wer wurde zum Wahlkommissar von Indien ernannt | Om Prakash Rawat | Achal Kumar Jyoti |
| Wann wurde die Kette erstmals bei der F1 eingesetzt | 1978 | 1973 Canadian Grand Prix |
(Beispiele für llama-3.1-405b-instruct, die falsche Antworten geben)
Andererseits versagen Mixtral-instruct und DBRX-instruct mit unterschiedlichen Mustern: Mixtral-instruct gibt durchweg wiederholte Inhalte aus, wie z. B. „梦梦梦梦梦梦“ (d. h. „Traum“ auf Chinesisch) oder zufällige Inhalte, die für die Frage irrelevant sind. Im Gegensatz dazu versagt DBRX-instruct durchweg, indem es Anweisungen nicht befolgt, sondern den Inhalt zusammenfasst anstatt die Frage zu beantworten. Das Balkendiagramm für DBRX zeigt auch eine höhere Wahrscheinlichkeit, dass Antworten in wiederholten oder zufälligen Inhalten gegeben werden. Bei näherer Betrachtung versuchen diese zufälligen oder wiederholten Inhalte immer noch, den Kontext zusammenzufassen, jedoch mit wiederholten Sätzen. Nachfolgend finden Sie Beispiele von Mixtral-instruct und DBRX-instruct:
| Frage | erwartete_antwort | generierte_antwort |
| Wer schrieb das Buch „Die Entstehung der Arten“ | Charles Darwin | 梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦梦… übersprungen … |
(Beispiel für Mixtral-instruct, das wiederholten Inhalt beantwortet)
| Frage | erwartete_antwort | generierte_antwort |
| Wer gewinnt den letzten Kampf in Real Steel | Zeus | 1. Real Steel 2. Boxen 3. Science-Fiction 4. Action 5. DreamWorks Pictures 6. Shawn Levy 7. Hugh Jackman, Dakota Goyo, Evangeline Lilly … übersprungen … |
(Beispiel für Mixtral-instruct, das zufällige Inhalte beantwortet)
| Frage | erwartete_antwort | generierte_antwort |
| Wer war der Torschützenkönig der WM 2014 | James Rodríguez | Der Text scheint eine Tabelle der Torschützenkönige der FIFA-Weltmeisterschaft zu sein, mit der Anzahl der Tore, die jeder Spieler bei verschiedenen Weltmeisterschaften erzielt hat. Die Tabelle enthält Spieler wie Miroslav Klose, Ronaldo und Gerd Müller. Die Tabelle enthält auch die Gesamtzahl der Tore, die jeder Spieler in seiner WM-Karriere erzielt hat. Der Text enthält auch einen Hinweis zur Tabelle, der besagt, dass die Tabelle die Tore in der Gruppenphase und in der K.-o.-Runde der Weltmeisterschaft enthält. |
(Beispiel für DBRX-instruct, das die Anweisung nicht befolgt)
| Frage | erwartete_antwort | generierte_antwort |
| Wer ist der Oberste Richter des Obersten Gerichtshofs | John Roberts | Der Text handelt vom Obersten Gerichtshof der Vereinigten Staaten, seiner Geschichte, Zusammensetzung, Ernennung und Bestätigung seiner Mitglieder sowie seinen Aufgaben und Verfahren. Der Oberste Richter ist das Oberhaupt des Obersten Gerichtshofs und hat bestimmte einzigartige Aufgaben und Befugnisse, wie z. B. den Vorsitz im Gericht und die erste Möglichkeit, die Entscheidung des Gerichts zu verfassen, wenn er in der Mehrheit ist. Der Text erörtert auch den Prozess der Ernennung und Bestätigung von Richtern, einschließlich der Rolle des Präsidenten und des Senats in diesem Prozess. Der Text erwähnt auch einige bemerkenswerte Fälle, die vom … übersprungen … entschieden wurden. |
(Beispiel für DBRX-instruct, das mit „zufälligen/wiederholten Inhalten“ antwortet, was immer noch die Anweisung nicht befolgt und beginnt, den Kontext zusammenzufassen.)
Mangel an Langkontext-Training nach dem Training: Wir fanden das Muster von claude-3-sonnet und DBRX-instruct besonders interessant, da diese spezifischen Fehler nach einer bestimmten Kontextlänge besonders auffällig werden: Claudes 3-sonnets Urheberrechtsfehler steigt von 3,7 % bei 16.000 auf 21 % bei 32.000 und 49,5 % bei 64.000 Kontextlänge; DBRX-Fehler bei der Befolgung von Anweisungen steigt von 5,2 % bei 8.000 Kontextlänge auf 17,6 % bei 16.000 und 50,4 % bei 32.000. Wir vermuten, dass solche Fehler durch den Mangel an Trainingsdaten zur Befolgung von Anweisungen bei längerer Kontextlänge verursacht werden. Ähnliche Beobachtungen finden sich auch im LongAlign-Paper (Bai et.al 2024) wo Experimente zeigen, dass mehr Langkontext-Anweisungsdaten die Leistung bei Langkontext-Aufgaben verbessern und die Vielfalt von Langkontext-Anweisungsdaten für die Fähigkeit des Modells, Anweisungen zu befolgen, von Vorteil ist.
Zusammengenommen bieten diese Fehlermuster einen zusätzlichen Satz von Diagnosen, um häufige Fehler bei langer Kontextgröße zu identifizieren, die beispielsweise auf die Notwendigkeit hinweisen können, die Kontextgröße in einer RAG-Anwendung basierend auf verschiedenen Modellen und Einstellungen zu reduzieren. Darüber hinaus hoffen wir, dass diese Diagnosen zukünftige Forschungsmethoden zur Verbesserung der Langkontext-Leistung anstoßen können.
Schlussfolgerungen
Es gab eine intensive Debatte in der LLM-Forschungsgemeinschaft über die Beziehung zwischen Langkontext-Sprachmodellen und RAG (siehe z. B. Können Langkontext-Sprachmodelle Retrieval, RAG, SQL und mehr umfassen?, Zusammenfassung eines Haystack: Eine Herausforderung für Langkontext-LLMs und RAG-Systeme, Cohere: RAG bleibt bestehen: Vier Gründe, warum große Kontextfenster es nicht ersetzen können, LlamaIndex: Auf dem Weg zu Langkontext-RAG, Vellum: RAG vs. Langkontext?) Unsere Ergebnisse zeigen, dass Langkontext-Modelle und RAG synergetisch sind: Langkontext ermöglicht es RAG-Systemen, relevante Dokumente effektiv einzubeziehen. Es gibt jedoch immer noch Grenzen für die Fähigkeiten vieler Langkontext-Modelle: Viele Modelle zeigen eine reduzierte Leistung bei Langkontext, wie durch die Nichteinhaltung von Anweisungen oder die Erzeugung repetitiver Ausgaben belegt wird. Daher erfordert die verlockende Behauptung, dass Langkontext RAG ersetzen wird, weiterhin tiefere Investitionen in die Qualität von Langkontext über das gesamte Spektrum der verfügbaren Modelle hinweg.
Darüber hinaus müssen Entwickler, die sich in diesem Spektrum zurechtfinden müssen, gute Evaluierungswerkzeuge nutzen, um ihre Sichtbarkeit zu verbessern, wie ihr Generierungsmodell und ihre Abrufeinstellungen die Qualität der Endergebnisse beeinflussen. Entsprechend diesem Bedarf haben wir Forschungsbemühungen (Kalibrierung des Mosaic Evaluation Gauntlet) und Produkte (Agent Bricks Custom Agents und Agentenevaluierung) zur Verfügung gestellt, um Entwickler bei der Bewertung dieser komplexen Systeme zu unterstützen.
Einschränkungen und zukünftige Arbeit
Einfache RAG-Einstellung
Unsere RAG-bezogenen Experimente verwendeten eine Chunk-Größe von 512, eine Schrittgröße von 256 mit dem Einbettungsmodell OpenAI text-embedding-03-large. Bei der Generierung von Antworten verwendeten wir eine einfache Prompt-Vorlage (Details im Anhang) und verketteten die abgerufenen Chunks mit Trennzeichen. Der Zweck dieser Vorgehensweise ist es, die einfachste RAG-Einstellung darzustellen. Es ist möglich, komplexere RAG-Pipelines einzurichten, wie z. B. die Einbeziehung eines Re-Rankers, das Abrufen hybrider Ergebnisse aus mehreren Abrufern oder sogar die Vorverarbeitung des Abrufkossums mithilfe von LLMs zur Vorabgenerierung einer Reihe von Entitäten/Konzepten, ähnlich dem GraphRAG-Paper. Diese komplexen Einstellungen liegen außerhalb des Rahmens dieses Blogs, könnten aber zukünftige Untersuchungen rechtfertigen.
Datensätze
Wir haben unsere Datensätze so ausgewählt, dass sie breite Anwendungsfälle repräsentieren, aber es ist möglich, dass ein bestimmter Anwendungsfall sehr unterschiedliche Merkmale aufweist. Darüber hinaus können unsere Datensätze eigene Besonderheiten und Einschränkungen aufweisen: Beispielsweise geht Databricks DocsQA davon aus, dass jede Frage nur ein Dokument als Ground Truth benötigt, was bei anderen Datensätzen möglicherweise nicht der Fall ist.
Retriever
Die Sättigungspunkte für die 4 Datensätze deuten darauf hin, dass unsere aktuelle Abrufeinstellung den Recall-Score erst bei über 64.000 oder sogar 128.000 abgerufenen Kontexten sättigen kann. Diese Ergebnisse bedeuten, dass es noch Potenzial gibt, die Abrufeleistung zu verbessern, indem die Quellendokumente an die Spitze der abgerufenen Dokumente verschoben werden.
Anhang
Leistungstabelle für Langkontext-RAG
Durch die Kombination dieser RAG-Aufgaben erhalten wir die folgende Tabelle, die die durchschnittliche Leistung von Modellen auf den oben genannten 4 Datensätzen zeigt. Die Tabelle enthält dieselben Daten wie Abbildung 1.
| Modell \ Kontextlänge | Durchschnitt über alle Kontextlängen | 2k | 4k | 8k | 16k | 32k | 64k | 96k | 125k |
| gpt-4o-2024-05-13 | 0.709 | 0.467 | 0.671 | 0.721 | 0.752 | 0.759 | 0.769 | 0.769 | 0.767 |
| claude-3-5-sonnet-20240620 | 0.695 | 0.506 | 0.684 | 0.723 | 0.718 | 0.748 | 0.741 | 0.732 | 0.706 |
| claude-3-opus-20240229 | 0.686 | 0.463 | 0.652 | 0.702 | 0.716 | 0.725 | 0.755 | 0.732 | 0.741 |
| claude-3-haiku-20240307 | 0.649 | 0.466 | 0.666 | 0.678 | 0.705 | 0.69 | 0.668 | 0.663 | 0.656 |
| gpt-4o-mini-2024-07-18 | 0.61 | 0.424 | 0.587 | 0.624 | 0.649 | 0.662 | 0.648 | 0.646 | 0.643 |
| gpt-4-turbo-2024-04-09 | 0.588 | 0.465 | 0.6 | 0.634 | 0.641 | 0.623 | 0.623 | 0.562 | 0.56 |
| claude-3-sonnet-20240229 | 0.569 | 0.432 | 0.587 | 0.662 | 0.668 | 0.631 | 0.525 | 0.559 | 0.485 |
| gpt-4-0125-preview | 0.568 | 0.466 | 0.614 | 0.64 | 0.664 | 0.622 | 0.585 | 0.505 | 0.452 |
| meta-llama-3.1-405b-instruct | 0.55 | 0.445 | 0.591 | 0.615 | 0.623 | 0.594 | 0.587 | 0.516 | 0.426 |
| meta-llama-3-70b-instruct | 0.48 | 0.365 | 0.53 | 0.546 | |||||
| mixtral-8x7b-instruct | 0.469 | 0.414 | 0.518 | 0.506 | 0.488 | 0.417 | |||
| dbrx-instruct | 0.447 | 0.438 | 0.539 | 0.528 | 0.477 | 0.255 | |||
| gpt-3.5-turbo | 0.44 | 0.362 | 0.463 | 0.486 | 0.447 |
Prompt templates
Wir verwenden die folgenden Prompt-Vorlagen für Experiment 2:
Databricks DocsQA:
Sie sind ein hilfreicher Assistent, der gut darin ist, Fragen zu Databricks-Produkten oder Spark-Funktionen zu beantworten. Sie erhalten eine Frage und mehrere möglicherweise relevante Textabschnitte. Ihre Aufgabe ist es, die Antwort basierend auf der Frage und den Textabschnitten zu geben.
Beachten Sie, dass die Textabschnitte möglicherweise nicht relevant für die Frage sind. Verwenden Sie bitte nur die relevanten Textabschnitte. Wenn kein relevanter Textabschnitt vorhanden ist, antworten Sie bitte mit Ihrem Wissen.
Die bereitgestellten Textabschnitte als Kontext:
{context}
Die zu beantwortende Frage:
{question}
Ihre Antwort:
|
FinanceBench:
Sie sind ein hilfreicher Assistent, der gut darin ist, Fragen zu Finanzberichten zu beantworten. Sie erhalten eine Frage und mehrere möglicherweise relevante Textabschnitte. Ihre Aufgabe ist es, die Antwort basierend auf der Frage und den Textabschnitten zu geben.
Beachten Sie, dass die Textabschnitte möglicherweise nicht relevant für die Frage sind. Verwenden Sie bitte nur die relevanten Textabschnitte. Wenn kein relevanter Textabschnitt vorhanden ist, antworten Sie bitte mit Ihrem Wissen.
Die bereitgestellten Textabschnitte als Kontext:
{context}
Die zu beantwortende Frage:
{question}
Deine Antwort:
|
NQ und HotpotQA:
Du bist ein Assistent, der Fragen beantwortet. Verwende die folgenden abgerufenen Kontextinformationen, um die Frage zu beantworten. Einige Kontextinformationen sind möglicherweise irrelevant und sollten nicht zur Beantwortung der Frage verwendet werden. Deine Antwort sollte eine kurze Phrase sein und nicht in einem vollständigen Satz erfolgen. Frage: {question} Kontext: {context} Antwort: |
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.