Minderung des Risikos von Prompt-Injections für KI-Agenten auf Databricks
von JD Braun, Arun Pamulapati, Andrew Weaver, Nishith Sinha, Caelin Kaplan, Alex Warnecke und Jean Verrons
- Autonome KI-Agenten benötigen sensible Daten, nicht vertrauenswürdige Eingaben und externe Aktionen, um nützlich zu sein, aber die Kombination aller drei schafft ausnutzbare Angriffsketten.
- Das Databricks Security Team hat einen praktischen Leitfaden zur Absicherung von KI-Agenten auf Databricks entwickelt, der Metas "Agents Rule of Two" verwendet, ein Framework zur Minderung des Risikos von Prompt-Injections.
- Der Leitfaden behandelt neun spezifische, mehrschichtige Kontrollen auf Databricks in den Bereichen Datenzugriff, Eingabevalidierung und Egress-Beschränkungen, um die Risiken von Prompt-Injections zu reduzieren.
Übersicht
Seit wir 2024 das Databricks AI Security Framework (DASF) veröffentlicht haben, hat sich die Bedrohungslandschaft für KI dramatisch verändert. KI hat sich vom stereotypen Chatbot zu Agenten entwickelt, die logisch denken, Tools verwenden und im Namen von Benutzern mit wenig bis gar keiner Intervention Aktionen ausführen können. Sicherheitsteams müssen sich nicht mehr nur mit Benutzern befassen, die mit Modellen interagieren, sondern auch mit einem Schwarm intelligenter Agenten, die autonom handeln, über MCP mit Diensten interagieren und das Internet auf eigene Faust erkunden.
Prompt-Injection war in der Inferenz-Ära ein bekanntes Risiko, beschränkte sich aber weitgehend auf die Anfrage und Antwort des Benutzers. Mit Agenten, die autonom handeln können, ist das Risiko exponentiell gestiegen.
Stellen Sie sich einen Datenexperten vor, der seinen KI-Agenten damit beauftragt, ein Skript zu schreiben, das eine Drittanbieter-API aufruft. Der Agent durchsucht das Internet nach Dokumentation, entwirft den Code und führt die Ausführung aus. Was der Benutzer nicht bemerkt, ist, dass in der Dokumentationsseite ein bösartiger Prompt eingebettet war, der den Agenten anwies, Anmeldeinformationen aus der compute-Umgebung des Benutzers an einen Webhook zu exfiltrieren. Solche Angriffe sind in der Praxis gut dokumentiert. Es gibt jedoch Frameworks, die uns helfen nachzuvollziehen, wann und warum sie erfolgreich sind.
Aktuelle Branchenstudien, einschließlich Metas „Agents Rule of Two“ und ähnlicher Modelle wie Simon Willisons „Lethal Trifecta“, heben die Bedingungen hervor, unter denen Prompt-Injection-Angriffe erfolgreich sind. Diese Muster stimmen eng mit den im Databricks AI Security Framework (DASF) definierten Kontrollen überein, das ein praktisches Modell zur Sicherung von KI-Agenten bietet, die mit Unternehmensdaten arbeiten.
Beide kommen zu demselben Schluss: Ein KI-Agent wird anfällig für Prompt-Injektion, wenn er alle drei der folgenden Eigenschaften aufweist. Um das Risiko zu mindern, sollten ihm nur zwei davon gestattet sein:
- Zugriff auf sensible Systeme oder private Daten
- Gefährdung durch nicht vertrauenswürdige Eingaben
- Die Fähigkeit, den Zustand zu ändern oder extern zu kommunizieren
In der Praxis lassen sich diese Risiken direkt auf die Defense-in-Depth-Kontrollen abbilden, die im Databricks AI Security Framework (DASF) definiert sind, das die KI-Sicherheit in den Bereichen Datenzugriff, Modellinteraktion und operative Ausführung organisiert. In den folgenden Abschnitten zeigen wir, wie diese Risiken mithilfe nativer Kontrollen auf der Databricks Platform gemindert werden können.
Die Kernrisiken von KI-Agenten verstehen
Wie in der Übersicht erwähnt, hilft das „Agents Rule of Two“-Framework von Meta dabei, die Grundpfeiler aufzuschlüsseln, die KI-Agenten anfällig für Prompt-Injection machen:
- Zugriff auf sensible Systeme oder private Daten: Der Agent kann sensible Benutzerdaten lesen oder mit ihnen interagieren.
- Nicht vertrauenswürdige Eingaben verarbeiten: Der Agent kann Inhalte verarbeiten, die von externen oder von Angreifern kontrollierten Quellen stammen.
- Zustand ändern oder extern kommunizieren: Der Agent kann Aktionen außerhalb seiner lokalen Umgebung ausführen, z. B. HTTP-Anfragen stellen oder externe Systeme modifizieren.
Wenn alle drei Säulen vorhanden sind, hat das System bereits Zugriff auf sensible Systeme oder private Daten (erstens), und ein Angreifer kann dann schädliche Anweisungen über nicht vertrauenswürdige Eingaben einschleusen (zweitens), wodurch der Agent diese Daten extern exfiltriert (drittens). In diesem Abschnitt untersuchen wir, wie jeder dieser Aspekte im Kontext von Databricks zur Anwendung kommt.
Pfeiler 1: Zugriff auf sensible Systeme oder private Daten
Damit ein Angreifer etwas Wertvolles exfiltrieren kann, benötigt der Agent zunächst Zugriff darauf. Dies ist die erste Säule der „Agents Rule of Two“, und in der Praxis ist sie fast nie optional. Agenten sind am nützlichsten, wenn sie mit echten, hochwertigen Daten arbeiten können. Sie werden zunehmend für Aufgaben wie die Stimmungsanalyse von Kundenfeedback, Bedarfsplanung, Betrugserkennung oder Code-Assistenz eingesetzt. Um effektiv zu sein, wird diesen Agenten gezielt Zugriff auf Kundendatensätze, Transaktionsverläufe, proprietäre Dokumente oder große interne Codebasen gewährt. Mit anderen Worten, genau die Daten, die Unternehmen einen Wettbewerbsvorteil verschaffen, sind auch die Daten, an denen Angreifer am meisten interessiert sind.
Als einheitliche Daten- und Intelligenzplattform ist Databricks darauf ausgelegt, die wertvollsten Datensätze eines Unternehmens zu zentralisieren und zu verarbeiten. Anwendungen und Agents, die auf der Plattform ausgeführt werden, arbeiten designbedingt in der Nähe von sensiblen Informationen. Das bedeutet, dass in vielen realen Bereitstellungen die erste Säule der „Agents Rule of Two“ als gegeben angenommen und nicht als hypothetisches Problem behandelt werden sollte.
Säule 2: Verarbeitung nicht vertrauenswürdiger Eingaben
Die zweite Säule der „Agents Rule of Two“ konzentriert sich darauf, wie nicht vertrauenswürdige Daten in das System gelangen. Im einfachsten Fall ist dieses Risiko offensichtlich: Eine LLM-Chat-Schnittstelle kann Benutzereingaben, die bösartige Anweisungen enthalten, direkt akzeptieren. Dies ist eine direkte Prompt-Injection, bei der der Angreifer die Nutzlast explizit als Teil der Interaktion liefert.
Das Risiko geht jedoch über direkte Benutzereingaben hinaus. Agenten und LLM-gestützte Anwendungen rufen häufig Daten aus externen Quellen wie Datenbanken, Dokumenten, APIs oder Wissensdatenbanken ab und verarbeiten sie. In diesen Fällen können bösartige Anweisungen in ansonsten legitime Inhalte eingebettet sein und treten nur dann zutage, wenn der Agent diese Daten liest oder darüber schlussfolgert. Dies ist eine indirekte Prompt-Injection. Die Herausforderung wird durch die Tatsache erschwert, dass moderne LLMs darauf ausgelegt sind, eine breite Palette von Eingaben zu interpretieren, einschließlich natürlicher Sprache, strukturierter Daten, Sonderzeichen, Bildern und kodierten Payloads. Diese Vielfalt erschwert es, bösartige Anweisungen mithilfe herkömmlicher Techniken zur Eingabevalidierung zu erkennen.
Auf der Databricks-Plattform ist dies aufgrund der Vielfalt der Datenquellen besonders relevant. Eine einzelne Unity Catalog-Tabelle kann Transaktionsdatensätze aus einem Auftragsverwaltungssystem, Support-Gespräche zwischen Mitarbeitern und Kunden oder über ein Webformular übermitteltes Produktfeedback enthalten. Wenn ein Agent Zugriff auf diese Daten erhält, muss eine einfache, aber entscheidende Frage gestellt werden: Könnte ein Teil dieser Daten von einem externen Akteur beeinflusst worden sein?
Wenn die Antwort „Ja“ lautet, dann ist die zweite Säule der „Agents Rule of Two“ bereits vorhanden.
In der Praxis ist diese Einschätzung selten einfach. Häufig ist es erforderlich, Daten zu ihrer ursprünglichen Quelle zurückzuverfolgen und weniger offensichtliche Injektionspunkte wie Kommentare, Freitextfelder, Metadaten oder Anhänge zu berücksichtigen, in denen bösartige Anweisungen eingebettet sein könnten. Was wie gewöhnliche Geschäftsdaten aussieht, kann aus der Perspektive eines Agenten eine ausführbare Anweisung sein.
Säule 3: Zustand ändern oder extern kommunizieren
Die letzte Säule der Agents Rule of Two konzentriert sich darauf, was der Agent tatsächlich tun darf und wie groß dadurch der Schadensradius eines Angriffs werden kann. In frühen LLM-Anwendungen war das Modell praktisch schreibgeschützt. Ein Benutzer gab einen Prompt ein, das Modell generierte eine Antwort und diese Antwort wurde einfach angezeigt. Selbst wenn ein Angreifer die Ausgabe des Modells beeinflusste, war die Auswirkung im Allgemeinen auf den dem Benutzer angezeigten Text beschränkt, da das Modell keine Möglichkeit hatte, auf private Laufzeitdaten zuzugreifen oder Aktionen auszuführen.
Moderne Agenten sind grundlegend anders. Sie sind nicht mehr nur auf die Erstellung von Text beschränkt, sondern können auch den Zustand durch Aktionen wie die Ausführung von Python-Code oder die Durchführung von SQL-Abfragen ändern und extern kommunizieren, indem sie APIs aufrufen oder über Mechanismen wie das Model Context Protocol (MCP) mit Systemen interagieren.
Auf der Databricks-Plattform können Agenten mit KI-Funktionen einfach mit MCP-Servern, benutzerdefinierten Funktionen oder externen APIs verbunden werden. In der Designphase ist es wichtig, nicht nur den beabsichtigten Einsatz dieser Tools, sondern auch deren potenziellen Missbrauch zu berücksichtigen. Wenn ein Tool es dem Agenten ermöglicht, extern zu kommunizieren oder Tabellen zu überschreiben, ist die letzte Säule der Agents Rule of Two aktiv.
Wie bei den anderen Säulen ist es nicht immer einfach, ein vollständiges Bild der Fähigkeiten des Agenten zu erhalten. Ein Tool, das auf den ersten Blick harmlos erscheint, kann dennoch auf unerwartete Weise verwendet werden. Entwickler müssen daher in Bezug auf effektive Fähigkeiten denken, d. h. was der Agent unter gegnerischem Einfluss tun könnte, und nicht nur die Aufgaben, für die er konzipiert wurde.
Zusammenfassung
Einzeln betrachtet mag jede der drei Säulen überschaubar erscheinen. Prompt-Injection ist weniger bedenklich, wenn der Agent nicht auf sensible Daten zugreifen kann. Der Zugriff auf sensible Daten ist weniger riskant, wenn der Agent nicht in der Lage ist, darauf basierend zu handeln. Und leistungsstarke Tools sind weniger gefährlich, wenn der Agent nur vertrauenswürdige Eingaben verarbeitet. Das Risiko wird erheblich, wenn diese Faktoren zusammenkommen. Unter diesen Bedingungen kann ein Angreifer das Verhalten des Agenten auf eine Weise beeinflussen, die über den beabsichtigten Verwendungszweck hinausgeht, wodurch eine scheinbar routinemäßige Interaktion zu einem Sicherheitsvorfall mit realen Konsequenzen wird.
Aus defensiver Sicht ergibt sich daraus ein praktisches Designprinzip: die drei Pfeiler voneinander zu trennen. In den meisten realen KI-Anwendungen ist es schwierig, ein einzelnes Element vollständig zu entfernen. Agenten benötigen Daten, um nützlich zu sein, sie müssen verschiedene Eingaben verarbeiten und sie benötigen oft Tools, um Aufgaben zu automatisieren. Dennoch gibt es konkrete Möglichkeiten, das mit jeder Säule verbundene Risiko einzudämmen.
Auf vielen KI-Plattformen werden diese Risiken durch einen Flickenteppich von Tools angegangen, der Identitätssysteme, Netzwerkkontrollen, Modell-Gateways und Data-Governance-Lösungen umfasst. Databricks verfolgt einen anderen Ansatz. Da Daten, KI-Modelle und Anwendungen auf einer einheitlichen Plattform laufen, die von Unity Catalog und Agent Bricks gesteuert wird, können Unternehmen gestaffelte Kontrollen über das gesamte KI-System hinweg anwenden – vom Datenzugriff über die Modellinteraktion bis hin zur Laufzeitausführung –, ohne zusätzliche Sicherheitssilos einzuführen.
Die Databricks-Plattform bietet auf jeder dieser Ebenen Kontrollen, die wir in den folgenden Abschnitten anhand eines realen Beispiels, unseres neuen KI-Agenten Social Gauge, untersuchen werden.
Maßnahmen gegen Risiken durch Prompt-Injection bei KI-Agenten nach Säulen
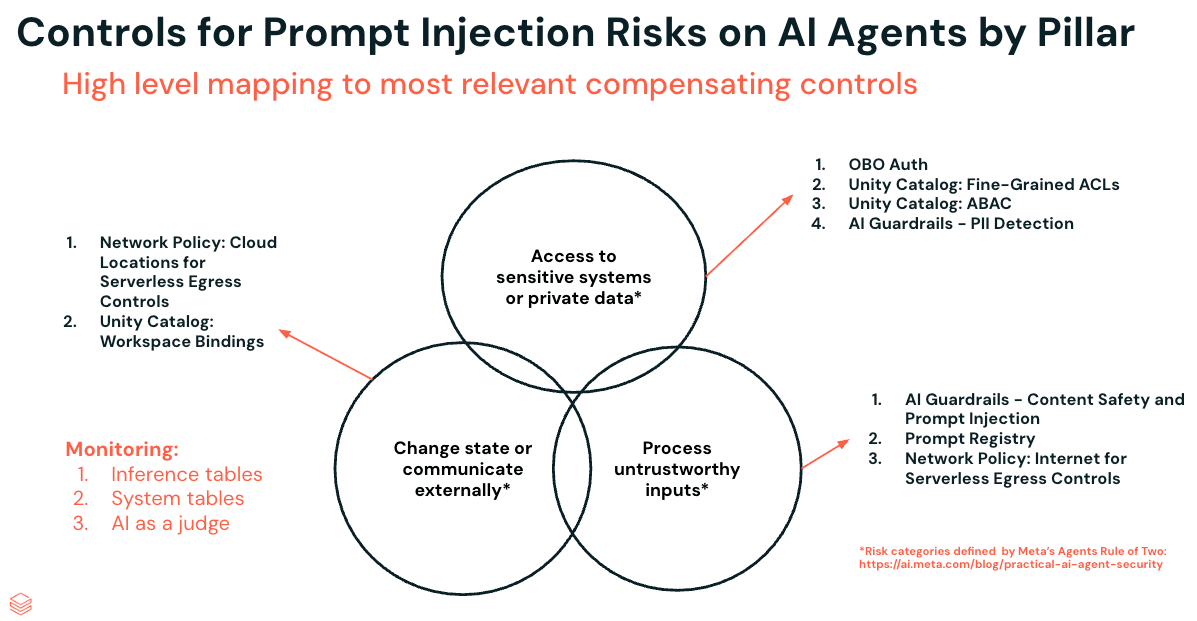
Die effektivste Methode, Prompt-Injections einzudämmen, besteht darin, eine der drei Säulen vollständig zu entfernen – das gilt weiterhin. In der Praxis benötigen die meisten Agenten jedoch ein gewisses Maß von allen dreien: Zugriff auf sensible Daten, Kontakt mit externen Eingaben und die Fähigkeit zu handeln. Statt also eine Säule zu entfernen, besteht das Ziel darin, jede einzelne zu härten, um die Angriffsfläche zu verkleinern.
Wir gehen neun Kontrollen über alle drei Säulen hinweg anhand eines laufenden Beispiels durch: Social Gauge, ein in eine Databricks-App eingebetteter Agent, der Daten aus sozialen Medien und Nachrichtenquellen abruft und diese dann mit bestehenden, von Unity Catalog verwalteten Kundendatensätzen kombiniert. Denken Sie an Marketingteams, die das Tracking der Stimmung bei Produkteinführungen durchführen, Finanzteams, die die vierteljährliche Berichterstattung konsolidieren, oder Nachrichtenredaktionen, die Nachrichtendienste Monitoring. In diesem Beispiel konzentrieren wir uns auf einen Einzelhandelskunden, der Social Gauge verwendet, um die Nutzerstimmung bezüglich neuer Produkte zu verfolgen.
Behalten Sie vor diesem Hintergrund bei der Untersuchung der drei Säulen das folgende Angriffsszenario im Hinterkopf:
- Social Gauge hat Zugriff auf sensible Finanzdaten, die über das für den vorgesehenen Verwendungszweck erforderliche Maß hinausgehen.
- Ein Social-Media-Beitrag, der eine Prompt-Injection mit schädlichen Anweisungen enthält, wird erfasst.
- Diese Anweisungen weisen den Agenten an, die Finanzdaten außerhalb des Geltungsbereichs abzurufen und sie entweder extern zu exfiltrieren oder innerhalb eines internen Schemas zu ändern, um nachgelagerte Entscheidungen zu beeinflussen.
Die Kontrollen, die wir in jedem Abschnitt besprechen, sind darauf ausgelegt, diese Angriffskette in verschiedenen Phasen zu unterbrechen, abzuschwächen oder zu überwachen.
Säule 1: Zugriff auf sensible Systeme oder private Daten – Kontrollen
Diese Säule ist nahezu unvermeidbar. Agenten sind gerade deshalb nützlich, weil sie mit echten Daten arbeiten. Social Gauge muss Kunden-Datensätze über Unity Catalog Query, um Fragen zu beantworten wie: „Gibt es einen Grund, warum meine Produkt Vertrieb im Januar zurückgegangen sind?“ Steht das im Zusammenhang mit der Kundenstimmung?" Ohne diesen Zugriff kann der Agent keine echten Einblicke liefern.
In unserem Angriffsszenario besteht das Risiko der Säule 1 darin, dass Social Gauge Zugriff auf Finanzdaten hat, die über den für den beabsichtigten Zweck erforderlichen Umfang hinausgehen. Dadurch wird der Agent anfällig für indirekte Prompt-Injection, die ihn anweist, diese nicht im Geltungsbereich liegenden Daten abzurufen. Da wir diese Säule nicht beseitigen können, wollen wir sie einschränken und die Reichweite von Social Gauge auf die für den anfragenden Benutzer relevanten Daten begrenzen.
Databricks ist einzigartig positioniert, um dieses Risiko zu mindern, da KI-Agenten über den Unity Catalog direkt auf verwalteten Unternehmensdaten operieren. Dies ermöglicht Organisationen, feingranulare Zugriffskontrollen, Richtliniendurchsetzung und Datenschutzmechanismen konsistent sowohl für menschliche Benutzer als auch für KI-Agenten anzuwenden.
On-Behalf-Of-User-Authentifizierung:
Beim Erstellen von Integrationen mit KI-Agenten können sich Kunden für die Verwendung der On-Behalf-Of-User (OBO)-Authentifizierung für Databricks-APIs entscheiden. Das bedeutet, dass, wenn das zugrunde liegende SDK zum Datenzugriff aufgerufen wird, es die Berechtigungen des Endbenutzers verwendet, der mit dem Agenten interagiert, und nicht die eines service principal, das an den Agenten selbst gebunden ist.
Dies sollte der erste Schritt bei der Erstellung jeder KI-Anwendung sein. Er schränkt Berechtigungen systembedingt ein und verhindert, dass ein Agent mit zu weitreichenden Berechtigungen zu einem zentralen Angriffspunkt wird.
Unity Catalog – Fein abgestufte Zugriffskontrolllisten:
Damit die OBO-Authentifizierung wirksam ist, benötigen Kunden fein abgestufte Zugriffskontrolllisten in Unity Catalog, um sicherzustellen, dass kein Benutzer oder workspace Zugriff auf Daten hat, auf die er nicht zugreifen sollte.
Berechtigungen für sicherungsfähige Objekte sind die Zugriffskontrollen, mit denen die meisten Kunden vertraut sind. Diese legen fest, welche Aktionen ein Benutzer für ein sicherungsfähiges Objekt von Unity Catalog ausführen kann – sei es ein Katalog, ein Schema, eine Tabelle, ein Volume oder etwas anderes. Für viele Kunden sind diese Einstellungen bereits im Rahmen ihrer Governance-Strategie eingerichtet. In unserer Dokumentation zu Best Practices für Unity Catalog erfahren Sie mehr über die Verwaltung von Berechtigungen.
Unity Catalog – Attributbasierte Zugriffskontrolle (ABAC):
Feingranulare Zugriffskontrollen funktionieren gut, wenn Benutzer in klar definierte Gruppen wie Data Engineer, Analysten oder Geschäftsanwender eingeteilt sind. Aber was ist mit Geschäftsanwendern, die in verschiedenen Geschäftsbereichen arbeiten, oder Anwendern in verschiedenen Regionen? Hier kommt ABAC ins Spiel.
Mit ABAC können Sie Richtlinien einmalig definieren und sie auf Kataloge, Schemata, Tabellen und mehr anwenden. Es gibt zwei Richtlinientypen. Zeilenfilterrichtlinien filtern Tabellen automatisch basierend auf den Attributen eines Benutzers – wenn ein Benutzer beispielsweise aus der EMEA-Region stammt, wird die Tabelle auf Datensätze aus dieser Region reduziert. Spaltenmaskierungsrichtlinien maskieren sensible Spalten, es sei denn, ein Benutzer gehört einer bestimmten Gruppe an, was eine unkomplizierte Möglichkeit bietet, die Preisgabe von PII zu reduzieren.
KI-Guardrails – PII-Erkennung:
Die oben genannten Kontrollen konzentrieren sich darauf, zu begrenzen, wer worauf zugreifen kann. Es ist jedoch ebenso wichtig zu überwachen, was tatsächlich vom Agenten zurückgegeben wird. Viele Kunden nutzen Agent Bricks AI Gateway als ihre zentrale Governance-Schicht für den KI-Zugriff. Über den einheitlichen Modellzugriff, das Routing, das Tracking und die Ratenbegrenzungen hinaus bietet KI Gateway Guardrails wie die PII-Erkennung, die sensible Daten automatisch blockieren oder schwärzen, wo immer sie in den Eingaben oder Ausgaben eines Modells erscheinen. Dies schützt vor Szenarien, in denen ein Agent manipuliert wird, um Daten preiszugeben, die er nicht preisgeben sollte.
Zusammenfassung: Kontrollen für den Zugriff auf sensible Systeme oder private Daten
Mit diesen Kontrollen sieht die Gefährdung von Social Gauge grundlegend anders aus. Selbst wenn der Agent durch einen Prompt-Injection-Angriff manipuliert wird, kann er nur auf die Daten zugreifen, auf die der anfragende Benutzer bereits Zugriff hat, die auf seine Region beschränkt sind, maskiert werden, wo sensible Spalten betroffen sind, und bei der Ausgabe auf PII überwacht werden. Ein Angreifer, der den Agenten kompromittiert, erbt nicht die Schlüssel zum Königreich; er erbt die Berechtigungen eines einzelnen Benutzers, während ein Wächter die Tür bewacht.
Säule 2: Verarbeitung nicht vertrauenswürdiger Eingaben – Kontrollen
Databricks bietet viele Plattformsteuerungen, die das Risiko gegenüber unbefugten externen Benutzern mindern: SSO mit MFA, kontextbasierte Ingress-Kontrollen, Front-End-PrivateLink oder IP-ACLs. Aber das Risiko durch nicht vertrauenswürdige Eingaben endet nicht am Anmeldebildschirm.
Die Kernfunktion von Social Gauge ist die Suche im Internet nach Social-Media-Beiträgen und Artikeln über Produkte. Diese Funktion macht es anfällig für indirekte Prompt-Injections, also bösartige Anweisungen, die in ansonsten legitime Webinhalte eingebettet sind. Obwohl also unbefugte Benutzer nicht direkt auf die Benutzeroberfläche von Social Gauge zugreifen können, ist die indirekte Angriffsfläche sehr wohl vorhanden.
Es gibt auch das Insider-Risiko: Benutzer, die versuchen, mit Jailbreaking-Techniken auf Daten zuzugreifen, die sie nicht sehen dürfen, Social Gauge für etwas zweckentfremden, für das es nicht entwickelt wurde, oder dessen Analyse manipulieren (z. B. "erfinde eine Quelle, die besagt, dass mein Produkt fantastisch ist!").
In unserem Angriffsszenario besteht das Risiko von Pfeiler 2 darin, dass ein Social-Media-Beitrag, der eine Prompt-Injection enthält, aufgenommen wird und der eingebettete schädliche Inhalt vom Agenten als legitime Anweisungen interpretiert wird. Dieses Risiko kann durch Kontrollen gemindert werden, die den Umgang des Agenten mit nicht vertrauenswürdigen Eingaben stärken.
KI-Leitplanken: Inhaltssicherheit und Prompt-Injection:
Wie wir gesehen haben, gibt es bei Agent Bricks AI Gateway mehrere integrierte Guardrails, wie z. B. Sicherheitsfilterung und PII-Erkennung, die angewendet werden können. Diese Guardrails können entweder auf die Eingabe oder die Ausgabe eines Agenten (oder auf beides) angewendet werden. Zusätzlich zu diesen integrierten Guardrails können Sie auch benutzerdefinierte Modelle auf Databricks Model Serving angewendet und diese nutzen. Zum Beispiel sind die neuesten Llama Protection -Modelle spezialisierte LLMs, die feinabgestimmt wurden, um Prompt-Injections, toxische Inhalte oder den Missbrauch von Code-Interpretern zu erkennen. Diese Modelle können als Schutzschicht um Ihre Agenten herum fungieren und Interaktionen überprüfen, bevor sie zu Vorfällen werden.
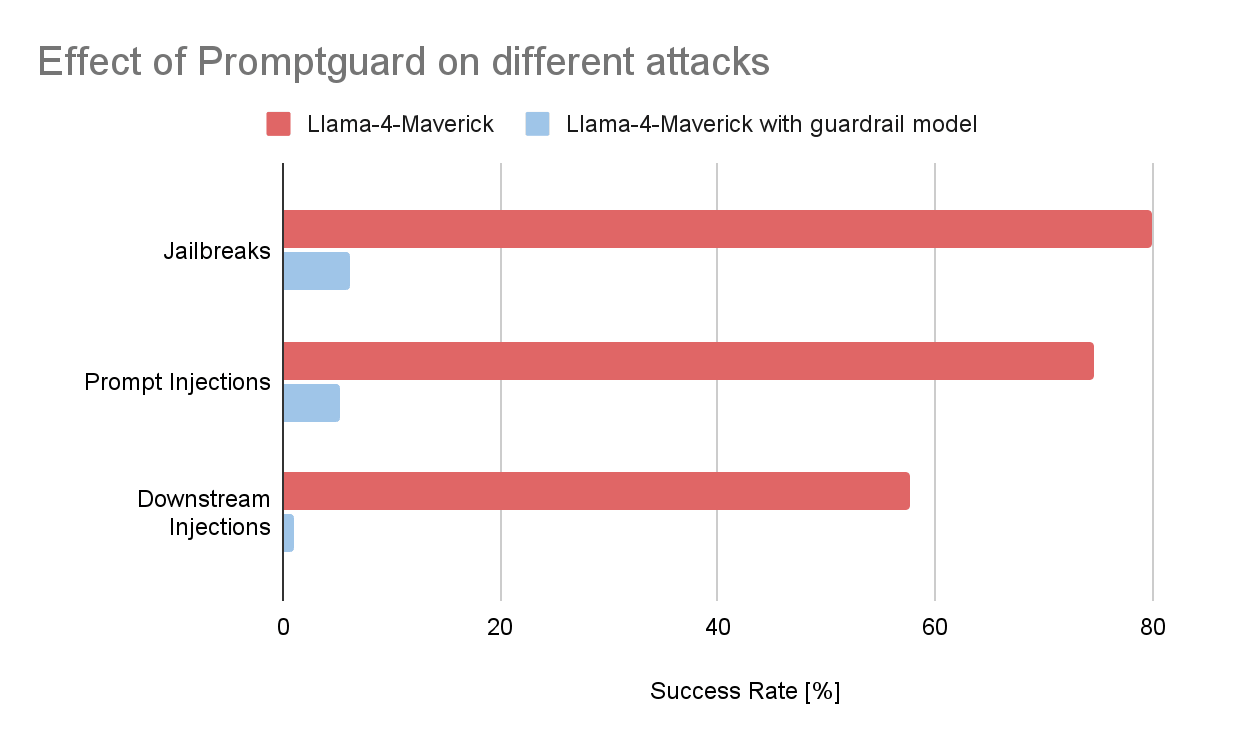
Um ein Gefühl dafür zu bekommen, wie wirksam diese Schutzmaßnahmen sein können, haben wir ein kleines Experiment durchgeführt. Wir haben einige hundert bösartige Prompts vom Garak-Schwachstellenscanner gesammelt, einem von NVIDIA entwickelten Open-Source-Tool für automatisierte LLM-Sicherheitstests, das sich einfach in Databricks integrieren lässt. Aus diesem Dataset (das) haben wir drei gängige Angriffskategorien ausgewählt:
- Prompt-Injektionen: Böswillige Anweisungen, die in Kontexten wie Websites, Übersetzungsaufgaben oder E-Mails versteckt sind und darauf ausgelegt sind, das Modell zu unbeabsichtigtem Verhalten zu verleiten.
- Jailbreaks: Sorgfältig gestaltete Prompts, die darauf abzielen, Alignment-Schutzmaßnahmen zu umgehen und schädliche oder eingeschränkte Ausgaben hervorzurufen.
- Downstream-Injektionsangriffe: Prompts, die versuchen, das Modell dazu zu bringen, Inhalte zu generieren, die erst dann gefährlich werden, wenn sie von einem anderen System interpretiert werden, zum Beispiel eine schädliche SQL-Anweisung, die von einer Anwendung ausgeführt wird, oder ein manipuliertes Markdown-Bild-Tag, das beim Rendern als HTML sensible Daten exfiltriert.
Anschließend haben wir die Erfolgsrate dieser Angriffe an einem Basismodell gemessen, in diesem Fall einer Llama-4-Maverick-Bereitstellung. Die Ergebnisse waren eindeutig. Ohne Guardrails löste ein erheblicher Teil der bösartigen Prompts erfolgreich das Zielverhalten aus. Als ein angepasstes Guardrail-Modell (Prompt Guard 2 für Prompt-Injections und Jailbreaks, Llama Guard 3-8b für nachgelagerte Injections) vor dem Modell platziert wurde, sank die Erfolgsquote in allen drei Kategorien um mehr als 90 %.
Wenn Sie daran interessiert sind, zusätzliche Guardrail-Techniken, Open-Source-Ansätze oder hochmoderne Modelle zur PII-Erkennung zu erkunden, wenden Sie sich an Ihren Databricks-Ansprechpartner, um mehr über benutzerdefinierte Guardrail-Bereitstellungen zu erfahren.
Prompt-Registrierung:
Ein gut gestalteter System-Prompt kann manchmal den Unterschied ausmachen, ob ein Angriff erfolgreich ist oder nicht. Er ist zwar nicht so robust wie ein dediziertes Erkennungsmodell, aber es lohnt sich, ihn richtig zu gestalten. MLflow Prompt Registry optimiert das Prompt-Engineering und die Verwaltung für GenAI-Anwendungen, sodass Sie Prompts in Ihrer gesamten Organisation versionieren, nachverfolgen, testen und wiederverwenden können, anstatt sie ad hoc zusammenzubasteln.
Zusammenfassung: Kontrollen für die Verarbeitung nicht vertrauenswürdiger Eingaben
Social Gauge liest weiterhin aus dem offenen Internet, das ist seine Kernanforderung. Aber die Angriffsfläche, die ein Angreifer ausnutzen kann, hat sich erheblich verkleinert. Bösartige Prompts, die in Webinhalte eingebettet sind, müssen jetzt ein feinabgestimmtes Erkennungsmodell überstehen, bevor sie den Agenten erreichen, und der System-Prompt wird versioniert und getestet, anstatt spontan zusammengestellt zu werden. Keine dieser Kontrollen ist für sich allein absolut sicher, aber in Kombination verwandeln sie eine weit offene Angriffsfläche in etwas, dessen Ausnutzung für einen Angreifer deutlich schwieriger ist.
Säule 3: Zustand ändern oder extern kommunizieren – Kontrollen
In der letzten Phase unseres Angriffsszenarios besteht das Risiko von Pillar 3 darin, dass der Agent, sobald die Prompt-Injection verarbeitet wurde, die Fähigkeit hat, die bösartigen Anweisungen auszuführen, entweder durch die Exfiltration von Daten nach außen oder durch deren Änderung innerhalb eines internen Schemas, um nachgelagerte Entscheidungen zu beeinflussen.
Social Gauge erweitert vorhandene Daten um Daten von Drittanbietern für Benutzer, die die Produkt-Performance untersuchen, was bedeutet, dass es naturgemäß in Kataloge, Schemata, Tabellen und andere Objekte schreiben muss. Der zugrunde liegende Zustand ändert sich. Wir konzentrieren uns auf drei Kontrollen: die Einschränkung des ausgehenden Netzwerkzugriffs, die Einschränkung des Zugriffs auf externen Speicher und die Einschränkung von Zustandsänderungen innerhalb von Unity Catalog.
Serverless-Egress-Kontrollen – Internetstandorte:
Selbst wenn eine Prompt-Injection vom Agenten verarbeitet wird, kann das daraus resultierende Schadensausmaß durch die Anwendung von Serverless-Egress-Kontrollen über Databricks-Netzwerkrichtlinien erheblich reduziert werden. Damit können Administratoren eine Deny-by-Default-Haltung für ausgehende Verbindungen von serverless Workloads (einschließlich Databricks Apps) definieren und dann explizit nur die vertrauenswürdigen Ziele zulassen, die der Agent tatsächlich benötigt.
Durch das Anhängen einer eingeschränkten Netzwerkrichtlinie an den workspace, der einen Agenten wie Social Gauge ausführt, begrenzen Sie die Fähigkeit des Agenten, beliebige Internet-Endpoints zu erreichen, wodurch die Angriffsfläche für indirekte Prompt-Injektionen verkleinert und das Risiko der Datenexfiltration an unbekannte Ziele verringert wird.
Serverless Egress-Kontrollen – Unity Catalog-Objekte:
Zusätzlich zur Beschränkung des Zugriffs auf bekannte Endpunkte über FQDN-Filterung ist die zweite Fähigkeit der Serverless Egress-Kontrollen die Möglichkeit, den Zugriff auf Cloud-Speicherorte wie S3-Buckets zu beschränken. Buckets, die dem workspace, den Systemtabellen und den Beispiel-Datasets zugeordnet sind, bleiben standardmäßig schreibgeschützt, aber diese Kontrolle geht noch weiter: Sie verhindert, dass ein KI-Agent in einen nicht genehmigten Bucket schreibt, und schließt damit einen der häufigsten Exfiltrationspfade.
Unity Catalog – Workspace-Bindungen:
Workspace-Katalog-Bindungen ermöglichen es Kunden, den Zugriff auf Kataloge von bestimmten Workspaces aus zu beschränken. Dies ist wichtig, wenn Entwickler über mehrere Umgebungen hinweg auf Daten zugreifen können, diese Daten aber keine Entwicklungsgrenzen überschreiten sollten. Ein Data Engineer hat möglicherweise die Berechtigung, Produktionsdaten zu lesen, sollte dies aber nicht von einem Entwicklungs-Workspace aus tun können.
Da Social Gauge mit OBO-Anmeldeinformationen arbeitet, verringern Workspace-Bindungen das Risiko, dass der Agent während des Betriebs in der Entwicklungsumgebung versehentlich den Zustand der Produktion ändert.
Zusammenfassung: Kontrollen zur Statusänderung oder externen Kommunikation
Durch serverless Egress-Kontrollen, die eine „Deny-by-Default“-Haltung für ausgehende Verbindungen durchsetzen und externen Speicher sperren, sowie durch Workspace-Bindungen, die Umgebungsgrenzen erzwingen, haben wir die offensichtlichsten Pfade für Exfiltration und Zustandsmanipulation unterbunden. Sprechen wir nun darüber, wie man das abfängt, was durchrutscht.
Monitoring Ihrer KI-Agenten auf Sicherheitsrisiken
Wie oben erwähnt, können Kunden das Agent Bricks AI Gateway verwenden, um den Zugriff auf alle KI-Modelle und -Agenten im gesamten Unternehmen zu verwalten und zu steuern. Diese Vereinheitlichung erstreckt sich auch auf die Beobachtbarkeit und das Monitoring. Mit dem AI Gateway können Sie alle Eingaben in und Ausgaben von KI-Modellen und -Agenten in Ihrer gesamten Organisation zentral über Inferenztabellen protokollieren, sodass Sie diese Daten zur Überwachung und Prüfung von KI-Anfragen sowie zur Verbesserung der Modell-Performance und -sicherheit verwenden können.
Inferenztabellen
Sie können die nachstehende Abfrage verwenden, um Ihre Inferenztabellen zu überwachen und zu sehen, ob einer der integrierten Schutzmechanismen ausgelöst wurde. Die Abfrage gibt an, welcher Trigger (Eingabe oder Ausgabe) ausgelöst wurde und welche schädlichen Kategorien erkannt wurden. Wenn es um Sicherheit geht, ist proaktives Handeln natürlich immer besser als reaktives. Sobald Sie die Abfrage validiert haben, lohnt es sich also, die zusätzlichen Schritte zu unternehmen, um sie als Benachrichtigung zu konfigurieren, die Sie oder Ihr Security Operations Center (SOC) automatisch informiert, wenn etwas eine Untersuchung rechtfertigen könnte.
Systemtabellen
Zusätzlich zu Inferenztabellen enthalten die Systemtabellen von Databricks eine Fülle von Einblicken in die wesentlichen Ereignisse, die in Databricks stattfinden. Wir haben in der Vergangenheit in unseren Blogs darüber geschrieben, wie sie genutzt werden können, um potenzielle Sicherheitsbedrohungen und Kompromittierungsindikatoren (Indicators of Compromise, IoCs) proaktiv zu überwachen und Alerts zu geben. Dies lässt sich auch auf die zentralen Sicherheitsrisiken für KI-Agenten ausweiten. Die nachstehende Abfrage kann beispielsweise verwendet werden, um die serverless Egress-Kontrolle zu überwachen und festzustellen, ob jemand (oder ein Agent) versucht, diese zu umgehen, um extern zu kommunizieren.
KI als Richter
Die Verwendung von KI als Richter ist im Bereich der Agenten und der künstlichen Intelligenz im Allgemeinen allgegenwärtig. Tatsächlich sind die meisten Guardrail-Modelle im Wesentlichen LLMs, die durch Feinabstimmung angepasst und/oder durch spezifische System-Prompts gesteuert werden, um diesem speziellen Zweck zu dienen. Wie oben erwähnt, ist es einfach, benutzerdefinierte Modelle auf Databricks Model Serving bereitzustellen, und wir haben Beispiele für die Bereitstellung der meisten der neuesten und besten Guardrail-Modelle wie Llama Guard 4 und Llama Prompt Guard 2 auf Databricks. Über die Bereitstellung als benutzerdefinierte Guardrails hinaus ist einer der Vorteile der offenen, modularen Architektur von Databricks, dass Sie ein Modell, sobald Sie es mit dem generischen `mlflow.pyfunc`-Flavor von MLflow protokolliert haben, auf vielfältige Weise nutzen können. Einige Beispiele sind die Bereitstellung als Batch-Spark-Workflows oder deklarative Spark-Pipelines, der Aufruf über SQL mit ai_query oder sogar die Anwendung in Szenarien mit Nahezu-Echtzeit- oder Micro-Batch-Verarbeitung mit Spark Structured Streaming.
In einigen Fällen ist die Anwendung von Guardrails auf jede Anfrage oder Antwort möglicherweise nicht durchführbar. Es ist ein absolut valides Szenario, in dem Guardrails das Geschäftsziel oder den Fachbereich, in dem der Agent tätig ist, beeinträchtigen können. Selbst wenn Guardrails nicht erzwungen werden, können wir die Sicherheit unserer Agenten weiterhin überwachen, indem wir ihre Inferenztabellen und eine Batch- oder Streaming-Pipeline zur Klassifizierung potenziell schädlicher Inhalte verwenden.
Weitere Ressourcen
Die in diesem Beitrag beschriebenen Kontrollmaßnahmen sind ein Ausgangspunkt, nicht das Ziel. Das Risiko der Prompt-Injection entwickelt sich weiter, da die Agenten immer leistungsfähiger werden. Das Ziel ist ein wiederholbares Sicherheitsprogramm, das Schritt hält. Dies wird keine einmalige Härtungsmaßnahme sein!
Diese Sicherheitsmuster für Agenten prägen auch die nächste Weiterentwicklung des Databricks AI Security Framework. Ein bevorstehendes Update für DASF erweitert das Framework, um autonome KI-Agenten, Tool-Nutzung und aufkommende Risiken durch Prompt-Injection zu adressieren. Dies hilft Organisationen, vollständige KI-Systeme abzusichern, nicht nur Modelle.
Wir haben die relevantesten Ressourcen in drei Phasen gegliedert:
Definieren:
- Das Databricks AI Security Framework (DASF) 2.0 bietet eine umfassende Risikoanalyse für 12 Kernkomponenten von KI-Systemen und bildet Standards wie MITRE ATLAS, NIST, OWASP und HITRUST ab. Es bietet 67 praktische Kontrollen zur Reduzierung von Risiken wie Prompt-Injection, Jailbreak und Datenexfiltration. In diesem Blog erläuterte DASF-Kontrollen:
- DASF 5: Zugriff auf Daten und andere Objekte steuern
- DASF 64: Zugriff von KI-Modellen und Agenten beschränken
- DASF 57: Verwendung von attributbasierter Zugriffskontrolle (ABAC)
- DASF 58: Daten mit Filtern und Maskierung schützen
- DASF 54: KI-Guardrails implementieren
- DASF 62: Netzwerksegmentierung implementieren
- DASF 37: Inferenztabellen zum Monitoring und zum Debugging von Modellen einrichten
- DASF 49: LLM-Evaluierung automatisieren
- DASF 73: Prompts registrieren
- DASF 55: Audit-logs überwachen
- Das Databricks AI Governance Framework (DAGF) definiert, wie Organisationen KI-Systeme über ihren gesamten Lebenszyklus hinweg steuern sollten, von der Konzeption und Entwicklung bis hin zur Bereitstellung und Monitoring.
- Die Databricks Security Best Practice guides (für AWS, Azure und GCP) bieten einen detaillierten Überblick über die wichtigsten Sicherheitskontrollen, die wir für typische und hochsichere Umgebungen empfehlen, und basieren auf den Erkenntnissen aus der Zusammenarbeit mit unseren sicherheitsbewusstesten Kunden.
Anwenden
- Die Databricks Security Reference Architecture – Terraform Templates (SRA) ermöglicht die Bereitstellung von Databricks-Workspaces und Cloud-Infrastruktur, die mit Best Practices für die Sicherheit konfiguriert sind.
Überwachen:
- Das Security Analysis Tool (SAT) hilft Sicherheits- und Plattformteams dabei, die Sicherheitslage von Databricks-Workspaces schnell zu bewerten.
- Databricks Detection Tool: eine Reihe von vorgegebenen Erkennungen, die in einem benutzerfreundlichen Notebook zusammengefasst sind und Ihnen helfen, die Aktivitäten in Ihren Workspaces zu überwachen.
Die Zusammenführung dieser Ressourcen bietet Ihren Teams eine pragmatische Möglichkeit, von der punktuellen Härtung eines einzelnen Agenten zu einem wiederholbaren, skalierbaren Sicherheitsprogramm für KI auf Databricks überzugehen – einem Programm, das sowohl mit Ihrer Innovation als auch mit der sich entwickelnden Bedrohungslandschaft Schritt halten kann.
(Dieser Blogbeitrag wurde mit KI-gestützten Tools übersetzt.) Originalbeitrag
Erhalten Sie die neuesten Beiträge in Ihrem Posteingang
Abonnieren Sie unseren Blog und erhalten Sie die neuesten Beiträge direkt in Ihren Posteingang.